消渴异名准确性的“方证量化模型”研究❋
2021-03-06文小平郭晶磊
杨 巍,文小平,郭晶磊
(上海中医药大学基础医学院,上海 201203)
“方证量化模型”是一种基于中医方证对应理论结合机器学习对中医基本概念进行量化研究的方法。以往中医数据挖掘研究往往多集中于专药、专方、专法、专病或专人的临床运用领域[1],而在中医基本概念领域的基础性研究较少,尤其缺乏量化研究的方法。本研究方法着眼于2个中医基本概念的比较,即其分别对应的不同方剂数据集之间的量化比较。
1 基本原理
“方证量化模型”的基本原理是基于方证对应理论将2个中医概念的比较转化为2个方剂集合的比较,再通过机器学习模型对2个方剂集合进行量化比较。
1.1 方证对应理论
方证对应也称方证相应,是指方剂的主治病证范畴及该方组方之理法与病人所表现出来的主要病症或病机相符合[2],是中医临床体现“理法方药”一致性的基本原则。笔者认为,其在数据挖掘领域的本质是对于病、证、症、病因病机等中医概念与方剂组成关联数据集的研究。
通过方证对应,在给定样本总体范围内,可以将2个中医概念的比较问题转化为其所代表的2个方剂集合的比较。以消渴异名为例,其中“上消”和“消渴”2个中医概念的比较,可以转化为上消方剂集合和消渴方剂集合的比较V上消/V消渴。
1.2 量化模型
图1示,随机森林是机器学习中的一种高级分类技术,它由Breiman在2001年提出[3],通过随机放回抽样[3]来削弱数据间的相关性,构建大量的规则树,进而通过简单投票判断类别,实现对学习样本集合规则的较优拟合。