大数据背景下公平竞争审查文本的排查研究
2021-03-01钟锦鸿林瑞娜龙熠燚孔荫莹
钟锦鸿,林瑞娜,龙熠燚,孔荫莹
(1.广东财经大学经济学院,广东 广州 510320;2.广东财经大学会计学院,广东 广州 510320;3.广东财经大学信息学院,广东 广州 510320)
0 引言
国务院2016年6月14日颁布的《关于在市场体系建设中建立公平竞争审查制度的意见》标志着我国公平竞争审查制度开始确立[1].公平竞争审查制度的含义是公平竞争审查主体针对立法及行政机关制定出来的法律及政策进行市场竞争影响评估,将不利于市场竞争秩序的法律及政策修改或废止的一项评估制度[2].
在现阶段,各地市场监管局开展公平竞争审查的依据主要是2017年国家发展改革委发布的《公平竞争审查实施细则(暂行)》(以下简称《实施细则》)[3].《实施细则》提出了违反公平竞争的四类审查标准,对各类标准下的一些典型违背行为作了明确或概括性的规定,但这些规定并没有涵盖更多的违反公平竞争审查标准的行为,因此在实务审查中需要借助监管人员的经验积累;在审查范围上,主要是对重点行业和地区开展专项审查,难以做到对各级政府单位的统一监督审查;在审查方式上,主要是依据政府监管人员对审查公文进行逐一排查,客观上受监管人员能力和主观性判断的限制,且人工排查条件下效率较低.
随着各级政府不断地发布新的法规和政策文件,积累了大量的文本数据.这些数据可以通过一些大数据技术来更好地帮助公平竞争审查人员去排查疑似违反公平竞争标准的文本.目前国内有关公平竞争审查的研究主要是集中于研究如何完善公平竞争的制度以及更好地落实公平竞争制度,如谢芳琳学者考察了目前公平竞争实施制度的现状并提出了关于公平竞争制度的一系列问题及有关改善的意见[5],孙考利学者和刘澜晶学者论述了如何更好地保障公平竞争制度的实施[6],金善明反思和检讨了公平竞争审查制度并提出了要将其拓展为外部的监督机制[7].上述学者对于公平竞争审查研究是基于法律和政治层面,对于如何利用大数据技术去处理公平竞争审查的文本分类还尚未有相关的研究.目前筛选和分类文本最常用和简单的方法是构建关键词词典并基于关键词词典来筛选含有关键词的文本[8].除此之外,还有应用朴素贝叶斯、支持向量机、卷积神经网络、决策树等算法进行文本分类.在应用卷积神经网络于文本分类方面,自Yoon Kim把CNN从图像领域转入到NLP的领域,提出了TextCNN,将CNN用于处理文本数据进行情感分析取得很好的效果后,涌现了许多应用该卷积神经网络的成果,如杨锐等学者应用了卷积神经网络对能源政策文本提取主题信息并进行分类[9],明建华等学者将TextCNN用于直播弹幕的过滤[10].
目前结合大数据技术去处理公平竞争审查文本的研究,国内外还处于一片空白.针对该领域,本文创新性地提出了将当前比较主流的数据分析技术和深度学习中的卷积神经网络应用到公平竞争审查的人工排查过程中,能够扩大实务中审查范围和提高人工审查效率;同时积累建立公平竞争审查疑似案例库,对违反《实施细则》中规定的典型市场行为做进一步补充和经验性总结,进一步对公平竞争审查工作重点提出反馈意见,同时也为后来学者在公平竞争审查领域的研究提供另一种思路和研究方法.
1 研究意义
中国共产党的十九大报告提出了加快完善社会主义市场经济体制,明确指出“深化商事制度改革,打破行政性垄断,防止市场垄断,加快要素价格市场化改革,放宽服务业准入限制,完善市场监管体制.”[11]公平竞争审查作为市场价格监督与反垄断排查的工作重点,对打破行政性垄断、提高市场活力起者关键性作用.下面分别从理论层面和应用层面对项目意义进行阐述.
1.1 理论指导意义
全面推进依法治国.应用数据政策工具健全行政机关内部决策合法性审查机制,有助于监督政府依法全面正确履行职能,加强政策文本的合宪性解释,巩固好经济宪法的地位,实现社会主义制度下的良法善治.
