基于有效距离的低秩表示
2021-02-22陶体伟刘明霞王明亮王琳琳杨德运
陶体伟,刘明霞,王明亮,王琳琳,杨德运,张 强
1.桂林理工大学 信息与工程学院,广西 桂林 541006
2.泰山学院 信息科学技术学院,山东 泰安 271021
3.南京航空航天大学 计算机科学与技术学院,南京 211106
4.泰山学院 数学与统计学院,山东 泰安 271021
5.大连理工大学 计算机科学与技术学院,辽宁 大连 116000
近年,低秩表示(Low-Rank Representation,LRR)作为一种能有效挖掘数据本质结构的方法,在机器学习领域引起了人们的关注[1],特别是在图像处理领域涉及低秩矩阵估计及低秩约束的问题是近期研究的热点。低秩表示在图像聚类、图像去噪、显著性检测、视频前景背景分离等领域有着广泛的应用。低秩方法是鲁棒性主成分分析方法(Robust Principal Component Analysis,RPCA)的一种推广形式的模型。RPCA 本质上也是寻找数据在低维空间上的最佳投影问题,并且能从噪声污染的数据中恢复其本质上的低秩数据。RPCA 模型隐式地假设原始数据的潜在结构为一个单独的低秩线性子空间,也就是说RPCA模型只能提取一个主子空间,即所有纯净数据所张成的子空间。但是在现实应用中,很多高维观测数据可近似来自于一个或者多个低维的线性独立子空间,且子空间的类别数以及每个数据点属于哪个子空间也是未知的。在这种情况下,如果只是简单地使用RPCA,得到的低秩矩阵就不能准确地抓住数据的子空间结构。
为了能够更好地表示数据的多个低维子空间结构,使RPCA 模型更具广义性,Liu 等人提出了低秩表示模型。其通过约束表示系数是低秩的,将子空间分割与噪声分离纳入一个框架中处理,这和RPCA 模型相比,可以更好地处理多个低维子空间数据。
如果一个高维空间中的所有数据实际上都是几个线性子空间的并集,则利用LRR 能有效地揭示数据中本质的低维结构。但在实际应用中,许多数据具有非线性几何结构,如面部图像就是在高维环境空间中的非线性子空间中采样的。因此,在这种情况下,LRR 方法可能无法发现数据的内在几何结构,在特征提取过程中数据之间的局部性和相似性信息可能会丢失[2]。
