基于先验知识的小样本刑期预测算法研究
2021-03-08姚直言赵学龙
姚直言,赵学龙,戚 湧,严 悍
(南京理工大学 计算机科学与工程学院,江苏 南京 210094)
0 引 言
随着深度学习的快速发展,这项前沿技术被应用于各个领域,如在医学[1]、商业[2]以及图像处理[3]等方面都取得了不少成果。在法律量刑方面,将神经网络用于量刑预测也取得了一些成果[4-6],但由于判刑依靠法官经验和主观判断,甚至在极端情况下会出现矛盾的判决,训练样本存在大量噪声,神经网络在此领域的表现不如其他领域优异。
该文提出了一种将先验知识转换为虚拟样本加入数据中进行训练与约束的方法,设计并实现了两层BP神经网络进行回归预测,选取了特定犯罪情节—盗窃作为预测对象,并在样本数较少,样本噪声大[7-10]的情况下,进行了定量的实验,证明了此方法可以提高预测的准确度,降低预测刑期的误差。
该文主要分为四个部分,第一部分粗略介绍了BP神经网络的原理,以及先验知识在神经网络优化上的应用;第二部分介绍了利用先验知识生成虚拟样本辅助训练的具体方法;第三部分是具体实验验证,首先介绍了当今司法系统中普遍存在的量刑偏差问题,然后实现了具体的BP神经网络进行交叉检验,验证了该方法的有效性;第四部分是一个简短的概括总结。
1 相关理论
1.1 BP神经网络
BP神经网络[11]是一种多层前馈网络,包含一层输入层、多层隐层以及一层输出层,理论上三层及三层以上的BP神经网络有着逼近任意函数的能力。BP神经网络根据输出层的输出与期望结果之间的误差,即损失函数,用梯度下降法反向传播更新权值,直到损失函数达到精度要求。图1是一个简单BP神经网络示意图。
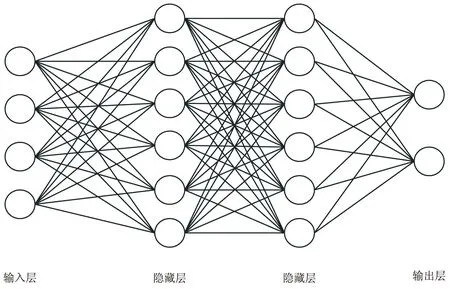
图1 简单BP神经网络示意图
训练BP神经网络的过程大体可分为两个部分:前向传播和反向传播。
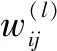
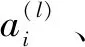
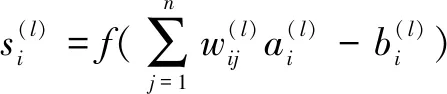
(1)
