使用候选框进行全卷积网络修正的目标分割算法
2021-03-11彭大芹许国良
彭大芹,刘 恒,2,许国良
(1.重庆邮电大学 电子信息与网络工程研究院,重庆 400065;2.重庆邮电大学 通信与信息工程学院,重庆 400065)
0 前 言
目标分割是计算机视觉领域中一项重要的技术,在实际生活中和工业生产中广泛应用,诸如自动驾驶系统中对路面上行人和马路的分割,在缺陷检测系统中对工业生产中出现的各类表面缺陷的检测。然而,由于现有技术在速度和精度上达不到工业生产的需求,目标分割技术在工业生产线上应用水平目前还处于比较不充分的层次。以液晶面板的缺陷检测为例,目前针对液晶面板的检测仍部分依赖于有专业经验的工人靠肉眼观察,受人工检测中主观和客观方面条件的限制,很难实现高效、精准和稳定的液晶面板缺陷检测。传统机器视觉的方法受限于其手工提取特征的方式,往往仅能在特定的几种缺陷场景下发挥良好性能,对于新型缺陷缺乏良好的自适应性和泛化性能,此外,也有研究者[1]使用数据场和水平集的方法进行图像分割,但仍然局限于这些特征的低效性。近年来随着深度学习在机器视觉领域的应用,催生了一大批在目标检测领域的成功案例,文献[2]中使用YOLO算法对车牌进行自动识别。YOLO系列[3-4]算法是J. Redmon等于2016年提出的单阶段目标检测网络,该网络将对各个目标的分类和对位置坐标的回归同时输出,极大地提高了目标检测的速度,但是由于输入的锚框误差被直接传导至输出层,其检测精度比相较于R-CNN系列[5-7]的两阶段网络有一定的差距。
目标的分割任务相比于目标检测任务而言具有更高的要求,需要对输入图片进行逐像素分类。目前实现目标分割任务有2种思路:①以R-CNN系列中最新的Mask R-CNN(mask region convolutional neural network)[8]为代表的先检测、后分割的技术路线。具体的思路是首先依靠候选框网络,产生高置信度的候选框实现了对待检测目标的框定及分类,然后将框内的特征像素导入全卷积网络,进而得到分割掩码。这种方式能够实现较高的分割精度,但对于液晶面板场景中多种尺度共存、语义信息模糊的缺陷,其检测精度达不到要求,这是因为候选框内的特征图的像素分辨率相较于原图已经缩小了数十倍,在此之上进行反卷积操作导致最终分割粒度太粗,小目标的缺陷很容易被忽略;②直接将卷积神经网络最后一层卷积层的特征进行上采样,得到和原图相同分辨率的特征图,这就是全卷积网络。典型的全卷积网络结构有FCN[9],DeconvNet[10],SegNet[11]和DeepLab[12]等网络。这种方法存在的问题是在全卷积网络中反卷积和上池化操作丢失了目标的位置信息,虽然分割粒度满足了要求,但是特征图中对目标位置的分割发生了较大偏差。