为了保留嵌入高维空间的局部几何结构,许多研究人员已经考虑了流形学习(非线性特征提取)方法,如局部线性嵌入(Locally Linear Embedding,LLE)[3]、局部保持投影(Locality Preserving Projections,LPP)[4]、邻域保留嵌入(Neighborhood Preserving Embedding,NPE)[5]和拉普拉斯特征映射(Laplacian Eigenmaps,LE)[6]。所有这些算法都受到局部不变性思想的启发,即两个数据点在数据分布的内在流形中是接近的,那么这两个点在新空间中的表示也会彼此接近。利用局部不变性思想,Zheng 等人[7]提出一种图正则化低秩模型,它基于在学习过程中获得的最相关的特征来构造图,因此该图受到无关和严重损坏的特征的影响较小,并且更具区分性。其中图拉普拉斯算子是基于特征学习过程迭代学习的,这与广泛使用的非线性技术有着明显的不同,后者通过独立的预处理步骤构造核矩阵或图拉普拉斯算子作为输入。Zhu等人[8]结合LRR技术,提出了一种新的低秩图正则化结构稀疏回归方法。该方法通过低秩约束将特征嵌入到遗传数据和脑影像数据中,并通过稀疏有向图和结构稀疏正则化对遗传数据进行变量选择,可有效提高阿尔兹海默症的诊断精度。Yang 等人[9]提出了非负对偶图正则化潜在低秩表示,引入双图正则化约束有效保留原始数据的内部空间结构,并在分割子空间时提高最终聚类的准确性。但是,这些方法都是基于欧氏距离来度量,通过构建子图来描述数据间的相似性结构,缺乏对数据全局结构信息的把握。最近的研究表明,概率激励距离测量(称为有效距离)可以对数据的全局结构信息进行建模。欧几里德距离一直被用来测量不同样本之间的相似性[3]。但是,数据底层的动态结构和内部关系不能完全用连通矩阵来表示,即在投影到新的子空间之前,相似矩阵中描述的信息已经失去了一些潜在的数据结构。在概率解释的驱动下,Brockmann等人提出了有效距离来发现数据间的结构相似性。结果表明,有效距离比欧几里德距离更能表现数据的全局关系信息[10]。
受上述工作的启发,本文提出了一种基于有效距离的低秩表示模型(Effective Distance Based Low-Rank Representation,EDLRR),并应用于图像分类。利用稀疏表示方法计算有效距离,可以更好地把握数据的全局信息,并使用最近邻图表示数据之间的相似性来构建数据的局部几何结构。然后将图结构合并到寻找最低秩表示矩阵的优化问题中,同时将表示系数约束为非负,以便学习局部流形结构,这也使模型在物理上更具可解释性。
1 相关工作
1.1 有效距离
