YOLOv3-ad在输电线路监控中提高小目标物体检测准确度的研究
2021-03-06李海峰武剑灵李立学
李海峰,武剑灵,李立学
(1.国网黑龙江省电力有限公司检修公司,黑龙江 哈尔滨 150090; 2.内蒙古超高压供电局,内蒙古 呼和浩特010000;3.上海交通大学,上海 200240)
随着现代社会经济的发展,高压输电线路的覆盖面积急剧增大。输电线路横跨山川、河流、城市、农村等,复杂的环境使其遭受外力破坏危害的概率大幅提升。输电线路一旦发生事故导致停电,必定造成巨大的经济损失,对社会产生极大影响;因此,对输电线路的监控与维护必不可少。当前,对输电线路的运行维护多依赖于人力巡查,以及依靠前端摄像头传回的图片进行人工监视。然而输电线路数量庞大,横跨地域广,以上方式的效率差强人意,需要耗费大量人力,成本高昂。
随着工业与信息技术的发展,作为智能电网重要的一环,输电线路自动化监测技术[1]日趋完善,其长时间不间断的监控以及利用图像识别技术的自动预警功能[2-4]比起人眼监视图像有着更高的效率。近年来,在人工智能、神经网络与目标检测技术的不断推动下,自动化监控的预警准确率也突破到了一个新的高度,使得自动化取代人力的进程向前迈进了一大步。在自动化监控的图像识别技术中,YOLOv3网络模型凭借其高精度和快速等优势,成为主流的目标检测方案。颜宏文等人[5]基于YOLOv3网络对绝缘子串进行定位与状态识别,对于采用的YOLOv1、YOLOv2版本存在小目标精度不高的问题,作者在YOLOv3版本中通过特征金字塔等方式进行减缓,但检测精度还是不尽人意。李慕锴等人[6]针对该问题,通过引入SE block到YOLOv3网络,来提高小目标检测精度,但该方法只针对红外图像。鞠默然等人[7]通过改变YOLOv3网络架构,来降低小目标信息的丢失程度,从而加强检测能力,但同时损失了其他尺寸物体的检测能力。本文从训练策略、模块性能和网络架构等多个方面进行优化,在提升小目标精度的同时,加强网络总体的目标检测能力,并保持图像检测速度几乎不变,且尽量不增加计算资源消耗。
1 目标检测神经网络
目标检测是计算机视觉的基础研究领域,是指对输入图像进行相关处理后,给出图像中物体的类别与位置信息。近年来,依靠神经网络进行目标检测的方式[8-9]相较于传统目标检测算法[10-11],在性能上有显著提升。
