一种面向Mashup应用的API推荐方法
2021-03-08李鑫
李 鑫
(河南大学 计算机与信息工程学院,河南 开封 475000)
0 引 言
近年来,随着Web2.0技术的兴起,大量功能丰富的Web服务不断涌现。Web服务基于互联网提供一种端到端的解决方案,由于其低成本、简单易用等优点逐渐受到开发者们的青睐。为了满足更复杂的场景和个性化需求,人们将多种功能不同的Web服务及其资源组合成Mashup服务。由于Web服务所处网络环境动态变化,导致用户选择并调用的Web服务常常不可获取(unavailable),即发生服务失效,这在一定程度上影响了用户对服务的选择,进而影响Mashup服务的应用。因此,在Web服务出现失效或不可用的情况下,获取(unavailable),即发生服务失效,这在一定程度上影响用户对服务的选择,进而影响Mashup服务的应用。因此,在Web服务出现失效或不可用的情况下,如何为用户推荐可替代的Web服务,仍然是一个亟待解决的关键问题。
目前,国内外研究人员针对失效服务无法调用的情形进行了相关研究。文献[1]探讨了服务描述文档(WSDL)中无效文件格式、解析错误和调用目标异常等造成服务失效的具体原因。文献[2]采用基于WordNet的概念语义进行功能相似度匹配,然后根据服务的调用率,从Web服务描述文档质量角度构建Web服务质量评价模型,进而选取服务以替换无效的Web服务。文献[3]在流程执行前,通过查询UDDI及QoS约束过滤,预先获得各成员服务的候选服务集合,并引入面向切面技术扩展BPEL引擎,通过容错代理切面拦截服务请求和调用服务实例,在服务失效时利用候选服务集合中的等价服务替代失效服务。但是,上述方法在为失效服务选择可替代服务时没有考虑到服务本身的规格信息,比如服务遵循的协议、服务的相应格式等。
针对该问题,该文提出了一种面向Mashup应用的API推荐方法。该方法首先从服务注册网站Programmableweb上爬取了API描述信息及其规格(Specs)信息,并对API的描述信息和规格信息进行预处理;在此基础上,通过LDA(latent Dirichlet allocation)主题模型对API描述信息进行主题聚类,然后从功能相似性角度出发,识别失效API所属的主题类簇,进而从API的规格信息方面通过Jaccard系数对失效API所属的类簇内的API进行筛选,将失效API与类簇内筛选后的API进行描述相似度计算并将相似度从高到低排序,将前Top-n个API进行推荐。
