一种基于纠删码的多节点失效修复算法
2021-03-23徐家冰朱浩辰
徐家冰,朱浩辰,杨 丽
(中国农业大学烟台研究院,山东 烟台 264670)
0 引 言
随着数据规模的不断增长,存储系统的规模不断扩大,过于庞大的规模使得节点失效成为常态,据统计,大型分布式存储系统中平均每天有1%~2%的节点失效[1],因此,如何在节点失效的情况下保障数据完整性以及迅速有效地修复失效节点变得十分重要。目前,数据完整性保障主要依靠多副本[2]和纠删码[3]技术来实现,后者能够以较低的存储开销获得更高的数据可用性[4-5],但修复成本较高,因此,如何降低纠删码重构所占网络资源并提高修复速率来提高纠删码性能具有重要研究价值。
纠删码中,传统的数据修复方法通常采用的是星型的数据传输方式,供应节点直接将数据发送给新生节点,所有参与修复的节点构成一个以新生节点为中心的星型结构。星型数据修复方法简单直观,但存在严重的性能瓶颈。Li等[6-7]提出了树型修复方法,以新生节点为根节点,提供者节点为叶节点,并从叶节点开始逐级向上传输数据,直到达到根节点。而树型修复方法能够提高数据传输效率,但并不能很好地保证数据完整性。实际使用中,分布式存储系统通常采用“延迟修复”的策略[8-9],即仅在失效存储节点的数目达到某阈值时,才启动对失效节点的修复。此时,传统的星型和树型修复方法不再最优,并且随着系统中节点的规模持续扩大,失效数据的修复代价将不断提高。
为解决星型和树型修复方法的不足,Dimakis和Vajha等[10-11]提出了优化修复带宽的再生码,在保持MDS性质同时,引入网络编码,通过选取较多的节点参与修复过程,以降低带宽的消耗,但该算法中新生节点只能使用部分链路,可能会浪费带宽较高的链路资源,导致修复效率较低。而Gong等[12]则提出了SPSN算法,通过遍历所有链路带宽,在d个供应节点和1个新生节点组成的所有可能的修复拓扑结构中,寻找最小链路且带宽最大的拓扑结构来降低修复时间,但该算法具有串行贪心选择的特征,会给系统带来巨大的时间和空间开销。Sun等[13]提出了边缘不相交算法和边缘共享算法,通过避开上次节点修复的瓶颈带宽链路来降低修复时间,但是当多节点失效时,后期修复成本代价会越来越高,且与实际情况不符。
多节点失效问题同样引起了广大学者的关注。而为解决多节点的修复,Kenneth等[14]提出了一种多节点合作修复方法,通过对纠删码中的节点数据进行分块,以完成修复过程,与单节点修复相比,合作修复消耗带宽更少,但编码过程复杂。而基于星型结构的串行修复方法[15](Serial Repair Strategy Based on Star Structure, SSR)和基于树型结构的串行修复方法[16](Serial Repair Strategy Based on Tree Structure, TSR)也被陆续提出,以串行修复多失效节点,但其效率较低且数据传输负载大。刘佩等[17]提出了B-WSJ算法,以解决新生节点间的数据传输问题,但会增加修复时间。郑力明等[18]根据节点间网络距离,选择总距离最小的中心节点以提高修复速率,但并未考虑中心节点的性能和网络的实时变化。
