面向英文句子的框架语义扩展及相似度计算
2021-02-28王铁鑫刘文静杨志斌曹静雯
王铁鑫,刘文静,杨志斌,曹静雯
1(南京航空航天大学 计算机科学与技术学院,南京 210016) 2(高安全系统的软件开发与验证技术-工信部重点实验室,南京 210016)
1 引 言
句子相似度计算是自然语言处理研究中的一个基本问题[1].许多基于自然语言处理技术的应用,使用句子相似度计算,如语义检索[2],文本摘要[3],自动问答系统[4],抄袭检测等.以论文抄袭检测为例,其被广泛应用于科研论文投稿、毕业论文查重等审核阶段.自动化、高效率的句子相似度分析检测方法,能够有效替代繁重且易错的人工判断过程.
句子的相似性可以从两个维度加以解释:语法与语义.语法相似性关注句子中使用的词汇及句子结构,如使用相同或相似的词汇与结构组织句子.语义相似性关注句子本身的语义,如不同的词汇在不同语法结构组织下,表达相同或相近的意思.
目前,使用较多且效果相对较好的句子相似度计算方法主要利用语义分析技术;根据采用分析技术的不同,可以进一步将计算方法划分为3类[5]:1)基于语料库的相似度计算方法;2)基于知识库的相似度计算方法;3)基于句子结构信息的相似度计算方法.然而,以上3种方法都有各自的不足.
基于语料库的相似度计算方法,依赖于人工智能技术,如机器学习与深度学习算法.语料库的选取、前期对语料库的人工标记、语料特征的选择与抽取等,都直接影响着相似度计算的准确性.与其他应用人工智能算法的方法类似,该类方法同样缺乏对计算结果的可解释性.基于知识库的相似度计算方法,依赖于对句子关键词的提取、分析与对比,缺乏对句子整体语义的把握与理解;同时,该类方法也受限于所选取知识库(目前多为WordNet)的内容与结构.针对基于句子结构信息的相似度计算方法,当前的研究工作较少,尚未成熟.
针对以上问题,本文提出一种基于扩展语义框架的英文句子相似度计算方法“Extended Frame Semantics based Sentences Similarity Computing(EFS3C)”.EFS3C将句子作为一个整体;系统分析计算句子中所有关键词的相似度,并考虑关键词在句子中的上下文语境.
EFS3C建立在框架语义网“FrameNet”基础上,并结合使用两种成熟工具“Semafor”与“NER”.首先,利用Semafor与NER实现对句子中所有关键词的识别;然后,通过结合使用Semafor与FrameNet实现对关键词激起框架的定位与分析;最后,通过量化分析被激起框架间的语义关系,实现句子间相似度的计算.
本文的主要贡献如下:
1)将框架语义引入英文句子相似度计算方法,这在目前的英文句子相似性计算方法中是从未有过的;面向框架语义网FrameNet构建可视化环境,实现框架间语义关系量化计算过程的可视化,提高计算结果的可解释性;
2)针对部分关键词无法激起语义框架的问题,定义3种新的语义框架:COUNTRY,STATE_OR_PROVINCE,LOCATION以扩充FrameNet,并定义相关相似性计算规则;
3)结合使用Semafor和NER工具,增强EFS3C方法的自动化与智能化;定义可配置的计算过程,提高效率的同时实现领域定制化.
本文结构如下:第2节介绍基于知识库的句子相似度计算的相关研究工作;第3节对EFS3C方法中使用的主要理论、技术和工具加以说明;第4节描述EFS3C方法的原理及计算过程;第5节通过实验,验证EFS3C方法的准确性与有效性;第6节是本文的总结与展望.
2 相关工作
2.1 基于知识库的句子相似度计算
WordNet[6]作为大型语义库,常被用作句子相似度计算方法中的知识库;它提供句子中关键词的语义对比基础.WordNet中包含3类主要元素:单词(及短语)、词义、同义词集.一个单词拥有一到多个词义,每个同义词集包含若干个语义相近的词义.同义词集间设定层次结构,并建有语义关系.
早期工作,如文献[7,8],单独使用WordNet作为计算关键词间语义关系的基础;但使用WordNet中数据的方法、定义的计算公式不尽相同.近年来,为了提高计算结果的准确度,研究工作常结合使用WordNet、语料库统计技术、句子结构分析技术,深度学习,本体等,如文献[9-14].
除利用WordNet进行句子相似性计算之外,程传鹏等人在分析已有研究工作的基础上,利用HowNet提出了一种改进的句子相似度计算方法[15].
