基于知识增强的深度新闻推荐网络
2021-03-31刘琼昕宋祥覃明帅
刘琼昕, 宋祥, 覃明帅
(1.北京理工大学 计算机学院,北京 100081;2.北京市海量语言信息处理与云计算应用工程技术研究中心,北京 100081)
新闻平台拥有大量的新闻信息,如果让用户直接选择,那么会对用户造成极大的选择困扰.因此,构建一个能够捕获用户的阅读兴趣并推送相关信息的个性化推荐系统对于新闻平台来说是至关重要的.在推荐系统中,主要有3类算法:基于内容的方法、协同过滤和混合方法.由于协同过滤具有用户和物品的交互信息是稀疏的特点且存在冷启动问题,不适合新闻推荐场景,主流的新闻推荐方法通常是基于内容或者混合方法.
随着深度学习技术的发展,一些研究人员开始利用深度学习模型来构建新闻特征和用户兴趣特征.Steffen提出了基于特征的因子分解模型LibFM[1],该模型在矩阵分解(MF)[2]、SVD++[3]、PITF[4]、FPMC[5]等基础之上,针对高维稀疏数据,实现了随机梯度下降(SGD)、交替最小二乘(ALS)[6]和使用MCMC进行贝叶斯推断的方法[7].Cheng等[8]提出了推荐模型Wide&Deep,将逻辑回归模型和前馈神经网络结合起来,既发挥逻辑回归模型的优势,又利用前馈神经网络的自动特征组合学习和强泛化能力进行补充,对模型整体学习,在Google Apps推荐的大规模数据上成功应用.Guo等[9]在FM[10]、FFM[11]的基础上进行改进,加入神经网络结构,提出了深度推荐模型DeepFM.该模型通过加入多层的神经网络,使得低阶和高阶特征组合隐含地体现在隐藏层中,解决之前模型只实现二阶组合特征的缺陷;并通过FFM的思想,将特征分为不同的域(Filed),降低模型网络参数;模型设计了并行和串行结构,实现了高阶的特征组合.
现阶段,基于新闻的推荐系统仅仅从语义层对新闻进行表示学习,忽略了新闻本身包含的知识层面的信息.而知识层面的信息大部分都存在于知识图谱中,将新闻推荐模型与知识图谱相结合的相关研究还很少.Wang等[12]提出了融合知识图谱信息的深度推荐模型DKN.DKN首先构造了一个与任务高度相关的知识图谱,接着在传统的深度神经网络模型的基础上,将知识图谱的实体信息融入到神经网络中,实现了把新闻的语义表示和实体的知识表示融合的目标.这种方法虽然考虑了不同层面上的信息,实验证明比未添加实体信息的传统方法效果好,但是用知识表示学习模型单独生成的实体向量更适合用于链接预测等任务,直接用在推荐模型中会丢失新闻实体之间的联系,造成一定程度的信息丢失.
现有的深度新闻推荐网络模型对知识图谱的融合只考虑实体本身的信息,融合知识图谱的实体特征或者与实体距离为1的相邻实体特征.这种方法虽然考虑了不同层面上的信息,补充了新闻实体信息,但是未考虑新闻实体之间的关联关系[13],忽略了知识图谱中远距离实体之间的联系,造成了新闻实体之间的关联信息和深层次语义联系的缺失.针对该信息缺失问题,本文提出了基于知识增强的深度新闻推荐网络DKEN,补充新闻标题实体之间的关联信息,在构建用户兴趣特征和预测点击候选新闻概率中分别添加实体路径特征[14],补充知识图谱中远距离实体之间的联系,增强模型的表达能力.
1 问题描述
融合知识图谱的深度新闻推荐网络模型通过构建新闻特征和用户兴趣特征对候选新闻进行推荐.模型定义如式(1)所示.
p=f(u,v|θ,C,G)
(1)
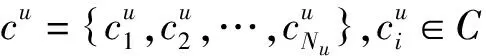
模型的整体流程如图1所示.在模型训练模块,DKEN考虑了两种向量:一种是实体和关系向量;一种是新闻标题中的词向量.实体和关系向量首先从新闻语料中识别出实体,将其与知识图谱中的实体相匹配,构造出新的知识图谱,利用知识表示学习模型得到实体和关系的向量表示.新闻标题中的词向量表示使用大规模语料通过词嵌入方法得到.在模型测试模块,基于训练得到的DKEN模型,预测用户点击候选新闻的概率.
