基于多特征双向门控神经网络的领域专家实体抽取方法
2021-03-30张柯文严云洋朱全银马甲林
张柯文,李 翔,严云洋,朱全银,马甲林
(淮阴工学院计算机与软件工程学院,江苏 淮安 223005)
信息抽取(information extraction,IE)的主要研究方法是基于自然语言处理和文本挖掘,从非结构化或半结构化的网络文本数据中挖掘出有价值的信息[1]. 命名实体识别(named-entity recognition,NER)是自然语言处理和信息抽取的基础任务,从文本中识别命名性指称项,为关系抽取、机器翻译和自动文摘等任务做铺垫[2].
专家信息是一种以网络文本形式存在的非结构化数据,是专家向社会展示个人基本信息和过去经历的重要载体[3]. 通过大数据技术对专家信息进行整理、分类和分析后,以不同的形式为政府、高校、企业提供精准的专家信息服务,可以构建高校科技人才与政府、企业的联通桥梁. 然而,随着互联网技术的普及,大量的电子文本信息在筛选过程中需要耗费大量的时间及精力[4]. 实体抽取的研究更好地满足人们信息检索的需求. 通过从非结构化文本中提取指定类型的关键性信息,自动转换为结构化信息以支持数据库的保存及数据的下一步处理[5]. 在实体抽取的研究中,Zhang等[6]主要是关注人名、地名和组织机构名这三类名词的识别. 对于处理专家简历信息而言,除人名、机构名外,专家的其他信息(包括职称、研究领域名称、电子邮件地址及电话号码)的提取同样起着基础性作用,而特定领域的专有名词是非常重要的实体. 对研究领域名的识别研究还很薄弱,一方面,研究领域很大程度上与行业知识息息相关,另一方面领域的特殊性给实体的抽取带来了挑战. 因此,为更好地对复杂文本进行处理,将自然语言处理与行业知识深度融合受到了更多的关注.
本文首先对领域专家实体抽取及相关问题进行介绍;然后阐述基于多特征双向门控神经网络的构建过程及命名实体识别抽取专家信息过程;最后,以化工专家网络文本作为实验数据,使用HMM、IDCNN-CRF、BiLSTM-CRF及多特征双向门控神经网络抽取方法进行化工专家实体抽取,根据实验结果分析本文提出的模型的优势及未来工作.
1 相关工作
实体抽取方法可分为传统实体抽取方法、基于机器学习的抽取方法和基于神经网络的抽取方法. 传统实体抽取方法都是基于词典和规则的,通过大规模语料库构建词典,在实体抽取的识别准确率和召回率上取得了很大的提升[7]. 面向专家领域的规则还需要领域专业人士去构建,此类方法在抽取专家实体过程中不仅受限于词典的规模和质量,还无法识别和抽取新的实体. 基于机器学习的抽取方法在预测性上可以预测新的实体,逐渐受到研究者们的广泛关注. Morwal[8]引入马尔科夫假设的隐马尔可夫模型(hidden Markov model,HMM)算法非常适合用于序列标注问题,但其局限于输出独立性假设,在实际文本中限制了上下文特征的选择. McCallum等[9]提出的最大熵隐马模型(maximum entropy Markov model,MEMM)使用局部最优值解决了隐马的问题,同时也带来了标记偏见的问题. Lafferty等[10]于2001年提出的条件随机场(conditional random field,CRF),结合了最大熵模型和隐马尔可夫模型的特点,通过监督学习可更加高效地进行实体识别任务,还可以准确地预测新的实体.
为减少特征工程的需求,深度学习方法给实体抽取方法提供了新的思路. 神经网络出色的非线性映射和自主学习的能力在很大程度上减少了特征工程的工作量. 2018年Google发布的基于双向 Transformer 的大规模预训练语言模型(Bi-directional encoder representation from transformers,Bert)[11]在处理命名实体识别等序列标注任务中取得了很好的效果. Collobert等[12]最早提出用CNN对序列标注任务来自动提取特征的模型. Strubell等[13]提出使用Iterated Dilated CNN+CRF模型进行命名实体识别,取得了很好的效果. Huang等[14]提出目前中文序列标注最常用的模型BiLSTM-CRF,充分利用上下文特征,在实体抽取任务上取得了很高的成就. 深度学习模型在行业领域研究和应用中还处于起步阶段. 在实际研究中,基于神经网络的实体抽取任务多以英文语料为主,在中文文本的应用中效果差强人意.
