基于元数据的林业开放政府数据质量评估
2021-03-15温继文
王 博,温继文
(北京林业大学经济管理学院,北京 100083)
1 引 言
林业“开放政府数据”(Open Government Data,OGD)能够释放林业数据价值,提升林业治理精准化,改善林业部门的社会服务能力。我国已建成“国家林业数据共享服务平台”“中国林业数据库”等开放数据平台,但存在规范性差、可读性低、格式单一、难以下载与难以重用等质量问题[1],数据开放仅流于形式,林业开放政府数据的质量问题逐渐得到关注。
提高开放政府数据质量的前提是实现数据管理的标准化和规范化,即运用元数据规范对政府数据进行科学描述,以提高政府数据资源的公众发现和重用[2],元数据质量的优劣直接影响到开放政府数据的质量和效果[3]。目前,国内外学者主要基于元数据元素及元数据记录评估开放政府数据的质量,缺乏系统的开放政府数据质量评估框架和量化方法研究,主要体现在两个方面:一方面,没有分析开放政府数据的“生成-开放-使用”生命周期对数据质量的要求;另一方面,主要从数据的“内容”和“形式”两个角度,选取存在性、完整性和可追溯性等指标进行分析[4],缺乏数据“使用质量”的研究,无法衡量政府数据开放后的效果和价值。
本文分析了林业开放政府数据资源特征,基于开放政府数据生命周期“生成-开放-使用”三个阶段,从开放政府元数据元素及元数据记录,构建全面衡量林业开放政府数据的“数据形式”“数据内容”和“数据使用”质量评估框架、评估指标及其量化方法,为我国开放政府数据质量评估提供理论与方法指导。
2 文献回顾
2.1 开放政府数据的元数据质量评估指标
随着开放政府数据平台资源数量的高速增长,开放政府数据及相应元数据的质量问题也逐步浮现[5]。近年来,国内外学者提出了各种元数据质量评估指标(表1),并逐渐应用于开放政府数据的质量评估的研究中。Moen 等[6]确定了21 个元数据质量标准用于美国政府信息定位服务GILS 的评估;Bruce 等[7]提出了一套与元数据的创建和应用环境无关的评估体系,研究了7 个最常见的质量元数据特征;还有学者研究了数据量、数据获取、完整性、可追溯性、时效性、精确性等开放政府数据质量维度[5,8];也有学者基于不同元数据模式(如DCAT、CKAN、Socrata、OpenDataSoft)评估开放政府数据的元数据质量:存在性、合规性、开放性、完整性、及时性、许可证、关联性、可访问性等[9-10]。然而,大多研究优先评估“数据形式”与“数据内容”质量,对“数据使用效用”的评估内容不够充分,而且这些评估指标的研究不够系统。
2.2 开放政府数据的元数据质量评估量化方法
国外学者较早开展了元数据质量评估指标量化的研究,并在开放政府数据领域进行实践和应用。Ochoa 等[12]研究了Bruce 等[7]提出的七个质量评估指标的量化方法:①计算非空记录数的占比衡量完整性,提出赋予动态权重的加权完整性;②计算用户从元数据实例提取的信息与同一用户可以从资源本身及其上下文获得的信息之间的语义距离衡量准确性;③计算元数据记录内容的信息熵衡量元数据的期望符合度;④将Flesch 指数应用于衡量用户理解元数据实例中包含的信息的容易程度;⑤统计不同时段的前述质量指标,可得及时性和溯源性。张晓娟等[3]将该方法应用于我国省级政府数据开放平台的质量评估中;还提出了开放政府数据的更新性定量指标[14]。Neumaier 等[9]提出利用数据门户模型的度量函数,通过计算相应DCAT 属性集合的平均值来评估元数据的质量度量,于梦月[13]将该方法应用于国内数据开放门户的数据进行质量评估。目前,这些指标及其量化方法,一部分基于元数据结构;另一部分基于元数据实例,没有进行系统全面的总结,而且这些指标的量化方法应用在一般性开放政府数据平台,缺少对行业性开放政府数据平台的研究。总体而言,开放政府数据的元数据质量评估,朝着基于元数据构建定量可测的质量指标,进行自动化评估的方向发展。