图1 DKEN的整体流程
2 模型描述
2.1 模型架构
DKEN的整体框架如图2所示,输入是候选新闻标题、用户浏览过的新闻标题以及候选新闻标题与每个浏览过的新闻标题之间的实体路径,输出是用户点击候选新闻标题的概率.模型首先用基于知识感知的卷积神经网络(knowledge-aware convolutional neural network,KCNN)[12]融合新闻标题的文本特征、实体特征和实体上下文特征,构建候选新闻特征.然后,对于用户浏览过的新闻标题,考虑候选新闻特征,使用注意力网络动态地构建用户的兴趣特征.为了更好地刻画用户浏览过的新闻标题与候选新闻标题之间的远距离联系,论文额外考虑了两者所包含实体之间的路径信息,利用长短期记忆网络构建路径特征.最终,以候选新闻特征、用户的动态兴趣特征和加权实体路径特征为输入,用多层感知机(MLP)得到用户点击候选新闻的概率,进而达到推荐目的.
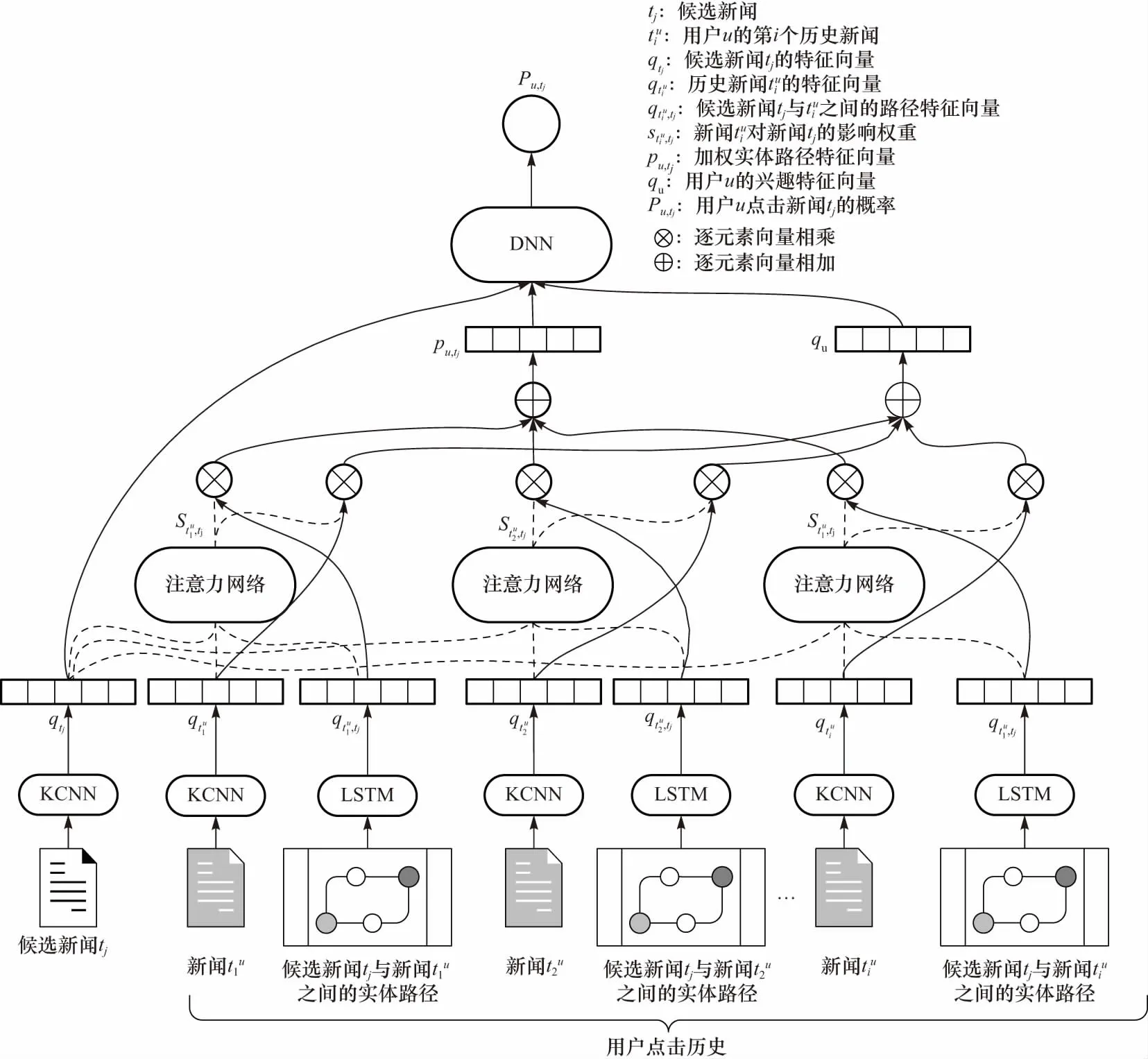
图2 DKEN的整体结构
2.2 知识图谱构建
为了在模型中利用知识图谱的信息,本文首先构建一个和任务高度相关的知识图谱.首先从新闻标题中识别出实体,本文采用Sil等[15]所提出的实体链接技术,将新闻标题中的单词与知识库中的实体进行匹配消歧.在处理完所有的新闻标题后,得到一个新闻实体集合Enews.由于原始的知识图谱规模较大,包含了大量与集合Enews中的实体无关的内容,为了减少计算代价,本文根据集合Enews从原始的知识图谱中抽取出一个子图,子图中剔除了那些不属于集合Enews且不处于连通任意ei∈Enews的路径上的结点和相应的边.接下来本采用知识表示学习方法,例如TransE[16]、TransH[17]、TransR[18]、TransD[19]等将知识图谱子图中的实体和关系映射到低维向量空间,得到实体和关系的特征向量,供后续的DKEN模型使用.
