基于RISC-V 指令扩展的低开销SM4 算法设计与实现*
2021-03-23刘向东
陈 锐,李 冰,刘向东
(1.南京工业职业技术大学计算机与软件学院,江苏 南京210012;2.东南大学微电子学院,江苏 南京210035)
近年来,物联网(Internet of Things,IoT)已被广泛应用于各个领域,特别是在工业领域[1]。 越来越多的物联网设备被安装在车间、厂房、机械装置和工业装备上[2]。 工业物联网不仅提高了生产效率,而且降低了生产成本[3]。 随着联网设备的增多,物联网面临的安全问题也越来越严峻[4]。 造成这一问题的主要原因是三个。 首先,出于成本方面的考虑,物联网设备资源受限,无法提供先进的安全技术保障[5]。 其次,物联网设备数量的增多,导致探索潜在安全漏洞的机会增多。 最后,物联网设备产生、处理和交换大量对公共安全至关重要的数据以及对隐私敏感的信息[6],这些数据和信息对攻击者具有一定的吸引性。 一般而言,物联网设备采集的数据会通过网络传递到云端服务器进行分析和处理[7]。这些数据在传输过程中,可能被中间人篡改、删除,从而破坏了数据的完整性、可靠性和机密性。 考虑到这些数据可能对公共安全至关重要或者对隐私敏感,应该在传输数据之前,对这些数据进行加密处理。
对称密码算法可用于数据加密。 常见的对称密码算法有美国的AES 标准、中国的SM4 标准等。SM4(也称为SMS4)已成为中国国家标准,与AES相比,SM4 具有以下特点,使其更适合于资源受限的环境:(1)SM4 的安全特性等效于AES-128[8];(2)加密和解密的结构相同;(2)用于加密和解密的Sbox 相同;(4)轮函数仅需要4 个Sbox(每个具有256×8 位),而在AES 中则需要16 个。 