基于深度集成学习的类极度不均衡数据信用欺诈检测算法
2021-04-01刘颖杨轲
刘 颖 杨 轲
1(吉林财经大学管理科学与信息工程学院 长春 130117) 2(吉林财经大学税务学院 长春 130117)
(lyaihua1995@163.com)
经济全球化背景下,金融衍生品的加速膨胀导致市场波动加剧、信用欺诈行为不断出现.信用欺诈识别是通过挖掘征信数据中蕴含的客观规律而对申请人信用等级进行划分,其本质属于二分类问题.然而,在构建信用分类模型时,信用样本的涌现性使得少数类样本点很少,即在获取大量的实际样本中,真正存在欺诈行为的样本点远少于非欺诈行为样本点.在处理这种样本不均衡信用欺诈数据时,错误识别一个信用差的客户往往要比误分一个信用好的客户给企业造成的损失大.因此,提升模型对不平衡数据的分类效果成为信用欺诈识别领域的研究重点.
目前,解决类不均衡问题的相关研究主要集中于重采样方法和集成算法2方面.重采样方法包括欠采样和过采样2种.其中过采样方法以合成少数类技术(synthetic minority oversampling technique, SMOTE)[1]为主要代表,并在所选样本近邻之间插入数据以实现类均衡.虽然历经数十年该方法已经发展成为解决类不均衡问题的经典方法,但SMOTE的算法仍然存在其自身的缺陷.Nguyen等人[2]在2009年以支持向量机(support vector machine, SVM)处理类不均衡数据为例,实验指出当分类样本重叠时,通过SMOTE随机采样可实现SVM分类器在重叠区域的无偏估计.然而如果少数类样本距离理想边界相对较远或者有效样本过少,便很难利用SMOTE随机插值法扩张少数样本.也就是说,当理想样本数量较少,或者样本存在一定数量的噪声、离群点时,SMOTE方法在某种程度上会放大无效样本的影响,进而降低分类精度.针对这一问题,学者们提出其他改进SMOTE方法,如BorderlineSMOTE[3],KMeansSMOTE[4],Generative Adversarial Networks[5].
为了减少训练集不完善对分类性能的影响,学者们也提出集成方法处理类不均衡问题.Chen等人[6]提出对随机森林(random forest, RF)分类器进行样本再平衡,在RF每次迭代的过程中,对不同类别样本的采样数量加以控制:分别从少数类和多数类样本中有放回地抽取一定数量的样本.Liu等人[7]提出Easy Ensemble算法,综合运用欠采样和AdaBoost算法解决欠采样方法丢失多数类样本有效信息的不足.具体而言,将多数类样本分成若干个与少数类样本集相同大小的子集,对每一个多数类样本的子集,将其与少数类样本合并后训练基分类器,最后利用AdaBoost算法集成.此外,Seiffert等人[8]提出RUSBoost算法,在AdaBoost的每次迭代过程中,随机抽取与少数类样本数量相同的多数类样本训练迭代分类器,综合运用随机欠采样和AdaBoost来处理类不均衡问题.Sun等人[9]构建一种装袋法(bagging)集成,即在类不均衡数据集中抽取若干均衡数据子集得到基分类器,最终通过集成规则预测输出训练结果.Díez-Pastor等人[10]研究随机均衡集成,利用特定分类器考虑受试者工作特征曲线(receiver operator characteristic curve, ROC)上不同的执行点,输出更大的曲线下面积(area under curve, AUC)值.夏利宇等人[11]提出迭代重抽样集成模型,在欠抽样的迭代中不断优化模型对于多数类和少数类样本的倾斜,并通过我国征信数据证明了该模型可以显著降低金融机构的违约风险.
