改进的EEMD-NNBR耦合模型在年径流预测中的应用
2021-03-03郑芳芳王文圣张岚婷
郑芳芳,王文圣,张岚婷
(四川大学水利水电学院,四川 成都 610065)
中长期水文预测对防汛抗旱、水资源管理与保护等具有重要意义[1]。水文学者对中长期水文预测开展了大量研究,常用途径有模糊分析法、灰色系统分析方法、小波分析方法[2-3]、人工神经网络模型(ANN)、支持向量机(SVM)、最近邻抽样回归模型(NNBR)及其相关耦合模型等[4-5]。基于相似原理建立的NNBR在水文中长期预测中进行了应用[6-7],随后提出了基于小波分析的NNBR模型、NNBR与SVM的耦合模型[8]、自适应NNBR和ANN的耦合模型[9],研究表明NNBR模型及其组合预测精度较高,并且通常操作简便,无需识别参数。集合经验模态分解方法(Ensemble Empirical Mode Decomposition,EEMD)能将具有非线性、非平稳特点的径流序列从不同时间尺度逐级分解出来[10-11],分解序列能较好地反映原始序列真实的多时间演变特征和周期成分,具有良好的局部自适应性和直观性。将EEMD与NNBR模型耦合,可充分利用2种方法的优势,不失为一种新的组合方式。文献[10]将该组合方式用于降水预测中并表明组合模型是可行的。但EEMD也存在不足,比如采用三次样条插值对信号上、下极值点进行拟合时,由于极值分布不均匀导致拟合的包络线不能正确反映信号的包络形状, 且端点处无法确定极大值和极小值,同时对极值点进行插值拟合时会产生较大的误差[12]。针对这2个问题,本文采用极值中心三次样条插值法对EEMD进行改善并与NNBR结合,建立了改进的EEMD-NNBR耦合模型。将改进的EEMD-NNBR耦合模型应用于金沙江屏山站年径流预测中,研究表明建议模型是有效的。