2.3 新闻特征构建
本文构建新闻特征采用与DKN模型相同的方法,即使用知识感知的卷积神经网络KCNN来提取新闻特征.该方法以Kim提出的TextCNN[20]为基础模型,融合文本特征、实体特征和实体上下文特征来提取新闻特征.
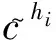
(2)
2.4 实体路径特征构建
(3)
其中,⊕为连接运算符,将实体向量el与关系向量rl连接为一个2d维的向量xl,作为LSTM的第l个输入,对于l=L的情况,用一个零向量填充缺失的关系向量.在LSTM中,每个单元的计算如式(4)~(9)所示.
zl=tanh(Wzxl+Whhl-1+bz)
(4)
fl=σ(Wfxl+Whhl-1+bf)
(5)
il=σ(Wixl+Whhl-1+bi)
(6)
ol=σ(Woxl+Whhl-1+bo)
(7)
cl=fl·cl-1+il·zl
(8)
hl=oltanh(cl)
(9)
其中,cl∈Rd′、z∈Rd′分别为细胞状态以及当前细胞要更新的信息;d′为隐含层的单元数量,即状态向量的维度;il、ol和fl分别代表输入门、输出门和遗忘门;Wz∈Rd′×3d、Wf∈Rd′×3d、Wi∈Rd′×3d、Wh∈Rd′×d′分别代表映射矩阵;bz、bf、bi和bo为偏置向量.σ为sigmoid激活函数,为逐元素(element-wise)的乘法操作.最后一层输出hl作为整个路径的特征向量表示,用H来表示LSTM网络,即H(p)=hl.
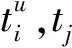
(10)
2.5 用户兴趣特征构建
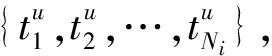
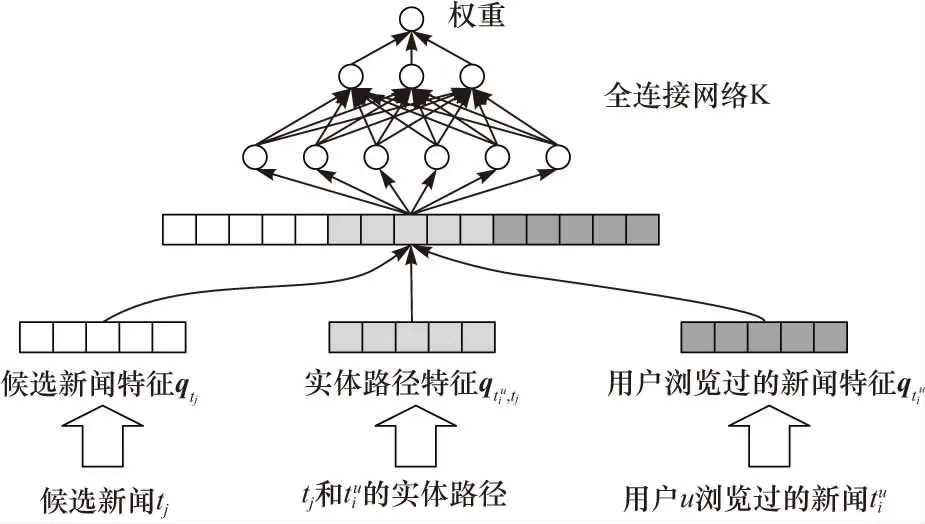
图3 注意力网络
(11)
用户u的动态兴趣特征qu的计算公式如式(12)所示.