本文针对中文专家信息的特点,以领域专业术语在文档中的特征进行分析,提出基于多特征双向门控神经网络的领域专家简介实体抽取的方法. 首先,挖掘网络文本并对其清洗及规范化,半自动标注构建领域专家简介语料库;接着,对语料库专业领域专业名词构造要素进行分析,使用Bert语言模型进行字嵌入表示;然后,将处理后的有监督文本向量输入双向门控神经网络,利用注意力机制有效获取特定词语长距离依赖关系;最后,结合边界特征构建条件随机场模型实现命名实体识别. 门控神经网络可以从上下文中自动找到更有用的单词以获得更好的NER性能,从而解决人工特征提取成本高和专业新词无法识别等问题.
2 问题描述
2.1 领域专家实体定义
领域专家实体抽取是进行专家信息抽取的首要工作,即从专家网络文本中识别并提取具有实际意义的实体,从而表示专家信息. 专家信息中的领域术语能够快捷准确地了解专家的研究领域及研究方向,有效抽取并利用领域专家实体能够更好地检索或推荐专家信息. 因此,本文以化工领域的专家网络文本为例抽取实体,基于多特征和双向门控神经网络构建自动抽取模型.
Zhang等[6]从新浪财经收集简历数据,将个人简历分为包括国家(country)、机构(educational institution)、所在地(location)、人名(personal name)、组织(organization)、行业(profession)、种族背景(ethnicity background)及职位(job title)8种实体,使用门控循环单元使模型从句子中选择最相关的字符和词,以生成更好的NER结果,而与行业领域方向相关的实体没有涉及. 本文分析专家网络文本发现化工领域术语存在以下特点:(1)中文行业领域术语实体歧义多变,且随时间推移不断出现新词,在抽取过程中新词识别无法掌控;(2)化工领域术语组合模式复杂,其中包含字长及中英文混杂的特点,如TAME原料预处理、DNW高温树脂合成异丙醚研究等;(3)领域术语多为嵌套或复合结构,如污染物防控及资源化利用、功能材料的合成及制备工艺等.
综上,本文将领域专家实体定义为3类,如表1所示. 第一类为普通名词性实体,包括人名、机构名及职称;第二类为数字性实体,包括联系方式和电子邮件;第三类为领域性实体,包括研究方向及领域关键词实体.

表1 化工领域专家实体描述Table 1 Entity description of experts in chemical industry

图1 领域专家简介实体抽取过程Fig.1 Process of domain expert introduction entity extraction
2.2 实体抽取目标
本研究的最终目标是从领域专家网络文本中提取定义的专家实体类型,重点解决领域性实体抽取过程中存在的领域实体无法识别及现有方法对人工特征过度依赖的问题. 本文从多特征角度对3类实体进行分析,提取相关性特征. 使用Bert语言模型以字符为单位进行文本向量化表示,统计特定词汇上下文边界信息;使用双向门控神经网络获取长文本上下文信息;训练条件随机场模型处理有强依赖性数据的难题,从而对文本实现更好的标注. 输出结果为:c={“content text”offset“content type”},其中,c表示输出内容;content text表示专家实体内容;offset表示实体起始到结束的标识;content type则表示定义的专家实体类型.
3 领域专家简介实体抽取模型
领域专家简介实体抽取过程以化工领域为例如图1所示,首先对化工专家网络文本进行预处理,包括分词、词性标注及特征抽取等;然后,将化工专家实体抽取转化为序列标注问题,将抽取的特征通过多特征双向门控神经网络提取隐藏层特征;最后将其输入到条件随机场模型对上下文标注进一步约束,得到序列标注结果,实现化工专家实体的识别和抽取.