1 相关研究
文献[4]通过以Web API的描述文档信息为语料库,通过HDP模型训练每个Web API的主题分布向量,利用已生成的主题模型预测每个Mashup的主题分布向量,用于相似度计算,并将Mashup间的相似度、Web API间的相似度、Web API的流行度共现性作为模型的输入信息,将得到的评分排序获取用于推荐的Web APIs集合。文献[5]通过用户历史记录信息,获得用户对API服务的兴趣值,从而得到用户对API的评分,通过Mashup调用API次数可以获得Mashup的评价贡献和API访问量,获得API服务的信誉评价值,根据用户对API服务的兴趣值以及信誉评价值,获取API服务的排名顺序,从而实现推荐。文献[6]针对API服务进行个性化推荐,其方法是通过Spark计算框架与改进的相似度计算相结合,解决了传统算法中的数据稀疏问题,提高了推荐算法的执行效率。
上述方法虽然考虑了API的表征能力以及API的流行度共现性,但是没有考虑到API本身的规格信息,比如,Programmableweb网站中每个API都有相应的Specs信息,具体包括Authentication Model、SSL Support、Supported Response Formats、Supported Request Formats等。在该研究中,首先对预处理后的API进行主题聚类,然后结合API的规格信息对特定主题类簇下的API进行过滤,在此基础上进行相似度计算,将相似度排名Top-n的API推荐给用户。
服务聚类是辅助服务发现的一种重要方法。目前基于相似度的服务聚类方法已有大量研究,具体描述如下:
(1)基于用户自身偏好相似度的服务聚类。文献[7]提出为用户与物品之间定义了一层关系,这层关系是由用户自身偏好的关键属性决定的,由此来排除不符合这层关系的集合,并结合对各个不同属性分配不同的权重来挑选出最符合的服务。文献[8]提出了基于Web服务描述语言、服务本体描述语言和文本方法的Web服务聚类方法。