表1 元数据质量评估指标
2.3 基于元数据的林业开放政府数据质量
目前,国内已经建设了中国林业数据库开放共享平台、林业科学数据中心等平台,开放了生态、经济与社会三大类具有不同时态、格式多样的林业政府数据。然而,不同形态、时态的数据具有不同的质量要求(表2),没有专有的林业开放政府数据元数据标准,当前已经有开放政府数据元数据标准或规范实行,如DCAT 词汇表、开源数据门户CK‐AN 元数据、美国开放政府数据元数据项目POD(Project Open Data),国内针对林业科学数据与林业资源数据分别设有林业科学数据元数据标准和森林资源数据核心元数据两个标准。这些标准描述了数据集的标识、质量、空间表示、空间参照、内容、数据分发、元数据参考以及引用、时间和联系信息与共享信息等内容。其中,林业科学数据元数据以美国联邦地理数据委员会的“地理空间元数据的内容标准(CSDGM)”和国际标准ISO TC211 为参考。因此,本文结合国际采用的开放政府数据标准(如DC、DCAT、CKAN 等)与林业专业数据的元数据标准,作为本研究依据的林业开放政府数据元数据标准。

表2 林业开放政府数据的内容、格式及质量要求
3 评估框架
基于元数据的林业开放政府数据质量评估,是针对开放政府数据平台中的元数据结构和元数据实例开展的数据质量评估。
开放政府数据质量评估可以借鉴一般的数据质量评估,从数据的形式、内容与效用三个方面开展研究[15]:①形式质量是基于数据的基本结构来考察数据的质量特征;②内容质量是基于数据内容来考察数据对事物状态的表述程度;③效用质量主要考察数据产品对数据用户的效用和价值以及数据满足数据用户需求的程度。
开放政府数据质量评估又不同于一般的数据质量评估,由于开放政府数据存在“生成-开放-使用”的生命周期,每个阶段对数据质量具有不同的要求,因此,开放政府数据的质量评估在不同阶段具有不同的指标。目前,开放政府数据的质量评估大多从“形式质量”“内容质量”层面进行分析,缺乏对“效用质量”评估指标的研究,而且没有结合开放政府数据生命周期的动态性开展研究。
因此,本文提出从林业开放政府数据“生成-开放-使用”三个生命周期阶段与“形式-内容-效用”三个质量层面的两个维度,构建林业开放政府数据的质量评估框架(图1)。
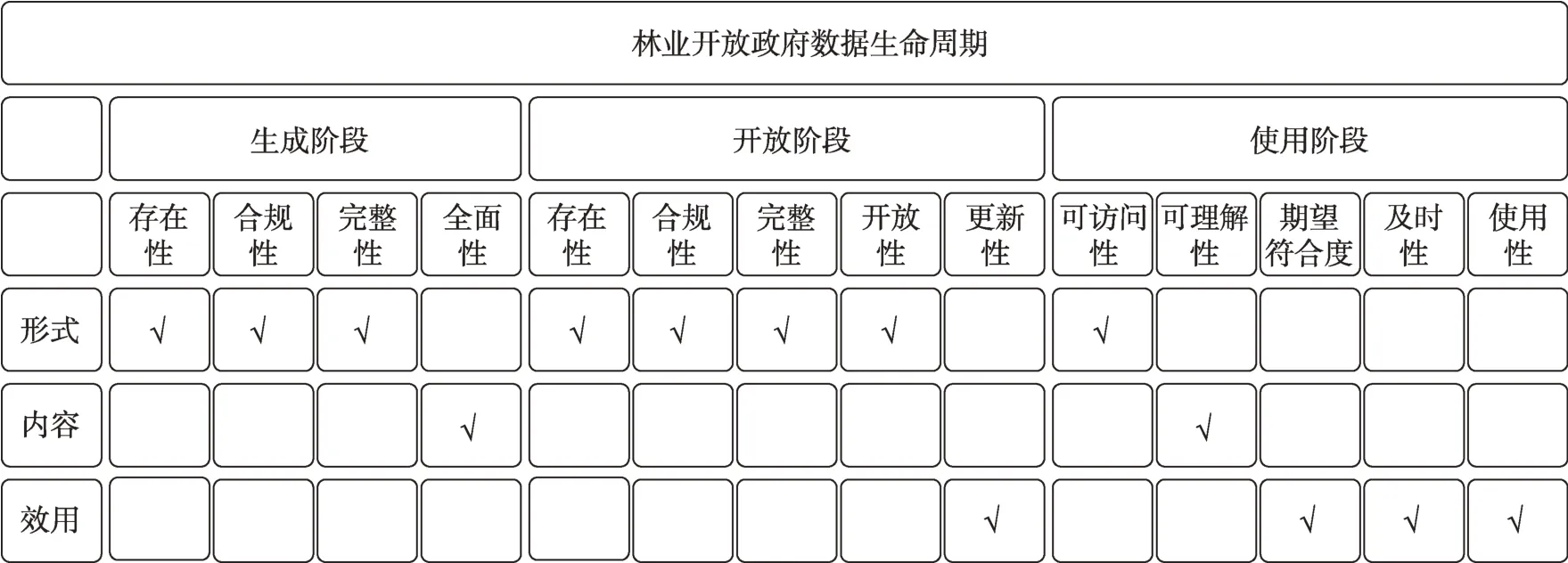
图1 林业开放政府数据的质量评估框架
林业开放政府数据质量的评估需要考虑多个维度,本文选择Bruce 等[7]提出的7 个最常见的质量元数据特征作为基础,因其是独立于元数据的创建和应用环境的评估体系,具有更广的应用范围。本着“科学、全面、针对性强、易操作”的原则,从元数据元素的存在性、元数据记录的完整性、合规性评估元数据的形式质量,基于元数据实例评估数据的内容与效用质量:开放性、完整性、可理解性、期望符合度、更新性和可访问性,达到从“数据形式-数据内容-数据使用效用”对林业开放政府数据进行质量评估。林业开放政府数据的质量评估内容如表3 所示。