3.1 语料库构建
3.1.1 数据清洗及规范化
通过数据源搜索的数据一定要经过清洗,才能让数据发挥价值,最终保证数据分析结果的准确性. 对于爬取的领域专家网络文本,通过预定义的清理规则,将脏数据转化为满足数据质量要求的数据,使数据变得完整和精准,从而保证后续数据分析结果的准确性[15]. 数据清洗方法包括:(1)筛查文本数据的一致性,根据数据源内部及数据元之间的规范,将文本转换为统一结构的规范化数据;(2)检测并清除特殊字符,使用规则匹配去除JavaScript代码及编号等无效字符;(3)检测重复文本,基于时间节点保留最新数据,保证数据的唯一性.
3.1.2 半自动标注构建领域专家语料库
张华平等[16]认为中文分词是中文自然语言处理的基础. 在中文自然语言处理中,词是最小的能够活动独立的有意义的语言成分,因此进行中文自然语言处理通常是先将中文文本中的字符串切分成合理的词语序列,然后在此基础上进行其他分析处理.
对于中文的分词规范取决于不同的应用,在领域专家文本中,本文使用半自动标注构建领域专家语料库. 首先,在基本分词步骤中引入专家姓名、机构名称及职称为基础词汇表,以保证分词结果的准确性;接着,对于数字性实体,使用正则表达式对邮箱及电话进行规则匹配并标记;然后,通过专业领域关键词,对研究方向及领域关键词实体进行匹配标记,其中嵌套或复合结构的领域术语不做细粒度拆分;最后,对分词后的结果进行人工检验,对于未标注实体,使用YEDDA工具进行人工补充.
3.2 特征抽取
数据预处理是自然语言处理的基础任务,处理的质量决定了模型实现的质量. 中文文本不同于英文文本,无法以空格进行划分,通常以词为单位. 分词结果的好坏同样影响着模型对实体抽取的性能. 本文根据所抽取的实体类别,引入字嵌入特征和边界特征进行分析.
3.2.1 字嵌入特征
唐明等[17]利用词嵌入方法生成文档向量,通过单词在连续的低维空间中表示,捕获单词间的语义联系,在处理文档分类上取得了很好的效果. Mikolov等[18]提出的Word2Vec和Pennington等[19]提出的GloVe在词嵌入上取得了很大的成功. 然而,对于中文语言没有明显词边界的特征,分词结果的好坏对语言处理的结果有很大的影响. 在专家网络文本中,除中文字符外,还包括标点符号、数字和英文字母,在处理词嵌入过程中给分词结果带来挑战. 因此,本文以字嵌入的方法对文本进行向量化表示,即每个汉字训练一个字嵌入. 根据训练集提取,在语言模型训练后生成一个大小为|C|的字典C,而未知字符也可以作为一个特殊的符号添加到字典中. 对于每个字c都可以映射为一个字向量vc∈Rd,d为向量维数,生成的字向量加入到字嵌入矩阵M∈Rd×|c|中. 本文通过对文本预处理,将文本以字表示,引入Bert语言模型生成字向量,作为实体抽取模型的输入.
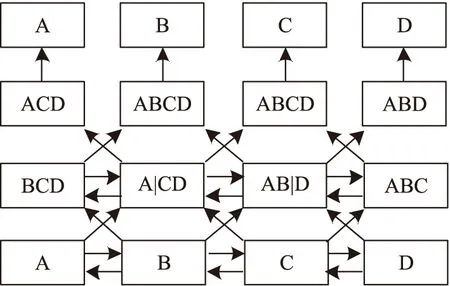
图2 双向语言模型任务Fig.2 Task of bidirectional language model
Bert模型采用Transfomer的编码器作为主体模型结构,舍弃了RNN循环式网络结构,引入了双向的语言模型任务如图2所示,完全基于注意力机制对文本进行建模. 通过注意力机制计算文本中每个词和所有词之间的相互关系,根据相互关系反应不同词之间的关联性及重要程度. 以词与词之间的权重获得每个词新的表征,通过自身及与其他词之间的关系得到全局性的表示. Transfomer则对输入的文本不断进行注意力机制层和非线性网络层的交叠得到最终文本的表达. 将Bert模型引入实体抽取任务,不仅考虑到上下文信息,还充分利用了全局信息,在进行实体消歧上有很大的优势,在处理相似的未登录字符上更容易被识别,提高了实体抽取模型的召回率.
