结合平移关系嵌入和CNN的知识图谱补全
2021-03-18陈新元谢晟祎陈庆强
陈新元,谢晟祎,陈庆强,刘 羽
(1. 闽江学院 计算机与控制工程学院,福建 福州 350100;2. 福州墨尔本理工职业学院 信息工程系,福建 福州 350100;3. 福建农业职业技术学院 实验实训中心,福建 福州 350300;4. 福建工程学院 信息科学与工程学院,福建 福州 350100;5. 福州墨尔本理工职业学院 现代教育技术中心,福建 福州 350100)
0 引言
知识库(KB)[1]是有效事实三元组的集合,三元组由头实体、关系和尾实体组成,表示为(h,r,t),h和t分别对应头、尾实体,r表示头、尾实体之间的关系。知识库广泛应用于语义搜索引擎[2]、问题解答技术[3-4]、专家系统和社交网络分析等领域[5]。然而,现有知识库存在大量缺失事实,即三元组不完整,缺少实体或关系[6]。
知识图谱补全[7]旨在解决上述问题,通过提取局部模式[8]或语义特征,用已知信息生成新的有效事实,经典模型如TransE[9]和ConvE[10]。实体之间的关系依照关系基数,可以分为一对一(1-to-1)、多对一(M-to-1)、一对多(1-to-M)和多对多(M-to-M)四种关系类别,简单方法在1-to-1关系上往往就可获得较好的建模结果,例如基于层次结构的概念树和词嵌入空间中矢量表示思想而设计的TransE模型;而对M-to-1,1-to-M和M-to-M等复杂关系,目前尚无统一的建模标准。
近期许多嵌入模型的研究通过贝叶斯扩展或张量/矩阵分解等方法[11]增强算法框架的表达能力,然而,表达能力的提高往往意味着更高的建模复杂度和计算开销,并带来一些诸如欠拟合(多个局部最小值)或过拟合等新问题。因此,部分算法,如TransH[12]尝试在复杂性、性能和可伸缩性之间取得平衡,并在较大规模数据集上测试[13];这类算法常使用不可信度评分衡量三元组的有效性。
本文提出的ATREC算法借鉴了TransE的向量平移思路,即若三元组(h,r,t)成立,其元素向量化的表示应符合: 将关系r嵌入头实体h的结果接近尾实体t。为保留关系特征,在将原始三元组表示为k维矩阵的基础上,将关系向量嵌入到头实体和尾实体中,与原始表示拼接,生成6列k维的关系融合矩阵,使用参数较少的CNN提取特征并评分以验证三元组有效性。将该算法在四个主流基准数据集上进行链路预测和三元组分类测试,并与其他主流算法进行比较。
本文第1节讨论相关工作,第2节介绍ATREC算法,第3节介绍实验并分析结果,第4节总结并提出未来的工作方向。
1 相关工作
基于矩阵嵌入的SE模型[14]使用以关系矩阵和头、尾实体向量点积为参数的距离函数判定三元组的合理性,即若三元组成立,则在关系确定的子空间中,其头部映射应接近尾部向量。然而矩阵投影的计算成本较高,模型训练中常发生欠拟合或过拟合现象。
