一种结合语义分割模型和图割的街景影像变化检测方法
2021-03-26李文国黄亮左小清王译著
李文国,黄亮,2,左小清,王译著
(1.昆明理工大学国土资源工程学院,昆明 650093;2.云南省高校高原山区空间信息测绘技术应用工程研究中心,昆明 650093)
0 引言
随着城市化和信息化的发展,城市和许多乡村都具有影像采集设备,同时随着交通的迅速发展,通过车载平台采集影像也越来越便利,这都为街景影像信息采集提供了便利手段.实时、精确的街景影像信息采集对城市规划、土地调查、交通监管、灾后评估等诸多领域都具有重要应用价值.但街景影像由于地物与拍摄设备的距离关系,造成同一地物尺度跨度范围大、远距离地物界限不清晰;同时也带来了地物光谱信息复杂多样的问题,如天空会同时存在阴云和晴空,造成严重的“同物异谱”现象.因此,如何自动、高精度的对街景影像进行语义分割和变化检测就成为当前计算机视觉领域的研究热点.
当前街景语义分割已开展了大量研究,但对多时相街景影像进行变化检测的研究则相对较少.文献[1]提出了基于视觉词袋模型(BOVW)的场景变化检测方法,并对比分析了不同字典构建方法对最终结果的影响.为了解决独立分类所带来的误差累计问题,文献[2]提出核化慢特征分析方法,并通过贝叶斯理论融合场景变化概率和场景分类概率;文献[3-4]提出利用二维图像进行场景变化检测.这种类型的方法根据不同时间段获取的图像对场景进行建模,然后在模型的基础上检测成对图像间的变化特征.但这类方法需要拍摄于同一视角的图像,不同视角拍摄的图像则无法处理.文献[5-8]则将场景变化检测转换为三维领域的问题.这类方法首先建立稳定持续的目标场景模型,然后将查询图像与目标图像进行比较以检测变化.但不同区域城市环境差异大,因此所建立的场景模型并不适合其他地区.近年来,深度学习在计算机视觉领域中展现出优异的表现,同时也应用于诸多领域,如自动驾驶、人机交互、医学研究等,因此目前也有人开展利用深度学习来对场景进行变化检测.文献[9]提出结合卷积神经网络(CNN)和超像素的方法对街景进行变化检测.这种方法利用CNN提取多时相影像特征,然后将不同时相的特征图进行对比形成差异图,再结合超像素所形成的差异图,形成整幅图像的差异图,最后去除天空和建筑,得到建筑物的变化检测结果.
