基于改进LMD和综合特征指标的滚动轴承故障诊断
2021-03-15辜志强林月叠
辜志强, 林月叠
(武汉理工大学 现代汽车零部件技术湖北省重点实验室,湖北 武汉 430070)
滚动轴承是机械设备中常见且重要的零部件,在汽车、航天、冶金等国家支柱行业有着广泛的应用。一旦滚动轴承发生故障,轻则影响设备的使用,重则会造成巨大的经济损失和人员伤亡。因此,滚动轴承的故障诊断是必须面对的重要课题。对滚动轴承故障诊断技术的研究具有重要的经济意义与社会意义。
滚动轴承发生故障时,其振动信号表现出非线性、非平稳的特征,同时也蕴含了大量的轴承状态信息。利用信号处理技术对采集得到的滚动轴承振动信号进行故障分析,是一种有效的方法。在各类信号处理技术中,基于傅里叶变换的经典谱分析方法并不适用于非线性信号,而能兼顾信号时域、频域的局部与全貌的时频分析方法十分适用。文献[1]提出一种新的自适应时频分析方法,即局部均值分解(local mean decomposition, LMD),结果表明其效果优于其他时频分析方法,受到了广泛的重视。该算法能够自适应地将一个成分多样的非平稳信号分解成一系列具有明确物理意义的乘积函数(product function,PF),最后对分解后的信号进行重组就可以获得原始信号的时频分布。文献[2]利用奇异值分解与LMD结合,有效检测出滚动轴承故障。文献[3]将LMD与拉普拉斯特征映射(laplacian eigenmap, LE)算法融合,实现非平稳的滚动轴承故障特征提取。但是由于端点效应等影响[4],振动信号在经LMD分解后,往往会出现模态混淆的问题。针对端点效应的问题,目前主要有波形延拓法以及数据预测延拓法[5-7]。这些方法都起到了一定的作用,但也存在一些不足。比如神经网络等数据预测延拓方法,实际效果受算法参数影响,且计算时间长;镜像延拓方法无法考虑信号内部变化规律。信号经LMD分解后,往往只有部分信号分量会包含有故障特征信息,即敏感分量[8],而剩余部分则是干扰成分,对故障特征提取没有帮助。