基于句法和语义的需求依赖关系自动获取
2021-03-08贾成真
关 慧,吕 颖,贾成真
(沈阳化工大学 计算机科学与技术学院,辽宁 沈阳 110000)
0 引 言
需求工程通过一种系统化的工程过程实现涉众需求的抽取、协商和文档化。作为需求工程输出制品的需求文档和需求规约是所有其他系统开发活动的重要基础[1]。在软件生命周期的概念建模阶段,需求的常用表示方式有用例和基于自然语言的文本形式。基于自然语言的文本收集了各类需求信息,因为自然语言本身就有多方面含义,并且对于自然语言的理解会由于各种因素的影响而不断改变,因此在处理自然语言以及需求关系分析的过程中也离不开人的参与。但是这并不是说自动建模工具的辅助没有存在的必要。如果遇到一个比较复杂的系统时,需求文本的处理工作量是相当大的,为了能够尽可能缩短处理的时间,减轻需求分析师的工作负担,一些自动化工具或者系统就显得尤为必要。目前在UML模型的自动生成上已有一些相关的工作。利用UML建造系统时,在系统开发的不同阶段有不同的模型,并且这些模型的目的是不同的,例如用例图、类图和活动图等。这些方法的处理过程可以总结归纳为:首先从文本中获得特定的信息,然后定义一系列的转换规则,最后再通过这些规则将需求文本映射到对应的图形化模型上。
需求文本由于它独特的领域知识以及潜在的语义而不同于普通文本:(1)需求文本通常不仅包含需求制品(即所描述的目标、场景、功能需求、质量需求和约束),还包含一些重要的上下文关系。(2)需求文本由于它特定的领域知识,一些领域词汇被定义语法词性。如:“联系信息”一词在需求文本中被定义为名词。(3)自然语言描述的需求文本也有一些本质性的问题,如固有的二义性。
为了解决上述问题,文中在自然语言表示的需求文本的基础上,施加语法限制,降低了自然语言描述需求存在的二义性等问题。通过定义语义词库,联系到需求文本的语义关系,实现了从大量的需求文本中自动抽取需求依赖关系的方法。基于该方法,设计并实现了一个自动从中文需求文本生成需求间依赖关系的原型系统,对需求依赖关系进行自动获取。最后,通过案例验证及对比,证明了方法的可用性和切实性。
1 相关工作
在需求自动建模开发工具上,李天颍等人[2]基于依存文法,依次对自然语言进行分词、词性标注及语法分析,设计并实现了一个系统,从中文需求文本自动生成i*框架中的SD(strategy dependency,策略依赖)模型,侧重抽取策略依赖关系信息,他们研究的同一个需求内部之间的依赖关系。Chetan Arora等人[3]应用NLP自动识别需求语句的组成短语,然后计算所有标识的成对相似度分数,输出句法和语义相似性函数,以判断需求之间存在关系,但他们并没有得出需求之间存在的关系类型。韩德帅等[4]将可视化的UML与严格化的时间自动机相结合,但该方法侧重于软件的实现阶段,不支持软件自适应的需求建模和形式化验证。
在定义需求依赖关系类型上,国内外学者均做了若干相关研究。罗术通[5]依据UML的定义把需求定义为七种原子关系:调用、中断、唤起、修改、通知、控制、资源控制,其次,提出了需求簇的概念以及基于需求之间关系划分需求簇的方法。关系的两个主体是直接影响彼此,并不依赖于其他主体,然而,这种关系并没有形式上的语义。Arda Goknila等人[6]研究的重点是业务需求的演变所带来的需求变化,旨在通过使用形式来改进需求中的变更影响分析需求关系和需求变更类型的语义,他们确定了五种关系类型:要求、精炼、包含、部分细化和冲突。R.P. Gohil等人[7]提出一个分析其影响的框架,并用依赖图显示需求之间的依赖关系,把需求看成事件,在框架中自动添加需求依赖关系。Hassine等人[8]基于UCM模型分析需求变化的影响,定义UCM元素之间依赖关系,并通过功能依赖、时间依赖、包含依赖和组件依赖性对它们进行分组。
