上市公司财务报表舞弊识别的实证研究
——基于Logistic回归模型
2021-03-26濮双羽赵洪进上海理工大学
濮双羽 赵洪进(上海理工大学)
一、引言
真实公允的财报是会计信息使用者了解企业实情,做出正确决策的基本保障,而屡禁不止的公司财务报表舞弊欺诈行为严重影响着社会经济的发展,给投资者、债权人等利益相关者造成了深重的伤害,也打击了社会公众对中国资本市场和会计职业界的信心。
根据《中国注册会计师审计准则第1141号——财务报表审计中与舞弊相关的责任》的最新文件,我国正逐渐明确审计职业界对舞弊应该负有必要责任。但由于审计的固有限制,审计检查风险难以降至零。因此,在提高审计人员自身技术水平和职业道德的同时,也应该探索更加有效的财务报表舞弊识别方式。
本文试图以上市公司的长期偿债能力、短期偿债能力、发展能力、现金流量、盈利能力、营运能力六个角度,以可能有影响力的财务指标为解释变量构建财务舞弊的识别Logistic模型;运用Lasso回归方法对15个变量进行了筛选和简化,更好地抓取影响财务报告舞弊风险的关键因素,一定程度改善了模型受多重共线性影响的问题,提高了模型识别效率。
二、文献回顾
从国内外研究状况看,财务舞弊识别研究可以分为以下两个方面。
(一)舞弊公司特征及财务征兆的研究
Beasley (1996)运用logistic回归方法实证研究发现外部董事的比例与会计舞弊的可能性显著负相关。黄世忠(2004)从五个角度阐述了财务舞弊预警信号,分别是销售收入和成本舞弊、资产舞弊和负债舞弊、费用舞弊和披露等。
