基于词性特征的明喻识别及要素抽取方法
2021-03-18赵琳玲王素格张兆滨
赵琳玲,王素格,2,陈 鑫,王 典,张兆滨
(1. 山西大学 计算机与信息技术学院,山西 太原 030006;2. 山西大学 计算智能与中文信息处理教育部重点实验室,山西 太原 030006)
0 引言
比喻是用于与其相似的事物、道理打比方的修辞格,使用比喻辞格的句子称为比喻句。利用比喻对事物的特征进行描述,可以使事物形象、生动、具体,给人留下深刻印象。在文学类作品中,利用比喻可增强语言的表现力,在近年的高考语文散文类鉴赏题中,多有涉及明喻句的考查。以2016年北京市高考语文第24题为例:
原文: 我在这腔调里沉迷且陷入遐想,这是发自雄浑的关中大地深处的声响,抑或是渭水波浪的涛声,也像是骤雨拍击无边秋禾的啸响,亦不知无时节的好雨润泽秦川初春返青麦苗的细近于无的柔声,甚至让我想到柴烟弥漫的村巷里牛哞马叫的声音……
问题: 文章第四段运用了多种手法,表达了作者对老腔的感受。请结合具体语句加以赏析。
部分参考答案: 比喻,将老腔的腔调比喻为骤雨拍击秋禾的啸响、雨润麦苗的柔声等,既写出了……,又写出了……。
如果能自动识别明喻句并抽取句子中的本体和喻体,不仅可以解答鉴赏类问题,还可以进一步了解作者所表达的思想感情。
比喻句中相关要素定义[1]如下:
本体: 被描写和说明的事物,即被比方的事物。
喻词/连接词: 连接本体和喻体的词语,在明喻中称为 “喻词”,例如,“像、如、好像”等,暗喻中为“连接词”,总称为“触发词”。
喻体: 与本体相对,即用来打比方的事物。
喻解/喻底: 使本体和喻体构成比喻关系的两者的相似点。
现代修辞学将比喻分为明喻、暗喻、借喻,将暗喻和借喻视为隐喻[2]。明喻就是直接打比方,有明显的喻词指引本体和喻体之间的关系[3]。通过研究明喻[4],分析和阐释明喻现象,了解明喻建立的意义和推理机制,探究明喻背后的认知过程,可以了解人的认知手段与过程。虽然与隐喻相比明喻研究相对容易,但由于数据的缺乏和相关研究较少,给研究也带来了挑战。
现代汉语明喻句的典型句式为“A像B”,此句中本体是A、喻体为B、喻词是像。针对此类明喻句,本文主要研究基于词性特征的明喻识别及要素抽取方法。由于双向的长短期记忆(BiLSTM)[5]能够充分利用上下文信息,而条件随机场(CRF)模型可以用来输出标签之间的前后依赖关系,因此,将词性特征融合到BiLSTM与CRF连接对序列化数据进行建模(BiLSTM-CRF)。在Chinese-Simile-Recognition[6]数据集上进行验证,实验结果表明,本文方法优于Liu等人[6]提出的单任务明喻识别和要素抽取方法。
1 相关工作
目前针对比喻句的已有研究主要是利用句法结构和深度学习的方法。