SM4 算法的实现可以通过软件、硬件或者软硬协同的方式。 软件实现的性能较低,特别是对于性能和延时比较敏感的工业场景,软件执行引入的延时是难以满足工业场景对于性能和延时的需求。 因此,相关研究工作主要关注于硬件电路实现。 虽然SM4 算法本身已具备适合于资源受限环境的众多优势,但是考虑到物联网设备成本方面的因素,需要尽可能地降低SM4 算法硬件实现时带来的资源开销。 目前已经有不少参考文献致力于降低SM4 算法的硬件电路资源开销,比如基于复合域算术实现Sbox[8-9],降低了Sbox 导致的资源开销;基于异步多米诺逻辑实现SM4[10],降低功耗的同时也降低了面积开销。 然而,从物联网设备成本方面考虑,SM4 算法硬件电路资源开销还需进一步地降低。
为了降低SM4 硬件资源开销,本文提出以软硬件协同设计的方式实现SM4 算法。 首先,分析了SM4 软件实现的性能瓶颈。 其次,基于软件分析结果,在开源指令集RISC-V[11]的基础上,提出了两条自定义指令,分别用于实现SM4 算法的加解密算法和密钥扩展算法的轮函数。 最后,提出一种复用RISC-V 处理器寄存器资源的方法,以减少SM4 存储资源开销,并设计了一款低开销的SM4 指令功能单元电路结构。 实验结果显示,相对于软件实现的性能,本文方法能够将吞吐率提升4.47 倍,延时缩短81.72%。 在SMIC 180nm 工艺下的综合结果显示,与参考文献相比,本文方法的硬件资源开销至少降低38.9%。
1 SM4 算法简介