3.2.2 边界特征
中文名词的表述上一般具有边界模糊的问题,即与名词相邻的词语具有很强的边界性. 传统基于词典和规则的方法可通过定义边界规则来区分名词信息,如联系方式与电子邮箱等具有明显的边界表示. 而在定义行业领域专业词汇上进行序列标注任务时,其组合模式多变、字长不固定及中英文混杂等特点使其在边界定义模糊. 本文以化工技术行业中英文关键词为标准,分词过程中基于关键词对嵌套或复合结构的领域术语实体不做细分,以减少对此类实体提取产生的影响. 在语料库中进行边界提取,提取结果如表2所示.
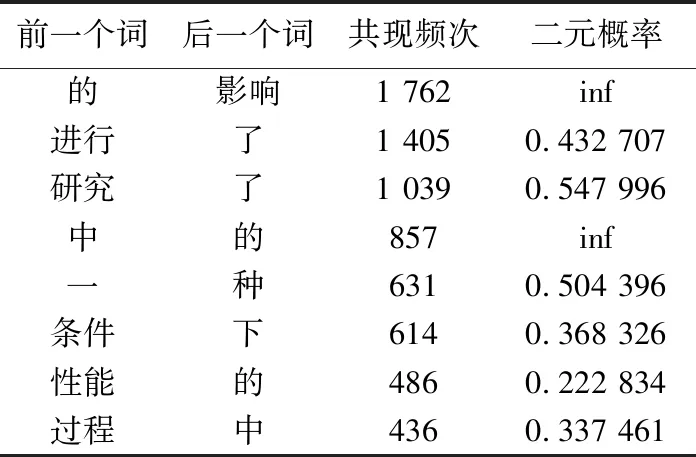
表2 边界提取统计表Table 2 Statistics table of boundary extraction
严云洋等[20]提出一种基于离群点检测的分类结果置信度的度量方法提高分类准确率. 本文将可信度作为边界的衡量标准,其定义如下所示:
(1)
式中,ci代表语料库中的第i个字符,fci表示其作为边界的二元概率,wci表示ci在未标注语料库中的共现频次. 通过可信度进行标准化得到离散化的特征数,作为边界特征输入到模型中.
3.3 BIGRU-CRF
循环神经网络(RNN)是一种能够有效解决序列标注问题及处理文本序列上下文依赖的神经网络模型. 而RNN无法很好地处理长距离依赖问题,在训练过程中存在梯度消失和梯度爆炸的问题. 基于这个问题,非线性激活函数长短期记忆(long short-term memory,LSTM)和门控循环单元(gated recurrent unit,GRU)被提出. LSTM在神经元中加入输入门(input gate)、输出门(output gate)、忘记门(forget gate)及记忆单元(cell state)改善梯度消失的问题. GRU作为LSTM的变体,将忘记门和输出门合并为一个更新门,结构更简单,训练时间更短,在训练结果上与LSTM取得相当的结果. 本文采用GRU学习文本的结构信息,其内部结构如图3所示,公式定义如下:

图3 GRU内部结构Fig.3 The internal structure of GRU
(2)
r=δ(Wr[x〈t〉,a〈t-1〉]+br),
(3)
(4)
(5)

伴随着20世纪80年代中国改革开放的大潮,新一代的闽商群体再度崛起,他们利用身处沿海开放地区的有利优势,以众多的中小坐商、行商为主,走南闯北,行销四方,从小商业开始,不断积累,逐步做强做大,呈现日益兴盛的趋势。很多人在赞叹闽商创造财富和取得成就的同时,认为闽商文化、闽商精神中缺少团队协作的精神,甚至认为闽商传统上有一种独立的、不合作的固有性格。这种看法值得商榷。从闽商赖于纵横天下的行销网络构建分析,其实我们处处都可以看到闽商团队协作的身影,不管是留守家乡,还是外出闯荡,就是依靠团队协作,他们才能克服困难、站稳脚跟进而发展壮大。
CRF可以关注句子级别利用邻居标签信息,产生更高的标记精度. 给定一组随机变量X={x1,x2,…,xn},对应随机变量Y={y1,y2,…,yn}满足P(Yv|X,Yw,w≠v)=P(Yv|X,Yw,w~v)的马尔科夫随机场为条件随机场,(X,Y)是条件随机字段,其中,X表示观察到的序列,w~v表示与节点v相连的w的所有相邻节点.Y的候选标签的联合概率分布可以在因子分解下表示为:
(6)
Z(x)为归一化因子,可表示为:
(7)
式中,tk是状态转移函数,sl是发射函数,vk和ui分别为tk和sl对应的权值.
