基于Storm平台的数据恢复节能策略
2021-04-01蒲勇霖李梓杨国冰磊
蒲勇霖 于 炯 鲁 亮 李梓杨 国冰磊 廖 彬
1(新疆大学信息科学与工程学院 乌鲁木齐 830046) 2(中国民航大学计算机科学与技术学院 天津 300300) 3(新疆财经大学统计与数据科学学院 乌鲁木齐 830012)
(puyonglin1991@foxmail.com)
近年来,随着各种功能强大的高速互联技术的出现,物联网场景下产生的数据量日益增多,对计算能力的需求日益增长,高性能集群由于其高性价比、高可用性以及可扩展性等特点[1]已成为商业应用与学术研究的基础架构.但是各种高性能集群在处理数据时产生的高能耗问题同样不容忽视.高德纳(Gartner)公司指出预计到2015年,全球数据中心占比71%的大型数据中心其电费支出超过1 262亿美元[2],而预计2020年,全球数据中心的能耗产值为20 000亿kW·h[3].我国数据中心的总耗电量同样惊人,截至2018年中国数据中心的总耗电量为1 608.89亿kW·h,占全国总用电量的2.35%[4].高额的能耗成本已对社会与环境造成巨大影响,因此解决IT行业的高能耗问题已经刻不容缓.
希捷(Seagate)公司与IDC联合发布的《数据时代2025》白皮书中预测,2025年全球数据量将达到163ZB.其中,超过25%的数据将成为实时数据,而物联网实时数据占比将达到实时数据的95%[5].针对大数据处理的高性能集群一般分为批量计算框架与流计算框架2类.其中批量计算框架由于存在先存储后计算的特性无法满足实时数据的处理需求;而流计算框架由于其强大的实时性,为实时大数据分析提供了良好的平台层解决方案[6].但是流式计算在高速处理实时数据的过程中同样伴随着高能耗的问题[7],因此流计算框架的节能优化是一个亟待解决的问题.
目前针对大数据流式处理的平台主要以Apache Storm框架[8]为主.Storm是一个主从式架构、开源、横向扩展性良好且容错能力强的分布式实时处理平台,其编程模型简单,支持包含Java在内的多种编程语言,且数据处理高效.与不开源的Puma[9]以及社区冷淡的S4[10]相比,Storm具有更活跃的社区发展;与属于微批的Spark Streaming[11]框架相比,Storm具有更稳定的集群性能;与后起之秀Flink[12]与Heron[13]相比,Storm具有更成熟的平台架构和更广泛的产业基础.目前Storm凭借低延迟、高吞吐的性能优势以及高效的容错机制[14],已经成为华为、百度以及小米等企业针对流数据处理业务的最佳选择,被誉为“实时处理领域的Hadoop”[15].
在Storm框架中,流式作业(拓扑)中的1个任务通常运行于1个工作线程内,1个工作进程包含有多个工作线程.但当Storm集群拓扑在处理任务出现计算资源不足或拓扑报错时,缺乏合理的应对策略,从而对集群拓扑任务处理的计算延迟与能耗造成影响,具体体现有2点:1)集群拓扑在执行任务时,工作节点可能会出现资源瓶颈的问题,工作节点的资源接近溢出,其功率不断增大,集群的计算延迟不断上升,对集群的性能与能耗造成巨大影响;2)拓扑在执行任务时,由于网络等问题而出现错误,需要终止拓扑内的任务并从磁盘重新读取数据,但是从磁盘读取数据存在较高的计算延迟与能耗,会对集群拓扑任务的正常执行造成一定的影响.因此,为了解决该问题.本文提出基于Storm平台的数据恢复节能策略(energy-efficient strategy based on data recovery in Storm, DR-Storm),该策略在降低集群出现过高计算延迟的基础上,保证集群拓扑任务的顺利执行并有效节约能耗.
本文的主要贡献包括3个方面:
1) 通过分析Storm框架的任务逻辑,建立任务分配模型,用于描述集群内工作节点间任务分配的逻辑关系,为后续监控集群拓扑内的元组信息提供帮助,并为研究集群拓扑内的任务执行情况奠定了理论基础.
2) 根据任务分配模型,建立了拓扑信息监控模型,通过监控反馈信息判断是否终止拓扑内的任务,并进一步建立数据恢复模型,其中是否对集群拓扑进行数据恢复由拓扑信息监控模型反馈的元组信息决定.在确定终止集群任务后,对集群拓扑进行数据恢复.
3) 根据拓扑信息监控模型与数据恢复模型,建立能耗模型,并在此基础上提出基于Storm平台的数据恢复节能策略,该策略包括吞吐量检测算法与数据恢复算法,其中吞吐量检测算法通过监控拓扑内的元组信息计算集群吞吐量,判断是否终止集群拓扑内的任务;而数据恢复算法根据吞吐量检测算法执行情况,确定是否对集群拓扑进行数据恢复.此外,实验选取4个代表不同作业类型的基准测试[16],从不同角度验证了算法的有效性.
1 相关工作
目前针对Storm,Flink,Spark Streaming,Heron等主流大数据流式计算框架的节能研究相对较少.但是IT行业日益增长的高能耗问题,已经严重制约着平台的发展.因此针对大数据流式计算框架的节能优化已经刻不容缓,是未来重要的研究方向.目前针对大数据流式计算框架的节能研究主要集中于硬件节能[17]、软件节能[18]与软硬件结合[19]3种方法.
硬件的节能主要基于2种思路:1)通过用低能耗、高效率的电子元件替换高能耗、低效率的电子元件[20];2)对集群的节点电压进行缩放管理[21].2种思路的节能效果显著,但是由于其价格高昂,且对节点电压进行缩放管理存在较大误差,因此不适合部署在大规模的集群当中.蒲勇霖等人[22]通过对Storm集群工作节点的内存电压进行动态调节,在不影响集群性能的条件下分别节约了系统28.5%与35.1%的能耗.Shin等人[23]提出了一种混合内存的节能策略,通过用低能耗高效率的PRAM(parallel random access machine)替换高能耗低效率的DRAM(dynamic random access memory),从而达到提高集群性能并降低能耗的目的.实验结果表明该策略降低了集群36%~42%的能耗.Pietri等人[24]通过将流式处理平台的部分CPU替换成GPU,使得CPU与GPU进行混合,从而减少了集群处理图数据的能耗,实验结果表明在节约9.69%能耗的前提下减少了8.63%的访问时间.文献[25]通过使用动态电压频率缩放技术(dynamic voltage frequency scaling, DVFS),对集群节点的CPU电压进行了动态缩放管理,以此达到了节能的效果.文献[26-28]通过替换高能耗、低效率的电子元件,在提高集群性能的基础上节约了能耗.
软件与软硬件结合的节能策略是目前研究的重点,其中软件的节能主要根据建立能耗感知模型[29]与通过资源调度[30]提高集群的能效,以达到节能的目的.文献[31]根据分析Spark Streaming框架的基本特性,提出一种自适应调度作业的节能策略,该策略通过在集群中建立能耗感知模型,对集群内的数据信息进行实时捕捉,从而分析集群任务的实际运行情况,根据不同任务的执行结果对集群的性能与能耗进行调控.实验表明该策略降低了集群的时间开销并节约了能耗.文献[32]提出一种作用于Spark Streaming的能耗分析基准测试方法,该方法通过使用机器学习算法,查找集群内数据流的大小与通信开销的平衡,实验结果表明当集群内数据流的大小与通信开销达到平衡时,集群执行任务的功耗最小.
文献[7]对流式大数据处理的框架进行了优化,提出了一种基于Storm框架的实时资源调度节能策略,该策略通过构建Storm的能耗、响应时间以及资源利用率之间的数学关系,获得了满足高能效和低响应时间的条件,并以此建立了实时资源调度模型,该模型在实现最佳能效的前提下,对集群的资源进行调度.然而该策略还存在2点值得探讨:1)节能策略只考虑了CPU的资源利用率与能耗,忽视了集群其他电子元件(内存、网络带宽与磁盘等)的资源利用率与能耗.由于流式处理集群的实时性较高,其他电子元件的资源利用率与能耗对其影响巨大而不容忽视;2)该节能策略使用自己定义的拓扑,而非公认的数据集,因此缺乏一定的通用性.
软硬件结合的节能主要通过对资源迁移后节点的电压进行动态缩放管理[33]或关闭其空闲的节点[34],以达到节能的效果.文献[35]通过分析流式大数据的自身特性,设计了2种节能算法,即能量感知副本算法与性能和能量均衡副本算法.2种节能算法根据集群任务的实际运行情况,对任务完成后或不执行任务处理的节点进行降压处理,以此达到节能的目的.文献[36]通过分析Spark Streaming框架在执行任务时性能与能耗的权衡,提出一种基于调度工作负载的高效节能策略.该策略通过建立时间序列预测模型对集群任务的处理时间与能耗进行捕捉,并使用DVFS技术来调节集群节点的电压,以此达到降低集群能耗的目的.
文献[19]从集群拓扑任务处理的弹性出发,提出一种针对流式大数据平台的弹性能耗感知节能策略(keep calm and react with foresight:strategies for low-latency and energy-efficient elastic data stream processing, LEEDSP),该策略通过建立能耗感知模型,对集群的任务处理进行弹性调节,以实现提高集群吞吐量并节约能耗的目的.但是该节能策略并不是始终有效的,这是由于大数据流式处理平台的任务一旦提交,将持续运行下去,而长时间运行节能策略会导致集群拓扑内的任务处理出现不平衡,从而严重影响集群拓扑任务的正常执行.
文献[37]针对Storm框架在进行数据处理时存在高能耗的问题,提出数据迁移合并节能策略(energy-efficient strategy for data migration and merging in Storm, DMM-Storm),该策略通过设计资源约束模型与最优线程数据重组原则,对集群内的资源进行迁移,并使用DVFS技术对迁移资源后工作节点的CPU进行电压缩放管理,有效降低了集群的能耗与节点间的通信开销.但是仍存在2点有待优化:其一为该节能策略对集群拓扑处理任务的实时性造成一定影响;其二为使用DVFS技术调节集群节点CPU的电压存在较大的偶然性,且技术的实现难度较高不适合部署于大规模集群当中.
与上述研究成果相比,本文的不同之处在于:
1) 文献[19,23-36]均未考虑任务迁移后,对集群工作节点的资源占用(CPU、内存与网络带宽等)是否造成影响,而文献[7]忽视了除CPU之外,其他电子元件对集群工作节点资源占用的影响.本文通过建立资源约束模型,避免了集群在进行任务处理时对节点资源占用造成的影响.
2) 文献[37]存在影响集群性能的问题,且节点CPU电压的调节存在偶然性.本文通过减少集群拓扑任务处理的延迟,在提高集群性能的同时节约了集群的能耗.此外,并未对节点CPU的电压进行调节,避免了因动态调节CPU电压而对集群拓扑正常执行任务造成影响.
3) 实验选取Intel公司Zhang[16]发布在GitHub上的4组Benchmark进行测试,而非自己定义的拓扑,因此更具有公认性.此外,本文与LEEDSP[19],DMM-Storm[37]进行实验对比,验证了节能策略的效果.
2 问题建模与分析
为了量化集群拓扑执行任务的能耗,本节首先建立Storm的任务分配模型、拓扑信息监控模型以及数据恢复模型,并在此基础上建立能耗模型.其中Storm的任务分配模型描述了拓扑中工作节点与各个任务之间的对应关系,为后续判断集群拓扑的任务执行奠定了基础;拓扑信息监控模型通过定义集群工作节点的资源约束设置滑动时间窗口,并计算集群吞吐量,确定集群拓扑任务的执行情况,以此判断是否终止拓扑内的任务;数据恢复模型将集群内的数据备份到内存,根据信息监控模型的反馈信息,确定是否进行数据恢复,并根据数据存储限制对节点内备份的数据进行实时删除;能耗模型通过任务的执行时间与功率计算集群能耗,为节能策略的实现提供了理论依据.