基于句法模式的分析方法是利用句子的句法结构(主谓宾结构)和词汇间的依存关系(并列,从属等)进行建模的方法。Niculae等人[7]提出了一种使用句法模式进行比较识别的方法,用于比喻句中的本体和喻体的抽取。该方法在处理明喻句中的短句时表现比较好,对于复杂或长句有时会导致本体和喻体抽取的不完整。Niculae等人[8]提出了在比较句中比喻的计算研究,探究了明喻的语言模式,发现领域知识是识别明喻的主要因素。
基于深度学习的比喻句识别,穆婉青[1]采用词和词性作为特征,提出了基于CNN_C的比喻句识别,正确率已达到94.7%,然而,并没有对要素进行抽取。对于要素抽取,研究者们利用多任务学习方法,通过在相关任务间共享表示信息,提升模型在原始任务上的泛化性能。Liu等人[6]提出了神经网络框架联合优化的三个任务。将明喻要素抽取看成序列标记问题,使用不同的前缀标签区分本体和喻体要素。CRF[9]能有效学习输出标签之间的前后依赖关系,近些年在自然语言处理领域中得到广泛应用。Huang等人[10]提出了一系列基于长短期记忆(LSTM)的序列标注模型,首次将BiLSTM-CRF模型应用于NLP基准序列标记数据集,并证明 BiLSTM 模型可以有效地利用过去和未来的输入特征。对于CRF层,它还可以使用句子级的标记信息,使方法具有较强的鲁棒性,而且对嵌入词的依赖性也较小。
本文将明喻识别和要素抽取作为序列标注任务。嵌入层将词性特征向量化得到的向量与词向量进行融合,采用BiLSTM学习文本中前向和后向距离特征来得到全局特征,在输出层添加CRF层得到文本的最优标注序列。
2 数据特征分析
为了对比喻句中本体和喻体准确的识别,本文选取两个数据集进行考察。
Chinese-Simile-Recognition(CSR)[6]: 该数据集是由首都师范大学、科大讯飞等提供(1)https://github.com/cnunlp/Chinese-Simile-Recognition-Dataset,训练集共有7 262条句子,其中比喻句(明喻句)有3 315条,非比喻句有3 947条。
Simile-Recognition-SXU(SRS)[1]: 该数据集是由山西大学研究团队构建,数据来源于高中语文课文、查字典网(2)https://www.Chazidian.com、散文吧网站(3)https://www.sanwen8.cn和BCC网站(4)http://bcc.blcu.edu.cn。该数据集共有3 207条,其中训练集有1 925条,开发集有641条,测试集有641条。人工标注明喻句中的本体和喻体是最简短的,且不带修饰语。
2.1 喻词分析