传统的相似度度量方法通常基于欧氏距离进行,然而欧氏距离仅能体现个体数值特征的绝对差异(即从数值大小的差异),无法对数据中的动态特性(比如时间序列数据的动态变化)和全局特性进行建模。然而,现实世界中两个事物之间的相似性不仅仅取决于几何坐标中的欧氏距离或者地理距离,因此在设计相似性度量准则时需要考虑样本自身的动态特性以及样本和样本之间的全局特性。
Brockmann 等人在研究复杂网络驱动对传染病传播过程的影响时,提出了有效距离的概念,并利用空中运输乘客的数据来构建各个大城市之间的有效距离,以此成功挖掘出病菌传播源并预测出病菌的传播状态[10]。文献[11]提出一种基于稀疏表示的方法来计算有效距离,并提出了基于有效距离的特征选择方法。实验结果表明,基于有效距离的相似度量方法在分类和聚类任务中都取得了比欧氏距离更好的性能。
有效距离的直观示意图如图1所示。在图1(a)中,存在具有4 个节点的图形,边的权重由箭头来量化表示。在图1(b)中,将节点m移动到节点n处的随机游走概率表示为P(n|m),该概率的大小由线宽表示。例如,节点A移动到节点B处的随机游走概率P(B|A)为1/2,其中数字2 表示节点A与其他节点的连接数。在图1(b),从D开始随机游走前往C的概率和从A开始随机游走前往B的概率较大,即P(B|A)=1/2,P(C|D)=1,反之则较小。在有效距离的定义中,小概率P(n|m)表示从点m到点n的有效距离大,大概率P(n|m)表示从点m到点n的有效距离小。与传统的欧式距离相比,有效距离综合考虑数据的动态结构信息以及样本与其他所有样本间的关系,因此有助于揭示数据的隐藏结构并提高模型的学习性能。

图1 有效距离的图示说明
1.2 LRR模型
LRR 可以看作是RPAC 的一种推广形式[12]。LRR模型[1]基于这样的假设:相关数据存在于一个低维线性子空间中。给定一组数据样本,LRR旨在找到所有数据中本质的低维结构。这和RPCA模型相比,可以更好地处理多子空间数据。
考虑数据Y是从由给出的多个子空间的并集中提取的情况,其中S1,S2,…,Sk是低维子空间,则给定数据Y的LRR定义为以下等级最小化问题:
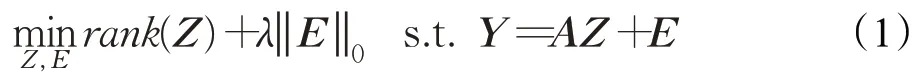
其中,rank(Z)为给定数据Y的最低秩表示;‖ · ‖0表示E中非零元素的个数,目的是为了拟合噪声;A为线性张成数据空间的字典;λ表示权重因子。
由于秩函数和l0范数的离散性质很难解决上述优化问题(1),它们都属于NP 难问题,因此提出上述优化问题的凸松弛,即将优化问题中秩函数和l0范数放松为各自的凸包形式(矩阵核范数和l1范数),进而再继续求解目标的凸优化问题,这就是低秩表示模型:
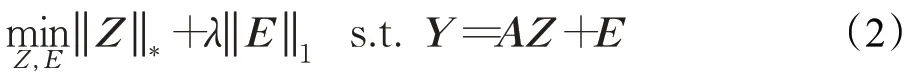
其中,‖Z‖*表示矩阵的核范数,即对Z进行奇异值分解所得到的所有奇异值的和。‖E‖1表示E的稀疏矩阵,即矩阵E的所有元素的绝对值之和。
文献[13]提出了基于非负低秩稀疏图(NNLRS)的方法,其中心思想是在半监督学习环境下构造一个好的图来发现内在的数据结构,用给定的数据表示建立一个非负的低秩稀疏图,图中边的权重是通过寻找非负的低秩稀疏重建系数矩阵获得的。该矩阵将每个数据样本表示为其他数据样本的线性组合,由此获取数据子空间的低维结构和数据的局部线性结构。
该方法具体模型如下:
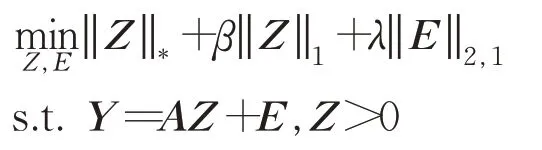
其中,‖E‖2,1是l2,1范数;参数λ用于平衡噪声的影响,使用经验值设定;l2,1范数鼓励噪声E为0。但是该方法没有考虑数据流形的问题。
文献[2]提出了非负稀疏拉普拉斯正则化LRR模型(NSHLRR),其使用基于欧氏距离的最近邻图来构建表示数据的局部结构,引入了流行正则化约束。与文献[13]不同,它采用局部线性子空间逼近非线性流形,在效果上更好一些。本文受此启发,使用基于稀疏表示的有效距离来构建数据的局部结构。
2 基于有效距离的低秩表示模型
2.1 基于稀疏表示的有效距离
稀疏表示作为信号分析领域的热点问题,其本质是从过完备字典矩阵中选择尽可能少的原子来表示信号,使学习任务得到简化,模型复杂度降低。
值得注意的是,稀疏表示方法能够有效表达数据的全局特性[14]。具体有效距离计方法如下:
给定一组训练样本X=[x1,x2,…,xn]∈Rn×d,其中n代表样本的个数,d代表特征的维数。根据稀疏重构系数模型[15],将每一个样本用其他的n-1 个样本线性表示,即x=Aα+k,其中A={x1,x2,…,xi-1,xi+1,…,xn},表示一个数据矩阵包含除了第i个样本之外的所有其他样本;用W表示权重矩阵,即样本xi在稀疏表示样本xj的过程中所占的权重值,其可通过字典学习模型求解:
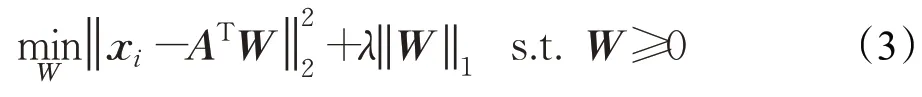
根据式(3)计算求得权重系数矩阵W,Wij表示第i个样本在第j个样本前的稀疏表示的系数。λ为正则化参数,用来约束模型稀疏性,值越小,得到的解中零元素越少,即稀疏性越小,反之则越大。
根据得到的权重系数矩阵W,对其进行归一化:

Qij越大,说明xi在稀疏重建xj时,所占的权重越大,则xi与xj之间的相似度越大,即有效距离越小。