表3 林业开放政府数据的质量评估内容
4 基于元数据的林业开放政府数据质量评估指标的量化
4.1 质量评估指标度量模型
林业开放政府数据平台(以下简称“平台P”)提供数据集的元数据描述,m表示平台P上每一个可用元数据描述,一个元数据描述m只对应一个数据集的URL。本文参考文献[9]定义了平台P上一个元数据实例m的基本质量指标的度量模型,即
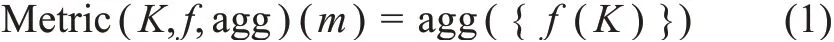
其中,K表示质量评估指标涉及的元数据元素;f(K)指对符合K条件的元数据实例进行的函数操作;agg 为聚合函数,用来指定如何聚合所有元数据实例的f值,还可通过聚合多个基本质量指标形成综合质量指标。
4.2 元数据元素层的质量评估
元数据元素层的质量评估可从三个方面入手:①存在,是指是否提供关键性元数据元素,衡量元数据是否全面、详尽地描述目标资源;②非空,是指在存在元数据关键元素的情况下,其实际的记录值是否存在缺失值;③符合规范,是指某些元数据是否符合格式规范要求。
4.2.1 存在性
存在性是衡量平台已提供的元数据元素存在于元数据标准中的存在率,本文将存在性分为简单存在度与关键存在度。公式(2)为判断元数据元素K是否存在的布尔函数ifExistence:
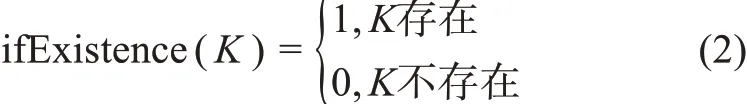
1)简单存在度
Metric(K,ifExistence,max)表示平台P提供的能与元数据标准映射的元数据元素K,使用max 聚合函数,表示存在,记为1;count(all_meta_std)表示元数据标准中元数据元素个数,则平台P的简单存在度为:
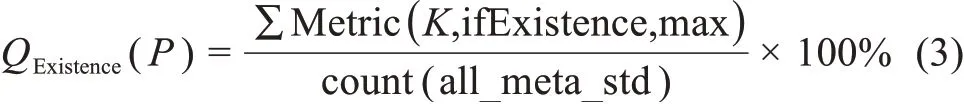
2)关键存在度
关键存在度是指在生成阶段是否提供能够发现/检索、访问/定位信息;开放阶段是否提供数据集的管理、维护信息以及元数据信息等关键元素。本文定义了衡量关键存在度必须有的关键性元素列表(表4),表5 所设的公式(4)~公式(9)定义了计算平台P的关键存在度的方式。
4.2.2 完整性
完整性是指元数据中非空元数据实例的比率,以衡量数据集是否提供了完整的元数据信息,采用简单完整度与加权完整度两个完整性指标来衡量。本文定义了布尔函数nonEmpty,确定元数据元素K的第i个元数据实例Ki是否非空:

1)简单完整度
简单完整度计算了每个元数据元素的非空实例的数量占比。令N代表平台P的元数据实例总数,当平台P的元数据元素K的第i个实例为空时,则Metric(Ki,nonEmpty) = 0,平台P的一个元数据元素K的全部元数据实例的简单完整度的计算方式为

2)加权完整度
并非所有元数据元素都与所有数据资源相关,且与上下文同等重要程度相关,因此,加权完整度提出为每个元数据元素赋予权重,再进行完整度的计算:
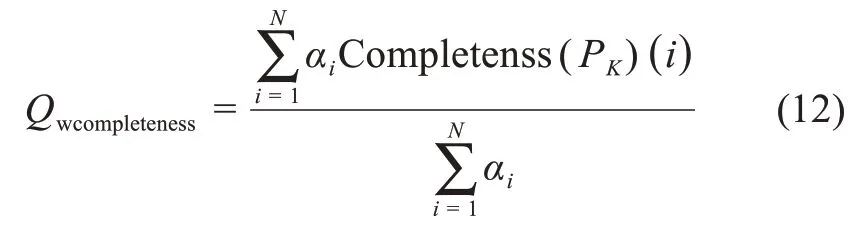
其中,αi为元数据元素K的权重,表示元数据元素对某些上下文或任务的重要性(或相关性)的任何正值,如果更频繁地使用某元素,那么其加权完整性度量应相应地改变,这也体现出加权系数应适应用户需求的变化而变化。

表4 关键性元数据元素说明

表5 关键元数据元素的关键存在度计算方法
在计算平台中各元数据元素的权重时,可依据各元数据元素meta 被用户使用的频数动态确定其权重。本文提出采用熵权法的原理,根据各平台的元数据元素的使用人数占比率求得各元数据元素的权重,进而计算其加权完整度。假设共有P个平台,元数据标准共有M个元数据元素,平台累计使用的用户数为user,M个元数据元素的被使用次数为use,因此可以计算求得各个平台的各元素的使用频率Upm(p= 1,2,…,P;m= 1,2,…,M) (表6),表7为加权完整度的计算步骤。
4.2.3 合规性
合规性是指应具有标准/规定数值内容的元数据元素中合规的元数据实例个数占比。公式(13)定义了检验元数据元素实例Ki是否合规的布尔函数nonCompliance,
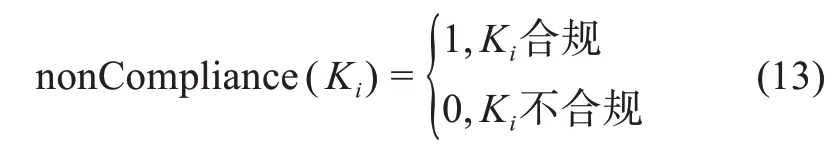
当平台P上K元素的第i个实例不合规时,则Metric(Ki,nonCompliance) = 0。公式(14)计算了平台P的合规性:
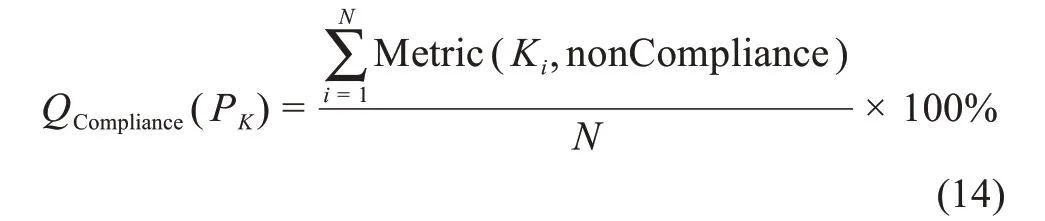
本文提出以下需要具有符合标准/规定输入内容的元数据元素及其合规性检验方式(表8)。