(2)基于服务文本相似性的服务聚类。文献[9]提出一种可以分步骤的对服务进行聚类的方法,第一步,先是利用一个具有融合领域特性的支持向量机对一个服务进行分类的操作;第二步,对进行分类后得到领域内服务的集合进行主题特性聚类。文献[10]通过建立一个服务的融合领域特征和内容支持向量,并通过使用T-LDA方法建立一个融合领域标签信息得到的隐含主题信息表示模型,用于同一融合领域服务进行聚类的操作。
(3)基于LDA的服务聚类。采用LDA的主题模型对其服务描述信息模型文档进行了建模,并设计和分析其包含的主题描述信息的分布,挖掘潜在语义知识,有助于解决使用单一关键字引起的信息丢失问题。
该文基于Word2vec和LDA对API描述文档进行主题聚类,在此基础上,结合API本身的规格信息,有利于提高可替代API服务推荐的准确率。
2 融合描述和Specs的API推荐方法
2.1 方法的框架研究
研究框架如图1所示。首先通过网络爬虫技术爬取Programmableweb网站上的API描述信息和API Specs信息,然后对API描述信息和API Specs信息进行预处理。在此基础上,基于Word2Vec和LDA主题模型对预处理后的API描述信息进行主题聚类;针对特定失效API,通过相似度计算识别该API所属的主题类簇;进一步通过Jaccard系数计算该主题类簇下的API的规格信息与失效API的规格信息间的相似度,筛选出规格信息满足要求的API集。最后将失效API与筛选后的API集合中的每个API进行相似度计算,将相似度较高的Top-n个API返回,从而实现失效API的推荐。
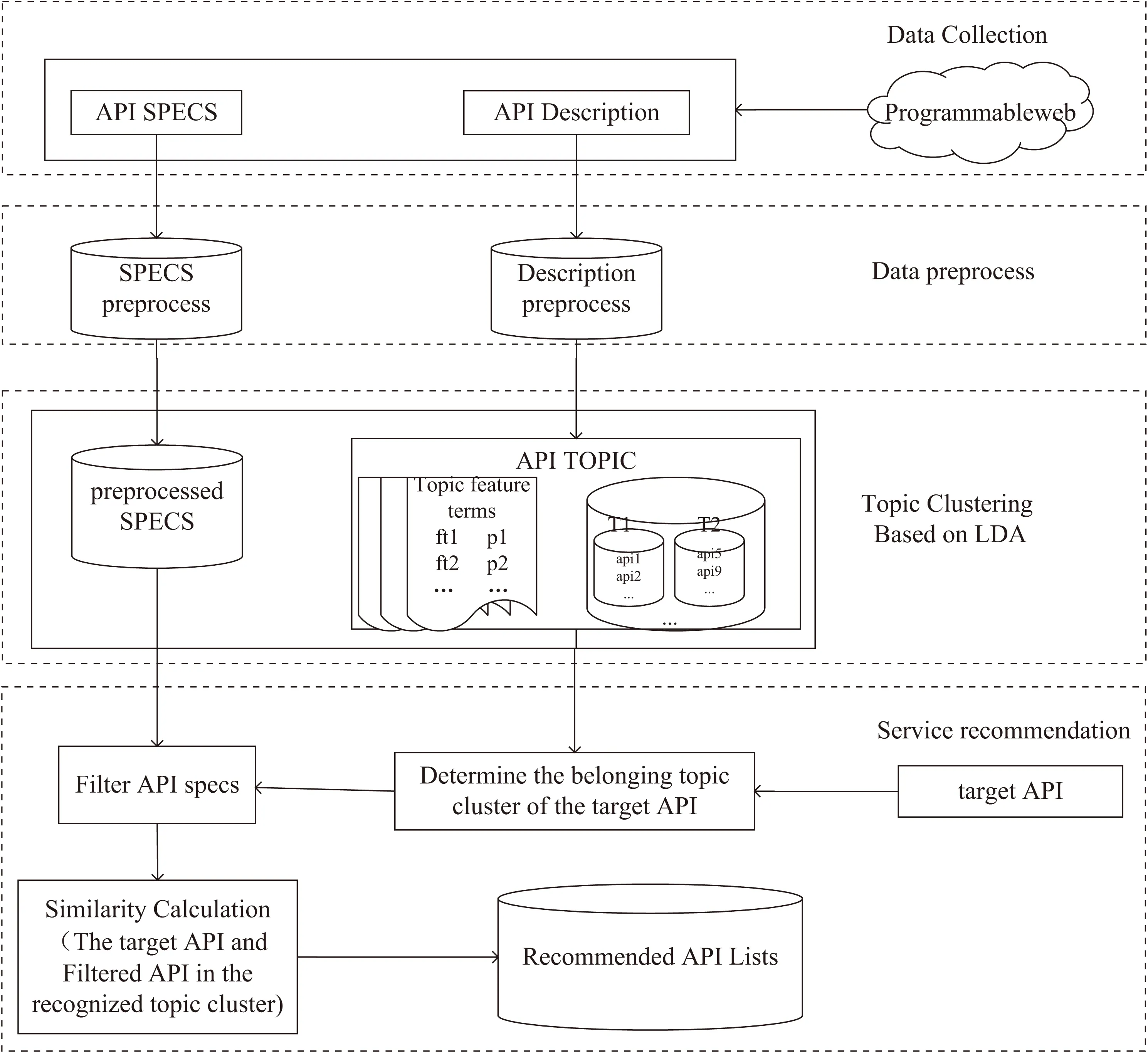
图1 融合描述和Specs的API推荐框架
2.2 基于描述和Specs的API推荐
2.2.1 数据收集及预处理
实验数据来自Programmableweb.com网站上的真实服务数据。该网站提供了大量的API服务数据。爬取了Programmableweb网站上包含API数目大于900的“category”中所有API的描述信息以及Specs信息,主要包括Authentication Model、SSL Support、Supported Response Formats、Supported Request Formats等。