有效距离计算如下:

因为0 ≤Qij≤1,所以lnQij≤0,显然EDij≥1。
2.2 EDLRR算法实现及优化
在流形学习中,非线性流形是与线性子空间局部近似的,假设Y=[y1,y2,…,yn]是从底层流形M中采样,那么点和其邻点之间的关系也是线性的。因此可以通过其邻点构建与这些数据点的线性系数,来表示数据点的局部几何形状。
因此,本文首先构造拉普拉斯矩阵,包括3个步骤。
步骤1使用2.1节中稀疏表示方法计算样本之间的有效距离,构造有效距离矩阵ED∈Rn×n。
步骤2基于每个采样点σi的有效距离计算局部尺度参数。
步骤3构建相似性矩阵。矩阵中的元素定义如下:
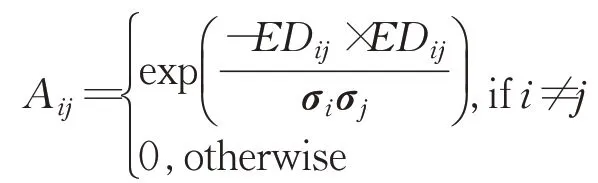
其中度矩阵被定义为D,D为对角矩阵,其对角线元素Dii对应于与Dii=∑jAij相关的所有相似性的总和。然后图拉普拉斯矩阵定义为[16]:

容易证明图拉普拉斯矩阵可以重写为min tr(ZLZT)。
考虑到稀疏表示能够更好地捕获每个数据向量的局部结构,为了在Z上引入更丰富的信息,对Z引入了稀疏性约束[17]。稀疏LRR模型可以表示为如下公式:
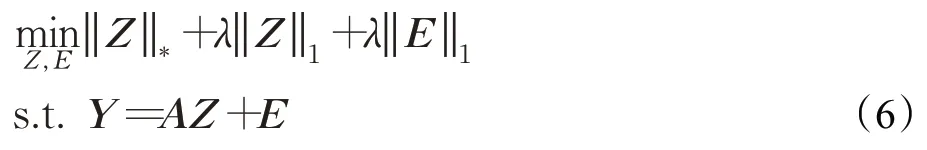
由于使用局部线性流形逼近非线性流形,因此要表示的样本最好位于局部线性流形的中心,以使之近似有效。为此,要求Z为非负数[2],即Z≥0,同时,在基于图的流形学习[3,14-15]推动下,可以将拉普拉斯正则化结合到目标函数(6)中,具体EDLRR模型如下:
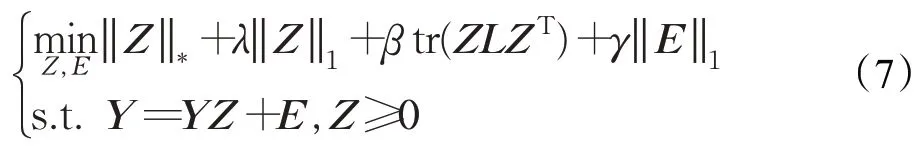
其中,L是基于有效距离的图拉普拉斯矩阵,而λ、β和γ是用于平衡正则项的惩罚参数。
本文提出的基于有效距离的LRR分类方法和LRR方法相比,在寻求低秩系数矩阵的基础上,加入了稀疏和非负性约束,并且使用有效距离度量来构建相似度矩阵,充分考虑整个数据的全局结构,不仅保留了数据点之间的局部几何结构,也更好地把握数据的隐藏结构,改善相似度量的有效性。
基于传统的交替方向法(Alternate Direction Method,ADM),Lin 等人[18]提出自适应惩罚项线性交替方法(Linearized ADM with Adaptive Penalty,LADMAP)。该方法针对ADM 算法中需要引入新的辅助变量,增加计算复杂度这一问题,采用一种新的准则在每步迭代过程中自适应地更新惩罚参数,节省了存储空间和引入辅助变量矩阵逆的运算。为了获得式(7)的最优解,使用LADMAP解决这一问题的优化问题。