表6 各平台各元数据元素的使用占比数值表

表7 加权完整度的计算步骤
4.3 元数据实例层
4.3.1 全面性
全面性是衡量林业开放政府数据内容的丰富性,如是否提供了林业领域各业务主题的数据内容。由于林业没有统一的开放政府数据资源目录,本文以《政务信息资源分类》[16]为标准,整理出以主题、行业为分类依据的林业数据主题分类目录(表9)。本文将“数据主题”元数据元素作为计算依 据,使 用Python 的difflib 库:difflib.Sequence‐Matcher(None,val1,val2).quick_ratio()进行文本相似度计算,得到表9 中与元数据实例具有最高相似度的标准主题分类,以此来标注现有平台提供的数据内容的全面性。
4.3.2 可理解性
当用户访问/下载所需数据后,接受、理解数据资源内容的容易程度至关重要,因此,衡量元数据相关描述信息能否方便用户理解数据资源内容的容易程度(即用户的可理解性)是元数据的质量要求。Flesch 指数可以应用于分析元数据实例的长文本元素(本文将“数据描述abstract”作为计算依据),当Flesch 指数得分越高,阅读文本越容易。Python 提供了一个计算可阅读性的包textstat,本文采用内置公式textstat.flesch_reading_ease(abstract)计算abstract 文本的易读性指标作为可理解性,

4.3.3 开放性
开放性的提出基于开放知识需满足的三个要求:①可以自由访问;②以机器可读和开放格式提供;③公开授权。要求①在可访问性中已有衡量,本文引入数据格式的开放性、机器可读、开放许可来衡量要求②和要求③。

表8 元数据元素的合规性检验方法

表9 林业开放政府数据主题分类目录
1)格式开放度
本文应用欧盟的开放数据监测器OpenDataMon‐itor 项目对文件格式的评估中定义的非专属格式列表[17]:

本文定义了布尔函数isOpenFormat,

确定数据格式是否在开放格式列表中。若平台P的第i个实例的所记录的数据格式不包含在预定义的开放格式描述列表中,则Metric(Ki,isOpenFormat)= 0。例如,若某数据资源的“数据格式”记录值为“CSV”,则Metric(Ki,isOpenFormat) = 1。公式(17)计算平台P的开放格式数据集比率:

2)机器可读度
本文应用欧盟的开放数据监测器OpenDataMon‐itor 项目对文件格式的评估中定义的机器可读格式列表[17]:
cdf, csv, csv.zip, esri shapefile, geojson, iati, ical,ics, json, kml, kmz, netcdf, nt, ods, psv, psv.zip, rdf, rd‐fa, rss, shapefile, shp, shp.zip, sparql, sparql web form,tsv, ttl, wms, xlb, xls, xls.zip, xlsx, xml, xml.zip
本文定义了布尔函数isMachineReadable,

判断元数据实例Ki的数据格式的机器可读性。若Ki所记录的数据格式包含在预定义的机器可读格式描述列表中,则返回1。例如,若某数据资源的“数据 格 式” 记 录 值 为“CSV”, 则 Metric(Ki,isMachineReadable) = 1。同时定义