(12)
2.6 预测点击概率
在预测用户u是否会点击候选新闻标题tj时,本文提出的模型DKEN不仅考虑了用户的动态兴趣特征、候选新闻特征,还考虑了候选新闻标题和用户浏览过的新闻标题的的加权路径特征,通过多层感知机预测用户点击候选新闻的概率.
候选新闻特征qt如式(2)所示,用户u的动态兴趣特征qu如式(12)所示,候选新闻标题和用户浏览过的新闻标题的的加权路径特征pu,tj的计算公式如式(13)所示.
(13)
最后,用一个多层感知机G来预测用户u点击候选新闻tj的概率,计算公式如式(14)所示.
pu,tj=G(qu,qtj,pu,tj)
(14)
3 实验结果和分析
3.1 实验设置
本文采用的数据集与DKN相同,来自必应新闻,其中每条记录包含用户ID、新闻标题、用户是否浏览以及时间戳等信息.训练集数据集来自2016年10月16日至2017年6月11日的新闻,测试集数据来自2017年6月12日至2017年8月11日的新闻.本文通过微软的Satori知识图谱数据库信息,将新闻标题中的单词与知识库中的实体进行匹配消歧,并同时获得与实体一步可达的实体.表1和表2分别是提取的知识图谱和新闻数据集的统计信息.

表1 提取的知识图谱的统计信息

表2 新闻数据集的统计信息
图4和图5分别是一条新闻标题中单词(去除停用词)和实体的数目的分布.实验中训练集和测试集都经过采样保证正负样本的均衡,表3是训练集和测试集的统计信息.
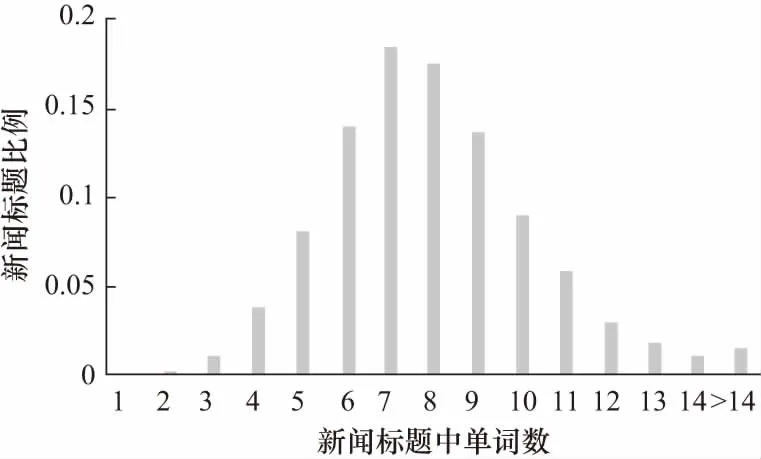
图4 新闻标题单词数量分布
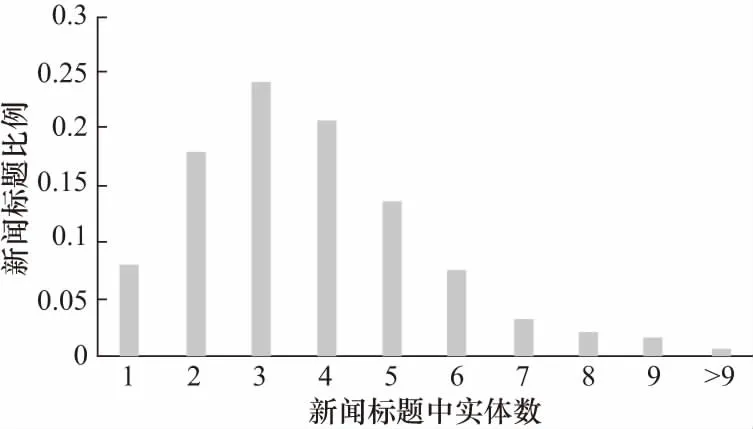
图5 新闻标题实体数量分布

表3 训练集和测试集的统计信息
实验的参数设置如下:word embeddings和entity embeddings的维度是100,KCNN中,窗口大小是1,2,3,4,每个窗口对应的卷积核个数均是100.使用Adam[22]训练优化模型.
实验对比的基准方法如下.
TextCNN:从新闻标题的词向量中提取文本特征作为新闻的向量表示,用户特征用该用户浏览过新闻的特征向量的均值来表示,用一个多层感知机基于用户特征和候选新闻特征来预测用户浏览新闻的概率.
KPCNN[23]:在TextCNN的基础上,引入单词对应的实体的向量,将其拼接在单词的词向量后面作为单词的综合向量.