基于上述2种算法的优缺点,本文提出将目标检测中最核心的候选框网络(region proposal network, RPN)和具有高分辨率输出特征图的全卷积网络进行有机结合,利用高置信度的候选框对全卷积网络输出的多通道类别缺陷分割图进行逐通道预矫正,进而实现对液晶面板中各种尺度差异缺陷的精准分割。本文所提网络被称为带RPN的全卷积网络结构(fully convolution network with region proposal network, FCN-RPNet)。
1 全卷积网络和候选框网络
1.1 输出多通道类别分割图的全卷积网络
最早使用全卷积网络做分割任务是在文献[8]中提出的FCN,作者分别基于AlexNet[13]、VGG-16[14]和GoogLeNet[15]构建了全卷积网络的主干部分,然后将全连接层以卷积化的形式表现,构成了不含全连接层的网络结构。在最后一层卷积层的基础上,使用双线性插值完成上采样,最后输出和原图相同大小的分割图。在实施上采样时,采取了多层级多倍率的上采样方案,在最后一层基础上扩大32倍,得到分割图,在Pool4层上扩大16倍,在Pool3层上扩大8倍。这种单次上采样的方案虽然取得了一定的效果,但是由于上采样倍率过大时,导致分割精度较差,而在放大倍率较小的特征处,其特征提取的信息有限,因此,这种上采样方式在后续很快被改进。随后以SegNet和DeconvNet为代表的语义分割网络均使用了反卷积和上池化操作进行上采样,并使用学习的方式对反卷积参数进行调整。图1为使用了卷积-反卷积方式的语义分割网络。

图1 运用反卷积进行上采样的全卷积网络Fig.1 Fully convolutional network usingdeconvolution for upsampling
网络的输入为W×H×3的图片,其中,W×H表示图片的尺寸,3表示RGB三通道。网络的输出为W×H的分割图。(1)式为网络的损失函数。
(1)

使用RPN直接对全卷积网络输出的单通道分割图进行预矫正,进行预矫正提升效果并不明显,因为该分割图包含全部缺陷类别的信息,针对每种缺陷的分割信息有限,如若对每种缺陷进行位置信息的预矫正,则需要单独得到每种缺陷的分割图。基于此,提出将全卷积网络输出增加为多通道的输出分割图,每通道代表对一种缺陷的分割图,并提出使用多通道的损失函数作为目标函数。如图2。
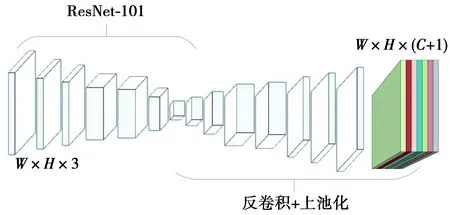
图2 输出多通道类别分割图的全卷积网络Fig.2 Fully convolutional network with outputs of multi-channel class segmentation maps