如果简单地采用相关系数、峭度等单一指标[9]来选择敏感分量,那么可能会存在遗漏。也有学者采用不同的方法,文献[10]利用LMD与Kullback-Leibler(K-L)散度相结合的方法,准确有效地区分出有效PF分量。
本文提出一种基于匹配误差的四点波形延拓方法,按照信号内部的变化规律以及匹配误差最小的原则对原始信号进行延拓,以此来改善端点效应;然后将改进后的LMD应用于滚动轴承振动信号的分解,通过将综合特征指标与K-means聚类算法相结合的方式,从分解后的PF分量中挑选出“敏感分量”进行重组;对重组后的信号进行频谱分析,可以成功提取到故障特征信息。
1 LMD信号分解
1.1 LMD原理
LMD是由经验模态分解(empirical mode decomposition, EMD)方法原理发展而来的,是一种性能优越的自适应时频分析方法。采用LMD方法的分解步骤[5]如下:
(1) 首先按顺序找出原始信号x(t)的所有极值点,定义为ni,然后计算全部的局部均值mi和局部包络值ai,即
mi=(ni+ni+1)/2
(1)
ai=|ni-ni+1|/2
(2)
(2) 将所有的局部均值mi和局部包络值ai分别用直线相连,再进行平滑处理,也可用样条函数插值法处理,求出局部均值函数m11(t)和局部包络函数a11(t)。
(3) 从原始信号x(t)中减去局部均值函数m11(t),可得:
h11(t)=x(t)-m11(t)
(3)
再除以局部包络函数a11(t),可得:
(4)
(4) 验证s11(t)是否为纯调频函数。计算s11(t)的包络估计函数a12(t),若a12(t)等于1,说明s11(t)已经是纯调频函数,则迭代结束,否则将s11(t)作为原始信号重复步骤(1)~步骤(3)的计算,直到得到纯调频函数s1n(t)。
(5) 将上述迭代过程中产生的所有包络估计函数相乘,可以得到包络信号a1(t),即
