面向工程领域的主题多样性知识推荐方法
2021-02-25王临科蒋祖华李心雨
王临科,蒋祖华+,李心雨
(1.上海交通大学 机械与动力工程学院,上海 200240;2.新加坡南洋理工大学 机械与宇航工程学院,新加坡 639798)
0 引言
随着互联网技术的发展与信息时代的到来,知识已成为企业极具价值的重要资产,通过高效的知识管理手段提供优质的知识服务,对驱动企业产品创新设计、增强企业竞争力至关重要[1]。目前,知识管理系统(Knowledge Management System, KMS)是企业提升自身知识服务能力的主要手段。作为能够收集、处理、共享一个组织全部知识的信息系统,KMS支持具有相似兴趣或专业背景的用户群体,以开放协作的形式共同创造积累和共享利用知识[2]。当用户进行工程任务时,要求KMS能够推送最相关的知识条目,为用户提供有力的技术支撑,而推荐算法的性能决定了知识推送的效果[3]。用户历史行为数据中包含了用户的兴趣偏好,推荐算法可以根据这些数据构建用户兴趣画像,进而从爆发式增长的海量知识资源中为用户筛选出合适的知识条目。传统推荐算法通常基于用户及项目的相似度进行推荐,并仅以提升准确度为目标对算法性能进行评估[4],在工程知识推荐背景下会导致两方面问题:
(1)为了尽可能提升准确度,推荐算法倾向于推荐与用户历史浏览高度相似的知识条目,导致KMS中仅有少数经常被浏览的“流行知识条目”能够参与推荐。在电商领域,只推荐流行项目也能够满足大部分人的兴趣与需求,因此是可被接受的,但工程用户针对不同的情境会产生特定的知识需求[5],若仅推荐流行知识条目,会使推荐算法在特定情境下降低甚至丧失其效用。
(2)工程问题普遍具有学科融合、领域交叉的复杂背景,使基于知识重用的工程任务成为多学科、知识密集型活动[6]。例如,船舶机舱布置图设计需要参考查阅主机、油泵、管路、电路等多个主题领域的知识,而传统推荐算法仅以准确度为优化目标,且未充分利用丰富的工程语义信息,导致知识推荐列表主题单一、同质化严重,缺乏针对工程问题和用户真实知识需求的全局视角[7],大大降低了推荐算法的效用。
综上所述,研究如何解决推荐列表“流行化”和“同质化”问题对提升知识推荐效果具有理论意义,对企业创新设计能力与竞争力的增强具有重要实践价值。
围绕以上问题,众多学者关于推荐服务的研究主要集中于多样性领域。Kunaver等[7]指出,在推荐中引入多样性能够减轻推荐列表同质化问题,提升用户满意度;Wu等[8]认为多样性已成为评估推荐有效性的重要指标,并指出该领域的研究关键是如何平衡准确度和多样性;Wang等[9]将多样性分为集体多样性和个体多样性,并将个体多样性定义为单个推荐列表中所有项目对的平均差异度,即以准确度和个体多样性作为优化目标,使推荐列表中的知识准确且全面地覆盖目标用户的兴趣与需求。基于以上个体多样性的定义,现有研究主要集中于开发新的多样性推荐方法并提出适当的多样性评估方法[7]。在多样性推荐方法中,后过滤与重排序策略应用广泛,这类方法首先基于现有推荐方法寻找与用户最相关的项目,然后对这些相关项目进行重新排序以提升推荐结果多样性。Zhang等[10]提出一种两阶段协同过滤优化方法,首先利用基于用户的协同过滤(User-based Collaborative Filtering, UCF)方法初步筛选出符合用户多个兴趣点的项目,然后基于用户兴趣和社会影响力生成最终推荐列表,以实现推荐准确度和多样性的平衡;Kotkov等[11]提出一种面向偶然性的重排序算法,通过项目特征多样化提高推荐的偶然性,进而提升推荐结果的多样性;Eskandanian等[12]提出一种聚类后过滤方法,满足了用户对多样性程度的不同偏好。