基于人工蜂群算法和XGBoost的网络入侵检测方法研究
2021-03-16徐伟冷静
徐 伟 冷 静
(湖北警官学院信息技术系 湖北 武汉 430034)
(电子取证及可信应用湖北省协同创新中心 湖北 武汉 430034)
0 引 言
网络攻击给用户带来的损失巨大,其范围广、危害大,有些损失和破坏甚至不可恢复。针对网络攻击,很多大型用户(企业级)使用入侵检测系统[1](Intrusion Detection System,IDS)等多种安全系统来抵御攻击。由于IDS可以识别异常模式和流量,并对系统中所有未授权活动进行监测、检测和响应[2],因此它一直是网络安全领域的重要研究方向。
IDS一般包括误用检测和异常检测[3]。在误用检测方法中,将预构建的入侵模式作为规律保存在数据集中,每个模式代表一种特定的攻击类型。这种情况下无法检测到网络中的新型攻击[4],因为其模式不在数据库中。异常检测方法是基于网络正常行为或特征来制定决策,将明显违背该模型的业务事件或数据流视为入侵[5]。这种IDS分类方法能够检测到新型未知攻击,但由于难以区分普通行为和异常行为的界限,会造成较高的虚警率。
目前已有一些IDS方面的研究成果。文献[6]提出的模型通过数据分析将网络数据分类为正常行为和异常行为,是一种多级混合入侵检测模型,使用支持向量机和极值学习机来提升对已知攻击和未知攻击的检测效率。此外,文献[6]还提出了改进的K均值算法,用于构建能够代表整个原始训练数据集的多个较小的新训练数据集,显著降低了分类器的训练时间,提升了入侵检测系统的性能。文献[7]提出了DDoS攻击的应用层实时检测方法,根据绝对时间间隔准则,推导出了一组新的训练和测试工具,该方法使用了布谷鸟等算法,其中布谷鸟二元聚类策略最大限度降低了算法的开销成本,并提升了预测准确度。文献[8]提出一种基于网络连接数据分析和在线贯序极限学习机分类器的IDS,对入侵数据库中的网络连接数据进行分析,通过特征选择算法选择出最优特征子集,利用优化后的样本特征集来训练OSELM分类器。鉴于DoS攻击是基础设施的一个主要隐患,文献[9]提出了一个基于cookie的统计模型,使用定性和定量结果对各种统计模型进行了分析,以提高模型检测效率。
目前,很多入侵检测的研究中使用了机器学习算法,例如分类和聚类算法或以不同方式将机器学习算法与特征选择方法结合在一起[10]。但这些研究很少考虑降低虚警率的问题。本文针对该问题提出了能够降低虚警率的异常检测方法,使用了人工蜂群(ABC)算法和XGBoost算法的混合检测,其中ABC算法被用于特征选择,XGBoost算法则被用于特征的评价和分类。实验结果证明了所提出的方法在准确度和检测率方面的优势。
1 混合式异常检测IDS
一般IDS方法都由三个主要阶段组成:预处理、特征选择、分类。由于数据集包括数值特征、非数值特征、字符串,应该对其进行同质化。因此,首先必须对数据集进行预处理。一般预处理包括两个阶段:1) 将数据集中非数值特征转换为数值量;2) 数值归一化。由于NSL-KDD数据集[11]特征包括离散量和连续量,特征量位于不同区间,所以这些特征不具备可比性。因此使用归一化完成特征的标准化,且所有数值均被限制在区间[0,1]内。
本文方法通过ABC算法进行特征选择,以提升准确度,并加快检测时间;通过XGBoost算法用于特征评价和分类。本文方法的流程如图1所示。

图1 本文方法的流程示意图
1.1 特征选择(ABC算法)
在ABC算法中,每类蜜蜂各司其职,食物源代表问题相关的解,而食物源花蜜量则表示解的质量。求解过程主要分为以下四个阶段:初始化阶段、雇佣蜂阶段、旁观蜂阶段、侦查蜂阶段[12]。
首先建立一群蜜蜂,其中半数为雇佣蜂,另一半为旁观蜂。生成NF个解,每个解Xi(i=1,2,…,NF)为一个D维向量。Xi表示蜂群中第i个食物源。每个食物源(解)仅对应一只雇佣蜂,即雇佣蜂或旁观蜂的数量等于解的数量。根据式(1)随机生成每个候选解。然后计算适应度并保存最优解。由于本文选择封装方法进行特征选择,因此使用了XGBoost进行适应度评价。
(1)