对于CSR,明喻句中喻词均为“像”,而明喻句中的喻词不仅只有“像”,还有“如,好似,仿佛,若,似乎”等。对SRS中不同喻词的句子进行统计,结果如表1所示。人工校对部分分词,标注的本体和喻体是不带修饰语的名词短语。
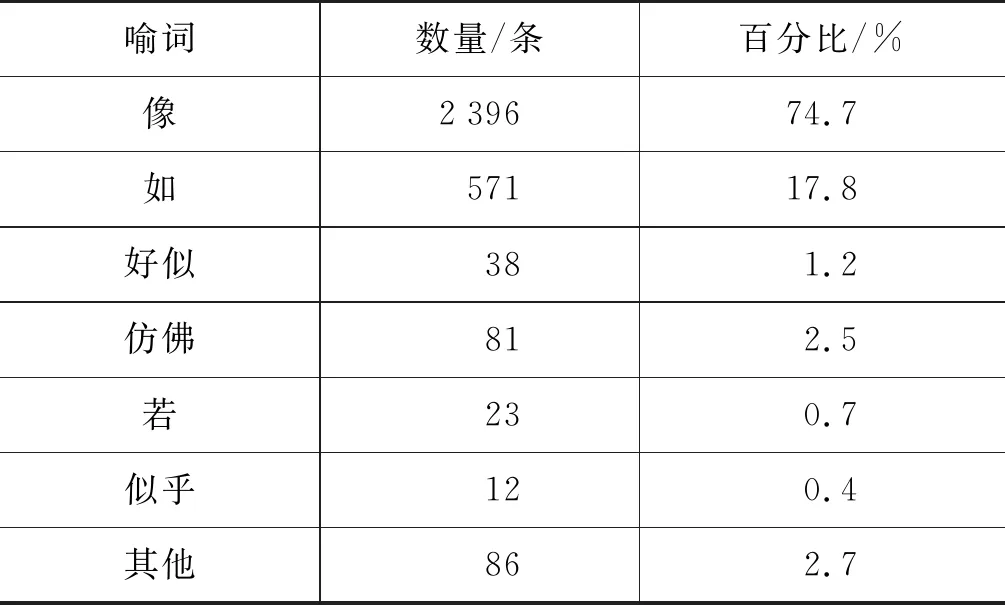
表1 SRS中不同喻词统计
2.2 词性特征分析
通过对CSR和SRS两个数据集的统计,发现CSR中比喻句标出的本体与喻体包含多词的仅占0.38%,而SRS本体与喻体中包含多词的仅占1.07%,因此,本文只对CSR和SRS中本体和喻体为单个词的开展研究。再对CSR和SRS的本体与喻体按照词性进行统计,发现CSR和SRS中名词分别占80.3%和85.9%。而动词在句子中扮演着重要角色,它表征概念实体间的相互关系,是句子中名词实体的概念依存体。因此,词性特征对于识别明喻句中的本体和喻体可以提供更准确的信息。
3 明喻识别及要素抽取方法
通过第2节对比喻句特征的分析可以发现,本体和喻体的词性对比喻句的识别具有重要的作用。因此,将词性特征融合到词的表示中。由于BiLSTM-CRF模型在BiLSTM输出后增加了CRF层,所以它能够加强文本间信息的相关性,并同时考虑过去的与未来的特征。因此,本文将明喻识别及要素抽取问题看作序列标注问题。利用每个句子中的词表示和词性表示的联合特征,学习特征到标注结果的映射,得到特征到任意标签的概率,通过这些概率,得到最优序列结果,根据最后序列结果对明喻识别及要素抽取,整体框架如图1所示。
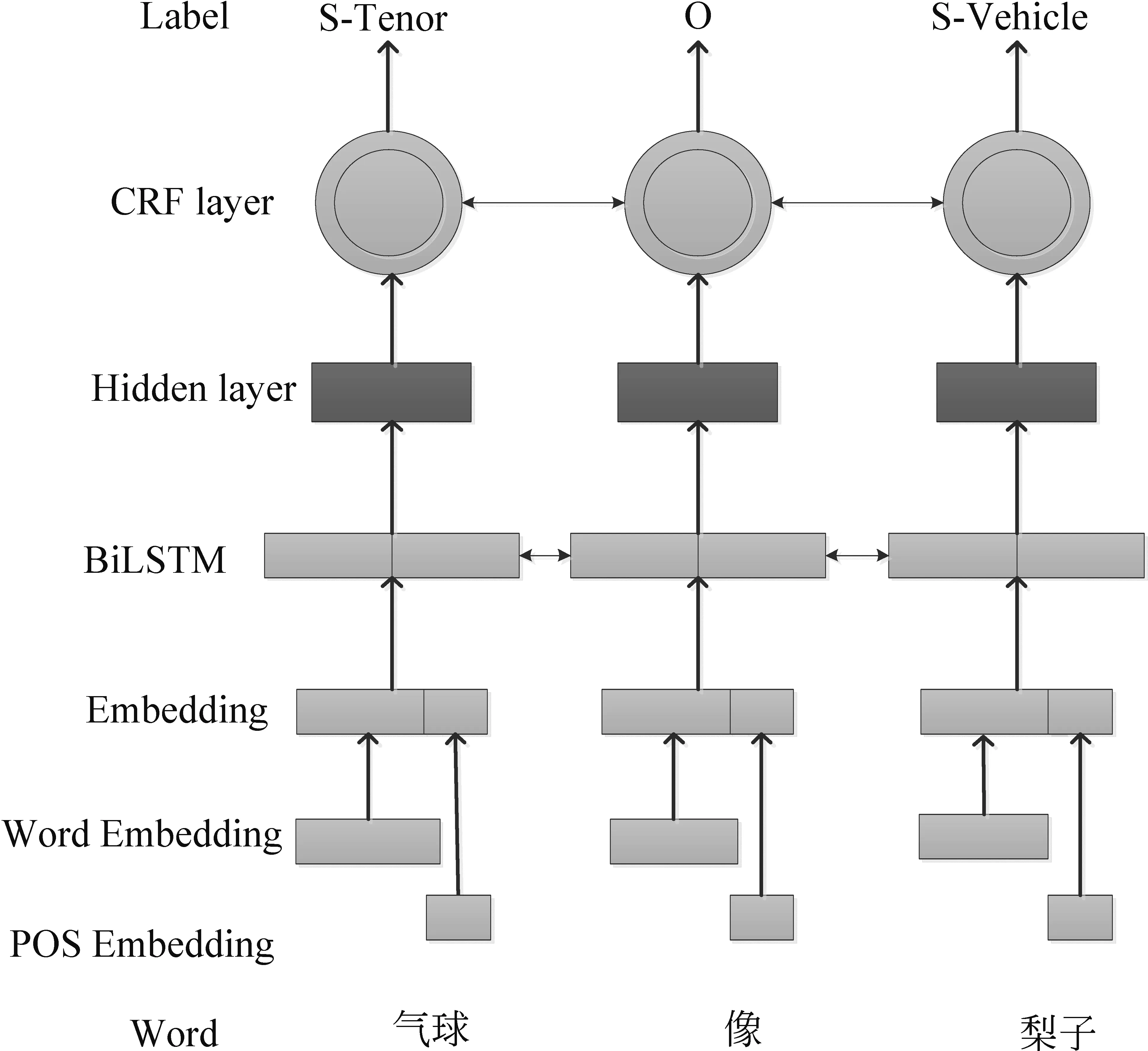
图 1 基于词性特征的明喻识别及要素抽取框架
图1中标注的实体有本体和喻体,分别用Tenor和Vehicle表示,将已标注的数据集转变为IOBES模式(O: 既不是本体,也不是喻体,S: 单独构成实体,B: 实体的开始,I: 实体的中间,E: 实体的结尾),共得到九种标签,具体的标签类型Typeset={O,S-Tenor,B-Tenor,I-Tenor,E-Tenor,S-Vehicle,B-Vehicle,I-Vehicle,E-Vehicle}。例如,S-Tenor表示单独一个词构成本体。对于明喻句的识别问题,当一个句子中所有词的标签都为“O”时,则判定此句为非明喻句,否则此句为明喻句。
3.1 词嵌入式表示
由于明喻句中的语言表达比较含蓄、委婉,直接从字面上对其识别比较困难。例如,图1中的例句,“气球像梨子”,之所以能这样说,主要原因是气球和梨子在形状上有某些相似之处,人们在使用时将“气球”比喻成“梨子”,也就是将有类似特征的词语放到一起使用。虽然它们在字面上属于不同领域的事物,但在上下文中又有一定的语义一致性,另外,它们所具有的词性都为名词。因此,可以建立词语和词性的深层语义表示。
3.1.1 词语的初始化表示[6]