也有部分学者将多样性推荐视为多目标优化问题[13-15],即分别建立准确度、多样性的目标函数,然后利用遗传算法、蚁群算法、群体智能算法等求帕累托最优解,进而通过对推荐列表进行重排序完成推荐。为了利用项目间的关联性,图论方法也被引入多样性推荐中。Lee等[16]利用用户的正向评价信息构建无向图,并利用图中音乐项目间的关联关系提升推荐结果的多样性;Zhou等[17]利用三方偏好图改进传统基于用户的协同过滤方法,平衡了推荐结果的准确度和多样性。对于多样性的评估,不同方法的差别在于使用不同信息计算项目间的相似度或差异度,主要有3种:①基于属性类别信息[18],使推荐列表中尽可能包含不同主题或种类的项目,常用于电影、音乐推荐;②基于项目评级信息[8,19],通过最大化推荐列表中项目评分向量间的几何距离提升多样性,适用于电商推荐;③基于内容信息[20],一般针对文本类推荐,利用关键词共现统计方法或关键词TD-IDF(term frequency-inverse document frequency)权重向量距离计算文本项目间的相似度,实现对推荐列表多样性的评估。
从现有研究成果来看:
(1)现有研究大多通过随机策略提升推荐多样性,未能充分挖掘特定情境下知识条目间的关联关系,虽然增加了推荐结果多样性,却大大降低了特定情境下所推荐知识条目的效用[21]。
(2)现有研究无论是多样性推荐方法还是多样性评估方法,都缺乏对情境和知识条目间工程语义关系的深入分析[22],因而无法有效解决面向工程领域的多样性知识需求。
为此,本文提出一种面向工程领域的主题多样性知识推荐(Topic-Diversity Knowledge Recommendation, TDKR)方法,在现有研究的基础上,充分考虑工程语义信息、知识应用情境以及知识任务相似度等信息,结合改进的基于用户的协同过滤方法(UCF),提出新的后过滤与重排序策略,在特定情境下有针对性地提升知识推荐结果的主题多样性,有效提升企业知识推送服务质量,进而驱动企业产品创新设计、增强企业竞争力。
1 基于KMS的企业知识管理
1.1 KMS运行机制
知识管理系统(KMS)能够为企业提供知识的积累、集成、维护、共享和重用等服务。例如,国内某船厂大约80%的船舶舾装设计工作都需要查阅参考行业标准、历史经验案例等各类知识[23],该船厂利用KMS实现有效的知识管理。KMS用户能够基于系统提供的模板创建新知识或修改已有的知识条目,经过管理员或领域专家审核通过后,存入企业知识库,形成企业的知识资产。用户可以通过主动检索和被动接收KMS系统推荐两种方式进行知识获取,以辅助当前工程任务[24]。
1.2 KMS中的工程知识
在国内某船厂的KMS中,与舾装设计相关的知识主要有3类:①经验案例知识,指员工在舾装设计任务中总结的成功与失败的经验教训,如图1a所示;②规范知识,指船舶领域的各种行业级或公司级标准规范文档,主要由各大船级社或企业内部领域专家统一制定,如图1b所示;③专利知识,指企业拥有的与船舶设计相关的专利文档,如图1c所示。
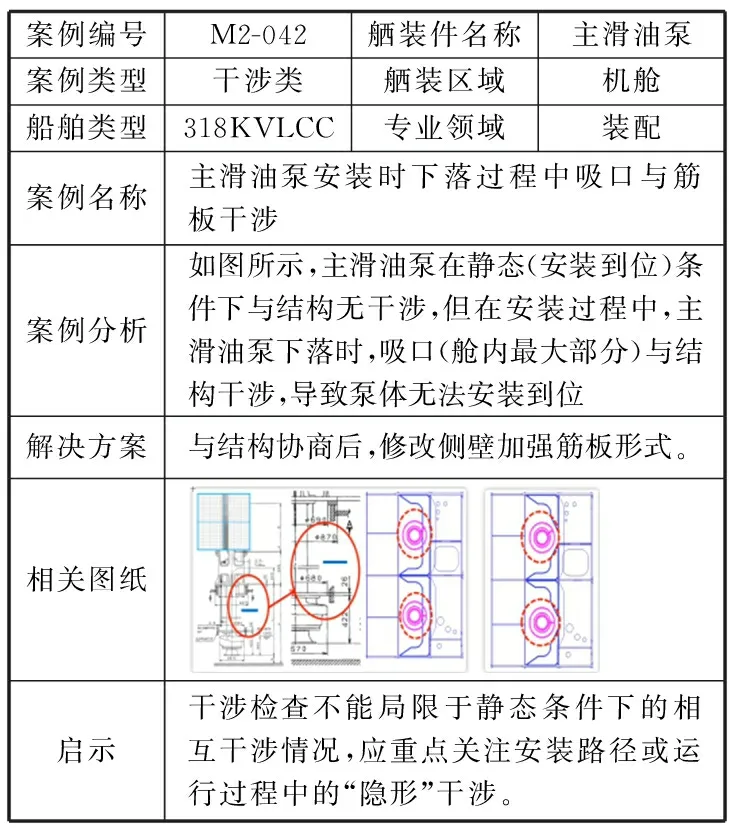
a 经验案例知识
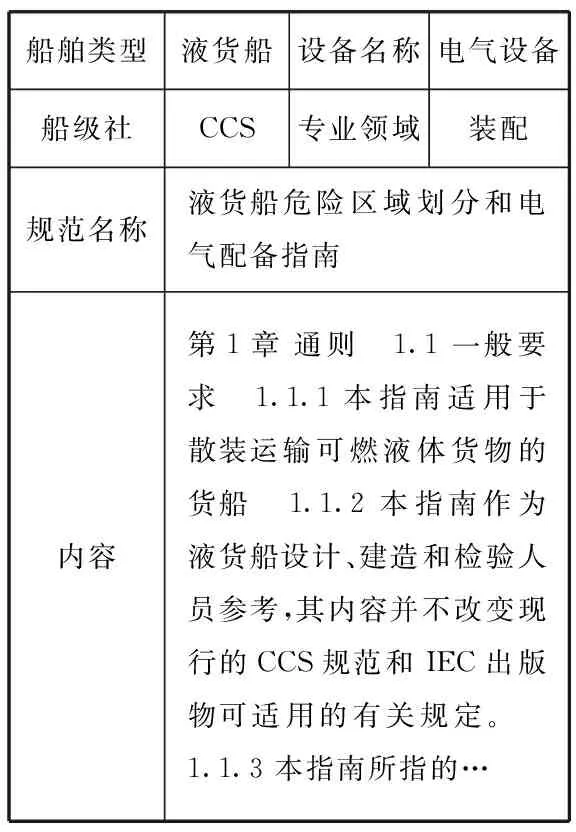
b 规范知识
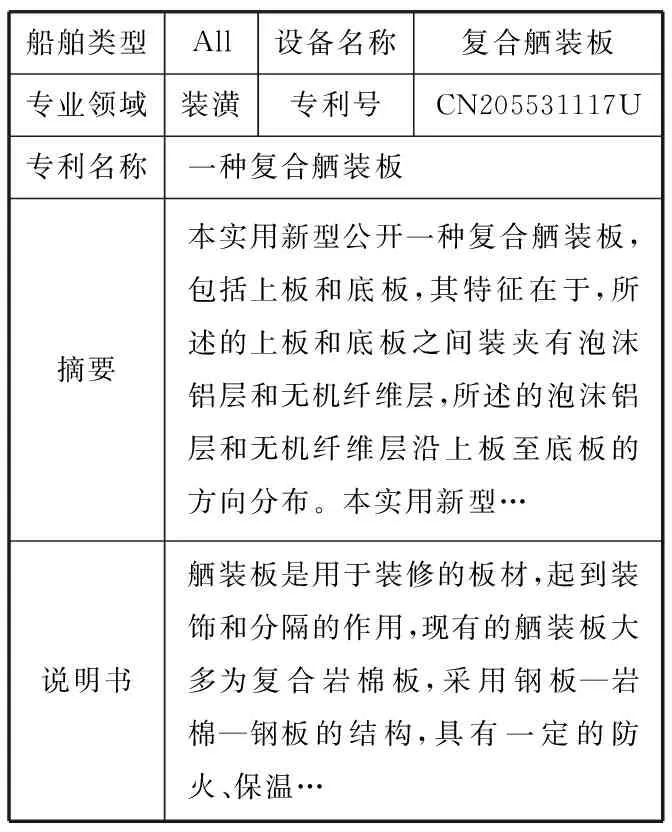
c 专利知识图1 知识条目示例
在工程领域,知识的产生和应用都具有特定的背景与环境,即不同的知识具有不同的应用情境[5]。知识应用情境可以视为知识应用的限定条件,是知识共享和知识重用的重要基础,能够有效解决知识过载问题[25]。考虑到如图1中知识的半结构化特征,本文整理出船舶类型、设备(舾装件)名称、舾装区域、案例类型、专业领域、船级社6个通用属性作为船舶舾装设计知识的应用情境C(C中的属性值ci均为船舶领域专有名词,为枚举类型,可以为空)。表1所示为情境属性及其部分属性值,为方便计算,将属性值用数字统一编码,并用向量表示为C=(c1,c2,c3,c4,c5,c6)。

