基于深度学习与显著性的数字图像构图优化
2021-03-08王永雄秦宇龙
邵 杭,王永雄,秦宇龙
(上海理工大学 光电信息与计算机工程学院,上海 200093)
随着信息技术的发展,数字图像对社会生活的影响日益深远,并已成为社交、传媒、商业活动的重要载体。但是受限于摄影器材、拍摄环境、拍摄者摄影水平和鉴赏者鉴赏能力等因素,许多数字图像往往难以满足较高的美学要求。此外,由于数字图像的后期处理工作极为繁琐,无论是对于专业人士还是业余爱好者,都会被其占用大量的时间和精力。因此,利用计算机图形学、数字图像处理技术和人工智能算法对图像进行符合美学的优化,无论是在计算机辅助设计领域,还是图像美学质量评价领域,都具有重要的研究意义和广泛的应用前景。
图像美学是一门交叉学科,纵观数字图像处理和人工智能在该领域的发展,对图像美学的研究呈现出了两个不同的发展趋势:其一是以机器学习和深度学习为代表的图像美学质量评价,即利用计算机算法,从模拟人类视觉感知[1]的角度出发,基于一定的评价指标[2-3]自动评价图像质量的高低。然而相较于物体识别、目标检测等的语义特征[4],人类审美的奥秘目前尚未有可量化的科学解释[5]。图像美学质量评价在具备客观性的同时,还存在很强的主观性[6-7];其二是基于已知的图像美学原则,对图像进行自动优化,例如利用生成式对抗网络(Generative Adversarial Network)实现图像的域间风格转换[8];利用双边滤波算法实现人物图像的自动美颜[9];利用深度卷积神经网络并融合多项损失函数实现图像的实时画质增强[10]等。研究表明,在影响图像美学质量的诸多因素中,例如光影、明暗、虚实、景深、色彩饱和度和色调对比度等,构图被认为是最重要的评价指标[11-12]。同时,基于传统的数字图像处理技术,例如图像去噪、锐化、均衡化、亮度和对比度增强等均属于面向图像底层像素信息的优化,构图优化则更关注图像高层信息特征[13-14]及美学质量的优化方法。
近年来,研究者们针对图像构图优化问题提出了许多新颖的解决方法。Bhattacharya等人[15]提出了一种交互式的优化算法,其将优化系统分为两个模块,分别为训练美学评价的回归器和根据美学评价重定位用户选择区域主体的分类器,以获得高美学评分的重定位图像来实现构图优化。Jin等人[16]在此基础上,结合图像裁剪和网格形变,使图像处理前后的尺寸比例关系保持一致,以尽可能多地保护图像原有信息。Guo等人[17]利用显著性和Content Aware Seam Carving算法,基于图像内容的比例缩放进行图像重构。Zhang等人[18]在此基础上通过提取图像前景区域的方法消除人工裁剪痕迹。Wang等人[19]利用图像显著性特征及Hough直线检测算法进行构图优化。Xiong[20]基于长直线几何形变,利用仿射变换对图像进行旋转校正。Chen等人[21]通过对图像像素点数量线性相关性的复杂度进行计算实现图像重构。Chen等人[22]通过去除图像画面主体之外的冗余场景裁剪图像来实现优化。Wang等人[23]基于带语义信息的双通道卷积网络,通过预测图像边界框和主体特征实现了裁剪重构。
为了解决图像画面平衡感缺失和画面主体构图不合理等问题,本文提出了一种基于深度学习和显著性模型的图像美学构图优化算法。本文利用深度卷积神经网络对图像进行显著性检测,提取主体特征,结合视觉平衡原理和三分构图法则来进行图像自动裁剪重构。本文深度网络架构以VGG-16作为主干,加权两项损失函数并以图像像素数目值进行平均,可在训练后实现端到端的全分辨率显著性回归,无需进行任何预处理和后处理,且在精度和性能上较传统算法均有明显提高。本文利用摄影图像验证所提出方法的科学性和有效性。实验结果证明,相较于目前传统的构图优化方法,本文算法在改善视觉平衡方面具有明显优势,处理后的图像画面平衡感得到显著提升,更符合美学评价原则,且更契合美学评价原则和人的视觉感受,处理后的构图达到更为谐调、自然、平衡的效果。
1 构图优化原理
构图是指根据图像题材和画面主体等要素,通过一定的关系将所要表现的对象以适当的形式组织起来,构成一个协调的整体。构图被广泛地应用在摄影、绘画、设计和图像美学评价等领域。在摄影中,为追求美学效果,需要遵循一定的构图方法[24]。常用的经典构图方法有十余种,包括对称式、框架式、中心构图、三角形构图、引导线构图、对角线构图、黄金螺旋构图等。这些方法繁杂林立,给利用计算机算法进行图像美学自动优化带来了一定困扰。因此,本文基于奥卡姆剃刀定律,选择三分法则和视觉平衡原理进行构图优化。
三分法则利用黄金分割比例,设一条直线段长度为h(h=h1+h2),当满足h1/h2=h2/(h1+h2)的比例关系时,即可获得最佳的视觉平衡效果,从而使图像画面达到一种更为有序、稳定的状态。利用这种关系,可将图像画面分割为9个区域,形成3×3的网络布局以及4个称之为锚点的分割线交点,如图1所示。构图时,将所要突出的显著主体置于锚点位置处,可很好地提升图像美学效果。基于三分法则构图的图像如图2所示。
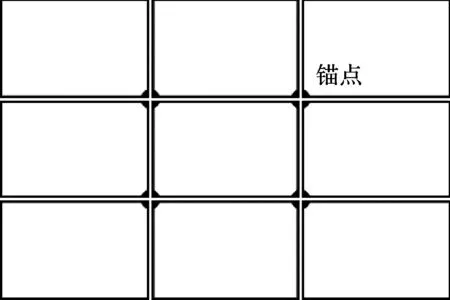
图1 三分法则视觉平衡原理