因此,针对现有纠删码技术存在的不足,本文提出一种基于纠删码的多节点失效修复算法(Multi-node Failure Repair Algorithm Based on Correction Code, MFREC)。该算法依据新生节点计算能力,选择负责接收、计算数据并传输的中心节点;同时考虑了供应节点与中心节点间的可用带宽、中心节点与其它新生节点之间的可用带宽,在存活节点中选择带宽较大的节点作为供应节点,并生成最大可用带宽修复树。实验表明,与星型修复算法SSR和系统默认随机节点选择修复方法BHS(Blind Helper Selection)相比,MFREC算法可有效提高修复速率,其多节点的修复性能更强。
1 传统的纠删码技术
通常纠删码可用三元组(n,k,d)表示。(n,k,d)-纠删码将原始数据划分为k个大小相同的数据块,通过特定的编码原理对k个原始数据块编码,生成n(n>k)个大小不变的编码块,使得其中任意d(d≥k)个编码块通过解码算法就能恢复原有数据或修复失效数据。以(4, 2, 2)纠删码为例,原始文件被分为4个块A、B、C、D,通过编码生成8个数据块,每2块按照文件布置策略存放到4个存储节点中。鉴于文件存储具有MDS性质,即任取拓扑中2个节点上的数据可以将源文件完整复现,因此,所用文件存储模型可以容忍2个节点失效。
在某个时间点,节点2和节点4上的数据失效,修复阈值r=2,此时系统开始数据修复。传统修复方法主要有BHS和SSR等修复方法,如图1所示,随机选择节点5和节点7作为新生节点,供应节点为节点1和节点3,每个新生节点需要从2个供应节点下载数据。每个供应节点需要向2个新生节点传输所存储的所有数据,且BHS修复方法和SSR修复方法仅考虑供应节点和新生节点之间的带宽选择,并未考虑新生节点之间的带宽选择,为后续多节点修复过程造成性能瓶颈;并且BHS修复方法和SSR修复方法为串行选择节点,使得数据再生过程中产生并传输了许多冗余信息,增加了网络的负担,降低了修复效率。
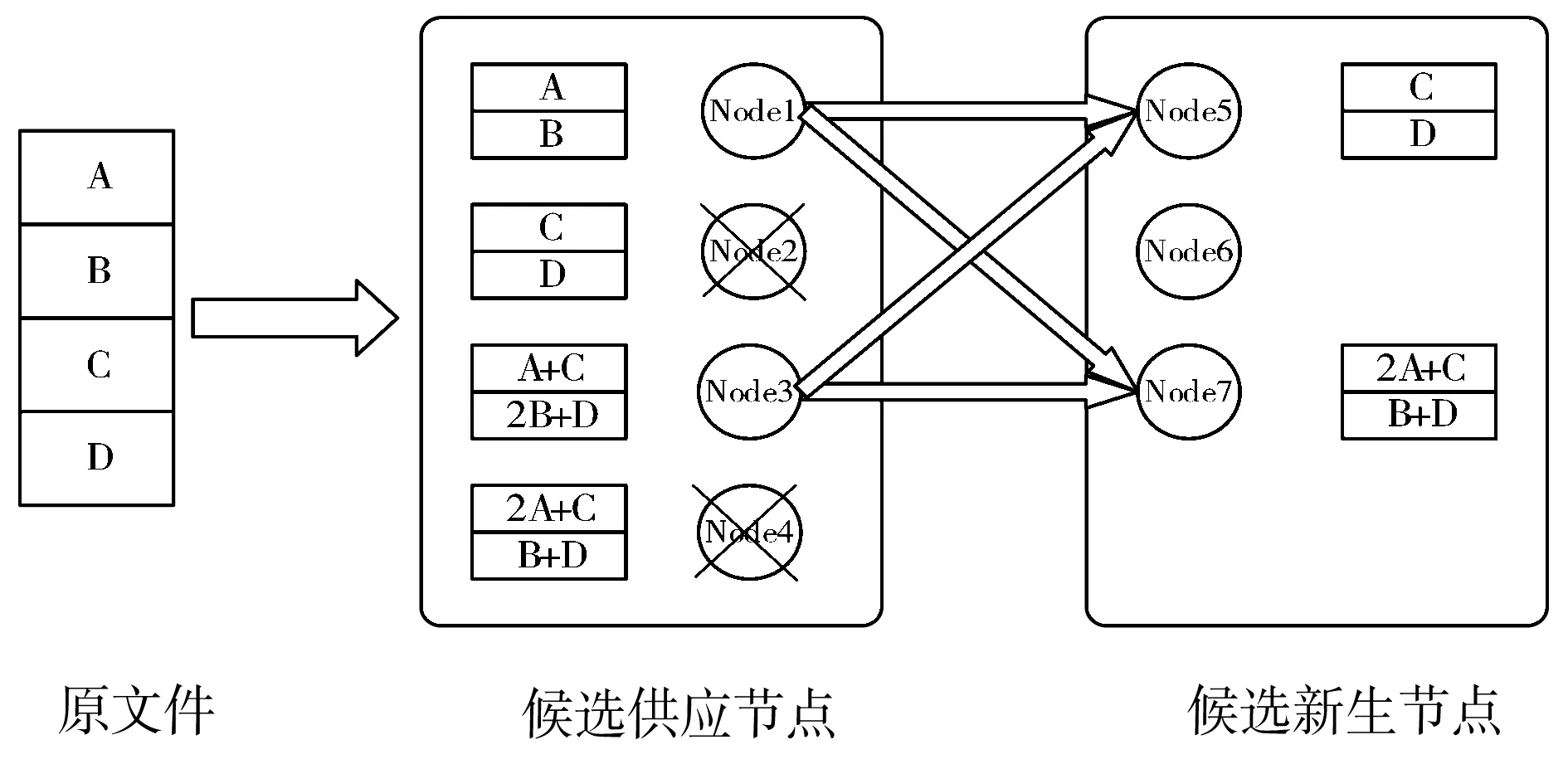
图1 传统修复方法
2 MFREC算法及分析
MFREC算法主要由中心节点选择策略和供应节点选择策略构成,即首先在中心节点的选择阶段,根据新生节点计算能力,选择出中心节点;其次在供应节点的选择阶段,考虑供应节点与中心节点间的可用带宽、中心节点与其它新生节点之间的可用带宽,提出一种最大修复树算法(Maximum Bandwidth Repair Tree, MBRT),以生成最大可用的带宽修复树,最终完成对多失效节点的修复。下面将详细介绍中心节点选择策略和供应节点选择策略。