在关系抽取领域上,国内外已经有很多研究成果,应用到各种不同的领域。甘丽新等人[9]主要利用依存句法分析中文实体关系抽取,肜博辉[10]提出多通道卷积神经网模型,用于多通道卷积神经网的实体关系抽取,还有的学者如李丽双[11]和田生伟[12]等人将关系抽取应用到生物医学和事件因果关系方面上。目前尚没有一个方法是用于自动获取需求间的依赖关系的研究。
2 需求依赖关系自动获取方法
在同一系统中,两个需求之间可能存在直接或间接的依赖关系,需求依赖关系描述了需求之间的功能调用,也就是说,一个需求可以直接或间接地作用于另一个需求,并对之产生影响。文中提出了一种自动获取需求依赖关系的方法,其主要步骤如图1所示。
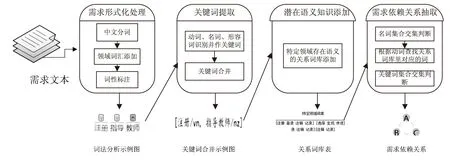
图1 需求关系自动获取方法框架
以自然语言描述的文本需求,往往不能被计算机理解,在实践中这已成为需求工程的一个显著的问题。为解决这一问题,文中需要对自然语言描述的需求文本进行处理,处理的第一步就是将需求形式化[13]。将需求表示成由关键词组成的数学集合。首先对已有的分词工具HanLP(http://hanlp.com/)进行改进,添加特定领域的语法词性对需求进行分词以及词性标注;其次提取需求文本中的关键词,通过依赖关键字中动词、名词等词性的语义特征来判断不同需求之间的关系类型;最后,通过系统自动抽取需求依赖关系。
2.1 需求形式化处理
定义1:需求是指用户解决某个问题或者达到某个目标所需要的条件或能力。每一个需求文本都由若干个需求组成,其中需求均被定义为以下形式的三元组:
Ri={R.content,R.kwset,R.relation}
其中,R.content是指需求文本的内容,R.kwset指提取需求中添加约束后提取的关键词集合,R.relation表示需求之间的依赖关系。关键词集合和依赖关系的定义见定义2和定义3。
提取关键词首先需要分词,文中基于已有的工具HanLP进行中文分词及词性标注,但由于需求文本中存在大量的领域词汇,一些词汇在分词或词性标注的过程中可能会发生错误,会直接影响到关系抽取的准确性。例如:“注册一个新指导教师”和“系统应使学生能够检索学生和预订课程的讲师的联系信息”这两条需求语句中“指导教师”和“联系信息”会被注释为动名词,而需求文本中“指导教师”和“联系信息”均被定义为名词,这一差异会影响关系的抽取。为了解决该问题,文中在原有的分词工具上添加了领域词典,通过遍历领域词典,修改被错误标注的词性和分词结果,从而提高关系抽取的准确率。基于3.1.1节测试的文本主要添加的领域词汇有:指导教师(n)、联系信息(n)、指定学校(n)、分数评定(v)、评估结果(n)、信息传递设施(n)、课程评估(v)、完成项目(v)、解答疑问(v)。下面是对分词工具的改进方法之一:如CustomDictionary.insert(“联系信息”,“n”)。
2.2 关键词提取