图2 基于三分法则构图的图像
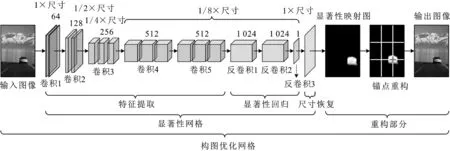
图3 算法整体架构图
2 构图优化方法
本文优化算法的整体架构图如图3所示。为提取画面主体并进行构图优化,本文基于深度卷积神经网络架构对图像进行显著性检测。本文网络以VGG-16作为模型的主干架构。网络由3个模块构成,分别为特征提取模块、显著性回归模块和图像尺寸恢复模块。经过训练后,网络可在没有相关场景先验知识的情况下,端到端地实现全分辨率的显著性回归。
特征提取模块包含5组卷积,采用分层架构提取图像的语义特征信息。具体而言,这5组卷积分别包含2、2、3、3、3个卷积层,卷积核均为3×3大小。本文以ReLU(Rectified Linear Unit)整流线性激活单元代替传统的Sigmoid作为激活函数。与传统的激活函数相比,ReLU可以使网络的收敛速度更快。同时,为了保留更多的边缘信息并扩大网络的感受野,本文将最大池化层的卷积尺寸由2×2修改为3×3。在迭代步长方面,前3组设置为2,其后设置为1。这一模块的输出为输入图像1/8大小的特征映射。
显著性回归模块包含3组卷积,每组卷积的全卷积层之后是ReLU激活函数层和Dropout层。该模块由前向输入的特征映射回归得到每个像素的显著性得分。由于深度学习需要大量训练样本才能获得令人满意的结果,而目前用于显著性任务的数据相对较少。为了更好地训练网络,本文采用两项加权并由像素数目平均的损失函数,具体形式为

(1)
(2)
(3)
其中,N+是显著对象所占像素的数目,N-是非显著对象所占像素的数目。ψ(·)定义为
(4)
由此可知ψ(x)可导,且其导数为
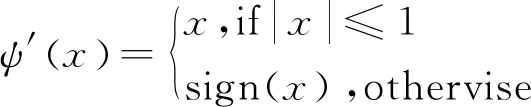
(5)
图像尺寸恢复模块由一个尺寸恢复层构成,其将前向输入恢复为原始输入大小,最终输出全分辨率显著图像。本文网络在MSRA10K数据集[25]上进行训练。MSRA10K数据集包含有10 000张带标注的图像,本文将其随机分为两个子类,以8 000张图像用于训练,2 000张图像用于验证。显著性检测结果如图4所示。与传统的、基于底层像素信息、利用先验特征的显著性检测方法相比,本文网络模型可以更好地提取图像的高级语义信息,结果也更贴合人的视觉感受。