若确定范数约束,并舍弃相关度低的参数以展开欧几里德距离公式,则神经张量模型(NTN)[15-16]可看作是TransE的特例。该模型使用双线性张量算子,表达能力强,但参数更多,复杂度同样较高。
TransE将标记边对应的关系映射到嵌入向量,即若三元组成立,则公式vh+vr≈vt也成立,其中vh,vr,vt是实体和关系的嵌入向量。算法使用不相似度量d=||vh+vr-vt||p,计算取L1或L2范数时三元组的能量得分,在此基础上设计基于间隔排序标准(margin-based ranking criterion)的损失函数,在迭代过程中不断更新相关参数,优化模型性能;三元组的全局特征在向量同一维度的条目中得以保持。该算法结构简单,效率较高,但也存在不足,如对复杂关系三元组的学习能力有限。
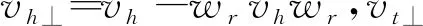
TransD[19]将投影矩阵分解为向量,从而简化计算;TranSparse[20]则使用稀疏矩阵解决头、尾实体分布不均衡的问题,同时降低计算开销;但该类模型尚未形成统一标准。
此外,DistMult[21]和ComplEx[22]使用三重积计算三元组得分;Nguyen等[23]和Toutanova等[24]引入了近邻混合/关系路径,通过加权计算或矩阵乘法获取上下文信息,优化模型的关系预测性能。也有研究使用了文本信息辅助等方法[25-31]。
近年来,在自然语言处理(NLP)[32]领域,最初设计用于计算机视觉的CNN大放光彩,因其参数和计算开销远少于全连接神经网络。ConvE是最早将CNN应用于链路预测的算法,将vh、vr转化并拼接后,作为卷积层输入;过滤器提取特征映射张量后,将其向量化并与vt计算点积,得到三元组得分。ConvE提取局部特征的效率较高,但同一维度上的全局特征可能会丢失,影响模型补全性能。
ConvKB[33]使用k维嵌入统一表示所有实体和关系,即每个三元组都可以看作是一个k×3的矩阵;卷积层中尺寸为1×3的过滤器对矩阵每一行进行遍历,提取全局关系,流程类似ConvE。然而,ConvKB仍然将实体和关系视为独立的元素,忽略其紧密联系,三元组完整性可能受损,导致关系隔离和特征丢失。
2 ATREC算法
知识图谱中,三元组(h,r,t)表示包含语义信息的事实,其中h,t∈E,r∈P,E和P分别指代实体和关系的集合。模型设计的目的是找到合理的评分函数,判定三元组的合理性或不可信度。参考TransE设计,本文使用k表示实体和关系嵌入的维数,故原始三元组可以表示为矩阵A=[vh,vr,vt]∈k×3,Ai,:∈1×3表示A的第i行。本文创新点在于将关系特征集成到头、尾实体的向量表示中,从而保证三元组的完整性,称为关系融合(relation integration),如式(1)所示。
其中,v′h是关系融合后的头实体,vh是原始头实体的k维向量表示,“·”表示点积运算,w1表示通过前馈神经网络学习获得的权重参数,vr为原始的k维关系,b1为偏置系数。尾实体计算方法相同。令v′r=v′t-v′h。 设计思路是将关系特征融入头/尾实体中,从而使对应不同关系的同一实体的不同属性得到完整表达,提高对具有复杂重数关系的三元组的分析能力。