反向传播过程中,根据损失函数计算预测误差,然后通过梯度下降方法修正误差,调整权值、偏置等网络参数,如式(2)、式(3)所示:
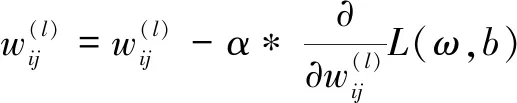
(2)
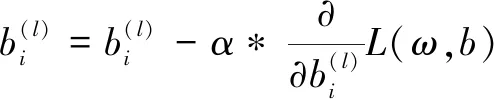
(3)
通过链式法则可求得偏导数,反复迭代直到损失函数满足精度要求。
1.2 先验知识在BP神经网络上的应用
先验知识[12]是指先于经验的知识,在先验知识应用于深度学习上的研究中,宣冬梅等人[13]为解决在多分类问题中使用深度学习方法提高分类效果的模型通常很复杂,且运行时间较长等问题,提出了先验知识与深度学习结合的方法,在MNIST手写体数据集上进行的实验中,以一定规则获取先验知识,提高了多分类方法的识别率,且使得学习的结构更加简单;Yaser S.Abu-Mostafa在预测外汇交易市场的实验[14]中,提出了利用对称性提示生成虚拟样本,并作为训练集的一部分训练模型的方法,大大提高了预测的准确度。
2 方法介绍
2.1 量刑偏差
量刑偏差是世界普遍存在的问题。量刑偏差,是指审判机关在同一时空条件下,对性质相同、情节相当的犯罪,在适用相同的法律时,刑罚裁量相差悬殊的现象。因刑罚裁定人是法官,不同的法官对相同的案情有着不同的主观判断,以及法官判刑多以经验论,难免出现量刑偏差的问题。再者,不同的地区经济发展状况不同,法官的评判标准也难免不同。在这些复杂因素的共同作用下,造成了量刑偏差这一普遍存在的问题。而如果要构建一个神经网络系统预测量刑,单单以真实数据作为训练样本,包含了大量的偏差和噪声,神经网络在一定程度上无法客观地学习到知识或规律,势必会对最后的预测结果造成影响。所以,该文提出了基于先验知识构造虚拟样本辅助训练,约束神经网络的方法。
2.2 虚拟样本
因为真实数据中包含了法官的主观判断和地区经济发展程度等主观因素,训练样本中包含大量的噪声,神经网络拟合效果不佳,没有学习到随金额上升预测刑期上升这一个关键因素,而对其他因素分配过重权值。所以针对这种情况,该文提出一种基于先验知识产生虚拟样本辅助训练的方法,基于大量经验总结出来的规则生成虚拟样本[14-15],加入到训练样本中。