目标检测神经网络目前主要有2个类别:一是单阶段检测网络,二是双阶段检测网络。双阶段检测网络的代表是区域卷积神经网络(regions-convolutional neural networks,RCNN)系列[12],网络分为2个阶段,第1阶段将图像中的物体提取出来,第2阶段将提取出来的物体进行分类。单阶段检测网络则不分2步走,而是在1个网络结构中,直接输出图像中物体的类别和位置信息,代表为YOLO系列[13-14]和SSD系列[15]。相较于双阶段网络,单阶段检测网络模型复杂度更低,检测速度更快,能够达到实时处理的水准,基于YOLOv3的推理速度甚至可以达到每秒60帧。本文针对单阶段检测网络YOLOv3进行性能改进,在保持单阶段检测速度快优势的同时,进一步提高检测准确率,并加强对小目标的检测性能,使网络对图像的处理方式更加符合输电线路监控的要求。
YOLOv3是YOLO系列的第3代版本,2018年由Redmon等人提出,有着速度快、准确度高的优点。YOLOv3采用了darknet53结构,尽管不同于一些传统的特征提取网络,darknet53依然通过残差模块[16]来提升网络深度,该结构提取过程如图1所示。在darknet53网络的特征提取过程中,有23个残差模块,每个残差模块中都有1个1×1的卷积和1个3×3的卷积。利用残差模块提高网络深度,可以使网络提取到更高级别的语义特征,从而提升检测性能。

图1 darknet53结构特征提取Fig.1 Feature extraction of darknet53 structure
在每个残差模块集合的前一层,都有1层步长为2的降采样卷积层,用来取代传统网络中的池化层,可避免池化层带来的梯度负面效果。darknet53中有5个降采样卷积层,可将输入图像的尺寸缩小32倍。在特征提取之后,利用多尺度的方式[17-18],将darknet53在3个不同的尺度下分别进行输出(如图2所示),以此提高小目标的检测准确度。

图2 darknet53结构中的多尺度输出Fig.2 Multi-scale output in darknet53 structure
小目标有2种定义方法:一种是根据物体在图片中的相对大小,当目标的物理面积小于图片面积的10%,属于小目标;另一种是根据物体的绝对大小,将尺寸小于32×32像素的物体认定为小目标。在输电线路图像监测中,部分类似汽吊的物体,尽管实际像素在图片中的占比较低,但其真实值的矩形框会因为机械臂的伸长而变大,故不能单纯依靠矩形框的大小来判断其是否为小目标。本文结合输电线路的具体场景特性,在基于相对大小定义的基础上,将目标物体尺寸小于原图尺寸20%、且目标物体所在区域内背景部分占比超过50%的,也定义为小目标物体。图3(a)、(b)所示均为输电线路图像监控中的小目标物体。

