集成学习思想预拟合分类算法
2021-03-23张跃,赵佳,胡明
张 跃,赵 佳,胡 明
(长春工业大学 计算机科学与工程学院,吉林 长春 130012)
0 引 言
随着大数据技术的发展,大数据时代已经到来[1-3]。而大数据的分类一直是大数据研究的热点问题[4-6],常用的分类算法有:朴素贝叶斯(naive bayes)、支持向量机(SVM)、k-近邻算法(KNN)、神经网络(ANN)和决策树,其中决策树凭借结构简单、计算复杂度低、对数据缺值不敏感等优点被广泛应用。它主要依靠每个节点上的属性对划分到该节点中的样本集合进行继续划分,最终落到对应各个决策结果的叶子节点中。即每一个决策树的根节点都包含了所有的样本,每个叶子结点对应着一个类别。但是传统的决策树也有不足之处,主要由于其过于简单,容易发生过拟合,以及不容易感知到特征之间的相互关联,各属性样本数量的平衡情况也会严重影响其分类效果,且判定特征的准则会对结果产生很大影响。
随机森林就是为了解决其中容易过拟合的问题,在2001年被LeoBreiman提出[7]。通过将多个决策树进行有机结合,改变了之前生成决策树时固定的选择样本方式,通过随机采样方法从原始数据样本集中选择多个特征样本,即有放回的抽取样本构建一个样本子集,再使用多个由样本子集构建的决策树分别进行分类,最后将分类结果进行融合。
目前,已经有许多研究者在此基础上进行了改进[8-11]。文献[9]提出使用MapReduce将过采样、欠采样和对成本敏感的学习应用于大数据,以便这些技术能够管理所需的、尽可能大的数据集,从而正确识别样本代表性不足的类别,但是对于直接处理样本代表性不平衡的数据和对特征较少的情况并未多作考虑;文献[12]提出文中一种在65 nm CMOS中的随机森林(RF)机器学习分类器的集成电路(IC)实现。通过利用源自RF分类器整体性质的固有错误恢复能力,对算法、体系结构和电路进行了共同优化,以实现积极的能量和延迟优势。确定性子采样(DSS)和泛化决策树降低了互连复杂性,并避免了不规则的内存访问模式和计算,最终降低了能量延迟积(EDP);文献[13]提出使用随机森林(RF)技术来搜索与糖尿病相关的最重要属性(SNP)。通过使用RF获得的属性相关性用于根据属性与RF的相关性在相似性度量中使用k最近邻加权方法对属性进行预测;文献[14]引入相似度矩阵,使用有关交互对的直接和间接信息从训练集中构造一个随机森林(决策树的集合)。生成的森林用于确定蛋白质对之间的相似性,再使用这种相似性对蛋白质对进行分类,但是算法的时间复杂度较高。
针对以上问题,文中提出一种基于集成的学习器和深度学习的分类方法,分为预拟合阶段和泛化拟合两个阶段:
1)预拟合阶段。借助神经网络强大的提炼效果,进行简单的初步拟合,并将特征进行融合提炼。
2)泛化拟合阶段。利用增强模型泛化能力的随机森林算法进一步拟合,最终得到一个更加具有鲁棒性和泛化能力的分类模型。
实验结果表明,PF-RF算法能够有效拟合特征,准确进行分类,最终得到更好的分类效果,且可以感知到特征之间的相互关联,对平衡数据也有更好的效果。
1 理论基础
定义1属性间的信息熵

(1)
为当前样本集合,pk(k=1,2,…,|y|)为当前样本种类k所占比例,信息熵越小,样本集合的纯度就越高。然后对于信息熵有下面的信息增益指标。
定义2信息增益

