基于神经网络树和人工蜂群优化的数据聚类
2021-03-30吉珊珊
吉珊珊
(东莞职业技术学院计算机工程系,广东 东莞 523808)
高维数据聚类算法存在“维数灾难”问题,导致数据聚类的准确率和时间效率均无法满足实际的应用要求[1]. 特征选择处理是解决“维数灾难”问题的一个有效方法,能够有效地加快聚类处理的速度[2]. 高维数据的特征选择过程中,容易误删除与目标类相关的特征,保留冗余的特征,将此类特征子集应用于聚类程序,不仅降低聚类的准确率,也增加聚类的处理时间[3]. 因此,特征选择的性能对聚类处理的性能具有巨大的影响.
特征选择方法可以选出信息量丰富的特征子集,用于后续的聚类处理,而大多数特征选择技术通过训练仅输出唯一的特征子集,如果测试集存在噪声或者不完整则会导致聚类的性能下降[4]. 采用聚类技术能够发现信息量最大的多个特征类簇[5],有助于兼容不同的测试集,聚类技术和特征选择结合的技术称为混合特征聚类算法,这些技术能够最大化聚类准确率,同时保持较低的特征冗余度[6]. 通常混合分类器处理高维数据集的能力强于单一的特征选择技术[7],目前主流的混合聚类算法主要分为两种策略:基于软件、硬件的并行计算策略和基于快速学习算法的策略. 第一种策略采用GPU、云计算等并行计算架构. 第二种策略则包括动态森林技术(dynamic clustering forest)[8]、特征分组技术[9]、粒子群混合聚类算法等. 综合不同的实验结果,并行计算架构对于加速聚类速度具有显著的效果,但对于聚类的准确率并不具备改进效果,甚至以牺牲聚类准确率为代价以加快数据处理的速度[10]. 基于学习算法的混合聚类算法不仅提高了高维数据的聚类准确率,并且通过降维处理加快了聚类的速度.
综上所述,本文设计了基于学习方法和预测方法的高维数据聚类算法. 通过二元人工蜂群优化算法选择每个簇的最优特征子集,将每个特征子集作为节点构建径向基函数网络神经树,通过该机制能够有效地提高聚类算法的聚类准确率,并且加快算法的处理速度. 以神经网络构建决策树,通过不同的神经树预测各个类簇,神经树不仅具备决策树生成规则的优势,而且具备径向基函数网络的泛化能力. 通过门网络机制聚集森林所有神经树的最优结果,最终决定最优的类标签.
1 人工蜂群优化算法
1.1 基础人工蜂群算法
目前存在多个基于种群的优化算法,如差分进化算法、粒子群算法和进化算法等,在高维数值问题的效果上人工蜂群算法好于其他的同类型算法,同时能够高效地用于解决多维工程问题.
人工蜂群(artificial bee colony,ABC)共有雇佣蜂、观察蜂和侦察蜂3种成员,雇佣蜂负责搜索和定位食物源,雇佣蜂和观察蜂分享食物源的位置信息,观察蜂对食物源的邻域进行开发,寻找更加优质的食物源. 如果在T次迭代之后无法提高食物源的质量,此时启动侦察蜂阶段,在搜索空间中随机选择一个新的食物源. 随机选择食物源的方法定义为:
xi,d=xd min+rand(0,1)(xd max-xd min),
(1)
式中,xi为食物源i的位置,rand(0,1)函数表示输出区间[0,1]服从均匀分布的一个随机数,xd max和xd min分别为搜索空间维度d的上界和下界.
蜂群根据下式产生候选食物源的位置:
vi,d=xi,d+rand(-1,1)(xi,d-xj,d),
(2)
式中,v为产生的候选食物源,i和j为两个食物源,其范围为{1,2,…,SN},SN为食物源的数量,d的范围为{1,2,…,D},D为最大的维度,x为当前食物源的位置,rand(-1,1)为生成区间[-1,1]随机数的函数.
如果式(2)产生的候选食物源优于当前的食物源,那么雇佣蜂和观察蜂按食物源质量更新位置. 食物源的质量评价方法为:
(3)
式中,fi为目标函数的结果,xi为食物源,abs为取绝对值的运算符.
根据式(4)计算一个概率值,观察蜂根据该概率值选择食物源.
(4)
式中,fit为食物源x的适应度,SN为食物源的数量. 式(4)为高频率、高质量的食物源分配了更高的被选择可能性.
ABC算法全部流程可参考文献[11].
1.2 改进的二元人工蜂群算法
为了使ABC算法适用于本文的特征选择问题,采用连续-二元映射机制将ABC的解转化为二元形式. 采用式(5)将连续解xi映射至二元空间(zi):
zi,d=mod 2(round(abs(mod 2(xi,d)))),
(5)
式中,zi为一个二元候选解,d为维度,其取值范围为{0,1,…,D},mod 2(·)函数将输入值除以2,abs(·)为取绝对值的函数,round(·)为取整数的函数. 式(5)将解约束到区间[-a,a]内,a是一个正实数.
在每个维度生成一个[0,1]区间的随机数,如果随机数大于或等于0.5,将该维度的值改为1,否则,改为0. 二元的食物源位置定义为下式:
vi,d=xi,d⊗[φ(xi,d⊗xj,d)],
(6)
式中,“⊗”表示XOR运算,φ为一个逻辑“非”运算.
另一个二元ABC版本采用比特运算代替连续ABC算法的实数运算,二元人工蜂群(Binary Artificial Bee Colony,BABC)的食物源位置更新方法为:
vi,d=xi,d⊗[φ⊙(xi,d⊗xj,d)],
(7)
式中,φ为以相等概率生成0或1的函数,⊗为XOR运算,⊙为逻辑“与”运算,⊕为逻辑“或”运算.
本文对连续ABC做修改,实现BABC算法. 首先,修改式(1)的初始化程序,以相等的概率产生0和1值:
(8)
式中,xi,d为食物源i在维度d的位置,rand(·)是生成[0,1]区间随机数的函数.
对雇佣蜂阶段和观察蜂阶段(式(2))做修改,采用算法1选择、更新食物源. 算法中vi,d是式(7)生成的位置,D为维度的总数量,ceil( )返回给定数的最小整数. max_flip是0~1之间的值,表示支持的最高维度,max_flip控制种群的收敛速度,ceil( )保证至少选择1个维度.