综上所述,三维建模的方法不能适用于其他城市,而传统CNN由于特征图分辨率不断变小的原因,会丢失小尺度地物,因此需要一种既能满足街景影像的特点,同时又具有普适性的方法.为了解决不同尺度地物的语义分割变化检测精度的影响,引入了对小尺度地物具有很好识别能力的DeeplabV3+网络模型;同时为了消除天空、植被等对街景影像的影响,将天空、植被等作为背景信息,采用图割(GC)的方法将背景信息消除.
1 研究方法
本文提出一种结合DeeplabV3+网络得到的迁移学习模型和GC的街景影像变化检测方法.方法架构包括3个部分:1)采用DeeplabV3+网络迁移学习模型分类;2)基于GC的方法去消除天空和植被等影响,并采用变化向量分析(CVA)获取差异影像;3)差异影像二值化和精度评价.具体而言,首先将两幅不同时相的街景数据输入到DeeplabV3+网络迁移学习模型得到分类图,将分类图去除天空和植被得到GC处理后的分类图,然后将此分类图进行CVA运算得到差异图,最后将差异图二值化并进行精度评价,流程图如图1所示.
1.1 街景影像语义分割
当前已有较多语义分割网络,如U-Net、ICNet、PSPNet、HRNet、Segnet、Deeplab系列.其中,Deeplab V3+网络结合了空洞卷积与萎缩空间金字塔池化(ASPP),与传统卷积相比,DeeplabV3+网络能保持特征图分辨率不变,对尺寸小的地物具有很好的识别能力,且DeeplabV3+网络能够较好的保留边缘细节信息.DeeplabV3+网络在PASCAL VOC 2012数据集上取得新的state-of-art表现,其m IoU=89.0,验证了DeeplabV3+网络的优秀性能[10].DeeplabV3+网络于2018年提出,该网络在原有的DeeplabV3网络上进行改进,也是目前Deeplab网络系列中性能最优的网络.DeeplabV3+网络具有不同的特征提取主干网络,不同的特征提取主干网络会造成网络性能不一,实验采用ResNet-18作为特征提取主干网络,其结构如图2所示.
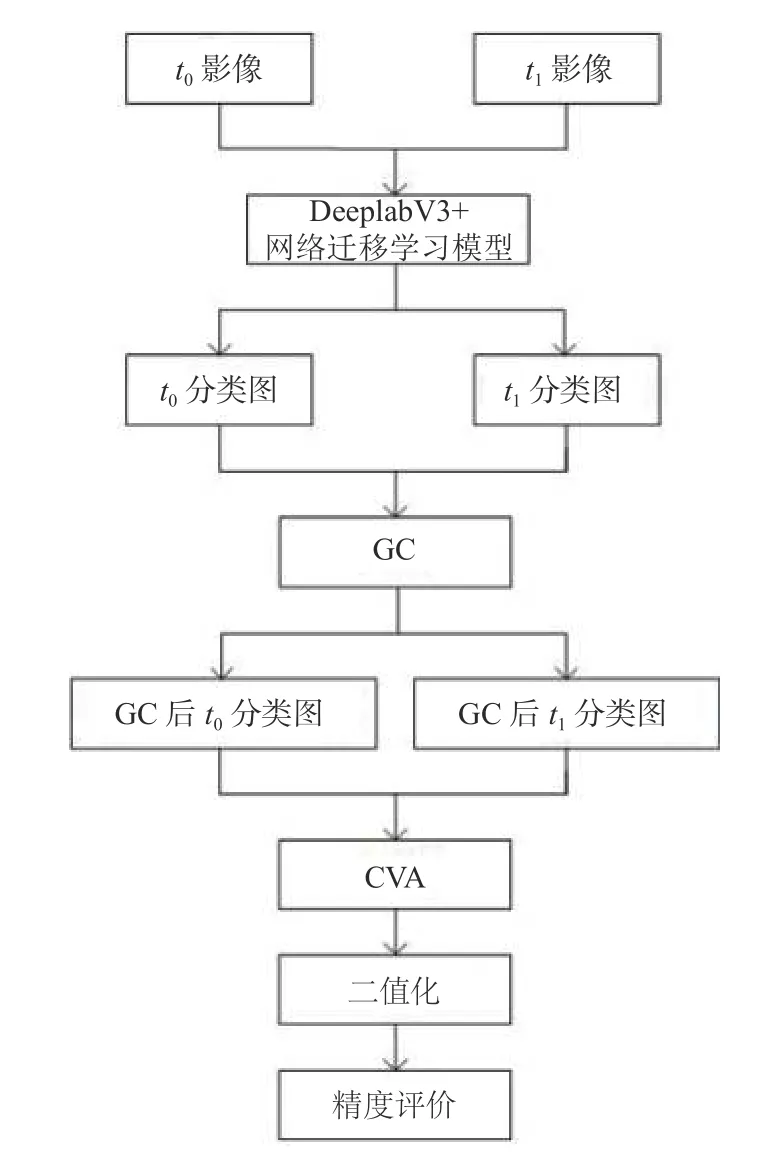
图1 变化检测流程图