计算平台P的机器可读数据集比率。
3)许可开放度
本文应用欧盟的开放数据监测器OpenDataMon‐itor 项目对文件格式的评估中定义的机器可读格式列表[17]:


定义布尔函数isOpenLicense,判断元数据实例值是否在开放定义提供的许可证列表中,以评估指定许可证的方式确认每个数据集的许可证的开放性。若Ki所记录的许可证包含在预定义的开放许可描述列表中,则返回1。例如,若某数据资源的“许可证”实例值为“OGL”,则Metric(Ki,isOpenLicense) = 1。公式(21)计算了平台P的已知/未知许可证使用率:

4.3.4 更新性
更新性指标的设计参考了文献[15],依据数据发布日期与更新日期来划分“存量/增量”数据:数据发布日期在近一年内(2018—2019 年),且在更新周期内保持最新状态的数据(即发布日期与更新日期相同)作为“增量数据”。其余的“存量数据”中超过更新周期而未进行更新的增量数据为历史增量数据,这部分数据没有得到持续的更新积累,随时间的变化价值逐渐降低。本文并从持续性、适时性和活跃性三个方面对两类数据的更新状态进行研究,主要指标有:更新积累度、更新及时度、更新增长度和更新转化度。
定义布尔函数isStockOrIncremental,

判断该数据集的数据类型。其中,Ds为数据首次发布日期;Du为最近更新日期;De为当前调查日期。
1)持续性——更新积累度
持续性的评估对象是存量数据,设更新积累度为U,将实际的数据集版本数Va与理应更新的期望数据集版本数Vp相除,得到更新积累度。当数据集的数据发布日期Ds与最近更新日期Du相同时,按照当前调查日期De为截止时间,数据发布日期Ds为起始时间,如公式(23)所示,U越大,更新积累度越高:
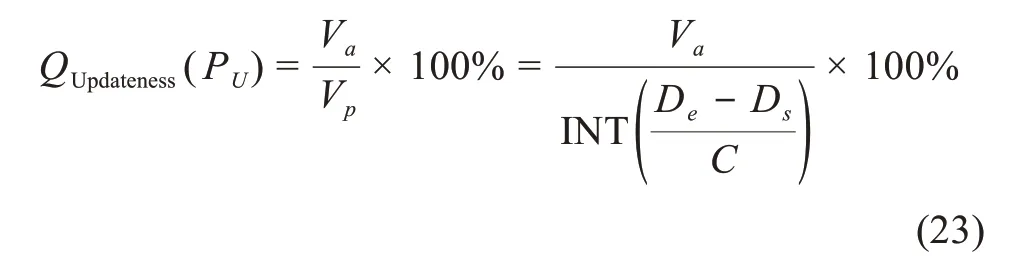
2)适时性——更新及时度
适时性的评估对象是存量数据,以当前调查日期De为基准判断最近更新日期Du是否在规定的更新周期内,计算当前调查日期De与最新更新日期Du的时间差,并与最新更新日期Du与数据首次发布日期Ds的时间差做比较。设及时度为T,则更新及时度为

当Ds=Du≤De时,认为QUpdateness(PT)= 1,此指标的计算值无意义。当Ds<Du=De时,QUpdateness(PT)=0,可认为更新及时度最佳。当Ds<Du<De时,若QUpdateness(PT) ≥1,则认为更新及时度不合格,T值越大,更新及时度越低;若QUpdateness(PT) <1 时,则认为更新及时度合格。
3)活跃性——更新增长度
活跃性的评估对象主要是增量数据,通过计算增量数据相对于存量数据的比重衡量其更新增长度,设存量数据的数量为X,增量数据的数量为Y,更新增长度为Z,则更新增长度为