DKN:利用TextCNN从新闻的文本特征和实体特征中学习新闻的综合特征,利用注意力网络构动态构造用户特征.
Wide&Deep:一种通用的推荐模型,包含一个线性的wide通道和非线性的deep通道.
LibFM:一个经典的基于特征分解的CTR预估模型.
3.2 实验结果分析
3.2.1基准模型对比
DKEN和各种基准方法的实验结果对比如表4所示,为了更方便的对比数据,在AUC指标上,将数值放大100倍后显示.其中Wide&Deep*和LibFM*分别代表Wide&Deep和LibFM去掉实体向量输入后的版本.
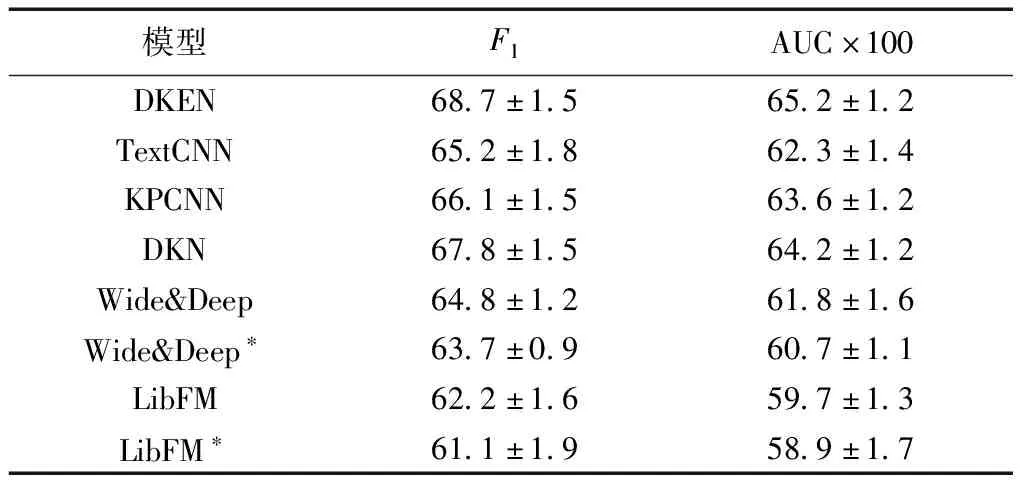
表4 DKEN与基准模型的实验结果比较
从表4中可以得出,LibFM的表现最差,一方面是因为LibFM模型本身结构比较简单,限制了表达能力;另一方面是因为LibFM需要人工从词向量中构造新闻的特征和用户特征,人工很难构造出最适合该模型的特征.除了LibFM,其他模型均为深度网络模型,其中Wide&Deep是一种通用的推荐模型,应用于本论文描述的新闻推荐问题时,同样需要人工从词向量中构造新闻特征作为模型输入,因此效果相对较差.Wide&Deep和LibFM在引入了实体向量作为额外输入后,性能均得到了一定的提升.
TextCNN、KPCNN、DKN、DKEN这4种模型均是基于CNN从原始的词向量中提取新闻特征.其中TextCNN仅考虑新闻标题文本的词向量,KPCNN在TextCNN的基础上,将单词的对应实体的向量拼接在每一个词向量后面作为单词的综合向量,模型相对TextCNN有一点提升.DKN在TextCNN的基础上,以多通道的形式融合了词向量和实体向量,并对实体向量做了映射,这种方式与KPCNN直接拼接两种向量的做法相比更加合理,另外还引入了注意力网络来更好地构造用户特征,因此DKN与KPCNN相比有了更大的提升.本文提出的模型DKEN在DKN的基础上引入路径向量,在一定程度上弥补了实体向量的信息丢失,加强了注意力网络的效果,与DKN 相比有了进一步的提升.
3.2.2模型变体对比
为了进一步说明DKEN中各种机制的效果,本文针对DKEN的各种变体进行了对比实验,结果如表5所示.其中,DKEN without attention表示DKEN去除注意力网络后的模型,DKEN without path embedding表示DKEN去除实体路径向量后的模型,DKEN without context embedding表示DKEN去除实体上下文向量后的模型,DKEN without entity embedding表示DKEN 去除实体向量后的模型,DKEN without knowledge embedding表示DKEN去除了实体向量和实体上下文向量后的模型,DKEN without mapping表示DKEN去除了对实体向量的映射后的模型,DKEN+TransE、DKEN+TransH和DKEN+TransR中的实体向量分别通过TransE、TransH和TransR学习得到,其他情况下的DKEN默认采用TransD 学习实体向量.