促进经济体制改革.通过大数据技术进行公平竞争文本排查,有利于完善和建立公平竞争的中国特色社会主义市场体系,同时防止政府过度干预以及不当干预市场的行为,更好地发挥市场在资源配置中所发挥的决定性作用,实现效益最大化和效率最优化.
释放市场主体活力.我国经济发展正处于培育和催生经济发展新动能的关键时期[12],通过目前的大数据技术手段规范政府有关行为,废除政府部门行政垄断的政策,有利于调动各类市场主体的积极性和创造性,优化营商环境,推动大众创业、万众创新.
实现创新驱动发展.随着市场竞争机制的强化和统一的全国大市场的初步确立,营造公平竞争的市场环境成为了创新驱动发展的重要动力.通过大数据手段破除具有排除、限制竞争内容的政策措施,能在新常态下推进经济稳定持续地健康发展.
深化“放管服”改革.“放管服”改革其中一点提出政府部门要创新和加强监管职能,利用新技术新体制加强监管体制创新[13].通过利用大数据的技术,可以提高市场监管局的监管能力,提高公平竞争审查工作效率,同时,通过建立公平竞争审查数据库也可以为公平竞争审查工作起到借鉴作用.
1.2 实际应用价值
针对政务审查中的“信息大爆炸困境”,引入大数据处理方法成为排查问题文本的有效手段和发挥监督价值的关键.一方面,大数据作为信息时代的重要生产要素和战略资源,能够在海量信息中获取所需要的关键信息;另一方面,深化电子政务审查技术的路径革新,能够提高国家治理能力的现代化水平.
2 研究方法
2.1 基于关键词词库筛选文本
需要排查的法律及政策的文本数据来源主要由广东省市场监督管理局官方提供和基于python的Selenium库和Requests库编写的爬虫程序从广东省的各级政府爬取的地方性法规、政策、通告等文本数据,两者相加共2 808份文本数据.将数据收集起来后,通过人工筛选先将数据分为违反了公平竞争标准和没有违反公平竞争标准的两类文本数据,然后分别从两类文本数据的标题中筛选出各自的关键词组成关键词词库,如表1和表2所示列出了关键词词库的关键词,表1是通过人工筛选从违反了公平竞争审查标准的文本的标题中筛选出来的关键词,而表2是通过人工筛选从没有违反公平竞争审查标准的文本的标题中筛选出来的关键词.将关键词词库和需要筛选的数据导入到MySQL数据库中,最后使用数据库MySQL编写的SQL程序对导入的数据进行筛选,筛选出两类文本数据.
2.2 基于TextCNN的文本分类
2.2.1 研究思路
基于TextCNN的法律及政策文本的分类流程如图1所示.

表1 违反公平竞争标准文本标题的关键词

表2 没有违反公平竞争标准文本标题的关键词
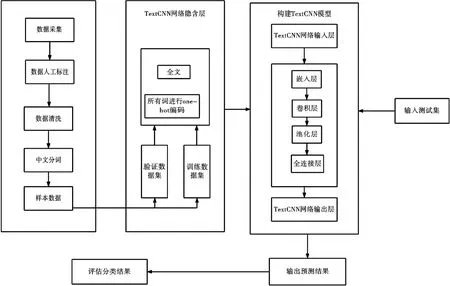
图1 基于TextCNN的文本分类流程
上述提到的基于关键词词库筛选文本的方法虽然是很高效,但由于准确度不高,同时由于违反公平竞争标准的文本千变万化所以关键词的选择需要不断地更新,这种简单的基于关键词的方法难以符合当前的实际需求,因此提出了基于TextCNN来分类需要排查的文本.
首先将收集到的所有需要排查的文本数据进行人工标注,将违反了公平竞争标准的文本标注为1,将没有违反公平竞争标准的文本标注为0.之后对数据进行清洗,使用jieba进行中文分词等一系列数据预处理后将数据划分为训练数据集、验证数据集和测试集.在训练数据集上训练模型,在验证数据集上评估模型.在训练数据集上训练好的模型会在验证数据集上评估模型的好坏[14],将模型在验证数据集上所表现出来的性能作为不断调整模型参数的反馈信号从而达到最佳的参数.模型达到最佳的参数后就在测试数据集上进行最后一次测试,来衡量模型的泛化能力是否在其它新的数据集上也有像在验证数据集上这么良好的性能.将输入的经过数据预处理后的文本数据进行one-hot编码后输入到基于python的keras框架搭建好的TextCNN的模型中,最后将训练好的模型对训练数据集进行最后一次的测试并评估模型的性能.