图3 小目标物体实物图Fig.3 Pictures of small target objects
在小目标研究上,Li等[19]利用感知生成式对抗网络来提高小目标的检测率;Li、Peng等[20]人通过比较识别与检测的落差,针对检测特性,建立专门用于检测的骨干网络,以提升小目标的检测精度。本文在YOLOv3的基础上,结合新的高功能模块来提升YOLOv3网络小目标的检测性能,在不损失YOLOv3网络检测速度优势的情况下,进一步改善小目标物体的检测精度。
2 YOLOv3-ad算法
针对输电线路监控设备安装位置一般较高、距离地面上的物体较远,从而大多数监控图像中物体成像较小的特点,本文提出新的网络模型YOLOv3-ad,旨在加强对图像中小目标的检测性能。该模型通过改善降采样问题、添加训练优化层、更换高性能模块以及提高特征复用性,可以更好地解决图像中小目标识别准确度低的问题。
2.1 膨胀卷积与降采样
尽管采用神经网络进行目标检测的起步时间晚于图像分类,但经过4~5 a的发展,目标检测在很大程度上沿袭了分类的结构设计,这其中就包括降采样。降采样是在空间维度下对图像信息进行凝练,虽然可以相应地降低计算量,提高感受野的大小,但也会导致空间信息丢失,而空间信息的不完备又会进一步影响到边界框的回归。同时,在多尺度架构的目标检测网络中,低分辨率的输出层由于降采样次数过多而会遗弃掉小目标信息;高分辨率的输出层虽然是由语义信息强的深层结合分辨率高的浅层得到的,但小目标已经在深层不可见,而浅层中可见的小目标又由于层浅的原因语义信息较弱,较难被检测到。
针对上述问题,本文将YOLOv3中原有的5次降采样减少到4次,以此来增大网络的输出尺寸,避免因为空间信息的过多丢失而导致小目标检测准确度的下降。同时对于降采样次数减少带来的计算量增加、感受野变小的问题,通过减少4次采样后的隐藏层通道数来避免计算量增加,然后利用膨胀卷积的方法[21]来提高感受野大小。
图4所示为膨胀卷积示意图,该方法最初起源于语义分割领域,将其应用在目标检测结构中能够起到独特的效果。由图4可以看出:相比于一般的卷积操作,膨胀卷积能够感受到更大范围的信息,这样对于空间信息的提炼就不再只局限于降采样。本文在YOLOv3第5次降采样后的残差模块中加入膨胀卷积,替换掉原有的普通3×3卷积层。由于不需要连续进行卷积膨胀,避免了其在像素尺度上不连续的问题。
2.2 AE层