大数据时代的金融改革背景下,半结构、非结构化数据大量涌现,深度学习作为一种端到端的数据驱动方法,越来越多的被学者应用于信用欺诈识别[12].Sohony等人[13]采用综合随机森林和神经网络集成算法处理类不均衡问题.Kazemi等人[14]提出使用深度自动编码器从交易数据样本中提取合适特征,并基于这些特征使用Softmax网络识别样本类别.Roy等人[15]使用云计算环境分析证明了神经网络及其拓扑结构在处理信用欺诈问题中的显著表现.Luo等人[16]利用深度信念神经网络(deep belief neural network, DBN)建立信用评估模型对信用违约互换(credit default swaps, CDS)数据进行评估,并将其表现与逻辑回归(logistic regression, LR)、多层感知器(multilayer perceptron, MLP)、SVM等传统机器学习算法比较,证实了DBN拥有最为优异的AUC值.Kim等人[17]基于韩国信用卡公司的实际数据,使用冠军-挑战者测试(champion-challenger)框架分别构建和比较Bagging集成算法和前馈神经网络学习模型,实验表明前馈神经网络算法的复杂神经元更适合处理高维、复杂的信用欺诈数据.
上述方法均能在一定程度上解决不平衡数据分类问题,但仍然存在两大不足:1)评估指标体系不完善.多数文献仍然基于总体分类准确率为目标,必然导致过度关注信用好的多数类样本,忽视信用差的少数类样本.2)较少考虑类极度不均衡问题.部分显示所处理类不均衡数据比例(少数类样本与多数类样本比值)通常不超过1∶10,而在现实的信用欺诈检测中,样本比例往往会达到1∶50,甚至更高.在这种类极度不均衡情况下,算法的设计和测试将面临极大挑战.本文提出一种基于深度信念神经网络集成的类极度不均衡信用欺诈算法.一方面提出双向联合采样法抽取样本,融合欠采样和过采样方法平衡数据集.同时,为了克服SVM在处理极度不均衡数据分类超平面偏移问题,将SVM结合RF生成基分类器簇,利用DBN集成输出.另一方面,提出成本-效益指数,以量化的成本收入改善评价性能.最后,论文以真实发生的欧洲信用卡欺诈数据进行测试,并与传统机器学习算法和类不均衡经典算法进行性能对比.
1 相关工作
1.1 支持向量机(SVM)
SVM[18]于20世纪60年代提出,主要任务是在处理二分类问题中寻求最优超平面.考虑一个有m个样本的n维样本集{(X1,y1),(X2,y2),…,(Xm,ym)},其中,第i个样本的特征为Xi=(x1,x2,…,xn),第i个样本的类标签为yi∈{0,1},超平面定义为
W·X+b=0,
(1)
其中,W=(w1,w2,…,wn),X=(x1,x2,…,xn).对于超平面∀yi=1,W·Xi+b>0;∀yi=-1,W·Xi+b<0,即∀i,yi(W·Xi+b)≥1,SVM的二分类问题转化为规划求解问题,即

(2)
使用拉格朗日公式可得决策边界:
(3)
其中,l表示支持向量个数,Xi为支持向量点的特征向量,yi为支持向量点的类标记,X为输入实例的特征向量,αi和b0为训练模型得到的参数,αi为拉格朗日乘数.
最后,SVM对目标样本的分类识别公式为
f(X)=sgn(decision(X)).
(4)
对于线性不可分的数据集,通过非线性变换将其转换为高维空间中的线性分类问题,以核函数K(x,z)代替两实例之间的内积即可得到非线性求解公式:
(5)
SVM常用核函数包括径向基函数(radial basis function, RBF)、二项式核函数(binomial kernel function, BKF),本文在求解过程中使用RBF核函数.