该算法由加解密算法(如图1(a)所示算法1)和密钥扩展算法(如图1(b)所示算法2)两部分组成,分组长度和密钥长度均为128 bit。 加解密算法与密钥扩展算法均采用32 轮非线性迭代结构。 从算法1 可以看出,加密算法和密钥扩展算法都需要32 轮的计算才能得到最终结果,因而每轮计算所消耗的时间决定了整个算法所消耗的时间。 为了评估SM4 软件实现的性能,本文以Linux 内核中的SM4算法源代码为基础,在一款商业级的开源RISC-V处理器SCR1[12]上运行,以获取时钟周期精确的仿真结果,然后对其进行了性能剖析。

图1 SM4 加密算法和密钥扩展算法
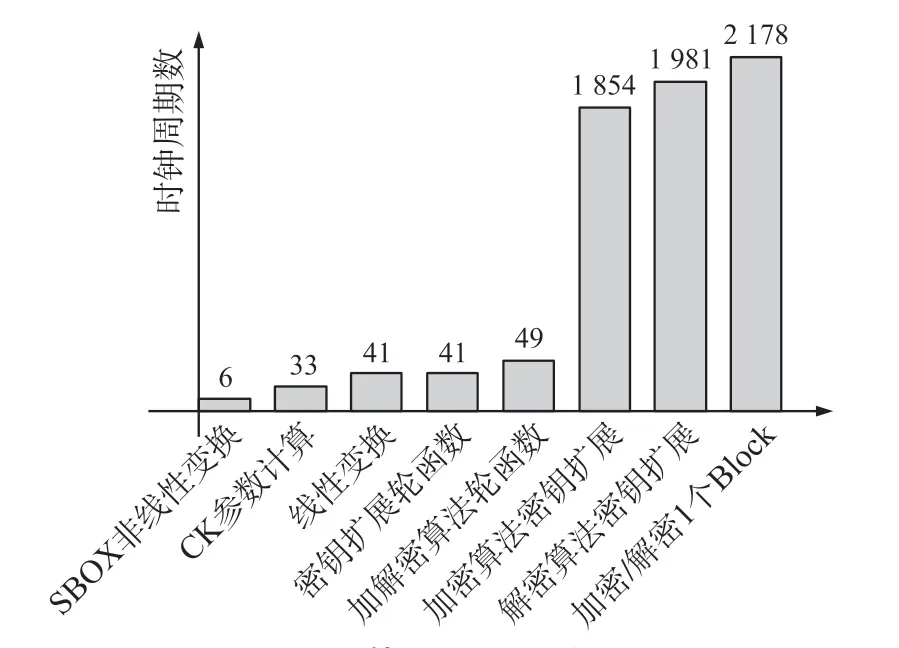
图2 SM4 算法子函数性能分析
分析结果如图2 所示,仅通过Sbox 完成一个字节的非线性变换就消耗了6 个时钟周期,而密钥扩展和加密算法轮函数的单次迭代分别需要41 和49个时钟周期。 值得注意的是,完成32 次轮函数迭代,密钥扩展和加解密分别需要1 802 和2 178 个时钟周期,而这两个值并不等于41×32 和49×32。 造成这一现象的主要原因是,每次轮函数的迭代都需要通过多个访存指令从存储器中将数据载入到寄存器中。 基于上述的分析,得出的结论是,为了消除SM4 软件性能瓶颈,提升SM4 性能,降低时延,必须做到:(1)降低Sbox 非线性变换消耗时间;(2)降低轮函数单次迭代消耗时间;(3)减少轮函数中的访存指令以减少访问存储器消耗时间。
从算法1 中的4~7 行和算法2 的3 ~7 行可以发现,轮函数中包含的运算较多,如果能将这些运算通过一条指令完成,则可以达到降低轮函数单次迭代消耗时间的目的,而Sbox 非线性变换已然包含在轮函数中了,因此上述结论(1)也可以通过扩展指令来消除或掩盖。 考虑到开源指令RISC-V 指令集定义了32 个通用寄存器,如果能够借用部分通用寄存器用于存放加解密或者密钥扩展算法运算过程中产生的中间数据,则可以减少不必要的存储器访问从而消除存储器访问消耗时间。