2.2.2 TextCNN理论模型
TextCNN最基本的模型如图2所示.
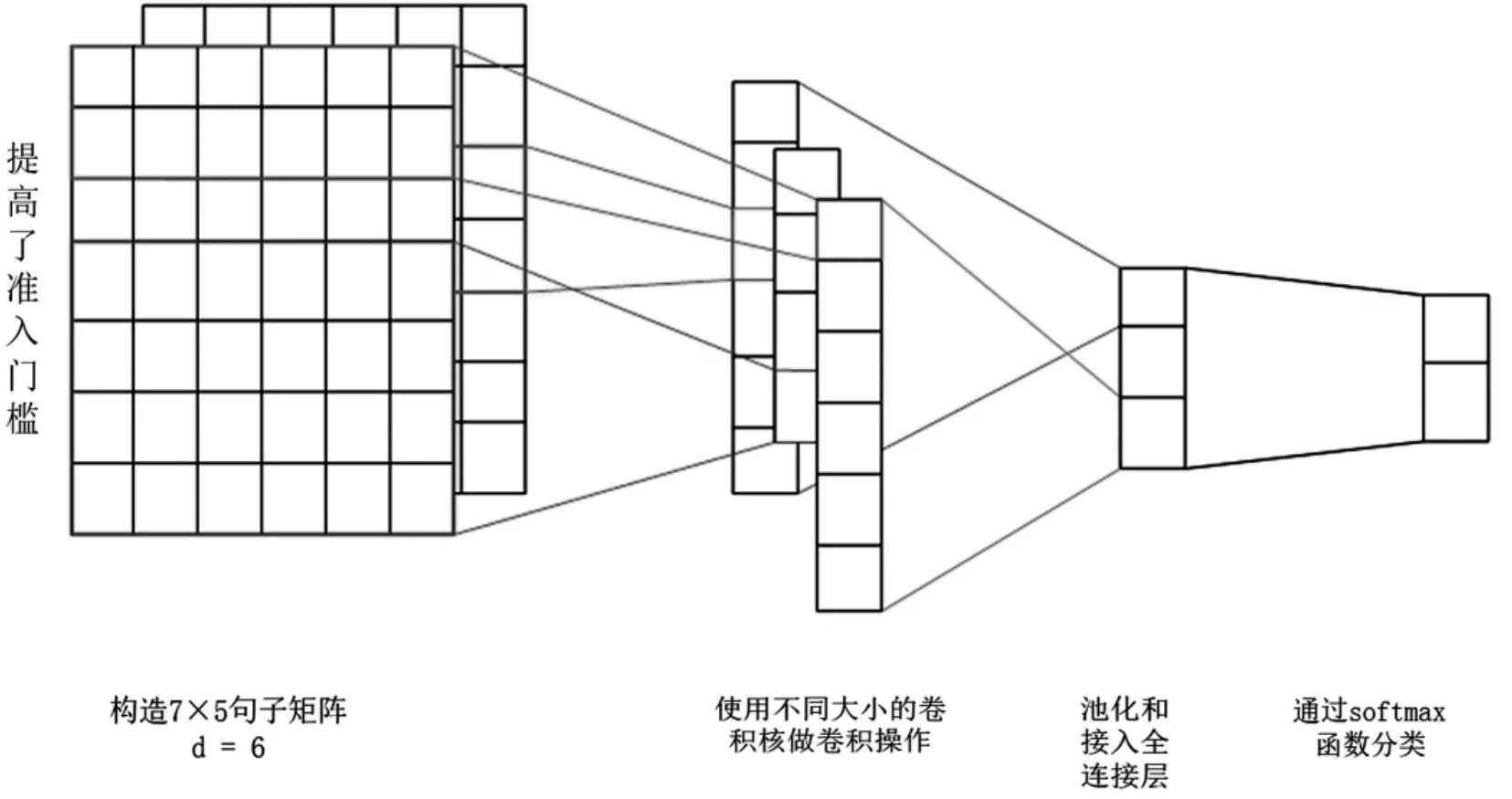
图2 TextCNN模型图
设xi∈Rk表示一个句子中第i个词的k维词向量,其中Rk表示k个Descartes乘积集,其数学表示为:
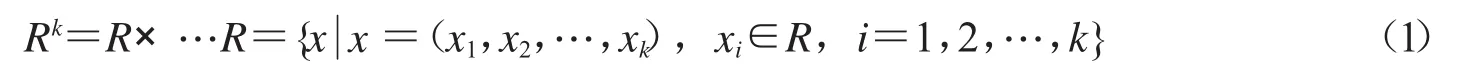
一个长度为n的句子可以表示为:

⊕表示的是连接操作符.因此,图2中所表示的句子“提高了准入门槛”就可以表示为 x1:7=x1⊕x2⊕…⊕x7,其中 xi∈R6.