本文对ABC的修改能够提高雇佣蜂阶段和观察蜂阶段的多样性,原因是这两个阶段的蜂群随机选择食物源和维度,该机制有助于提高种群的总体多样性. 在雇佣蜂阶段和观察蜂阶段,维度可能不等于dim,如果从食物源选择一个随机维度,该维度可能与当前蜜蜂的位置不同,但随着种群收敛,位置的差异会逐渐降低.

图1 高维数据的混合聚类算法流程框图Fig.1 Flow chart of hybrid clustering algorithm for high dimensional data
2 基于神经树的特征混合聚类算法
本文提出的高维数据混合聚类算法的流程框图如图1所示. 首先,对输入数据做基于聚类的特征选择处理,初步过滤部分冗余度高的特征;然后,基于分类的特征子集和样本集建立神经树,为神经树的叶节点分配类标签;最终,采用门网络分割类簇,区分类簇之间的交集.
在特征选择和特征聚类两类方法中,如果一些目标类相关的特征与其他类的冗余度也较高,那么这两种方法均会删除此类特征. 混合特征聚类算法能够有效地解决该问题,其基本思想是根据分类准确率将特征集分类,选出性能最好的特征子集. 本算法引入ABC算法筛选出与目标类最相关的特征子集.
2.1 基于互信息初步筛选特征集
采用互信息(Mutual Information,MI)评估不相关特征和冗余特征,一种互信息评估方法为MI(x,y),比较特征x∈X和目标类y之间的相关性,如果MI(x,y)较低,那么特征x是类y的不相关特征. 另一种互信息的评估方法为MI(x′,x″),计算每对特征{x′,x″}X的MI,寻找冗余的特征. 离散数据的MI计算为下式:
(9)
连续数据的MI计算为下式:
(10)
式中,P(x(i))为特征x的出现概率,P(x(i),y(j))为(x(i),y(j))同时出现的联合概率. 因为连续MI的计算复杂度高,所以采用式(9)的离散MI.
设计了基于MI的过滤式特征选择程序,其步骤为:
Step1.计算所有特征的互信息MI;
Step2.计算全部MI的平均值和标准偏差;
Step3.如果某个特征的MI值小于diff(diff=平均值-标准偏差),那么从特征空间删除该特征.
2.2 基于BABC的特征处理
聚集初步筛选后剩余的特征集,为每个类簇构建一个神经树. 每个神经树的时间复杂度为O(hNM),M为特征数量,N为样本数量,h为神经树的深度. 为了减少每个神经树的计算时间,定义参数δ使复杂度满足O(hNM)<δ,根据这个不等式能够确定每个类的特征数量. 然后通过ABC搜索每个类的最优特征子集,ABC的目标函数是最大化径向基函数(Radical Basis Function,RBF)网络的精度、最小化特征的冗余度. 特征聚类算法的程序如算法2所示.