1 改进的EEMD-NNBR耦合模型
1.1 改进的集合经验模态分解方法
集合经验模态分解方法(EEMD)非常适用于处理非线性、非平稳的径流序列,它可以将复杂的径流序列分解成不同时间尺度的IMF分量,揭示其内在的径流周期。加入新的径流信息后,分解过程可以自适应调整[13]。但EEMD分解过程中,需找出序列所有的局部极大和极小值点,而序列端点处不可能正好是极值点,即使是极值点,也不可能既是极大值点又是极小值点,导致在进行插值拟合时,端点处会产生较大拟合误差。因此,为了充分利用端点值,防止得到的IMF分量在端点处产生畸变,在年径流序列前后端各延拓一个序列均值。序列均值计算如下:
(1)
式中x0——序列前端延拓值;xn+1——序列后端延拓值。
改进的EEMD方法的步骤如下。
步骤1在延拓后的径流序列xt(t=0,1, 2,…,n,n+1)中加入高斯白噪声序列,即:
xt(i)=xt+nt(i)
( 2 )
式中xt(i)——第i次添加高斯白噪声得到的序列。
高斯白噪声添加次数NE通常取50或100,其标准差要根据原始序列标准差确定,一般取原始序列标准差的Nstd倍,Nstd根据信号来设置,没有确定的计算公式。
白噪声具有频谱均匀分布的特性,在添加白噪声后,序列中原本不同时间尺度的信号会自动分离到适当的参照尺度上去,避免隐含尺度的出现。