输出的特征分割图的大小为W×H×(C+1),其中,C代表需要分类的C种液晶面板缺陷;1代表背景区域。基于此输出结构,提出多通道的损失函数,如(2)式
(2)
(2)式中,Lc代表每个分割通道的损失函数。其表达式为
(3)
1.2 候选框网络
目标检测技术能够快速发展的重要技术创新是以R-CNN为代表的系列神经网络架构提出了候选框进行初步框定的思想。候选框的出现使得两阶段的目标检测算法在性能上领先于其他的检测算法。
早期的候选框提取方式仍然采用了传统手工构造特征的方式,比如选择搜索算法[16]等,这些方法利用各类基于非学习类的特征,诸如边缘梯度、颜色直方图、统计分布特征等来进行候选区域的提取。这些方法能够较好地提取可能存在前景的候选区域,但是前提往往是其需要产生海量的候选框才能基本囊括全部的前景可能存在的区域,由此,导致检测效率比较低效,因此,很快被后续的算法所改进。
在Faster R-CNN中,将候选区域的提取首次视为学习的过程,使用卷积神经网络并结合预先定义的锚框机制,并使用包含分类和回归任务的损失函数,较好地产生了具有高置信度的候选区域,也因此降低了所需候选框的数量,大大提高了网络的检测效率。图3为RPN网络示意图。

图3 RPN示意图Fig.3 Schematic of RPN
假设在高层特征图上以每个特征像素点为中心,按照预先设定的各种尺度和比例的锚框进行滑动检测,锚框的设定是根据先验信息通过聚类得到的,在液晶面板缺陷检测任务中,使用了5种不同尺度和3种不同比例的锚框,这5种尺度分别为:2,8,16,32,64,3种不同的比例分别为1∶1,1∶2,2∶1(见图3)。也就是每个像素块有5×3=15种锚框进行滑动检测,每种锚框所覆盖的区域将被提取至后续的全连接层。后续的2个网络分支分别对这些候选区域进行分类和回归操作,分类使用Softmax损失,回归使用Smooth L1损失,如(4)式所示,总的误差函数如(5)式
(4)
(5)
(5)式中:pi表示前景的预测概率;pi*表示标签值,当对应区域是缺陷目标时为1,否则为0。第2项中乘以该标记值的目的是仅对包含了缺陷目标的候选框计算位置损失。ti,ti*分别表示预测的位置值和真实位置值标签,它们是一个向量,其表达式为(6)式
(6)
(6)式中:xa,ya,wa,ha分别表示anchor的中心坐标及其宽高;x,y,w,h分别表示预测出来的矩形框的中心坐标及其宽高;x*,y*,w*,h*表示真实缺陷框的中心坐标及其宽高。
2 使用候选框对全卷积的类别分割图逐通道矫正
2.1 算法框架