a1(t)=a11(t)a12(t)…a1n(t)
(5)
将a1(t)与s1n(t)相乘可以得到原始信号的第1个PF分量,即
PF1(t)=s1n(t)a1(t)
(6)
(6) 从原始信号x(t)中减去PF1(t),得到新的信号u1(t)。将u1(t)视作新的原始信号重复上述步骤,循环j次,直至uj(t)变成单调函数。
此时,原始信号x(t)经LMD分解后变为j个PF分量和1个残余分量uj(t)之和,即
(7)
容易发现,PF分量的理论表达式与调幅-调频信号一致。因此,可以容易地从PF分量中提取得到信号的幅值调制特征和频率调制特征,具有明确的物理意义。
1.2 端点效应改进
端点效应的产生,是因为LMD的计算过程中,需要使用到局部极值点的数据,但是信号两端的端点可能并不是极值点。如果运算时简单地将端点视为极值点,那么必定会存在误差。而且随着算法循环次数的增加,这种误差会使得信号由外向内逐渐失真。波形延拓是一种有效的改善方法,主要思路是在信号的左右两端各自延拓新的波形,将端点效应产生的影响转移到原始信号外部。本文提出一种基于匹配误差的四点波形延拓方法改进LMD,按照信号内部的变化规律以及匹配误差最小的原则来找到延拓波形。具体延拓步骤如下:
(1) 对于给定的原始信号x(t)(t=1,2,…),找出信号的极值点序列ni(i=1,2,…)。首先以包含x(1)、x(n1)、x(n2)、x(n3)的波形作为特征波形S,长度为L,如图1所示。其中:x(1)为波形左端点;x(n3)为波形的右端点。
(3) 找出匹配误差计算值最小的匹配波形,以其左端点x(i)的前一点x(i-1)作为延拓波形的右端点,向左截取长度为L′的波形作为延拓波形。将延拓波形左移至x(1)前,完成信号左端点延拓,L′可依据实际情况自行选择。按照类似的方法,可以完成信号右端点延拓。
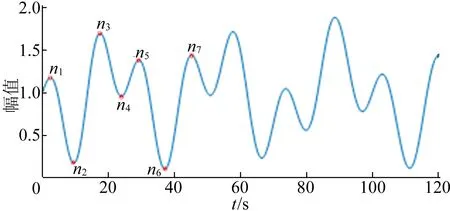
图1 波形示意图