为了刻画句子中词语深层语义表示,Word2Vec可以作为其初始化表示工具,其原因是Word2Vec是在大规模的语料库上进行训练所得,能使词语表达的深层语义更加丰富。
设给定一个句子Sentence={w1,w2,…,wn},wi为句子Sentence中的第i个词语,利用Word2Vec工具获得wi的初始化嵌入表示为ci,得到句子的嵌入表示为Sentence={c1,c2,…,cn},其中,ci∈Rd(i=1,2,…,n)。
对于比喻句中的词性特征,直接利用结巴工具进行获取,其中名词用“1”表示,代词用“2”表示,动词用“3”表示,其他词性用“0”表示。词性特征也可使用Word2Vec工具获得,pi代表词性特征向量,其中pi∈Rd(i=1,2,…,n)。 将词语嵌入和词性特征向量进行拼接,如式(1)所示。
其中,“;”表示拼接操作,xi∈R2d,代表拼接后的向量表示。
利用式(1)可得到句子表示为Sentence=(x1,x2,…,xn)。
3.1.2 基于BiLSTM的词语上下文表示



3.2 基于BiLSTM-CRF的明喻要素预测
由于BiLSTM-CRF模型是在BiLSTM输出后增加CRF[13]层,可以增强词语间上下文信息相关性的特征,同时考虑当前每个词的隐层状态的特征。因此,为了对句子进行序列标注,将第3.1节得到的嵌入式表示,经过一个线性变换获得隐藏层每个词的新表示,这个新表示一方面作为CRF[13]的输入,另一方面作为该词在序列标注时标签的得分。
对于嵌入层表示后的句子Sentence=(h1,h2,…,hn),再使用一个线性变换层,得到句子中每个词wi隐藏状态的嵌入表示pi,将句子中的词语从4d维映射到q维空间,q为标注序列中标签的个数,如式(4)所示。
其中,W∈Rq×4d,pi∈Rq。
由式(4)获得句子Sentence输入CRF层的嵌入式表示为P=(p1,p2,…,pn),其中,P∈Rn×q,pi中的每一个元素pi,j表示句子中第i个词语xi得到第j个标签的得分。
在序列标注任务中,需要利用词的标签与周围词标签存在的依赖关系,然后解码出全局最优的标签序列,CRF正是针对这项工作的。因此,在 BiLSTM 网络输出层后加入CRF。
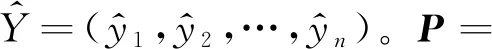
对于预测句子Sentence的标签序列,由softmax计算获得,如式(6)所示。
在训练过程中,最大化正确标签序列的对数概率[15],如式(7)所示。
log(p(Y|Sentence))=s(Sentence,Y)-

(7)
从式(7)中能够获得模型生成概率中最大的标签序列。在解码阶段,最后预测的输出序列是根据最高得分的标签序列所获得的,如式(8)所示。