以上研究工作都是针对关键词的语义分析与计算展开的,缺乏对句子整体语义及关键词上下文语境的考虑.针对特定测试集,通过调整计算方法中的可变参数及判断阈值,能够取得较好的测试效果.然而,这类计算方法的通用性及适用性都有很大的局限性.
2.2 FrameNet应用
文献[16]提出了基于框架语义分析的汉语句子相似度计算方法.该方法建立在汉语框架网(Chinese FrameNet:CFN)基础上,整合了ICTCLAS分词工具、LTP依存句法分析器等成熟工具.该方法的主要创新点在于对关键词激起框架作了重要度度量(依据框架元素),并在此基础上,实现了多框架语义分析及计算.
实验结果表明,与其他传统方法相比,该方法在计算准确率上有优势.然而,该方法也存在弱点,如句子中关键词激起框架需要人工参与完成,算法执行前的预处理工作需要大量人工参与等.另外,该方法实验用的测试集是定制的(对比句子均抽取自CFN),并基于该测试集与其他计算方法的输出结果做对比.这种实验与对比方法的有效性值得商榷.
文献[16]证明了CFN用于中文句子相似性计算是可行的,间接证明了基于框架语义理论计算英文句子相似性的可行性,进而证明了我们提出的EFS3C方法的合理性.
2.3 小 结
本文提出的EFS3C方法扩展FrameNet:使用框架语义克服只针对关键词计算相似度的缺点,通过增加新的语义框架,更好的对应句子中的关键词,从而提高计算的准确度.
EFS3C整合使用Semafor与NER工具,在算法应用过程中,降低人工参与度,提高算法的执行效率.实验阶段使用通用的测试集,实验结果与对比分析具有更好的说服力.
3 相关技术和工具
3.1 FrameNet
FrameNet[17](1)http://framenet.icsi.berkeley.edu/是一个基于框架语义学(Frame Semantics)的语义知识库.框架语义理论[18]通过引入概念显像与框架这一组关系,从根本上改变了人们对概念的认识与分类方法.
在FrameNet中,框架(Frame)被用来描述一个事件或一个场景.框架包含的各种参与者或者其他的概念性角色,被称为框架元素(Frame Elements),它是框架的基本单元.能够激起框架的被称为词元(Lexical Unit).
图1以框架“Intentionally_act”和“Intentionally_affect”为例展示了3种元素之间的关系.框架“Intentionally_act”和“Intentionally_affect”之间存在继承关系“inheritance”.两个框架分别由词元“act.v”,“do.v”激起,且包含对应的框架元素如“Agent”,“Act”等.框架包含的框架元素之间也存在映射关系,如框架“Intentionally_act”的框架元素“Agent”和框架“Intentionally_affect”的框架元素“Agent”.
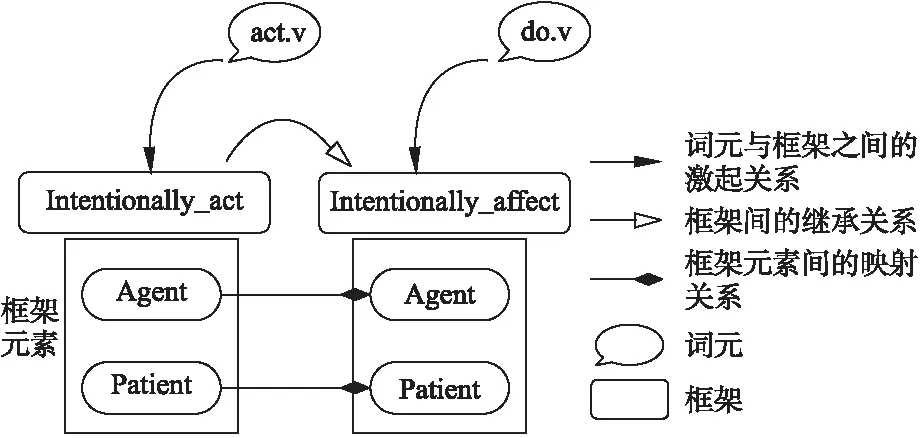
图1 FrameNet的示意性描述
EFS3C的基本工作原理可描述为:首先,将句子中的关键词映射匹配到FrameNet中的词元;接着,追溯得到对应词元所激起的框架;然后,量化分析所激起框架间的语义关系;最后,通过执行预定义计算公式,从而得到不同句子间的相似度.
为了更好地使用FrameNet,我们开发了一个可视化工具“Graphical Interpretation for FrameNet:GIFN”.GIFN基于图形化数据库Neo4j实现,在4.2节对其进行详细介绍.