(二)舞弊识别指标和模型的研究
Persons(1995)、张长海(2005)等运用逐步Logistic回归模型成功判别了大部分的财务舞弊。研究指出舞弊公司具有舞弊信号的财务特征如:高财务杠杆、高度关联方交易、高流动资产比例、低资本周转率和较小规模等。陈国欣等(2007)在前人基础上,选取29个财务指标、股权结构、内控和公司治理指标,将财务指标舞弊当年数据和舞弊前一年比值作为解释变量,进行Logistic回归,预测正确率达95.1%,效果显著。总的来说,通过实证分析建立Logistic舞弊识别模型是一种预测舞弊的清晰有效且具有实际应用价值的研究方法。
三、研究设计
(一)数据来源
本文参考中国证监局在2006~2018年间公布的我国A股上市公司违规处罚名单,从中选取发生舞弊行为的116家上市公司数据为初始样本。剔除了金融及保险类企业、财务数据不全的公司,最终得到舞弊公司样本68家。
本文按照一一配对原则,为每一家舞弊公司选取配对非舞弊公司控制样本。选取过程如下:1.同一交易所:选取与舞弊公司在同一交易所上市的公司。2.行业相同:按证监会行业细分标准,选择与舞弊公司行业相同的公司。3.规模相近:选择与舞弊公司资产总额相近的公司,落在资产总额上下浮动20%范围内。4.未有过舞弊历史:上述公司从未有过因违规被证监会处罚的历史。数据来源于国泰安CSMAR数据库、CCER经济金融数据库。
(二)相关变量选取