2.3 结合BABC和特征选择的实现方式
BABC和特征选择的结合方式有如下两点:
(1)解表示方法:BABC的蜜源为二元值(0或1),如果某个蜜源为1,表示选择该蜜源对应的特征,每个空间维度为一个特征分类,值为1的蜜源数量约束为满足O(hNM)<δ的最多特征数量.
(2)适应度函数:采用式(3)的适应度函数最大化径向基函数网络的准确率、最小化特征的冗余度,以封装式方法最大化径向基函数网络的准确率,以过滤式方法最小化特征的冗余度:
(11)
式中,acc(k)为训练径向基函数网络的准确率,red(k)为特征的内部冗余度. red(k)的计算方法为:
(12)
式中,|ck|为类簇k的特征数量. 直接将式(9)的(x,y)替换为(x′,x″),计算类簇k中所有特征的MI(x′,x″).
3 构建神经树
3.1 径向基函数网络的决策树
每个神经树按特征分类将数据样本分类,其处理步骤为:
Step 1 在每个神经树的根节点中,将该类簇的特征子集按MI值降序排列,在神经树的每个深度将MI值最高的新特征作为分支.
Step 2 神经树的每个节点为一个径向基函数网络,径向基函数网络训练当前特征子集的样本. 径向基函数网络是一种单隐层前馈神经网络,使用径向基函数作为隐层神经元激活函数,输出层则是对隐层神经元输出的线性组合. 采用k-means聚类方法选择隐层节点的中心,网络输入层和隐层的节点数量均等于特征的数量,输出层的节点数量等于类标签的数量.
Step 3 对于父节点中的每个RBF网络nl,评估每个类的计算误差. 采用反向传播方式和上文选出的特征对RBF进行训练,选出误差最小的一个类,将该类的所有样本放入左子节点,剩余样本放入右子节点. 图2所示是构建神经树的流程图,图3所示是构建神经树的一个实例. 因为左子节点的样本同质,所以左子节点为叶节点,而右子节点继续分支处理.

图2 构建神经树的流程图Fig.2 Flow chart for building a neural tree

图3 构建神经树的一个实例Fig.3 Building an instance of a neural tree
Step 4 右子节点采用父节点的先验知识,从而加快RBF网络的训练速度. 首先,将父节点的特征集输入右子节点,然后,加入一个新特征. 父节点径向基函数网络的最终权重w(nl)也输入右子节点,设计了算法3确定右子节点径向基函数网络的最优权重,算法3中w(nl+1)是一个均匀随机数. 如果重新计算右子神经树的权重,需要计算矩阵(M行×N列)的伪逆矩阵,其复杂度为O(MN3). 因此,本文利用父节点的先验知识加速右子节点的分支速度.
Step 5.如果类簇的所有特征输入分类器或者右子节点达到同质,那么跳至步骤6;否则更新神经树的结构,增加深度l=l+1,返回步骤3.
Step 6.该步骤将比例最高的类标签分配至右子节点的所有样本.

3.2 基于门网络的类簇分割
特征聚类阶段并未保证特征类簇间的分离性,所以不同类簇之间可能存在交集. 将新样本的特征集按特征分类做分解,样本加入对应的神经树,神经树可能为样本分配不同的类标签,采用门网络集成所有的结果. 门网络的设计目标主要有两点:(1)结合所有神经树的结果,最终为每个样本产生一个唯一的类标签;(2)如果一个样本存在多个类标签,那么采用多数投票(Majority Voting,MV)技术根据可靠性选出唯一的类标签.
具体过程为:检查是否所有叶节点分配了唯一的类标签,如果存在叶节点分配了多个类标签的情况,那么采用MV技术根据可靠性选出唯一的类标签. 最终所有的叶节点均分配了唯一的类标签.
3.3 算法的时间复杂度分析
神经树的计算复杂度依赖径向基函数网络节点的数量和每个径向基函数网络的复杂度.
径向基函数网络负责搜索最优的权重向量W′,并为每个样本分配正确的类标签. 假设样本的数量为N,特征的数量为M,隐层神经元的数量为nhidd,类的数量为C. 一个全连接RBF网络输入层-隐层的时间复杂度为O(Mnhidd),隐层-输出层的时间复杂度为O(nhiddC),所有训练样本的时间复杂度为O(N(Mnhidd+nhiddC)).