图4 显著特征图
在获得显著特征图像后,本文基于0~255的像素值对图像像素进行加权平均计算,进一步得到像素重心点,如图5所示。随后,算法基于视觉平衡原理,将像素重心点与三分法则中的锚点位置进行匹配,求取与重心点欧式距离(Euclidean Distance)最近处的锚点,并将图像随显著图像像素重心点移至该锚点位置处,进而将图像冗余部分进行裁剪,实现符合图像美学和视觉平衡的图像重构。
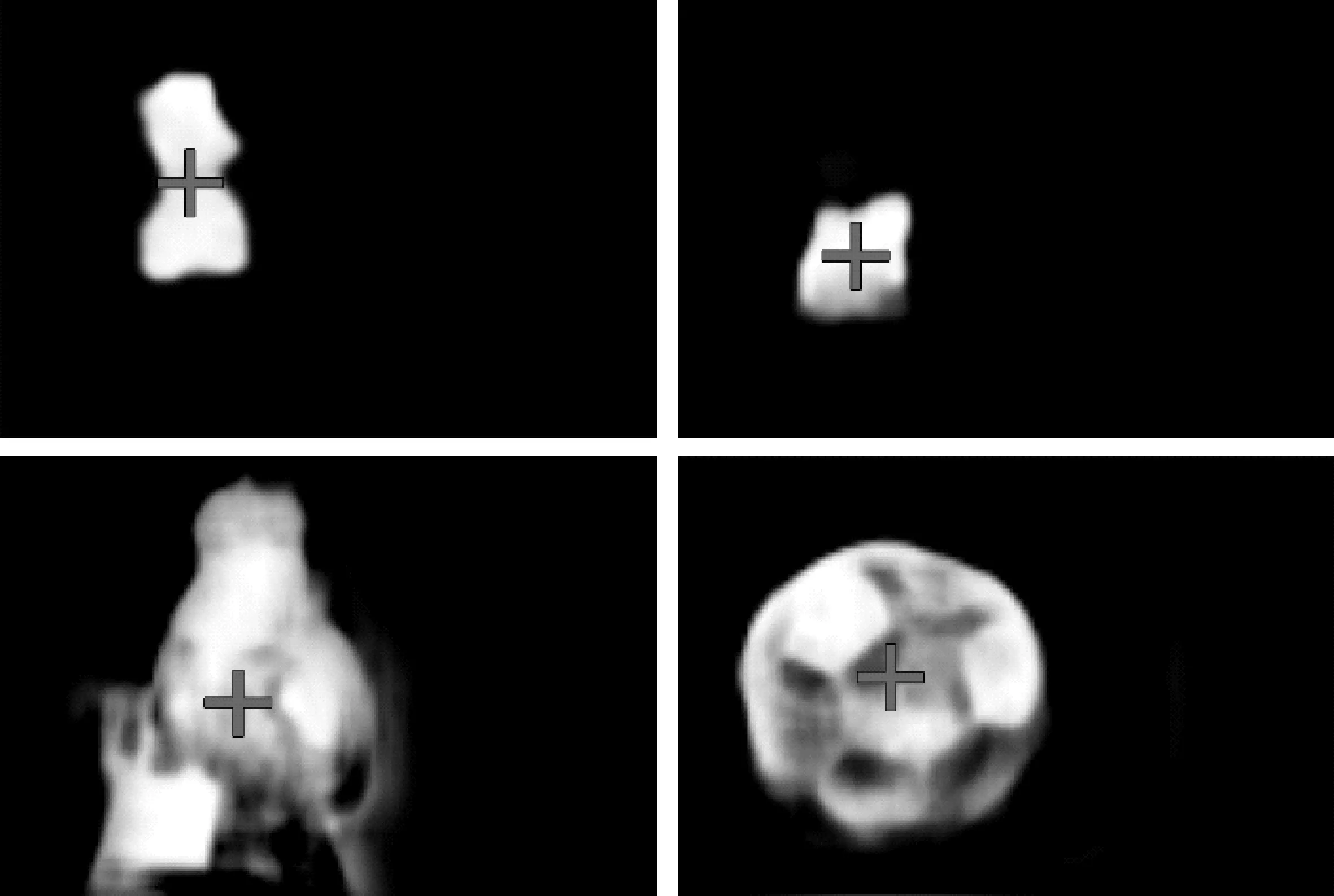
图5 显著像素重心图
3 实验结果与分析
本文利用摄影图片,通过对比实验,定性地验证所提出算法的有效性。现有基于图像美学分析的数据集,如CUHKPQ[26]、Photo Quality Dataset[27]和Google AVA[28]等,均面向图像美学质量评价得分的分类和回归问题展开研究。本文算法基于图像特征进行优化,且由于现有基于特征提取的图像美学模型,例如Kong等人[6]和Malu等人[29]提出的深度网络,难以有效评估本文算法优化前后图像美学关系间存在的对应差异,因此本文利用1范数损失(最小绝对值偏差)、2范数损失(最小平方偏差)、峰值信噪比(Peak Signal to Noise Ratio,PSNR)和结构相似性(Structural Similarity Index,SSIM)来定量分析所提出方法的科学性。
首先,本文将所提出深度网络与两种显著性检测方法进行对比验证。两种方法分别为wCtr方法[30]和LPS方法[31]。实验结果如图6所示,定量验证结果如表1所示。wCtr方法原理为基于边界连通性进行显著性检测,这种方法所标注的显著区域目标较大;LPS方法原理为通过边界先验、背景标签进行显著性检测,这种方法对于像素信息要求较高,对于上下文语义关系的提取不够准确。而本文深度网络模型可以更准确地定位图像画面的表现主体,效果和性能均较为突出。且由表1可以看出,本文方法的1损失仅次于LPS;2损失较高;PSNR和SSIM较低,说明本文显著性特征范围选取较小,更有利于进一步的像素重心点提取。