匹配误差定义为峰值误差、绝对误差、差值误差之和,如图2所示。图2中,黑色线为原波形S,红色线为某一匹配波形S′。各项误差的公式定义如下:
(8)
(9)
(10)
E=E1+E2+E3
(11)
从图2可以看出,匹配误差越小,波形的形状与变化趋势就越相似。四点波形延拓使得特征波形内包含一个波峰和一个波谷,相比常见的三点波形延拓,能包含更多的信号波形变化规律,在寻找匹配波形时能更加准确。
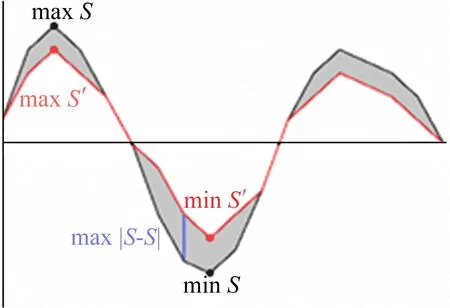
图2 匹配误差示意图
采用文献[11]中的仿真信号与端点效应评价指标来进行对比分析。仿真信号x(t)如下:
(12)
采样频率为12 000 Hz,采样时间为0~0.1 s。采用镜像延拓法、BP神经网络预测法、本文提出的方法进行对比,结果如图3所示。图3中,蓝色波形为原始信号,红色波形为延拓波形。从图3可以看出,相比其他2种方法,四点波形延拓的结果更加符合信号变化规律。信号有效值与端点效应评价因子计算公式如下:
(13)
(14)
其中:n为采样点数;Rx、Rp、Ru分别为原始信号、PF分量、残余分量的有效值;k为分解所得的PF分量数量。分析可知,θ值越小,说明端点效应对信号分解的影响越小。
对比不同的方法,结果见表1所列,说明本文所提方法是有效的,且受端点效应影响更小。
针对上述应用案例,分别采用5M预评价法和一般评估法进行评价。一般评估法采用文献[19]所制定的由设备和管理要素建立的“信号设备评价表”作为参考[19],并按照评价表的定性定量指标采用专家打分法进行预评价。两种方法实施效果对比如图2所示。

图3 3种波形延拓法对比

表1 各类方法的θ值
2 故障特征提取