3.4 Attention机制
双向GRU获取的上下文信息无法完全融入当前字符信息. Attention机制在不同时刻计算输出特征向量的权重,突出字符的重要特征.
score=vTtanh(W1hi+b1),
(8)
(9)
(10)
式中,score为包含语义信息的hi输入到单层感知机中获得单篇文档隐藏层的输出,计算出当前字符权重矩阵αi与文本特征向量hi进行加权和,得到包含文档各字符重要性信息的向量ci. 通过Attention机制控制当前字符权重,从而增加文档表示之间的语义联系,使整个模型获得更好的效果.
3.5 多特征双向门控神经网络的领域专家实体抽取
本文设计了一种在多特征选择的基础上,扩展基本字符单元,使用双向门控神经网络并添加注意力机制,CRF对获取的信息再利用进行序列标注,抽取领域专家实体信息,抽取结构如图4所示.
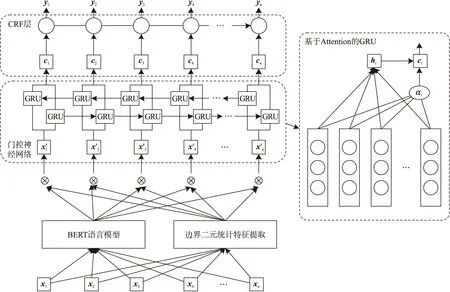
图4 多特征双向门控神经网络实体抽取结构Fig.4 Multi-feature bidirectional gated neural network entity extraction structure
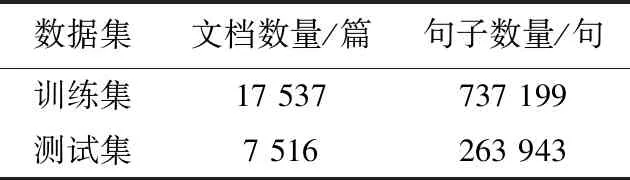
表3 实验数据描述Table 3 Description of experimental data
4 结果与讨论
4.1 实验数据
本文使用高校官网收集的专家网络文本作为实验数据,其中包含25 053篇化工专家文档,共5 162个汉字. 使用1 089条化工技术行业中英文关键词对化工领域术语进行边界特征提取. 将25 053篇化工专家文档以7∶3的比例分为训练集和测试集,数据描述如表3所示. 训练集共包含化工专家文档17 537篇、737 199句文本,测试集共包含化工专家文档7 516篇、263 943句文本. 通过使用本文提出的多特征双向门控神经网络算法进行命名实体识别与传统HMM、BiLSTM-CRF和IDCNN-CRF进行比较,验证算法的优越性.
4.2 评价指标
为减少外在人为因素的影响,本文通过精确率P、召回率R和F1值来评价模型效果[21]. 精确率为被识别为该分类的正确分类记录数与被识别为该分类的记录数之比;召回率为被识别为该分类的正确分类记录数与测试集中该分类的记录总数之比,召回率是覆盖面的度量,衡量了分类器对正例的识别能力;F1为精确率和召回率的调和均值. 其公式为:
P=np/nt,
(11)
R=np/nc,
(12)
(13)
式中,np表示正确识别的实体数,nt表示抽取的实体数,nc表示语料库中的实体数.