由于全卷积网络中存在反卷积和上池化的操作,因此,在此过程丢失了关于目标的位置信息,从而对分割结果产生了较大的位置损失。而液晶面板的缺陷检测具有多种尺度缺陷共存、缺陷语义模糊和背景前景差异性小等难题,这些小目标和语义信息模糊的缺陷信息在反卷积过程中很容易产生位置飘移,从而导致对缺陷的分割精度大大降低。为了解决这一问题,提出使用RPN对卷积神经网络正向卷积特征图中的位置信息进行提取,以高置信度的候选框对全卷积网络的多通道输出分割图进行逐通道预矫正,达到对位置信息增益的效果。本文提出的使用RPN网络对全卷积网络输出的多类别分割图进行逐通道预矫正的算法框架如图4。
图4中,算法整体由7个元素组成,首先由ResNet-101和深度反卷积网络构成全卷积网络的主体部分,然后以ResNet-101中的高层特征图为RPN的输入,产生若干高置信度的缺陷目标候选框,基于候选框对全卷积网络输出的多通道类别分割图进行逐通道预矫正。使用矫正后的多通道类别分割图进行逐像素分割,最后计算分割图和真实分割图之间的损失,并将其反馈至逐通道预矫正模块,更新预矫正参数,直至预矫正损失收敛。
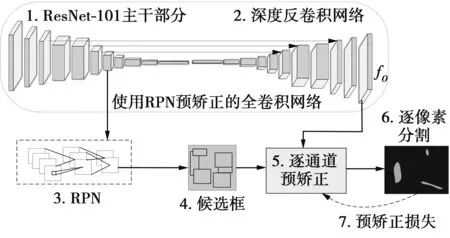
图4 使用RPN对全卷积网络进行逐通道预矫正算法框架图Fig.4 Frame-by-channel pre-correction algorithmframework for full convolutional networks using RPN
2.2 逐通道预矫正
图5是逐通道预矫正算法部分示意图,算法的输入为2个部分:全卷积网络的多通道类别分割图和RPN提取的高置信度候选框区域。算法主体由2个模块组成:①逐通道预矫正模块;②预矫正损失反馈模块。由于候选框网络产生的是高置信度的候选框,其包含了非常丰富的关于待检测缺陷的位置信息,但其和实际缺陷位置仍有细小的偏差,因此,使用这些候选框进行缺陷矫正时,只能称为预矫正算法,配合学习过程一同完成对分割区域矫正。为了更精细化地修正缺陷位置,因此使用预矫正损失,使用少量样本数据,学习预矫正中的参数。
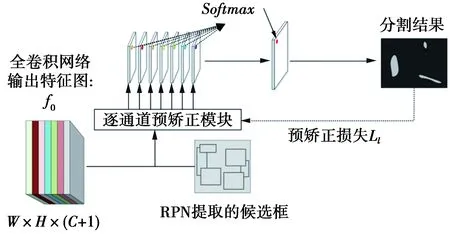
图5 逐通道矫正算法示意图Fig.5 Schematic diagram of channel-by-channel correction algorithm
首先介绍使用高置信度的候选框对单个通道的缺陷分割图进行预矫正的算法。其算法流程如图6。
(7)

(8)
(9)
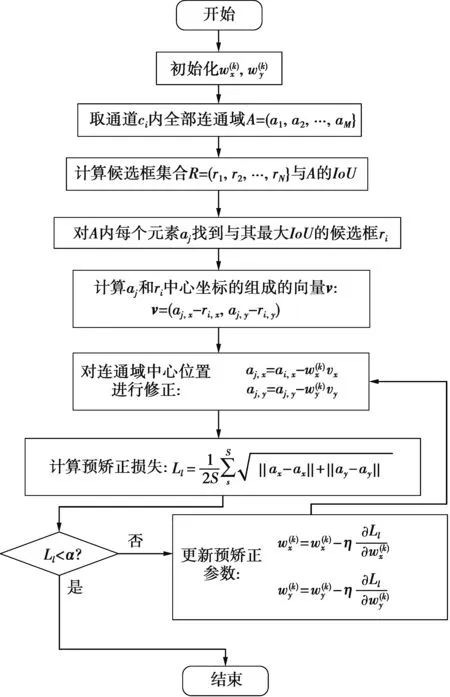
图6 对单通道缺陷分割图进行预矫正示意图Fig.6 Pre-correction diagram for single-channeldefect segmentation