接下来,需要对每个API描述信息和Specs信息进行预处理。首先对API描述中的句子进行过滤,去掉数字、标点以及非字母符号,并将字母统一小写;然后进行错别单词检测,下一步建立停用词表去除文本中的所有停用词,例如“an”、“it”、“is”、“and”等等;最后将这些英文单词全部进行了词干化处理,主要解决方法包括将复数名词变为单数和动词时态形式变为原始的动词形态等。
2.2.2 基于描述的API聚类
LDA是一种文档主题生成模型,包含特征词、隐含主题和文档三层结构[11]。LDA可以将文档集中每篇文档的主题以概率分布的形式给出,从而通过分析一些文档抽取出它们的主题(分布),进而根据主题(分布)进行主题聚类或文本分类。该文使用LDA主题模型对预处理后的API描述进行聚类。LDA主题概率模型建模过程是一个通过文档集合建立生成模型的反向过程。假设给定一个文档集D,其包含M个文档,主题数为k,即Nm为第m个文档的单词总数,Zm,n为第m个文档中第n个词的主题;Wm,n为m个文档中的第n个词;α和β为它们的先验参数;隐含变量θm表示第m个文档下的Topic分布;φk表示第k个主题下词的分布D={d1,d2,…,dm},dm={wm1,wm2,…,wmn}表示第m篇文档,zm={zm1,zm2,…,zmn}表示文档dm中每个单词对应所属主题的集合。
将API描述信息作为LDA模型的输入,采用吉布斯抽样(Gibbs sampling)方法,得到每个描述文档的文档主题矩阵和词主题矩阵,根据每个API包含的不同主题的概率对API描述信息进行聚类。假设API的描述信息Di包含r个主题T1,T2,…,Tr,P(Di,Tr)表示API描述信息Di包含主题Tr的概率。如果一个API包含某个主题的概率越大,则该API属于该主题的可能性就越大。因此,如果一个API包含某个主题的概率最大,认为该API就属于相应的主题类簇;在此基础上,得到聚类后的API类簇集以及每个主题包含的主题特征词集。