首先引入一个辅助变量J,以使式(7)的目标函数可分离,因此以上优化问题可以重写如下:
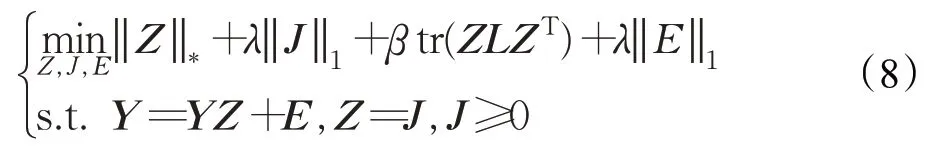
则问题(8)的增广拉格朗日函数是:

其中,M1、M2是拉格朗日乘子,μ>0 是惩罚参数,在其他变量不变的情况下,通过最小化增广拉格朗日函数交替更新变量。
(1)更新Z,通过最小化公式(9)的增广拉格朗日函数,相当于最小化以下函数:

但是它没有闭式解,本文参照LADMAP,使用如下公式表示ε1的平滑分量:
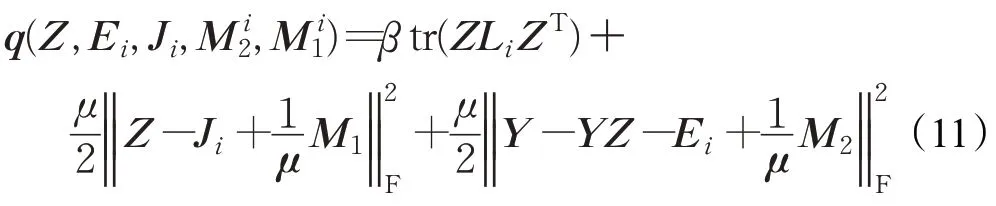
则最小化ε1可以通过解决如下问题来替代:

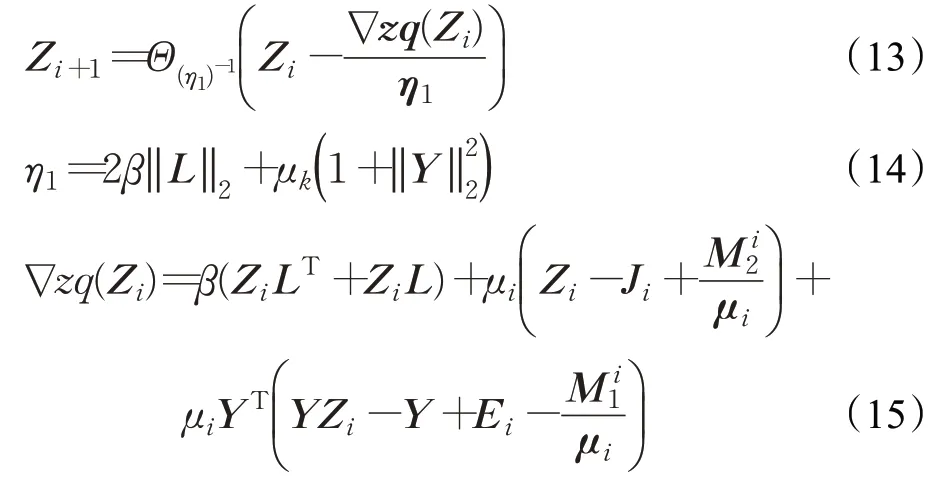
其中,Θ(η1)为奇异值算子。
(2)更新E,可以通过最小化来更新E与J:
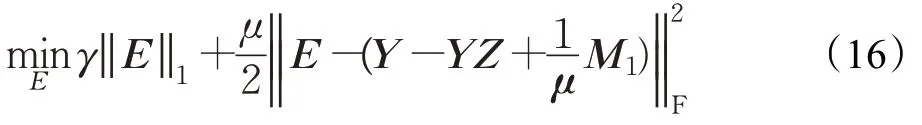
其闭式解为:
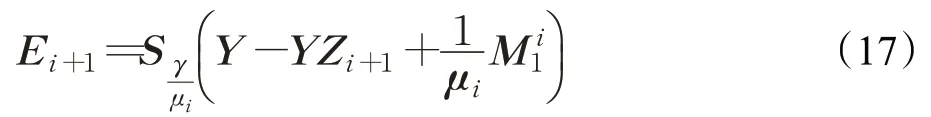
(3)更新J:
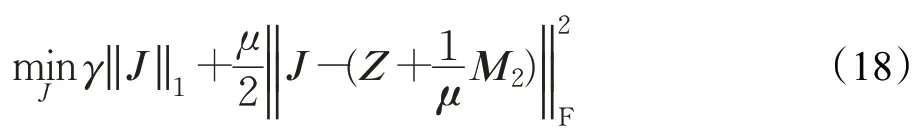
其闭式解为:

随后交替更新拉格朗日乘子,并使用LADMAP 中自适应更新策略来调整惩罚参数,使其能够迅速收敛,其总体流程如下。
算法1LADMAP对EDLRR算法的优化求解

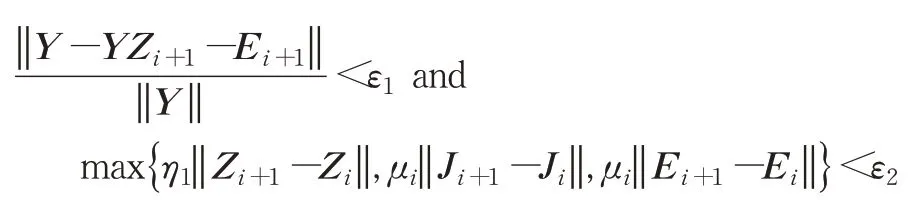
由于LADMAP 的直接应用,上述算法收敛于全局最优解。当用奇异值收缩去更新Z时,可以使用文献[18]中所描述的秩预测策略来预测Zi+1的秩R,它在迭代过程中慢慢增长,并稳定在真实数值上。此外,使用Lanczos 方法(求解大规模稀疏矩阵特征值问题最常用的方法之一)来计算每次迭代之前的一个奇异值和奇异向量,这只需要将及其转置和向量相乘,并通过连续矩阵向量相乘来有效地计算。在这样的处理下,本文算法每次迭代的复杂度仅为O(rn2),其中n是样本数,r为矩阵的秩。
3 实验及结果分析
3.1 实验设置
本文中的实验图像都经过标准化处理,实验环境为64 位 Windows 8.1 操作系统,内存16 GB,Intel®CoreTMi5-4590 CPU@3.30 GHz,并用Matlab R2014a软件编程实现。