3.2 Semafor
Semafor[19](2)http://www.cs.cmu.edu/~ark/SEMAFOR/是一个开源的FrameNet解析工具.它能自动地依据FrameNet结构解析句子,以获得句子内容所激起的框架,框架元素以及框架元素所指代的具体内容等.
以句子S1:“A tropical storm rapidly developed in the Gulf of Mexico Sunday and was expected to hit somewhere along the Texas or Louisiana coasts by Monday night.”为例,以下为Semafor自动分析获得的部分结果.
…
以框架“Weather”为例,S1中“storm”激起了该框架,该框架的框架元素“Place”在S1中的指代内容是“tropical”.
EFS3C方法整合使用Semafor,以自动提取对比句子中的相关语义框架信息.Semafor在EFS3C中的详细使用方法在本文的4.1小节中给出.
3.3 NER
由于FrameNet和Semafor本身的局限性,即无法对句子中所有关键词进行识别并关联语义框架,我们将命名实体识别技术与EFS3C进行整合.作为技术实现工具,我们选用斯坦福大学的自然语言处理工具CoreNLP[20]中的“the named entity recognizer:NER”,作为EFS3C的组成部分.
目前,EFS3C能够识别句子中的:人名、地名、机构名、钱、数字、百分比等实体.
表1展示了对例句S1的命名实体识别结果.第1列是句子S1中包含的单词,第2列是对应的实体类型,如单词“night”对应的实体类型是“TIME”.

表1 NER对S1的实体识别结果
EFS3C中自定义3个扩展语义框架:COUNTRY,STATE_OR_PROVINCE,LOCATION;通过扩充FrameNet和Semafor的覆盖范围,以更好的匹配句子关键词,进而提高EFS3C方法计算结果的准确性.扩展框架的使用在4.3小节中有详细阐述.
4 EFS3C方法
4.1 算法过程
如图2所示,EFS3C以两个独立的英文句子作为输入,输出是两个句子间的相似度计算结果(取值范围在0-1之间).该计算结果的值越高意味着两个句子的相似性越强.

图2 EFS3C计算流程示意图
Semafor和NER并行处理两个待比较的英文句子.EFS3C从Semafor分析的结果得到两个句子所激起的框架,分别用集合frame_s和frame_s′记录;进一步比较、抽取两个集合的相同元素,形成集合frame_same.
EFS3C从NER得到两个句子中的命名实体,判断是否是本文自定义框架并判断其对应内容是否相同.若相同则将其加入集合frame_same.同时记录所激起的自定义框架个数.得到去除了相同框架的集合frame_s和frame_s′之后,利用GIFN,通过执行预定义计算公式,计算获得句子间的相似度值.
4.2 FrameNet可视化
FrameNet可视化环境(GIFN)将FrameNet中所有的框架,框架元素和词元当作结点,将框架之间的关系,以及词元与框架之间的关系当做边存储在Neo4j中.
目前,GIFN中存有1019个框架结点,11829个词元结点,8995个框架元素结点,框架之间的关系有1507个.
图3展示了框架“Intentionally_act”、其包含的框架元素,可激起该框架的词元,及框架“Intentionally_affect”之间的关系.图中的面积最大的结点(圆圈)代表框架;两个框架结点之间存在继承关系.图中面积最小的结点是能够激起框架“Intentionally_act”的词元结点.其余结点代表了框架“Intentionally_act”所包含的框架元素.