图2 DeeplabV3+网络结构
深度学习需要大量的优质标签,而制作标签的过程常常是耗时耗力,本文所使用的街景影像数据集标签数量少,因此会因标签数量过少导致模型性能差,为了解决标签数量少的问题,引入迁移学习解决该问题.迁移学习可以减少训练时间和成本,同时也不需要大量的标签,在实验中,采用Camvid数据集训练的DeeplabV3+网络迁移学习模型对两幅不同时相的街景影像进行分类,图3(a)和图3(b)分别展示了DeeplabV3+网络迁移学习模型和Segnet网络迁移学习模型在街景影像分类结果,其中可以看出DeeplabV3+网络对汽车、电杆等识别能力优于Segnet网络,而且边缘细节也优于Segnet网络.因此本文选用Deeplab V3+网络对两个时相的街景影像进行语义分割.

图3 Deep labV3+网络与Segnet网络分类结果
1.2 背景消除
由于天空和植被等类别存在严重的“同物异谱”现象,为了消除“同物异谱”的影响.本文将天空和植被等作为背景类,其他作为目标类.采用GC法对目标类和背景类进行分割.
GC是一种能量优化算法,可以将目标和背景分割出来.GC将图像分割问题转换为图的最小割问题.具体而言,首先图具有两种边和两种顶点:第一种顶点为普通顶点,对应图像中每个像素,普通顶点间的连接线构成第一种边,为n-links;第二种顶点为终端顶点,用于区分前景和背景,因此也就有两个终端顶点,为S和T,每个普通顶点和终端顶点的连线构成第二种边,为t-links,每条边都具有权值.所有边的集合称为E,一个割即为边集合E的子集,为C,集合E中所有边的断开会导致S和T的分开,所以就为“割”.如果一个割,它的边的所有权值之和最小,那么这个就为最小割,也就是GC的结果.Boykov等[11]使用最大流最小割算法实现最小割.
在实验中,将天空和植被设定为背景,其他类别设定为前景,但未使用最大流最小割算法来计算前景和背景间的分割线,这样会导致前景和背景分割不精确,部分区域存在错误分类,因此人为设定一条分割线,从而实现前景与背景分割.
1.3 差异影像获取和二值化
为了获取两期街景影像语义分割结果的变化区域,本文采用CVA方法.CVA是一种常用的多波段影像差异分析方法,每个像元的特征是采用向量的方式来表示的,g和h为对应波段的一维列向量.由于TSUNAM I数据集使用R、G、B三个波段信息,因此n=3.设时相t1和时相t2中像元的灰度矢量分别为:

∆中包含两期图像中所有像元的变化信息,其变化强度用欧式距离∥∆∥来表示,以此可以生成两期影像的变化强度图.

式中,∥∆∥中表示全部像元的灰度差异,当∥∆∥越大时,则说明变化的可能性越大.因此在分割变化像元和非变化像元,可通过确定变化强度的大小,来选择分割的最佳阈值.
实验在获取差异影像后,将差异影像的像素分为两种类型:一种为0值,代表未变化区域;一种为非0值,代表变化区域.然后将差异影像中为0值的像素更改为255,将差异影像中非零值的像素更改为0,此过程即为二值化.二值化后黑色像素代表变化区域,白色像素代表未变化区域.
2 实验结果及分析
2.1 数据介绍
本文采用的街景数据集为TSUNAM I数据集,TSUNAM I数据集来源于文献[12],是日本某一地区海啸前后的全景街区影像.图4展示了实验选取的两组街景影像及参考图,两组影像的大小都为1 024像素×224像素,对两组街景影像分别命名为G1和G2,其中t0代表变化前的影像,t1代表变化后的影像,G1组t0和t1影像分别如图4(a)、图4(b)所示,G2组t0和t1影像分别如图4(c)、图4(d)所示,G1和G2参考图分别如图4(e)、图4(f)所示.G1组影像的变化区域像素为50242,非变化区域像素为 179134;G2组影像变化区域像素为55052,非变化区域像素为174 324.从每组数据两幅不同时刻的影像中看出建筑物的尺度变化范围大,远处的建筑物边界十分模糊,在阴影地方建筑物与植被界限混淆在一起;同时车辆及电杆等地物也存在尺度范围变化大,与周围地物界限模糊的问题,天空不同天气的原因也造成像素不均匀,高亮区域和灰暗区域同时存在.

图4 G1和G2街景影像及参考图
2.2 实验设计
为了验证提出方法在街景影像变化检测中的有效性,设计了两组对比实验:1)采用提出方法与OTSU[13]和K均值[14]进行对比;2)采用Segnet、DeeplabV3+网络、Segnet+GC和本文方法进行对比.精度评价采用文献[15]中的错检率、漏检率和总体精度.
2.3 第一组对比实验
实验采用OTSU、K均值和本文所提出的方法,分别对G1和G2两组影像进行变化检测.G1和G2两组影像采用OTSU方法得到的结果图如图5(a)、图5(b)所示,采用K均值方法得到结果图如图5(c)、图5(d)所示,本文方法结果图如图5(e)、图5(f)所示.实验结果精度如表1所示.

