基于局部序列比对相似度的用户会话聚类新方法
2021-03-15姚瑶,周铜
姚 瑶,周 铜
(郑州工程技术学院 信息工程学院,河南 郑州 450044)
1 引言
伴随大数据时代的到来,网络信息无论从数量上还是形态上均增长迅速,尤其是用户行为数据越来越复杂。降低用户访问延迟的核心方法归纳为缓存技术与预取技术[1]。预取技术的关键是页面预测,预测的准确率直接影响预取效率[2],而精准预测的难点在于如何挖掘用户浏览行为的相似性,提高用户会话聚类准确度是关键。
聚类方法分为划分聚类,层次聚类法,密度聚类,模型聚类,基于神经网络的聚类和图论聚类等[3]。利用聚类方法分析大数据环境下用户的行为偏好是近年来研究的热点[4]。通过计算用户会话之间的距离彼此相似度是一种有效方法。但是,由于网络信息的复杂环境影响,用户及其访问行为数量巨大、变化多端,网络会话会根据其不同的性质导致长短不齐,传统的用户相似性判定算法普遍存在数据过于稀疏和计算量过大的问题。
基于计算会话距离从而聚类网络用户的研究始终是焦点。用于衡量用户会话间距离具有较高准确性的方法是序列对比方法(简称SAM)[5],源于氨基酸序列的比对校准,但是侧重于划分基于用户请求的导航序列[6],未曾考虑用户偏好,受限于用户会话因不同的浏览偏好导致会话序列长短不齐的问题。Khasawneh等人[7]采用动态规划的多维会话比较方法,其中页面列表是比较的主要维度,但是计算代价较高。Poornalatha[8]提出了一种有效的基于VLVD函数的K-means算法来对Web会话进行聚类,该算法虽然考虑了可变长度会话的问题,却忽略了页面访问的顺序。文献[9]提出了一种针对大规模数据的快速聚类方法,旨在降低聚类的时间,但聚类效果有所降低。文献[10]介绍了一种基于kullback-Leibler(Kl)散度的相似度度量方法,依据不对称因素评判用户的偏好,该模型适用于稀疏数据。文献[11]采用基于MapReduce的算法,通过贝叶斯网络的概率推理来测量相关度,侧重于发现数据密集型的用户相似性。
上述方法主要集中在对用户相似性的数学模型改进上,却没有充分考虑用户本身的评分偏好,忽略了网络会话的复杂环境。因此,本文提出基于用户会话聚类的页面预测新模型,通过计算序列比对技术的集成距离度量衡量任何两个会话之间的相似度。该方法兼顾用户聚类和评分偏好,重点对最近邻选取和预测评分生成方法进行改进,具有较好的聚类性能。
2 基于页面会话聚类的Web预测模型
预测模型分两个阶段工作:离线和在线阶段,如图1所示。离线阶段在服务器上执行,在线阶段包括服务器和客户端。
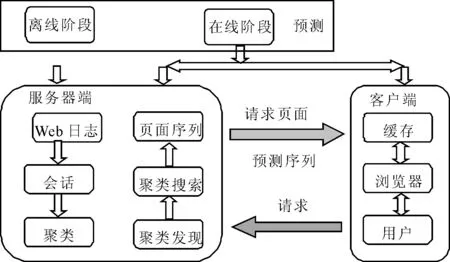
图1 Web页面预测模型
Web日志模块:日志包含每个客户端访问服务器的信息,包括客户端IP地址,访问服务器的日期和时间,HTTP方法(例如get)、请求的URL、响应代码,从服务器传输到客户端的字节数等。用户会话是基于IP地址、日期和时间创建的,由用户在一定时间段内(例如30分钟)访问的一组连续的网页序列组成。 此外,对会话进行过滤以删除图像文件,机器人导航等。从这些过滤的会话中识别出唯一请求,并为每个会话赋予唯一的ID。
聚类模块:将用户会话划分为60%的训练集和40%的测试集。训练集会话部分的聚类由改进的K均值算法获得。随机选择聚类中心,并且中心可能在每次迭代中都发生变化,直到收敛为止。形成聚类后,将对每个聚类进行唯一标识。