2 RISC-V 指令扩展
基于上述的分析,依据开源RISC-V 指令规范,本文定义了两条自定义指令,SM4.KEY.RF 和SM4.ENC.RF。 扩展指令SM4.KEY.RF 用于实现密钥扩展算法轮函数单次迭代中所有运算,包括异或、Sbox 非线性变换、线性变换,如算法2 中4 ~7 行所示。 扩展指令SM4.ENC.RF 用于实现加解密算法轮函数单次迭代中的所有运算,如算法1 中4 ~7 行所示。 二者指令编码格式如图3 所示。 依据RISC-V指令规范,选取7 位二进制数0001011 作为SM4 扩展指令的操作码,以便于与其他类型指令进行区分。在扩展指令SM4.KEY.RF 中,目标寄存器由编译器决定,可以为任意寄存器,源寄存器只需要1 个,用于载入CK 参数。 在扩展指令SM4.ENC.RF 中,将指定目标寄存器为x28,以减少不必要的存储器访问,而源寄存器用于载入密钥扩展算法生成的轮密钥。

图3 本文提出的两条RISC-V 扩展指令
3 低开销SM4 指令功能单元结构设计
依据两条扩展指令的功能,本文设计了一款低开销的SM4 指令功能单元,并对RISC-V 处理器的寄存器堆的电路结构进行了修改,具体结构如图4所示。 从图4 可以看出,SM4 指令功能单元有6 个输入和1 个输出端口,其中5 个输入用于传递轮函数单次迭代所需的数据,而这5 个输入直接从寄存器堆引入。 需要注意的是,这5 个从寄存器堆直接引入的输入,有4 个是固定连接到某一个寄存器,剩余1 个由指令传递的rs1 选取。 