Z越大,该数据开放平台的增量数据就越多,即其开放的林业政府数据越活跃。
4)活跃性——更新转化度
更新转化度可衡量存量数据中历史增量数据的有效转化比重,设更新转化度为W,未转化的历史增量数据数量为V,则更新转化度为
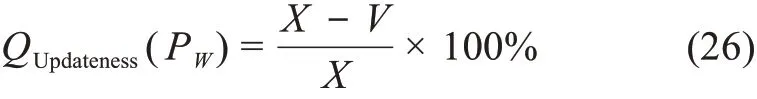
4.3.5 可访问性
可访问性是衡量用户通过平台提供的数据资源访问URL 真正访问到实际数据资源的程度,这是用户使用数据的基础保障。评估内容可分为两部分:①使用正则表达式验证Access URL、Download URL的访问属性的值是否为有效HTTP URL;②通过使用GET 请求返回HTTP 状态代码展示错误状态码的分布。
1)URL 有效度
定义布尔函数isValidURL,
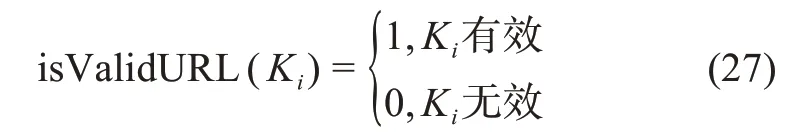
通过正则表达式“[a-zA-z]+://[^s]*”分别检验Ac‐cess URL、Download URL 的有效性。公式(28)计算了平台P的URL 有效度,规定了有效URL 的标识过程:

若平台P的第i个实例的所记录的“访问地址”或“下载地址”其中一个为有效值,则max 函数使得Metric(K{访问地址,下载地址}i,isValidUrl,max)=1。
2)错误状态码
本文定义了函数isErrorCode,

通过获取GET 请求的HTTP 状态代码来计算错误状态码(error status codes)的分布。参考美国“开放数据项目(Project Open Data) ”的仪表板在线系统,分别为5 种状态码给定从0~1 的5 等距得分作为此函数的值。公式(30)使用max 函数统计了平台P中第i个实例的所记录的“访问地址”或“下载地址”返回的状态码函数值,

因而可基于展示出URL 状态码的分布,求得平台P的URL 状态码分值。
4.3.6 期望符合度
期望符合度是衡量提供的元数据内容满足数据用户需求的程度,可通过测量元数据实例信息量的方法来估计其与用户的期望的一致性。熵通常被用来衡量一条信息的信息内容,计算元数据实例的信息熵,需先将元数据元素归为两类:受控值元素的信息量和自由文本元素的信息量[18]。
1)受控值元素的信息量
需从受控词汇表中取值的元素为“受控值元素”,记为control_meta,通过计算平台P上所有元数据实例中该受控值元素中存在value 值的相对频次并将其标准化,使其从最小值0(最低质量)到最大值1(最高质量)变化,
表示平台P上受控值元素在第i个元数据实例中的信息量。设C为受控值元素数量,control_metaj为第j个受控值元素,公式(32)表示平台P上所有元数据实例的所有受控值元素的平均信息熵:

2)自由文本元素的信息量
取值为自由文本的元素为“自由文本值元素”,记为freetext_meta。对于自由文本元素,信息内容计算需要估计每个单词在每个元素中的贡献,因此,选择使用术语频率-逆文档频率(TFIDF)值计算单词的重要性。公式(33)提供了平台P上自由文本信息元素freetext_meta 在第i个元数据实例中的信息量内容的计算:
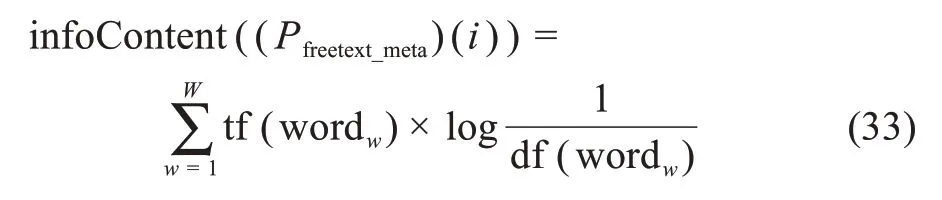
其中, tf(wordw) 表示第w个词的术语频率;df(wordw)表示第w个词的文档频率;W表示该自由文本值元素freetext_meta 中有效词的个数。设T为自由文本元素数量,freetext_metaj为第j个自由文本值元素,公式(34)计算了数据开放平台P上所有元数据实例的所有自由文本元素的平均信息熵:

4.3.7 使用性
使用率的衡量主要基于用户行为数据,本文将用户使用行为归纳为“检索→浏览→下载/分享→反馈”,其使用行为数据包括数据集的被检索次数、浏览时长、浏览次数、下载次数、分享次数与分享目的地,以及评分与评价内容等。因此,本文提出“使用转化度”质量指标,定义了Filler 函数,

来度量每一个元数据实例的相邻用户行为(K1,K2)的转化度。公式(36)计算了平台P上所有元数据实例的该相邻行为的转化度:
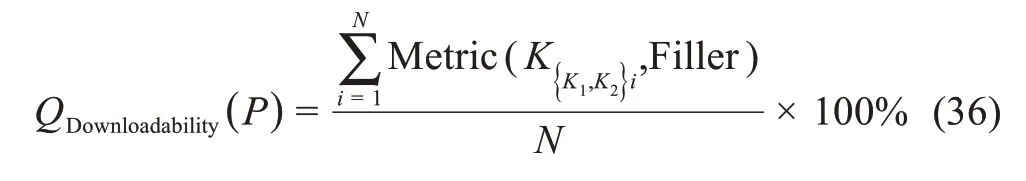
4.3.8 及时性
元数据实例的瞬时值在给定的时间可以等同于其整体质量[12],本文将前述指标的平均值用作平台元数据质量的瞬时估计值。设Qi为第i个指标的度量值,count(Q)为前述指标的数量,公式(37)计算了平台P在当前时间下的元数据质量瞬时值:

设t1、t2、t3为不同时间节点,以t2对应当前时间,t3为期望Qcurr估计的时间,公式(38)通过测量一段时间内瞬时值的变化率来估计元数据实例的及时度Qtime:
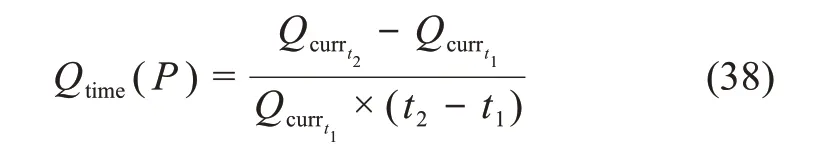
能表明质量变化的方向。Qtime(t2-t1)为(t1-t2)间隔期间的及时度,公式(39)可估计未来时间的元数据质量:

5 结论与展望
5.1 结 论
本文的结论主要有三方面:第一,基于林业开放政府数据资源特征与开放政府数据生命周期理论,分别从开放政府数据生命周期“生成-开放-使用”三个阶段与“形式-内容-效用”三个质量层面,构建了林业开放政府数据质量评估框架;第二,针对目前开放政府数据质量评估中缺乏“效用质量”的研究现状,提出从元数据元素的存在性、元数据实例的完整性、合规性评估数据质量,基于元数据实例评估林业开放政府数据的全面性、可理解性、开放性、更新性、可访问性、期望符合度、使用性与及时性;第三,通过定义质量评估指标度量模型,提出质量评估指标的量化公式,构建全面衡量林业开放政府数据质量评估框架、评估指标及其量化方法,为一般开放政府数据质量评估提供借鉴。
5.2 展 望
本文提出的基于元数据的林业开放政府数据质量评估方法还有待于进一步验证,接下来的研究主要有两个方面。一方面,通过采集现有林业开放政府数据平台的元数据元素与元数据实例,应用本文提出的质量评估量化方法,验证基于元数据的林业开放政府数据质量评估指标的可靠性和可行性;另一方面,林业开放政府数据质量自动评估系统是管控林业开放政府数据质量的重要方式,将质量评估指标的量化方式纳入系统,能够实现定期检测、自动评估开放政府数据平台的数据质量,不仅有助于帮助政府发现开放数据的质量问题,还能使人们以创新的方式使用数据,提升开放政府数据的价值。