从理论上来说,每个PF分量对应着原信号的某一个时间尺度特征。但在实际应用时,由于分解精度、端点效应、噪声等问题,原信号中相似的时间尺度特征被分解到不同的PF中,原信号中的时频特征不能与分解后的PF分量一一对应,因此产生模态混淆的现象。实际采用LMD方法对采集到的振动信号进行分析时,会获得若干PF分量,但是其中仅有一部分保留了故障特征信息,可称之为敏感分量;剩余的虚假分量不包含故障特征信息,对故障诊断没有帮助。要对设备真实的运行状态进行准确的判断,就需要正确分辨出敏感分量,进一步进行频谱分析。
滚动轴承产生的故障信号具有周期性、脉冲性特点,分解过后的某些PF分量会蕴含这部分特性。因此,在一定程度上这些敏感分量可以视为故障信号分量。以往的研究常常采用单一的指标对PF分量进行分类,这会导致分类存在不稳定性。本文采用基于综合特征指标与K-means聚类算法相结合的故障特征提取方法。
2.1 综合特征指标

本文选取信号在时域上的峰值因子、波形因子、峭度因子、裕度因子、脉冲因子、峭度、偏度、能量共8个特征指标,作为综合特征指标。信号经LMD分解后得到N个PF分量,分别计算每个PF分量的8个特征指标。再使用K-means聚类算法对N个PF分量进行分类。
2.2 K-means聚类算法
K-means聚类算法是基于静态数据对象之间相似度的动态硬聚类算法,采用距离作为相似性的评价指标。当2个对象的距离越近,就认为两者相似度越高。聚类的最终目的是使得各个类别的总的距离平方和最小[13],定义如下:
(15)
其中:J为总的距离平方和;K为类的个数;n为个体总数;xi为第i个个体;μk为第k个类中心。
K-means聚类算法处理过程如下:
(1) 从数据集中随机选取K个样本作为初始中心点,依次计算所有数据样本到所选的K个中心点的距离。
(2) 将样本分配到计算距离最小的聚类中心所在的类别中。
(3) 针对每个聚类的类别,重新计算它的聚类中心。若聚类中心位置发生变化,则重复上述算法过程,直至聚类中心不再改变。
当故障特征被分解到多个敏感分量上时,相比于虚假分量,这些多个分量会更具相似性。利用K-means聚类算法,可以有效地区分敏感分量与虚假分量。
2.3 故障特征提取步骤