步骤2对xt(i)进行EEMD分解,得到IMFct(ij)(j=1,2,…M;M为IMF分量个数)和趋势rt(i)。ct(ij)为EEMD对序列xt(i)进行分解得到的第j个IMF分量,rt(i)为EEMD对序列xt(i)进行分解得到的趋势项分量。由于三次样条曲线良好的稳定性和收敛性,EEMD分解过程中常采用三次样条插值方法对上、下极值点进行插值拟合,但通常年径流序列的极值点分布并不均匀,导致拟合的包络线出现过包络和欠包络的现象,不能反映正确的包络形状,从而造成较大的误差,影响预测精度。为了改善这种现象,应用极值中心三次样条插值方法到EEMD分解年径流序列过程中,其具体分解过程如下。
找出xt(i)序列所有的局部极大和极小值点。端点和极大值点之间、端点和极小值点之间分别用直线段连接,形成上、下包络折线xmax和xmin。对所有极值点时刻的xmax和xmin取平均,得到极值中心点。再对极值中心进行三次样条插值,拟合出平均包络线再用减去平均包络线,获得去掉低频序列的新序列。该过程即为极值中心三次样条插值方法。对新序列重复上述操作,整个过程循环至平均包络线趋近于零时停止,然后截断两端延拓部分,得到表示原始序列中最高频的第一个IMF分量ct(i1)。一般IMF分量必须满足:①过零点数和极值点数差值为0或1;②xmax和xmin每个时刻的平均值为零。用序列减去未截断的ct(i1)得到剩余值序列r1,然后把r1序列作为一个新的原始序列,重复上述步骤得到ct(i2),ct(i3),…,ct(iM),当剩余值序列为常数、单调函数或仅有一个极值的函数时,分解过程结束,此时的剩余值序列即为趋势项rt(i)。
步骤3步骤1和步骤2重复NE次,对IMF分量进行平均运算,得到EEMD的IMF分量为:
( 3 )
式中ct(j)——第j个IMF分量,由EEMD对原始序列进行分解得到。