2.1 中心节点选择策略
在分布式存储系统中,各个存储集群以及同一存储集群中的各个节点的性能并不完全相同,甚至可能有较大的差异,这就会导致存储节点计算能力的差异。因此,本文的中心节点选择策略为:首先依据主要决定因素去初始化节点的计算能力,并在每次重构完成后,将新的数据处理时间以加权形式与节点原数据处理时间求和,以更新节点的计算能力,进行中心节点的选择。由于该策略是基于节点的性能来进行选取,所以不会改变节点的物理分布,即不改变纠删码系统的数据分布。其具体过程如下:
假设编码方案为(n,k,d),系统修复阈值为r,即当系统中累计有r个节点失效时,开始进行修复工作。系统网络中一共有N个节点,则需要在N-n个节点中选择r个空闲节点作为新生节点。由于存活节点承担数据读取及数据传输等功能,负载较大,因此本文在新生节点中选择中心节点。
首先根据空闲节点的计算能力选择出中心节点,并选取磁盘I/O、CPU核数、主频和内存这4个决定性因素作为节点计算能力来初始化公式的参数。将这4个因素用x1~x4表示,并分配相应的权重ω1~ω4,可以对其中更加重要的因素分配较大的权重,ω1+ω2+ω3+ω4=1。每个节点Ni的计算能力Ci初始化为:
(1)
假设节点Ni在重构过程中的计算量为Qi,则Ni对编码块的读取、解码以及转发等一系列处理时间可以表示为:
(2)
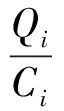
记最近一次重构时数据的处理时间为T,单位为s,权重为β1。节点Ni目前记录的数据处理时间为Ti,权重设为β2,其中β1+β2=1。将Ti的值更新为Tupdate,继续在下一次重构结束之后参与Tupdate的计算,更新公式可以表示为:
Tupdate=β1T1+β2T2
(3)
这样节点Ni的计算能力就能以数据处理时间来度量,数据处理时间越短,节点计算能力越强,反之节点计算能力越弱。选取具有高节点计算能力的节点作为中心节点时,可以提高重构效率。
2.2 供应节点选择策略
在中心节点选择完成后,需要确定向其传输数据的供应节点。各节点之间链路带宽一般通过数据中心的主节点获取,并且只需2~4个往返时延,该时间相对于再生修复的时长来说可忽略不计[20]。且已有相关研究表明,未来带宽大小与历史带宽大小是相关联的,即在很短时间内带宽大小变化很小[21]。故而,可假设系统中的主节点获取的链路带宽大小在修复时间内保持不变,且修复过程中每个节点之间传输的数据量均为b。本节根据节点间的可用带宽,提出一种最大修复树算法,通过选取拥有较高可用带宽的存活节点作为供应节点来参与修复,并将其作为MFREC算法中的一个重要步骤,从而使MFREC算法具备更强的多失效节点修复能力。下面将对本文所提的供应节点策略作详尽介绍。