设给定的句子的长度(词汇数)为s,用d表示词向量的维数,因此可以将句子转化为一个s×d的维数矩阵.在图2中有6个过滤器,每两个过滤器分别对应一个窗口大小,一共有3个窗口,大小分别为2、3和4.如图3所示的是一个窗口大小为4的一个过滤器,图中的数字表示的是过滤器的参数.设窗口的大小为h,某个过滤器的参数化权向量为 ω∈Rh×d,ω 包含了 h×d 个参数.用 A∈Rs×d表示句子矩阵,A[i,j]表示从 i行到j行的子矩阵,如A[1,2]表示x1:2=x1⊕x2.
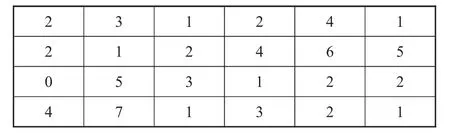
图3 窗口大小为4的过滤器
句子矩阵与过滤器进行卷积运算得到:

其中,i=1…s-h+1,表示子矩阵与过滤器之间的点积运算,输出的序列长度为s-h+1,最后通过激活函数f与偏置项b得到对应的特征向量c∈Rs-h+1:

对特征向量进行池化运算池化成一个值,并将池化后的值全都连接起来组成一个新的特征向量,并使用softmax函数进行分类.
3 实验与结果
3.1 实验环境配置
表3 实验环境配置情况
3.2 实验设计
3.2.1 数据预处理
对由广东省市场监督局收集和爬取到的数据共2 808份数据首先进行人工标注分类,之后进行数据清洗,用jieba进行中文分词,分词后对数据进行去除停用词处理,停用词表采用哈尔滨工业大学的停用词表hit_stopwords[15].将数据划分为训练数据集1581份,验证数据集678份,测试数据集549份.
3.2.2 TextCNN
TextCNN模型主要由输入层、卷积层、池化层、全连接层和输出层构成,其中卷积层负责进行卷积运算,池化层负责进行池化运算而全连接层是将卷积运算后的特征值连接起来[16].本文的TextCNN模型加入了嵌入层用于学习词嵌入得到一个密集的词向量.TextCNN模型使用基于python的keras深度学习框架来进行搭建,具体的参数如表4所示,将训练数据集1 581份和验证数据集678份输入到构建好的TextCNN模型中,训练完成后载入训练完成的模型对测试数据集549份进行最后一次测试,检验模型的泛化能力.