表1 船舶舾装设计知识应用情境示例

续表1
1.3 KMS中的用户行为数据
KMS以用户日志的形式记录用户操作行为数据,并存入相应的数据库,部分行为数据如表2所示。为便于研究,将用户行为数据表示为R={U,I,C,ΔT,O},即用户U对应用情境为C的知识条目I进行了时长为ΔT的O操作。其中:C为表1中6种属性的编码向量;O包括创建(Oc)、修改(Or)、浏览(Ob)三种操作。
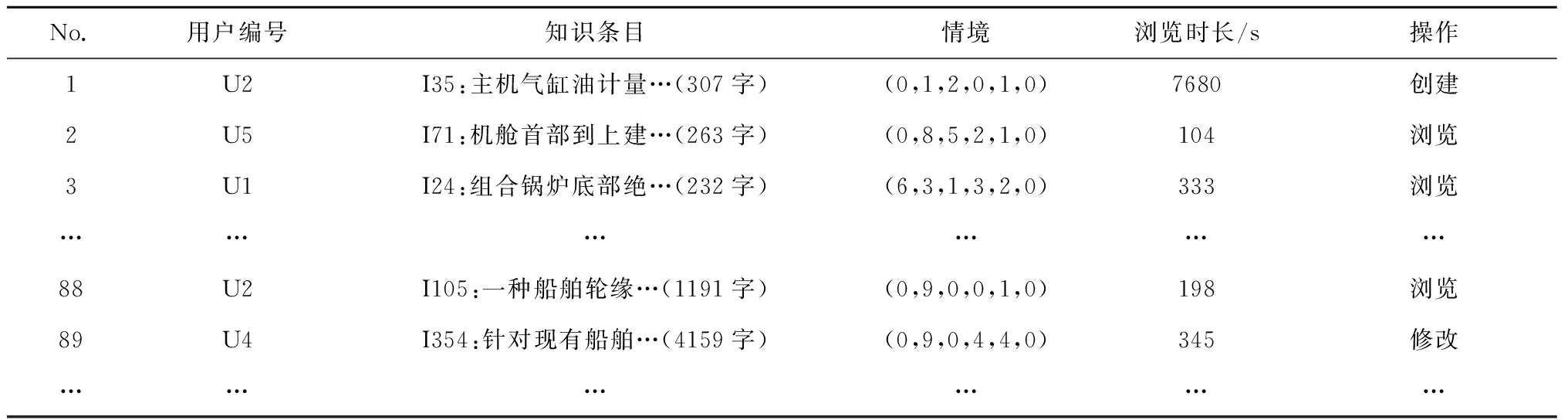
表2 用户行为数据示例
2 面向工程领域的主题多样性知识推荐方法
2.1 总体框架
为满足工程领域用户多样性的知识需求,本文提出了TDKR方法,方法框架如图2所示。
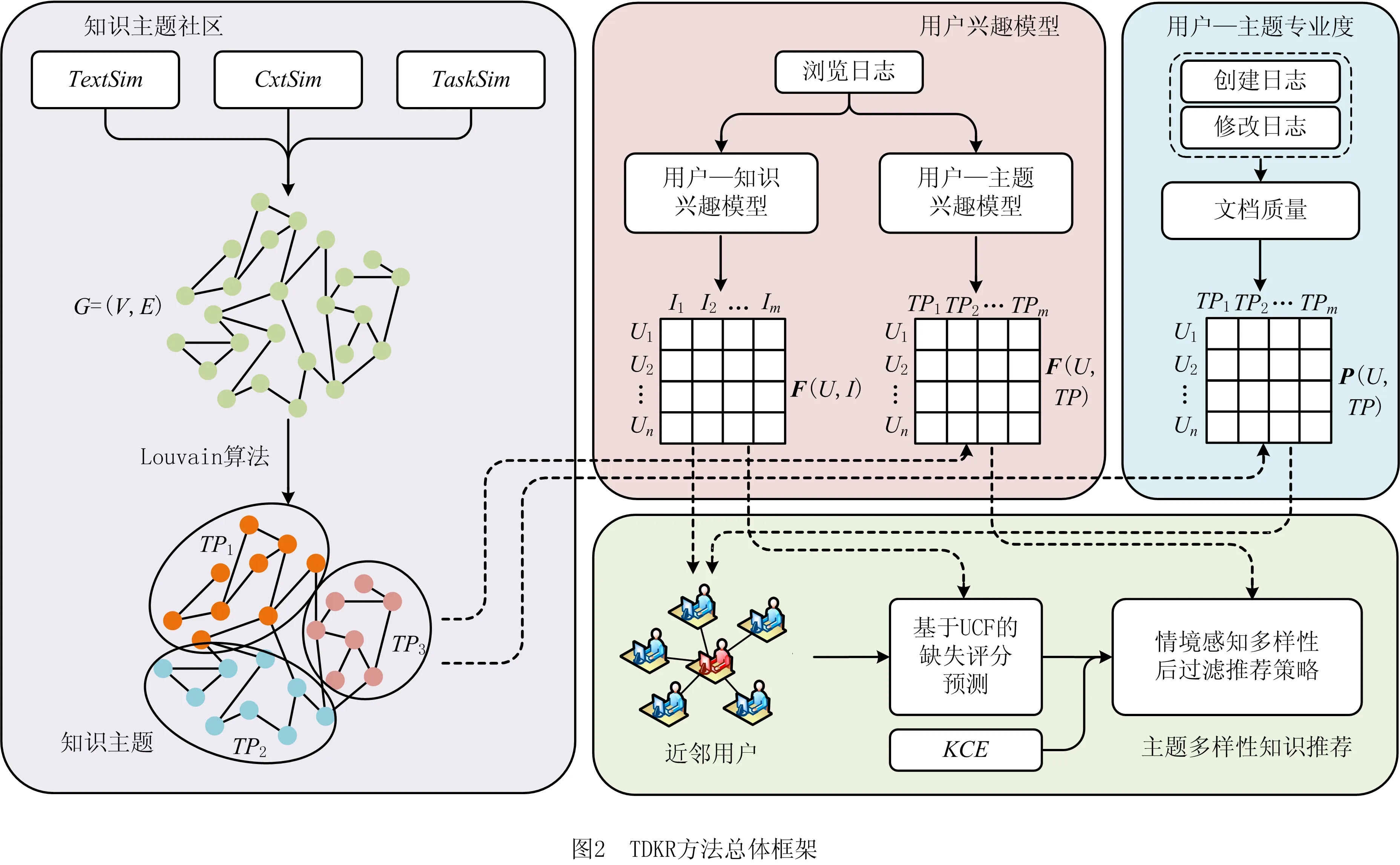
TDKR方法框架主要包含4部分:
(1)知识主题社区 挖掘知识条目间的内容相似度、应用情境相似度以及任务相似度,据此构建知识相关性网络,进而利用Louvain社区发现算法从知识相关性网络中发现知识主题社区,用于建立用户—主题兴趣模型和计算用户—主题专业度。
(2)用户兴趣模型 分别建立用户—知识兴趣模型和用户—主题兴趣模型,以挖掘用户对浏览过的知识条目和相应知识主题的偏好,前者用于构建初始评分矩阵,后者用于实施多样性策略。
(3)用户—主题专业度 利用用户群浏览行为数据计算知识文档质量,并进一步根据用户创建和修改行为数据以及知识主题社区划分结果计算用户对相应知识主题的专业度,用于改进传统UCF方法。
(4)主题多样性知识推荐 首先利用用户—主题专业度改进传统UCF方法,并为目标用户查找近邻用户,进而根据近邻用户预测初始评分矩阵中的缺失评分,然后定义知识对于目标用户的情境可用性,并同时考虑用户—主题兴趣模型,实施情境感知多样性后过滤推荐策略,对初始预测评分进行重新打分排序,进而为目标用户进行Top-N推荐。
知识推荐部分(2.5节)利用模型层对知识的表征和用户的建模进行推荐。基于输入的目标用户及其浏览行为序列数据,首先考虑用户—主题专业度为目标用户查找近邻用户,然后利用UCF方法对目标用户的缺失评分数据进行预测,最后根据用户—主题兴趣模型以及情境信息实施后过滤多样性推荐策略,为目标用户输出具有主题多样性的知识推荐列表。
2.2 知识主题社区
本文旨在有针对性地提升知识推荐列表的主题多样性。因此,本节首先构建知识网络,然后利用社区发现算法将知识网络划分为多个知识主题社区。
2.2.1 知识网络构建
在知识网络中,节点表示知识条目,边和权值表示知识条目间的关联关系及其关联度大小。知识条目间的关联关系包括共享相似的工程概念(即内容相似度)、在相似的情况下被相似的工程师重用(即情境相似度)、解决相关的工程问题(即面向问题解决的相关性)等。为便于计算分析,本文首先分别计算这3种关联关系权重,再综合计算知识条目间的总体关联度[26]。
(1)知识内容相似度计算。计算知识内容相似度之前,需要对知识进行表示。本文引入向量空间模型,将知识内容表示为一系列关键词权重二元组形式。首先分别对每个知识条目进行预处理,包括分词、去除停用词、词性标注、关键词提取、基于同义词词典的关键词融合等操作,然后使用TF-IDF算法计算关键词权重,即可将知识条目I表示为
I={(k1,w1),(k2,w2),…,(kn,wn)}。
(1)
式中wi为关键词ki在知识条目I中的TF-IDF值,