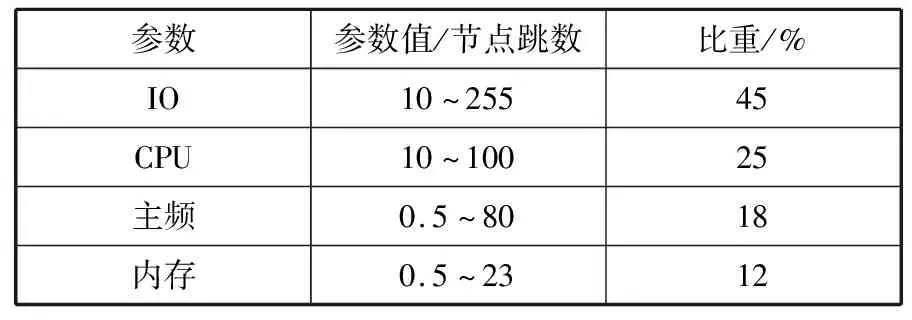
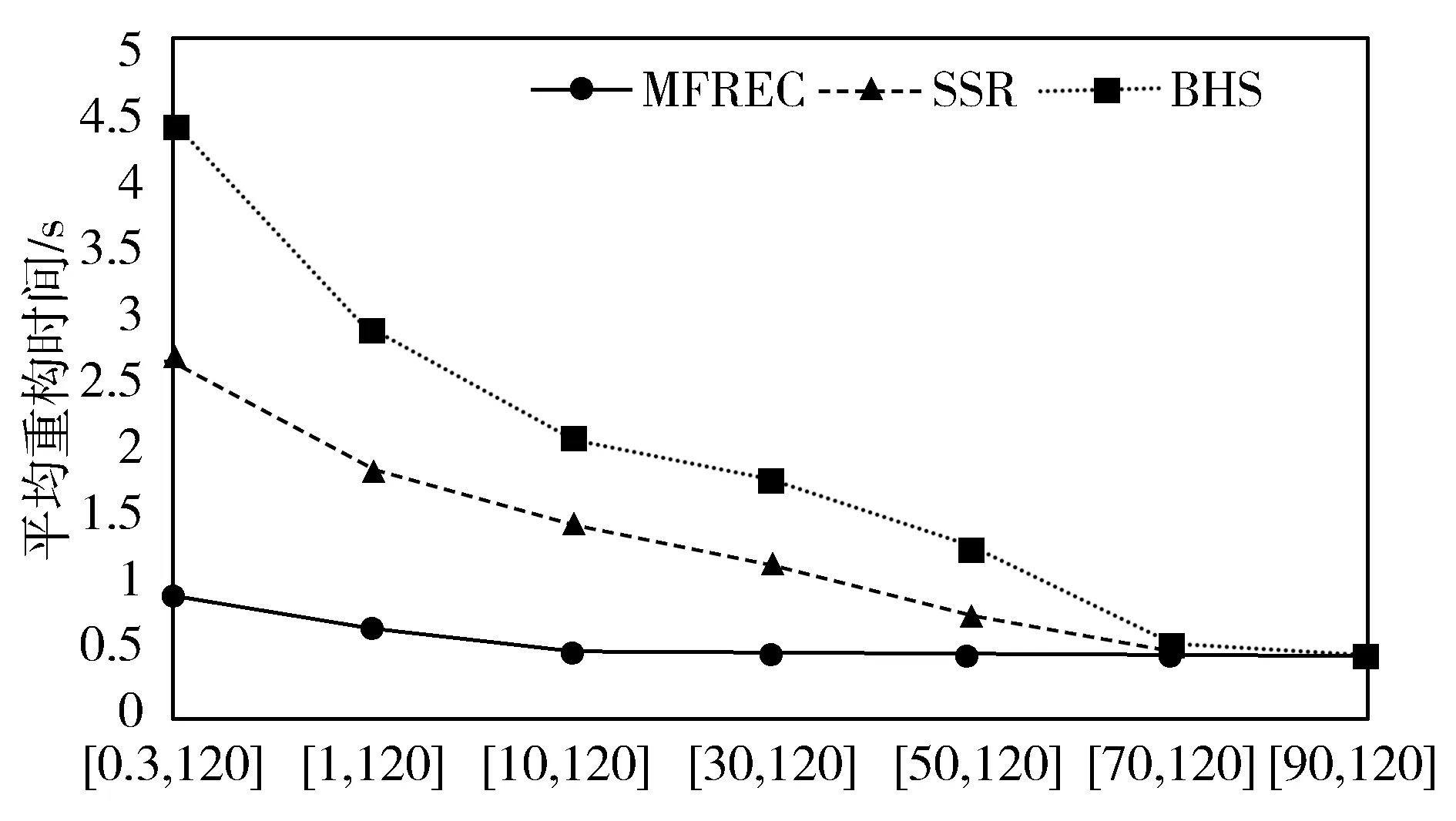
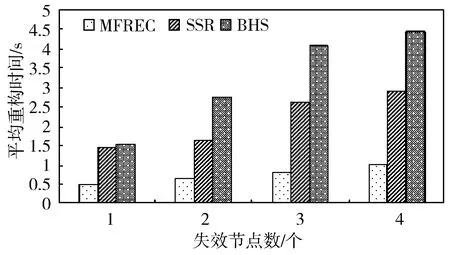
不失一般性地,以N={N0,N1,…,Nn-r}表示中心节点与候选供应节点组成的集合,其中N0表示中心节点,N0,N1,…,Nn-r表示候选供应节点。边集E={(Ni,Nj)|i,j=0,1,…,n-r,i 通过引入N′和E′,分别存放参与修复的供应节点和中心节点间的传输链路。由于最大重构树要以N0为根节点,因此初始时N′={0},0表示节点N0,E′=Φ。为了便于在集合N′和N-N′之间选择权值最大的边,可以建立2个数组NODE和WEIGHT。NODE[i]表示N′中的一个节点,该节点和N-N′中的一个定点构成的边(i,NODE[i])具有最大的带宽;WEIGHT[i]表示边(i,NODE[i])的权值。初始时,由于N′的初值为{0},因此NODE[i]的值为0,i=1,…,n;而WEIGHT[i]为边(0,i)的权,i=1,…,n。 算法的每一步扫描数组WEIGHT,在N-N′中找出与N′有最大带宽的节点,令其为k,并输出边(k,NODE[k])。然后修改数组NODE和WEIGHT,标记k已加入N′,直到N′中有d+1个节点结束,而不是遍历所有候选供应节点。用M表示图的邻接矩阵,M[i][j]是边(i,j)的权,方向由i到j。如果不存在边(i,j),则M[i][j]的值为一个大于任何权值而小于无限大的常数。MBRT算法过程如算法1所示。 算法1供应节点的最大生成树选择算法 输入:网络带宽图G=(N,E),其中N={0,1,…,r} 输出:供应节点和中心节点生成的最大修复树 1: void XX(int M[r + 1][r + 1]){ 2: int WEIGHT[r + 1]; 3: int NODE[r + 1]; 4: int i, j, k; 5: int max; 6: for(i = 1; i <= r; i ++){ 7: WEIGHT[i]= M[i][0]; 8: NODE[i]= 0; 9: } 10: for(i = 1; i <= r; i++){ 11: max = WEIGHT[i]; 12: k = i; 13: for(j = 1; j <= r; j ++){ 14: if(WEIGHT[j]> max){ 15: max = WEIGHT[j]; 16: k = j; 17: } 18: println(k +“,” + NODE[k]); 19: } 20: WEIGHT[k]= infinity;//k加入N′ 21: for(j = 1; j <= r; j++){ 22: if(M[j][k]> WEIGHT[j]&& WEIGHT[j]!