辅助激励(assisted excitation,AE)层利用课程学习的原理,即学习应该按照由易到难的顺序进行,让模型先从简单的样本开始学习,之后逐渐提升样本难度,使模型能够找到局部最优并加速收敛速率,最终提高网络的检测精度,其结构如图5所示。本文在网络的最大分辨率输出支路上添加1层AE层来加强网络对小目标的检测[22]。并根据真实的目标信息中目标的大小进行筛选,对于不属于该支路检测的目标不给予真实信息提示。不同于将真实的目标信息中所有目标信息附加到特征图上,筛选后的AE层只针对小目标进行信息加强,使得网络对小目标的检测更加精准。
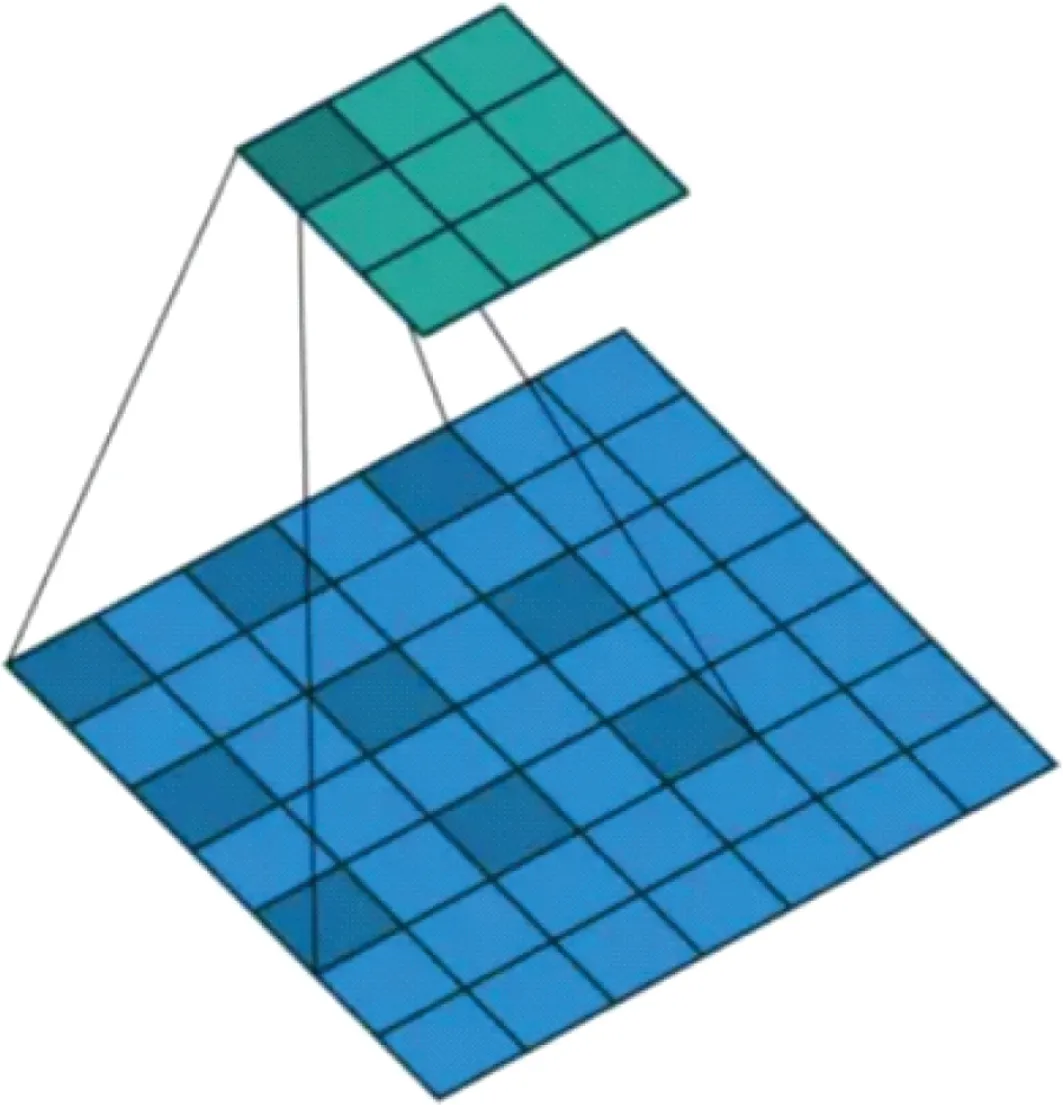
图4 膨胀卷积示意图Fig.4 Schematic diagram of dilated convolution
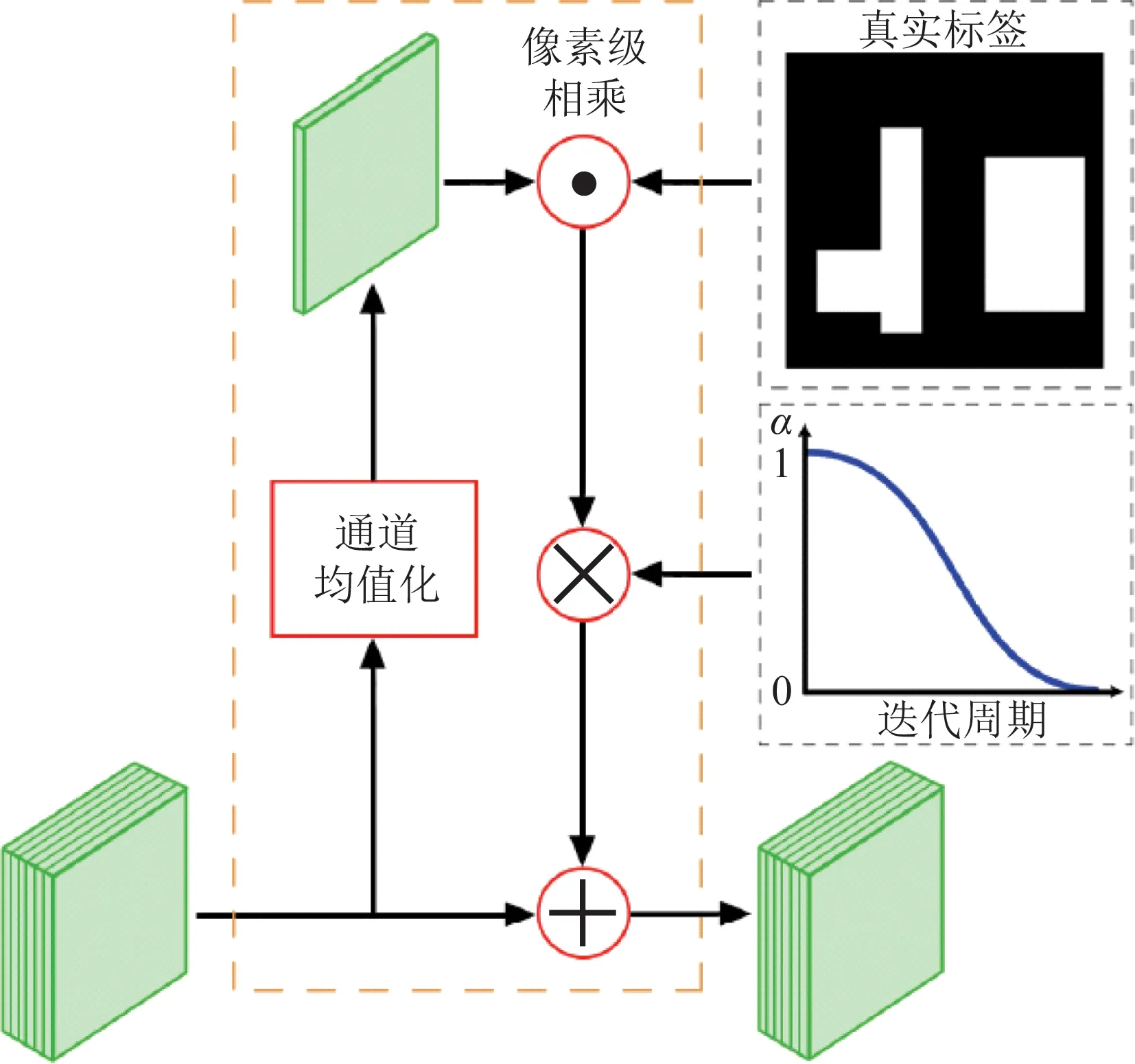
图5 AE层结构Fig.5 AE layer structure
训练图片中正负样本的不均衡是YOLOv3广受诟病的原因之一。大量容易分辨的负样本在较大程度上影响网络的训练方向,减少正样本以及难以分辨样本的贡献。而AE层通过引导训练难度曲线,使正样本和难分样本能够在训练初期更好地影响模型的迭代方向,从而缓解YOLOv3中大量易分负样本堆砌的问题。同时,AE层的增强也会作用于反向传播中,由于它对真实的目标信息区域的反应更强,也会增大感受野的响应,使正样本提供更多的贡献,而降低易分负样本的作用。
对某一隐藏层的输出以通道为单位进行平均,之后在像素级上与真实的目标信息中的mask相乘(该mask的数值只取决于筛选后的目标物体,不受被筛选掉目标的影响),再乘以1个激励系数α后,与输入的每个通道相加,计算式如下:
αc,i,j,l+1=αc,i,j,l+α(t)ec,i,j;
(1)
其中
(2)
(3)
式(1)—(3)中:αc,i,j,l+1和αc,i,j,l分别为l+1层和l层的输入,c、i、j分别为输入特征图的通道数、行坐标和列坐标;ec,i,j为激励函数;t为训练迭代次数;M为网络训练的总迭代次数;gi,j根据真实的目标信息得到mask值为1或0,当坐标为(i,j)的像素不在标注框之内,gi,j=0,否则gi,j=1;d为特征图通道数。
在训练的初期,α值较大,将真实的目标信息更多地附加到样本上,从而降低样本困难度。在训练快结束的时候,α值趋于0,网络训练不再受AE层的影响。该AE层只在训练时起作用,不影响推理时的速度。