本文设置共15个财务比率指标(见表1)。数据处理由stata15.1和R完成。
(三)模型构建
根据本文研究目的:识别上市公司财务报表舞弊,即发掘财务报表舞弊行为与财务指标信息的相关性,可知舞弊基本回归模型如下:
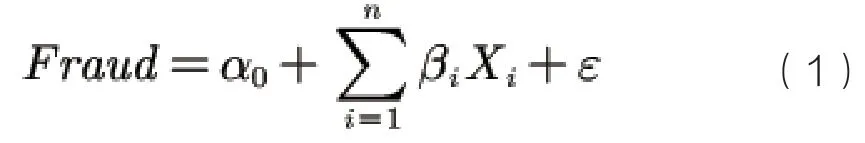
其中,因变量Fraud为虚拟变量,1代表发生舞弊样本,0代表未发生舞弊,a为常数项,β0表示各项系数,Xi代表各财务指标,ε代表残差项。
由于Fraud的二元选择性,非常适用二值分类因变量Logistic模型,根据模型(1)可建立如下Logistic模型2:
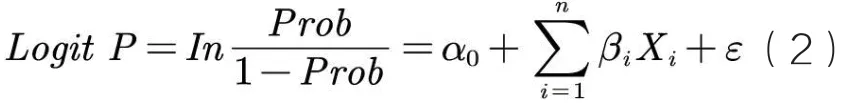
考虑到Logistic模型对多重共线性敏感,过多变量会使部分指标的统计检验不显著。为提高模型的预测效果,在回归之前,本文先采用Lasso回归方法对15个变量进行筛选(采用R中的glmnet程序包):根据一定的性能参数和复杂度调整对变量进行筛选,从而得出一个变量较少的模型。如图1反映了变量X1~X15的系数随着参数λ的增大,最终被压缩至0的过程。
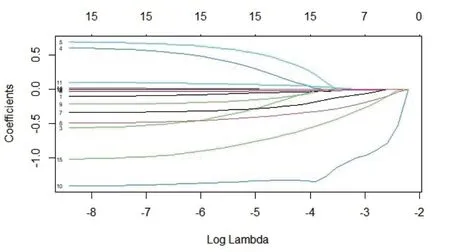
图1 Lasso 回归中变量剔除过程图示
在此基础上,为防止二元因变量Logistic模型过度拟合造成预测结果的偏差,本文采用交叉验证(cross validation)拟合进而选取变量。下图给出了在不同复杂度参数λ(横坐标)的条件下,筛选出的变量个数(图形上方数字)和相应模型误差(纵坐标)。