在分类实验中,选取了3 个公开数据集CMU-PIE、USPS和UCI Zoo。
CMU-PIE 是美国卡耐基梅隆大学建立的数据库,它包括68个人的在13种姿态条件、43种光照条件和4种表情下的4万多张照片。对于这个数据库,本文采用不同姿态、光照和表情下的每人170张每张32×32 维特征的图像,共计11 560 张图片作为目标库,样例如图2(a)所示。

图2 人脸数据库和手写字体库实例
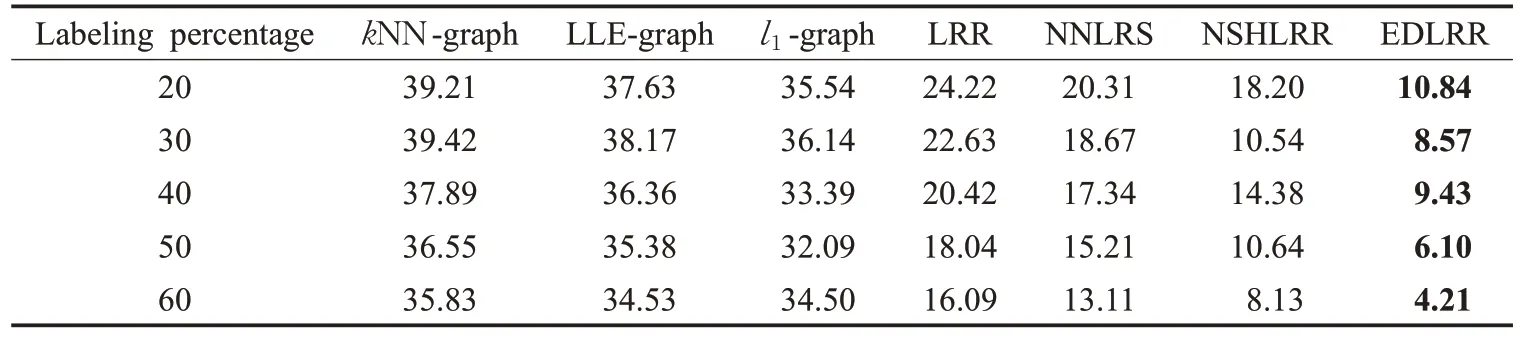
表1 不同方法在CMU-PIE人脸数据库上的分类错误率 %
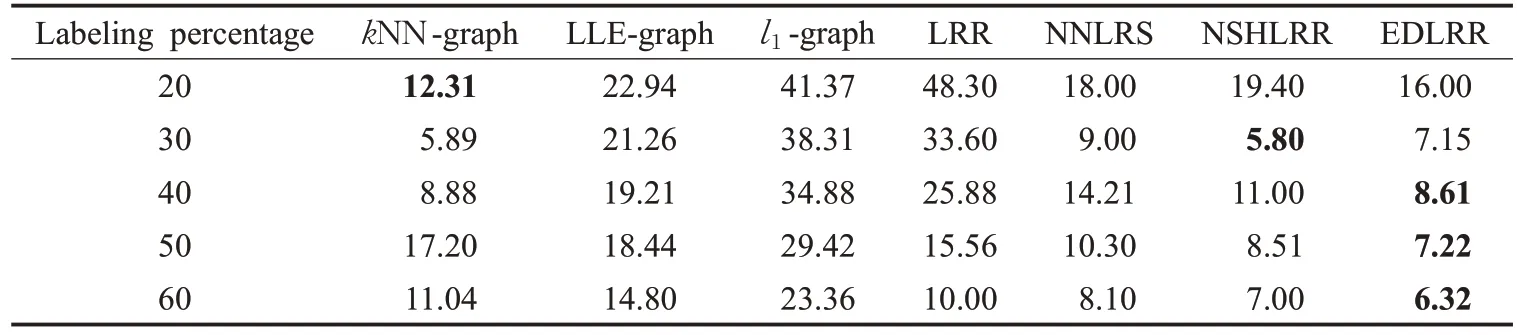
表2 不同方法在USPS数据集上的分类错误率 %
此外,本文使用了UCI机器学习数据库的Zoo数据集,其中包含了7 个类,共101 个元素,它们是线性不可分的,由16个属性来描述样本,其中15个为布尔属性值{0,1}和1 个分类属性(腿的数量),这些数据都是有标签数据[19]。
3.2 对比方法
本文采用了以下6种方法进行对比,来评估本文提出的EDLRR的有效性。
(1)基于k-最近邻的分类方法(kNN-graph):将最近邻接点的数量设置为5,在相似性度量上采用传统的欧氏距离。
(2)基于LLE图的方法[20]:构造了一个LLE图,其最近邻数设置为8。
(3)基于l1-graph[21]的方法:通过求解每个样本的最稀疏表示,使用其他样本作为字典来构造鲁棒的基准自适应图。
(4)基于LRR 的方法(LRR):相比于SR(稀疏表示),LRR可以更好地表示数据的整体结构。LRR的参数与文献[1]中的参数相同。
(5)非负低秩稀疏图(Nonnegative Low-Rank Sparse,NNLRS)[13]:该方法使用非负的低秩稀疏矩阵来构造一个图,该矩阵将每个数据点表示为其他数据点的线性组合,系数矩阵也是对称的。
(6)非负稀疏拉普拉斯正则化LRR(Non-negative Sparse Hyper-Laplace regularized LRR,NSHLRR)[2]:使用欧氏距离构建图拉普拉斯矩阵,并引入非负约束。
在实验中,本文所提模型的参数和其他对比方法的参数通过五折交叉验证的方式进行选择[22],且参数选择范围是{2-3,2-2,…,23}。具体地,首先随机把初始采样分割成5 个子样本集,1 个单独的子样本集被保留作为验证模型的数据(即test data),其他4 个子样本集用来训练(即training data)。交叉验证重复5次,每个子样本集验证1 次,平均5 次的结果得到一个评价结果。实验中,发现本文所提模型的参数 (λ,β,γ)值在 [2-1,2-3]范围内保持稳定,且当λ=8,γ=1 和β=4 时在各个数据集上都能取得较好结果。