1.2 SVM处理非均衡数据性能分析
SVM作为一种经典的模式识别方法,具有泛化能力强、结构简单、易解决高维和小样本数据优势.通常SVM分类算法基于正负类样本数量大致相同的假设,因此样本不均衡可能造成SVM算法分类超平面发生偏移.为了比较非均衡数据对SVM分类器的影响,论文以美国加州大学尔湾分校开发的蘑菇数据集(UCI mushroom)[19]作为实验样本,其总数为8 124,包括6 093个训练样本、2 031个测试样本、22个特征维数.为了更好地可视化,利用主成分分析(principal component analysis, PCA)降至2维.对训练样本进行抽取,分别构建1∶4,1∶40,1∶100的非均衡样本集合.实验选择SVM、基于过采样的SMOTE平衡样本的SMOTE_SVM及基于随机欠采样(random under sampling, RUS)的RUS_SVM这3种模型测试比较,结果如表1所示:
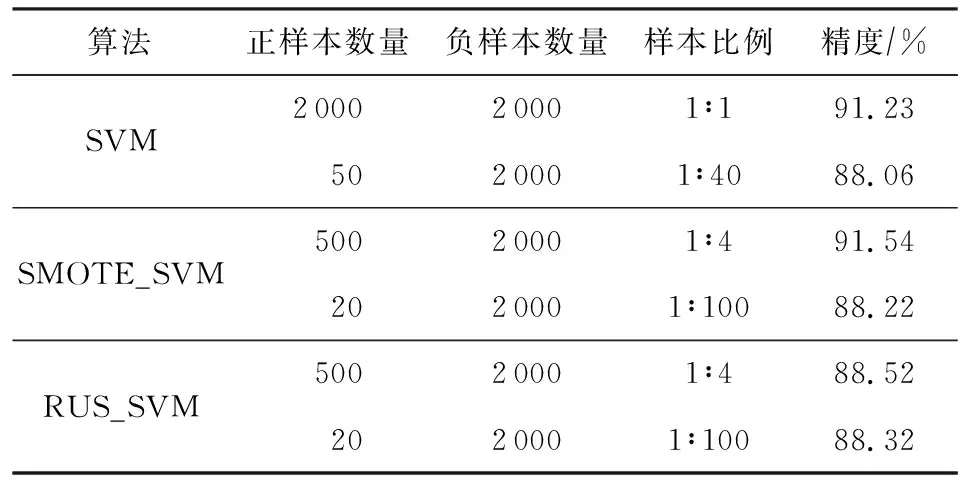
Table 1 Experiment Description of SVM with Imbalanced Data
实验表明,当样本出现不均衡现象时,重采样方法某种程度上会提高分类精度,但对于样本出现极度不均衡现象时表现效果不佳.
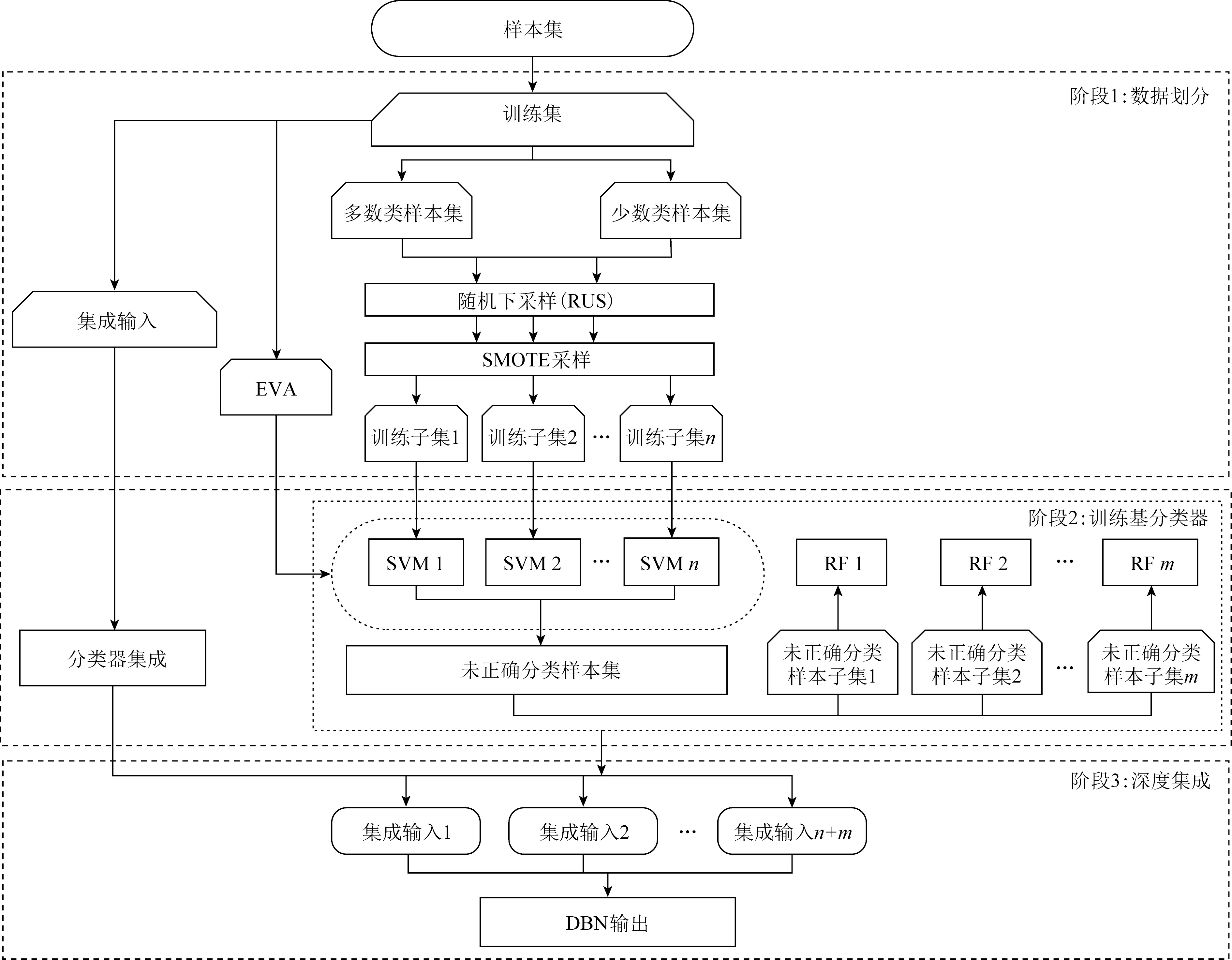
Fig. 1 Framework for DBN ensembled algorithm图1 DBN深度集成算法框架
2 本文方法
本节首先给出深度信念神经网络集成框架,然后介绍双向联合采样法及DBN深度集成算法,表2列出了本文后续内容使用的一些符号定义.

Table 2 Description of Symbols表2 符号描述

Continued (Table 2)
2.1 算法整体框架与流程