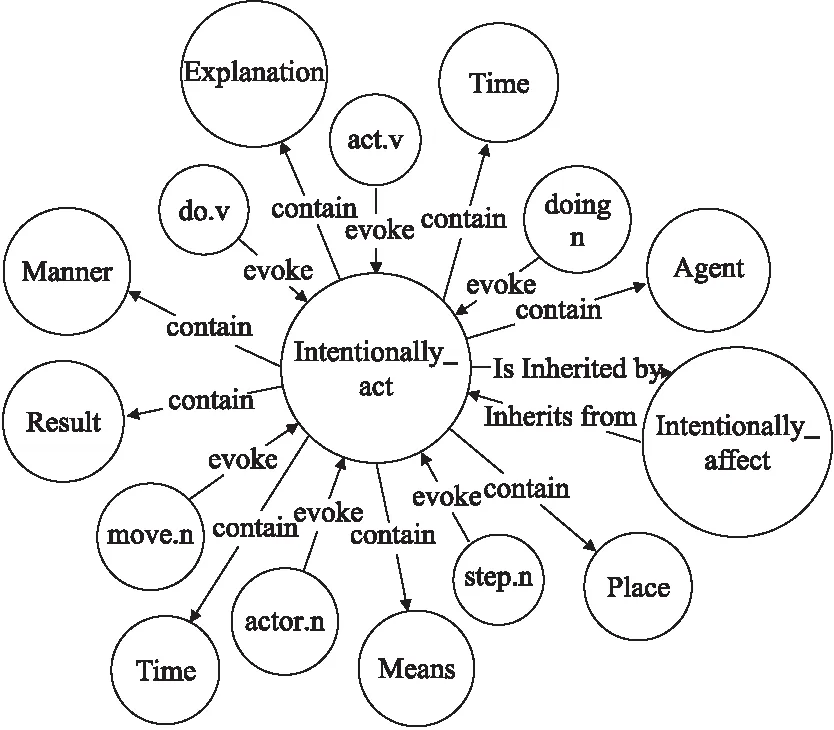
图3 GIFN中结点与边的说明示意图
在EFS3C中,框架之间的语义关系被用来衡量两个句子之间的相似性.为了实现对语义关系的量化分析,我们对不同的框架关系赋值.为框架关系赋值的想法来源于文献[21].对应的赋值越大,意味着两个框架结点语义关联越密切.
为框架之间的语义关系赋值过程如下.首先,我们邀请5位语义学相关学者分别为框架语义关系赋值;接着,通过圆桌讨论,由所有学者共同拟定一组赋值,如表2中第2列所示;然后,随机从数据集“Microsoft Research Paraphrase Corpus:MSRP”中挑选出60对句子(其中15对是不相似的,另外45对相似)来测试初始赋值的可靠性.

表2 FrameNet框架之间的语义关系赋值
根据测试结果的F1值(在5.1小节有说明),设定语义关系初始赋值的判定阈值 “0.595”(高于此阈值,认为句子相似,否则不相似).此阈值对应的F1值是“0.7957”.
5位专家根据EFS3C在特定测试集上的测试结果(与已知结果做对比),进一步调整对语义关系的赋值.
最终的赋值结果如表2中第3列所示.针对这组最终语义关系赋值,我们设定判定阈值为“0.505”.
4.3 框架扩展
实验结果显示,由于FrameNet的不完善和Semafor工具本身的缺陷,导致Semafor对句子的分析结果漏掉了句子中的重要地点成分信息.
例如,Semafor对句子S1的处理结果中并没有关于“Mexcical”的信息,而对于“Texas” “Louisiana”等地点信息,Semafor也并没有分析出与其相关联的框架.所以EFS3C使用命名实体识别工具来弥补这一缺陷.
NER可以将句子S1中的“Mexico”,“Texas”和 “Louisiana”信息分别识别为:COUNTRY,STATE_OR_PROVINCE和STATE_OR_PROVINCE.从而,S1所激起的框架就会增加两个,COUNTRY和STATE_OR_PROVINCE,对应的词元分别为:“Mexico”,“Texas”和 “Louisiana”.
4.4 句子相似性计算
EFS3C使用Semafor分析句子内容所激起的所有框架,使用NER分析的结果进而获得自定义框架.在给出具体的方法之前,我们先给出预定义计算算法中使用变量的定义.
定义1.frame_s={framei|i∈[1,|frame_s|]}
定义2.frame_s′={framej|j∈[1,|frame_s′|]}
定义3.frame_same=frame_s∩frame_s′
定义4.frame_rel={
frame_s,frame_s′,frame_same和frame_rel是框架或者框架对的集合.frame_s和frame_s′是包含了两个待比较的句子所激起的框架的集合.frame_same是集合frame_s和frame_s′的交集;frame_rel包含了frame_s和frame_s′中除去相同框架之后在GIFN中有最短路径的框架对.
基于以上变量,我们定义如下计算公式.
(1)
公式(1)中,Frame_score代表了两个句子之间的相似度.它由3部分所决定,相同框架的个数(即|frame_same|),两个句子所能激起的最大框架数(即Maximum(|frame_s|,|frame_s′|))和Path_score.公式(2)是Path_score的计算方式.
(2)
Path_score是指Path_value的累加和.Path_value是指两个框架在GIFN中的路径权重的累加和与路径长度之比,公式(3)是其具体计算方法,公式中的CountPath是指GIFN中两个框架结点的最短路径长度.
(3)
以如下句子S2和S3为例,阐述比较算法的执行过程.