2.3 ResneXt
ResneXt模块[23]是在Resnet残差模块上进行的改进,在不增加参数复杂度的前提下可提高准确率。图6(a)所示为YOLOv3中的残差结构,图6(b)为改进后的ResneXt结构。ResneXt结构在Resnet残差模块的基础上,结合Inception结构中的split-transform-merge策略,提出cardiality超参数来控制单个模块下transform路径的数量,这里定义为32,并且transform路径的拓扑结构都一样。
由图6可知:ResneXt在利用Inception结构来平衡分组卷积的同时,摒弃掉了Inception中不同分支不同拓扑结构的特点,从而避免了大量参数的调整工作。在路径合并时,RexneXt也不同于Inception先链接后采样的方式,而是在每条路径最后采用恢复到输入的尺寸,再对所有路径进行相加。依靠这种平行堆叠相同拓扑结构的模块来代替原来Resnet的残差模块,在不明显增加参数量级的情况下能够提升模型准确率。本文将YOLOv3中所有残差模块替换为ResneXt模块,提升了YOLOv3的整体性能。2.1节中使用的膨胀卷积也相应地替换最后1个ResneXt模块的3×3卷积层。
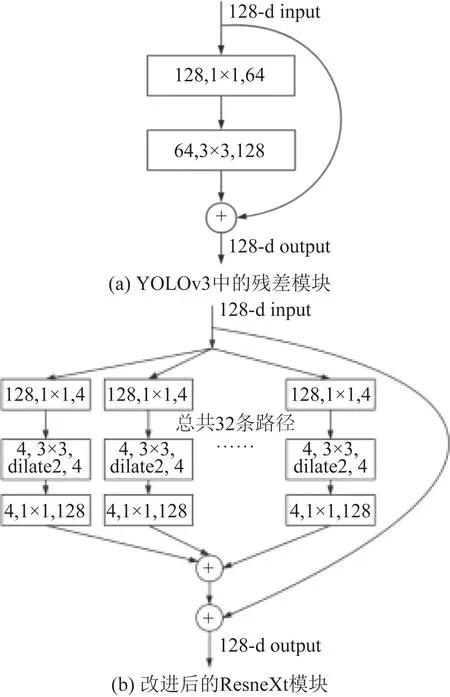
图6 YOLOv3中的残差结构及改进后的ResneXt结构Fig.6 Residual structure in YOLOv3 and the improved ResneXt structure
2.4 Dense
尽管利用残差块能够在性能不退化的情况下堆叠更深的网络结构,但随着残差块数量的增加,在网络中流动的冗余信息也在增加,这些冗余信息会给网络带来负面影响。特别是小目标,由于其携带的信息较少,会更加容易受到冗余信息或者噪点的影响。另一方面,在网络的深度和宽度到达一定程度后,继续增加层数不再会带来性能上的提高。为了解决上述问题,进一步提高网络性能,Dense模块[24-25]从特征复用的角度出发,这一点不同于传统的Resnet模块与Inception模块。
在Dense模块中,每个卷积层的输入Xl都与它之前所有层的输出X0,X1,X2,…Xl-1有关,即
Xl=Hl(X0,X1,X2,…,Xl-1),
(4)
式中Hl为输入与输出之间的激励。
对比残差模块式(5),其输入Xl只与前一层输出Xl-1有关,由此可知,在特征的传递和复用上,Dense模块有着更高的效率。
Xl=Hl(Xl-1)+Xl-1.