此时,原始序列被EEMD方法分解成M个IMF和一个趋势项:
( 4 )
式中rt——最后残余分量,代表序列整体趋势。
1.2 最近邻抽样回归模型(NNBR)
NNBR模型无需预先假设随机过程的分布规律,是依靠数据驱动的非参数模型。NNBR模型根据研究对象的不同分为单因子模型和多因子模型[14],本文采用单因子模型对(j=1, 2,…,M)和趋势项建模并进行预测。
设某一个分解序列yt(t=1, 2,…,n),yt依赖于前p个历史值yt-1,yt-2,…,yt-p。定义历史模式矢量Dt=(yt-1,yt-2,…,yt-p),其后续值为yt(t=p+1,p+2 ,… ,n),p为矢量Dt的维数。已知当前模式矢量Di=(yi-1,yi-2,… ,yi-p),按照水文相似性原理,在历史模式矢量中找出与当前模式矢量最相似(最近邻)的K个历史模式矢量,然后将其按照相似程度由高到低进行排列:D1(i),D2(i),… ,DK(i),与之对应的后续值记为yj(i)(j=1, 2 ,… ,K)。矢量维数一般由yt的自相关图和偏自相关图综合确定[15],同时要求。最近邻模式矢量数K的选取一般采用K[16]。
当前模式矢量的后续值预测如下:
( 5 )
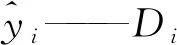
( 6 )
判别当前模式Di与历史模式Dt相似程度的指标有欧氏距离、余弦相似度、耦合序位值、DTW距离等,文献[14]研究表明基于欧式距离的NNBR模型预测精度较高,且欧式距离计算简便,故本文采用欧式距离指标来选择最近邻模式矢量。欧式距离越小,则表示二者越近邻(相似),欧式距离计算公式为:
(7)