客户端模块:每当用户请求网页时,浏览器首先在缓存中查找该网页是否存在。如果找到该页面,则立即检索该页面并将其显示给用户,否则将请求转发到实际的Web服务器。该请求由用户访问的一组页面组成。服务器通过发送所请求的页面以及预测列表进行响应。当浏览器空闲时,它将尝试下载预测列表中列出的网页,这些网页目前在缓存中。当用户请求下一页时,用户立即从本地缓存中获取页面,并且用户立即获得响应。因此,通过预取网页,可以使用户等待时间最小化。
聚类发现模块:在线阶段预测的第一步,通过使用集成距离度量将请求与所有现有聚类中心进行比较,可以确定最接近请求的簇。
聚类搜索模块:根据从聚类发现模块获得的聚类搜索请求的网页,检索下一个页面,并根据聚类中下一个页面所在的会话数以及当前请求的页面数来认定下一个页面的计数。
页面序列模块:主要认定聚类搜索模块接收的页面列表。
3 基于用户会话距离集成测量的聚类方法
对于给定的任意两个用户会话,为了计算彼此间的有效距离,需要查找会话间的匹配对。如果两个页面是相同的,则认为它们是匹配的。对于不匹配序列,则需要经过插入/删除/替代操作后使其成为相似序列,然后对匹配和不匹配序列进行有效评分。目的是找到两个会话间的两两比对数,插入/删除/替换操作被认为是相同的(不匹配)。为匹配和不匹配适当的计分,分别为2和-1。通过计分,构建页面对的评分矩阵,通过矩阵计算可得两个Web用户会话的距离,从而进一步计算会话间的相似度。
3.1 局部比对算法(SAM)
著名的局部比对算法最早由Smith-Waterman提出[12],主要用于对共同分子子序列的局部比对,其中相似性的度量考虑到了任意长度序列的删除和插入。对于不够相似的序列局部比对显得更为有应用价值,序列排序SAM方法可以有效衡量用户会话间距离,侧重于划分基于用户请求的导航序列。一组会话的两个会话序列包含的Web页面分为两种,共同页面和单独页面。共同页面为两组会话均访问的页面,单独页面表示各自访问的独立的页面,与其他会话并无交叉。为了使两组会话更为相似,两组会话中相同的页面被重新排序,彼此结合,单独的页面被插入或删除。插入操作、删除操作和重排操作的数量被用来计算两组会话间的距离。排序操作改变的序列中,Web页面是在一个会话访问。SAM方法中关于会话距离的计算公式如式(1)所示,参数说明如表1所示:
dSAM(S1,S2)=MIN[(wdD+wiI)+δR]
(1)

表1 SAM计算方法参数说明
从公式(1)可以看出,采用两会话间的距离由删除操作、插入唯一元素和重排共同元素的开销构成。由于删除和插入是单独操作,故ωD和ωI假设为1,并且δ=ωD+ωI。如果共同页面的数量过多,但是访问的页面顺序又不相同,那么需要花费较大的开销查找共同元素并重新排序的计算操作。SAM方法无法区分出完全不同的会话和有相似序列的会话。
3.2 基于会话距离的局部序列比对方法(SDM)
鉴于SAM方法存在计算量大并且尚未考虑相似序列的会话等问题,本文对该方法做适度改进,通过引入评分矩阵、距离矩阵和线索矩阵的构建,将该方法有效应用在衡量任意两个用户会话的距离,从而判断用户的相似性,简称SDM方法。该方法采取通过计算用户会话间页面匹配数量的情况衡量会话的相似度,从而达到为用户分组目的。通过衡量用户之间的会话距离来度量用户会话的相似度。
若给定两组会话序列S1=(ABCDE)和S2=(ACDBE),会话长度m=5,n=5,mismatch=-1,match=2。
计算用户会话距离的主要步骤表现在构建评分矩阵、构建距离矩阵和计算线索矩阵,最后依据上述的三个矩阵计算会话的相似度。