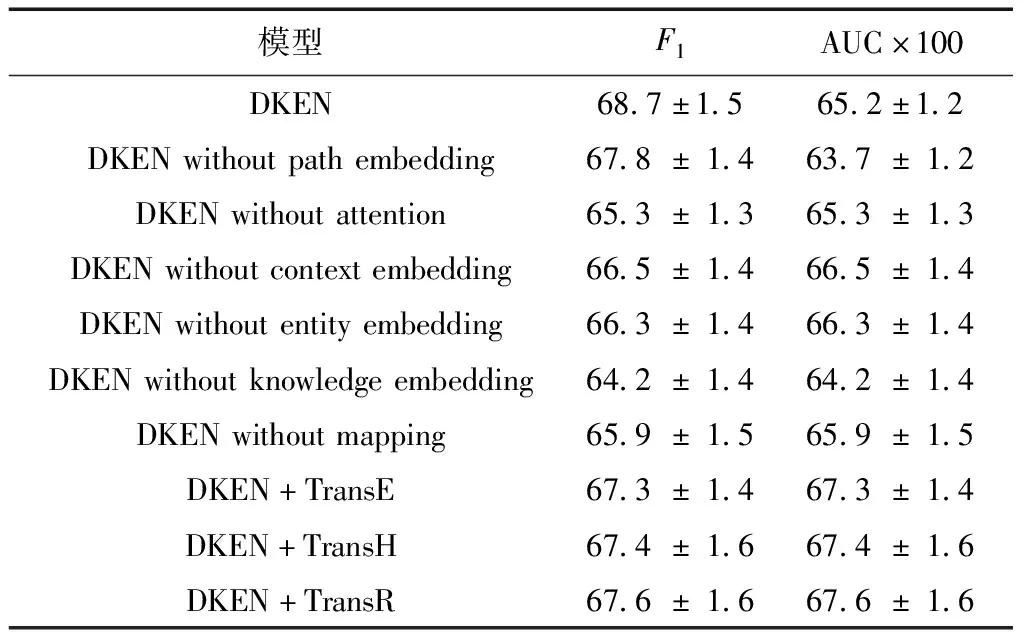
表5 DKEN变体直接的实验结果比较
从表5中可以得出如下结论.
(1)实体路径向量的引入使得模型性能得到了提升.对知识图谱信息的融合如果仅仅考虑实体的信息,那么就会忽略了远距离实体之间的联系,实体路径向量补充了这种实体之间的关系联系和深层次语义联系.
(2)注意力网络使模型关注到更为重要的信息,性能得到较大提升.
(3)实体向量和实体上下文向量都能带来一些提升,同时将这两种向量作为输入时,它们能够起到互补的作用,带来更多的提升.
(4)非线性映射函数的引入能够有效地减轻实体向量与词向量的兼容性问题,显著地提升模型效果.
(5)在使用不同的知识表示学习模型生成的向量时,DKEN性能有一些较小的变化,其中使用TransD生成的向量的DKEN模型取得了最好的效果.
3.2.3案例分析
为了直观地说明知识图谱在模型中起到的作用,本文抽取了某个用户A在训练集和测试集中的样本,分别如表6和表7所示,在训练样本集中,第1~5条跟IT相关,第6~8条跟政治相关,在测试样本集中,第1~3条和IT相关,第4条和电影相关.论文用同样的数据集分别训练包含知识图谱信息的模型(DKEN with KG)和不包含知识图谱信息的模型(DKEN without KG),这两种模型对用户A进行预测时的注意力结果分别如图6和图7所示,颜色越深表示注意力越高.从图5中可以看出,第1条测试样本对第1~4条训练样本有较高的注意力,这是因为“Apple”、“Microsoft”等词在新闻标题语料库中经常一起出现,如表8所示,而词向量正是基于这种词的共现关系来生成的,因此仅使用词向量的模型也能较好地捕获这种关联.第2~3条测试样本的结果较差,因为这两个标题中词与训练样本中的词没有在语料库中频繁地共现.而在图6中可以看出,第2条测试样本对第3~4条训练样本有较高注意力,第3条测试样本对第1~2条训练样本有较高注意力.这是因为“Youtube”和“Cortana”的实体在知识图谱中分别与“Google”和“Microsoft”的实体密切相关,它们的上下文重叠程度较高.