式中lt(i)——Dt与Di间的欧氏距离;yij、ytj——Di、Dt的第j个元素。
1.3 EEMD-NNBR耦合模型
将EEMD与NNBR结合构建EEMD-NNBR耦合模型,其基本步骤如下。
步骤1利用改进的EEMD方法对年径流时间序列进行分解,得到年时间尺度由小到大的IMF分量序列(j=1, 2, …,M)和一个趋势项rt。
步骤2分别对各IMF分量(j=1, 2, …,M)和趋势项rt建立最近邻抽样回归模型并进行预测,将各预测值相加得到年径流量的预测值,即:
(8)
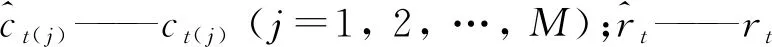
2 改进的EEMD-NNBR耦合模型在年径流预测中的应用
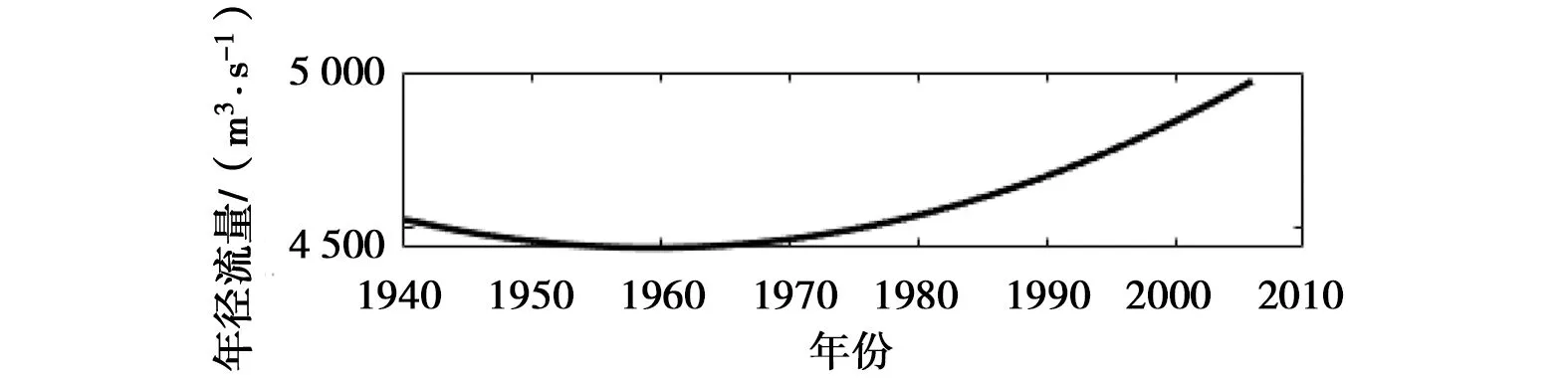
采用金沙江屏山站1940—2016年的年径流序列(图1)来验证EEMD-NNBR耦合模型的适用性。金沙江位于长江上游,长江河源有北源楚玛尔河,正源沱沱河和南源当曲,沱沱河与当曲汇合处为通天河起点,终点为玉树市巴塘河口;巴塘河口至宜宾市岷江河口称为金沙江,以下始称长江。从青海江源到四川宜宾干流河长3 481 km,流域面积约47.32万km2,多年平均降水量在600~1 500 mm,部分地区超过1 800 mm。由屏山站1940—2016年径流数据可知,金沙江流域径流的年内、年际分配极不均匀。连续最小三月(一般2—4月)占年径流量6%~14%,连续最大三月(一般7—9月)占年径流量41%~67%,多年的最大月径流量与最小月径流量比值在4~16之间。年径流的变差系数CV为0.16,最大、最小年径流的比值为1.95。
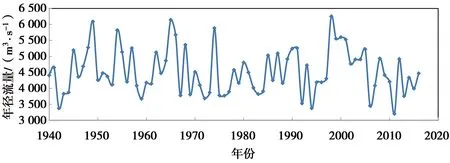