之所以这样设计,主要原因有3 个:(1)由于轮函数单次迭代需要5个32 位的数据,固定连接寄存器后,数据直接从寄存器中读取,无需等待,提升指令执行效率;(2)借用处理器的4 个通用寄存器存放轮函数每次迭代产生的临时数据,无需再通过存储器访问指令从存储器中载入数据,减少访问存储器次数,缩短算法延时;(3)轮函数计算结果直接写入固定寄存器,无需编译器指定存放位置,省去读取寄存器时间,提升指令执行效率。
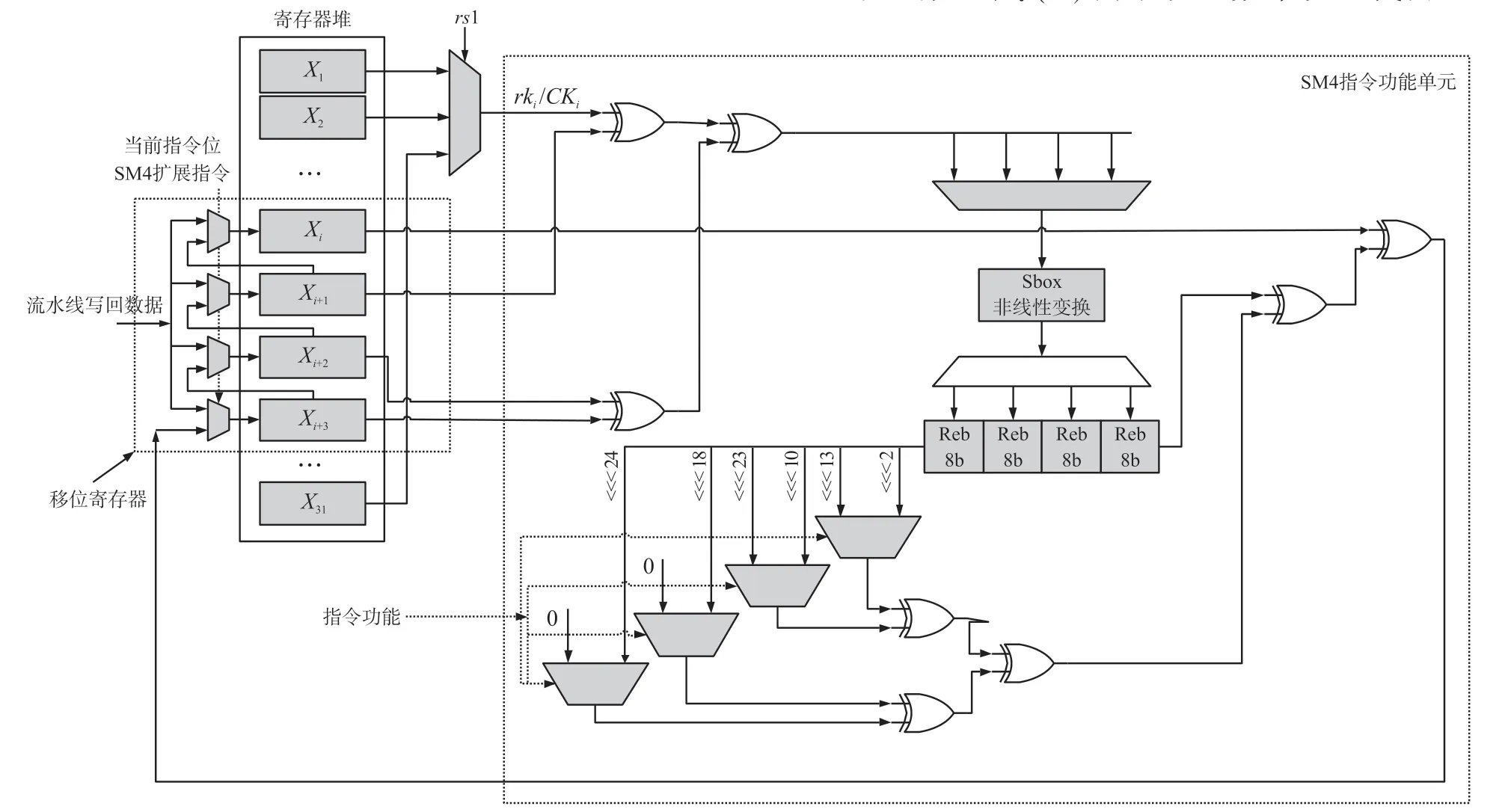
图4 本文提出的SM4 指令功能单元
如图4 所示,当处理器执行到SM4.ENC.RF 或者SM4.KEY.RF 指令时,寄存器堆中的寄存器t0-t3构成移位寄存器,数据可以从t3移入,然后通过移位从t0移出。 之所以这样设计,是为了在轮函数单次迭代结束之后,能够自动进行为移位,为下一次的迭代准备数据,从而不需要再通过指令从其他位置加载数据,因而可以提升效率。
3.1 软硬件协同工作
SM4 指令功能单元仅完成轮函数单次迭代计算,完成整个加密算法或者密钥扩展算法,还需要软件的配合,软件主要负责算法流程的控制。 为了节省扩展密钥所占用的资源开销,本文不采用在线密钥扩展,而是在加解密之前预先执行密钥扩展算法,并将生成的32 个32 位的扩展密钥存放到数据存储器中。 如图5(a)所示,在调用SM4.KEY.RF 指令进行密钥扩展之前,需要先将128 位的用户密钥存放到指定的4 个寄存器中,然后才能开始循环迭代。每次迭代都会生成一个32 位的轮密钥,这些密钥交由编译器指定存放位置。 在32 个轮密钥生成完毕之后,可以开始数据加解密。
如图5(b)所示,在调用SM4.ENC.RF 指令进行加解密之前,需要先将128 位的明文或者密文存放到指定的4 个寄存器中,然后才能开始循环迭代计算。 每次迭代均会先载入一个轮密钥,然后执行SM4.ENC.RF,每次迭代计算的结果直接写入到寄存器t3(x28),32 次迭代结束之后,直接从寄存器t0-t3读取数据即可。