通过式(8),可以获得句子Sentence中词的每个标签,其标签类型为第3节介绍的九种标签之一。
4 实验结果及分析
4.1 参数设置及评价指标
本文实验中词向量维度是50,字向量维度是100,均采用Word2Vec训练得到的向量。特征向量的维度设置为50,LSTM隐藏层的维度设置为100,dropout设置为0.6。梯度下降优化算法采用Adam[16],学习率设置为0.001。
本文采用第2节介绍的CSR和SRS作为实验数据集。对于一个明喻句,只有本体和喻体的边界和标签都标记正确时,才判定此明喻句要素抽取正确。因此,实验结果采用成对的评价指标(5)https://github.com/cnunlp/Chinese-Simile-Recognition-Dataset,精确率P(precision)、召回率R(recall)和F1值。
4.2 对比方法介绍
为验证本文方法的有效性,设置如下方法对比实验。
CRF: 直接利用分词特征,设计CRF的特征模板,窗口大小为5。
RNN: 以字向量作为输入的循环神经网络。
CNN: 以字向量作为输入的卷积神经网络。
下面的方法仅说明其输入向量的方式,在此基础上采用BiLSTM-CRF。
C: Embedding层为每个字的字向量。
C+J: Embedding层为每个字向量和位置信息的拼接,位置信息的表示是通过结巴分词得到分词信息特征。1表示词的开始;2表示词的中间;3表示词的结尾;0表示单个词。
Singletask(CE): 由Liu等人[6]提出的Embedding层为每个词的词向量。
W+T: Embedding层为每个词的词向量和主题信息的拼接,主题信息是利用LDA聚类方法得到的。
W+F: Embedding层为每个词的词向量和词性特征的拼接。
W+F+T: Embedding层为每个词的词向量、词性特征和主题信息拼接。
4.3 实验结果及分析
实验1七种方法的明喻要素抽取比较
为了验证本文提出方法的有效性,在CSR和SRS上设置了如下对比实验,实验结果分别如表2、表3所示。

表2 七种抽取方法在CSR上明喻要素抽取的实验结果比较(%)

表3 七种抽取方法在SRS上明喻要素抽取的实验结果比较(%)
由表2和表3可以看出:
(1) 以CRF方法作为基准方法,可以解决序列标注问题,但是与其他深度学习的方法相比,需要自定义特征模板,并没有学习到文本深层次的特征,因此抽取效果不及其他深度学习方法。
(2) 词向量表示优于字向量表示,主要原因是明喻句中的本体和喻体多数是一个词而不是一个字,而且词比字包含更多的语义信息。
(3) 喻体的抽取效果均比本体的抽取效果好。为了展示其原因,图2和图3给出了本体—喻词的相对距离以及喻体—喻词的相对距离,可以看出,相对于本体来说,喻体大多数分布在喻词的后面,比较集中,而本体的分布相对比较分散。