Fig. 1 Data allocation in the topology图1 拓扑内的数据分配
2.1 Storm的任务分配模型
在Storm框架中,1个流式作业由1个称为拓扑(topology)的有向无环图构成,其中由数据源编程单元Spout和数据处理编程单元Bolt这2类组件(component)共同构成了有向无环图的顶点,各组件之间通过不同的流组模式发送和接收数据流,构成了有向无环图的边.为了提高集群拓扑的执行效率,需要满足每个组件在同一时刻创建多个实例,称之为任务(task).1个任务运行于1个工作线程(executor)内,是各组件最终执行的代码单元.拓扑提交到集群后,任务将分布到各个工作节点中,并开始进行任务的处理和任务间数据流的传输工作.令Storm集群工作节点的集合为N={n1,n2,…,n|N|},且工作节点内存在组件的集合为C={c1,c2,…,c|C|},由于每个组件都可同时创建多个实例,则组件ci创建的第j个实例作为任务tij(若组件ci创建的实例数为1,则将该任务简化为任务ti),由此存在T(N)={ti1,ti2,…,tin}表示工作节点分配到拓扑的任务集合.图1为集群拓扑内的任务分配情况,共由3个工作节点、12个实例与19条有向边组成.其中节点集合为N={n1,n2,n3},各工作节点内的任务集合为Tn1={ta,td1,tf1,th1},Tn2={tb,td2,tf2,th2},Tn3={tc,te,tg,ti}.
2.2 拓扑信息监控模型
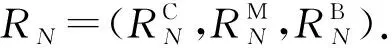
(1)
(2)
(3)
此外,集群拓扑在执行任务时可能会出现节点丢失(报错)的问题,则集群拓扑就会舍弃该节点(不再向该节点分配任务),此时集群内工作节点的资源占用率会迅速升高,从而接近工作节点资源占用的极限(该现象被称为工作节点的资源瓶颈),进而影响任务的顺利执行,并提高工作节点执行任务的功率.为解决这一问题,需要设置滑动时间窗口计算集群吞吐量,从而实时反馈拓扑执行任务的信息,对任务的执行情况进行判断.滑动时间窗口的设置可用定义2表示:
定义2.滑动时间窗口.滑动时间窗口的取值可通过定义时间窗口的初始值对额外增加的网络资源占用率与系统延迟的影响确定.令滑动时间窗口的初始值为wori,额外增加的网络资源占用率为oext,系统计算延迟为tdel,则滑动时间窗口的初始值对额外增加的网络资源占用率与系统计算延迟的影响为

(4)
其中,a表示其他因素如拓扑任务处理带来的影响,为常数.为选择对额外增加的网络资源占用率与系统延迟影响最小的时间窗口取值,则可通过式(5)获得其相应窗口
Ii=min(I1,I2,…,In).
(5)
通过式(5)可知,当时间窗口为Ii时,其取值对额外增加的网络资源占用率与系统延迟的影响最小,此时对应的时间窗口取值为wi.本文滑动时间窗口的取值通过4.1节进行测试.此外在实际应用中,可将不同数值带入式(4)(5),通过多次训练,确定合适的时间窗口取值.
为保障拓扑执行任务时Storm集群的性能不受影响,需要对拓扑内的每个tuple进行标记,使其在单位时间内以心跳信息形式进行信息反馈,并通过计算集群吞吐量判断拓扑任务的执行情况,从而确定是否结束拓扑内的任务.图2为时间窗口的设置与集群吞吐量的计算示意图,令滑动时间窗口的长度为w(单位为s),数据的标记信息为Mlab,发送信息的节点为NWorkNode,接收信息的节点为NNimbus,则滑动时间窗口的信息反馈为
(6)