DBN集成算法分为3个阶段实现:1)数据划分,主要利用双向联合采样法平衡训练子集;2)训练基分类器,为了解决SVM在处理数据极度不均衡时超平面偏移问题,综合SVM和RF双重分类器构建基分类器集;3)DBN深度集成.算法整体框架与流程如图1所示:
2.2 算法详细步骤
阶段1.数据划分.首先,在控制采样比例的前提下对训练集中多数类样本和少数类样本进行随机欠采样,然后,针对训练子集执行SMOTE过采样.确定该训练子集中支持向量及其近邻数量,若其近邻数量较少,采取外推方式合成新样本,若其近邻数量较多,采取插值方式合成新样本.迭代上述采样过程,直至训练出与本文设计的SVM分类器相同数量的训练子集.
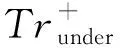
算法1.joint_sampling().
① forc∈[1,num_svm]
② 由Tr提取Trmaj,Trmin;
③ 确保L∶S<10∶1,且S>60;
在Trmaj中随机抽取L个样本,在Trmin中随机抽取S个样本组成Trunder;
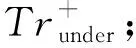
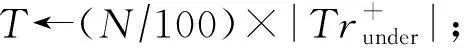
⑤ 由Trunder训练SVM分类器,得到Sv+;
⑥ 在Sv+中平均分配T,得到amount;
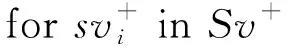
⑨ 由Trunder确定m个近邻;
阶段2.训练基分类器.首先,由算法1采样得到的训练子集训练SVM分类器得到SVM基分类器簇.针对每个SVM基分类器,都从训练集中不放回抽取一定数量的样本构成评估集,共采集若干个互不重叠的评估集,并以该SVM基分类器对这些评估集进行预测,生成未能正确分类样本集Failure,以其为新的训练集训练RF基分类器,最后组合SVM和RF基分类器簇构成本文的基分类器集合.