对振动信号采取如下的分析步骤:
(1) 采用改进的LMD对振动信号x(t)进行端点延拓后分解信号,得到N个PF分量。
(2) 分别计算每个PF分量的综合特征指标,使用K-means聚类算法对N个PF分量进行分类。
(3) 分类完成后,重组同类的PF分量,对重组信号进行频谱分析。
3 实例分析
本节利用美国凯斯西储大学轴承实验室公开的轴承故障数据对上述方法的有效性进行验证。试验轴承是SKF6205-2RS型深沟球轴承,采用电火花加工技术在外滚道引入了0.178 mm的故障。选取的故障数据编号为OR007@6-0,采用其中的驱动端数据作为故障信号。试验采样频率为12 000 Hz,电机转速为1 797 r/min,滚动轴承外圈故障频率理论计算公式如下:
(16)
其中:fr为轴转动频率,fr=29.95 Hz;n为滚动体个数,n=9;d为滚动体直径,d=0.008 m;D为轴承节径,D=0.04 m;α为接触角,α=0°。经计算可得外圈故障特征频率fc为107.82 Hz。滚动轴承故障信号时域图和频域图如图4所示。
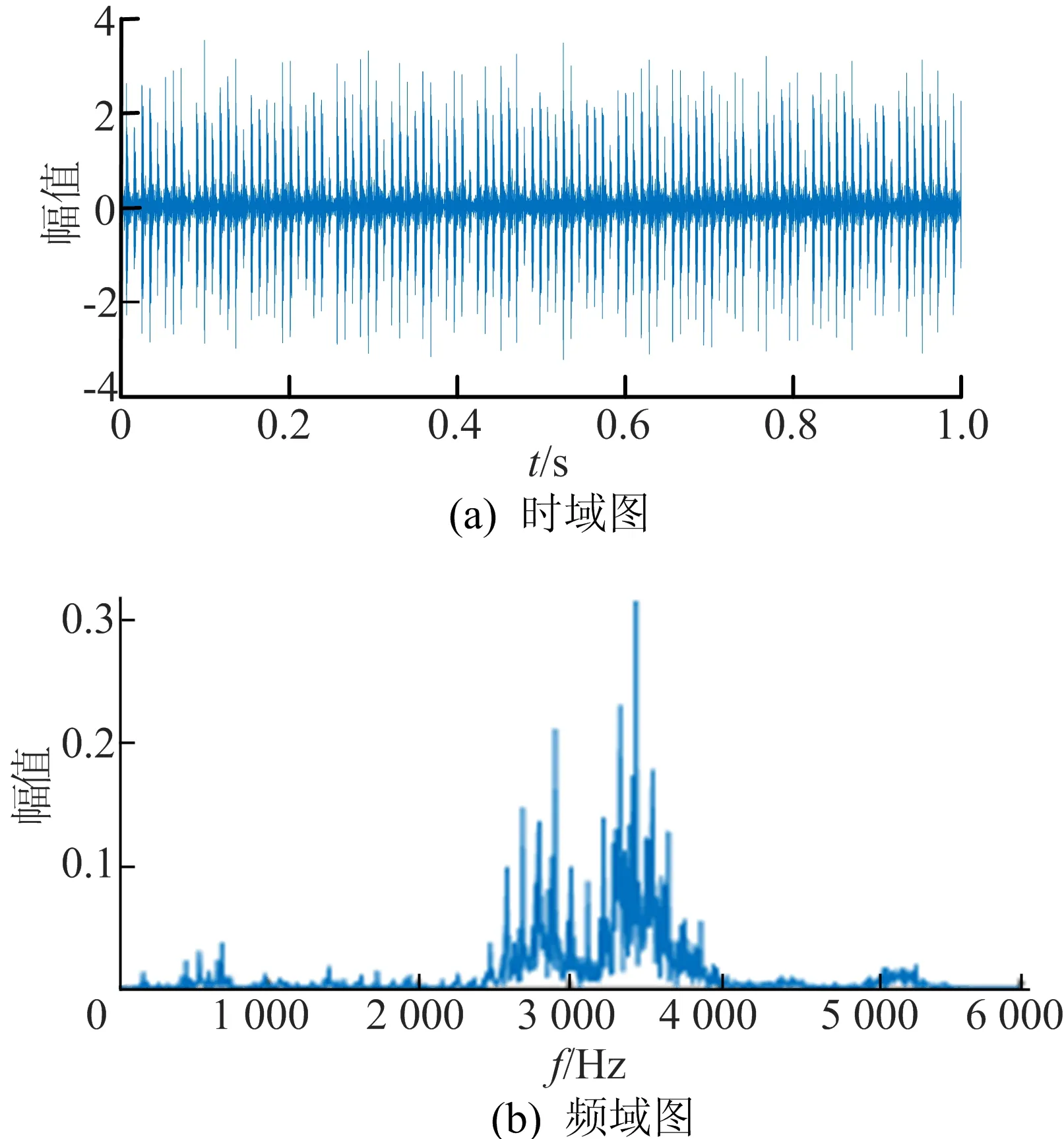
图4 滚动轴承故障信号时域图、频域图
从图4可以看出,外圈故障特征频率已经无法识别,信号频段主要集中在高频部分。
首先,采用基于匹配误差的四点波形延拓方法对端点进行延拓。对延拓后的信号进行LMD分解,得到7个PF分量以及1个残余分量u,如图5所示。
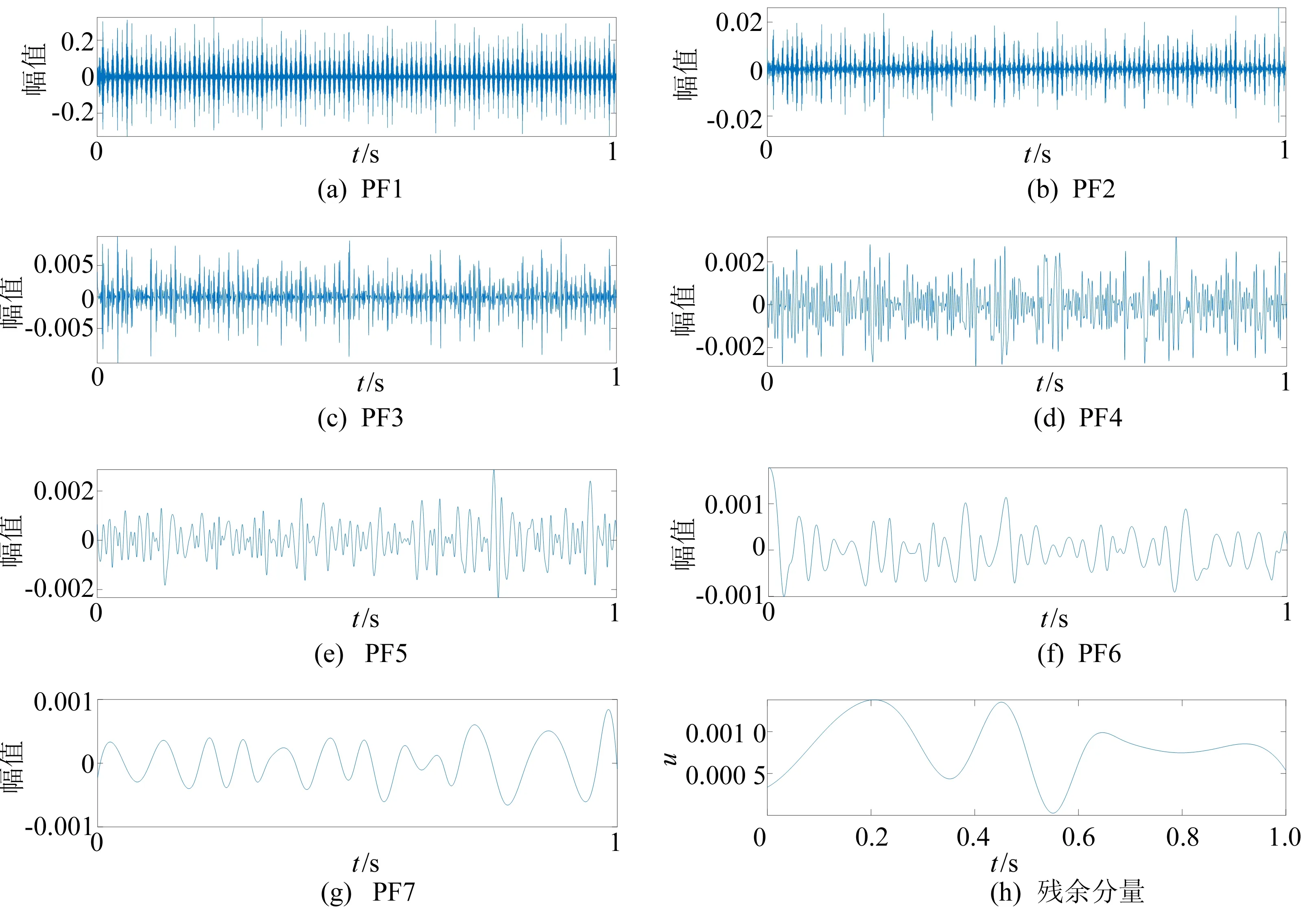
图5 LMD分解结果
对每个PF分量计算相应的8个特征指标,并对同一指标进行归一化处理,结果见表2所列。
将归一化后的7个PF分量的综合特征指标值构建成7×8型矩阵A,利用K-means聚类算法对矩阵A进行聚类分析,采用欧氏距离作为评价指标,不断重复计算聚类中心,直到聚类中心不再发生改变,最终得到2个聚类中心。
聚类后的各个PF分量个体到聚类中心的距离见表3所列。