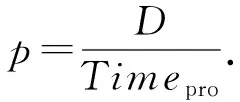
(7)
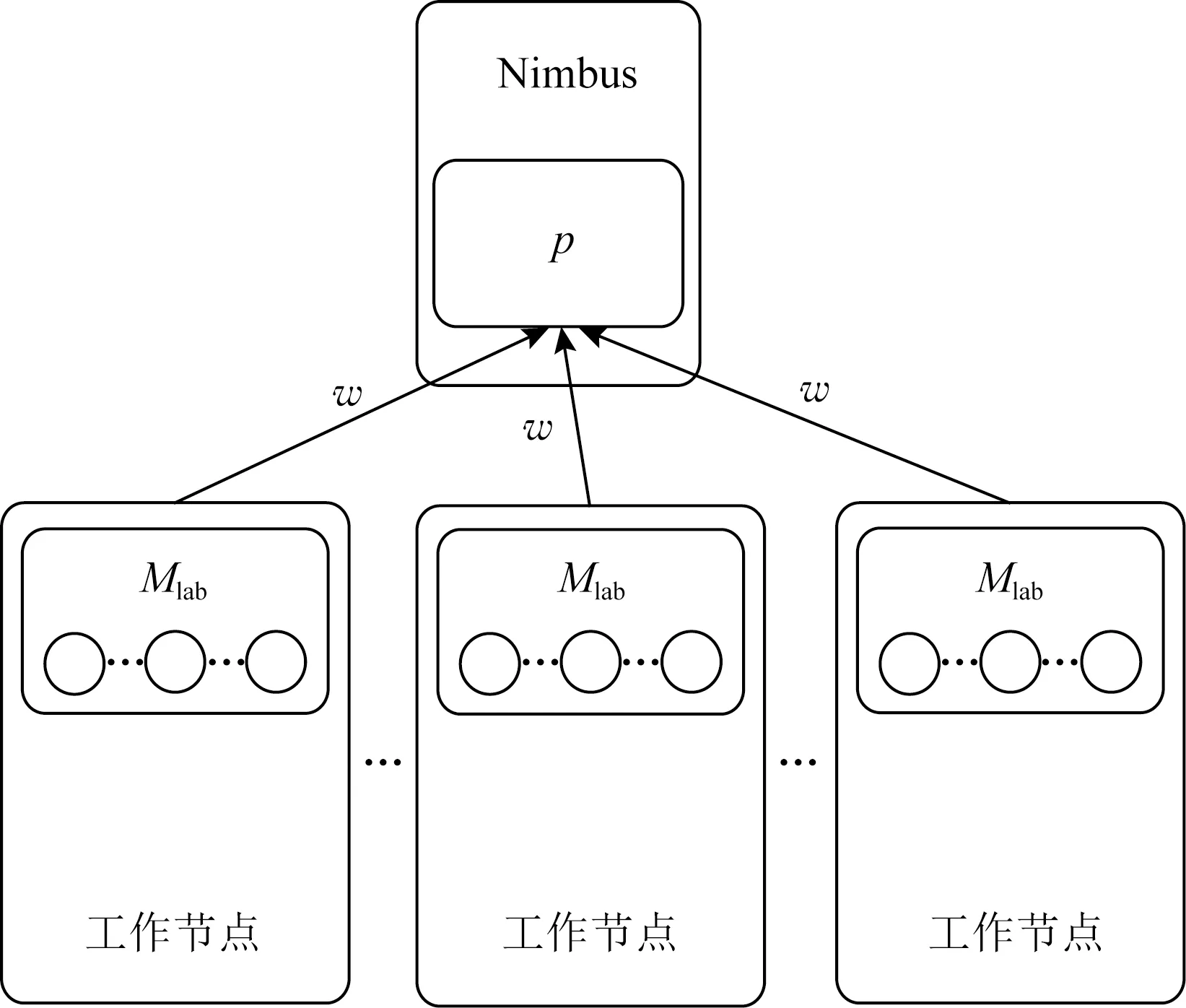
Fig. 2 Time window setting and cluster throughput computing图2 时间窗口的设置与集群吞吐量的计算
此外,检测集群吞吐量存在2个限制条件:1)因节点丢失等问题而出现资源瓶颈,导致集群吞吐量低于原集群吞吐量的最低值;2)因网络等问题而出现拓扑报错,集群吞吐量为零.因此为检测集群吞吐量是否受限制条件的影响,需要设置集群吞吐量的下限,令集群吞吐量存在1个阈值下限为pval,为保障集群拓扑内的任务顺利执行,则:

(8)
因此,根据式(8)对集群拓扑执行任务进行判断,确定是否终止集群拓扑内的任务.
2.3 数据恢复模型
Storm集群在进行数据的传输与处理时,数据通过磁盘发送至集群拓扑.根据2.2节可知,当集群出现资源瓶颈或拓扑报错时,终止集群任务,但由于从磁盘内读取数据,整个集群的计算延迟与能耗开销相对较大,因此建立数据恢复模型,使集群通过内存读取数据,以此减少不必要的计算延迟与能耗开销.
定义3.内存数据存储.为减少由于数据从磁盘读取而产生不必要的计算延迟与能耗开销,现选择内存资源占用率最小的节点作为备份节点,用于数据的存储,具体的计算为
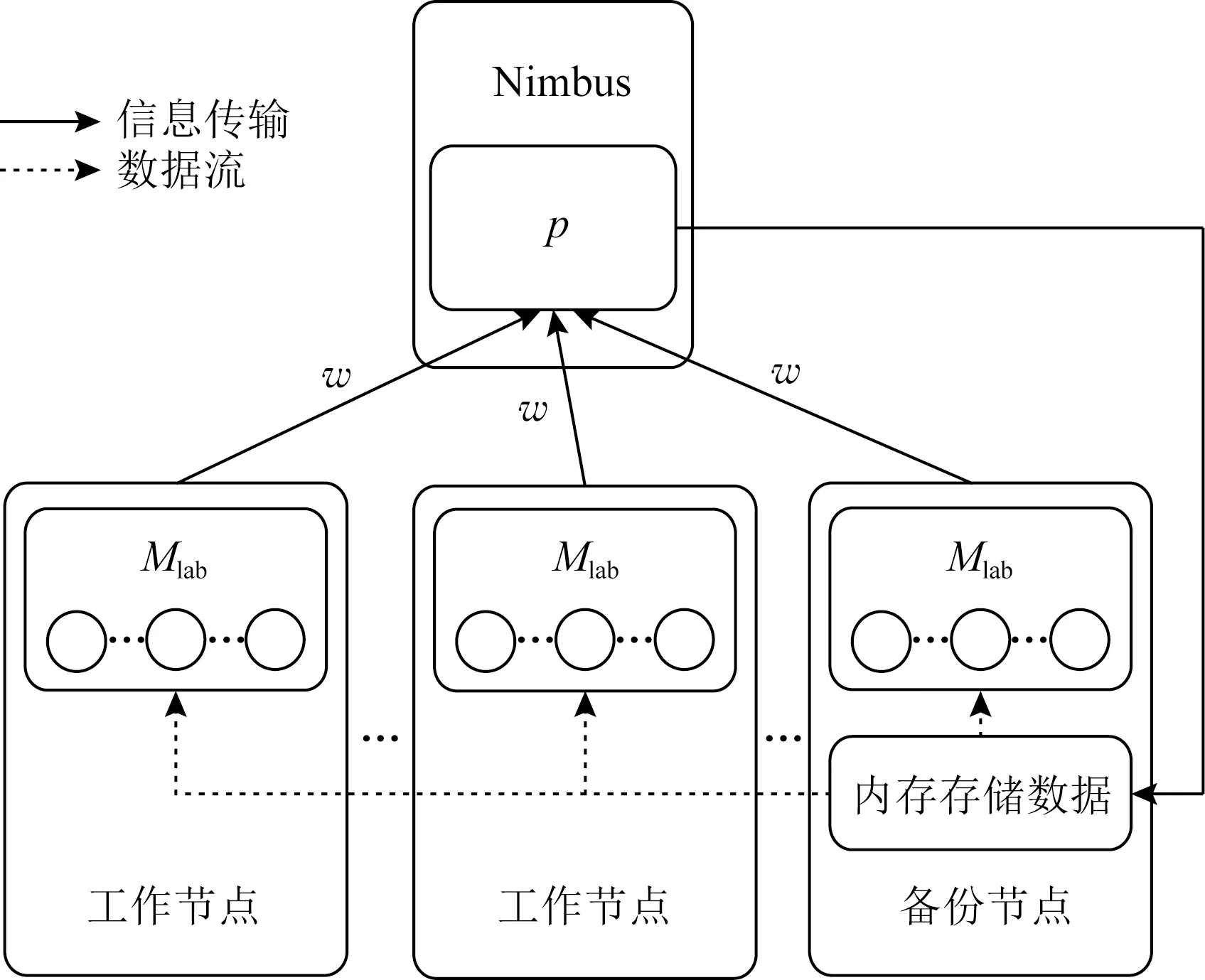
Fig. 3 Data monitoring and recovery in the topology图3 拓扑内数据监控与恢复
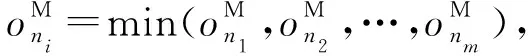
(9)
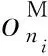
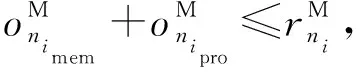
(10)
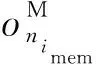
此外,将磁盘内的数据存储至备份节点内存,会增加额外的节点间通信开销,但由于出现资源瓶颈或拓扑报错等问题而终止集群任务后,数据从备份节点内存读取相比于从磁盘读取降低了延迟,因此这部分额外增加的节点间通信开销对集群拓扑任务处理的影响可忽略不计.
为计算集群数据恢复的时间,令拓扑从内存读取数据的时间为Timeram,滑动时间窗口信息反馈的时间为Timewin,终止集群任务的时间为Timeter,则拓扑从内存恢复数据的时间Timeres为
Timeres=Timewin+Timeter+Timeram.
(11)
此外,由于滑动时间窗口信息反馈的时间与终止集群任务的时间非常短,可忽略不计,则化简式(11)可得:
Timeres=Timeram.
(12)
为计算集群数据传输与处理的总时间,令拓扑从磁盘读取数据的时间为Timedisk,由于集群拓扑数据传输与处理的时间为Timepro,则集群数据传输与处理的总时间Timetot为
Timetot=Timedisk+Timepro.
(13)
此外,若原集群拓扑在执行任务时因网络等问题而出现拓扑报错的问题,令报错前数据传输与处理的时间为Timebef,报错后数据传输与处理的时间为Timeaft,由于拓扑报错之后,集群拓扑内的数据需要重新读取,因此,数据传输与处理的时间与原集群拓扑任务处理的时间相等,即
Timeaft=Timepro.
(14)
由于拓扑报错后,原集群拓扑从磁盘读取数据,即