随机森林有适用性广泛的特点,尤其是对离散数据的拟合[4],比较适合方剂集合之间的比较。在给定样本总体范围内,比较2个方剂集合的问题,通过随机森林转化为以1个方剂集合建模,另一个方剂集合应用模型的形式量化比较2个方剂集合的相似性。以“上消”方剂集合(V上消)和“消渴”方剂集合(V消渴)两者比较为例,由V消渴生成判定模型F消渴,则V上消/V消渴=F消渴(V上消)/ F消渴(V消渴)=F消渴(V上消)。通俗地说,就是近似地建立一个含有几百个消渴方证专家的辨别模型系统,通过投票来量化“上消”方剂集合(V上消)和“消渴”方剂集合(V消渴)的相似性,即异名“上消”相对于“消渴”病名的准确性。

图1 基本逻辑图
2 研究对象
“消渴”是中医常见的疾病名,以多饮、多食、多尿、身体消瘦或尿浊、尿有甜味为特征的病证[5]。“消渴”一词最早出现于《黄帝内经》,但是由于中医古籍浩如烟海又历经不同朝代的变迁,历代医家创造和发展了众多与“消渴”相似或相关的信息,其表现形式之一就是消渴的异名。这样的消渴异名多以数十计[6-10],以《中医方剂大辞典》出现5首及以上对应治疗方剂为常见异名条件,消渴的常见异名多达17种(见表1)。通过方证对应基于随即森林量化消渴异名,可以量化这些消渴相关或者相似的异名,判断他们指代“消渴”病名的准确性。这样的量化研究,可以确定消渴病的研究范围,量化不同异名在消渴研究中的重要程度,清除古代研究相关文献的学习障碍,更全面地理解历代医家对消渴范围的认识。
3 模型建立