(2)
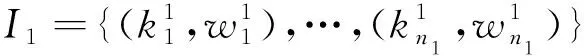
(3)
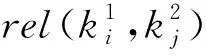
(4)
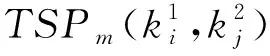
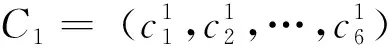
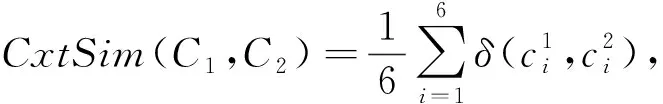
(5)
(3)知识任务相似度计算。知识任务相似度指两条知识条目能够解决相关工程问题的概率。用户在解决工程问题时,需要浏览并参考KMS中的知识条目。由于用户短期内针对相同或相似的工程问题总是会连续浏览较为相关的知识条目,利用用户群浏览行为序列数据可以挖掘知识任务相似度。首先利用表2中的信息将每个用户的浏览行为序列数据表示为向量的形式:
Rb(Ui)={(I,ΔT)1st,(I,ΔT)2nd,…,(I,ΔT)nth}。
(6)
式中包含了用户Ui的所有浏览记录。基于所有用户的浏览行为序列数据即可计算I1和I2的知识任务相似度:
TaskSim(I1,I2)=
(7)
式中:U表示所有用户集合;I1↔I2表示在用户浏览序列数据中知识条目I1和I2相邻出现;|I1|和|I2|分别表示I1和I2的文本长度,用以消除文本长度对浏览时长的影响。
综上所述,知识条目I1和I2的关联度
Rel(I1,I2)=TextSim(I1,I2)×
CxtSim(CI1,CI2)×TaskSim(I1,I2)。
(8)
根据式(8)计算所有知识条目间的关联度,即可构建知识相关性网络G=(V,E),其中:结点V表示所有知识条目,带权边E表示知识条目间的关联度。
2.2.2 知识主题社区划分
在知识网络G中,面向相关工程问题的知识条目间关联度较大,联系也会较为紧密,本文利用Louvain算法[27]将知识网络划分为多个面向工程领域的知识主题社区。Louvain算法是基于图的社区发现算法,具有快速、准确的优点,被认为是最好的社区发现算法之一。该算法基于模块度划分社区,即算法的优化目标为最大化整个网络图结构的模块度,根据本文知识网络的特点,模块度的定义如下:
Aij=Rel(Ii,Ij),
ki=∑Ij∈GRel(Ii,Ij),kj=∑Ii∈GRel(Ii,Ij),
m=∑Rel(Ii,Ij),
(9)
式中:Aij为图中结点Ii和Ij之间边的权重;ki和kj分别表示图中所有与Ii和Ij相连的边的权重之和;m为图中所有边的权重之和;TPI表示知识条目I所属的主题。根据算法的运行结果,最终可以将知识网络图G中的所有知识条目结点划分为n类知识主题,即TP={TP1st,TP2nd,…,TPnth}。
2.3 用户兴趣模型
传统推荐算法利用显性用户行为数据表示用户兴趣。在电商推荐中,可以根据用户是否购买或收藏构建0-1用户评分矩阵;在电影/音乐推荐中,也可以利用用户对项目的评分数据(如1~5星)构建用户评分矩阵。然而,企业KMS中用户评价系统的缺失导致无法获取显性用户评分数据。考虑到企业KMS可以收集隐性用户行为数据(如表2),且隐性用户行为数据能够反映短期内用户的真实兴趣偏好,避免显性用户评分中蓄意打高/低分的问题,本文利用表2中的用户浏览行为数据构建用户兴趣模型,包括用户对历史浏览的知识条目的偏好和用户对不同知识主题的偏好。
2.3.1 用户—知识兴趣模型
用户Ui的浏览行为序列数据如式(6)所示,Rb(Ui)中包含该用户所有n次浏览记录。然而,用户的兴趣随着时间不断变化,过早的浏览行为通常与用户当前兴趣偏好相异,因此本文取Rb(Ui)中最近的L次浏览行为数据构建用户—知识兴趣模型如下:
(10)