S2:“Moseley and a senior aide delivered their summary assessments to about 300 American and allied military officers on Thursday.”
S3:“GeNERal Moseley and a senior aide presented their assessments at an internal briefing for American and allied military officers at Nellis Air Force Base in Nevada on Thursday.”
表3列举了句子S2(第1列)和S3(第2列)所激起的框架.

表3 S2和S3所激起的框架
由表3知,frame_same包含6个元素:Subordinates_and_superiors,Delivery,Assessing,Origin,Military,Leadership,Calendric_unit.
从GIFN中我们可以得到与frame_s中的元素Delivery有最短路径的是frame_s′中的元素Presence.所以frame_rel只包含了一个元素,
EFS3C假定最短路径在10步以内的两个结点才属于集合frame_rel.根据表2和公式(2),我们可以得到Path_score的结果是0.45625.
NER的分析结果显示,句子S2中没有激起自定义扩展框架,S3激起LOCATION和STATE_OR_PROVINCE两个框架,对应的内容分别是“Nellis Air Force Base”和“Nevada”.所以公式(1)中的Maximum(|frame_s|,|frame_s′|)是11.因句子S2和S3没有相同的扩展框架,所以二者的相同框架个数是6.根据公式(1)可以得到Frame_score的结果是0.5869.参考4.2小节中设定的0.505的阈值,可以认定句子S2和S3是相似的,而这个结果也符合数据集MSRP人工标注结果.
5 实验及结果分析
5.1 评价指标
使用F1和accuracy两个指标来评估EFS3C方法.F1在自然语言处理领域中常被用来衡量方法的优劣[22].F1和accuracy的计算公式如下所示.
(4)
(5)
F1是统计学中用来衡量二分类模型精度的一种指标,同时兼顾了分类模型的准确性precision和召回率recall.F1可以看作是模型precision和recall的一种加权平均,它的取值范围是0-1.precision和recall的定义如下.
(6)
(7)
公式(5)-公式(7)中的TP,TN,FP和FN分别定义如下.
1)TP(True Positive):预测为正例,实际也为正例;
2)TN(True Negative):预测为负例,实际也为负例;
3)FP(False Positive):预测为正例,实际为负例;
4)FN(False Negative):预测为负例,实际为正例.
5.2 数据集
MSRP是一个被广泛用来测试句子相似性技术的数据集.本文用MSRP来测试EFS3C方法的有效性.
MSRP数据集包含有约5700对句子,并且每一对句子都被人工标注为0(不相似)或者1(相似).其中,有67%的句子被人工判定为相似,其余的被判定为不相似.所有的句子对被划分成为了两个集合:一是训练集(包含4076对句子),另一个测试集(包含1725对句子).
5.3 结果分析
我们使用MSRP的测试集验证EFS3C的有效性.在这个测试集的1725对句子中,有1147对句子是相似的,其余的578对句子不相似.
图4展示了EFS3C,Mihalcea[23]的5种其他基于WordNet的句子相似性计算方法和Mamdouth[12]提出的方法在accuracy和F1的对比结果.

图4 EFS3C和其他方法的accuracy和F1对比
表4列出了这6种方法和EFS3C的accuracy,precision,recall和F1值.观察表4可以得到,EFS3C的F1值虽然位于第2位,但是它的accuracy和precision要远高于Mihalcea文献中所列举的5种方法.而Mamdouth的accuracy和precision虽然很高,但是其recall是非常低的,且F1值也不高.

表4 EFS3C和其他计算方法的综合对比
实验表明,EFS3C基于FrameNet的相似性计算方法优于基于WordNet的句子相似性计算方法.这也说明,EFS3C为句子相似性计算提供了一个新的可行方向.
6 总结与展望
本文提出了一种新的基于框架语义理论的句子相似性计算方法,文献[16]间接证明了我们的方法的合理性.首先,本文通过利用Semafor对句子进行语义分析来刻画句子的语义;其次通过命名实体识别对句子进行地点实体提取,以补充Semafor的分析结果;最后以框架为基本单元,结合框架之间的语义关系来计算句子之间的相似度.本文方法侧重于将句子看作一个整体而非单词的组合.实验表明,本文方法相比于其他基于WordNet的方法中能够在相似度测试中获得更好的结果.但由于目前的方法依赖于Semafor的分析结果,使得本文方法的性能受限于Semafor的性能.
下一步将利用句子的其他特征,如框架元素等,以进一步提高方法的性能.此外,也将扩大方法应用方向,并逐渐向缺陷分析等实际应用拓展.