表4 TextCNN参数设置
3.3 实验结果
为了评估模型的性能,本文使用了准确率、精确率以及召回率这3个指标作为评估的标准,计算公式如下:
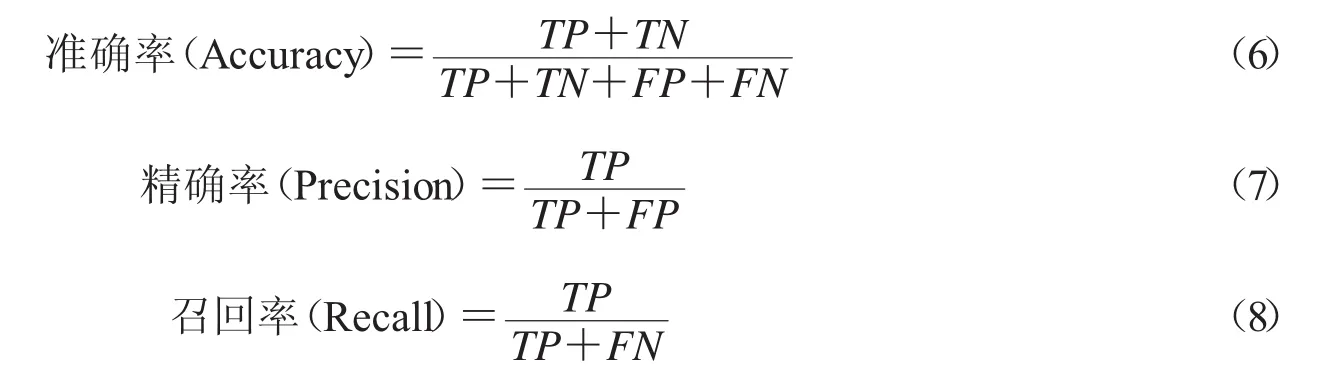
准确率表示判断正确的次数和所有判断的次数的比值,精确率表示在所有被判断为正样本的样本中有多大比例是真正的正样本,召回率表示在所有真正的正样本中有多大的比例是被判断正确了[17].在本实验中正样本是没有违反公平竞争标准的文本数据,负样本是违反了公平竞争标准的文本数据.从实验结果来看,该模型在判断文本是没有违反公平竞争标准的准确度较高,而在判断文本是违反了公平竞争标准的这个情况下准确度却较低,需要做进一步的改进.

表5 实验结果评估
4 讨论
目前公平竞争审查流程如图4所示,在人工工作模式下,对于公平竞争文本初步审查(即判断公平竞争审查文本是否涉及市场经济活动这一部分)的工作难度不大,但是工作量庞大,对于经验丰富的工作人员来说是简单重复的工作,这在一定程度上增加了人工成本.在判断公平竞争审查文本是否违反了18条标准的判断阶段,工作人员一般需要查阅大量的法律文献和资料作为参考,这个阶段不仅耗时长,过程繁琐,还会给判断结果带来一定的误差.
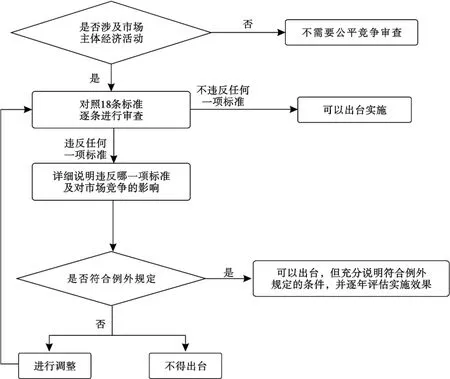
图4 公平竞争审查基本流程
本文通过实现卷积神经网络对公平竞争审查文本的分类能够在一定程度上帮助到工作人员进行公平竞争审查文本的排查,初步快速地对大量的公平竞争的审查文本给出初步的判断,同时在判断没有违反公平竞争审查的文本准确率较高,但是目前该算法仍然不能完全替代人工,而是作为工作人员的辅助工具.其仍然存在一定的误差项和局限性,在面对较为复杂的审查文本的时候可能无法精准判断仍需要人工判断,仍然需要进一步地研究.
5 结束语
本文针对公平竞争审查中的人工审查的过程首先提出了基于关键词过滤筛选违反公平竞争审查标准的文本,由于该方法存在准确度不是很高、难以抽全关键词等问题,因此难以适应目前的实际需求.接着提出了将深度学习结合到公平审查中的方法提升了分类的准确率,实现通过电脑程序来自动进行公平竞争审查文本的排查,模型在训练数据集中各项指标都达到了92.22%,验证数据集中各项指标达到了92.48%,测试数据集中的各项指标也基本在90%左右,然而模型由于样本数据不均衡导致了负样本的精确率和召回率指标数很低,因此模型仍存在着一些问题需要进一步的改进.感谢广东省市场监督局为我们提供实习机会并提供相关的研究数据和公平竞争审查的标准,帮助我们更好地了解和掌握公平竞争审查的流程,在之后的工作中,会更加深入地研究以提高排查的准确度.