Word2Vec算法是基于词嵌入的新方法,可以将几万个词特征缩减到几百甚至几十维度,可以解决文本分类维度灾难的问题[12]。由于一部分API的描述信息过短,直接利用LDA主题建模方法难以有效估计出API的隐含主题,而Word2ec能够将一个词转化为一个词向量,所以该文采用Word2ec进行文本向量化。首先用维基百科的语料库训练一个词向量模型,然后用这个词向量模型对LDA主题特征词进行向量化,由于Word2Vec模型无法区分提取出的特征词的重要程度,故将该特征词的TF-IDF值作为权重,与Word2Vec模型相结合,得到最终的API描述文本向量[13]。
2.2.3 基于Specs和相似度计算的API推荐
(1)识别API所属类簇。
特定失效API首先通过预处理,然后将预处理后的失效API和2.2.2节API聚类产生的主题特征词通过Word2Vec进行向量化,进而采用余弦相似度计算失效API与聚类产生的主题类簇间的相似度,计算公式如下:
(1)
其中,sim(D,T)的取值范围为[0,1]。如果sim(D,T)越大,表示失效API与该主题类簇内的API越相似;因此,当失效API与特定主题间得到的sim(D,T)最大时,就认为给定的失效API属于该主题类簇。
(2)通过Specs进行筛选。
识别失效API所属主题类簇后,进一步通过API Specs信息对类簇内的API进行筛选,以提高方法的性能。采用的API Specs信息主要包括Authentication Model、SSL Support、Supported Response Formats、Supported Request Formats等。通过Jaccard系数计算失效API与类簇内每个API间Specs信息的相关度[14],如式(2)所示。
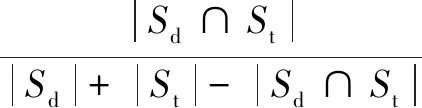
(2)
其中,Sd,St分别表示失效API规格信息集和主题类簇中相应API的规格信息集,J(Sd,St)属于[0,1]。当J(Sd,St)大于特定阈值时,表示目标API规格信息与主题类簇中API的规格信息间的相似度越高,从而得到筛选后的类簇中的API集合。
(3)相似度计算。
将筛选后的API集合通过Word2Vec进行向量化,然后采用余弦相似度计算失效API与筛选后的每个API间的描述相似度。
(4)排序。
将步骤3得到的相似度按照从大到小的顺序进行排序,取前Top-n个API进行推荐。