图1 屏山站1940—2016年的年径流序列
2.1 模型建立
为充分利用信息,采用逐步向下滑动方式进行建模,即根据屏山站1940—2006年的年径流序列预测2007年年径流量,然后在序列中加入2007年的实测年径流量,预测2008年年径流量。以此类推,滑动预测2009—2016年的年径流量。
以2007年年径流量的预测过程为例,分别运用改进的EEMD方法和EEMD方法对屏山站1940—2006年的年径流序列进行多时间尺度分解。通过参数试错分析,白噪声标准差取原始序列标准差的4倍,即取Nstd=4;添加100次高斯白噪声,即NE=100。图2所示,EEMD方法采用三次样条插值方法得到的上、下包络线存在多处过包络和欠包络,这样导致2个同样性质的极值点间的包络线不单调,不能很好地反映序列的频率特征。改进的EEMD方法分解年径流序列时,包络线为各极值点的折线连接,相比三次样条插值方法得到的包络线,过包络和欠包络现象明显降低,且在进行端点延拓后,减缓了端点效应。年径流序列分解后最终得到5个IMF分量以及一个趋势项rt,见图3、4。调用Matlab中hhspectrum函数求得的各IMF分量频率统计特征值见表1、2。由表1可以看出,基于改进的EEMD方法,屏山站年径流序列存在约为3、5、8、11、15年的周期。5个IMF分量中,IMF1的振幅相对较大,频率相对较高;IMF2、IMF3、IMF4和IMF5的振幅相对较小,频率较低。由表2可知,EEMD方法分解得到的年径流序列存在约为3、6、14、38、65年的周期,由于资料长度有限,不能确定屏山站年径流序列是否存在65年周期变化。