TextCNN[32]使用六元组表示卷积网络的输入语句,参考其思路,本文将矩阵A扩展为6列k维矩阵A′,将原始三元组表示和关系融合后的三元组表示组合作为卷积层输入,即A′=[vh,vr,vt,v′h,v′r,v′t]∈k×6
过滤器的尺寸和步长对特征提取和计算开销影响较大,本文使用ω∈1×3提取同一维度嵌入向量的特征,步长为3,避免抽取无意义的局部特征,使用多个卷积核遍历矩阵A′。 这样在分别提取原始三元组和关系融合三元组的局部特征的同时,尽可能保留三元组同一维度的整体特征和语义相关性。特征映射vi表示如式(2)所示,g为非线性激活函数(如ReLU或sigmoid),b2为偏置系数。令Ω和τ分别表示ω的卷积核集合和核数,即τ=|Ω|。 卷积层处理后,特征映射v=[v1,v2,…,vk]的规模可表示为k×2(×τ)。
评分函数f定义如式(3)所示,“*”表示卷积运算。非线性函数的参数通过关系融合和平移转换得到。流程框架如图1所示。
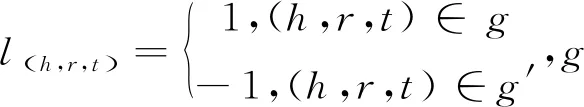
具体步骤如算法1所示,时间复杂度为O(nek+nrk),接近TransE,在数据量较大时远低于SE的O(nek+2nrk2)。
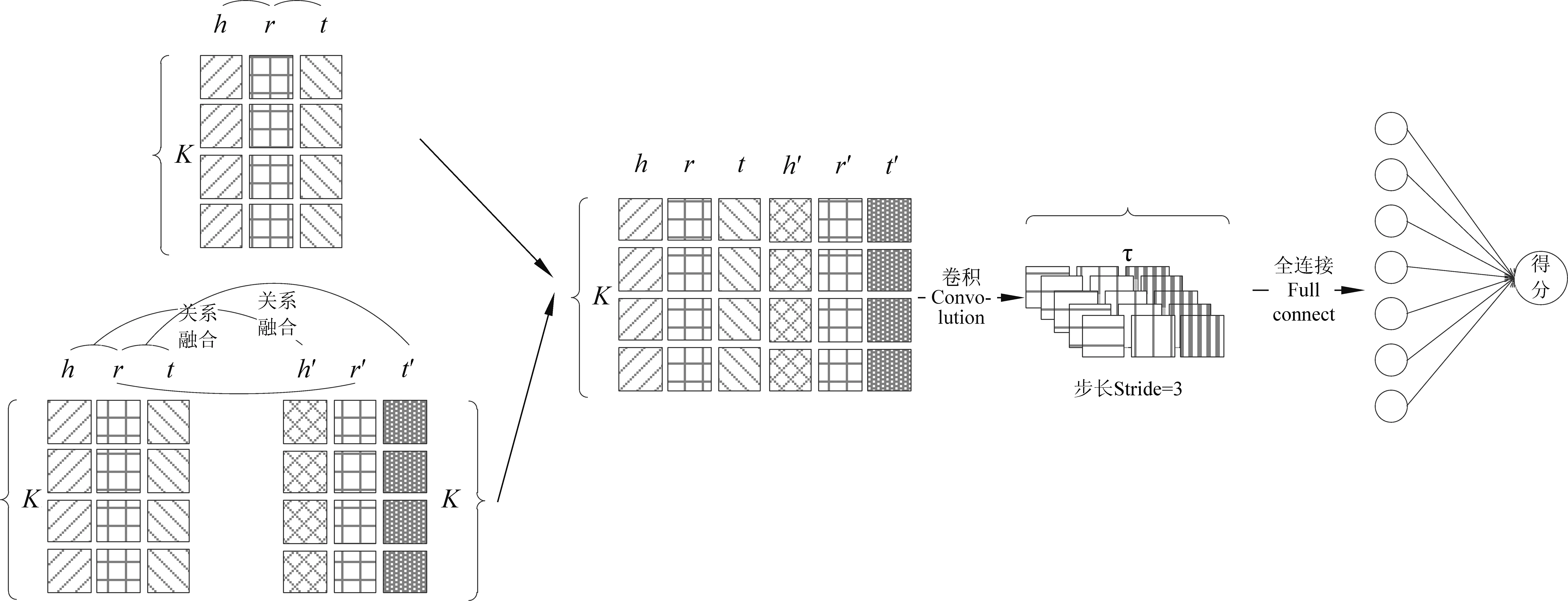
图1 ATREC的卷积流程

算法1: ATREC的优化过程Input: KB g, entity set E, relation set P, embedding dimension k, batch size b, regularizer λ, pre-trained embeddings of en-tities and relations by TransE //输入: 数据集和相关参数1Initialize variables for each vh,vr,vt //初始化实体/关系表示//Using a truncated normal distribution with init_filter_normal=True while using [0.1, 0.1, -0.1] with init_filter_normal = False2For each ω initialize with init_filter_normal //对应所有卷积核3 w←uniform(- 6 k×τ+1, 6 k×τ+1)//初始化权重4Fori=1, 2, …, n,n denotes the upper limit of epochs//对应每轮训练的操作5 Forj=1, 2, …, gb+1//对应每批(batch)训练的操作6 Batch←Sample(g,b)//从数据集中采样该批的有效三元组7 IBatch=⌀ //设置对应无效三元组集合为空 “I” short for invalid8 For each triplet in Batch//对应该批的所有有效三元组9 (h',r,t')←ISample() // 逐一生成无效样本10 IBatch←IBatch∪(h',r,t')//将无效样本加入该批的无效三元组集合11 Batch←Batch∪IBatch//合并有效三元组集合和无效三元组集合12 For each triplet∈Batch//对应该批的所有三元组13 fh,r,t =concatg(vh,vr,vt,v'h,v'r,v't *Ω) ·w2//逐一计分14 compute l(h,r,t) //取有效/无效系数15 LBatch=∑(h,r,t)∈Batchlog (1+exp (l(h,r,t)·f(h,r,t)))+λ2||w||22//计算梯度16 Update weight vector w and filters Ω w.r.t. LBatch //调整卷积核和权重
3 实验与分析
本文使用4个基准数据集,FB15k-237、WN18RR、WN11和FB13进行链路预测和三元组验证,将ATREC与其他主流算法比较,其中FB15k-237和WN18RR用于链路预测,WN11和FB13用于三元组验证。根据Toutanova等[24]的研究,使用筛除了反向关系模式的FB15k-237和WN18RR防止算法高分漏洞; WN11和FB13则删除测试集中头、尾实体曾在训练集中一起出现的三元组。数据集的统计信息如表1所示。

表1 数据集统计信息
3.1 链路预测
链路预测是在给定关系和头/尾实体的条件下推测另一个实体,以对构成的三元组评分。实验中使用MR(平均排名)、MRR(平均倒数排名)和Hits@10(排名在前10位的有效实体的比例)作为评估指标。MR越低越好,MRR和Hits@10的得分越高越好。将验证数据集上Hits@10得分最高的模型在测试集中运行以获取最终得分。
实验中使用TransE进行实体和关系的嵌入初始化。最佳性能表现时,TransE的超参数初始化设置如下:k∈[50, 100],学习率∈[1e-4, 5e-4],L1或L2范数,margin γ∈[1, 3, 5, 7]。Hits@10得分在FB15k-237上,当k=100,学习率为5e-4,L1范数,γ= 1时得分最高;在WN18RR上,当k=50,γ= 5且其他参数相同时,得分最高。
CNN学习过程中,学习率设置为∈[1e-5, 1e-4, 5e-4],批大小(batch size)∈[128, 256],卷积核数τ∈[100, 200, 500],轮数(epoch)∈[200, 500, 1 000],λ= 0.001,使用算法1中描述的过滤器正态分布,Adam优化器,并将ReLU作为非线性激活函数。在FB15k-237上,当k=100, 学习率为5e-4,τ= 100,使用[0.1, 0.1, -0.1]的过滤器分布时Hits@10分数最高;WN18RR上,当k= 50,τ= 500,truncated分布,其他参数相同时分数最高,两个数据集上批大小都为256,轮数= 200。