(13)
式中,|nodeRBF|为神经树中径向基函数网络节点的数量.
4 结论与讨论
通常集成分类器处理高维数据集的能力较强,本算法采用BABC优化特征的分类,其次采用RBF神经树增强算法的分类性能. 在提高聚类性能的工作中,本算法主要设计了3个机制:(1)在RBF网络的最后一层,RBF网络仅识别一个类,这种一对多分类器(one-versus-rest,1-v-r)具有较高的分类准确率. (2)在最后一层中,神经树多个RBF网络积累的知识能够纠正一些错误分类的样本. (3)神经树最终的分类结果是统计了若干个RBF网络的结果所总结的结果,其准确率应当较高.
首先,通过1.2小节的算法最大化径向基函数网络的准确率. 然后,通过第2小节的方法选出每个特征子集的样本集,利用选择的样本集合第3小节的方法训练以径向基函数网络为节点的神经树. 最终,采用门网络将连接的类簇分离,获得最终的聚类结果.
4.1 实验数据集和实验方法
将本算法与其他5个混合特征聚类算法比较,分别为:AdaBoost ANN[12]、MOGPEF[13]、EFS-MI[14]、EFSHDD[15]、MCDCV[16]. AdaBoost ANN是一种基于人工神经网络的特征聚类算法,与本文的神经树策略相似;MOGPEF是一种基于多目标遗传算法的特征聚类算法与本文的BABC策略相似;EFS-MI、EFSHDD、MCDCV则是近期对于高维数据聚类准确率和计算效率均较好的3个混合聚类算法.
采用低维数据集和高维数据集评估本算法的综合性能,表1所示是低维数据集的一般属性,其特征数量的范围为4~60,低维数据集主要来自于UCI数据集. 表2所示是高维数据集的一般属性,其特征数量范围为10 000以上,其中Arcene、Twin gas和URL也来自于UCI数据集,Gas 2来自于文献[17].