分量PF1、PF2、PF3被聚为一类,分量PF4、PF5、PF6、PF7被聚为一类。从表3中可以看出2个类群区分明显,效果较好。综合分析可知,PF1、PF2、PF3为敏感分量,将其重组,得到重组信号X(t)。

表2 PF分量时域参数归一化
首先对重组信号X(t)进行包络分析,采用Hilbert方法进行解调后,得到的频谱图如图6所示。从图6可以看出,108 Hz及其2倍频216 Hz、4倍频432 Hz等高阶频率谱线,与理论计算得到的滚动轴承外圈故障特征频率107.82 Hz及其倍频十分接近。特征频率略有误差的原因可能是受到实验设备实际安装、运行情况的影响,可以视作成功提取到故障特征频率。由此可以判断出轴承外圈出现故障,证明了本文所提方法的有效性。
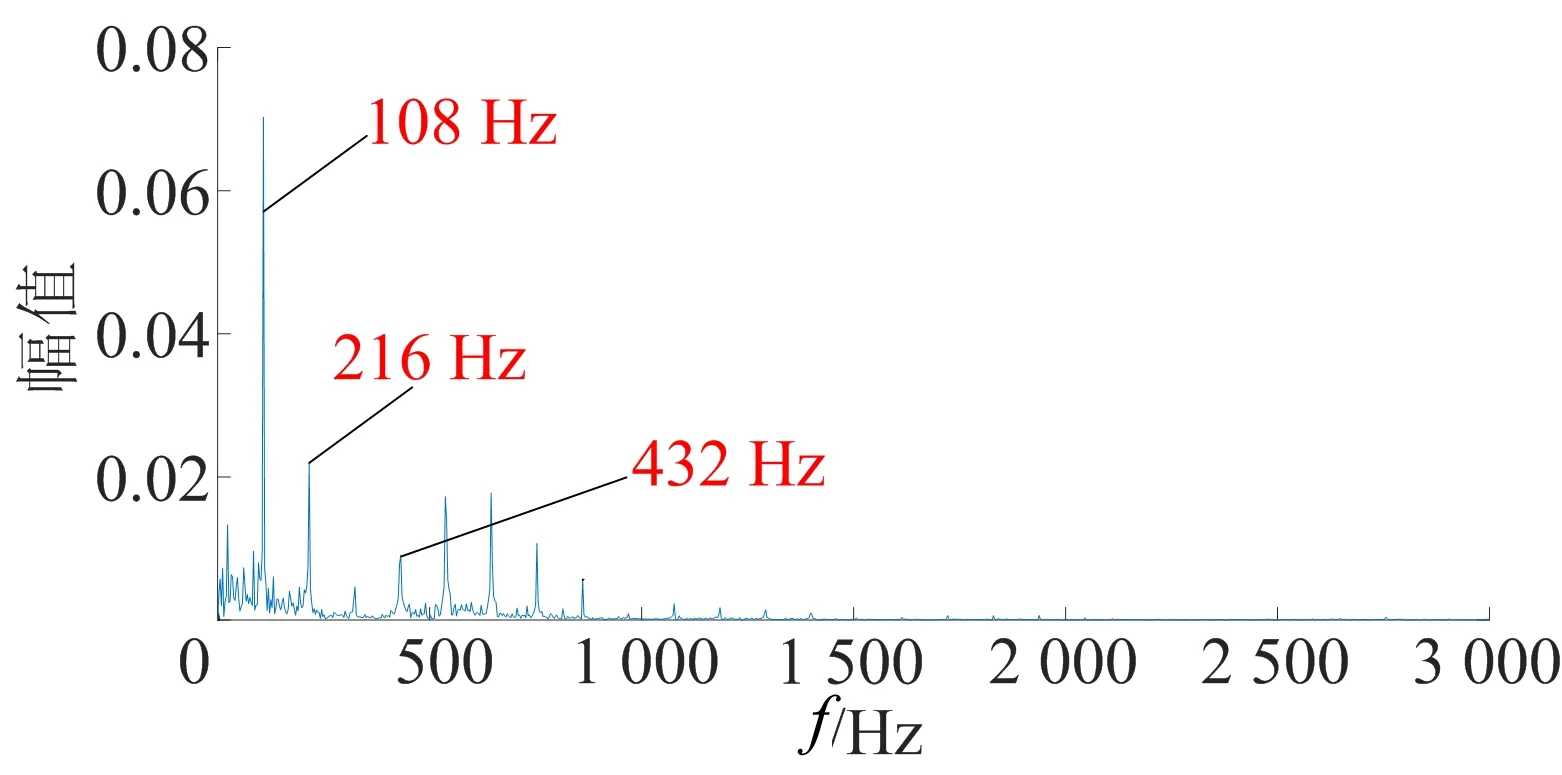
图6 包络谱分析
按相关性指标对PF分量进行选择[9],指标相关系数见表4所列。

表4 相关系数
当相关性系数小于0.1时,可以认为信号的相关性已经很小。于是选择PF1分量作为有效的敏感分量,进行包络谱分析,同时,本文也分析PF2、PF3分量的包络谱,结果如图7所示。

图7 PF1、PF2、PF3包络分析
从图7可以看出,PF1、PF2、PF3分量的包络谱中均可以发现故障特征频率,若只按照相关性指标选择PF分量,可能存在遗漏的情况。而基于本文综合特征指标的评判,会更加准确。
4 结 论
本文首先研究了LMD的端点效应改进方法,提出基于匹配误差的四点波形延拓法,与镜像延拓法、神经网络预测法的对比验证了该延拓方法的有效性。将峰值因子、波形因子、峭度因子、裕度因子、脉冲因子、峭度、偏度、能量等8个指标作为综合特征指标,与K-means聚类分析相结合,应用到滚动轴承的故障特征提取中。实例分析结果表明,敏感分量可以被正确地筛选出来,提取到的故障特征频率与理论值相符,说明该方法是一种有效的滚动轴承故障诊断方法。