本算法涉及的局部变量:num_eva表示每个SVM基分类器设置的评估集数量,num_sample_in_eva表示每个评估集采集的样本数量,num_sample_for_rf表示训练RF基分类器时从指定样本中分别抽取多数类和少数类样本的数量,Svm表示训练的支持向量基分类器簇.Rf表示训练的随机森林基分类器簇.具体算法如下:
算法2.base_clf_training().
① forc∈[1,num_svm]
② 由Trsc训练SVM分类器;
③ end for
④ forsvm∈Svm
⑤ fork∈[1,num_eva]
⑥ 从Tr中采集num_sample_in_eva个样本构成Evasvmk;
⑦ 使用svm对Evasvmk进行预测,输出
Predictsvmk;
⑧ 在Evasvmk中筛选出Predictsvmk错误预测的子集放入Failure;
⑨ end for
⑩ end for
阶段3.深度集成算法.首先从训练集中抽取一个样本集;然后针对每个样本都由基分类器集合中的每个基分类器预测其结果,从而形成以样本为行向量、各分类器预测结果及样本真实标签为列向量的训练集.以该训练集训练DBN集成模型,并对测试集完成预测输出,具体算法如算法3、算法4:
算法3.DBN_ensemble_training().
① forc∈[1,num_clf]
② 由Clfc预测E得到Eic;
③ end for
④ 由矩阵(Ei,E(N+1))训练深度信念神经网络.
算法4.DBN_ensemble_predict().
① forc∈[1,num_clf]
② 由Clfc预测T得到Applicantc;
③ end for
④ 由深度信念神经网络预测Applicant输出Output.
3 实验与结果
3.1 数据描述
本文实验数据选取源讯科技(Worldline)公司和布鲁塞尔自由大学机器学习研究小组共同开发和维护、经由Kaggle平台发布的信用卡欺诈数据[20-26].数据集表征了2013年9月欧洲信用卡持卡人发生的部分交易及其相关信息.实验数据集(详见表3)共有21 693个样本,28个特征向量经由PCA进行了预处理.样本类别由0和1表示,其中0表示信用好样本(又称负类样本)且为多数类,1表示欺诈样本(又称正类样本)且为少数类样本.少数类样本356个,多数类样本21 337个,不平衡比例达到1∶60,达到类极度不均衡比例.

Table 3 Description of Experiment Data表3 实验数据描述
3.2 评价指标
通常,处理类不均衡学习算法可经由ROC曲线下面积AUC来评估其效果[7,16].但当负类样本与正类样本数量差异较大时,ROC的AUC难以显著区分分类器性能.在混淆矩阵中,TN表示被正确识别的负类样本,FP表示被错误识别的负类样本,FN表示被错误识别的正类样本,TP表示被正确识别的正类样本,其中,真正类率TPR=TP(TP+FN),真负类率TNR=TN(FP+TN),假正类率FPR=FP(FP+TN),假负类率FNR=FN(TP+FN).在负类极多、正类极少的情形下,假正类率FPR的分母过大,即使其分子有显著变化,也很难被明显地体现在FPR数值及其最终对应曲线上.同时,单纯考虑混淆矩阵各数值的绝对指标和相对指标会潜在地忽略信用欺诈的现实情境.鉴于此,Yu等人[27]提出成本-效益指数(revenue cost index,RCI),但该指数强调现实成本而忽视机会成本,本文在此基础上完善该评价指标对机会成本的考虑.指标做3个假设:1)信用卡供应商因某笔交易产生一个FP而承担的显隐性成本之和为该笔交易数额的资金在一个记账期内所产生的利息;2)欺诈行为人实施欺诈行为后不会被抓获;3)一个记账期内的利息为10%.