实验结果如表2所示,FB15k-237上ATREC获得了最佳的Hits@10结果,明显优于其他算法,MRR得分也排第二;WN18RR上获得了最高的Hits@10(略优于ConvKB)和MRR得分(和ConvE并列),MR得分也排名第二,仅次于ConvKB。
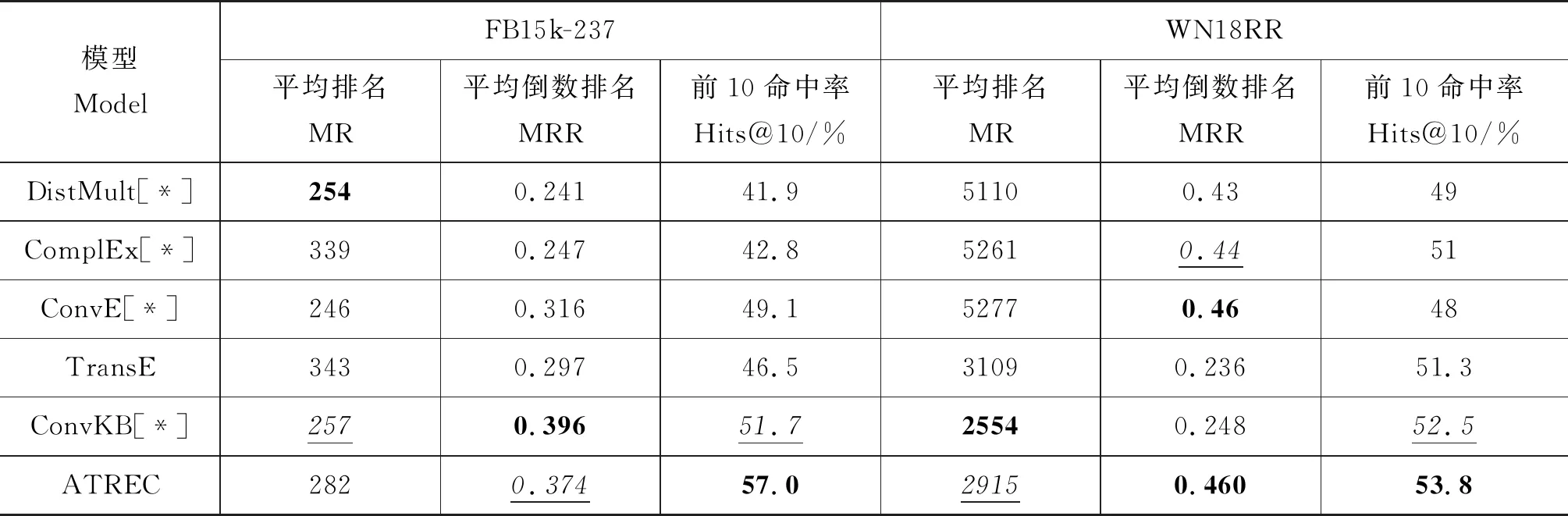
表2 FB15k-237 and WN18RR上的链路预测结果①②
DistMult和ComplEx所使用的双线性乘法运算擅长提取实体相似性特征,在稠密数据集WN18RR(每关系对应实体对数量较大)上表现较好,MRR接近最高分(ConvE);但在稀疏数据集FB15k-237上,则难以提取足够的信息优化实体表示,MRR和Hits@10都有明显下滑。
ConvE在两个数据集的几乎所有指标上都表现出色(除了WN18RR上的MR得分),说明对实体/关系向量的拼接和二维转化有助于CNN提取局部模式和关系特征。
与双线性模型相反,TransE模型的向量平移在稀疏数据集上能有效捕捉三元组的全局特征;但在稠密数据集上,特别在处理复杂关系类型时,M侧的实体表示会趋近,甚至相同,在WN18RR上的MRR得分反映出了这一缺陷。
ConvKB结合了CNN和TransE的平移特性,在两个数据集上的所有指标相比TransE都有提升,在FB15k-237上1项指标最优,2项指标第二;但却没有解决实体表示趋同的问题,因此在WN18RR的MRR指标上同样表现出性能下滑。
在FB15k-237上,ATREC的MR得分略低于ConvE和ConvKB,但相差不大。MRR得分稳定,相对于DistMult和ComplEx优势明显,比ConvE和TransE也有一定提高,仅略低于ConvKB,说明模型结构保留的平移特性能有效提取全局特征。Hits@10得分上,ATREC得分最高,相比ConvKB提高了约10%,由于ATREC与ConvKB近似,都结合了CNN框架和平移特性,关键区别在于是否进行关系集成(即本文核心特色),因此该结果说明关系属性集成提取了更丰富的特征。由于DistMult在MR排名第一,因此未来的工作方向之一是将其思路集成到ATREC中。
MR得分容易受到单次排序结果的影响;在WN18RR上,ATREC的MR得分仍然较低,说明模型稳定性较好。MRR得分与ConvE相同,明显高于TransE和ConvKB,说明集成关系属性有助于防止实体趋同,提升模型在复杂关系上的表现。Hits@10上ATREC保持了最高得分,略优于ConvKB。
借鉴之前的模型[17,19-20],本文使用TransE生成的向量初始化实体/关系表达;而ConvKB的整体性能较好(除了WN18RR上的MRR得分),且与ATREC类似,故将TransE和ConvKB用作进一步分析的基准。