vi,j=xi,j+φi,j(xi,j-xk,j)
(2)
式中:xi,j为上一个位置;φi,j为区间[-1,1]内的随机量;xk,j为xi,j的一个邻居。通过下式计算每个解的适应度:
(3)
式中:f(xi)为第i个解的目标函数值。
在所有雇佣蜂都完成探索过程后,将更新后解的适应度数值与旁观蜂共享。蜜蜂基于食物源概率选择一个食物源。利用下式计算任意解的选择概率[13]:
(4)
式中:fiti为雇佣蜂计算出的第i个解的适应度数值。根据式(4)随机选择邻近解,并通过式(2)搜索周围更好的解,使得位置xi,j的变化减少。由此在搜索空间中搜索到的最优解是在附近的。在利用式(2)完成每个探索后,若上一个食物源的位置不优于新位置,则将trial的数值加1。为了防止局部最优陷阱,若经过几次连续的重复后,食物源的trail数值是预先确定的限值,且未更新,则丢弃该食物源,与其对应的雇佣蜂将该食物源丢弃给侦查蜂。接着,基于式(1)利用随机探索选择一个新的食物源来替代丢弃的食物源,丢弃食物源的trial数值为0。最后,通过反复探索计算出最优食物源,若计算出的最优食物源优于整个算法的最优食物源,则进行替换。ABC算法的流程如图2所示。