按照规则[16]生成除盗窃金额、判决刑期不同,其余维度均相同的虚拟样本,如表1所示,其中x和f(x)分别对应盗窃金额和判决刑期。

表1 虚拟样本示例
如此构造虚拟样本,可以强化神经网络学习到刑期预测的“骨架”——在其他条件相同的情况下,盗窃金额越大,判决刑期应该越高。
3 实验验证
3.1 预测模型
盗窃金额是刑期判罚的关键因素,因此在建立神经网络模型时,以盗窃金额为主要的判断依据,结合年龄、是否主犯、初犯还是累犯等因素进行综合分析,最后输出预测刑期。建立的预测模型如图2所示。
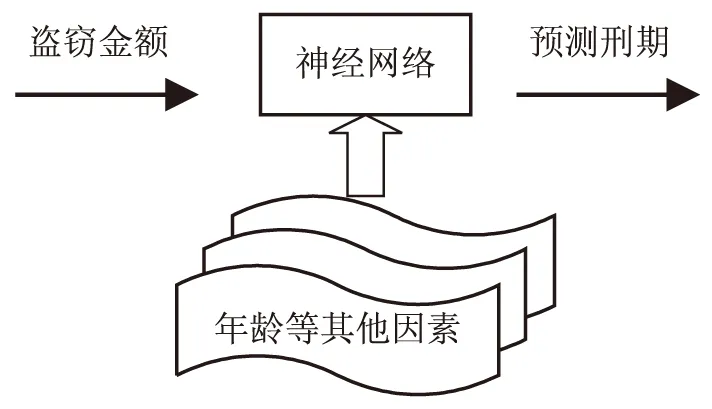
图2 神经网络预测模型的描述
3.2 网络结构
该量刑预测系统采用四层BP神经网络实现,分别为一层输入层、两层隐层和一层线性输出层,输入层神经元结构如表2所示,分为X1至X16共16个神经元,分别代表各种量刑情节以及案件性质。其中X9为案件盗窃金额,为判决中真实实数,其余变量均为布尔变量。设(X,Y)为样本空间,X为样本输入,Y为样本输出(期望输出)。

表2 量刑情节各种情况与输入层神经元变量对应关系
隐层共两层,每一层采用8个神经元,激励函数采用式(4)的Relu函数。
Relu(x)=max(0,x)
(4)
输出层采用式(5)线性函数,输出单变量,即预测刑期。
f(x)=x
(5)
损失函数采用式(6)均方误差(MSE)。
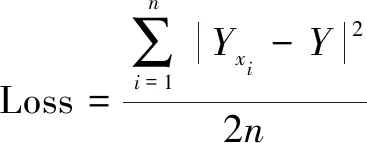
(6)
评价指标采用式(7)平均绝对误差(MAE)和式(8)相对准确度。
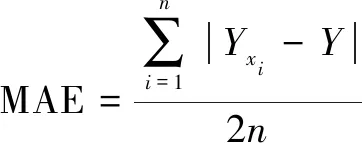
(7)
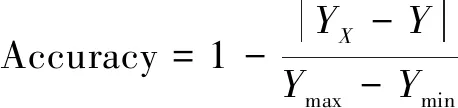
(8)
式(8)中,Ymax与Ymin代表实际判决期限所在区间。据中华人民共和国刑法规定,将盗窃刑期粗略划分为0至3年,3至10年,10至无期徒刑三个区间,其中无期徒刑在本公式中用21年代替。若实际判决期限为4年,在3至10年区间内,则相对准确度应该如式(9)所示。
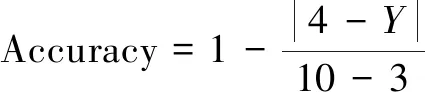