(a)原图 (b)wCtr方法 (c)LPS方法(d)本文方法

表1 显著性检测方法定量验证
本文基于不同的显著性检测方法,对图像进行构图优化。优化结果如图7所示,定量验证结果如表2所示。在图7中,相比wCtr方法和LPS方法,由于本文方法可以更准确地定位画面表现主体,故构图优化结果具有更高的美学质量。同时由表2可以看出,本文方法的1损失和2损失的值均较低,而PSNR和SSIM的值均较高,说明基于本文算法进行构图优化后,有更多的图像信息被保留。

(a) (b) (c) (d)
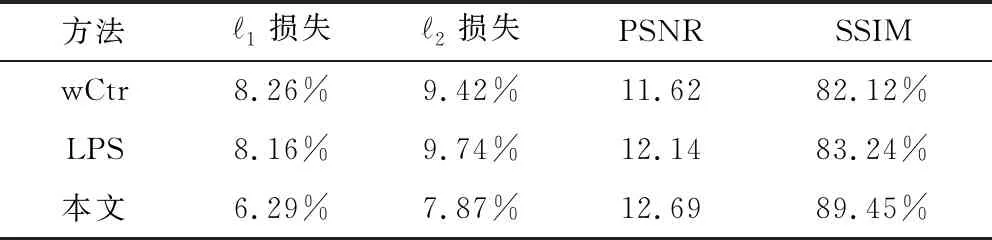
表2 基于不同显著性检测方法构图后的定量对比结果
本文进一步验证所提出构图优化算法的整体有效性,实验结果如图8所示。由图8可以看出,优化后4幅图像的表现主体均得到突出,虽然因画面裁剪原因,图像部分冗余信息缺失,但是其整体画面更符合人的审美感受,视觉平衡感亦随之增强。

(a)原图 (b)显著映射 (c)显著图 (d)优化结果
最后,本文分别与文献[17]、文献[19]、文献[22]所提出的图像构图优化方法进行对比实验。实验结果如图9所示,定量验证结果如表3所示。文献[17]中的方法通过将除画面主体之外的背景区域进行比例关系调整,以实现构图优化。优化之后背景信息虽得以保留,但是主体与背景的比例关系被改变。文献[19]方法将画面主体进行提取,继而基于三分原则、利用背景区域中的某条直线对背景区域进行比例关系调整,最后将先前所提取的画面主体重置于画面内,以实现图像的优化。但是优化之后背景信息裁剪过多,且主体与背景之间的相对位置关系被改变。文献[22]方法利用深度卷积网络架构,通过训练来学习画面主体,对图像画面主体所在区域进行提取以实现画面重构,但其结果的视觉平衡感较差。由图9可以看出,与上述方法相比,本文方法优化后的画面可以达到更为平衡的效果,画面美感亦随之显著提高。同时,由表3可以看出,本文1损失、2损失均较小,PSNR仅次于文献[22]方法,且SSIM较大,说明本文算法可以在实现构图优化的基础上更好地保护图像原有信息。
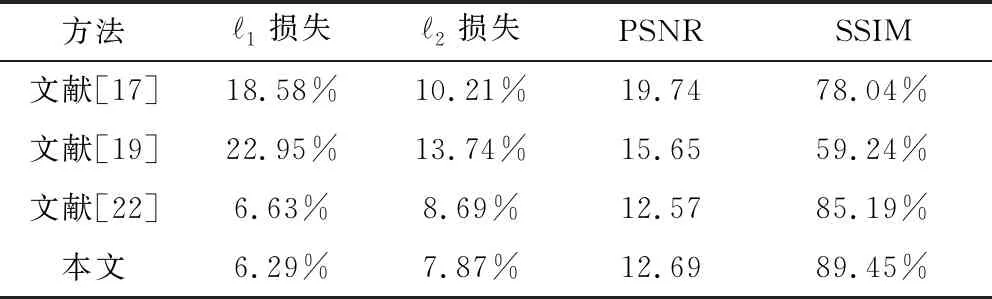
表3 算法整体有效性定量对比

(a) (b) (c) (d) (e)
4 结束语
本文提出了一种基于画面主体特征、视觉平衡原理和三分法则的计算机构图优化方法。本文利用深度网络模型获取图像显著性主体,以实现符合图像美学的优化重构。经定性和定量实验对比验证,本文优化算法可有效地解决图像主体位置不佳等构图缺陷问题,并为图像美学构图优化算法的设计提供了新的思路。然而图像构图是一个比较复杂的问题,图像美学还与诸多因素有关,本文算法能依照常用的构图方法对图像进行优化,但用于某些个性化、风格化较强的图像时效果并不理想,这也是今后研究的主要方向。