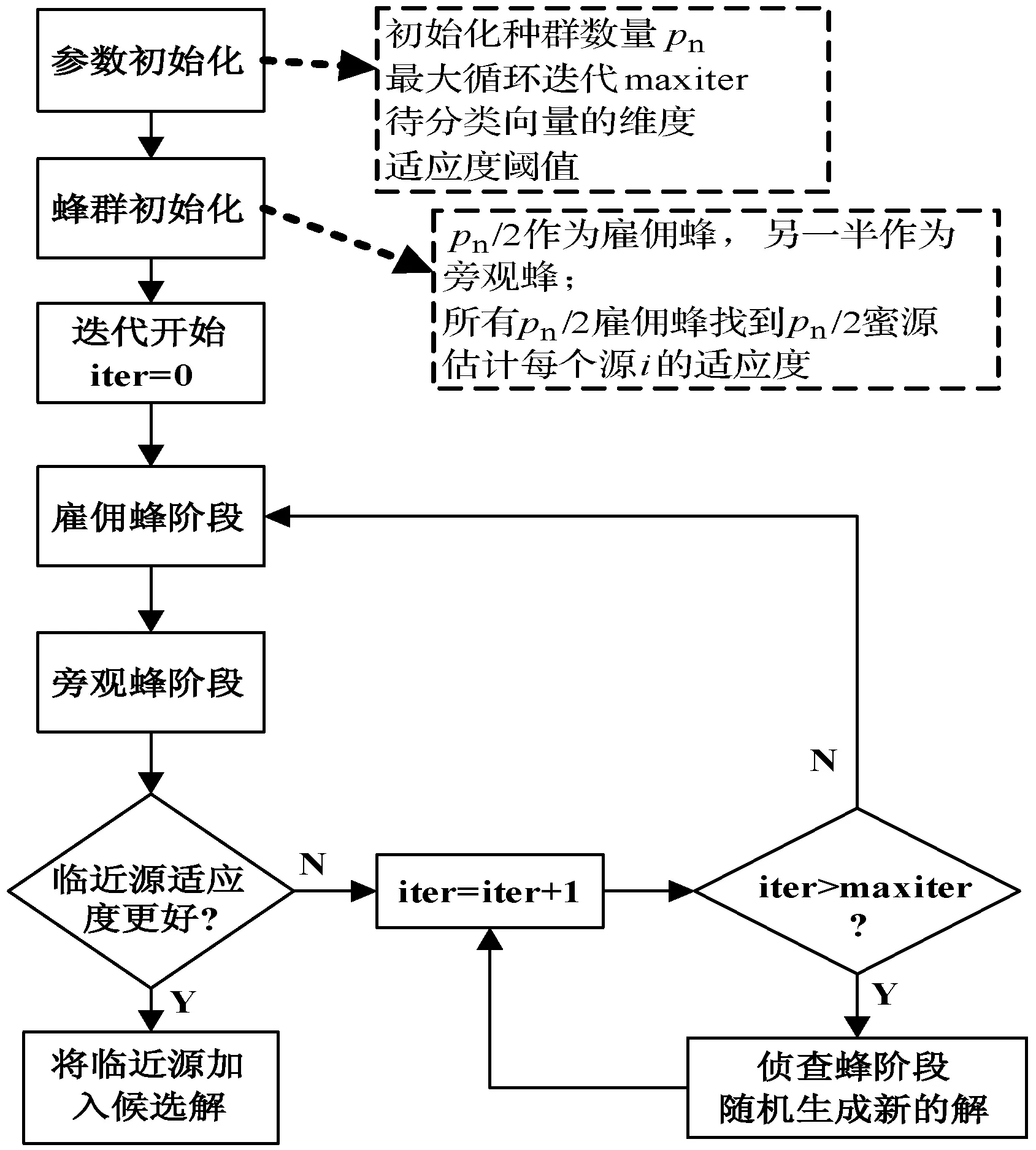
图2 应用ABC算法的流程示意图
1.2 分类(XGBoost算法)
由于入侵检测数据集中包含多个分类,目前很多智能算法(如AdaBoost算法)是针对二元分类设计的,并不适用于多分类问题。因此,本文在XGBoost算法的基础上,利用伪损失的概念来衡量弱假设的优良度。其伪代码如算法1所示。将包含5片树叶的决策树作为基分类器,初始时所有样本权重相等,在每个T中改变样本权重。弱分类器旨在最小化步骤3中的伪损失。如果弱分类器能够不断生成伪损失小于1/2的弱假设,则对其进行增强。
算法1XGBoost算法
输入:m个带标签样本的序列((x1,y1),(x2,y2),…,(xm,ym));yi∈Y={1,2,…,k};弱分类算法DT;迭代次数T。
输出:分类结果hfin(x)。
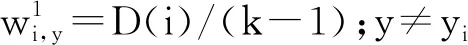
fort=1,2,…,Tdo
2.DT(给出分布Dt和标签加权函数qt)
ht:X×Y→[0,1]