基于2.1节的分词及修改后的词性标注,文本中的需求可以用若干个短语组成,常见的短语有很多种,如:动词性短语、名词性短语、形容词性短语、副词性短语、连词性短语、介词短语以及动名词结构等。而提取出的关键词的共现程度可以被视为其语义相关性的度量,由于动词能够很好地反映需求中某些事件之间的关系类型,很多依赖关系通常可以通过动词来引发。同样判断两个需求潜在的语义关系时需要通过动词之间隐含的语义来引发,然而只依靠动词判断关系势必会造成很多不相关的需求也出现依赖关系,与研究结果差异太大,因此文中引入了通过名词的共现程度来考虑是否需要联系动词的语义特征。基于上述问题,文中主要保留动词(v)和名词(n)作为每个需求语句的关键词,并把每个需求封装成一个关键词集合来表示。
定义2:关键词集合是指对需求进行关键词提取之后由动词和名词词性所组成的集合。
R.kwset={v1,v2,…,vn,n1,n2,…,ni}
2.3 语义词库添加
文中重点在于需求关系特征的选择和抽取,以需求文本表示的需求通常被用于全文本分析,因此会忽略与特定领域相关的语义特征,同时词汇之间的语义信息也容易被忽略,这些潜在的问题给需求之间依赖关系的抽取任务带来了挑战。
为了解决上述问题,文中通过分析词汇之间的语义,提出自动抽取需求之间依赖关系的方法。通过定义具有语义关系的关系词库(如:有前提关系的词汇对),利用关键词集合中各个词的词义来联系两个需求之间的语义关系,结合领域相关的语义特征,通过关键字词性映射来抽取特定领域的需求依赖关系,更好地应用于抽取结果。此外,需求语义词库的建立是一个动态的过程,需要在更多了解用户的需求上修改或补充需求以及关系词库表和语义关系。
表1给出了针对文中测试的需求文本领域所添加的关系词库表。由于测试文本篇幅较小,因此提取出的关系词也有限。可以看出,关系词库知识的引入丰富了需求文本中词汇的语义,使得提取结果更为准确。
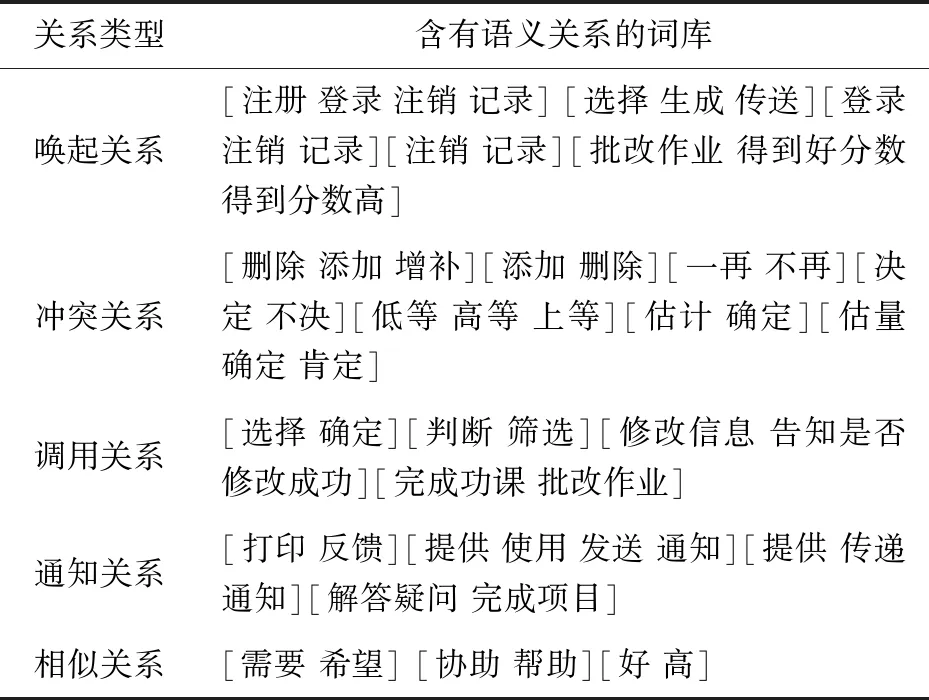
表1 含有语义关系的依赖关系词库表
2.4 需求依赖关系抽取
2.4.1 依赖关系定义
需求之间存在多种依赖关系类型,比如:前提、相似、解释、影响、异常、冲突、业务相关、进化、价值、成本、精炼、包含、部分细化和不相关等多种关系[14-16]。
需求之间的关系采用统一建模语言中定义的关系语义来描述,并且在特定的系统中,所抽取的需求关系被限制在一定的范围内。文中主要对以下6种需求关系做自动化抽取,分别是:相似关系(similar:s)、聚合关系(polymerize,p)、唤起关系(arouse:a)、调用关系(call:c)、通知关系(notice:n)及冲突关系(conflict:co)。
定义3:需求依赖关系指的是一个系统中一个需求与另一个需求之间的关系,也就是说,需求与需求之间可能存在直接或间接的依赖性关系。它被定义为:
R.relation={R.s,R.p,R.a,R.c,R.n,R.co}。
通过系统对其进行抽取和验证。以上关系的非正式定义如下:
相似关系:如果R1和R2需求相同,则具有相似关系。
聚合关系:如果需求R2是R1的一部分,则R1与R2是聚合关系。
唤起关系:如果需求R2需要在R1后才能实现,则R1和R2有唤起关系。
通知关系:如果R1在实现后允许R2开始实现,则R1和R2有通知关系。