3.2.1 构建评分矩阵
构建(m+1)*(n+1)的用户的评分矩阵,记作Ps,公式如下:
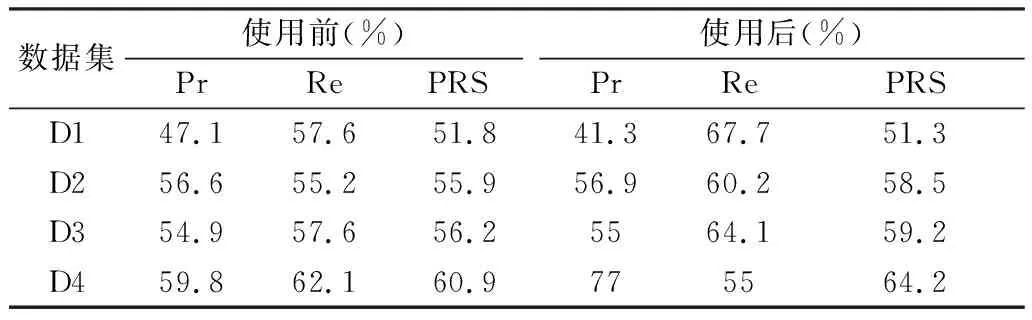
Ps(i,0)=mismatch,其中0 Ps(0,i)=match,其中0 (2) 如表2所示,构建了会话S1和S2的评分矩阵,其中Ps(i,j)代表两组会话对应页面是否匹配,匹配计分2,否则计分-1。初始化该矩阵的第1行第1列为0,第2行第1列为-1。对于i如果S1(i)=S2(j),代表匹配,否则代表不匹配。 表2 会话S1和S2的评分矩阵 3.2.2 构建距离矩阵Pd 计算会话间对应页面的比对距离Pd(i,j),其中i∈(0,m+1],j∈(0,n+1],计算方法如式(3): Pd(0,j)=Pd(0,j-1)+mismatch Pd(i,0)=Pd(i-1,0)+mismatch (3) 其中,第一项参数0概况了当比对评分为负时忽略不计的情况;第二项和第三项参数表示为插入/删除/替换操作插入一个空缺所执行的延伸操作;第四项考虑到对两个会话延伸序列的每一页的比对。给定序列两会话的Pd如表3所示。 表3 会话S1和S2的距离矩阵Pd 3.2.3 构建线索矩阵Pp 在计算Pd的同时构建线索矩阵Pp,主要为后续的遍历工作做准备。首先,初始化该矩阵的第0行和第0列值为0。然后,根据Pd(i,j)的取值来源数据单元的所在位置top/left/left-top为Pp(i,j)分别赋值为1/2/3。 给定会话序列的线索矩阵如表4所示。 表4 会话S1和S2的线索矩阵Pp 3.2.4 相似度计算 依次构建评分矩阵、距离矩阵和线索矩阵后,开始计算用户会话的相似度。具体计算方法是遍历Pd,确定其中最大值的位置单元,对应在Ps中检查是否匹配,如果匹配则SimCount值加1。同时,在Pp中根据Pp(i,j)的取值确定下一次的线索。重复遍历Pd,直至其中出现值为0的单元。若Pd中多个单元格包含相同的最大值,重复上述步骤。 会话相似度的计算方法依赖于会话间的相似页面的个数,会话距离度量方法参见式(4)。 dSDM(S1,S2)= [Max(m,n)-SimCount]/Max(m,n) (4) 其中,m和n分别代表会话S1和S2的长度;SimCount代表采用局部序列比对后的子序列数量;d∈[0,1],1表示两会话完全不一样,0表示两会话极度相似。因此,SDM可以区分完全不同的会话。 示例中的会话S1和S2的相似度经计算为0.2。 3.2.5 SDM算法 算法1:基于距离测量的序列比对算法 Input:用户访问会话序列S1,S2 Output: d(S1,S2) Method: Step1.根据式(2)构建Ps; Step2.根据式(3)构建Pd,同时修正Pp的值; Step3.遍历Pd,确定其中最大值的位置MaxValLoc(i,j) If (Ps(i,j)=2) SimCount=SimCount+1; 扫描Pp(i,j)的值,确定next(i,j); Step4.Repeat Step3直到Pd(i,j)=0; Step5.If MaxCountPd(i,j)!=1 Repeat Step3; Step6.根据式(4)计算d(S1,S2)。 由于在SDM中缺少对两个会话之间存在的直接匹配方式和通过插入间隙获得的对齐方式的区分,进而提出基于集成距离的用户会话相似度度量方法(SADM),该方法融合SAM和SDM计算方法,可以获得更准确的距离度量,既找到了SAM 方法中的单独序列数量,又可基于SDM方法获得无须调整页码顺序的序列数量。