为了确认ATREC在FB15k-237上的Hits@10得分提升源于更强的复杂关系处理能力,计算FB15k-237上4种关系类别的预测头/尾实体的Hits@10得分,如图2、图3所示。在1-to-1关系中,无论是预测头部还是尾部,TransE、ConvKB和ATREC的性能相仿;预测1-to-M类型的头部和M-to-1类型的尾部,三者表现也接近,因为在上述任务中,都是单个或多个源实体指向单个目标实体,后者识别难度较小。在M-to-1和M-to-M类型的头部预测,以及1-to-M和M-to-M类型的尾部预测这4种情况下,ATREC的得分均为最高,尤其在1-to-M类型的尾实体预测上,相比ConvKB得分高出一倍有余,说明ATREC的性能提升确实是因为提高了复杂关系的处理能力;换言之,关系集成能更有效地提取M侧的角色特征,具有较好的泛化能力。

图2 FB15k-237上针对四种类型关系的头实体预测的前10命中率(Hits@10)
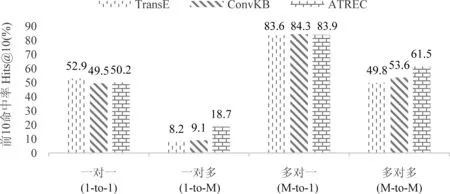
图3 FB15k-237上针对四种类型关系的尾实体预测的前10命中率(Hits@10)
在WN18RR基础上,将所有11种关系按其百分比升序排列(次纵轴+折线图),比较3种模型的Hits@10和MRR得分(仍为柱状图),如图4、图5所示。TransE和ConvKB在其中3种复杂关系has_part (1-to-M)、member_meronym (1-to-M)和hypernym (M-to-1)上性能明显下滑,说明该类关系是平移模型的短板(这3种关系占整体比例较高,导致了TransE和ConvKB的MRR总得分下降);ATREC则保持相对稳定。这一现象与3种模型在FB15k-237上预测M-to-1类型的头实体和1-to-M类型的尾实体的表现相符,再次验证了ATREC的模型优势。在similar_to、verb_group、also_see和derivationally_related_form这四种M-to-M关系上,由于存在大量对称模式的三元组(学习难度较低),3种模型的表现都较好。
3.2 三元组分类
三元组验证引入阈值θ,将特定三元组得分与之相比以判定三元组是否有效。根据Socher等[16],θ通过提高验证数据集上的平均分类精度得出。实验中嵌入初始化仍由TransE生成,无效三元组的生成方法也相同。
从相关研究中引用部分性能较好的模型结果进行比较;本文也自行实现并测试了TransE、ConvE和DistMult模型。对于TranSparse模型,“S”和“US”分别表示结构化和非结构化模式。TransE取得最优性能时的超参数设置如下: WN11上学习率为0.001,L1范数,γ= 7,k=50;FB13上学习率相同,L2范数,γ= 1,k=100。