成本-效益评估指标RCI构建公式为
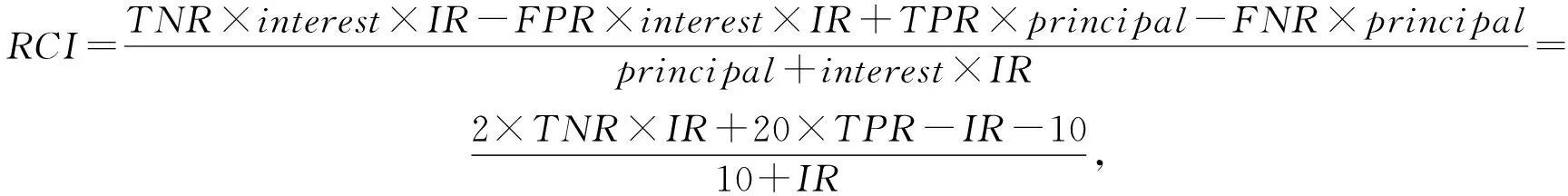
(6)
其中,分子表示期望收益,分母用于将指标数值归一;样本类不均衡比例(imbalance ratio,IR)为样本的不均衡程度,它为样本中多数类样本的数量与少数类样本数量的比值.
3.3 实验结果
本节为了比较所提DBN集成算法的性能,与类不均衡经典算法Balanced Random Forest[6],Easy Ensemble[7],Rus Boost[8],SMOTE_SVM[2],及常用机器学习算法Random Forest[28],SVM[18],MLP进行对比,分别实现基于不同算法和不同样本比例的分类结果.
3.3.1 基于不同算法的实验结果
在第1阶段的双向联合采样法中,设定参数S=100,L=900,N=900,k=5,m=10;在第2阶段的基分类器训练中,设定参数num_svm=100,num_rf=20,num_eva=10,num_sample_in_eva=1 000,num_sample_for_rf=200.本实验进行20次随机实验,最终输出8个分类器的RCI均值,实验结果如表4所示.

Table 4 Comparation among Credit Fraud Detection Machine Learning Algorithms表4 信用欺诈检测机器学习算法比较 %
从表4不难发现,在本文设定的成本-效益指数下,DBN深度集成算法产生了最好的效果,RCI达到95.19%,高于传统Random Forest的94.75%,SVM的92.80%,MLP的90.93%三种算法.综合来看,DBN深度集成算法在RCI指标上较其他算法的平均值高出3个百分点.同时,图2显示各个分类器的综合混淆矩阵,包括20次实验TN,TP,FN,FP的平均值.类不均衡算法实现了最高的TP值,但TN较低,削弱了成本-效益的综合表现.DBN集成算法优势是能够在较高TNR值的情况下提高TPR的值,进而获得较高的RCI值.
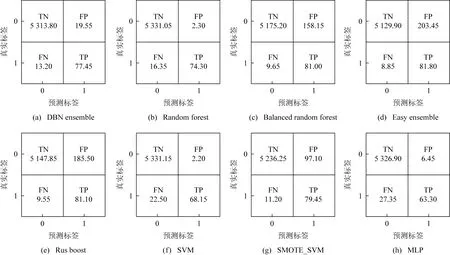
Fig. 2 Confusion matrix summary for 8 algorithms图2 8种算法在本次实验中的混淆矩阵比较
3.3.2 基于不均衡样本比例实验结果
为了比较所提算法在样本不均衡比例下的性能变化,本节固定少数类样本数量,调整多数类样本获得样本比例1∶5至1∶55共计11组测试数据集,分别比较8种算法的RCI指标,结果如图3所示.在类不均衡比例较低时,DBN深度集成算法的RCI指标并不能显著高于其他算法;但随着类不均衡比例不断提高,尤其当类不均衡比例超过20进入类极度不均衡状态之后,DBN深度集成算法的RCI表现优于其他算法.