该方法实际上捕获了一对原始会话之间的序列方式,也获得了局部比对后的比对序列和它们之间的唯一元素。计算方法如式(5)。 dINTE(S1,S2)= (5) 其中,dINTE(S1,S2)代表两会话间的集成距离。 CAP-表示未匹配页面的数量,一对会话的唯一网页,不能通过插入间隙对齐。例如,如果S1=(A,B,C,D)和S2=(A,B,C,E),那么D和E是唯一的。因此CAP-=2;CAP-表达含义等同于与SAM方法中的(wdD+wiI)。 CAP+表示匹配页面数量,是通过SDM方法找到的匹配序列,可以通过插入间隙来对齐, 例如,S1=(A,B,C,F,G,H)和S2=(A,F,G,J,U),则在S2中的A之后插入两个间隙后,页面F和页面G分别与S1的F和G匹配,故CAP+是2。 CPD表示直接比对数量,指在原始会话中匹配的页码,例如,S1=(A,B,C,F,G,H),S2=(A,E,G,F,U),CPD为2。两会话的页面A与页面F彼此匹配,页面A位于会话的第1位,F位于第4位。|S1|与|S2|分别表示其会话的长度。 |CAP+-CPD|给出实际的页面数可以通过插入间隙来对齐。即插入间隙是一项操作,移动现有页面插入间隙的位置是另一种操作,故乘以系数2。 例如,给定会话:S1=(ABDFCABEDHGB),S2=(ABGGEDABFEHGC),匹配的路径过程如下: AB--EFCAB-EDHGB||||||||ABGGED-ABFE-HGC 分析序列,-表示间隙,|表示匹配。页面AB是直接匹配,故CPD=2;经插入间隙操作后获得的匹配页面数CAP+=6;依据SAM剩下的单独页面是G,G,B,故CAP-=3;经计算,dINTE(S1,S2)=0.44,即表示两会话的相似度为0.44。集成距离度量方法可以实现在不对序列做任何修改的前提下获得任意两个任意长度的会话之间距离。 为了进一步验证用户相似度的实际性能,将其应用于用户推荐的相关实验,分别与Needleman-Wunsch全局比对算法(以下简称NW方法)和SAM算法比较,该方法应用于基于用户相似度的Web预取系统取得了较好的推荐效果,并在用户会话挖掘上表现了有效性。 与NW相比,该方法最大的优点在于能够发现序列间的序列,因为该方法搜寻的范围是在相似区域内的序列,而不是调整每一个序列的残基。因此,所获得距离值小于NW方法。例如,参见会话示例S1=(ABCDE)和S2=(ACDBE),NW方法为页面A排序。观察会话S1和S2,访问完A后均访问C和D。唯一不同的是,S1中在访问C、D之前还访问了B,S2中用户直接访问的C和D。说明在页面A、C和D之间有某种关联性。在NW方法中,这种信息无法获取到,但是在SADM的算法中可以挖掘出该关联性,换言之,本文的方法搜索的序列数量将远远大于NW方法。与SAM相比,SADM侧重基于插入、删除和重排序方法查找会话间的集成距离,获得的距离与SAM方法相比更有可比性。 实验通过对不同的会话序列分别采用三种传统方法进行测试,计算会话间的集成距离。首先采用简短会话序列进行比对,分析不同方法的优劣。然后采用真实日志文件,基于Markov模型建立用户访问路径序列,最后将其用于Web预取系统,衡量预取效果,并根据会话的相似度对用户进行聚类,分析其聚类效果。 选取准确率(Pr)、召回率(Re)、预取综合性能指标(PRS)以及聚类比率对实验结果进行评价。其中PRS计算公式如下: (5) 其中,P+和P-分别表示正确的和不正确的预测数,R+表示模型预测的请求数,|R|表示总请求数。 