= infinity){ 23: WEIGHT[j]= M[j][k]; 24: NODE[j]= k; 25: } 26: } 27: } 其他新生节点选取方法与供应节点选取方法类似。以中心节点为起点,在候选新生节点集合中选择与中心节点有最大可用链路带宽的候选新生节点为新生节点,从候选集合中删去该点,并将其加入中心节点和新生节点的集合,然后继续选择与新生节点和新生节点带宽最大的候选新生节点为新生节点,直到选出r-1个新生节点为止,从而生成完整的修复树。 以(8, 4, 4)-纠删码为例,通过模拟节点间的带宽,具体介绍MBRT节点选择方法的实现过程。以N1~N5表示存活节点,以N6~N9表示空闲节点,则用公式(4)所示矩阵来表示各节点之间带宽的邻接矩阵,每一项表示从横坐标节点到纵坐标节点的带宽大小,节点到自身和节点到节点间无连接用带宽0表示。 (4) 当有3个节点失效时,修复阈值r=3,系统开始进行数据修复,在空闲节点中选择3个节点作为新生节点来存放恢复后的失效数据,如图2所示为节点间的带宽示意图。 图2 (8,4,4)-纠删码节点选择示意图 图3展示了MBRT方法节点选择的过程。首先根据新生节点计算能力,选出节点7为中心节点(步骤1)。然后根据候选供应节点与中心节点间可用链路带宽大小,通过MBRT节点选择方法,依次选择节点3、节点2、节点1和节点4作为数据修复的供应节点(步骤2~步骤5)。根据中心节点与候选新生节点间可用网络带宽,依次选择出节点8、节点9作为新生节点(步骤6~步骤7),完成修复树的构造。 图3 (8,4,4)-MBRT方法节点选择示意图 通过MBRT方法构成了以Node3为根节点(中心节点),以Node1、Node2和Node4为供应节点,Node7、Node8和Node9为新生节点的MBRT修复树,如图4所示。 图4 MBRT修复树 MFREC算法在选定中心节点后,利用MBRT算法生成最大可用带宽修复树,以对多失效节点进行重构、修复,具备效率高、能同时对多节点进行修复等特点。 本章通过对比实验,分别设置不同带宽和失效节点个数,探究对MFREC算法与SSR和BHS修复方法性能的影响。 实验环境基于Facebook研发的HDFS-RAID[22]平台。该平台通过纠删码技术来改变原有的3个副本的冗余方式。实验设置17个DataNode、1个NameNode和1个RaidNode进行测试,其中DataNode负责数据的存储,NameNode负责管理HDFS的元数据,RaidNode负责编码以及数据的修复,并通过1 Gb/s的交换机连接所有节点。