图2中两条虚线代表了两个特殊的λ值:左边虚线对应的lambda.min代表最小误差的λ值;右边虚线对应的lambda.1se是指在lambda.min一个方差范围内得到最少变量的λ值。本文采用后者为基准筛选,最终进入模型的变量是资产负债率、营业利润增长率、每股现金流增长率、每股经营活动现金净流量、总资产净利润率、营业利润率、存货周转率、应收账款周转率、固定资产周转率、总资产周转率(X1、X6、X7、X8、X10、X11、X12、X13、X14、X15)10个变量(见表2、见表3)。
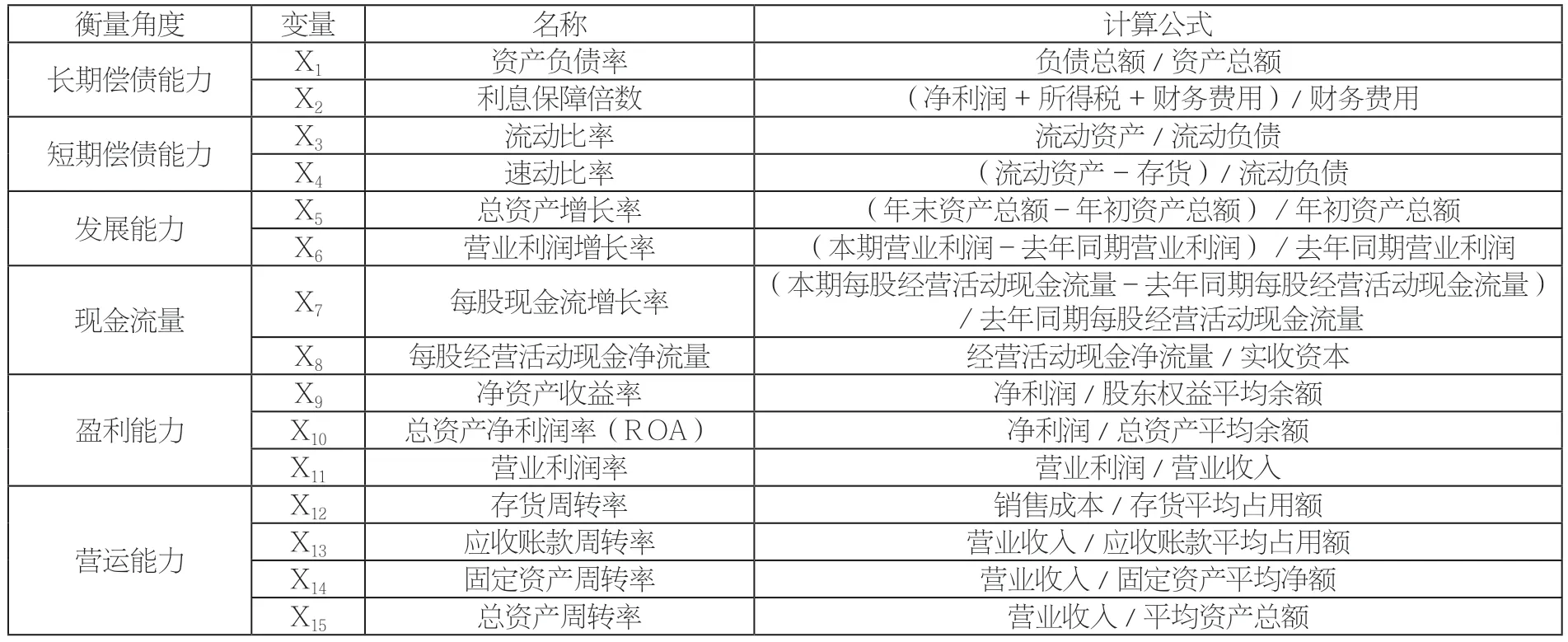
表1 解释变量
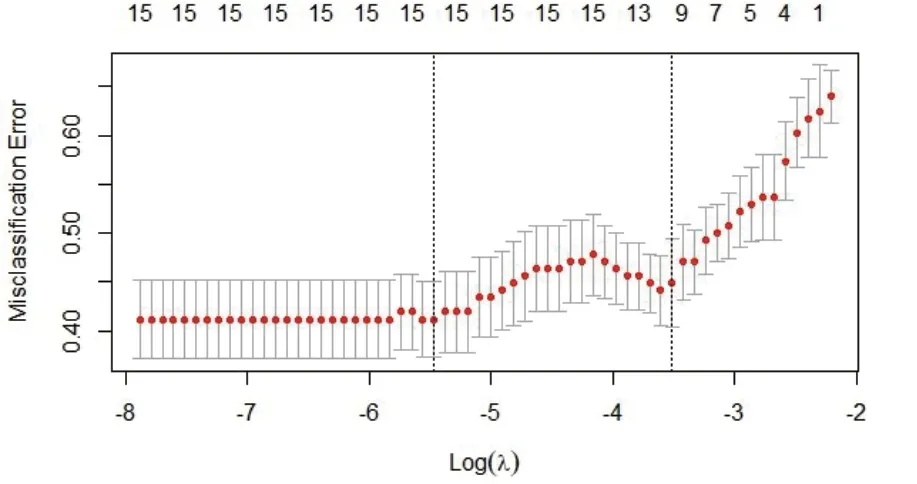
图2 Lambda与变量数目对应走势
得到经变量精简后的模型3:
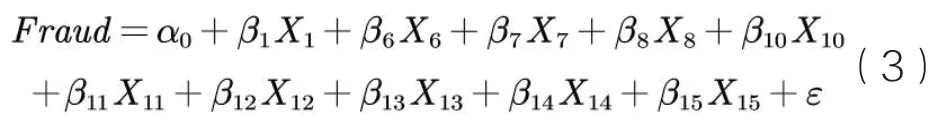
四、结果分析
(一)描述性分析
本文对选取的财务指标变量分舞弊公司和非舞弊公司分别列示,根据t检验值和Wilcoxon符号秩检验,发现营业利润增长率、每股现金流增长率、净资产收益率、总资产净利润率和总资产周转率(X6、X7、X9、X10、X15)这5个指标在舞弊公司和非舞弊公司之间存在显著差异(见表4)。因此,可以根据这五个指标对上市公司是否发生财务舞弊进行初步预判。

表2 交叉验证(cross validation)拟合结果