(2)
式中:a----离散属性的V个可能取值{a1,a2,…,an},信息增益越大,代表属性a对样本进行分类后的样本纯度越有提升。
定义3增益率

(3)
定义4基尼指数

(4)
计算数据集纯度的另一种方式,其中
2 决策树和随机森林算法基本思想
传统的决策树思想:一棵决策树包含一个根结点、若干个内部结点和若干个叶结点,叶结点对应于决策结果,其他每个结点都对应一个属性测试每个结点包含的样本集合,根据属性测试结果被划分到子结点中,根结点包含样本全集从根结点到每个叶节点的路径对应一个判定测试序列,决策树学习的目的是产生一棵泛化能力强的决策树。
而随机森林是多个决策树的一种有机结合,改变了之前生成决策树时固定的选择样本方式,通过随机采样方法从原始数据样本集中选择多个特征样本,即有放回地抽取样本构建一个样本子集,再使用多个由样本子集构建的决策树分别进行分类,最终将分类结果进行融合。
传统的随机森林算法训练过程如下:
输入:数据集D={(X1,Y1),(X2,Y2),…,(Xm,Ym)},属性集A={a1,a2,…,ad}。
输出:多个以node为节点的决策树组成的森林。
1)如果D中样本全属于同一类别C,将node标记为C类叶节点;
2)如果A不为空或者D中样本在A上取值相同,将node节点标记为叶节点;
3)从A中选择最优的划分属性a*;
4)遍历a*的每一个值,将分支节点标记为叶节点,其类别标记为D中样本最多的类;
5)得到一个以node为根节点的一颗决策树;
6)重复上面步骤,生成t个决策树,对于每个新的测试样例,综合多个决策树的分类结果作为随机森林的分类结果。
3 基于改进随机森林算法的预测
传统的Random Forest算法仅仅是多个决策树的集成。通过分析发现,其容易发生过拟合,以及不容易感知到特征之间的相互关联,样本代表性不平衡的数据也会严重影响其分类效果,且判定特征的准则会对结果产生很大影响。
文中提出的算法首先将数据通过适度的矩阵计算进行预拟合,同时也将特征之间的相互关联融入特征,得到一个提炼过的高级特征,然后再通过随机森林进一步地泛化拟合,并在生成之后进行剪枝,最终得到一个较高鲁棒性的分类结果。
这样处理方式的优势在于一方面弥补了随机森林在小样本时易过拟合的缺陷,使模型对于特征间关系可以有所考量;另一方面对数据进行一个预拟合能够降低算法的迭代次数,最重要的是可以在处理小样本数据时,对噪声数据有更好的抗性,且对不平衡的样本取得较好的分类效果。
PF-RF算法描述如下:
输入:数据集D={X1,X2,…,Xn,…,Xm},每个对象有特征集合x={a1,a2,…,ad}。
输出:训练集中每个对象对应的类别
C={y1,y2,…,ym}。
1)从数据集
D={X1,X2,…,Xn,…,Xm}
中取出每一个对象,从数据集中逐个取一个数据点,放入预拟合层进行处理。
2)进行逐层矩阵计算
φi=f(Wiφi-1+Bi)。
3)重复步骤2),最后通过全连接层得到一个萃取后的特征
4)将处理后的数据集
再次放入集成拟合区。
5)集成区中每个基分类器中的每个节点通过其属性
对D′进行划分。
6)重复步骤5),达到最后的结点时,通过投票算法得到最终结果。
4 实 验
4.1 实验描述
4.1.1 硬件
主频为3.40 GHz的CPU,16 G内存和GTX970显卡。
4.1.2 软件
使用64位Windows操作系统,基于Tensorflow框架进行计算。
4.1.3 概述
为了测试算法的性能,文中选取UCI机器学习数据库中的LETTER[15-16]数据集作为实验数据进行测试。将提出的PF-RF算法与Random Forest算法进行以下性能的对比分析:
1)分类结果的准确率方面;
2)小数量样本下的分类准确率;
3)算法的运行时间。
4.2 结果及分析
文中将两种算法分别运行10次。LETTER数据集中有20 000条数据,每条数据包含16个属性,数据集分为26类。将两种算法在准确率方面进行对比,在LETTER数据集上的测试结果见表1。
从表1可以清楚地看到,Random Forest算法的准确率最高为95.07%,最低为91.45%,平均值为93.68%,准确率的范围波动较大,这也是由于Random Forest算法在生成时选取样本和节点属性时采用随机选取的方法,生成后也没有进行有效的剪枝操作。当出现抽取样本类别不平衡时,会出现准确性波动大的情况,且当同一类别样本多次被选取时,容易导致分类结果的准确性较低。而文中提出的PF-RF算法准确率最高为96.63%,最低为95.26%,平均值为95.87%。PF-RF算法在准确率方面总体高于Random Forest算法,说明提出的PF-RF算法较为合理,得到的分类结果也更为准确。