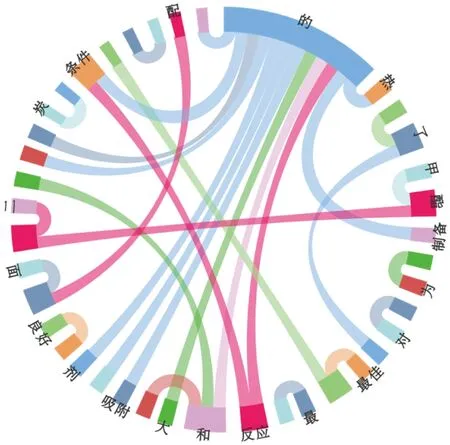
图5 边界二元词的可视化展示Fig.5 Visual display of boundary binary words
4.3 实验结果与分析
根据化工专家信息将实体分为人名、机构名、职称、联系方式、电子邮件、研究方向及化工关键词7个类别. 通过1 089条化工技术行业中英文关键词对化工领域术语进行边界特征分析,统计出化工领域术语上下文边界二元词共194 750对,图5为边界二元词的可视化展示. 同时统计边界二元词频集及出现频率,得到边界特征向量矩阵. 尽管和弦图无法表达术语方向,但和弦图的节点宽度给出了重量的直观表示.
实验以BiLSTM-CRF为基线对于加入特征提取算法进行测试,模型通过多特征与非字嵌入特征提取随机生成向量作为神经网络模型的输入,对比多特征神经网络模型在实体抽取任务上带来的增益. 实验结果如表4所示,相较于传统仅使用神经网络模型作为特征提取,加入字特征和边界特征对模型抽取的结果带来的效果最高. 模型的综合F1值达到94.69%,高于其他机器学习模型和深度学习模型.
本文重点以抽取领域专家实体为目标,以专业领域性实体为代表,通过抽取部分化工领域性实体对比本文提出的多特征双向门控神经网络和BiLSTM-CRF在化工专家语料上实体抽取的差异,如表5所示. 多特征双向门控神经网络模型能完整地识别专业术语“Pictet-Spengler反应”,而BiLSTM-CRF只能识别“反应”两个字,可见本文模型在识别中英文混杂化工专业关键词实体上具有很好的效果.

表5 本文模型和BiLSTM-CRF的实体识别效果Table 5 The entity recognition effect of the model in this paper and BiLSTM-CRF
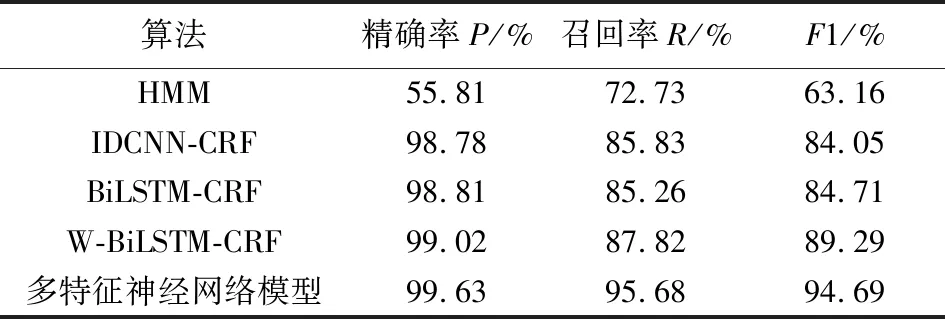
表4 多特征神经网络模型实体抽取任务实验比较Table 4 Experiment comparison of multi-feature neural network model entity extraction task
5 结论
本文提出的基于多特征双向门控神经网络的领域专家实体抽取方法,在抽取专家个人信息的同时,抽取代表其研究领域相关的关键词实体. 该方法通过分析使用Bert语言模型获取中文字符字特征,统计关键词上下文边界词分析获取边界特征;采用双向门控神经网络结合Attention机制获取字符上下文依赖特征;使用CRF进行序列标注. 以化工专家数据集为例,实验结果表明,该方法能够有效识别化工领域关键词实体. 然而,在抽取的关键词实体中仍然存在相似性较高的词汇如“环氧化酶-2,环氧合酶-2”. 因此,在抽取领域专家信息实体之后,如何抽取并利用实体之间的关系进行歧义性分析是本文进一步研究的重点.