算法:基于Specs和相似度计算的API推荐算法。
输入:失效API的描述文档Di,失效API的Specs信息Sd,主题特征词集合T,每个主题类簇下API描述文档集合Dt,每个主题类簇下API的Specs信息集合St,阈值th。
输出:Top-n个API列表。
(a)通过Word2Vec将失效API的描述文档Di和主题特征词集合T中的词进行向量化。
(b)根据式(1)计算失效API的描述Di与主题特征词间的相似度。
(c)根据得到的相似度识别失效API所属的主题类簇。
(d)在识别的主题类簇下,根据式(2)计算失效API的Specs信息与主题类簇下API的Specs信息间的Jaccard系数。
(e)遍历得到的Jaccard系数,统计系数大于阈值th的API集合Ds。
(f)将Ds中的每个API的描述信息通过Word2Vec进行向量化。
(g)通过余弦相似度计算失效API的描述信息Di与Ds中向量化后的每个API描述间的相似度。
(h)将得到的相似度按照从大到小排序,选择Top-n个API作为推荐结果。
3 实验结果分析
本节进行实验验证,通过Programmableweb网站上真实的API数据进行实验,以验证方法的有效性。
3.1 实验准备
所有实验和算法均通过JAVA实现,开发环境为Eclipse,所有实验均运行在一台具有Intel Core i5-8300 CPU,8 GB内存,操作系统为Windows10的PC上。
从Programmableweb网站上收集“category”中API数目大于900的“category”中的API,并从中随机选取Mapping、Financial、eCommerce、Data、Cloud、Analytics 7个领域包括7 600个API的描述信息以及Specs信息进行实验。
3.2 评估指标
该文采用聚类纯度(purity)和F-measure两个指标评估聚类的结果。聚类纯度采用式(3)进行计算,其中k是聚类的数目,m是整个聚类所涉及到的文本个数,mi表示聚类i中所有成员个数,pi表示聚类i中的成员属于类的概率。P是精确率,R是召回率,计算公式分别如式(4)、式(5)所示,TP(true positives)表示正类判定为正类,FP(false positives)表示负类判定为正类,FN(false negatives)表示正类判定为负类,F-measure通过式(6)进行计算,其中β是参数,一般取值为1。