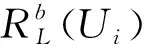
2.3.2 用户—主题兴趣模型
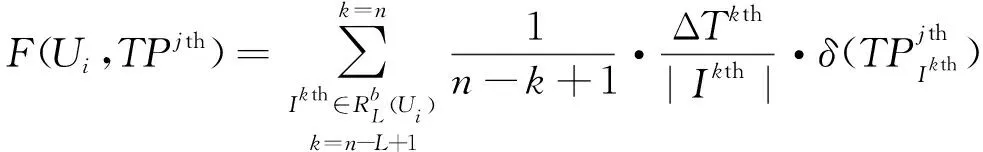
(11)
2.4 用户—主题专业度
不同专业与工作背景的用户对不同知识主题的专业度不同,选取对相关主题专业度高的用户作为近邻用户,能够提升推荐效果。本文根据用户的创建和修改行为计算用户对各个主题的专业度,基于表2,分别利用式(12)和式(13)表示用户Ui的创建和修改行为序列数据:
Rc(Ui)={(I,ΔT)1st,(I,ΔT)2nd,…,(I,ΔT)n1th} ,
(12)
Rr(Ui)={(I,ΔT)1st,(I,ΔT)2nd,…,(I,ΔT)n2th}。
(13)
首先将Rc(Ui)和Rr(Ui)中所有知识条目表示为如式(1)所示的词向量形式,然后将这些词向量合并,如式(14)所示,用以表示用户Ui的专业领域。
UP(Ui)={(k1,w1),(k2,w2),…,(kn3,wn3)}。
(14)
考虑到用户Ui参与创建或修改的知识条目I的质量更能反映Ui对I的专业度,因此本文定义知识条目I的质量q(I)为用户群对I的平均相对兴趣评分,并利用式(15)计算。
q(I)=
(15)
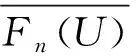
(16)
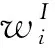
(17)
式中:UP(Ui)表示用户专业领域的词向量,如式(14)所示;TextSim(UP(Ui),I)为两个词向量的相似度,由式(3)计算;|TPjth|为主题TPjth中包含的知识条目数量。
2.5 主题多样性知识推荐
本文结合改进的基于用户的协同过滤方法(UCF)和后过滤重排序策略进行推荐。首先选取与目标用户Ui相似度最高的Top-K个近邻用户,然后利用UCF对Ui的缺失评分进行预测,最后采取后过滤多样性推荐策略完成推荐。
2.5.1 考虑用户—主题专业度的近邻用户查找
近邻用户指的是与目标用户有相似知识偏好的用户,在本文中,具有相似行为的用户即为近邻用户。本文用户行为数据中包含创建、修改、浏览3类行为,用户—主题专业度能够反映创建/修改行为信息,而用户—知识兴趣模型(即用户评分)能够反映用户浏览行为信息。实际在UCF中,用户—主题专业度能够衡量用户评分的参考价值,即用户的可信度,因此,应当在计算目标用户Ui与其他用户U的相似度时考虑用户—主题专业度,如式(18)所示。
(18)
式中:TPI为知识条目I所属知识主题;UserSim(Ui,U)为用户U对于目标用户Ui的相似度,UserSim(Ui,U)≠UserSim(U,Ui)。
2.5.2 基于近邻用户的评分矩阵预填充
利用式(10)计算部分评分数据,进而构建用户—知识评分矩阵,如式(19)所示:
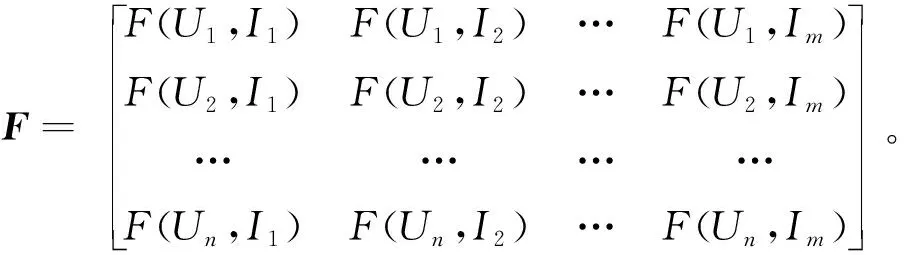
(19)
由于企业KMS中知识数量远大于用户数量,导致评分矩阵F极其稀疏,针对缺失的评分数据F*(Ui,Ij),采用式(20)进行预测:

(20)
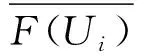
2.5.3 多样性推荐策略
本文运用后过滤策略,对2.5.2节中所有预测评分进行重新打分排序,进而完成主题多样性知识推荐,如式(21)所示。
FDiv(Ui,Ij)=F*(Ui,Ij)·KCE
(21)
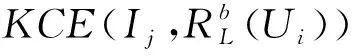
3 实验
3.1 实验背景与数据集