调用关系:如果R1在实现的过程中需要先实现R2,即R1在R2之前实现,但R2先于R1完成实现,则R1和R2具有调用关系。
冲突关系:如果R1和R2不能同时实现,则R1和R2有冲突关系。
2.4.2 计算相似度
文中把需求划分为几部分短语再提取出关键词,通过关键词在任意两句的全部关键词集合中出现的频率,把词频表示成向量来计算余弦值得出相似度,这个方法分为以下三部分:(1)每条需求文本各取出若干个关键词,合并成一个集合,计算每个需求对于这个集合中的关键词的词频;(2)生成两个需求各自的词频向量(这个向量是n维的,形如:A[A1,A2,…,An]);(3)计算两个向量的余弦相似度,文中取余弦值大于0.4作为相似参考。常用的计算余弦值的公式为:
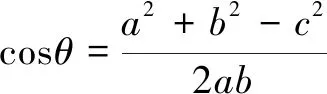
(1)
已有数学家证明,计算余弦值的这种方法在计算n维向量中同样适用。在步骤2中把每个需求的词频分别用n维向量表示,如:A=[A1,A2,…,An],B=[B1,B2,…,Bn],那么A与B的夹角θ的余弦值为:
(2)
通过这个公式可以求得两个需求之间的相似度,如:R13:指导教师选择评估某个学校的作文,R14:指导教师选择评估某个年级的作文。提取关键词得出R13[学校,选择,教师,评估,指导];R14[年级,教师,选择,评估,指导],词频向量A:[1,1,1,1,1,0];B[0,1,1,1,1,1],通过公式计算余弦值为0.8。
算法1:计算相似度算法伪代码。
GetSimilarity(int[]wordA,int[] wordB) returns num
wordA;{*需求文本A的词频向量*}
wordB;{*需求文本B的词频向量*}
dividend;{需求文本A、B词频向量的乘积*}
divisor1;{需求文本A的词频向量值*}
divisor2 ;{需求文本B的词频向量值*}
num;{需求文本A、B的相似度*}
for i←0 to wordA.length
dividend←dividend+wordA[i] * wordB[i]
divisor1←divisor1+Math.pow(wordA[i], 2)
divisor2←divisor2+Math.pow(wordB[i], 2)
end for
num←dividend / (Math.sqrt(divisor1) * Math.sqrt(divisor2))
Return num
End GetSimilarity
2.4.3 关系抽取方法
若要判断直接关系(如相似等),通过关键词的共现程度采取集合运算即可;若两个需求之间存在间接依赖关系,那么在这两个需求中一定会出现两个动词,通过这两个动词判断出这两个需求是否存在上下文关系,如果不考虑动词之间所存在的语义关系,会让抽取结果不准确或遗漏。
因此,为了解决上述问题,文中采用基于潜在语义获取需求依赖关系的方法,通过关键词的共现程度联系动词的语义特征来判断需求依赖关系。基于2.2节提取关键词之后,关系抽取方法分为四步(如图2):
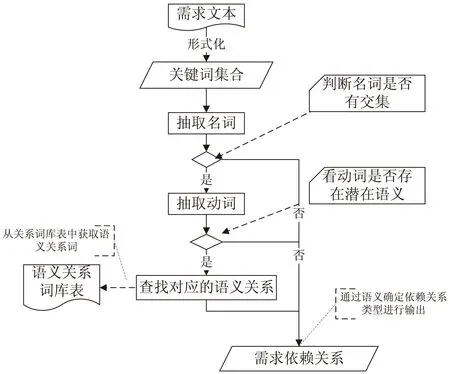
图2 依赖关系抽取方法