(3)
(4)
(5)
(6)
采用准确率和平均绝对误差评估推荐方法的有效性。准确率计算公式为式(7),其中Pre表示准确率,Ni表示匹配成功的API的数目,Nj表示Top-n个API。平均绝对误差计算公式如式(8),其中pm表示对Programmableweb网站上原有失效API的相似API的评分,tm表示实验中不同方法得到的相似API的评分,n表示得到的相似API的个数,评分取值为[0,1]。MAE值越小,表示得到的推荐结果越准确。
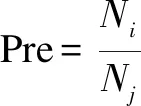
(7)
(8)
3.3 实验结果
3.3.1 聚类结果分析
实验中先确定LDA中主题个数k的不同取值对服务聚类效果的影响。为了客观体现k的取值对聚类的影响,选取不同的k值进行实验,然后对聚类结果取平均值。结果如表1所示。
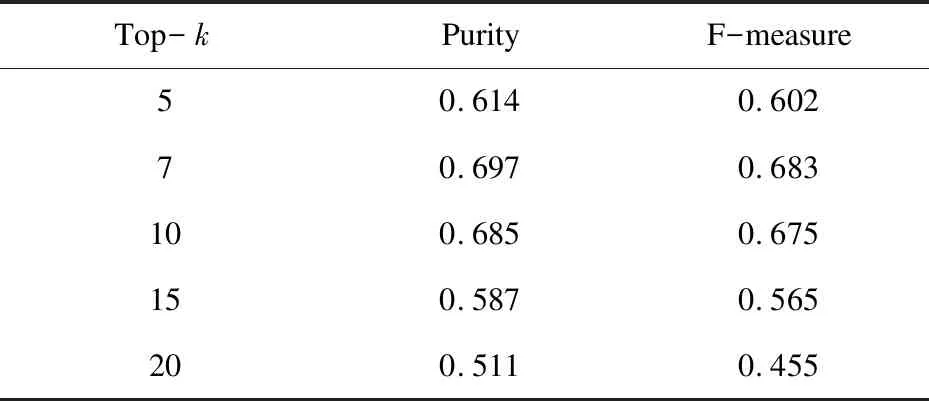
表1 k的取值对聚类效果的影响
实验表明,当主题个数为5,7,10的时候,聚类的实验效果比主题个数为15,20时更好,可能是采取的实验数据较小的原因,而当主题数为7时的聚类效果最好,因为实验数据是随机选择的7个领域的API数据的集合,所以主题数为7时效果最好。
聚类结果的好坏对推荐结果的准确性会产生一定影响,因此,设计表2中的4种方法进行实验,以验证文中聚类方法的有效性。

表2 四种方法的描述
四种方法得到的聚类结果如图2所示。
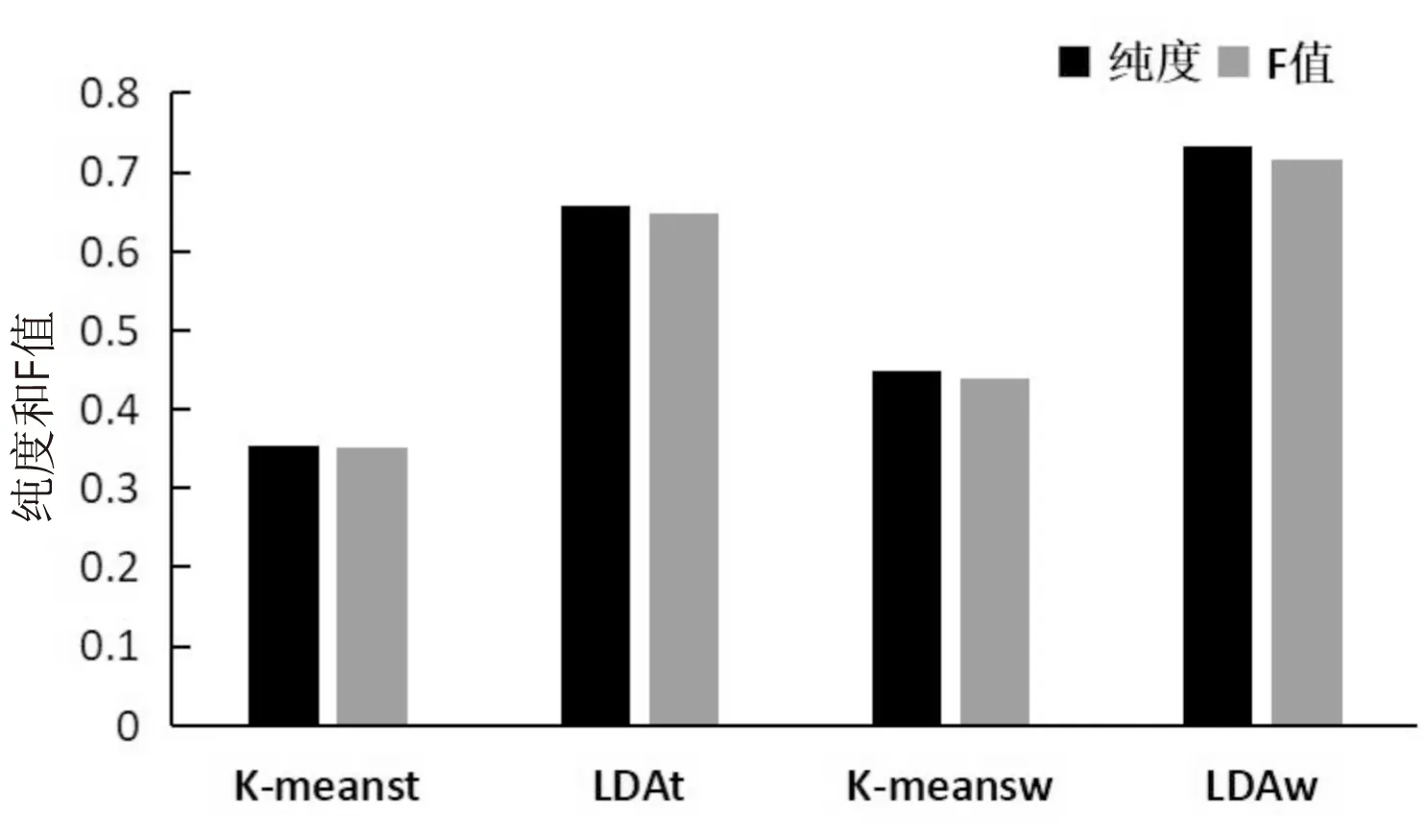
图2 四种方法的纯度和F-measure对比
从图2中可以看出,通过基于Word2Vec和LDA主题模型的聚类方法LDAw得到的聚类效果更好。K-meanst算法聚类效果最差的原因可能是使用K-means算法有初始聚类中心选择的任意性,使得每个类簇所包括的API信息相差较大,从而导致纯度较低。
3.3.2 推荐结果分析