图7 使用学习的预矫正参数对缺陷位置进行微调Fig.7 Fine-tune the defect location using the learnedpre-correction parameters
使用上述算法依次对全部通道进行预矫正,得到(C+1)个通道的矫正后子类分割图。对全部通道相同像素位置的值使用Softmax回归进行逐像素分类,进而得到最后的液晶面板缺陷分割图,如图5。
3 实验与分析
3.1 实验数据来源
为了验证本文算法的有效性和稳定性,本文分别在2种场景下进行了对比分析实验:通用视觉场景和液晶面板缺陷检测场景。前一种环境下语义信息更加丰富,重点考察了网络对语义信息提取的能力,后者场景中存在较多不规则和小目标缺陷,考察了网络在语义模糊情况下的稳定性。
在对液晶面板缺陷检测场景的分割实验中,课题依托于重庆市技术创新与应用示范专项产业类重点研发项目,基于中国信息通信研究院西部分院自主研制的一体式自动采集装置在重庆美景光电工业园液晶面板生产基地进行了数据集的采集。并对数据集进行了预处理,形成了液晶面板缺陷数据集TFT-LCD。数据集包含各类缺陷图片和经过数据增强新增的图片共计10 000张。包含Mura、背景白印、划痕、暗斑等多种缺陷,其中以Mura缺陷居多。图8为数据集中典型缺陷示意图。

表1 图像数据集
基于上述数据集,本文在Caffe框架下搭建了全卷积网络,实验环境为Intel Core i7-7700HQ、CPU3.50 GHz、GPU Nvidia1 080、内存16 GByte。

图8 典型的液晶面板缺陷Fig.8 Typical LCD panel defect
在对通用视觉场景的分割实验中,课题选取了CamVid公开数据集[17-18]作为训练集和测试集。CamVid数据集是一个包含街景图片的公开数据集。
3.2 准确度分析
网络的训练分为2个阶段进行,第1阶段对基于ResNet-101构建的全卷积网络前半部分进行单独训练,首先使用从网络下载的已在ImageNet数据集上收敛的权重进行初始化,然后使用TFT-LCD数据集进行迁移学习的训练,使用多分类损失函数,并使用随机梯度下降算法(stochastic gradient descent, SGD)进行参数的更新,网络的初始学习率Ir=0.01,动量参数设为mentum=0.85,学习衰减率设为decay=1×e-6。在液晶面板缺陷数据集TFT-LCD训练下损失函数的输出值和迭代次数变化图如图9。
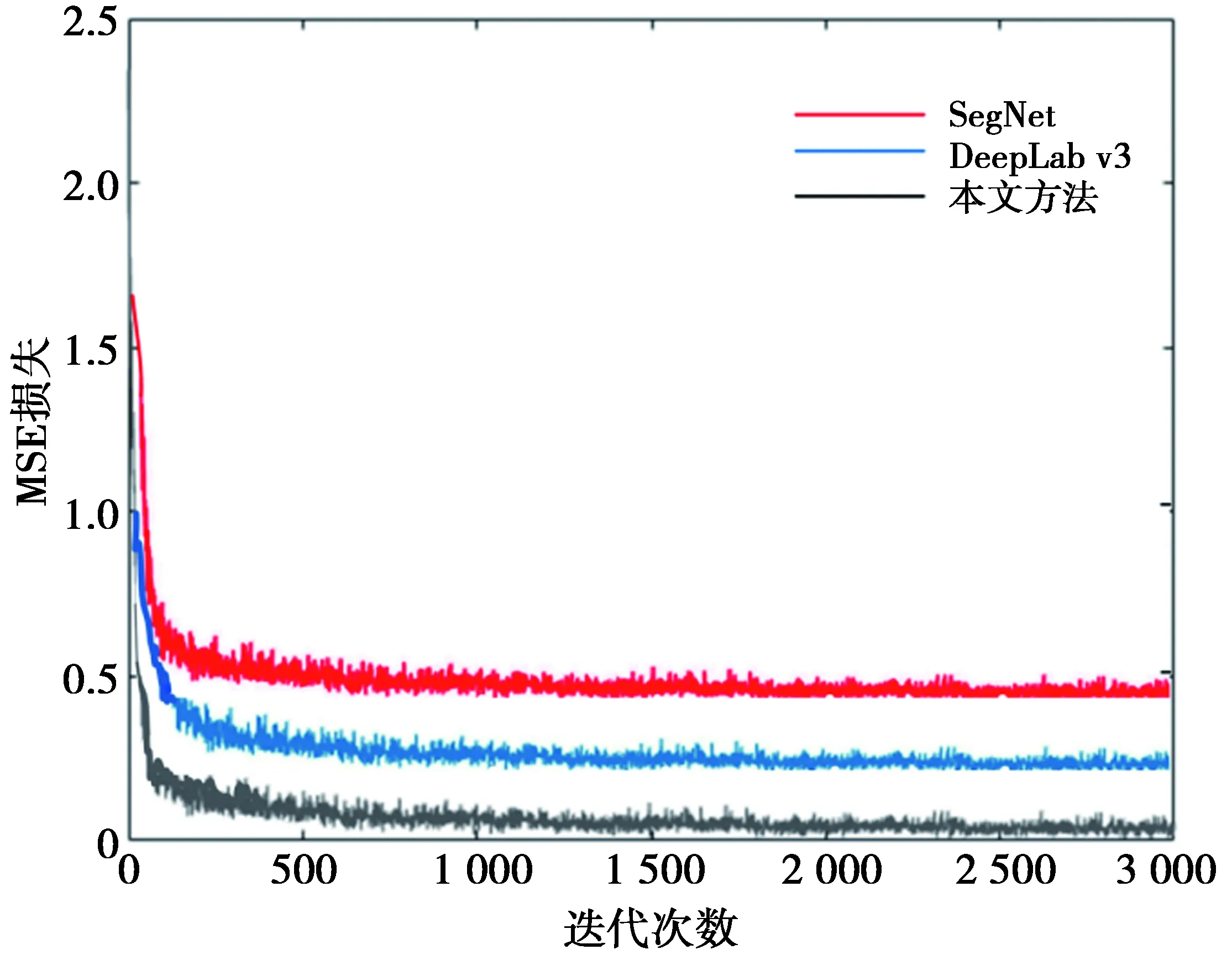
图9 基于ResNet网络搭建的3种算法训练损失Fig.9 Loss of ResNet-101 training with the TFT-LCDdata set