半监督学习是使用大量的未标记数据,以及同时使用标记数据,来进行模式识别工作。在基于上述数据集分类实验中,使标记样本的百分比在20%到60%之间。为了防止产生计算误差,对每个标签的百分比算法运算20次,取平均值作为最终结果。
3.3 实验结果
表1、表2 分别给出了在CMU-PIE 人脸数据库和USPS手写数据集上的分类结果。表中的粗体数字表示相应标签百分比下的最佳值。
从这些结果中可以看出,在标签比较低的时候,传统的kNN 方法效果较好,但是在标签比增加后,本文提出的EDLRR几乎始终优于其他方法。这说明在图像分类任务中,本文方法是有效的。相对于原始的LRR 方法,本文增加的稀疏和非负的正则化约束和基于有效距离的相似矩阵使模型具备更好的分类精度。
为比较基于有效距离和欧氏距离的低秩表示方法的性能,将本文所提方法EDLRR 与3 种传统基于欧式距离的低秩表示方法(LRR,NNLRS,NSLLRR)在Zoo数据集上进行了比较。此外,还与基线方法kNN 进行比较,实验结果见表3。
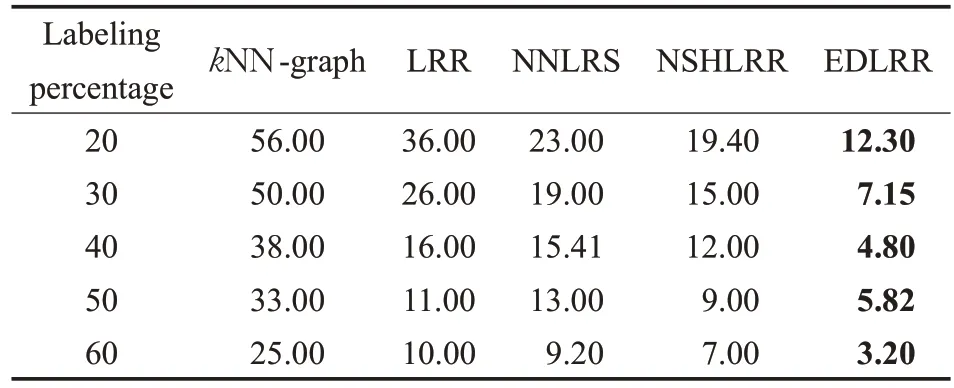
表3 不同方法在Zoo数据集上的分类错误率 %
表3 的结果表明,在3 个数据集上本文所提出的EDLRR方法一般优于其他方法。原因是基于有效距离的方法可以挖掘样本之间的全局信息,因此可以对关系复杂的数据进行更好的建模,从而提高分类性能。为验证所提方法的稳定性,以CMU-PIE 数据集标签比60%下五折分类结果为例报告了分类错误率的均值和方差,实验结果见图3。
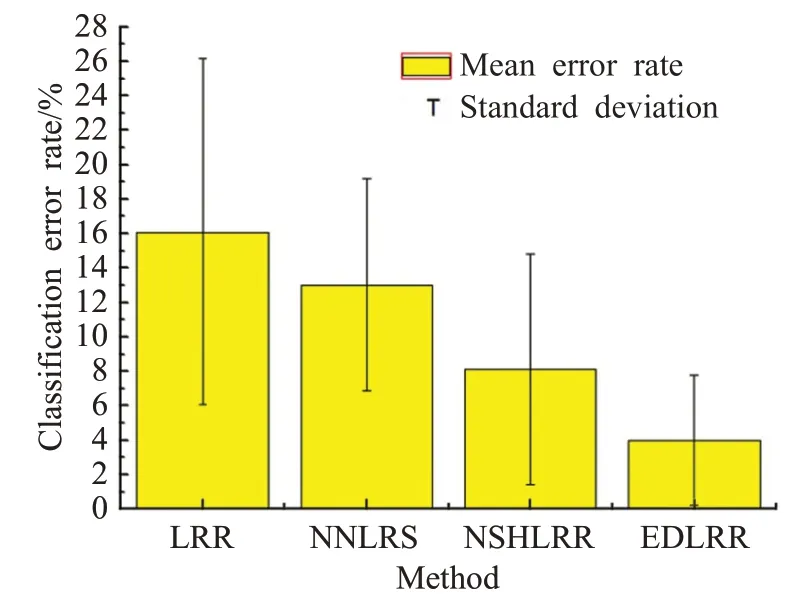
图3 均值方差图
如图3 所示,本文方法与其他方法相比方差较小,原因是非负约束的存在使得计算具有一定的稀疏性,流形正则化约束的使用也增强了基于LRR图方法的鲁棒性。
4 结束语
本文提出了一种基于有效距离的低秩表示模型(EDLRR)。首先采用稀疏表示方法计算样本间的有效距离并构建拉普拉斯矩阵,然后构建包含拉普拉斯正则化项的低秩表示模型。本文方法不仅能表示全局低维结构,且能捕获流形结构的数据中的几何结构信息。在三个公开数据集上的分类实验结果表明,与传统方法相比,本文方法具有更高的分类精度和鲁棒性。