以“Google Cloud Inference API”为失效API,通过相似度计算识别出该API属于Analytics主题类簇,进一步计算该API的Specs信息与Analytics主题类簇下每个API Specs信息间的Jaccard系数,将阈值th设置为0.5,得到筛选后的658个API,进而计算该失效API与658个API间的相似度。表3为相似度top-10的API及相应的相似度。
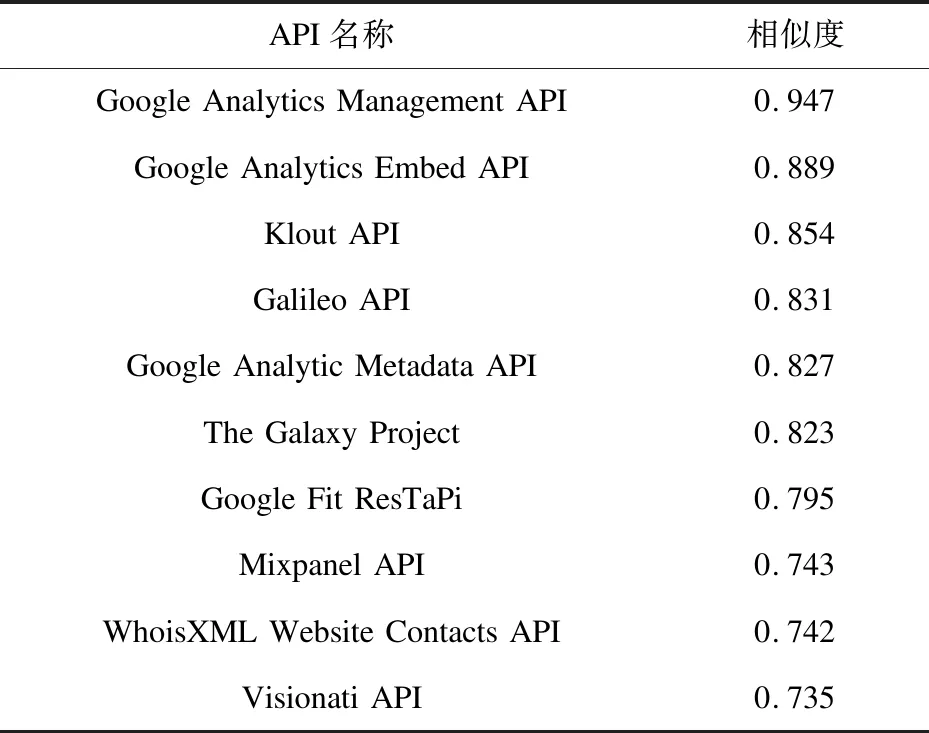
表3 top-10 API及相似度
为了体现文中推荐方法的有效性,设计表4所示的对比方法进行实验验证。

表4 八种方法的描述
表4中的8种方法得到的实验结果分别如图3、图4所示。
从图3、图4中可以看出,m1,m3,m5,m7中采用了TF-IDF进行向量化,可能引起向量维度爆炸的问题且没有考虑到语义相关性,没有取得良好的推荐效果;m2,m4,m6,m8中采用了Word2Vec进行向量化[15],取得了较好的实验结果,表明考虑API的Specs信息一定程度上可以提高推荐的准确率,验证了所提推荐方法的有效性。
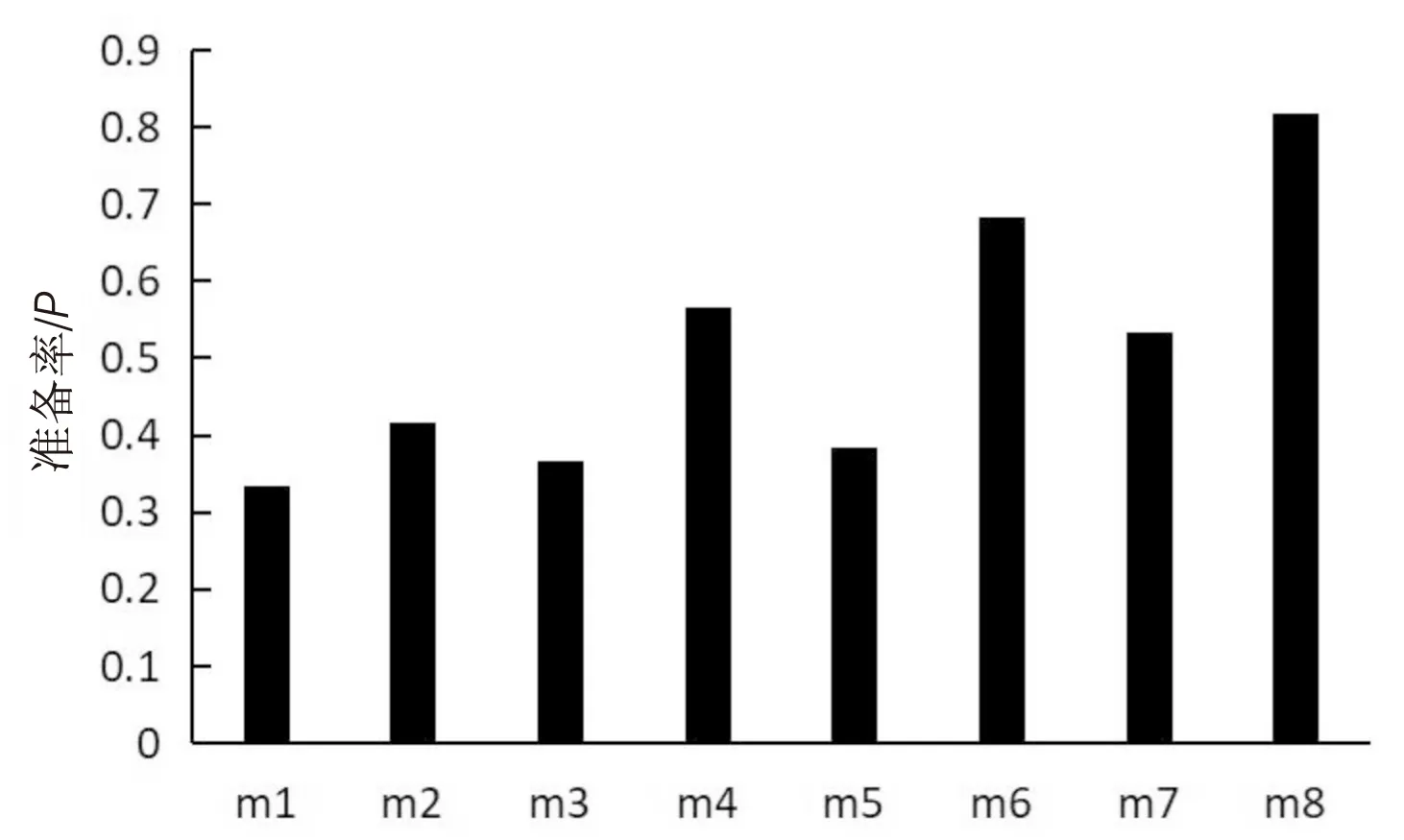
图3 八种方法的准确率对比
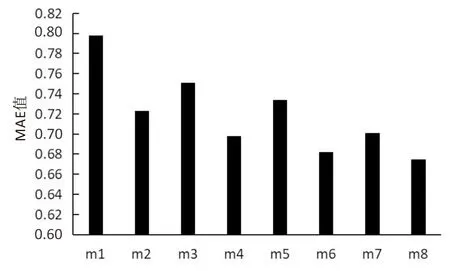
图4 八种方法的平均绝对误差对比
4 结束语
该文提出了一种面向Mashup应用的API推荐方法,首先通过LDA主题模型对API描述进行聚类[16],然后通过失效API与类簇间的相似度计算,识别失效API所属的主题类簇,并根据API的规格信息对识别类簇内的API进行筛选,进一步计算失效API与筛选后的API间的相似度,将相似度较高的Top-n个API进行推荐。通过对真实服务集进行实验表明,该方法推荐准确率较高,验证了该方法的可行性和有效性。
在未来工作中,还需要改进的地方如下:
(1)考虑到Programmableweb网站上API有标签[17]的存在,该文没有考虑标签的因素,可能会造成一定误差,下一步可以考虑加入Programmableweb网站上的标签信息。
(2)目前推荐的API仅来源于一个服务类簇,下一步可考虑主题类簇间的相关性,扩大推荐范围,以更好地提高方法的性能。