(4) 在七种方法的比较中,W+F在明喻要素抽取中整体效果最好。
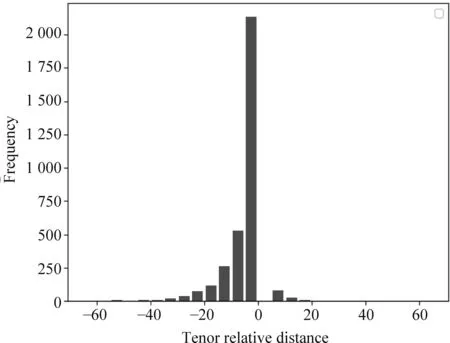
图2 在CSR中本体—喻词的相对距离

图3 在CSR中喻体—喻词的相对距离
实验2九种方法在CSR上的明喻识别
为了与文献[6]中的单任务方法进行对比,仅在CSR上进行明喻识别对比实验,实验结果如表4所示。
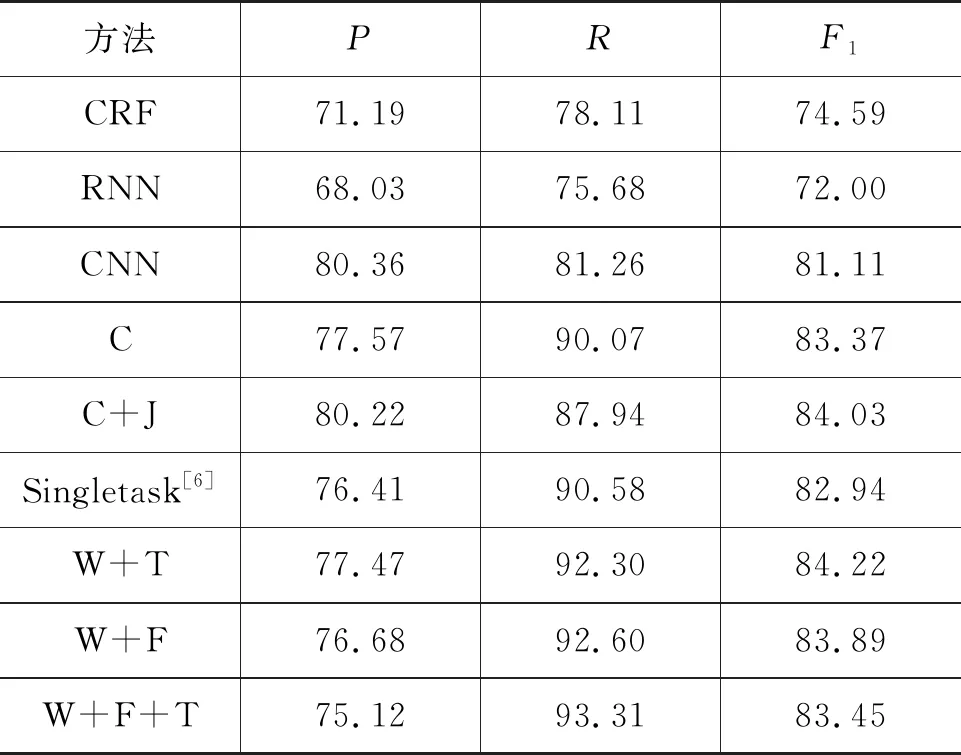
表4 各类识别方法在CSR上的实验结果比较(%)
由表4可以看出:
(1) CRF、RNN、CNN三类方法作为基准方法,识别效果均不及BiLSTM-CRF方法。这是因为CRF、RNN、CNN都无法充分考虑文本上下文信息,因此难以得到深层次的语义信息,不能较好地对文本语义进行特征建模。
(2) 对于Embedding层分别仅用字向量和词向量表示,在Recall指标下,Singletask > C,而在F1指标下,C > Singletask,这是因为判断是否为明喻句只是通过判断句中是否有本体或喻体的标注,而不能判断明喻要素抽取是否正确。
(3) 对于Embedding层都包含词向量的,在F1指标下,识别效果Singletask < W+F+T < W+F < W+T,W+T的识别效果最好,而W+F+T不如W+T,这是因为W+F+T中Embedding层融合了比较多的信息,而本文的数据集较小。
实验3W+F方法应用实验
为了验证W+F方法的应用能力,对引言中高考鉴赏题进行实验,其结果如表5所示。

表5 本文方法解答高考题示例
由表5可以看出,本文提出的方法可以抽取到本体和喻体最简洁的名词短语,并能识别出明喻句。抽取到的本体和喻体与参考答案相比不够完整,因此,需要根据抽取的本体和喻体,再与原文中抽取相关的修饰语相结合,形成最终的完整答案。完整答案与参考答案相比,可知本文方法能为解答散文类鉴赏题提供支持,以提升答题的准确率。
5 结论和展望
针对明喻句的识别及明喻句中本体和喻体的抽取问题,本文采用明喻句中本体和喻体的词性特征,设计了基于词性特征的明喻识别及要素抽取方法,并与现有的方法进行了对比,证明了本文所提方法的有效性。针对高考散文类鉴赏题,将本文所提的方法应用到答题中,可以获取部分答案信息。
由于在实际数据中句子比较复杂,而本文实验的数据集中大多数是句式简单的句子,并且其数据集中标注的本体和喻体均为不带修饰语的名词短语,训练集的数据集也比较小,所以深度学习学习到相应特征有限。在未来的工作里,将考虑加入注意力机制来识别带有修饰语的本体和喻体,并且从更深层次挖掘比喻句的特征来对隐喻进行研究。此外,创建更丰富的语料库也是我们下一步重点的工作方向。