本例采用《中医方剂大辞典》的消渴方剂组成数据,基于随机森林构建消渴方辨别模型F消渴(图2),运用模型方证对应判别消渴异名对应方剂是否用于治疗消渴。通过其被判别为应用于消渴治疗(消渴方)的比例F消渴(V异名),分析消渴异名的准确性(图3)。
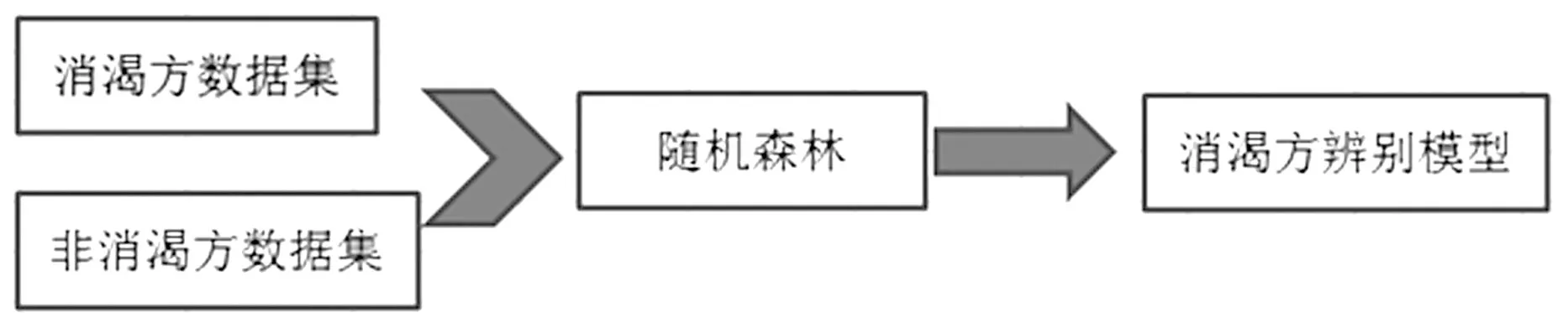
图2 建立模型图
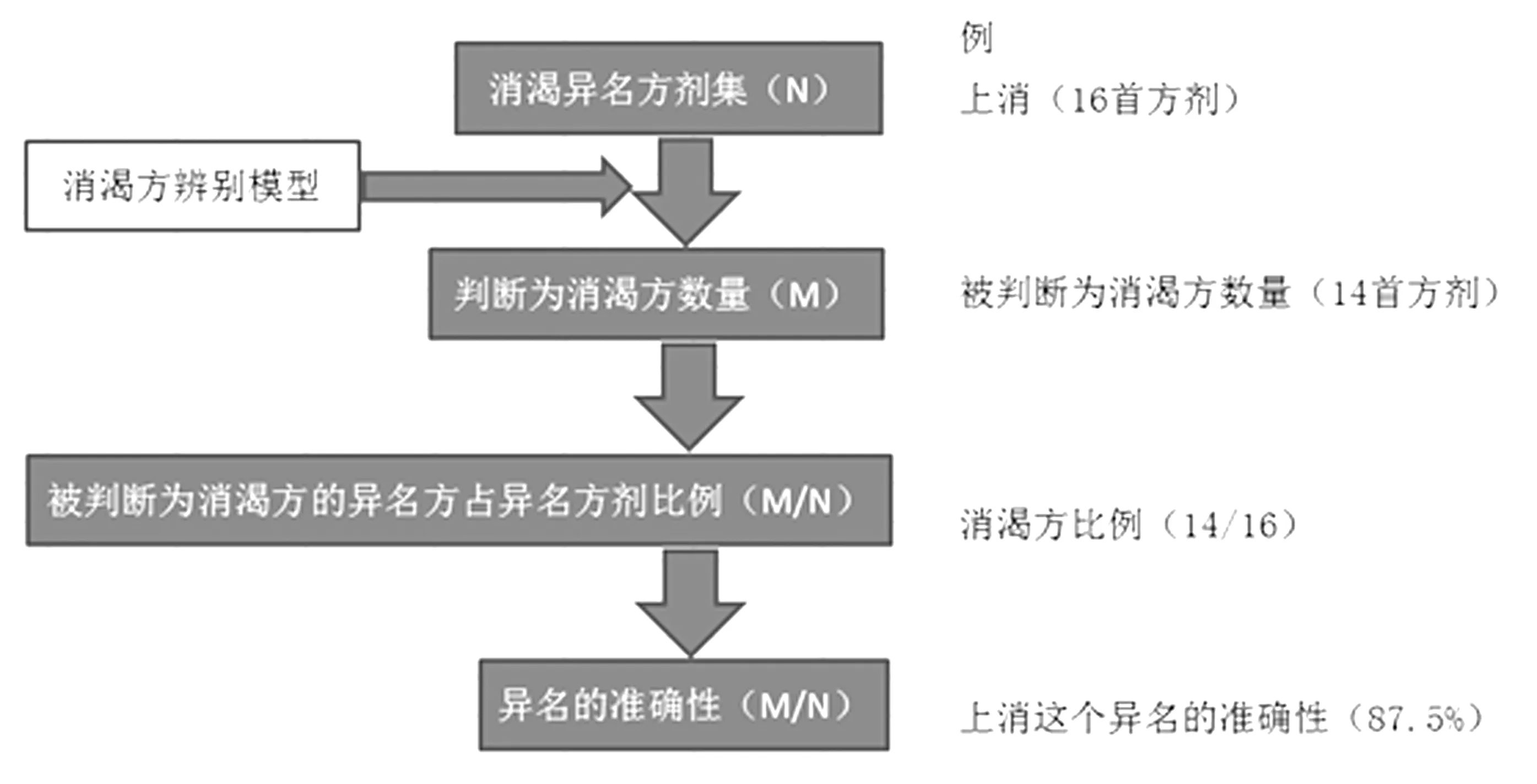
图3 模型应用图
3.1 数据录入
以《中医方剂大辞典》电子版为数据来源并导入数据库,采用“消渴”为关键词,在主治字段进行检索,选取主治字段包含消渴的方剂463首;在排除消渴方和消渴异名方后的80699首方剂中,以0.5%随机选取方剂443首作为非消渴方,两者构成学习集。以表1中消渴常见异名(出现5首方剂及以上对应异名)检索主治字段,共获得方剂310首构成应用集。
3.2 数据清洗
3.2.1 排除数据 表1示,人工排查主治字段,排除“非”病名、“似”病名等与消渴无关的数据,获得各检索条件下筛选后方剂数量。
3.2.2 标准化 提取方剂组成字段的中药,剔除剂量、炮制和服药方法等信息,根据《中华人民共和国药典》《中华本草》《中药大辞典》《中药学》《中药别名速查大辞典》对药名进行规范。
3.3 模型训练与应用
3.3.1 参数选择 表1示,从随机森林调参效率角度,本次研究将在学习集中出现次数12次以上的中药(共99味)作为随机森林的构成参数,各检索条件下筛选后方剂数量。
3.3.2 模型训练 使用R 语言,调用randomForest包,参数设置try=11,nodesizes=8,ntree=300,其他参数使用默认值。