5个IMF分量中,IMF1、IMF2和IMF3的振幅相对较大,频率相对较高;IMF4、IMF5的振幅相对较小,频率较低。由于2种方法分解得到的周期存在一定的差别,故本文运用小波分析来识别屏山站1940—2006年的年径流序列周期,结果表明存在3、9、12、17年左右的周期,可见改进EEMD方法识别周期成分是有效的,进一步说明其改进是有意义的。
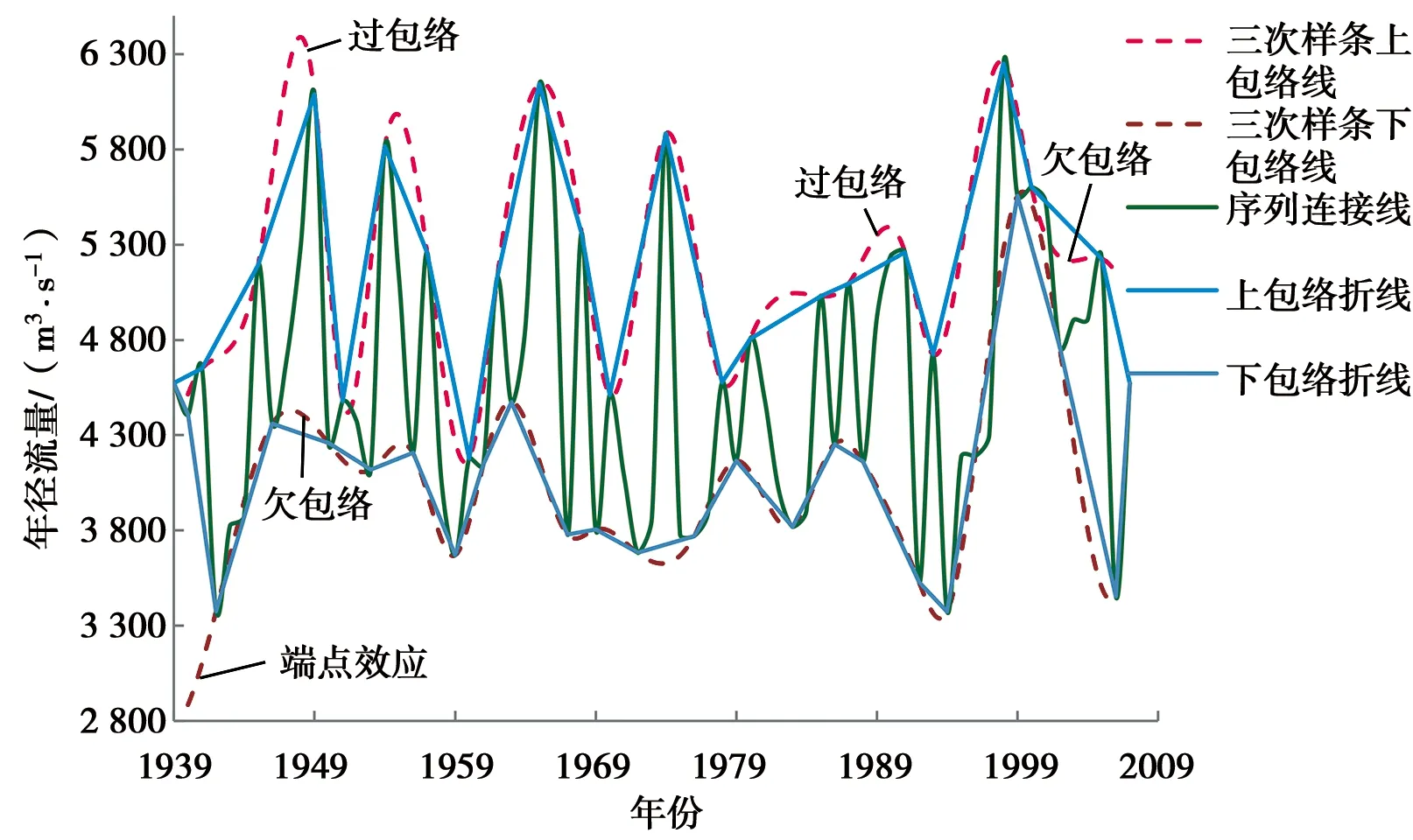
图2 折线包络线与三次样条包络线比较
a) IMF1
b) IMF2
c) IMF3
d) IMF4图3 改进的EEMD方法分解得到的IMF分量

e) IMF5

f) 趋势项续图3 改进的EEMD方法分解得到的IMF分量
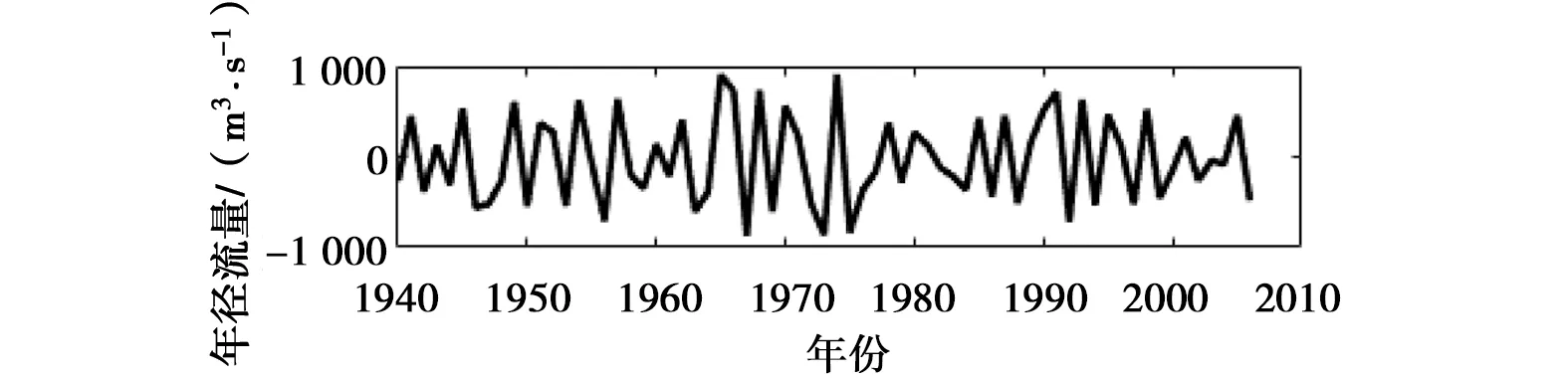
a) IMF1
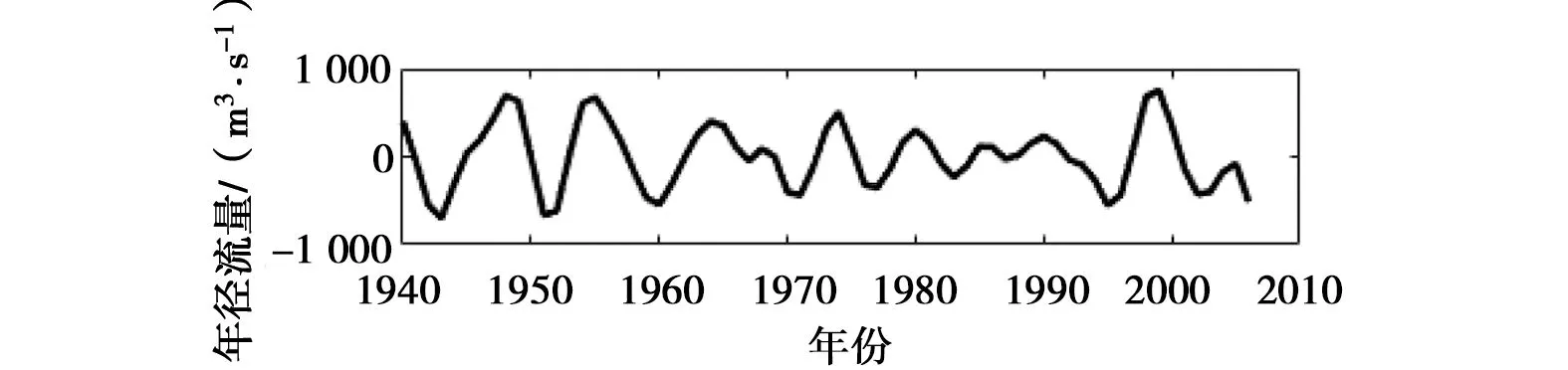
b) IMF2
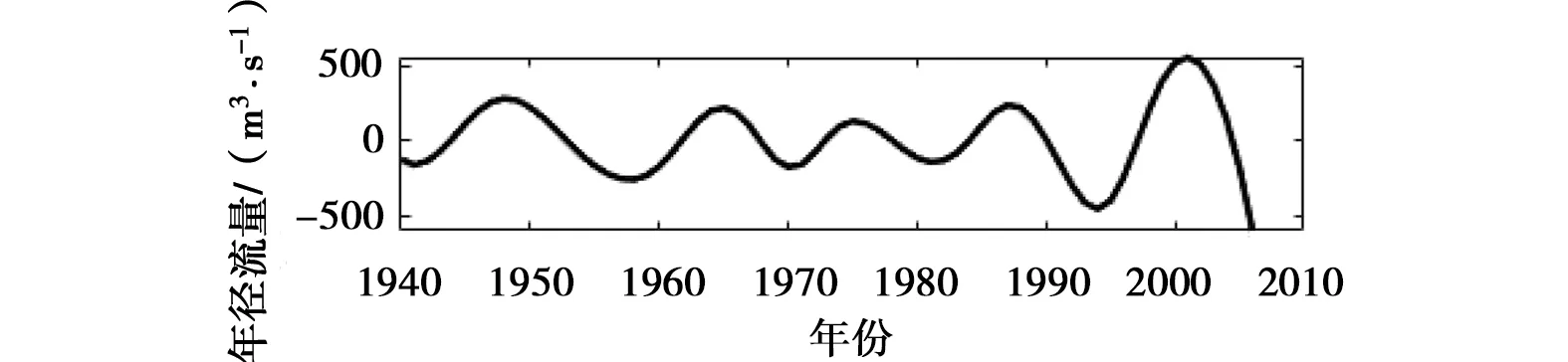
c) IMF3

d) IMF4
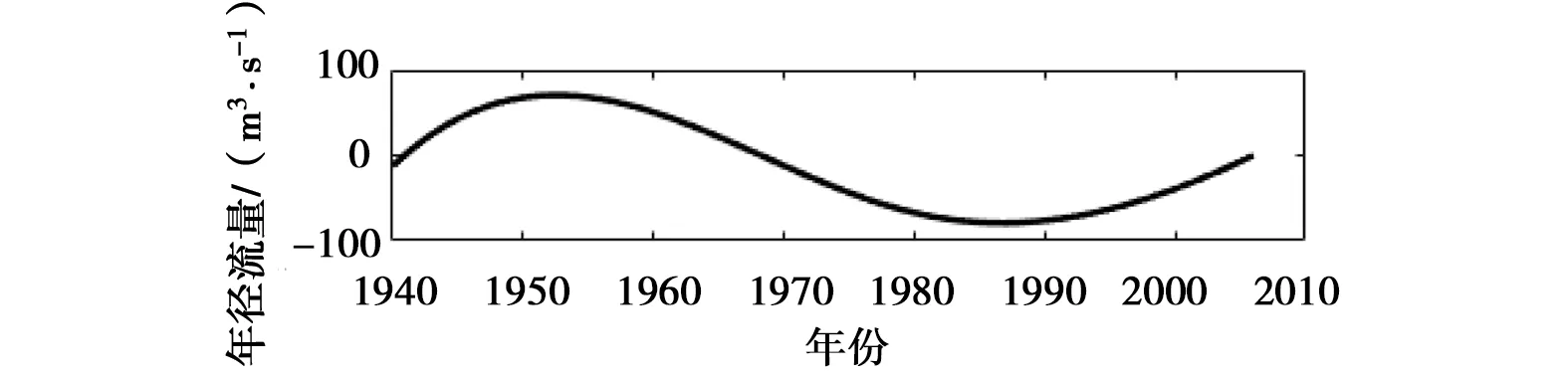
e) IMF5
f) 趋势项图4 EEMD方法分解得到的IMF分量
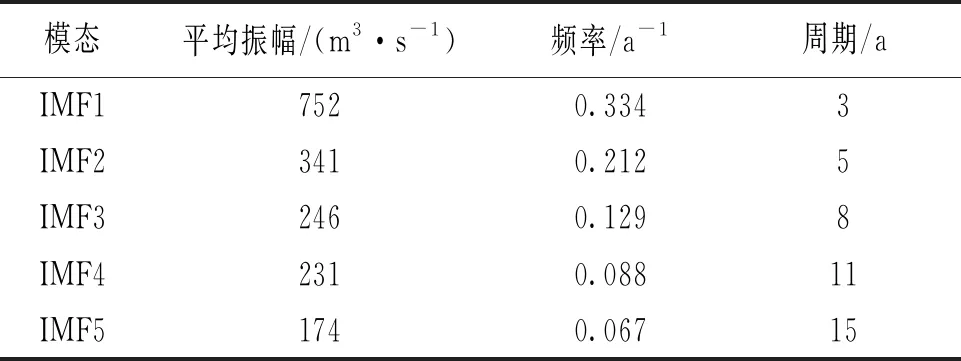
表1 改进的EEMD分解得到的IMF分量频率统计特征值
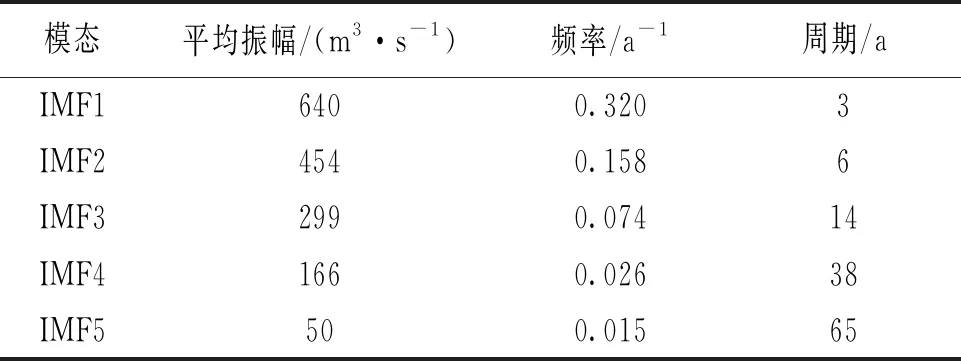
表2 EEMD分解得到的IMF分量频率统计特征值