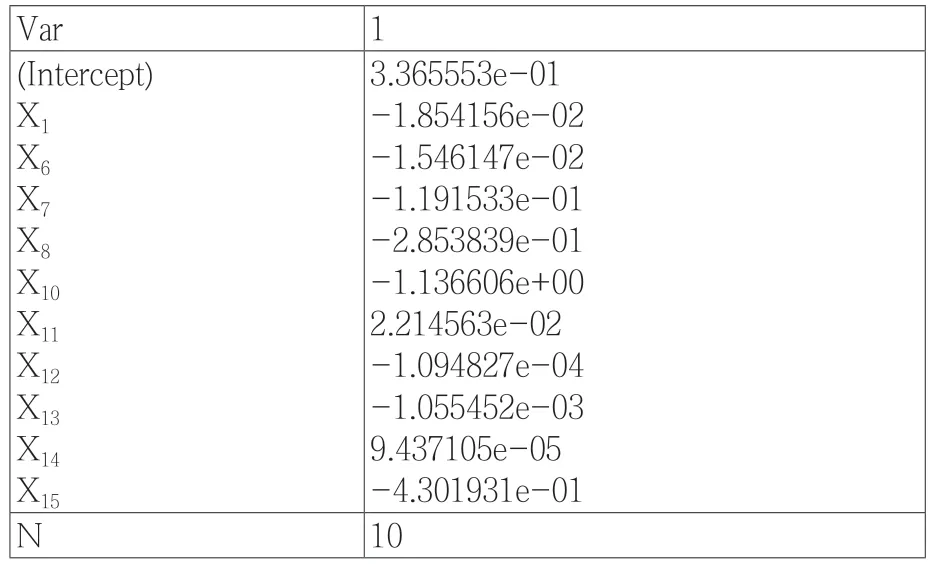
表3 交叉验证(cross validation)筛选变量
(二)实证结果分析
根据表5,资产负债率、每股经营活动现金净流量、营业利润率、存货周转率、固定资产周转率、总资产周转率(X1、X8、X11、X12、X14、X15)6个变量在一定水平下具有显著性,表明这些变量与企业财务舞弊之间相关性较好,可以通过这些指标识别财务舞弊,审计人员在实务中应重点关注。其中,X1、X8、X12、X15与Fraud呈负相关性,该变量值越大,发生舞弊的概率越小,也说明了具有较高长期偿债能力、充足现金流的企业舞弊动机较小。
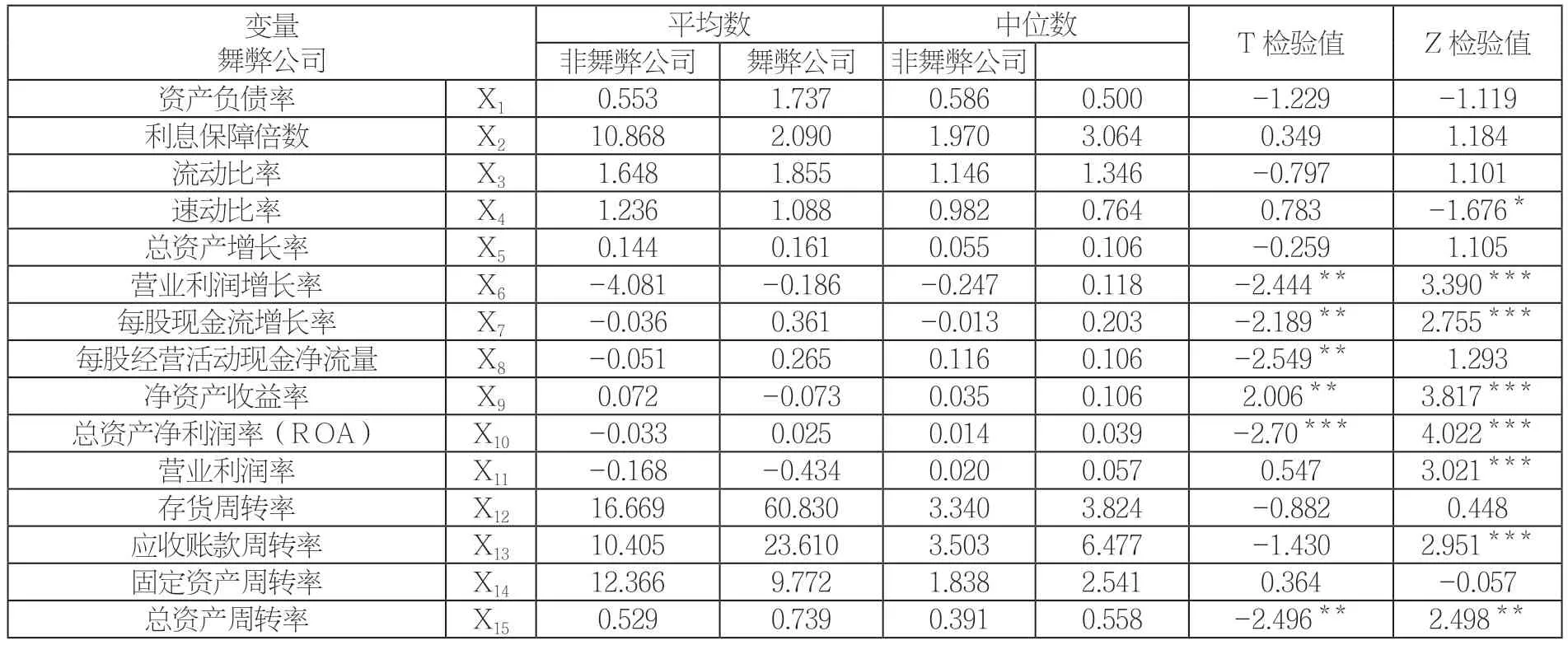
表4 描述性统计
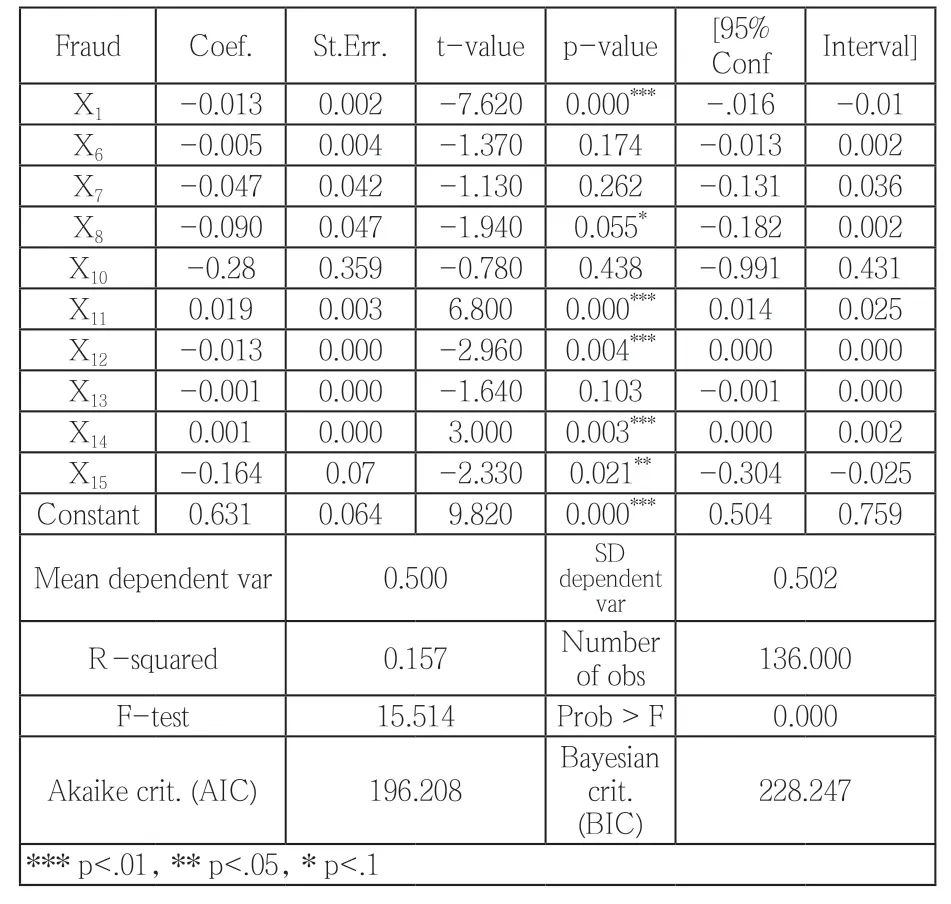
表5 Logistic回归结果
在代表盈利能力和经营能力的指标中,营业利润率(X11)、固定资产周转率(X14)和fraud呈现微弱正相关性,说明营业利润和固定资产周转率高的上市公司反而存在虚增利润、粉饰经营状况进行财务舞弊的可能性。究其原因,首先,虚构利润是上市公司舞弊的主要手段;另外,虚增营业收入和利润也会带来高于正常的固定资产周转率。针对这种情况,对两个指标更应该深入解读其内涵,需要审慎考虑该公司的收入是否真实,固定资产状况是否合理,而不能只停留于表面。
(三)模型识别能力检验
模型(3)经过OLS回归,将回归系数代入模型,得到财务舞弊识别模型(4):