通过set.seed保证随机模型的可重复性,以学习集正确率0.96、袋外错误率[4]0.16选择为“异名识别模型”。
其中学习集正确率反映模型对学习集的学习程度,正确771条,错误31条,正确率0.96。袋外错误率是一种取代测试集的误差泛估计[4],其中消渴TF值0.12、FT值0.20。
3.3.3 模型应用 表1示,使用“异名识别模型”对应用集进行判断,获得各异名对应方属于消渴方的比例。
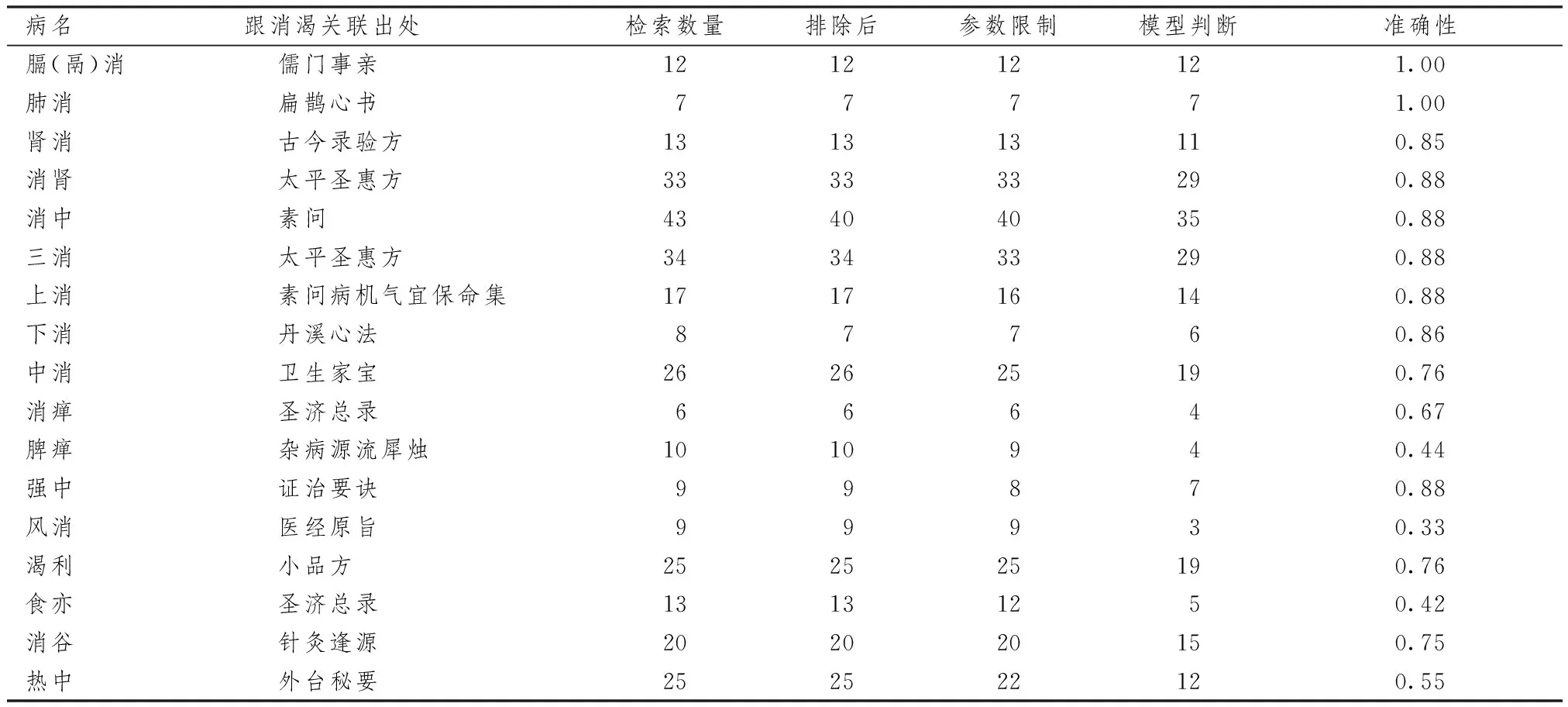
表1 不同异名、不同筛选条件下对应方剂数量及准确性比较
4 结果分析
4.1 高准确性异名
准确性在85%以上的异名有“膈消、肺消、上消、下消、消中、三消、肾消、消肾、强中”9个,这些异名与消渴在方剂组成中的相似程度很高,准确性较高,可以认为是消渴的专有异名。
4.2 中等准确性异名
准确性在85%以下65%以上的异名为“中消、渴利、消瘅、消谷”4个,通过研究被判断为非消渴方的主治、功用和组成,能够发现它们多数与其他疾病同时出现。由此推断,这些异名可能是作为症状出现在其他病种中,将这些异名纳入消渴进行分析时,应考虑排除作为其他病种症状出现的情况。
4.3 低准确性异名
准确性在65%以下的异名有“脾瘅、热中、食亦、风消”4个,准确性较低,可以认为是与消渴类似或者有关联的单独病种。
5 不足与改进
5.1 随机森林的局限性