图9分别显示3种算法SegNet,DeepLab v3和本文算法分别在TFT-LCD数据集训练下的MSE损失。从图9中可以发现,本文的方法在网络迭代至1 500次左右时趋于稳定,在训练初期网络的损失下降得比较快,由于网络的训练是在已导入预训练权重之上进行的,网络很快便进入逐渐收敛的状态。在网络收敛时,本文方法的MSE损失小于0.1。同时可以看出,其余2种算法在前期损失函数的下降同样比较迅速,在2 000次迭代后逐渐趋于稳定,在网络最后收敛之和,他们的损失分别超过了0.3和0.5,由此,表明使用多通道损失函数的全卷积网络能够取得更好的网络学习效果。第2阶段的训练为反卷积网络的训练,固定第一阶段网络的参数,使用TFT-LCD的分割标签进行反卷积网络的训练,使用标准差为0.01的零均值高斯分布对反卷积网络参数权重的初始化,学习的其他参数同上。并使用(2)式的多通道损失函数。
图10为本文方法、SegNet算法、SegNet+RPN算法和DeepLab v3 4种算法的精确度的数值随着迭代次数变化的曲线。训练至1 200次左右,网络逐渐收敛,全卷积网络像素分类的平均精度到达91%。DeepLab v3算法在收敛后精确度为89%,SegNet+RPN和SegNet在收敛后的精度分别为88%和87%。由此证明了使用RPN进行修正后的目标分割算法对分割的整体精度有一定的改善。

图10 反卷积网络精确度Fig.10 Deconvolution network accuracy
3.3 分割输出位置性能分析
为验证候选框网络提取的位置信息对全卷积网络最终的分割缺陷的位置产生了正向增益,本文进行了多组实验测试全卷积网络在液晶面板缺陷检测位置精度方面的性能。为了使得分析过程更加清晰,本文现对本节采用的评价指标进行说明。本文使用的评价指标平均交并比(mean intersection over union, mIoU)为
(10)
(10)式中:N为全部缺陷的数量;mIoU计算了全部液晶面板真实缺陷及其分割图间的交并比的统计平均值。
图11对比了3种分割算法在不同情况下的mIoU的值。横坐标表示像素级分割时判断为各类缺陷的置信度阈值,当大于该值时,认定为缺陷,否则为背景区域。
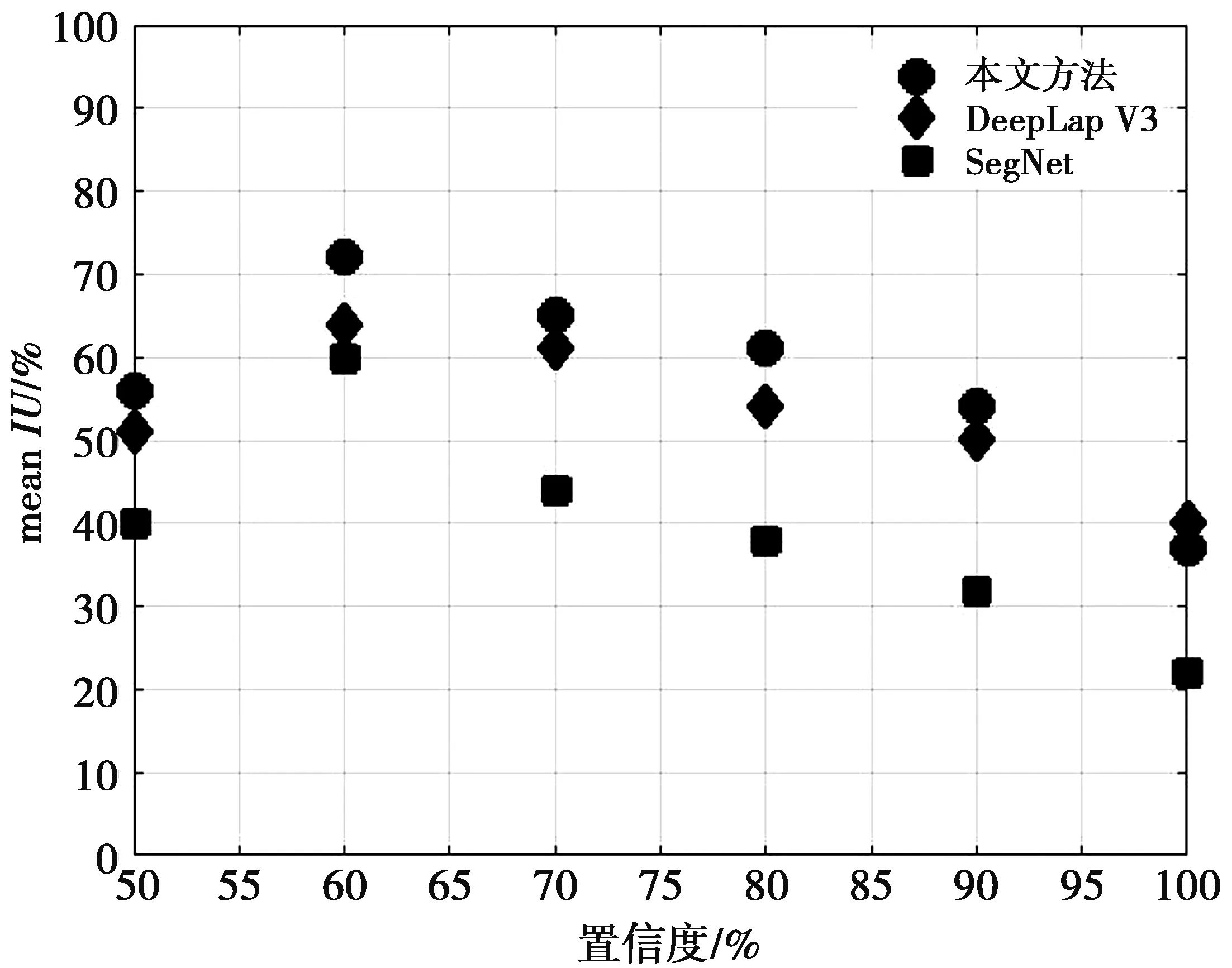
图11 不同置信度阈值判定下的mean IU图Fig.11 Mean IU diagram under different confidence thresholds
此外,为了衡量对缺陷的误检和漏检方面的性能,使用平均精确率(mean average precision,mAP)性能指标对其进行衡量,指标mAP的定义式为