(9)
3.3 交叉检验
将北大法宝网站上选取202例盗窃罪名的案件作为学习样本,取出其中40例作为测试样本,以上述方法生成占训练样本数0%、10%、20%、30%…90%的虚拟样本加入训练集中辅助训练。测试试验获得数据如表3所示。
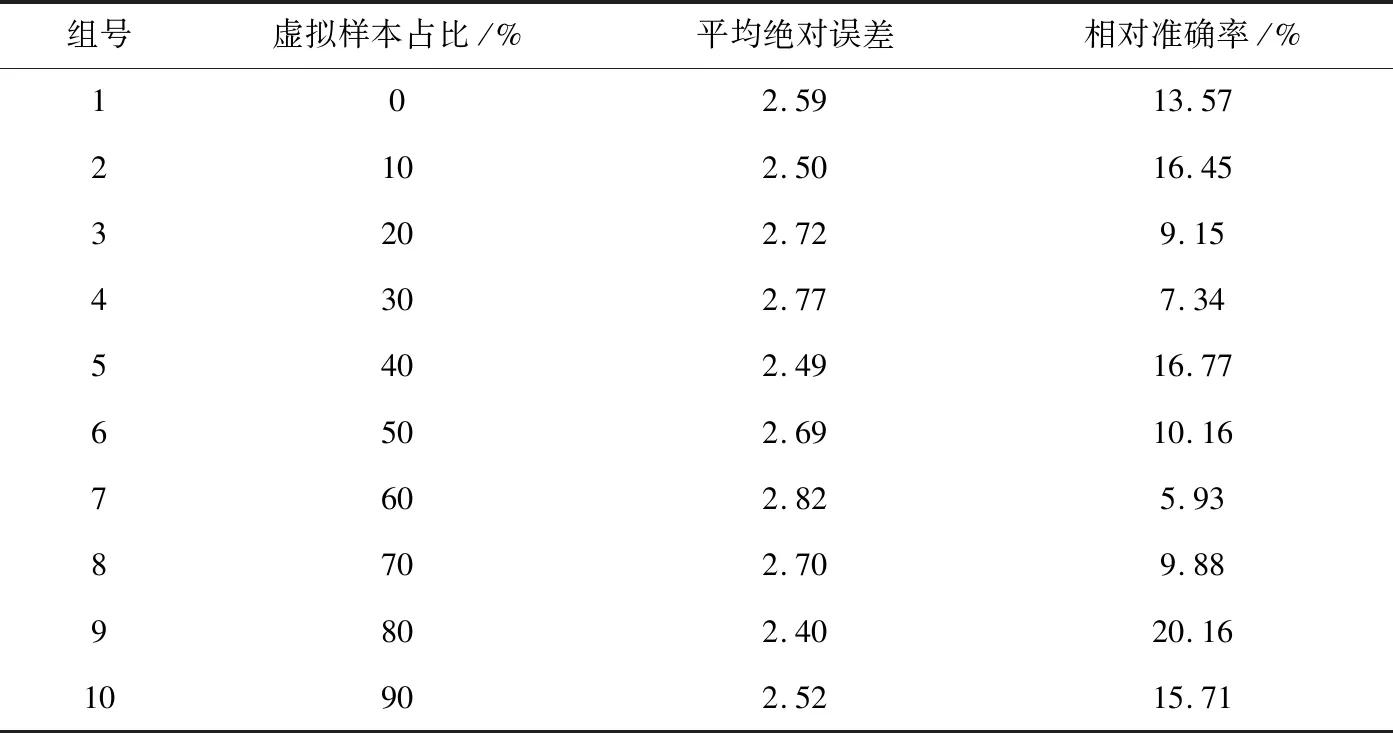
表3 不同虚拟样本占比组具体数据
将表3中的平均绝对误差(MAE)作为纵轴,用训练迭代次数(epoch)作为横轴,建立平均绝对误差变化曲线,如图3所示。
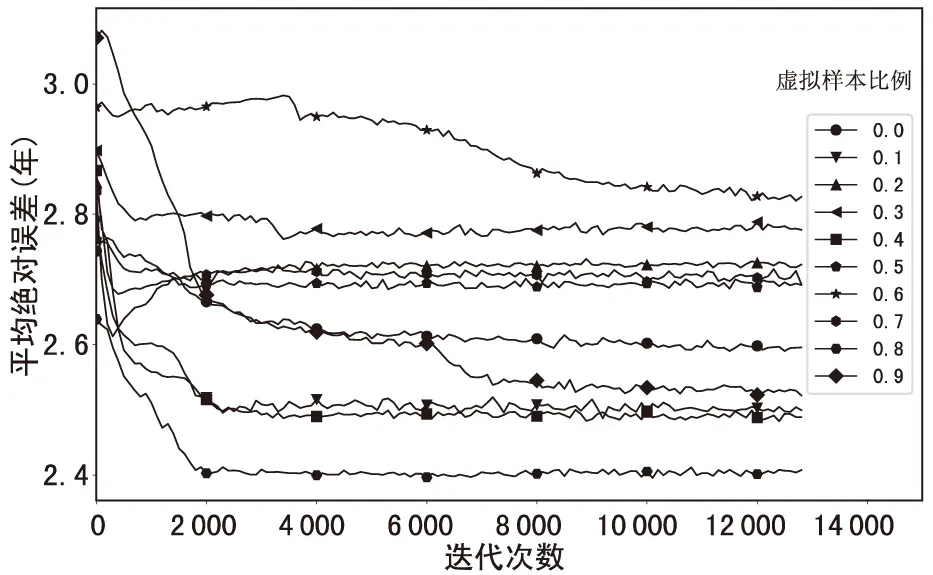
图3 平均绝对误差变化曲线
以相对准确率(Accuracy)和训练迭代次数(epoch)的关系建立相对准确率变化曲线,如图4所示,其中每一条不同线型的线平均绝对误差/相对准确率0.X代表虚拟样本占总样本数的X%。
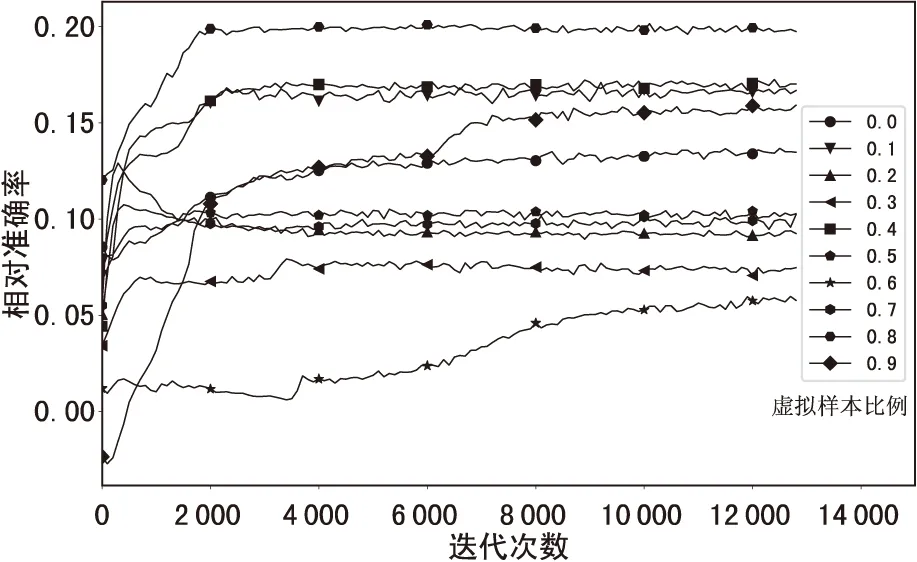
图4 相对准确率变化曲线
由图3和图4可见,虚拟样本占训练样本集10%、40%、80%、90%时的拟合效果比不加虚拟样本要好,说明虚拟样本辅助训练的方法在小样本上是行之有效的。通过对比发现,虚拟样本比例在80%时效果最好,刑期平均绝对误差降低了4个月左右,相对准确率提高了8%左右。考虑到实验于小样本上进行,且样本中包含了大量噪声,虽然数据拟合的平均损失误差相对较高,相对准确率相对较低,但从整体对比来看,实验证明虚拟样本的加入的确有助于网络学习到本质规律,改善了神经网络在小样本上的表现,弱化了主观判断和大量噪声在训练集中的作用,增强了拟合效果。
4 结束语
该文提出了基于先验知识的虚拟样本辅助训练神经网络方法,改善了神经网络在小样本上的表现,一定程度上克服了传统司法系统中存在的量刑偏差问题。将案件的量刑情节人工提取出来,加上虚拟样本的纠正作用,使得神经网络既学习到了其余因素的影响,同时也不会丢掉最关键的规律。实验结果表明,该方法在小样本上刑期预测平均损失误差可降低4个月,平均准确率可提升8%,相对有效地改善了神经网络在量刑预测问题上的拟合能力,为此类问题提供了一个新的研究思路与方向。