实验一,选用4组不同会话序列,分别采用NW方法、SAM方法、SDM方法和SADM方法计算给定会话的集成距离。 表5 会话距离比较 如表5可以看出,本文提出的方法测量的会话距离较其他方法表现出了优势。由于SADM方法挖掘了会话间隐含的序列,会话间的集成距离值相对较近,更为精确。因此,考虑到两组会话的长度不等的问题,通过保留导航序列的相关信息尤为重要,SADM方法计算所得会话距离更为有效,那么聚类的准确率越高。 实验二,针对聚类后的会话序列应用于预取系统,分析其预取效果。其中预测分为两个阶段,在第一个阶段通过预处理服务器日志文件创建会话,60%的会话作为训练集,经过集成聚类法对其聚类。一般情况下一个聚类总会包含一些单独页面,但是像起始页面可能会出现在不止一个聚类中这种情况是可能的。另外,聚类是基于用户访问页面的序列产生的,不是基于访问页面的类型。实验中,为评估本文的预测模型要求而对最后一个页面进行预测。测试会话的最后一页先被删除,其余页面被用来查找最近的聚类中心。例如会话序列(P1,P2,…,Pn-1,Pn) ,页面P1到页面Pn-1用来查找最近的聚类,一旦查找成功,只有最后一个页面如Pn-1用来预测下一个页面。实验选取信息网络重点实验室日志文件为数据源,数据清洗后进行会话聚类,然后应用于预取系统,使用SADM方法前后的预取效果如表6所示。 表6 预取效果比较 依据表中实验结果可知,随机抽取的四组数据集中,在使用SADM聚类方法后仅有第一组数据的准确率稍微有些降低。由于聚类使得状态特性趋于一般化,四组数据在召回率方面表现很好,均有提高。综合两方面,对PRS指标的影响也是积极的,聚类后使得PRS上浮了3%左右。 对比本文改进的SADM方法与NW、SAM、SDM三种聚类方法对预取性能(PRS)的影响,如图2所示。 图2 不同聚类算法对预测模型的综合影响 整体上,数据越密级,页面相似的可能性越大,三种方法的预取性能越有优势。当数据密集度低于10%时,NW和SAM算法对于数据的稀疏性并不敏感,预取效率维持在不高的水平。而SADM模型采用的聚类算法相比传统方法在预取效率方面有明显的优势,具有可行性和高效性。 随着网络应用的大面积普及以及网络对象的爆炸性增长,通过分析用户会话挖掘其相似性,并应用在Web预取系统有很大的意义。本文通过对传统SAM的局部比对算法进行改进,提出了一种基于提取共同分子子序列的序列比对(SADM)计算会话距离的用户聚类方法。文中首先考察为不同会话构建评分矩阵;再者,通过计算会话间相应页面的比对距离构建距离矩阵,具体地引入线索矩阵为后续的遍历做铺垫;最后,选取会话长度不一的数据集进行测试分析,并将改聚类结果应用于预取系统,分析预取效果。实验验证了该模型有较好的聚类效果并在预取性能方面具有一定优势。由于SADM方法兼顾了不同会话长度的问题和保留用户访问页面序列的问题进行测量会话的长度,通过对用户会话的合理度量,可以进一步地对用户聚类,从而能够更好地应用在页面预测、Web缓存和预取中。进一步的工作,将该方法用于大数据背景下的用户聚类中,考虑基于滑动窗口的预测模型,增加数据集数量进行综合评价,进而改进聚类效果。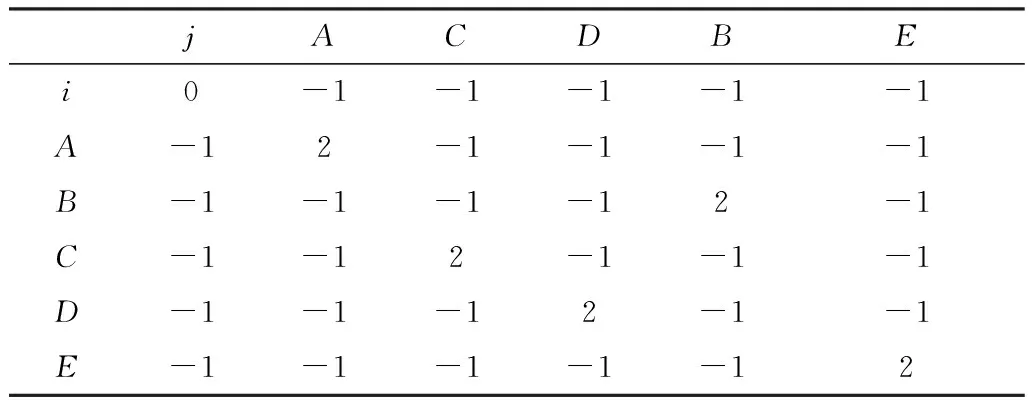


3.3 基于集成距离的用户会话相似性度量方法(SADM)
[CAP-+2(|CAP+-CPD| )]/(|S1|+|S2|)
4 实验结果与分析
4.1 实验设计
4.2 实验结果


5 结语