表2示,随机森林相对其他简单分类方法难以解释,只能从结果进行逆向推测,且调参困难,面对失衡分布学习集效果不佳。本研究在构建学习集时,应尽量平衡数据,采用随机抽样的方式构建非消渴方学习集。随机森林结果具有随机性,本研究通过set.seed保证其可重复性。不同模型结果的不稳定问题,改进方法为建立5个同参数不同随机数(不同seed)的模型,各模型结果基本与原模型的结果分析无差异。
5.2 本研究的改进
本次研究仅仅是涉及到方剂的组成,如果对药物剂量、味数、炮制和服用方法也纳入分析,数据分析模型将会使结果更加全面和准确。
6 应用前景
6.1 文献病名研究
本研究举例的方法可以直接运用于各种中医疾病异名准确性研究,以及现代病名与古代病名的对应关系研究,如骨质疏松症对应的古代病名是什么。
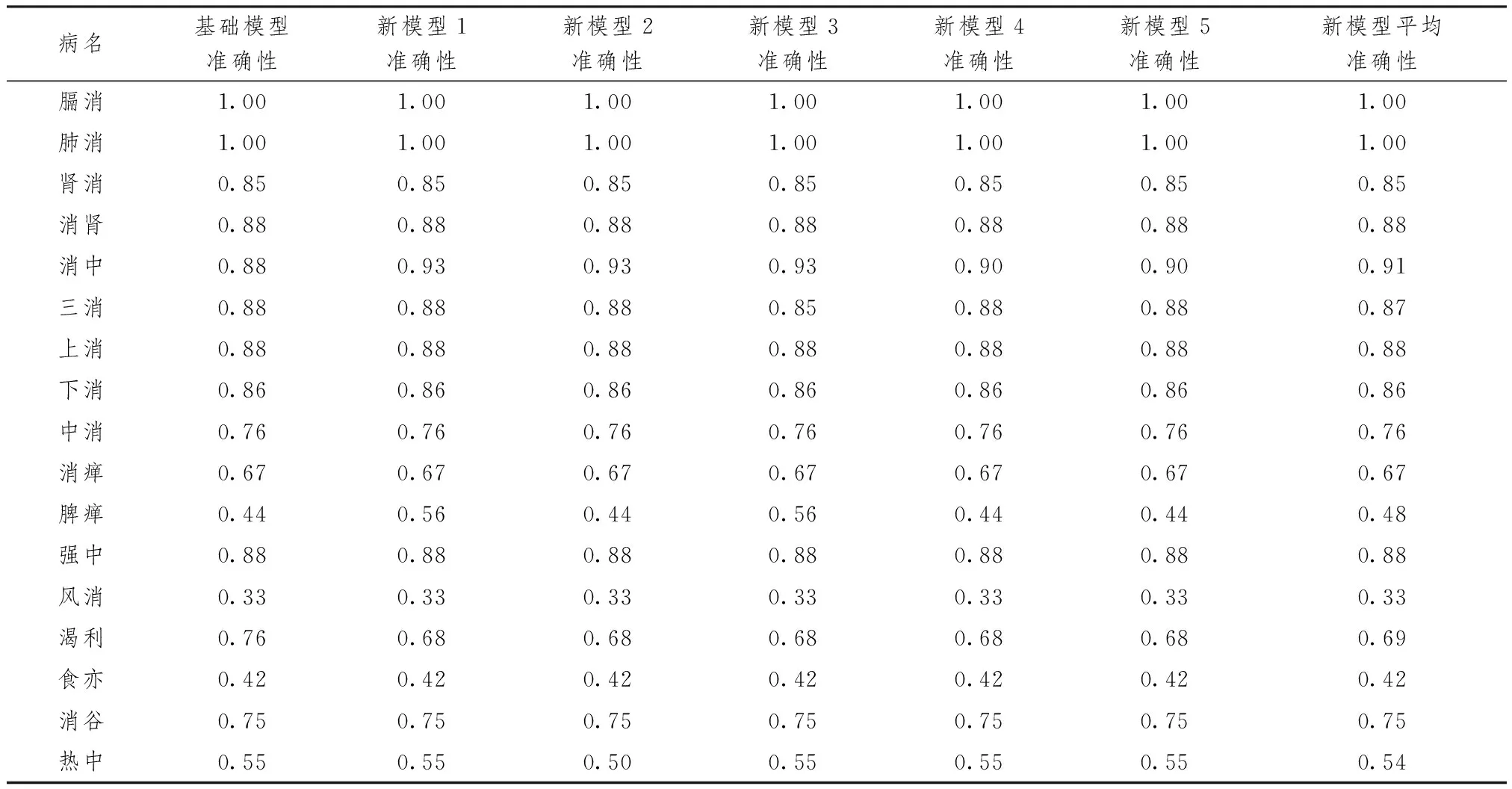
表2 不同Seed情况下各异名准确性比较
6.2 方剂功效研究
运用本方法可以量化类比方剂功效,如以清热方剂集构成学习集,泻火方剂集构成应用集,可以量化泻火功效与清热功效的相似度。
6.3 中医基本概念的研究
本研究方法经过一定变换可以广泛应用于基于对应方剂的各种中医基本概念量化比较,如以五脏方剂集构成学习集,三焦方剂集构成应用集,可以量化判断三焦从方剂组成角度与五脏哪一脏更有相关性。
综上所述,本研究以量化消渴异名准确性为例,结合方证对应和机器学习,将方剂集合量化比较问题转换为随机森林的建模和应用,进而为反映与方剂集合关联的中医概念之间量化关系提供一种新的中医基本概念量化研究方法,即“方证量化模型”。目前本方法还不十分成熟,对于中医概念转化为方剂集合、方剂集合变换为随机森林模型的过程中,如何更好地进行数据信息的取舍、最终结果的参数评估,还需要进一步大量积累实践经验和教训。