式(5)和式(6)通过XGBoost函数建立网络用户的行为模型,该模型通过对测试数据集的分类进行预测(正常类或攻击类)。
[MDL]=XGBoost(X,t)
(5)
pre=predict(MDL,XTest)
(6)
式中:X和t分别表示训练数据集和样本标签;XTest为测试数据集。然后根据式(7)确定实际情况下的模型误差量,通过重复最大搜索次数的方式确定影响IDS性能的最佳特征。
L=loss(MDL,XTest,GroupTest)
(7)
式中:GroupTest为测试集标签。根据这些最佳特征设定检测操作的参数,这些参数将会影响到运行时间和求解效率。
2 实 验
2.1 数据集
为了评价该方法,本文在NSL-KDD(KDD99修改版本)和ISCXIDS2012数据集上基于MATLAB进行了仿真。网络拓扑如图3所示,在上述数据集中定义不同的攻击场景。仿真参数如表1所示。

图3 混合式计算机网络拓扑
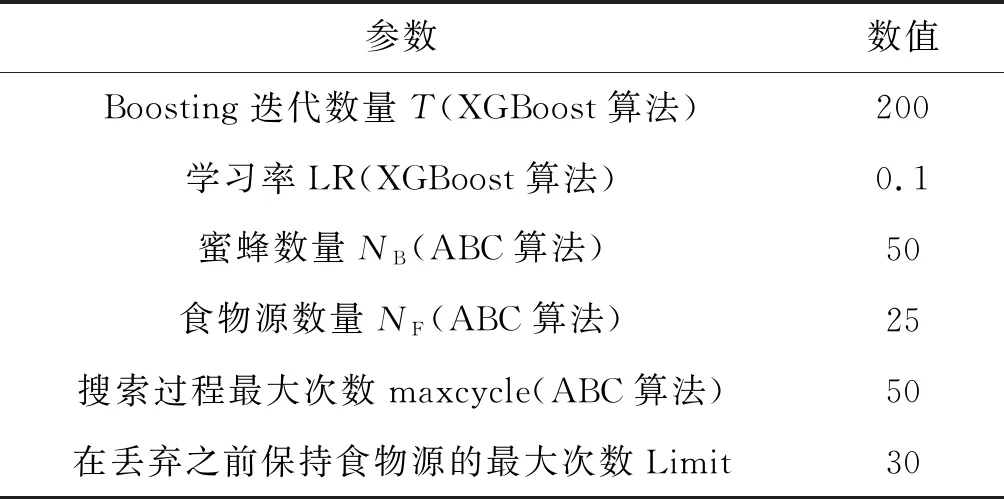
表1 仿真参数设定
2.2 评价指标
鉴于IDS性能存在若干标准,本文在方法验证中计算了检测率DR、虚警率FPR和准确率Ac。具体计算公式为:
(8)
(9)
(10)
式中:TP表示真阳性;TN表示真阴性;FP表示假阳性;FN表示假阴性。其含义为:1) 真阳性(TP):生成警报且确实存在入侵。2) 假阴性(FN):未生成警报,但存在入侵,即漏警。3) 假阳性(FP):生成警报,但不存在入侵,即虚警。4) 真阴性(TN):未生成警报,且不存在入侵。
2.3 仿真结果
本文使用NSL-KDD和ISCXIDS2012数据集来测试本文方法在不同场景下的性能。仿真在MATLAB中完成,训练时间和测试时间分别为2.3 s和32.5 s。捕捉期间每秒的数据流数量在10 MB以上。基于流量可视化的分析[14]使用Wireshark工具绘制,如图4所示。

图4 流量可视化分析的Wireshark工具界面
2.3.1场景1
在场景1中,攻击者使用的攻击类型包括:
1) DoS攻击(拒绝服务):攻击者占用处理有效请求所需的计算资源或内存资源,使得系统无法应答正常的用户请求。
2) R2L攻击(远程到本地):攻击者远程非授权接入系统,使用有效用户账户。
3) U2R攻击(用户到Root):攻击者远程接入网络,并非法获得超级用户权限,使用有效用户账户。
4) 探测攻击:攻击者试图获得计算机网络相关信息。
表2给出了本文方法使用NSL-KDD数据集在场景1下的运行结果,可以看出,该方法成功完成了攻击检测。特别针对攻击特征与正常业务非常相似的攻击类型(识别难度较大),表3进一步给出了场景1下本文方法的运行情况。