本文通过随机生成1 TB的数据,并将数据块划分成64 MB大小的数据块,通过编码将数据块划分到不同的条带上,通过随机断开节点的方式来模拟不同节点以及不同失效节点个数的情况。 针对节点计算能力的度量,实验选取存储节点的IO、CPU、主频和内存4个参数作为决定计算能力的变量,并在系统中获取每个变量的参数值。由于每个参数对数据修复的影响值不同,本文对每个参数设置不同的比重,其中因为数据传输时间消耗大,所以IO占比较大,故设置比重依次为45%、25%、18%和12%。通过对节点参数的对比选择出中心节点,各参数取值范围和比重如表1所示。 表1 节点参数 首先验证不同的网络带宽对MFREC和其它多节点修复方法性能的影响。以RS(8,4)编码策略为例,设置修复阈值为3,并选择不同的带宽范围进行实验,并取100次实验结果的平均值作为最终结果。实验分别在网络拓扑中带宽均匀分布范围为[0.3,120],[1,120],[10,120],[30,120],[50,120],[70,120],[90,120]情况下进行,结果如图5所示。 从图5可以看出,在带宽范围变化较大的情况下,现有的节点选择方法性能急剧下降。当带宽分布为[0.3,120]时,MFREC修复方法比SSR修复算法提高了66.67%,比BHS修复算法性能提高了79.31%。在带宽变化比较平稳时,MFREC修复性能有显著提高,即带宽分布为[50,120]时,MFREC修复算法比SSR算法提高了40%、比BHS算法提高了64%,在带宽变化较小时,本文修复算法的修复性能也有一定提升,即带宽分布为[70,120]时,MFREC算法性能比SSR提高了6.25%、比BHS提高了13.46%。 图5 不同带宽分布下不同修复方法的性能 为验证失效节点个数对各修复方法性能的影响,在不同失效节点个数的情况下进行实验。同样以RS(8,4)编码策略为例,设定带宽分布为[90,120],保证带宽不是实验的决定性影响因子,在保证失效数据能恢复的前提下,设定失效节点个数分别为1、2、3、4。图6结果表明,随着失效节点个数的增加,SSR修复方法和BHS修复方法的性能越来越差,MFREC修复方法性能最优。由于SSR修复方法为串行修复,虽然结构简单,但是传输冗余较大,当失效节点个数增多时性能不佳。BHS修复方法虽然改进为随机选择节点,但是稳定性较差,所以平均性能不佳。 图6 不同失效节点数目下不同修复方法的性能 分布式存储系统通过纠删码技术来降低存储开销同时保证数据的可用性与可靠性,由于很多信息知识库在失效节点达到设定阈值时,才开始进行失效数据的修复。本文针对多节点失效情境,提出了一种MFREC修复算法,通过选举中心节点,并根据MBRT方法生成最大可用生成树。本文方法修复性能较传统的SSR和BHS方法提高了6.25%~79.31%,其修复效率得到了明显改善。


3 实验验证
4 结束语