(5)
图7为在1个Dense模块中特征图的信息流向。需要注意的是,Dense模块中各个层的聚合是以通道的连接执行的,而不是对应通道进行数值相加,因此会在Dense模块之后加入一个1×1卷积过渡层,来降低由于相连导致的最后输出通道数过于庞大的问题。
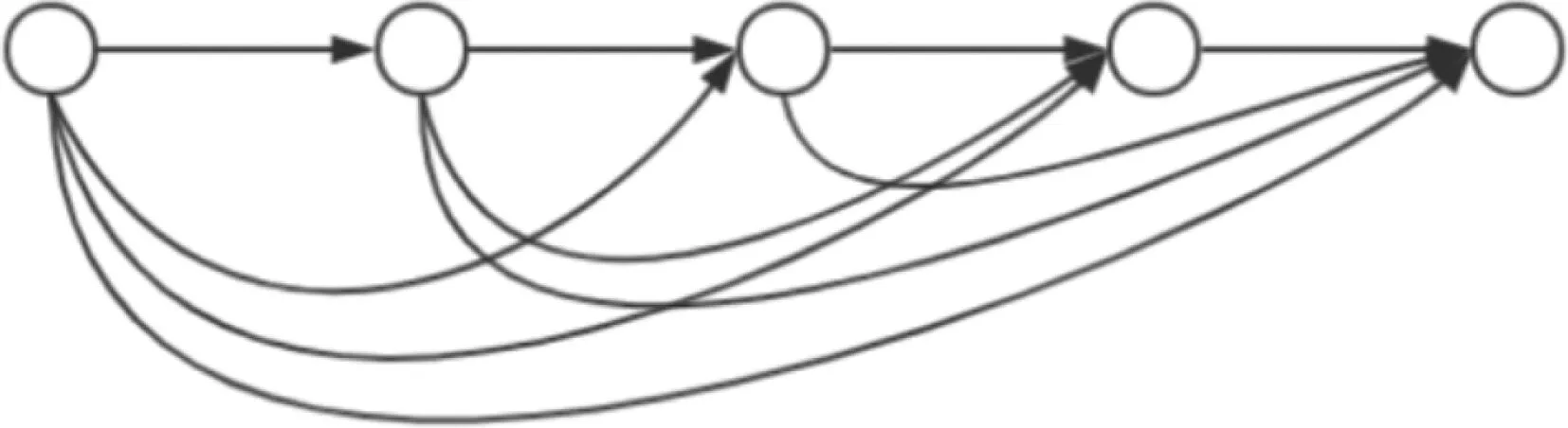
图7 Dense模块Fig.7 Dense module
针对YOLOv3,本文减少了原本结构中残差块的数量,来减少冗余信息的生成,同时添加2个Dense模块来建立不同层之间的连接关系,提高对特征的利用率,减轻网络回传时梯度消失的问题,从而提高网络的性能。
2.5 YOLOv3-ad网络结构
改进后的网络结构如图8所示,在原有基本框架的基础上,去掉了底部8层的残差块,增加了2层的Dense模块来提高特征的提取效果,提升特征的复用率。并且去除了图像尺寸从26—13的降采样过程来遏制空间信息的过多流失,取而代之的膨胀卷积添加到ResneXt模块中的3×3卷积层中,从而弥补减少降采样次数导致的感受野不足问题。在第2次上采样和网络靠前的浅层特征图聚合之后,添加AE层来强化小目标物体的检测,同时缓解在神经网络训练过程中样本的不平衡。
3 现场实测效果
表1为各网络在COCO数据集下的性能指标,相比YOLOv3网络,本文改进后的网络模型YOLOv3-ad在AP上有3个点的提升。在AP50指标下,YOLOv3-ad已经超过了ResNet101FPN结构的RetinaNet。表1中:AP表示平均精度,AP50表示阈值为50%时的平均精度,AP75表示阈值为75%时的平均精度。