表2 场景1攻击的多项检测结果

表3 场景1攻击检测的样本情况
2.3.2场景2
场景2中,攻击者使用的攻击手段包括:
1) 渗透攻击:攻击者首先收集目标相关信息,包括网络IP段、服务器名等。通过使用网络管理工具查询资源记录来实现[15]。
2) 暴力SSH攻击:一种常见的网络攻击,穷举弱用户名和密码组合完成账户入侵。该场景设计是对邮件服务器进行暴力攻击以获取SSH账户[15]。
3) 僵尸网络攻击:将上述行为合并为单个平台,最终帮助平台上的用户执行针对世界各地网络的复杂攻击。此类行为包括扫描、分布式拒绝服务(DDoS)活动等[15]。
本文方法使用ISCXIDS2012数据集在场景2的运行结果如表4所示,其中:正确报警率为86%,错误报警率为14%,虚警率小于等于5%,漏警率为3%,准确率为83%,检测率为73%,误差率为27%。表5给出了本文方法与其他方法的比较结果。可以看出,方法在所有三个重要标准中均显著优于其他方法。这主要因为ABC算法能够避免局部最优区域,选择出最优相关特征,从而实现性能改进。
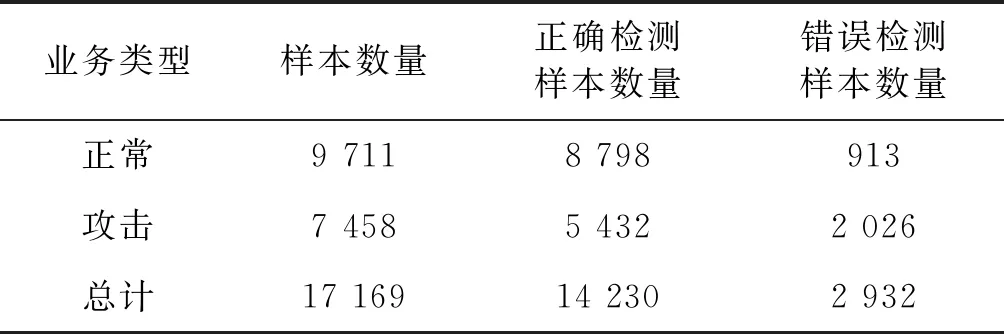
表4 本文方法对场景2攻击的检测结果
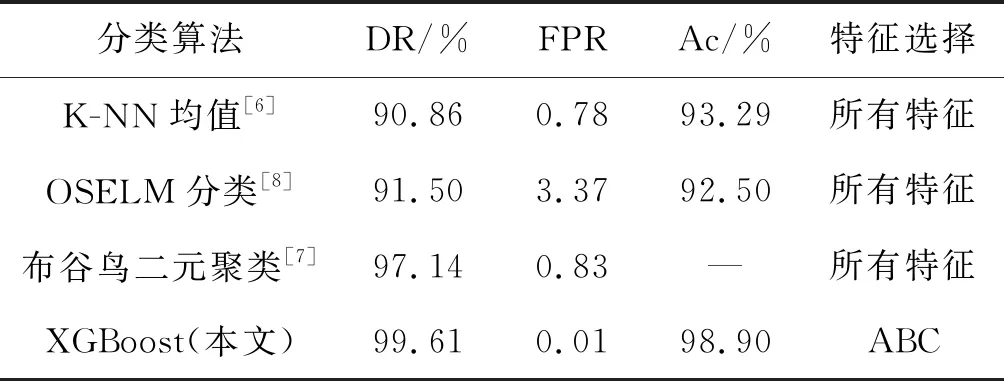
表5 与其他方法的结果比较
2.4 灵敏度分析
表6给出了对于DR、Ac和FPR标准,本文方法在每个特征子集中单独实施的结果。可见,参数T的数量至少要在200以上调整。当T=200时,DR和Ac会随最大循环数的增加而上升,且FPR则会下降。同样,当maxcycle=10时,T增加会带来性能提升。由于相关特征直接影响到分类准确度,循环次数增加会提高选择最合适的分类特征的概率,由此对攻击检测造成积极的影响。另一方面,由于XGBoost的设计能够降低分类中的误差,在迭代次数较高的水平上调整特征数也能得到较理想的结果。

表6 本文方法的灵敏度分析
为了分析NF的影响,以maxcycle=10,T=200运行程序,NF分别为25和50。得到25个解时,DR=98.81,Ac=93.67,FPR=0.093;在50个解时,DR=99.40,Ac=97.50,FPR=0.040。结果表明增加NF能够提升性能。4个实验下的分类误差如图5所示,其中最佳情况下分类误差低于0.006(T=200,maxcycle=50)。
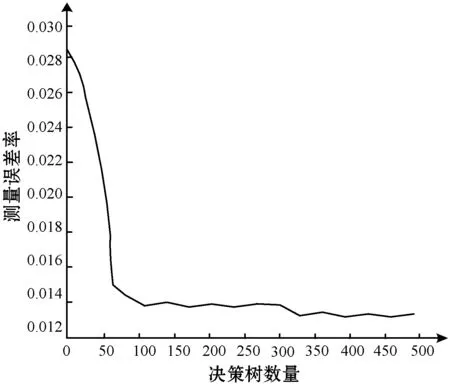
(a) T=500,maxcycle=10的情况
各方法的复杂度结果如表7所示。可以看出,本文方法在攻击检测中表现出很高的效率。在选定的数据集上,本文方法能够以适当的时间和空间复杂度有效检测网络异常,其ABC算法的适应度函数在30次迭代即可达到收敛状态。

表7 时间和空间复杂度结果
3 结 语
网络流量数据集非常大且不平衡,会影响到IDS的性能,其不平衡性会造成传统的数据挖掘算法无法正确检测少数异常类,而少数实例类非常重要。因此本文针对不平衡数据采用了XGBoost算法,使本文方法能够准确地对不同攻击类型进行分类。另一方面,ABC算法适用于优化IDS问题,因此采用ABC算法进行特征选择。在NSL-KDD和ISCXIDS2012数据集上执行了仿真和评价。实验结果表明,该方法在准确度和检测率方面的性能优秀,强于传统方法。