将获得的5个IMF分量和趋势项数据代入NNBR模型进行预测,通过参数试错分析,确定P=3,K=8。同理,利用1940—2007年的年径流序列建立EEMD-NNBR模型并预测2008年年径流量。以此类推,分别预测2009—2016年的年径流量。
2.2 预测结果
屏山站年径流预测结果见表3。采用平均相对误差对模型改进前后的预测精度进行评定比较,分别为10.08%、8.59%。
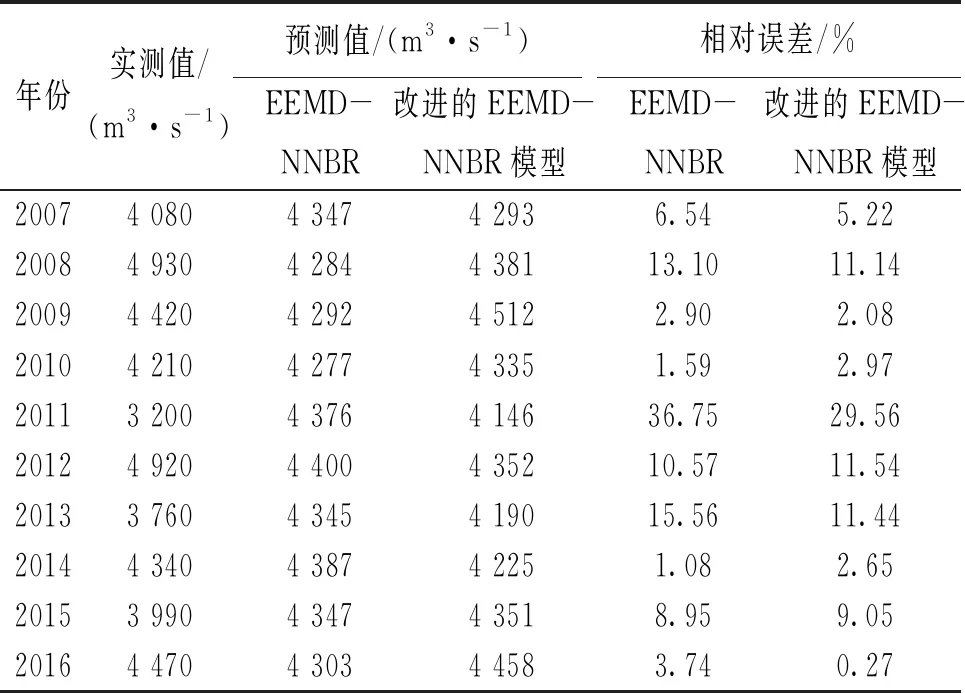
表3 屏山站年径流预测精度分析结果
2.3 对比分析与讨论
由表4可知,总体上EEMD-NNBR模型不如改进的EEMD-NNBR模型预测精度高。另外,由表3可知,对于2008年径流极大值和2011年径流极小值而言,改进的EEMD-NNBR耦合模型预测的相对误差分别为11.14%、29.56%,较改进前的误差13.10%和36.75%有明显的降低,说明改进的EEMD-NNBR耦合模型对过程线的极值点预测效果更好。
EEMD-NNBR耦合模型在进行端点延拓和采用极值中心三次样条插值的方法后,提高了对年径流序列的预测精度。
3 结论
本文提出了改进的EEMD技术,改进技术采用极值中心三次样条插值方法,减缓了EEMD分解过程出现的过包络、欠包络现象和端点效应。在此基础上建立改进的EEMD-NNBR耦合模型,模型充分利用了EEMD分解非线性、非平稳序列的优势和NNBR预测过程简便、预测精度高的特点。以屏山站年径流量预测为例,研究结果表明改进的EEMD-NNBR耦合模型在年径流序列预测中模型适用性好,预测精度高,同时能良好地预测过程线的极值点。EEMD-NNBR耦合模型是在基于各种模型优点基础上建立的一种模型,值得进一步加以推广和应用。