(15)

(16)
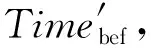

(17)
则当出现资源瓶颈时,集群数据传输与处理的总时间为
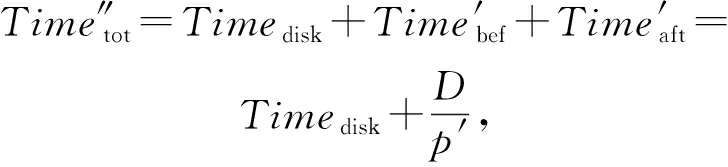
(18)
其中,p′表示原集群拓扑在执行任务出现资源瓶颈时集群的平均吞吐量.
若原集群拓扑在执行任务出现拓扑报错或资源瓶颈时,集群使用数据恢复模型,则同理可得集群数据传输与处理的总时间Time‴tot为

(19)
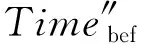
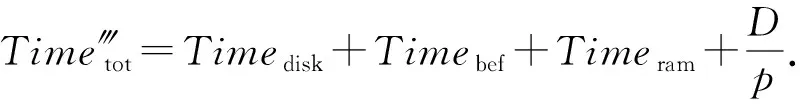
(20)
则集群使用数据恢复模型后,减少的计算延迟Timesave为

(21)
其中,式(21)内的参数与式(16)(18)(20)相同.
2.4 能耗模型
针对流式处理集群建立能耗模型首先需要注意是否影响集群的性能,而降低集群能耗一般从2个角度出发:1)提高集群拓扑任务处理的速度,减少任务处理的时间;2)降低集群拓扑任务处理的功率.因此需要引入经典的能耗模型,即
Energy=Power×Time,
(22)
其中,Energy表示集群拓扑任务处理的能耗,Power表示集群拓扑任务处理的功率,Time表示集群拓扑执行任务的总时间.现将式(13)代入式(22),化简可得:
Energy=Power×(Timedisk+Timepro).
(23)
若集群拓扑在任务处理的过程中出现拓扑报错,则系统的能耗为

(24)
其中,Energy1表示出现拓扑报错后集群的能耗,Power1表示出现拓扑报错后集群的平均功率.若集群拓扑在任务处理的过程中出现资源瓶颈,则系统的能耗为

(25)
其中,Energy2表示出现资源瓶颈后集群的能耗,Power2表示出现资源瓶颈后集群的平均功率.若原集群拓扑在执行任务出现拓扑报错或资源瓶颈时,使用数据恢复模型,则系统的能耗为
Energy3=
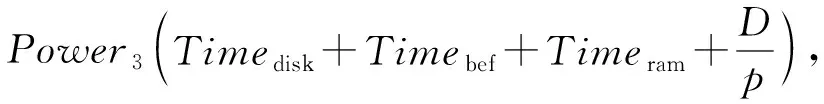
(26)
其中,Energy3表示使用数据恢复模型后集群的能耗,Power3表示使用数据恢复模型后集群的平均功率.则集群使用数据恢复模型后,节约的能耗Energysave为

(27)
其中,式(27)内的参数与式(24)~(26)相同.
3 节能策略分析
在理论模型的基础上,提出基于Storm平台的数据恢复节能策略,该策略包括吞吐量检测算法与数据恢复算法,通过在原集群拓扑执行任务出现拓扑报错或资源瓶颈时,终止拓扑内的任务并通过备份节点内存读取数据,以此降低了系统计算延迟与能耗开销.该策略主要分为4个步骤:
1) 选择内存资源占用率最低的工作节点作为备份节点,并对备份节点的内存进行逻辑分割以用于数据存储.
2) 根据拓扑信息监控模型判断集群拓扑是否出现资源瓶颈或拓扑报错.
3) 根据数据恢复模型从备份节点的内存向集群拓扑读取数据.
4) 根据节能策略计算集群的延迟与能耗开销.
具体流程图如图4所示:

Fig. 4 Flowchart of energy-efficient strategy图4 节能策略流程图
3.1 吞吐量检测算法
为监控集群拓扑在执行任务时是否会出现资源瓶颈或拓扑报错的问题,需要设计吞吐量检测算法.其中该算法需要对集群拓扑内的元组进行标记,并根据计算集群吞吐量判断拓扑内的任务执行情况.该算法保证集群的实际吞吐量低于阈值下限时,终止拓扑内的任务.由于需要对整个集群拓扑内的数据信息进行遍历,因此需要确定工作节点与各个任务之间的对应关系.具体情况在算法1中描述.
算法1.吞吐量检测算法.
输入:集群拓扑的任务集合T(N)={ti1,ti2,…,tin}、时间窗口长度w、数据的标记信息Mlab、集群实际吞吐量p、集群吞吐量的阈值下限pval;
输出:判断是否终止集群拓扑内的任务.
① newMlab(labletuple);*对集群内的元组信息进行标记*
②WindowLength=w;*滑动时间窗口的长度为w*
③ fortid=ti1toT(N).tindo
④NWordNode=NNimbus;*工作节点将数据信息汇总至主控节点*
⑤ 心跳信息转化为集群吞吐量;
⑥ 根据式(7)计算集群吞吐量;
⑦ switchpval=pthen
⑧ case1:
⑨pval-p=pval;*出现拓扑报错*
⑩ 终止集群拓扑内的任务;
算法1的输入参数为集群拓扑的任务集合、时间窗口长度、数据的标记信息、集群实际吞吐量以及集群吞吐量的阈值下限;输出参数为判断是否终止集群拓扑内的任务.行①②表示对集群拓扑内的元组进行标记,并设置滑动时间窗口的长度;行③④表示遍历整个集群拓扑内的任务信息,并以心跳信息的形式返回Nimbus节点;行⑤⑥表示心跳信息转换为集群吞吐量,并根据式(7)计算集群的实际吞吐量,以判断拓扑内的任务实际运行情况;行⑦~表示集群实际吞吐量与阈值下限进行对比,共存在3种情况,当出现拓扑报错与资源瓶颈时,终止集群拓扑内的任务,当集群实际吞吐量高于或等于阈值下限时,集群拓扑内的任务正常执行.
由算法1可知,DR-Storm首先需要确定集群是否出现资源瓶颈与拓扑报错,由此判断是否终止集群拓扑内的任务.为满足监控集群拓扑内的数据信息,需要对其元组进行标记,并设置滑动时间窗口,其中滑动时间窗口的取值通过式(4)(5)选择确定.按照心跳信息的形式对主控节点进行反馈,根据反馈结果计算集群实际吞吐量,并与集群吞吐量的阈值下限进行对比,以此判断集群任务处理的状态.
基于Storm的节能策略首先需要判断是否影响集群的性能,而Storm集群默认的轮询调度策略,其时间复杂度为O(n).算法1首先对集群拓扑的元组进行标记并设置滑动时间窗口的长度,其时间复杂度为O(1);其次算法1需要对整个集群拓扑内的数据信息进行遍历,并以心跳信息的形式返回Nimbus节点,类似于轮询调度算法,因此其时间复杂度为O(n);最后算法1通过计算集群实际吞吐量,并与阈值下限进行对比,确定拓扑内的任务实际运行情况,从而判断是否终止集群拓扑内的任务,其时间复杂度为3O(1).则算法1的时间复杂度T(A)为
T(A)=O(1)+O(n)×3O(1)=O(n).
(28)
3.2 数据恢复算法
为满足算法1终止任务后恢复集群拓扑内的数据,提出数据恢复算法.该算法主要由3部分组成:1)根据工作节点的内存资源占用率选择备份节点,并对备份节点的内存进行逻辑划分;2)备份节点存储数据后要满足节点资源约束;3)集群拓扑内的数据处理完成后,实时删除备份节点内存储的数据.具体情况在算法2中描述.
算法2.数据恢复算法.
输出:集群拓扑内的任务顺利执行.