(1)抽取名词。将分词中的名词抽取放在集合A1、B1中;(2)判断名词有无交集。若集合有交集[名词有一致的部分-主语],则进行第3步;(3)抽取动词。抽取的动词放在集合A2、B2中;(4)判断关系。通过在自定义的潜在语义关系词典中,查找集合A2中动词对应的关系词C;若关系词C存在集合B2中的动词,则通过关系词判定另两个需求之间存在何种关系,最后确定依赖关系。为了证明文中方法的有效性,文献[5]中基于需求文本提到的依赖关系被用来进行对比实验,并对文献[5]的需求依赖关系做自动抽取。
算法2:关系抽取算法伪代码。
Dependencies(StringxqTextA,String xqTextB) returns result
xqTextA;{*需求文本A*}
xqTextB;{*需求文本B*}
List
{*需求文本A的分词词组*}
List
{*需求文本B的分词词组*}
List
{*需求文本A的名词集合*}
List
{*需求文本B的名词集合*}
List
{*需求文本A的动词集合*}
List
{*需求文本B的动词集合*}
Boolean Nend = false;{*名词是否匹配成功*}
Stringresult = NULL;{*需求依赖关系*}
termA= HanLP.segment(xqTextA);
termB= HanLP.segment(xqTextB);
for i←0 to term[A/B].size()
{*通过词性标注n抽取termA,termB的名词集合*}
if(term[i].nature.startsWith("n") = true) then
NListTerm[A/B].add(term[i].word)
end if
end for
for j←0 to NListTermA.size(){**}
if(NListTermB.contains(NListTermA[j])=true)
{*名词匹配成功的话获取动词,之后可以根据语义词库获取需求依赖关系*}
Nend=true;
for i←0 to term[A/B].size()
{*同理通过词性标注v抽取termA,termB的动词集合*}
if(term[i].nature.startsWith("v") = true) then
NListTerm[A/B].add(term[i].word)
end if
end for
Break;
end if
end for
if Nend == true{*根据语义词库获取需求依赖关系*}
for i ← 0 to VListTermA.size()
for j ← 0 to VListTermB.size()
if((VListTermA[i],语义词库).contains
(VListTermB[j])) then
result ← 关系类型
end if
end for
end for
end if
Return result
End Dependencies
3 系统实现和实例验证
3.1 实验验证和相关工作对比
3.1.1 实验验证
为证明该方法的可行性,文中采用如下评测标准:准确率P、召回率R和F1度量值,其中准确率P用来表示抽取结果中正确标注为给定关系类型所占的比率,召回率R表示相对于测试数据集抽取结果中正确给出关系类型所占的比率,F1度量值表示度量实验的准确性。针对需求依赖关系抽取的结果,具体评价公式为:
P=(抽取结果中正确标注为给定关系类型的需求对的个数)/(结果中标有存在给定关系类型的需求对总个数)