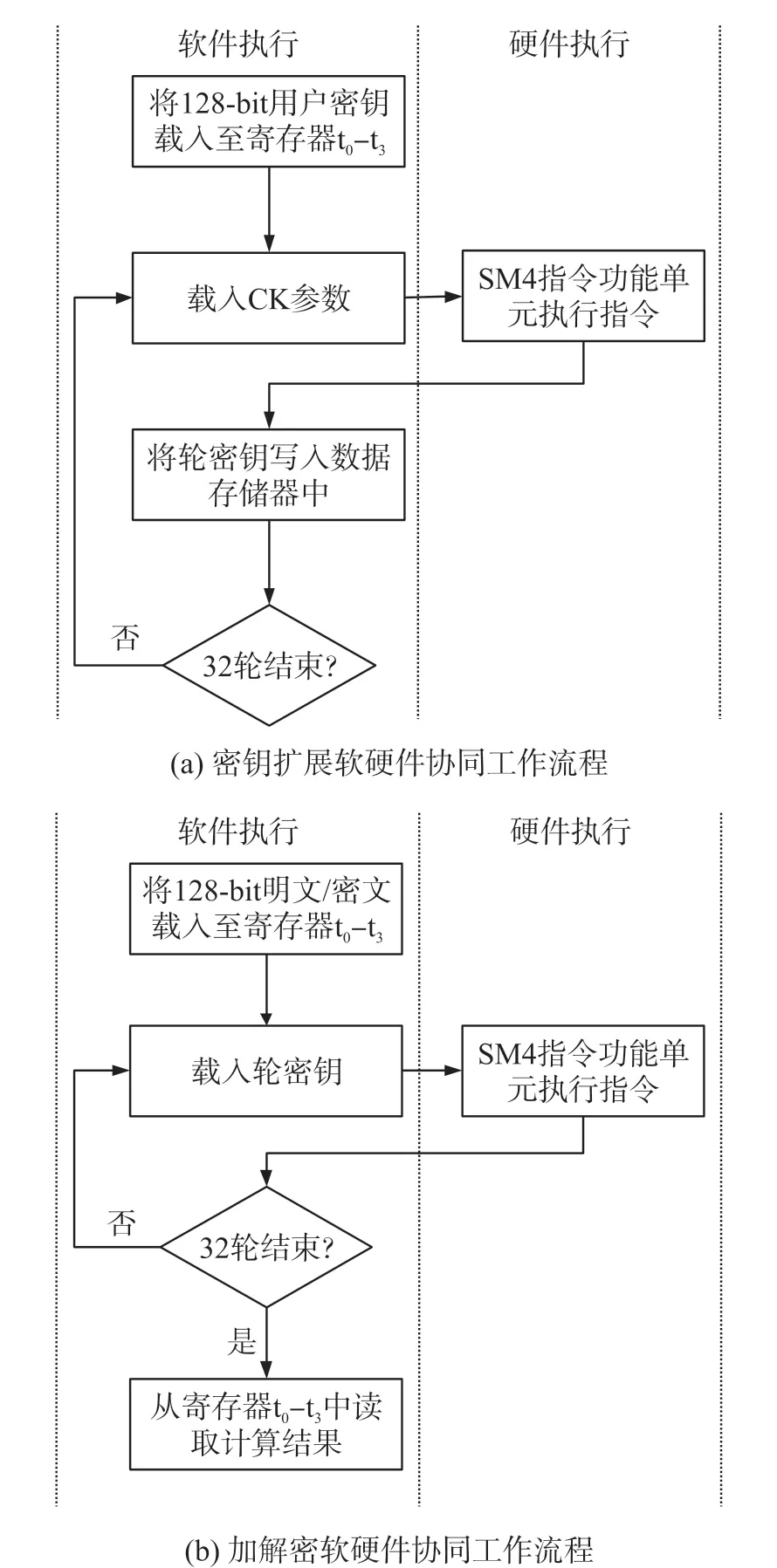
图5 SM4 算法软硬件协同工作流程
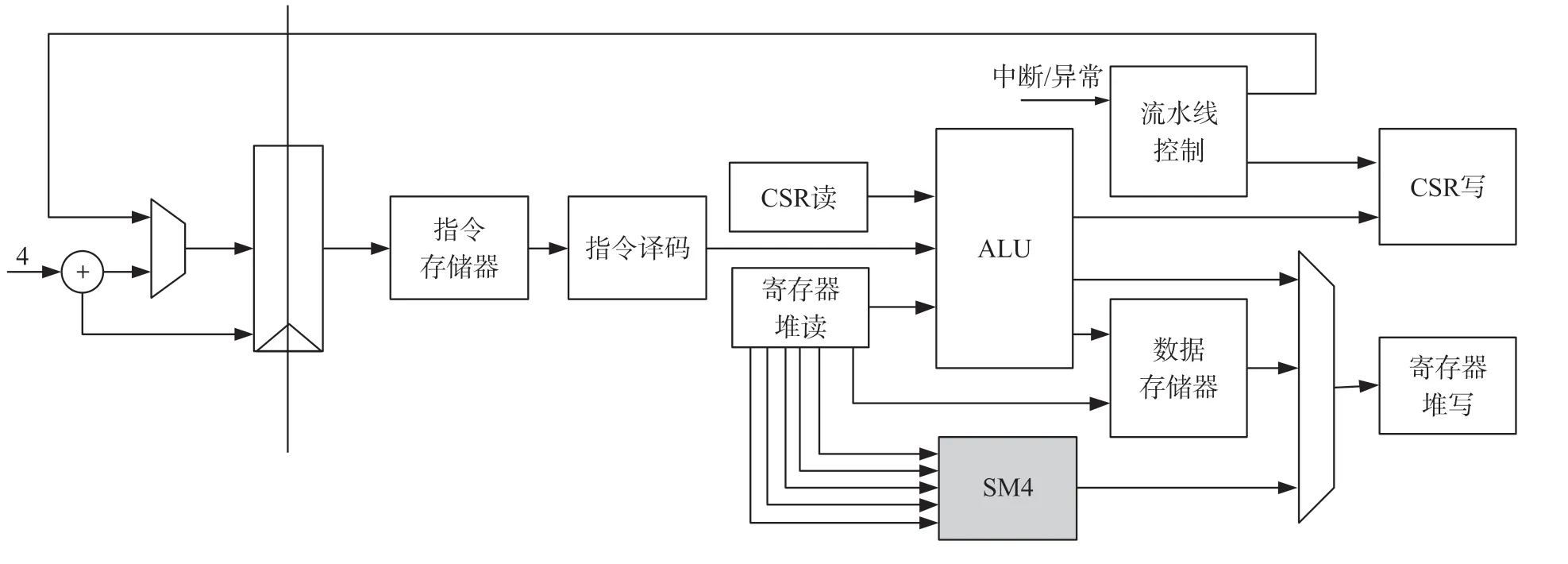
图6 SM4 指令功能单元嵌入到开源RISC-V 处理器SCR1 中
4 实验与结果分析
为了验证扩展指令的功能,评估指令功能单元的资源开销,本文采用Verilog HDL 对其进行了描述,然后将其集成到商业级开源RISC-V 处理器SCR1 中。 如图6 所示,SCR1 配置成了二级流水线结构,而SM4 指令功能单元嵌入到流水线的第二级,与算术运算单元ALU 处于同一个流水级。
4.1 面积开销
为了评估资源开销,本文将未修改的SCR1 以及修改之后的SCR1 分别以100 MHz 的时钟频率在SMIC 180 nm 工艺下,通过Synopsys Design Compiler进行综合,综合结果如表1 所示。 从表1 可以看出,SM4 引入的硬件资源开销只有1684 等效门。
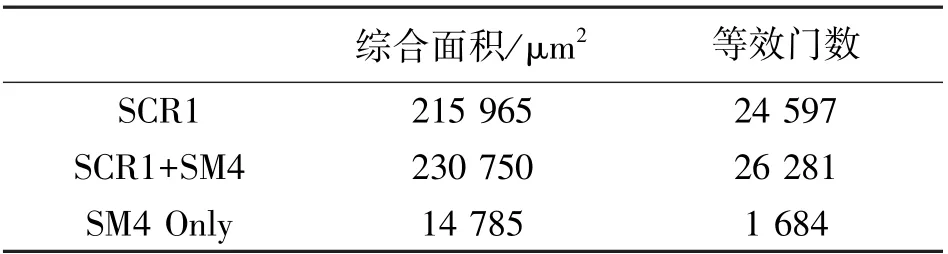
表1 SMIC 180nm 工艺下的100MHz 综合结果
4.2 性能表现
为了评估性能,本文将SM4 算法分别采用有指令集扩展和没有指令集扩展的方式进行软件实现,并通过RISC-V 处理器提供的CYCLE 计数器对算法消耗的时钟周期数进行计数。 软件实现通过修改之后的RISC-V GCC 交叉编译器进行编译,然后将编译输出的Hex 文件以测试激励的方式载入到Synopsys VCS 仿真平台,以获得时钟周期精确的仿真结果。 如表2 所示,添加指令集扩展之后,密钥扩展、加密和解密所需的时钟周期分别缩减了81.72%、87.69%、82.40%,而吞吐率分别提升了4.47 倍、7.12倍和4.68 倍。