为验证本文方法在工程知识推荐中的效果,本文以课题组与某船厂的合作项目成果“舾装智能化设计知识库管理系统”(即KMS)为例进行了实例研究。船舶设计领域绝大部分工作都极其依赖于相关知识的支撑[23],因此知识供应质量直接影响设计任务的进度。该船厂的KMS系统中集成了对企业知识库中各类知识的管理,并面向相关用户提供查询、共享等知识服务,以辅助用户设计任务,但由于技术条件限制,已有KMS系统出现了两个主要问题:①KMS中知识数量众多,当用户遇到陌生领域问题时,想要检索到所需知识较为困难;②船舶设计任务复杂,通常需要参考多种知识,即用户有多样性的知识需求,而由于用户自身知识结构限制,通常无法通过检索获取到所有相关知识条目[26]。这些问题导致企业知识重用效率低下,严重阻碍了企业知识管理的发展与企业知识资产的转化。
针对以上问题,本文将TDKR方法应用于KMS中,主动挖掘目标用户兴趣,并为其推送合适的知识条目,以期更好地满足用户多样性的知识需求。对于系统当前用户,KMS利用TDKR方法为其生成相应的推荐列表,该用户可以从推荐列表中选择所需知识条目点击浏览,若没有所需知识条目,则继续搜索浏览其他知识条目。用户的行为数据会被不断存入KMS后台数据库,以便及时更新TDKR方法模型。
为评估TDKR方法的推荐性能,从该船厂KMS系统中获取379条知识条目内容和2 867条用户行为数据(包括163条创建记录、84条修改记录和2 620条浏览记录)作为本实验所用数据,行为数据来自该船厂某舾装设计团队中的13名设计人员对这379条知识条目的操作记录,部分数据如表2所示。本实验中,相应算法在Core-i5、16RAM的MacOS-10.15计算机配置环境下,使用Python-3.7编码。
3.2 评价指标
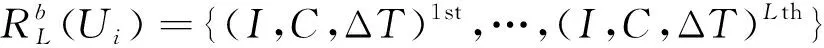
(22)
(23)
式中:|U|为集合U中用户人数,|Rec(Ui)|和|Real(Ui)|分别为两个列表中知识条目的数量。本文多样性是指单个推荐列表中知识条目间的差异程度。若用div(Rec(Ui))表示单个推荐列表Rec(Ui)的多样性,则TDKR方法在单次实验中的多样性Div用式(24)计算[9]。
(24)
式(24)采用所有用户推荐列表的多样性均值作为单次实验的多样性指标,其中TextSim(I1,I2)为知识条目I1和I2的相似度,由式(3)计算。式(3)利用自然语言处理(Natural Language Processing, NLP)技术分析计算了知识条目间关键词语义级别的内容相似度,使式(24)更适用于面向工程领域问题解决的知识推荐。为消除实验结果随机性因素的影响,本文采用5次实验结果的平均值作为评估标准,并保证每次实验所用数据不同。
3.3 TDKR方法应用示例
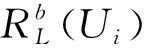
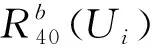
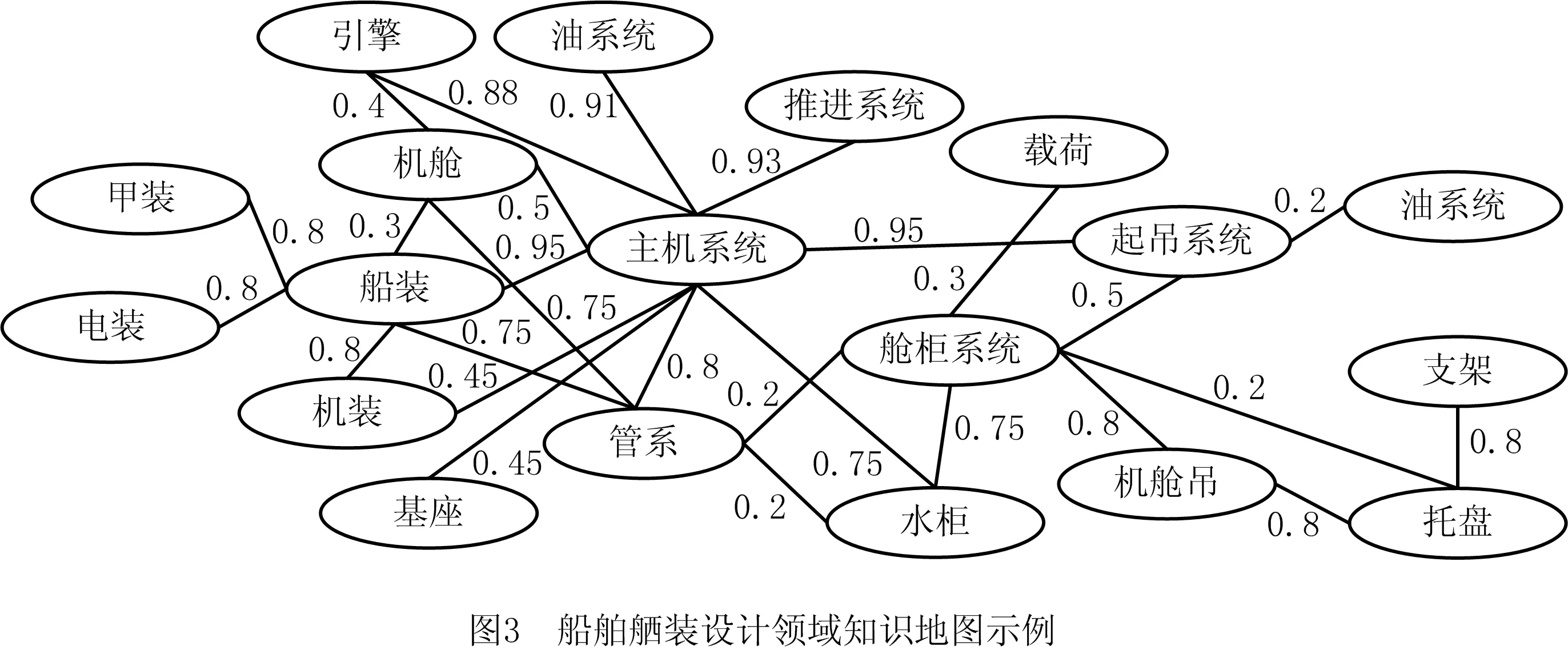
(1)知识主题社区划分 根据2.2.1节方法构建知识网络。在利用公式表示知识时,为方便计算,仅保留TF-IDF权重最高的前30个关键词,知识地图根据文献[23]构建,其中包含从379条知识条目中提取的65个领域概念和230条语义路径。基于2.2.2节方法将知识网络划分为30个面向舾装设计领域的知识主题社区(如表3),表3中“主题关键词”为人工选出以供展示,非权重最高的词。

表3 船舶舾装设计领域知识主题社区
(2)用户兴趣模型构建 根据2.3.1节方法构建用户—知识兴趣模型,计算每名用户对近期40条浏览记录中的知识条目的评分并归一化处理,进而初步构建用户评分矩阵F13×379,由于存在重复浏览现象,F13×379中包含目标用户U3的32个评分数据。根据2.3.2节方法构建用户—主题兴趣模型,计算U3对每个知识主题的偏好并归一化处理,如表4所示。