表1 预测准确度 %
两个算法在较低数量的LETTER数据集上运行时的表现如图1所示。
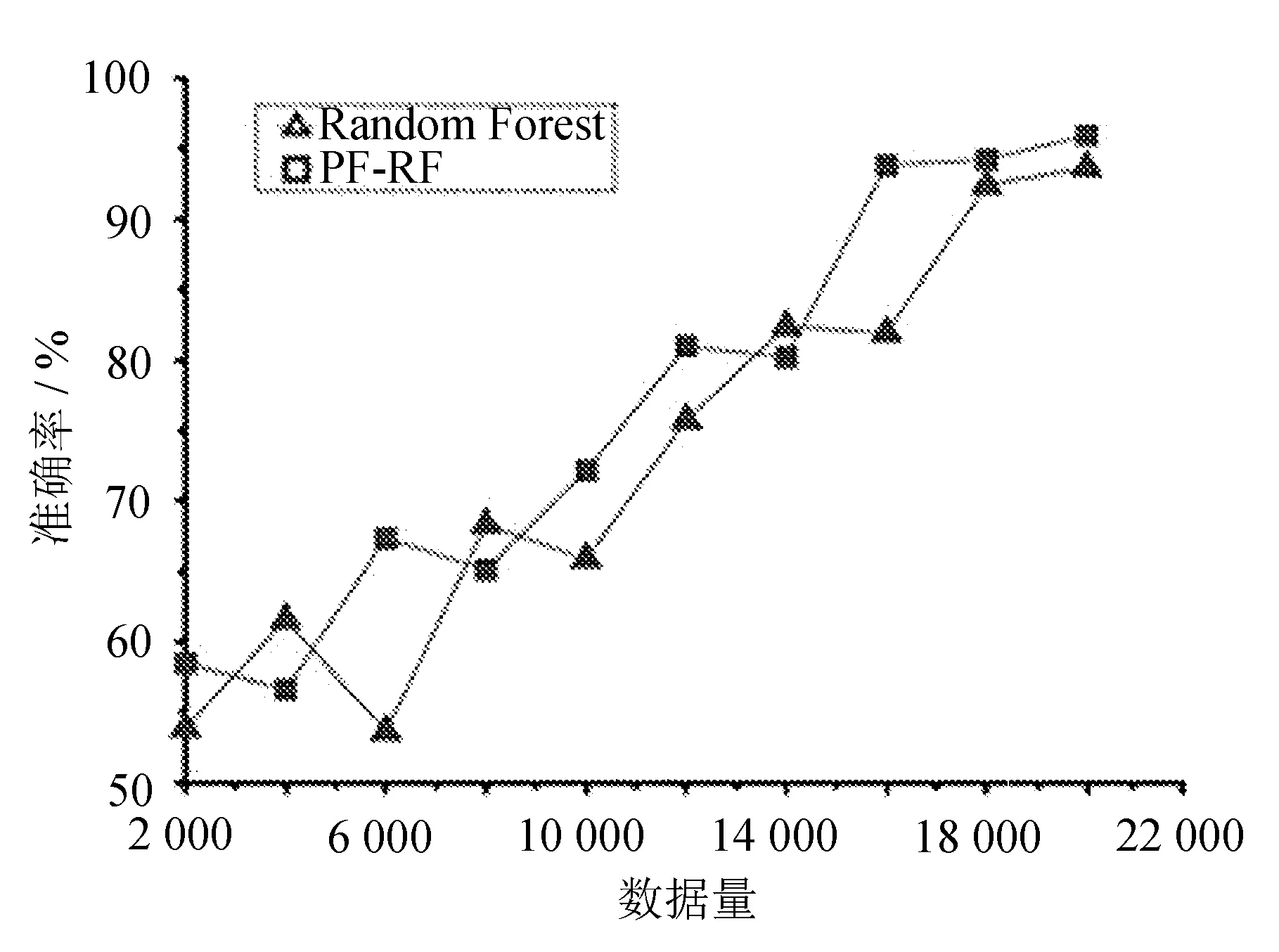
图1 算法准确度和数据量的关系
从图1可以看出,在样本较少时,传统随机森林的分类准确性波动较大,这是因为随机抽样时抽到少量噪声样本的时候,噪声样本占全部训练样本的比例会比较大。再加上最终类别较多,导致其更加不稳定,所以波动幅度很大。而改进后的PF-RF算法在样本较少时,虽然准确度也受到很大影响,但是总体保持稳定,且提出的PF-RF算法在多分类时相比原始算法有一定的提升。这是因为改进后的算法有预拟合操作,同时也会进行剪枝,避免过度生长,最终表现出比传统算法更好的鲁棒性。
从LETTER的20 000条数据中随机选取多个数量的数据对算法的运行时间进行比较。两种算法的运行时间和数据量的关系如图2所示。
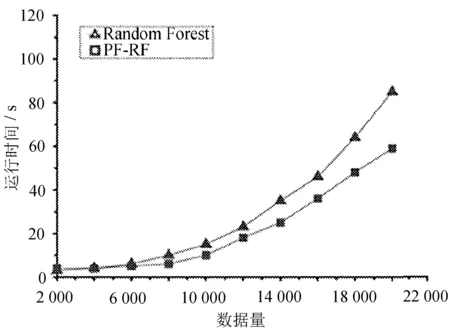
图2 算法运行时间和数据量的关系
在数据量较低时,PF-RF算法的运行时间略高于Random Forest算法。随着数据量的增加,Random Forest算法运行时间的增长趋势非常明显,而PR-RF算法的运行时间增长相对平缓。导致这样的原因是Random Forest算法没有剪枝处理,数据规模地增长会导致它的执行时间也随之大幅增长。相对而言,PF-RF算法的执行时间虽然也呈增长趋势,但是相对Random Forest算法增长幅度缓慢许多。总体看来,PF-RF算法的运行时间优于原始算法。这是因为在生成森林之后会有剪枝操作,且处理的是已经预拟合之后的特征。
5 结 语
研究基于初始聚类中心的优化算法PF-RF,采用预拟合的随机森林进行分类,有效地解决了原始算法在小样本集时有时会过拟合的表现,并且算法中加入了剪枝步骤,有效解决了算法在多分类中容易过度增长的缺陷。文中所提到的泛化拟合层中的基学习器个数,它的取值是一个开放性问题,需要根据具体的基学习器种类和数据集的特点进行设定。对于使用决策树作为基学习器时个数t的选定,以及其他基学习器的使用将是进一步的研究内容。