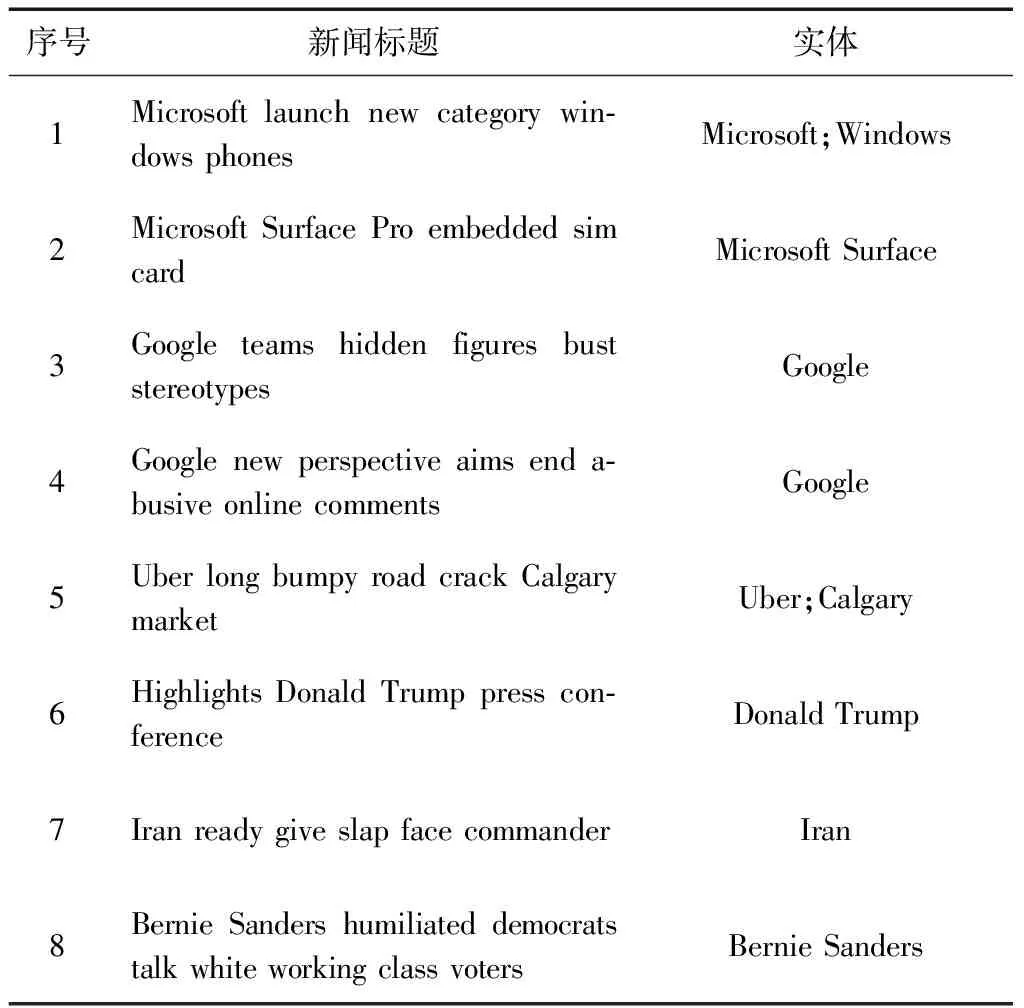
表6 用户A的训练样本集

表7 用户A的测试样本集

表8 部分与Microsoft相关的新闻标题
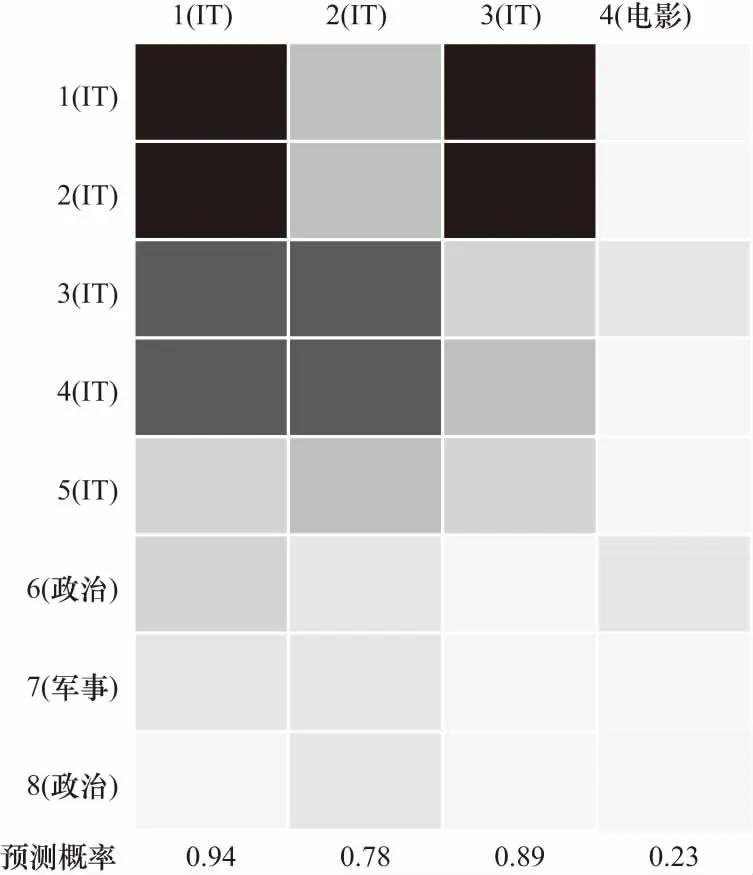
图6 用户A训练集和测试集的注意力可视化结果(有KG)
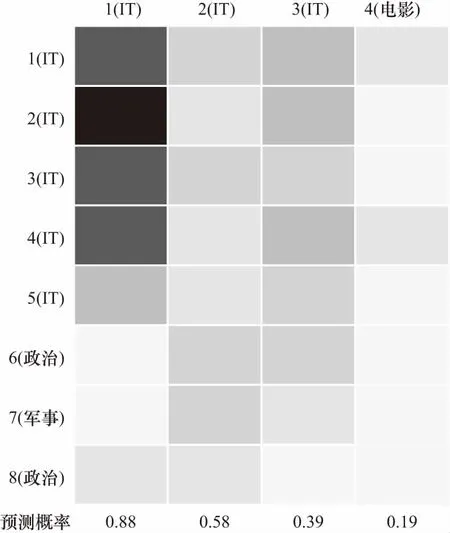
图7 用户A训练集和测试集的注意力可视化结果(无KG)
3.2.4推荐结果解释
结合注意力机制和新闻之间的实体关系路径,论文可以模型的推荐结果提供直观的解释.以用户A的测试样本3为例,该样本的注意力集中在训练样本1和训练样本2,这意味着测试样本3被推荐给用户A主要是受训练样本1和2的影响,因此可以将训练样本1和2中的实体与测试样本3中的实体之间的路径提取出来作为推荐的解释.训练样本1和2中包含实体“Microsoft”、“Windows”和“Microsoft