表4 目标用户—主题偏好评分
(3)用户—主题专业度计算 根据2.4节方法,基于每位用户创建、修改行为数据计算用户对相应知识主题的专业度并归一化处理,如表5所示。在利用式(14)表示用户时,同样保留TF-IDF值最高的30个词。表5中加粗显示的为该主题拥有的最高专业度。
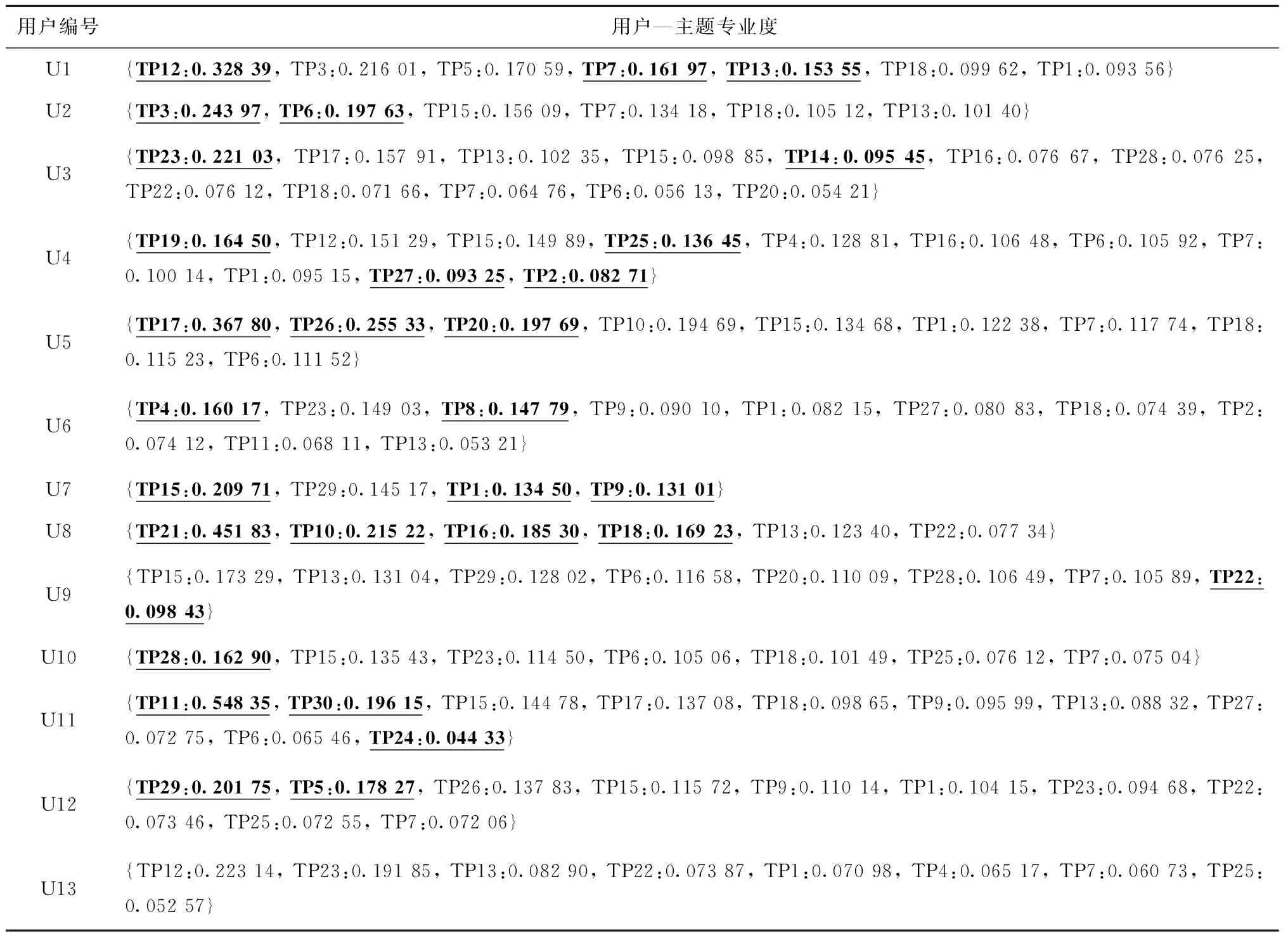
表5 用户—主题专业度
(4)主题多样性知识推荐 基于式(18),结合表5用户—主题专业度查找目标用户U3的6个近邻用户,根据用户相似度排序依次为U1>U13>U9>U4>U11>U6。结合表4可知,近邻用户对目标用户U3偏好的主题普遍具有较高专业度,如U1对TP7和TP13、U9对TP22、U11对TP11和TP24等都具有最高专业度。根据式(20)预测目标用户U3的缺失评分数据,若U3为对知识条目I所在主题TPI专业度最高的用户,则将U3现有评分最小值作为U3对I的评分,否则根据6个近邻用户预测评分,结果算得143个U3的缺失评分数据。基于式(21),结合表4对143个预测评分进行后过滤重排序,将最终评分最高的5条知识推送给目标用户U3。如表6所示为推荐列表以及用户真实浏览的8条知识。
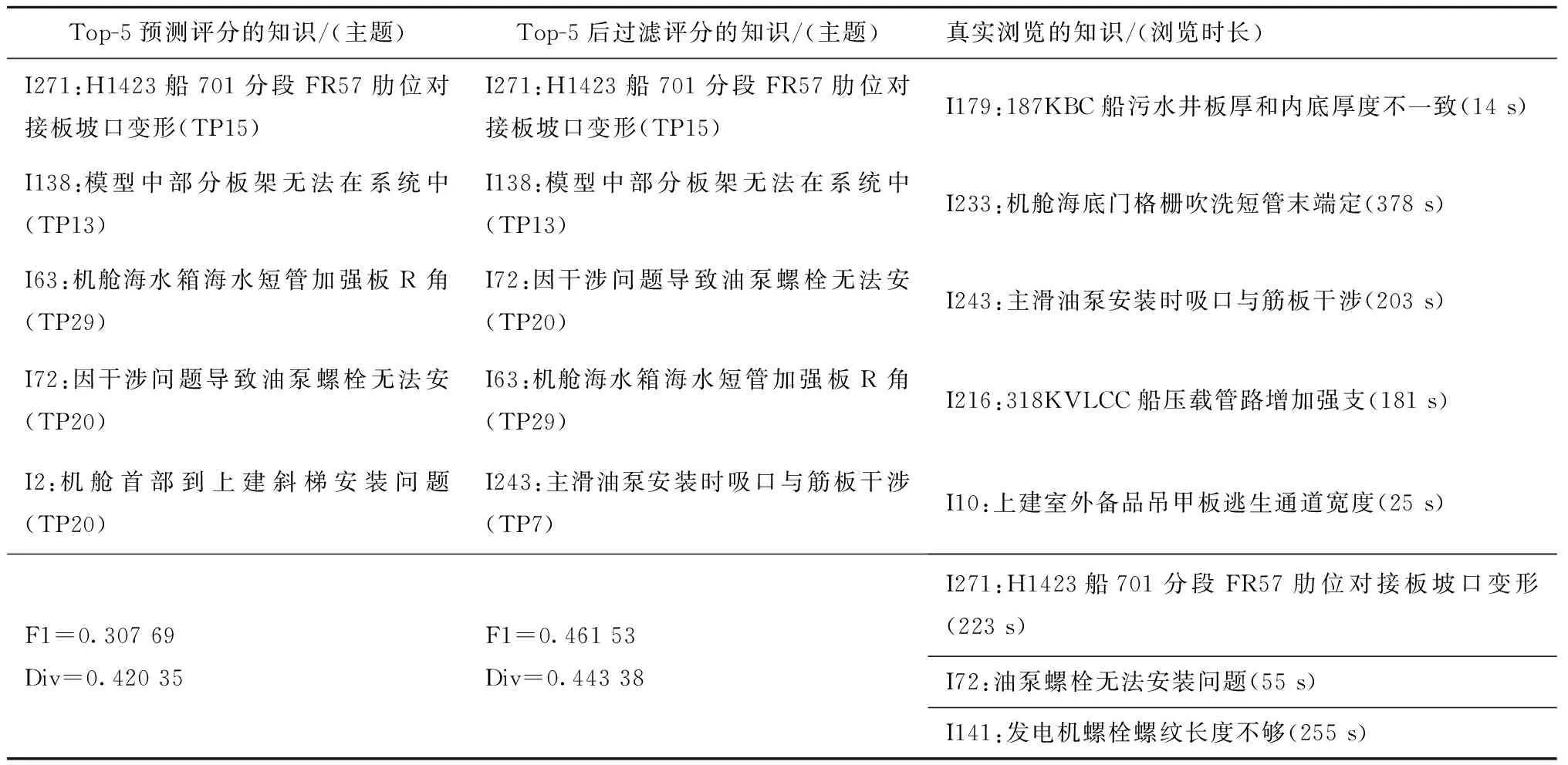
表6 目标用户的推荐列表及真实浏览列表
由表6可知,U3真实浏览的8个知识条目中,I179与I10的浏览时长较短,根据其内容可知,这两条知识与机舱布置相关性较小,而其余6条知识都与机舱内设备安装、布局相关,即目标用户真实浏览行为与其任务目标一致。对于推荐结果,未采用后过滤时,命中I271和I72,F1和Div分别为0.31和0.42,又经该用户确认,I63对机舱布置图设计任务也具有参考价值,而I138和I2的参考价值不高,即推荐列表中有3条知识对当前工程任务有参考价值,可以认为本文在预测评分时考虑用户专业度能够提升评分预测准确度。采用后过滤策略后,与之前的推荐结果相比,调换了I63和I72的位置,并将I2替换为I243,命中三条知识,F1和Div分别提升至0.46和0.44。I243与主滑油泵安装相关,且属于TP7(目标用户最感兴趣的主题之一,如表4),表明本文同时考虑知识情境可用性和用户—主题兴趣模型的后过滤策略能够在保证推荐结果准确度的前提下,有针对性地提升推荐结果的主题多样性。
3.4 对比实验
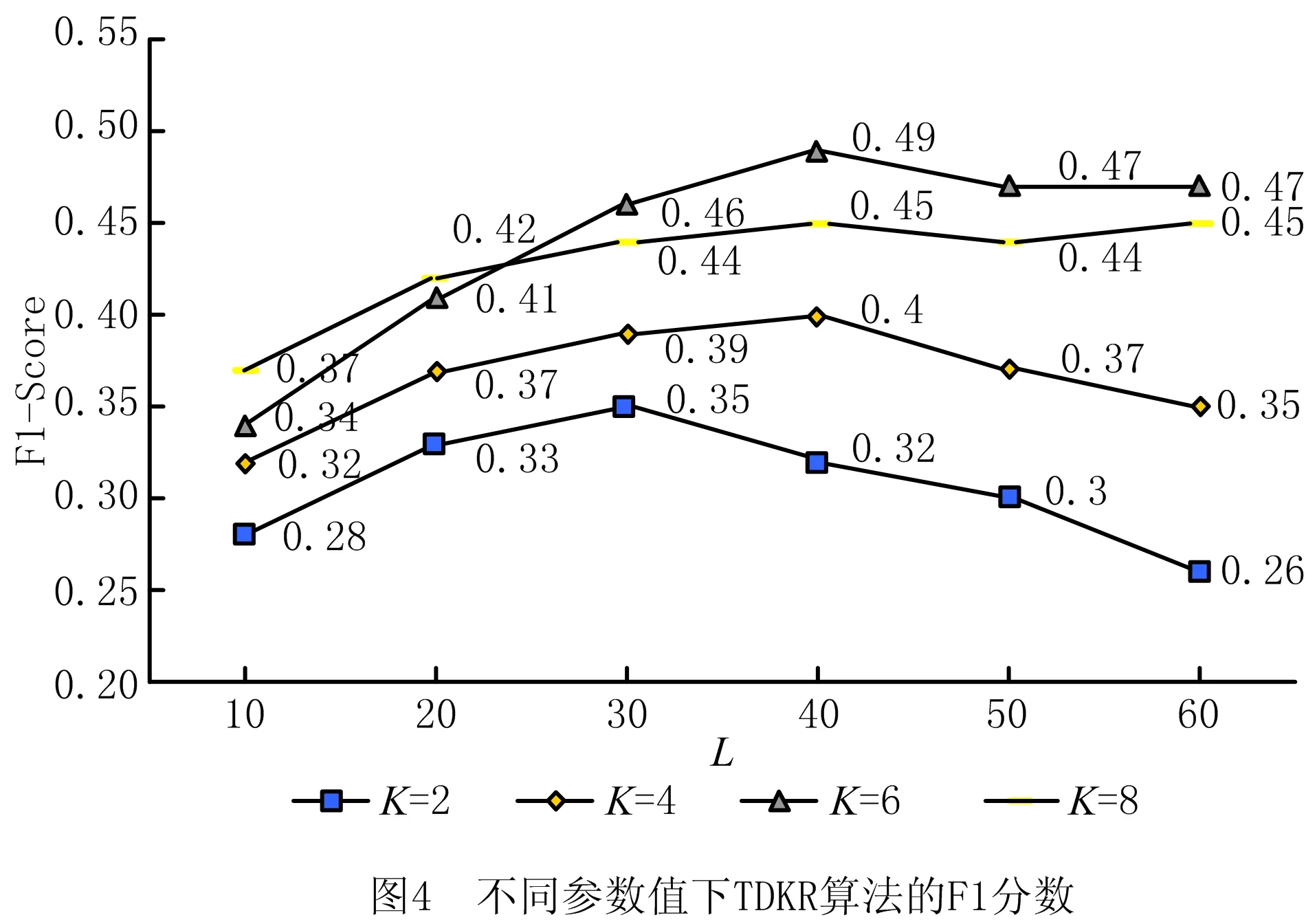
相较于传统推荐算法,本文TDKR方法主要有3点改进之处,即在2.5.1节查找近邻用户时考虑用户—主题专业度(User-Topic-Professionalism, UTP),以及在2.5.3节多样性知识推荐中同时考虑了知识的情境可用性(Knowledge-Context-based-Effectiveness, KCE)和用户—主题兴趣模型(User-Topic-Interest, UTI)。对此,设计以下对比算法:①基于用户的协同过滤算法(UCF);②在TDKR基础上去除第一点改进(TDKR without UTP);③在TDKR基础上去除第二点改进(TDKR w/o KCE);④在TDKR基础上去除第3点改进(TDKR w/o UTI)。TDKR方法与4种对比算法的推荐性能表现如图5所示。
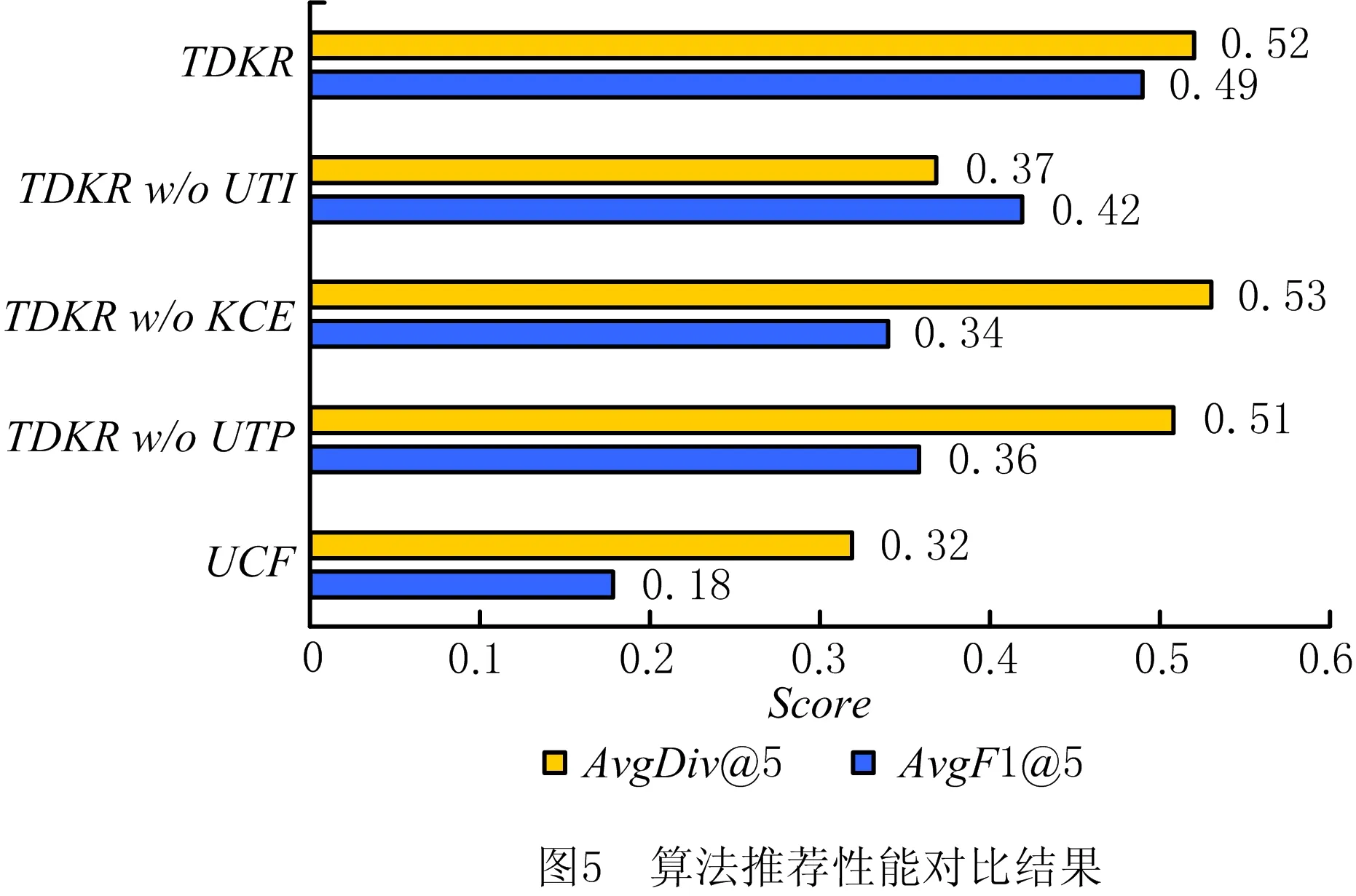