(3)
R=(抽取结果中正确标注为给定关系类型的需求对的个数)/(测试数据集中所有存在关系的需求对
总个数
(4)
(5)
文中测试了三个数据集来验证方法的可行性,分别是文献[2]、文献[5]和文献[6]中的需求文本,结果如表2所示。
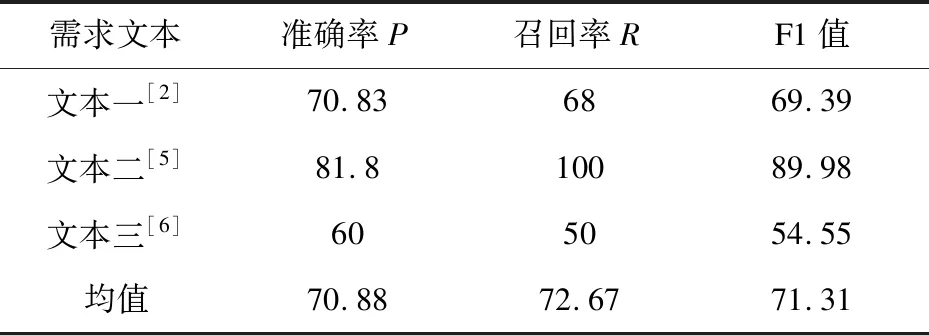
表2 实验结果 %
如表2所示,无论准确率还是召回率的均值均在70%以上,且文本一和文本二的准确率和召回率均较高,说明该方法是可行的。文本三的召回率只有50%,并不高,说明当前系统在关键词的语义上处理得并不是很准确,主要原因在于文本三的需求文本采用文献[6]的英文需求文本翻译而来,在一些词汇和句式上处理不准确,如一个英文单词可能对应多个汉语释义,在系统提取关键词对比时匹配不到相同的关键词而引起误差。
3.1.2 相关工作对比
笔者分别对三个领域的需求文本做了实验并与专家抽取的关系作对比,分别统计需求和需求间关系识别结果,其对比数据如表3所示。为了更直观地表示文本一需求之间的依赖关系,图3给出了文本一案例对比的需求依赖关系图。
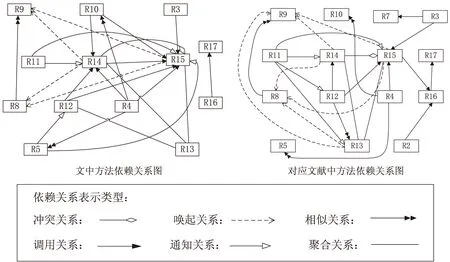
图3 文本一需求依赖关系对比
由于文中是基于中文需求,和国外相关工作使用同一数据集作对比时有一定偏差,同义词太多,系统无法正确做出判断,导致了一些关系抽取的误差。但从实验结果来看,文中方法准确率较高,有一定的可用性。同时,表4给出了文中方法在不同关系类型抽取上的性能分析数据。从表3的效率以及表4的数据来看,文中在加入领域词汇以及定义语义词库这两大特征后,其效率以及各方面性能百分比都较高,从一定程度上证明了文中方法的可行性及可靠性。图4表示了在不同领域上文中方法抽取结果的数据分析。

表3 相关工作对比

表4 文中方法在不同关系类型抽取上的性能 %
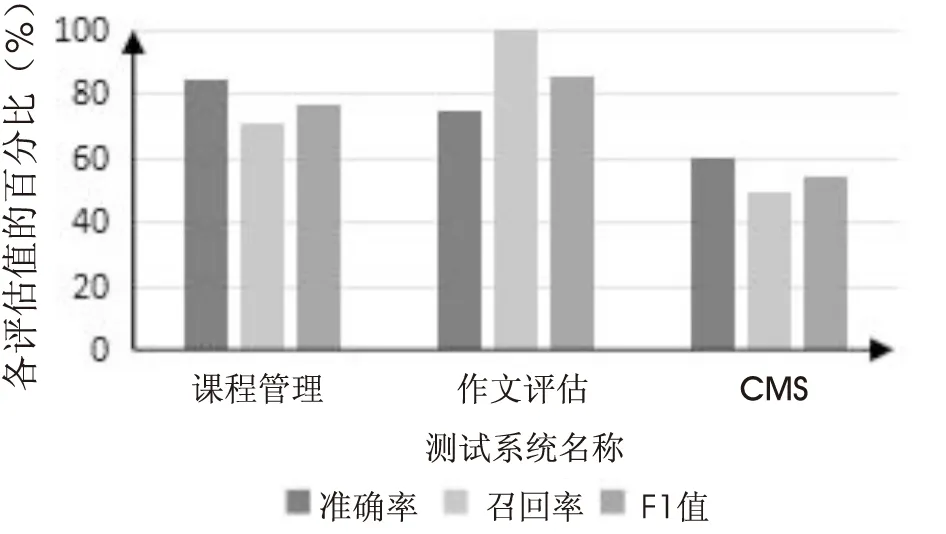
图4 不同领域文中方法的数据分析
3.2 系统实现
使用servlet+jsp技术设计并实现了一个针对中文自然语言需求文本的依赖关系抽取系统,对系统中用到的方法中的各个步骤进行了支持。该系统主要由需求文本添加、文本相似度、文本查询以及需求依赖关系显示4个模块组成,想要查询的需求对象与哪些需求有关并获取需求之间的关系类型都可以在点击此需求时显示,页面如图5所示。

图5 系统实现界面
4 结束语
文中基于领域知识和语义相结合的方法实现了对需求依赖关系的自动化抽取,首先对已有的分词工具进行改进,其次提取关键词,对关键词集合里的词性作集合判断,联系潜在的语义判断需求依赖关系,最后通过系统证明方法的可用性,不仅对定义的几种关系进行自动获取,同时对参考文献中定义的关系也进行了实现并与之结果进行比较得出该方法的优点与不足。该方法的优势在于:(1)基于关键词,不同关系上对关键词处理可能不同,使结果更可信;(2)添加了一些领域词汇,消除了自然语言固有的二义性;(3)建立语义词库表。根据用户需求的特点,设计关系词库表,定义各个词汇之间的语义关系,使结果更准确;(4)自动抽取关系。以便于在需求量巨大的时候可以节省人力物力,具有更高的效率。不足之处在于包含语义的词库添加上属于人工添加并且仅仅是基于特定领域上,测试集越多,需要的人力资源也就越大,未来将在这方面以及需求变更上做进一步研究。