(11)
(11)式中:N表示缺陷的类别数量;Pi表示第i种缺陷的准确率;ri表示第i种缺陷的召回率。
从图11中可知,本文所提的方法在各种缺陷置信度判定阈值下均取得了超过或者持平于当前最领先分割算法的mIoU,这表明使用RPN进行预矫正后,习得了关于缺陷位置的特征,能较好地在原有分割的基础上对缺陷位置进行微调,从而使得更多的像素点被分割成其正确的类别。此外,从图11中的散点在水平方向的走势中可以看出,mIoU的值先是处于上升的趋势,当置信度大于一定值时,mIoU整体的性能会降低。产生这一结果是因为当判定是否为缺陷的阈值提高时,更多的点会被分割正确判定为其原有的属性,因此,分割图与真实缺陷区域之间的重叠的面积会更多,当判定阈值升高至一定水平时,由于分割误差导致网络对其的置信度并没有那么高,所以会被判定为非缺陷区域,更多的点被误分类,因此,造成分割区域与真实缺陷区域重叠面积降低,由此拉低了mIoU的值。
3.4 分割性能分析
为验证使用RPN对全卷积网络多通道输出进行逐通道预矫正后的分割精度是否得到了提升,本节使用mAP对其输出分割图进行评价。表2对SegNet和DeepLab v3 2种算法以及在这2种算法之上进行了候选框预矫正之后的算法进行性能对比。SegNet和DeepLab v3分别是2015年和2018被提出的2种性能优异的目标分割算法。此外还对候选框网络所产生的候选置信度阈值进行了调整,对比不同数量和置信度条件下的候选框对算法整体分割和检测性能影响。
表2中的SegNet[M]和DeepLab v3[M]表示分别将其输出分割图改进为多通道输出之后的网络。从表2中可以看到,在已有的全卷积网络分割算法之上使用RPN进行逐通道的缺陷位置预矫正后,其目标分割性能得到了提升,相较于使用了RPN的DeepLab v3算法相比于使用前其mIoU提升了7.5%,mAP提升了6.5%。当在候选框网络中使用不同的置信度阈值时,产生候选框的质量和数量不一样,其对算法最后的性能也产生了影响,当置信度阈值为0.9时,平均产生约10个候选框,当置信度阈值为0.8时,平均产生30个候选框,经过实验发现,置信度较高的候选框数量多时,其能够小幅提升分割性能。在效率方面,可以看出添加了RPN结构的SegNet和DeepLab v3相较于未添加时,检测效率有略微的降低。
除了对缺陷进行完整的分割之外,对漏检和误检的分析也是对算法分析的基本要求,为单独验证算法对单种缺陷的检测性能,以Mura缺陷为实验对象,进行了测试。图12为不同算法在针对Mura缺陷进行检测时的Precison-Recall性能图。