图5 第一组对比实验结果图
结果表明两组数据采用本文方法得到的总体精度比OTUS分别高38%、41%,比K均值分别高31%、29%;结合错检率与漏检率来看,本文方法在漏检率方面虽然与其他两种方法差别不明显,但错检率方面远远少于另外两种方法;从结果图来看,本文方法错检及漏检区域都远远少于OTSU和K均值.其原因在于DeeplabV3+网络对街景影像的整体分类效果优于其他两种方法,同时GC方法有效减少了天空和植被等区域的错检.
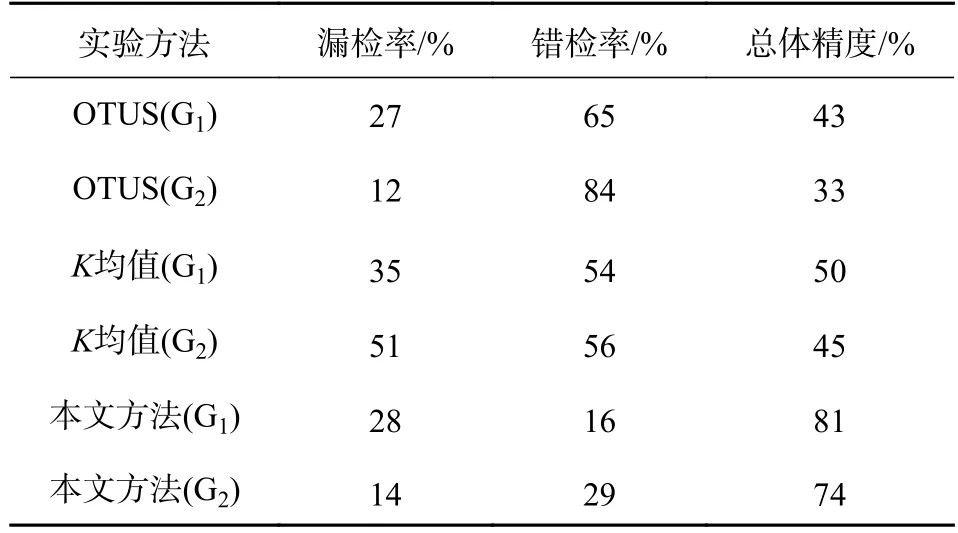
表1 实验结果精度对比
综上,本文方法相比OTSU和K均值,不仅变化检测效果优于OTSU和K均值,而且对街景影像的分类效果也优于OTSU和K均值,因此本文方法更适用于街景影像变化检测.
2.4 第二组对比实验
实验采用Segnet网络、DeeplabV3+网络、Segnet网络结合GC方法和本文方法,分别对G1和G2两组影像进行变化检测.G1和G2两组影像采用Segnet网络方法得到的结果图如图6(a)、图6(b)所示,采用DeeplabV3+网络方法得到结果图如图6(c)、图6(d)所示,采用Segnet网络结合GC方法结果图如图6(e)、图6(f)所示,本文方法结果图如图6(g)、图6(h)所示.实验结果精度如表2所示.
从实验结果精度来看,G1和G2两组街景影像采用本文方法得到的漏检率比Segnet网络方法分别低9%、25%,错检率比Segnet网络方法分别低36%、25%,总体精度比Segnet网络方法分别高30%、25%;对比DeeplabV3+网络方法,漏检率比DeeplabV3+网络方法分别高4%、低1%,错检率比DeeplabV3+网络方法分别低28%、18%,总体精度比DeeplabV3+网络方法分别高19%、13%.从实验结果图来看,本文方法在植被和天空类别的错检区域远少于Segnet网络方法和DeeplabV3+网络方法.
G1和G2两组街景影像采用本文方法得到的漏检率比Segnet网络结合GC方法分别低5%、14%,错检率比Segnet网络结合GC方法分别低4%、3%,总体精度比Segnet网络结合GC方法分别高4%、7%;从精度结果来看,本文方法虽然在漏检率和总体精度上比Segnet网络结合GC方法具有一定的优势,但错检率上不存在明显差别.结合结果图来看,也未具有明显的差距.但从DeeplabV3+网络与Segnet网络的分类图可以看出,DeeplabV3+网络不仅对汽车、树木等小尺寸地物具有很好的识别能力,同时边缘细节也优于Segnet网络.

图6 第二组对比实验结果图

表2 实验结果精度对比
综上,本文方法相比Segnet网络和DeeplabV3+网络能有效降低错检率,同时提升变化检测精度,而相比Segnet网络结合GC方法,本文方法得益于空洞卷积及ASPP的优势,比具有传统卷积的Segnet网络更加适合街景数据变化检测,也更加具有发展潜力.
3 结论
针对多时相街景影像变化检测,提出了一种结合DeeplabV3+网络模型和GC的变化检测方法.为了验证提出方法,设计了两组对比实验,实验结果表明提出的方法优于传统的统计方法、机器学习方法、未经改进的Segnet网络和DeeplabV3+网络模型.
实验利用迁移学习的方法对街景数据进行分类,但实际上这种未经过大量样本训练的神经网络泛化能力还有待加强,后续将通过对本数据集街景数据进行大量标注样本来重新测试网络,同时,对网络改进也将成为未来的主要工作.