由于UCF方法未进行任何优化,算法准确度极差,F1仅为0.18,而由于协同过滤的推荐结果具有随机性,多样性Div的值远高于其F1值,达到0.32。TDKR方法采用了上述3种改进方式,具有很高准确度,且能有针对性地提升推荐结果的主题多样性,F1和Div分别达到了0.49和0.52。对于TDKR w/o UTP,由于其采用了KCE和UTI两种改进,能够提升知识推荐结果的情境可用性和主题多样性,F1和Div分别提升到了0.36和0.51,但相比TDKR去除了UTP改进,即在查找近邻用户时忽略了用户—主题专业度,导致了其基于近邻用户的协同过滤算法的评分预测值可信度降低,因此F1值低于TDKR;对于TDKR w/o KCE,由于在后过滤多样性推荐时未考虑知识的情境可用性,导致准确度相比于TDKR降至0.34;对于TDKR w/o UTI,F1和Div分别为0.42和0.37,相较于TDKR都下降较多,这是由于其未采用多样性策略,推荐结果无法满足用户多样性的知识需求,证明本文基于用户—主题兴趣模型的多样性策略能够帮助用户发掘面向工程领域问题解决的知识关联关系,有针对性地提升推荐结果的主题多样性,更好地满足用户多样性的求,且对于KMS系统来说,也增加了冷门知识被推荐的概率,缓解了仅推荐流行项目的问题。
综上所述,TDKR方法能够较好地满足用户在特定情境下对知识推荐结果的准确度和多样性的要求,在工程知识推荐任务中具有良好表现。
4 结束语
为了更好地满足KMS用户多样性的知识需求,本文提出一种能够应用于现有KMS中的主题多样性知识推荐方法(TDKR)。该方法考虑了知识应用情境与用户—主题专业度,并基于划分的知识主题社区和用户—主题兴趣模型实施多样性推荐策略,能够有针对性地提升知识推荐列表的主题多样性,以更智能的方式协助KMS用户完成工程任务。本文贡献总结如下:
(1)构建知识网络并划分知识主题社区 利用关键词权重向量与知识地图计算知识内容相似度,归纳知识应用情境并计算相似度,定义并基于用户群浏览行为序列数据计算知识任务相似度,进而构建知识相关性网络,最后再利用Louvain算法将知识相关性网络划分为多个知识主题社区。由于知识相关性网络构建方法利用了工程领域丰富的语义信息和用户群的行为信息,相比于其他聚类算法,本文主题划分结果更符合领域特征。
(2)构建用户—主题兴趣模型并计算用户—主题专业度 在划分好的知识主题社区基础上,首先利用用户浏览行为序列数据建立用户—主题兴趣模型,用于实施多样性策略;然后利用用户的创建和修改行为序列数据计算用户—主题专业度,用于改进近邻用户查找方法,以使基于近邻用户的协同过滤方法(UCF)的预测值更为准确可靠。
(3)提出考虑知识情境可用性和用户—主题兴趣的多样性推荐策略 在多样性推荐策略中,同时考虑知识情境可用性和用户—主题兴趣模型。对比实验结果表明,知识情境可用性可以保证推荐结果的准确度和可用性,而用户—主题兴趣模型能够帮助KMS用户发掘面向问题解决的知识关联性,有针对性地提升知识推荐列表的主题多样性,进而更好地满足用户多样性的知识需求。
高质量的知识推荐不仅依赖于先进的知识推荐算法,还需要有大量优质的知识源信息以及相应的知识组织与表征技术等的支持,而作为一种具有极强的表达能力和建模灵活性的语义网络,知识图谱能够以更合理、更智能的方式进行知识表征与链接,在推荐系统领域具有广泛的应用前景。因此,可以考虑结合知识图谱技术,并从以下3个方面扩展本文研究内容:①可以利用知识图谱对工程问题、任务、情境、解决方案等内容进行智能化表征,进而实现更为优质的场景化推荐和任务型推荐;②可以利用知识图谱连接不同领域的知识,进而实现跨领域推荐,尽可能为用户提供更多的解决方案;③知识图谱中包含的丰富语义信息极大提升了推荐结果的可解释性,可以据此获取用户的行为反馈信息,从而实现数据模型的及时更新,更好地满足用户需求。