从图12中可以看出,在使用了反卷积的SegNet网络,目前分割性能领先的DeepLab v3种,使用RPN预矫正算法在其分割输出进行逐通道分割,并学习少量参数再进行微调的方案之后,网络的分割性能均得到了不同程度的提升,其中在SegNet网络上提升比较有限,这是因为其全卷积网络分割原始的特征图遗失的缺陷太多,导致使用候选框进行矫正时,找不到矫正目标,因此,最终矫正结果只能取得较为有限的提升。

图13 多种分割算法在液晶面板上分割效果对比图Fig.13 Comparison of segmentation effects of multiplesegmentation algorithms on a liquid crystal panel
图13和图14分别显示了本文算法和其他基于全卷积网络分割算法在常见液晶面板缺陷场景以及通用视觉场景的这两类场景上的分割效果图。在图13中可以看出,本文算法对缺陷位置的预测的精确度和精细化程度方面均优于其他2种算法,图13中第一行是常见的Mura缺陷,使用多通道损失以及候选框逐通道微调后,算法的分割性能得到了较好的提升,对Mura缺陷的边缘和主体部分更好地进行了分割,在划痕和暗斑区域等缺陷上也取得了良好的分割性能。图14第1列为CamVid数据集中的几种街景图片;第2列为CamVid数据集中对应结晶图片的标签;第3列为使用DeepLab v3算法对街景图片的分割图;第4列为本文算法对该街景照片的分割效果图。从图14中可以看出,相较于DeepLab v3的分割效果而言,本文算法在对房子的轮廓的分割、对行人的分割、对道路斑马线和对道路路沿等部分的分割效果均取得更优的分割表现,验证了本文算法在多种场景下的分割性能具有较强的稳定性。

图14 多种分割算法在CamVid数据集上分割效果对比图Fig.14 Comparison of segmentation effects of multiplesegmentation algorithms on CamVid datasets
4 结束语
本文针对现有全卷积网络在液晶面板缺陷分割任务中精度差、位置信息丢失等问题,提出了使用多通道损失函数的全卷积网络,并利用候选框网络学习关于缺陷目标位置信息的候选框,使用预矫正算法对全卷积网络输出的多通道类别分割图进行逐通道修正,并基于修正损失的反馈对预矫正参数进行微调。通过多组实验对比分析表明,该算法在液晶面板缺陷检测上取得了超过目前领先的目标分割网络的性能,基于该算法改进后的DeepLab v3相较于未改进前的mIoU提升了7.5%。同时在CamVid街景数据集上进行了测试,实验结果显示,相比于目前目标分割领域性能领先的DeepLab v3算法的分割效果而言,本文算法在对前景的分割细节上取得了更好的效果,验证了算法的稳定性。