② 根据式(9)确定集群备份节点;
③ end for
⑤ 磁盘向备份节点的内存发送数据;
⑥ 备份节点的内存资源占用满足式(10);
⑦ if集群出现拓扑报错then
⑧ 集群拓扑从备份节点内存读取数据;
⑨ end if
⑩ if集群出现资源瓶颈then
算法2的输入参数为节点的内存资源占用率集合;输出参数为集群拓扑内的任务顺利执行.行①~③表示通过遍历集群节点内存资源占用选择备份节点;行④~⑥表示逻辑分割备份节点的内存,使磁盘向备份节点的内存发送数据时满足式(10);行⑦~表示集群出现拓扑报错或资源瓶颈时,拓扑从备份节点内存读取数据;行表示集群完成数据恢复后,根据算法1重新判断是否出现拓扑报错或资源瓶颈;行表示实时删除备份节点内存储的数据,防止因集群备份节点内存空间不足而造成资源瓶颈的问题.
由算法2可以看出,数据恢复算法根据算法1执行情况判断是否对拓扑内的数据进行恢复.数据恢复算法首先根据集群内节点的内存资源约束,确定备份节点用于数据存储.其次若反馈信息显示集群拓扑出现资源溢出或拓扑报错,则通过备份节点内存向集群拓扑读取数据,并将其元组重新返回算法1进行标记.数据恢复算法保证了可以快速恢复集群拓扑内的数据,进而减少集群的计算延迟.
为确定数据恢复算法对集群性能带来的影响,现计算数据恢复算法的时间复杂度.1)算法2通过遍历节点内存资源占用率确定备份节点,其时间复杂度为O(n);2)算法2确定备份节点的内存满足资源约束,其时间复杂度为O(1);3)判断集群是否出现拓扑报错,从而进行数据恢复,其时间复杂度为O(1);4)判断集群是否出现资源瓶颈,从而进行数据恢复,其时间复杂度为O(1);此外集群完成数据恢复后,重新将任务返回算法1,其时间复杂度为O(1);最后算法2实时删除备份节点内存储的数据,其时间复杂度为O(1).则算法2的时间复杂度T(B)为
T(B)=O(n)+5O(1)=O(n).
(29)
此外,DR-Storm由算法1与算法2组成,则该策略的时间复杂度T(C)为
T(C)=O(n)+O(n)=O(n).
(30)
3.3 算法的部署与实现
在Storm的基本架构中,1个完整的流式作业通常由主控节点(运行Nimbus进程)、工作节点(运行Supervisor进程)与关联节点(运行Zookeeper进程)协同完成计算.其中Nimbus进程为Storm框架的核心,负责接受用户提交的拓扑并向工作节点分配任务;Supervisor进程负责监听Nimbus进程分配的任务并启动工作进程及工作线程;Zookeeper进程负责其他节点的分布式协调工作,并存储整个集群的状态信息与配置信息.为了部署与实现基于Storm平台的数据恢复节能策略,本研究在Storm原有架构基础上新增了4个模块,如图5所示.各模块功能介绍如下:
1) 负载监控器(load monitor).负责监控集群拓扑信息、工作节点的各类资源占用信息.具体实现需添加在拓扑组件各Spout的open()和nextTuple()方法以及各Bolt的prepare()和execute()方法中.
2) 数据库(database).负责收集负载监控器发送的信息与拓扑任务分配信息,并实时更新.
3) 滑动时间窗口模块(slide time window module).部署算法1,通过标记集群拓扑元组,并读取数据库的信息,设置滑动时间窗口的长度,执行吞吐量检测算法.
4) 数据恢复模块(data recovery module).部署算法2,通过算法1返回心跳信息的结果,执行数据恢复算法.
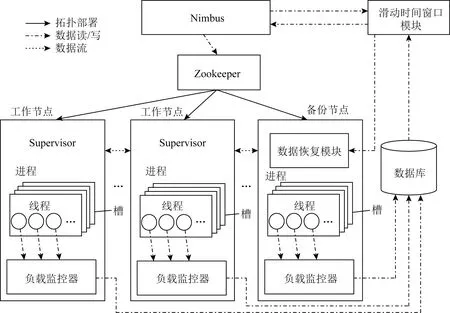
Fig. 5 Improved architecture of Storm图5 改进后的Storm框架
此外,代码编译完成后,通过打jar包分组至主控节点Nimbus的STORM_HOMElib目录下,并在confstorm.yaml中配置好相关参数后运行.
本文提出算法1与算法2设计并实现了基于Storm平台的数据恢复节能策略,减少了集群的计算延迟,并节约了能耗.
4 实验结果及数据分析
为了验证DR-Storm的计算延迟与能耗,本文通过设置对比实验,分别将DR-Storm与原集群及其相关研究成果进行对比.实验选择4组代表不同作业类型的标准Benchmark进行测试,最后对实验结果进行讨论与分析.
4.1 实验环境
实验搭建的集群由19台同构的PC机组成.其中Storm集群包含1个主控节点(运行Nimbus进程、UI进程与数据库)、16个工作节点(运行Supervisor进程)以及3个关联节点(运行Zookeeper进程).此外,集群每台PC机的网卡配置为100 Mbps LAN;内存为8 GB;硬盘容量为250 GB,转速为7 200 rmin,接口为SATA3.0.除硬件配置外,各节点软件配置相同,具体结果如表1与表2所示:

Table 1 Hardware Configuration of Storm Cluster表1 Storm集群的硬件参数配置

Table 2 Software Configuration of Storm Cluster表2 Storm集群的软件参数配置
此外,为了检验不同基准测试下节能策略的效果,实验选取Intel公司Zhang[16]发布在GitHub上的4组Benchmark进行测试,分别为CPU敏感型(CPU-sensitive)的WordCount、网络带宽敏感型(network-sensitive)的Sol、内存敏感型(memory-sensitive)的RollingSort以及Storm在真实场景下的应用RollingCount.表3为4组基准测试各项参数的基本配置,部分参数需要进一步说明如下:component.xxx_num为集群内组件的并行度;Sol中的topology.level为集群拓扑的层次,由于1个Spout对应2个Bolt,因此集群拓扑的层次设置为3;topology.works统一设置为16,表示集群内1个工作节点内仅分配1个工作进程;topology.acker.executors统一设置为16,表示满足集群数据流的可靠传输;最后统一设置每个message.size等于1个tuple的大小.
为对比DR-Storm的效果,本文还与LEEDSP[19],DMM-Storm[37]进行了对比实验.其中LEEDSP的核心思想是弹性调节集群节点的资源,并通过DVFS技术动态调节节点CPU的电压,以此达到节能的效果,且该策略为流式处理节能策略的主要代表,适用于大多数流式处理平台(如Storm,Spark Streaming[11],Flink[12]等);DMM-Storm的核心思想为使用DVFS降低被迁移任务后工作节点的电压而达到节能的效果.此外DMM-Storm由关键线程中的数据迁移合并节能算法(energy-efficient algorithm for data migration and merging among critical executor, EDMMCE)与非关键线程中的数据迁移合并节能算法(energy-efficient algorithm for data migration and merging among non-critical executor, EDMMNE)组成.为保证在同等条件下验证本文策略的有效性,LEEDSP,DMM-Storm的相关参数与DR-Storm保持一致.
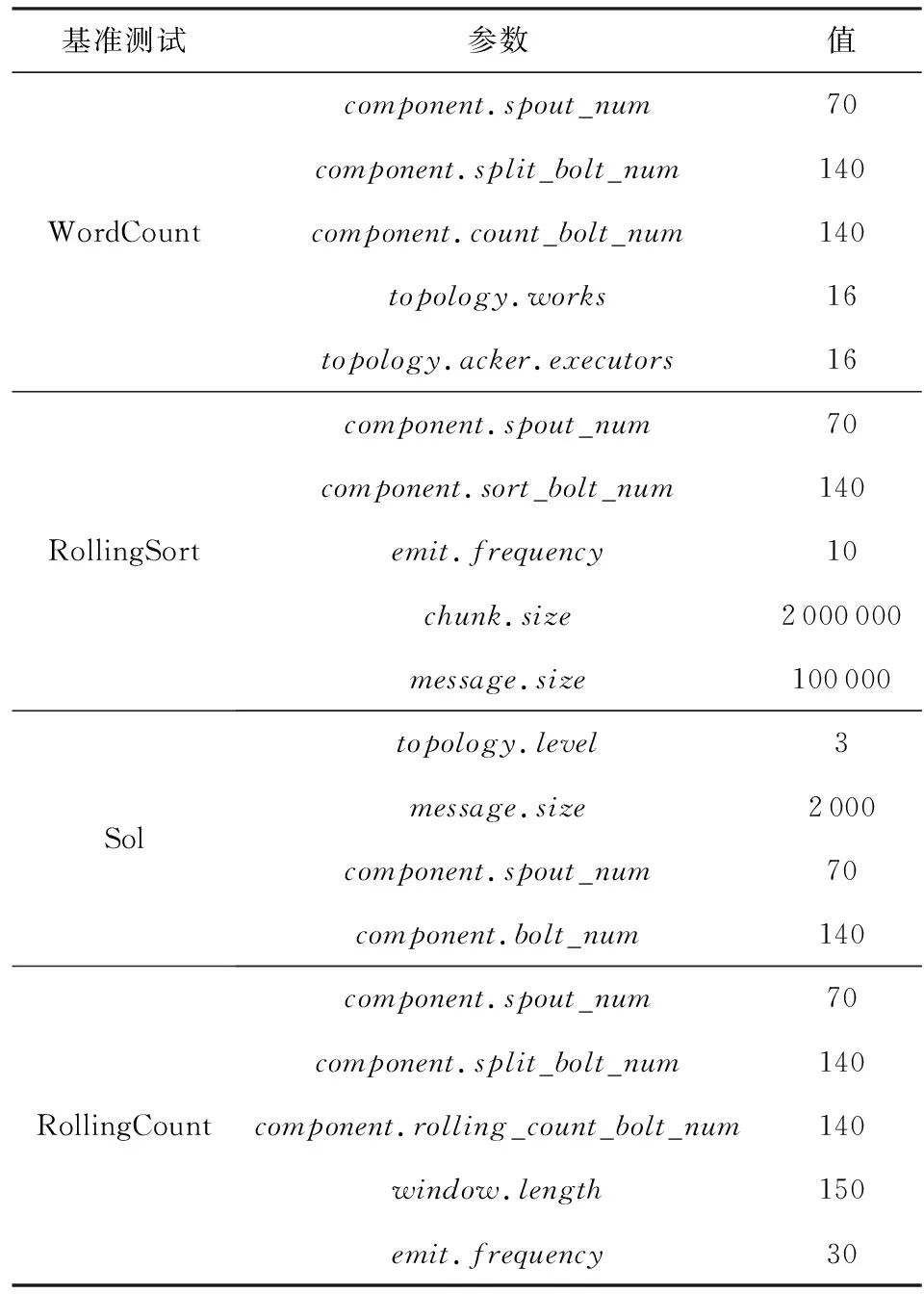
Table 3 Configuration of Benchmarks表3 基准测试参数配置
为选择合适的时间窗口用于检测集群拓扑内数据的信息,本文以WordCount为例在集群默认调度策略下,根据增加的网络资源占用率与系统延迟对集群性能的影响选择合适的时间窗口长度,具体的结果如表4所示:

Table 4 Choose of Time Windows表4 时间窗口的选择
其中I的取值根据式(4)(5)确定.根据表4可知,当时间窗口长度为10 s,20 s时,集群增加的网络资源占用率较大,且I值较高.其原因为时间窗口取值较低而导致集群内数据库的读写过于频繁,读写数据库产生的网络资源占用率相对较大,从而对集群拓扑内的任务处理性能造成影响.当时间窗口长度为40 s,50 s时,集群内增加的系统延迟与I值较高,已影响到集群拓扑内的任务正常执行.其原因为集群内数据库的读写过于缓慢,影响拓扑内数据信息的获取时间,进而延误了DR-Storm的触发时间,造成影响集群性能的问题.综上所述,时间窗口的取值设置为30 s,在该时间窗口长度下能够较好满足实验的执行.同理可得Sol,RollingSort,Rolling-Count的时间窗口长度.
此外,为便于数据统计,以下测试均设置metrics.poll=5 000,metrics.time=300 000,其单位为ms,即每组实验每5 s进行1次采样,时长为5 min.
4.2 工作节点的资源约束测试
为执行DR-Storm首先需要查找集群内的备份节点用于数据的存储,而备份节点则需要根据集群内工作节点的内存资源占用情况确定.此外,为满足集群内的任务顺利执行,需要确定原集群内各节点的资源占用情况.具体结果如图6所示.

Fig. 6 Resources utilization of 16 work nodes in the original cluster图6 原集群16个工作节点的资源占用率
图6为集群运行4组基准测试后,16个节点的平均资源占用情况.由图6可知,运行4组基准测试,集群内工作节点的资源占用率主要集中于40%~70%,满足集群拓扑内的任务正常执行.由式(9)与图6(c)可知,不同的基准测试由于其拓扑不同,节点平均内存资源占用率的最低值也不相同.其中原集群在WordCount下,9号节点的平均内存资源占用率最低为42.8%;原集群在Sol下,7号节点的平均内存资源占用率最低为42.3%;原集群在Rolling-Sort下,12号节点的平均内存资源占用率最低为44.3%;原集群在RollingCount下,15号节点的平均内存资源占用率最低为45.7%.则根据不同的基准测试,选择平均内存资源占用率最低的节点为备份节点.为确定备份节点的内存进行数据存储后,备份节点是否满足资源约束,具体结果在图7显示.
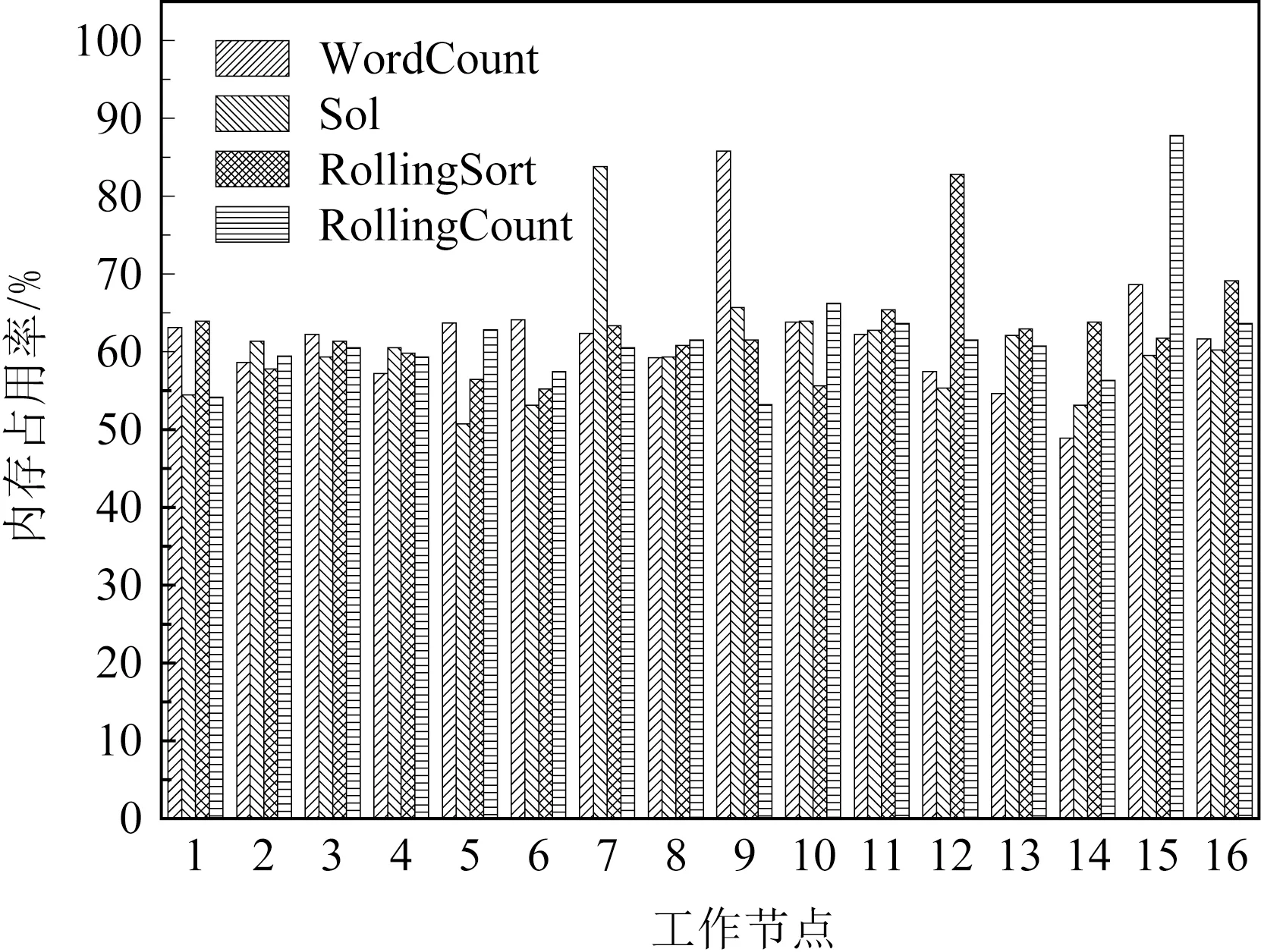
Fig. 7 Memory resources utilization after the backupnode store data图7 备份节点存储数据后的内存资源占用率
图7为集群内备份节点存储数据后节点的平均内存资源占用率.根据图7可知,集群内4个备份节点的平均内存资源占用率远高于原集群的相同节点,其内存资源占用率主要集中于80%~90%.其原因为备份节点的部分内存用于数据存储,由于集群拓扑未发生改变,则集群节点数据的处理未发生改变,因此备份节点的内存资源占用率等于原节点用于数据处理的内存资源占用率与备份节点用于数据存储的内存资源占用率之和,满足式(10).
为检测执行DR-Storm对集群性能造成的影响,需要测试集群的平均吞吐量.现计算原集群出现资源瓶颈、拓扑报错与执行DR-Storm时对集群平均吞吐量的影响,具体结果如图8所示.