ConvE的embedding dropout取0.2,feature map dropout 取0.2,projection layer dropout 取0.4,k=200,批大小取128,学习率取0.001,label smoothing 取0.1。DistMult,维数k=100,轮数取200,学习率取0.001,L2范数,正则化系数0.0001。ATREC在WN11上当初始学习率为5e-4,k=50,卷积核数τ= 200,truncated分布时性能最优;在FB13上,k调整为100,学习率等其他参数不变。
分类准确率结果如表3所示,平均得分ConvKB最优,ATREC略低,与TransD持平,相较许多经典算法(NTN、ConvE和TransE等)具备一定优势。
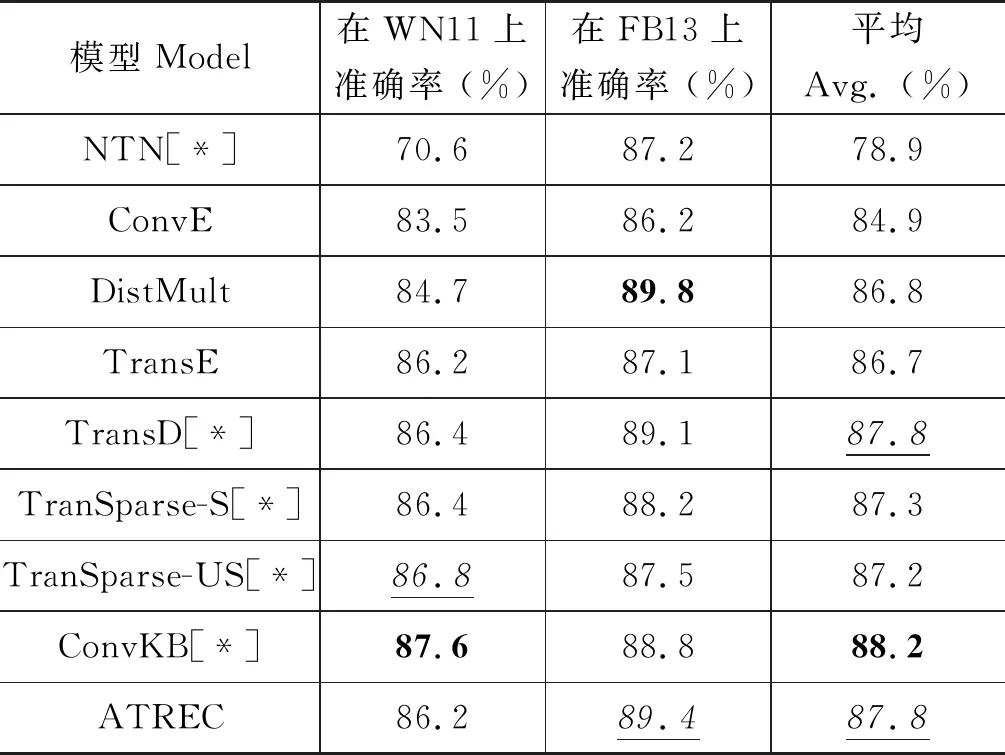
表3 分类准确率
NTN模型在稀疏数据集上容易过拟合,因此WN11上得分较低。ConvE在两个数据集上的表现都一般,说明单纯加强局部模式的识别存在一定局限性。DistMult在稠密数据集FB13上取得最高得分,在稀疏数据集WN11上则性能明显下降,与之前实验结果一致。平移模型TransE及其变种在该任务上表现普遍较好。ATREC在FB13上相比TransE和ConvKB都有提升,再次证明了使用关系集成而非双线性乘法运算处理复杂关系的可行性;但在WN11上,ATREC得分与TransE持平,低于ConvKB,原因可能为: 尽管同时考虑复杂关系和平移特性有其优势,但也增加了特征提取的不确定性。针对该假设的改进仍在计划中。
由于NTN、ConvE和DistMult模型总体表现一般;TransD、TranSparse-S和TranSparse-US都利用TransE生成嵌入表示,可看作是TransE的扩展,性能也近似;ConvKB在该任务上表现最优;因此只使用TransE和ConvKB作为基准模型来进一步生成FB13上各种关系分类准确率的比较,结果如图6所示。除institution和profession属于M-to-M类型之外,其他关系都属于M-to-1类型。可以看出,ATREC在M-to-M关系上的优势明显,在M-to-1关系上性能也较稳定,且在所有7个关系上性能表现都优于TransE。
4 总结
在保留三元组完整性和处理复杂关系的问题上,现有基于嵌入表示的知识库补全模型仍有瑕疵,如特征丢失、参数规模庞大等。因此本文提出ATREC,旨在将平移变换后的全局和局部特征在统一框架中表示并提取,同时使用CNN降低参数规模,减少计算开销;主要创新点在于将关系特征融合到头/尾实体中以应对复杂关系。链路预测和三元组分类验证的实验结果证明,ATREC算法的稳定性较好,相较主流模型有一定提高,特别是在处理FB15k-237和FB13数据集上复杂关系时优势较明显。我们未来的工作方向包括: 尝试从基于逻辑规则的关系推理中获得支持;通过集成关系路径信息改善模型性能;将ATREC应用于行业数据处理和更大规模数据集分析等等。