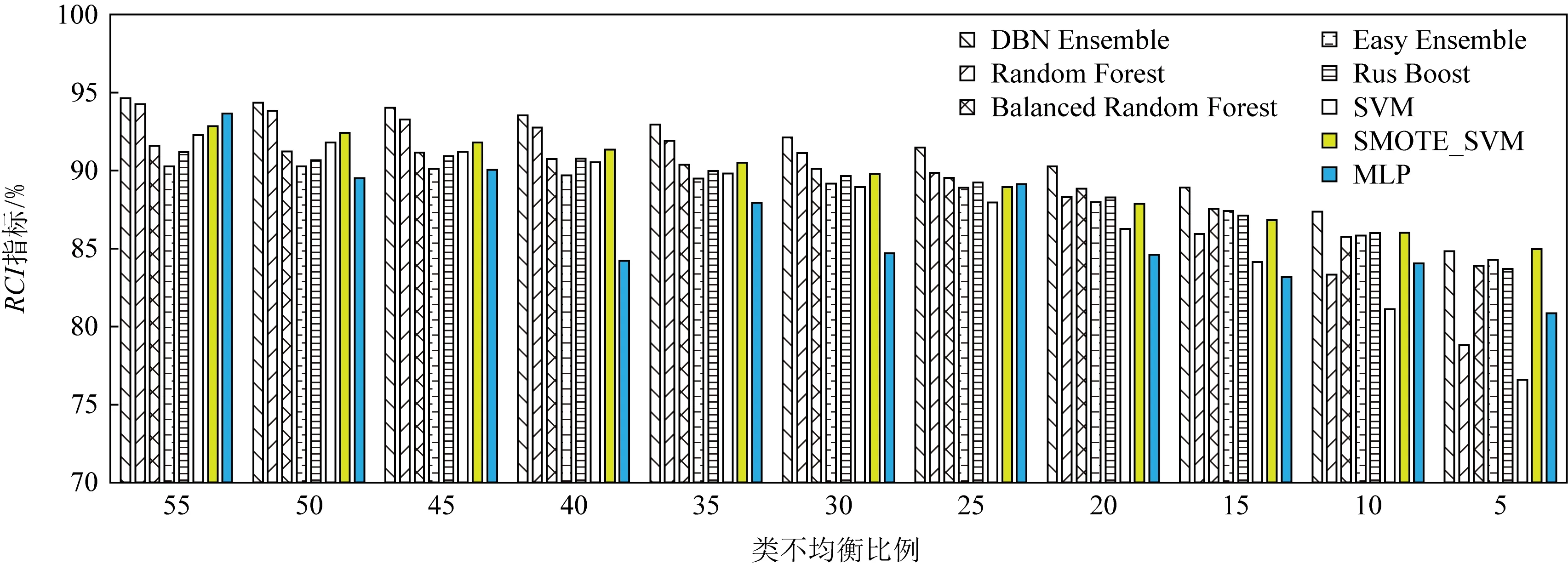
Fig. 3 Comparison of algorithms for different sample proportions图3 不同样本比例算法比较
4 结 论
样本分布极度不均衡是影响信用欺诈评估的主要因素.本文提出一种深度信念神经网络集成算法来解决类极度不均衡问题.一方面,提出双向联合采样法平衡样本集,为了克服单一SVM分类器处理不平衡数据表现的超平面偏移问题,融合RF分类器构建基分类器簇,利用DBN学习增强对多维伯努利数据的特征识别能力,从而更好地处理信用欺诈检测不均衡数据的极端情形.另一方面,鉴于传统的精度评价指标对信用欺诈风险评价形成较大制约,本文综合考虑正负类样本对数据使用者成本和效益的不同影响,提出成本-效益评估指标评价算法性能.通过对比实验发现在样本类极度不均衡情况下所提算法优于传统机器学习算法和一般类不均衡数据处理方法.
未来的工作包含2个方向:1)进一步结合行业的实际特点建立更加全面的计算成本效益指标数学模型;2)探索本文提出算法的参数优化策略.