Fig. 8 Comparison of throughput under different benchmarks图8 在不同的基准测试下比较吞吐量
图8为集群执行3组(WordCount,Sol,Rolling-Sort)基准测试后,策略对集群平均吞吐量的影响.由图8可知,在95 s前集群的吞吐量基本相同,这是由于集群在出现资源瓶颈或拓扑报错前,未触发DR-Storm,拓扑任务始终执行默认处理机制.
在95 s左右,由于出现节点计算资源不足或网络故障等原因,而造成资源瓶颈或拓扑报错的问题,其原因为节点间的数据传输量较大,容易导致集群内网络传输出现拥挤现象,造成节点间计算资源不足或网络故障的问题.由于在95 s左右发生网络拥挤现象,故通过执行DR-Storm,重启集群拓扑缓解网络传输压力,解决网络拥塞的问题.
集群执行DR-Storm的平均吞吐量为68 927 tuples,70 913 tuples,51 855 tuples,相比于原集群拓扑报错,执行DR-Storm时集群的平均吞吐量略高于原集群拓扑报错.这是由于原集群出现拓扑报错,集群拓扑从磁盘读取数据,而执行DR-Storm,集群拓扑从内存读取数据,数据恢复过程中的时间间隔较短,故对集群吞吐量的影响较小.相比于原集群资源瓶颈,执行DR-Storm时集群的平均吞吐量远高于原集群资源瓶颈,这是由于原集群出现资源瓶颈时,节点的各类资源占用率不断升高,集群拓扑的任务处理出现拥挤,集群默认策略的时间复杂度不断上升,集群拓扑任务执行效率不断下降,集群的吞吐量降低,而执行DR-Storm时,集群拓扑在经历短暂重启后迅速恢复了其吞吐量.因此原集群资源瓶颈时,执行DR-Storm的吞吐量远高于原集群.此外,集群执行DR-Storm在95 s~115 s之间的集群吞吐量从0逐步上升,其原因为这段时间内终止了集群拓扑内的任务,并从备份节点内存重新读取任务,但是由于从内存读取数据时间间隔相对较短,因此对集群整体性能的影响较小.
4.3 节能策略的实验结果与分析
针对DR-Storm的效果可通过系统延迟与能耗2个标准进行评估.
1) 系统延迟
系统延迟是评估策略是否影响集群性能的重要指标之一,本文根据式(16)(18)(20)对单位时间内集群拓扑任务处理的延迟进行计算,具体结果如图9所示.此外还可通过Storm框架自身提供的Storm UI[8]进行统计.
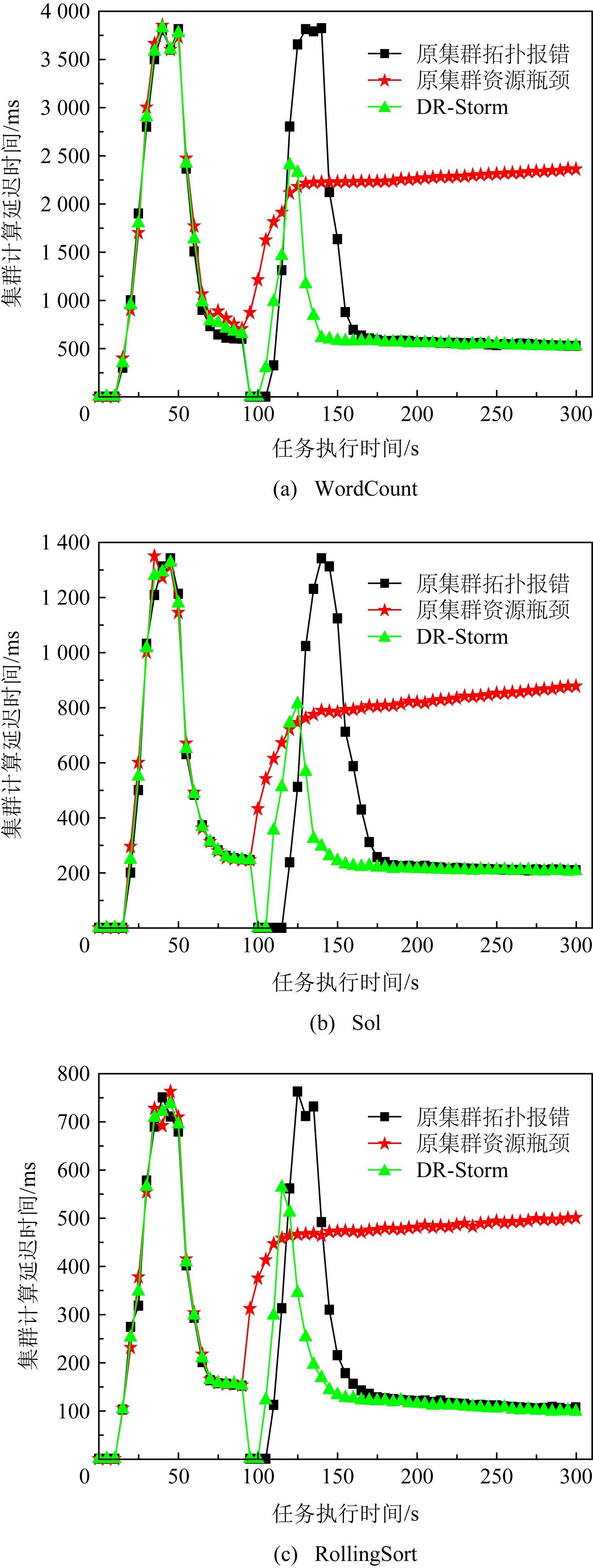
Fig. 9 Comparison of system latency under different benchmarks图9 在不同的基准测试下比较系统的延迟
图9为在各基准测试(WordCount,Sol,Rolling-Sort)下,单位时间内集群拓扑任务处理的延迟.由图9可知,95 s前DR-Storm与原集群拓扑任务处理的延迟基本相同,这是由于集群拓扑在这段时间内进行任务部署,且集群并未触发资源瓶颈与拓扑报错.95s后触发资源瓶颈与拓扑报错,集群执行DR-Storm的平均延迟为660.2 ms,256.2 ms,143.9 ms,相比于原集群出现资源瓶颈其延迟降低了69.7%,67.9%,69.6%.这是由于原集群出现资源瓶颈各节点的计算资源不足,致使拓扑内的任务处理速度受到影响,故集群计算资源越来越接近溢出导致系统延迟不断上升,集群于95 s~125 s内,共耗时约30 s,执行DR-Storm,使集群延迟在140 s后逐步趋于稳定,最终导致执行DR-Storm的计算延迟远低于原集群.此外,集群执行DR-Storm存在1个峰值,这是由于执行策略在95 s左右终止了集群拓扑内的任务,并通过备份节点的内存对拓扑内的任务进行重新部署,但由于时间间隔较短,因此对整个集群拓扑内的任务处理影响较小.相比于原集群出现拓扑报错其延迟降低了31.4%,27.5%,22.3%,其原因为虽然原集群出现拓扑报错延迟趋于稳定后与执行DR-Storm基本相同,但由于原集群在终止任务后从磁盘对拓扑内的任务进行部署,时间间隔为95 s~155 s,共耗时约60 s,且存在峰值为3 821 ms,1 342 ms,763 ms,严重影响了集群拓扑任务的正常处理,因此DR-Storm的效果优于原集群.此外3组基准测试的延迟并不相同,这是由于不同基准测试的拓扑并不相同,且节点内的线程数量也不相同,但并不影响集群拓扑任务的执行结果.图10为集群在实际应用场景下拓扑任务处理的延迟.
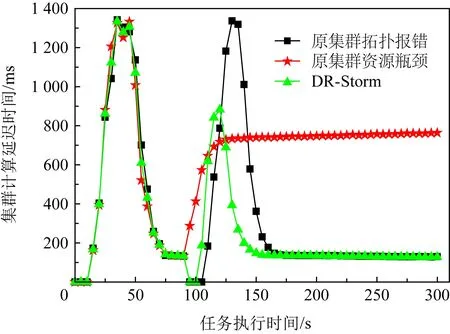
Fig. 10 Comparison of system latency under the RollingCount图10 在RollingCount下比较系统的延迟
如图10所示,集群在RollingCount下执行DR-Storm的平均延迟为497.2 ms,相比于原集群出现资源瓶颈与拓扑报错其延迟降低了72.4%,26.7%,因此与原集群相比,执行DR-Storm具有更好的集群性能.
2) 集群能耗
集群能耗是反映节能策略效果的重要指标之一,本文通过拓扑执行任务的功率与时间相乘计算集群的能耗,并根据式(27)计算执行DR-Storm相比于原集群节约的能耗.此外引入LEEDSP,DMM-Storm与DR-Storm作对比,以验证DR-Storm的实际效果.为计算集群能耗需要统计单位时间内集群执行不同策略的功率,具体结果如图11所示:

Fig. 11 Comparison of power on RollingCount among different strategies图11 RollingCount在不同策略下的功率对比
图11为在RollingCount下集群执行不同策略的功率对比.根据图11可知,集群执行DR-Storm的平均功率为1 073.34 W;原集群出现拓扑报错与资源瓶颈的平均功率分别为1 103.69 W,1 244.01 W;执行LEEDSP拓扑报错与资源瓶颈的平均功率分别为1 070.43 W,1 207.03 W;执行EDMMNE拓扑报错与资源瓶颈的平均功率分别为984.89 W,1 268.70 W;执行EDMMCE拓扑报错与资源瓶颈的平均功率分别为1 004.97 W,1 274.21 W.
根据11(a)可知,执行DR-Storm相比于原集群的功率降低了2.7%,13.7%,且在95 s前原集群与DR-Storm的功率基本相等.这是由于95 s前并未出现拓扑报错与资源瓶颈,DR-Storm尚未触发.95 s后集群功率波动较大,其原因为在95s后集群出现拓扑报错与资源瓶颈,执行DR-Storm拓扑终止任务后,从备份节点内存读取数据.原集群出现拓扑报错终止任务后,从磁盘读取数据,而从内存读取数据消耗的功率小于磁盘内读取数据,故集群功率趋于稳定后执行DR-Storm的功率略低于原集群出现拓扑报错.原集群出现资源瓶颈,节点的资源占用持续上升,导致集群的功率不断升高,因此原集群出现资源瓶颈的功率远高于DR-Storm.
根据11(b)可知,DR-Storm,LEEDSP出现拓扑报错的功率接近,低于LEEDSP出现资源瓶颈的功率,其原因为当集群出现资源瓶颈时,LEEDSP无法进行资源调度,节能策略失效,故与原集群出现资源瓶颈相同,节点的功率迅速上升.此外,虽然LEEDSP出现拓扑报错与DR-Storm的功率接近,但由于LEEDSP进行资源调度,集群功率存在1个峰值,影响集群拓扑任务的正常执行,且LEEDSP由于使用DVFS技术调节节点电压,集群节点的功率波动较大,非常不稳定,不适合部署在大规模的集群当中.
根据11(c)可知,DR-Storm的功率高于DMM-Storm出现拓扑报错,低于DMM-Storm出现资源瓶颈的功率,这是由于当集群节点出现资源瓶颈时,集群节点内的任务无法正常进行迁移,故DMM-Storm失效,集群节点功率急速上升.虽然集群出现拓扑报错时,DMM-Storm的功率低于DR-Storm,但DMM-Storm的功率因任务迁移同样存在峰值,影响集群拓扑任务的正常执行.此外当出现资源瓶颈时,DMM-Storm完全失效,存在一定的缺陷,且DVFS的实现较为困难,因此同样不适合部署在大规模的集群当中.为计算集群的能耗,需要对集群内的功率进行累加求和,具体结果如图12所示:

Fig.12 Comparison of energy consumption on RollingCount among different strategies图12 RollingCount在不同策略下的能耗对比
图12为在RollingCount下集群执行不同策略的能耗对比.根据图12可知,集群在单位时间内执行DR-Storm的能耗为4.50 MJ;原集群拓扑报错与资源瓶颈的能耗为5.07 MJ,9.79 MJ;执行LEEDSP拓扑报错与资源瓶颈的能耗分别为4.62 MJ,9.73 MJ;执行EDMMNE拓扑报错与资源瓶颈的能耗分别为4.03 MJ,10.22 MJ;执行EDMMCE拓扑报错与资源瓶颈的能耗分别为4.18 MJ,10.22 MJ.
图12(a)为集群出现拓扑报错后不同策略的能耗对比,与原集群相比,执行DR-Storm的能耗降低了11.2%,但是在95 s~135 s内,DR-Storm的能耗在所有策略当中最高,这是由于执行数据恢复算法,集群拓扑内的数据从备份节点内存中读取,且拓扑内的数据恢复时间较快,故集群节点的功率未下降至最低值,其他策略通过磁盘恢复集群拓扑内的数据,拓扑内的数据恢复时间较慢,集群内的功率降低至最低值,因此其他策略(包括原集群)在这段时间内的能耗低于DR-Storm.135 s后,执行DR-Storm的能耗趋于稳定,对于集群拓扑任务的整体处理影响较小.LEEDSP,DR-Storm的能耗接近,而DMM-Storm的能耗低于DR-Storm,但是由于LEEDSP,DMM-Storm都是使用DVFS技术进行电压调节,功率的获取存在较大的偶然性且容易对集群拓扑任务的正常执行带来影响(LEEDSP容易带来拓扑任务处理出现失衡的问题,DMM-Storm容易影响集群拓扑任务处理性能的问题),进而影响节能策略的实际效果.
图12(b)为集群出现资源瓶颈后不同策略的能耗对比,与原集群相比,执行DR-Storm的能耗降低了54.1%,这是由于随着集群内节点资源占用的不足,节点的功率持续上升,导致集群的能耗不断增大.LEEDSP,DMM-Storm都是对资源迁移后的节点进行电压缩放管理,但由于节点的资源占用已达到瓶颈,无法进行资源的迁移,故节能策略失效,集群还是按照系统默认机制进行任务的处理,与原集群的能耗基本相等.
此外,根据集群内功率与系统延迟的降低情况可以确定,当集群出现资源瓶颈时,执行DR-Storm的系统延迟每降低72.4%,功率下降13.7%,则集群的能耗节约54.1%;当集群出现拓扑报错时,执行DR-Storm的系统延迟每降低26.7%,功率下降2.7%,则集群的能耗节约11.2%.因此,相比于原集群,本文提出的DR-Storm具有更好的节能效果.
5 总结与展望
高能耗问题已经成为制约绿色流式计算平台发展的主要障碍之一,Storm作为最受企业界与学术界追捧的大数据流式计算平台之一,在最初设计时并未考虑高能耗的问题,以至于影响平台其他领域的发展.针对这一问题,本文通过研究Storm的框架结构与拓扑逻辑,建立了任务分配模型、拓扑信息监控模型、数据恢复模型以及能耗模型,并进一步提出了基于Storm平台的数据恢复节能策略,该策略由吞吐量检测算法与数据恢复算法组成,在减少系统计算延迟的前提下,降低了集群的功率,并节约了能耗.最后,实验通过4组基准测试从资源占用、吞吐量、系统延迟与能耗的角度验证了策略的效果.
下一步的研究工作主要包括3个方面:
1) 将DR-Storm部署到更为复杂的商业环境,使其具有更为广阔的应用场景.
2) 与其他节能策略融合使用,达到双重的节能效果.
3) 替换高能效的电子元件,在满足节能的前提下,提高集群的性能.