表2展示了本文改进方法具体对模型性能的提升,表中“?”表示是否使用该模块或采用该方法。将Resnet模块更换为ResneXt模块后,模型性能提升了0.6%;添加Dense模块后,有1.1%的提升;利用膨胀卷积并减少降采样次数后,模型提升了0.9%;最后,使用AE层后有0.5%提升。通过对以上各个子模块的添加、修改和优化,神经网络性能提升超过36.1%。
表3为各个尺寸目标的检测性能,其中YOLOv3-ad在各尺寸上都比YOLOv3好。在中型和大型目标物体上,YOLOv3-ad高出3%~4%,而在小目标物体的检测上,AP则提升了将近7%。在推理用时上,YOLOv3每帧耗时为51 ms,而YOLOv3-ad的耗时为57 ms,耗时基本一致,并没有增加太多的计算开销。表3中:APS表示小目标精度,APM表示中等目标精度,APL表示大目标精度。
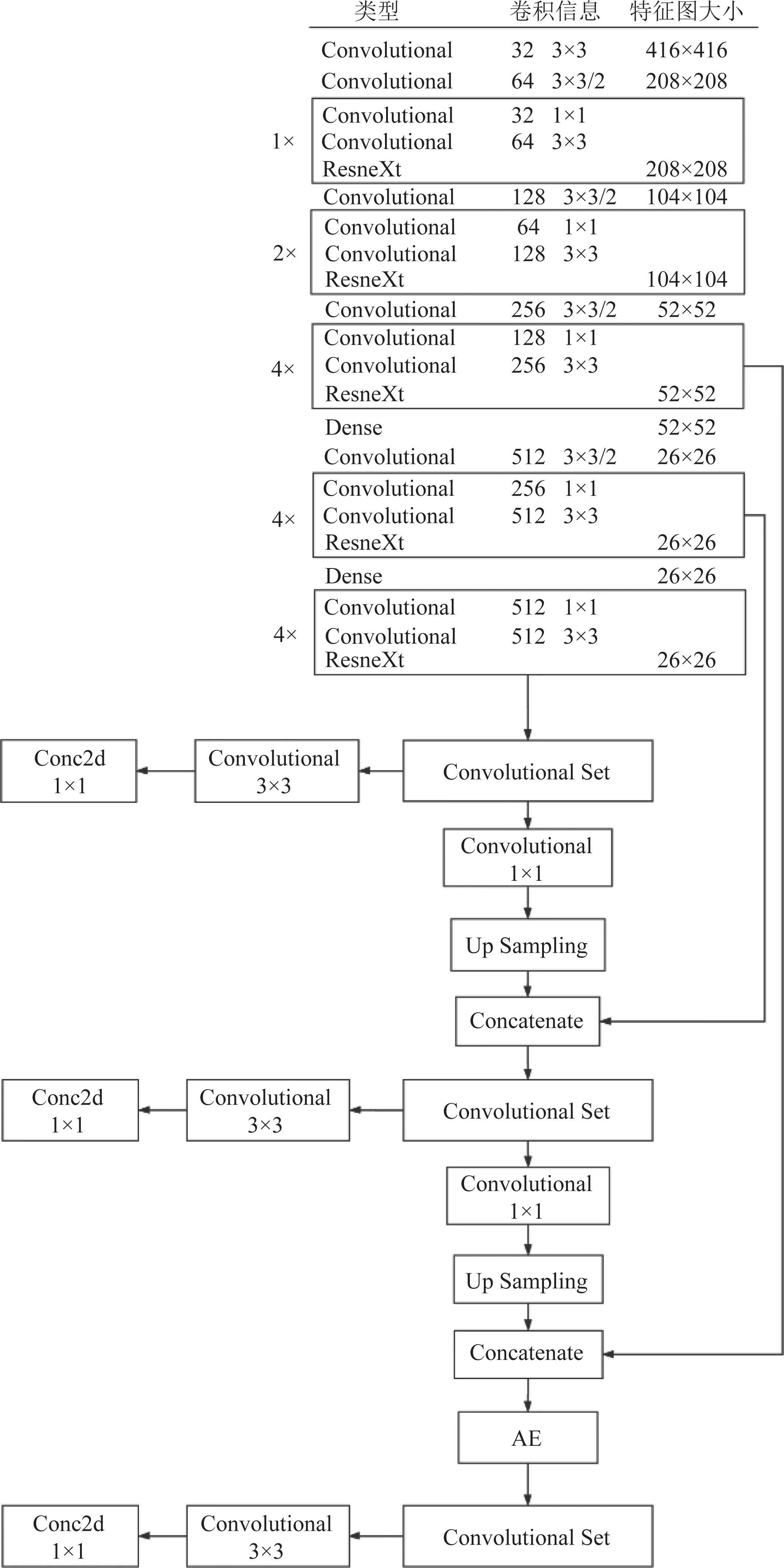
图8 YOLOv3-ad网络结构Fig.8 YOLOv3-ad network structure

表1 各网络在COCO数据集下的性能指标Tab.1 Performance of each network in COCO data set

表2 各个改进方法对YOLOv3的影响Tab.2 Impact of each improvement method on YOLOv3