表1 低维数据集的基本属性Table 1 Basic property of low dimensional datasets

表2 高维数据集的基本属性Table 2 Basic property of high dimensional datasets
4.2 处理低维数据集的性能
首先评估本算法对于一般低维数据集的处理效果,为了保证实验结果的置信度,所有算法的分类准确率结果采用十折交叉验证机制统计算法的准确性. 图4是5个集成分类算法对低维数据集的分类准确率结果,图中结果显示本算法对于6个不同的数据集均实现了较高的分类准确率,Adaboost ANN算法和MCDCV算法对于Glass数据集的分类准确率低于50%,而MOGPEF算法、EFS-MI算法和EFSHDD算法对于Glass数据集的分类准确率也远低于本算法,综合图中可看出,其他5个集成分类算法对于不同数据集的稳定性较差,而本算法对于6个数据集的平均分类准确率均高于90%.
分类算法的处理时间是一种重要的性能,比较了本算法与其他算法的时间效率. 图5是6个集成分类算法对低维数据集的平均处理时间结果(10次独立时间的平均值). 图中结果显示本算法对于IRIS数据集的时间高于其他两个算法,对于Glass数据集和Breast数据集的时间则高于EFS-MI算法,对于Wine数据集、Heart数据集和WDBC数据集的时间则低于其他两个算法. 总体而言,EFSHDD算法的处理时间较长,该算法需要针对每个特征计算其预测精度,该过程消耗大量的时间. 本算法通过高效的初步筛选机制过滤了大量的冗余特征,在构架神经树的过程,神经树的每个深度对应一个类簇,因此预测的效率较高.
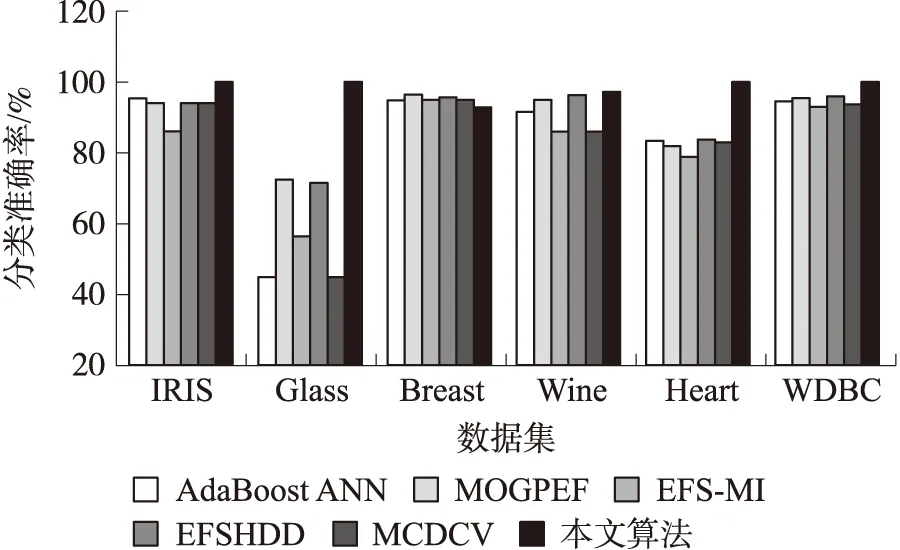
图4 低维数据集的分类准确率结果Fig.4 Classification accuracy results for low-dimensional data sets
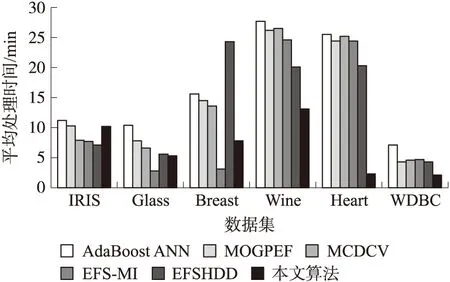
图5 低维数据集的平均处理时间Fig.5 Average processing time for low-dimensional data sets
4.3 处理高维数据集的性能
本部分将重点评估本算法对于高维数据集的处理效果. 为了保证实验结果的置信度,所有算法的分类准确率结果采用十折交叉验证机制统计算法的准确性. 图6是5个集成分类算法对高维数据集的分类准确率结果,图中结果显示本算法对于4个不同的数据集均实现了较高的分类准确率,4个数据集的特征数量均高于10 000,Arcene的特征数最低,6个分类算法均实现了可接受的准确率结果. 比较Arcene、Gas 2、Twin gas 3个数据集的结果,其特征量从10 000大幅度增至480 000,本算法的分类准确率从97.26%降至94.69%,依然保持较高的分类准确率,URL数据集的特征量高达3 231 961,而本算法对于URL的准确率降低至约80%,依然明显高于其他5个分类算法. 观察高维数据的实验结果,本算法对于特征数量大于样本数量的数据集性能更好,原因是神经树森林中多个树可能包含重复的样本和非冗余的特征,而通过训练神经树中不同特征类簇的小样本集合,综合不同角度的神经树能够有效地提高最终的分类准确率.
高维数据分类处理的时间复杂度较高,所以时间是高维数据分类处理的关键性能,比较了本算法与其他算法的时间效率. 图7是6个混合分类算法对高维数据集的平均处理时间结果(10次独立时间的平均值). 图中显示6个算法对于Arcene数据集的处理时间较为接近,而随着特征量的大幅度增加,EFS-MI算法和EFSHDD算法均表现出明显地增长,而本算法时间的增长幅度较小.
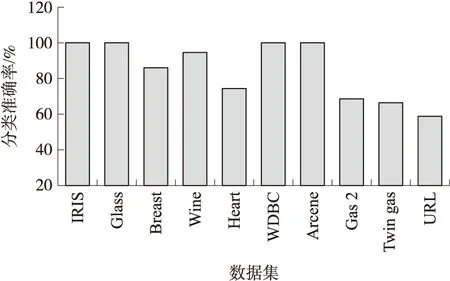
图8 噪声数据集的分类准确率结果Fig.8 Classification accuracy results for noise data sets
4.4 噪声鲁棒性的性能
测试聚类算法对于噪声的鲁棒性,为数据集增加15%的高斯噪声处理,本算法对每个数据集独立地运行20次,统计20次的平均结果作为最终的实验结果,结果如图8所示. 结果显示,本算法对于高斯噪声的分类性能略低低于无噪声的数据,但是性能的衰减极小,属于可接受的范围.
5 结论
本文设计了混合特征聚类算法,算法的混合特征聚类算法支持多特征子集的聚类处理,能够有效地增强对高维大数据的性能,对于噪声也具有较好的鲁棒性. 本算法通过高效的初步筛选机制过滤了大量的冗余特征,在构架神经树的过程中,神经树的每个深度对应一个类簇,因此预测的效率较高. 随着数据特征量的大幅度增加,算法时间的增长幅度较小,能够高效地处理高维数据. 未来将关注于将本算法应用于GPU或者MapReduce等并行计算架构,提高本算法的处理效率.