Surface”,测试样本3中包含实体“Cortana”,在知识图谱中实体之间的关系如图8所示.DKEN模型在预测用户兴趣时,考虑到了实体在知识图谱中的关联,测试样本3被推荐给用户A,很大程度上是因为“Cortana”与“Microsoft”等实体关系密切,因此可以将这种实体关系展示出来解释推荐的原因.
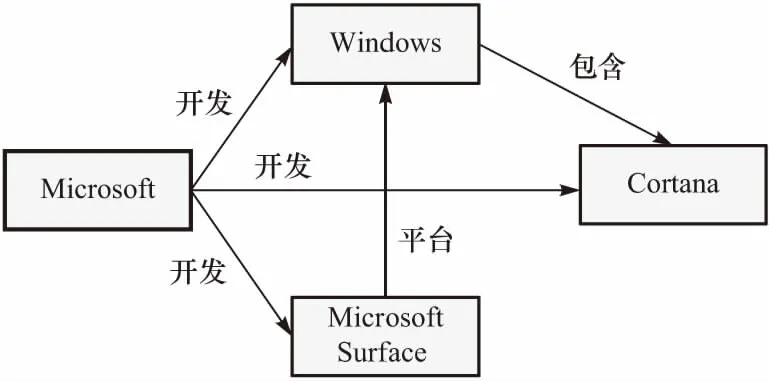
图8 对推荐结果的知识路径解释
4 结 论
本文基于现有的新闻推荐系统无法捕捉实体之间的深层次语义联系,提出了DKEN模型.模型利用KCNN从新闻标题的词向量、实体向量和实体上下文向量组成的三通道输入中提取新闻特征,利用注意力网络根据用户浏览过的新闻标题和候选新闻标题来动态构建用户特征、实体路径特征.为了更好地刻画用户浏览过的新闻标题与候选新闻标题之间的远距离联系,论文额外考虑了两者所包含实体之间的路径信息,利用LSTM构建实体路径特征.最后通过MLP来预测用户点击候选新闻标题的概率.实验结果显示该模型效果优于其他新闻推荐模型.在DKEN模型中,新闻标题中的部分单词无法对应到知识图谱中的实体,本文的做法是用零向量填充,在未来的工作中,可以考虑用更合理的方法解决该问题.