表3 YOLOv3与YOLOv3-ad检测性能对比Tab.3 Comparison of YOLOv3 and YOLOv3-ad detection performance
如图9所示,分别在图中的3个箭头标记(Stage1、2、3)处插入AE层来测试改进效果。
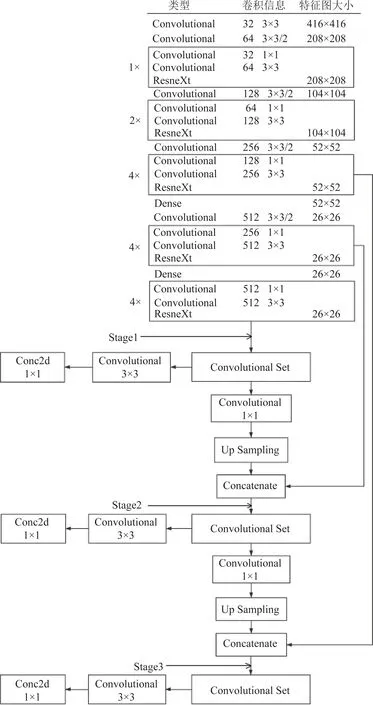
图9 AE层插入位置示意图Fig.9 Schematic diagram of AE layer insertion position
表4给出了不同位置处,AE层对整个网络性能的影响。尽管在Stage1位置处总体AP最高,但在Stage3处时,小目标的检测精度最高,故本文将AE层插在Stage3的位置。同时也可以看出,AE层通过真实的目标信息来强调难分样本和负样本的重要程度,降低样本间的不平衡,以此来提升网络训练后的检测效果。
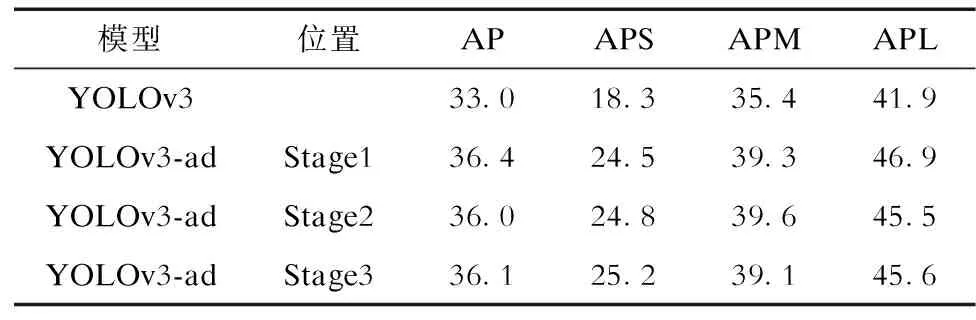
表4 不同位置加入AE层的效果Tab.4 Effect of AE in different positions
4 结束语
本文通过降低降采样次数、添加AE层、替换新的残差结构和使用Dense模块等方法,基于YOLOv3算法,提出一种新的优化模型YOLOv3-ad。现场实测图像的识别效果证明,在输电线路图像监测识别方面,该模型在不牺牲速度的情况下,整体提升了目标检测的准确度,尤其是对小目标物体的检测有较大的提升,从而提高了输电线路场景下对施工机械、树木和山火等进行图像监测和自动化识别预警的准确率,降低了输电线路发生外破等安全危害的风险。