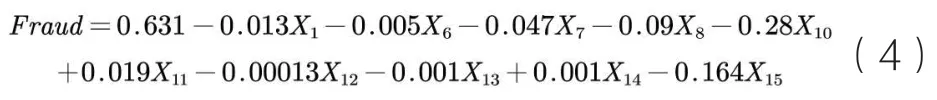
为了证明模型的识别效果,本文另选取我国A股市场2016~2020年15家舞弊公司和15家历史上未发生舞弊公司的数据分别带入模型(4),得到了分类结果,如表6所示。本文以Fraud>=0.5作为公司舞弊的分界点,对于舞弊样本预测成功率为73.33%,非舞弊样本预测成功率为100%,整体成功率为86.67%,说明通过模型能够很好地识别财务舞弊。
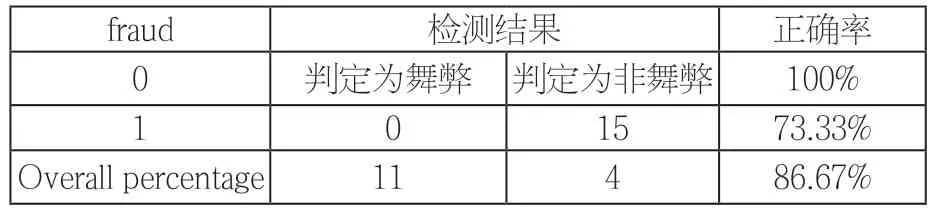
表6 分类验证结果
五、结论与建议
通过对我国证券市场上2006~2018年被证监局披露发生财务舞弊的上市公司,建立Logistic模型进行实证研究发现。
1.根据回归结果显示,资产负债率、每股经营活动现金净流量、营业利润率、存货周转率、固定资产周转率、总资产周转率6个变量在一定水平下具有显著性,可以通过这些指标识别财务舞弊,审计人员在实务中应重点关注。
2.将2016~2020年30家公司样本带入建立的Logistic模型进行检验,正确率达86.67%,说明模型对财务报表舞弊预测水平较显著。审计师可以在审计前通过模型对公司舞弊可能性进行判断,有针对性地安排审计计划。
总之,防范财务报表舞弊最直接的方法在于规范公司管理者的行为和态度。公司董事、监事以及高管,对于舞弊企业应该集中精力于提升生产效率与完善治理结构,从根本上提高企业自身价值。