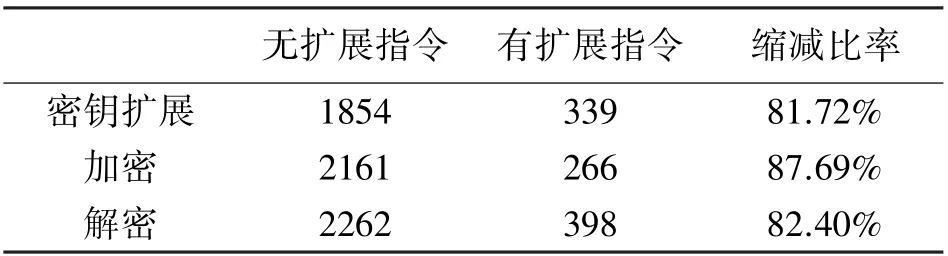
表2 有/无扩展指令延时(时钟周期)对比
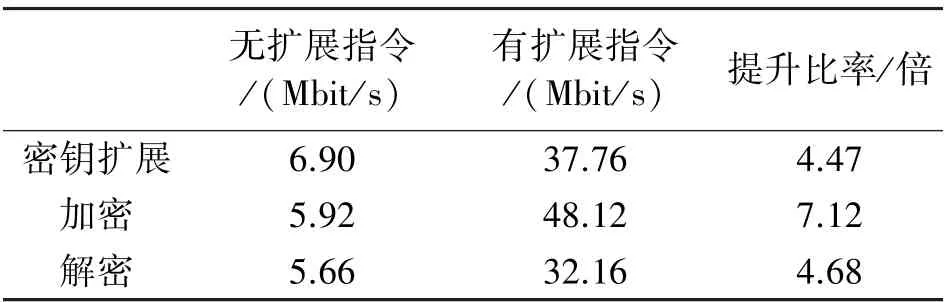
表3 有/无扩展指令100 MHz 时钟频率下的吞吐率对比
4.3 与参考文献的对比
表4 罗列了本文与参考文献的比较结果。 虽然本文在延时和吞吐率方面的优势都不明显,但是面积和等效门数优势突出,造成这一现象的主要是原因各个设计的设计目标可能不一致,比如文献[13]瞄准的是高吞吐率,而本文的设计目标是低开销。从表4 中数据可以看出,与参考文献相比,面积开销(等效门数)至少降低38.9%。
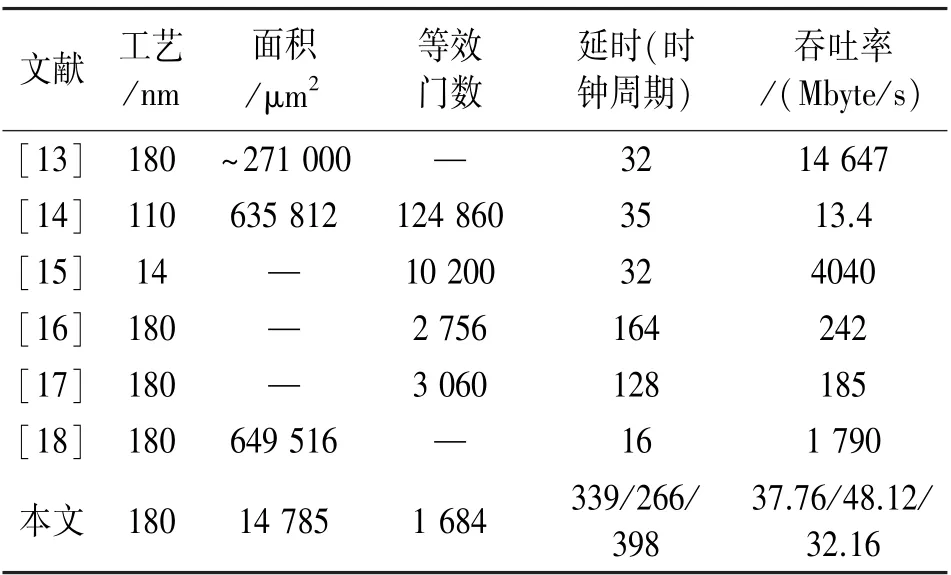
表4 与参考文献资源开销的比较结果
5 总结
面向低成本物联网终端领域数据加密需求,针对SM4 算法,本文基于开源RISC-V 指令集,提出了两条SM4 扩展指令,设计了一款低开销的SM4 指令功能单元硬件电路结构,以软硬件协同工作的方式实现SM4 密钥扩展算法和加解密算法,并在性能和硬件资源开销之间取得平衡。 本文提出2 条扩展指令分别用于实现SM4 密钥扩展算法和加密算法轮函数中的所有运算。 从时钟周期精确的仿真结果来看,与无扩展指令的实现方式相比,延时至少降低81.72%,吞吐率至少提升4.47 倍。 从SMIC 180 nm工艺下的综合结果来看,与参考文献相比,硬件资源开销至少降低38.9%。 本文提出的方法能够兼顾性能和资源开销,因而较为适合于资源受限成本低廉的物联网场景。
