基于Apex帧光流和卷积自编码器的微表情识别
2021-02-22温杰彬杨文忠马国祥张志豪李海磊
温杰彬,杨文忠 ,2,马国祥,张志豪,李海磊
1.新疆大学 信息科学与工程学院,乌鲁木齐 830046
2.中国电子科学研究院 社会安全风险感知与防控大数据应用国家工程实验室,北京 100041
3.新疆大学 软件学院,乌鲁木齐 830091
微表情[1]是一种自发的面部表情,持续时间短(通常在0.04~0.20 s之间[2]),局部变化且变化强度低[3],极少人能用裸眼观察到微表情。微表情通常发生在人试图隐藏自己的真实情绪时,无法伪造也不能抑制[4]。微表情能够反映人的真实情感,在刑侦审判、教学评估、婚姻关系预测、国家安全等领域都有潜在应用。
1978 年,Ekman 等人建立了面部动作编码系统[5-6](Facial Action Coding System,FACS),用来编码面部肌肉运动和情感类别的对应关系。该系统可用于识别每个动作单元(Action Unit,AU)开始和结束的确切时间。第一个出现的AU称为Onset,最后结束的AU称为Offset,Apex 代表AU 达到峰值或面部运动的最高强度。2002年,Ekman设计了一套专业的微表情训练工具METT训练学员识别微表情,然而成功毕业的学员对微表情识别准确率也不到50%[7]。
微表情的识别要消耗大量的人力物力,且识别准确率不高。随着计算机视觉的发展,越来越多的研究者开始使用机器学习的方法进行微表情的自动化识别。微表情自动识别系统通常包括三个阶段:预处理、特征提取和分类[8]。预处理阶段主要包括人脸检测、人脸特征点对齐、感兴趣区域划分、重要帧选取和运动放大等。特征提取就是在保留重要微表情信息的情况下提取到低维的图像或视频特征。分类阶段就是用各种分类器对上一阶段提取的特征分类为具体的情绪类别。特征提取被很多研究者认为是微表情识别中最重要的步骤。如何在不损失关键信息的情况下设计低维的特征是特征提取的关键,恰当的特征表示方法可以大大提高识别的准确率。按照特征的不同,传统的微表情识别方法有基于LBP(Local Binary Pattern)的方法[9]和基于光流的方法[10-12]。但是由于微表情持续时间短、运动强度低的特点,很难找到合适的特征描述子,因此传统手工特征方法的识别率依然不高。本文提出一种结合传统方法和深度学习的微表情识别方法,实验结果表明该方法较传统方法在识别性能上有了很大的提高。
1 相关工作
1.1 基于Apex帧光流的微表情识别
大多数的研究中微表情都被当作一个视频序列来处理。常规的特征提取方法考虑整个视频序列或者采用时域插值模型[13](Temporal Interpolation Model,TIM)处理过的部分序列。以Liong等人[12]为代表的研究者认为高帧率下的微表情序列并不是每一帧都是必要的,相反可能会带来一些计算上的冗余。他们提出了一种只用两帧(起始帧和峰值帧)图像来表示微表情的特征提取方法(Bi-WOOF),并且提出了一个Divide & Conquer[12]算法实现Apex 帧的定位,之后计算起始帧(参照帧)到Apex帧的光流图像。在以上工作的基础上,Liong等人结合卷积神经网络提出了OFF-ApexNet[8],对计算出的水平和竖直光流分量图像分别通过两层的卷积神经网络提取特征,将两部分的特征拼接,再经过两个全连接层后使用softmax进行分类。作者在3 个数据集SMIC[9]、CASME II[14]和SAMM[15]的组合数据集上使用LOSOCV(Leave-One-Subject-Out Cross-Validation)协议进行验证,达到了74.6%的准确率和71.04%的F1 值。最近的研究中Liong等人[16]拓展了OFF-ApxeNet,使用Apex帧光流推导出了光学应变(Optical Strain)等相关衍生特征。
Apex 帧代表了面部微表情运动变化的峰值,含有很具判别性的特征。使用Apxe帧光流方法可以减少计算量,大量的研究也验证了该方法的出色性能。由于只选取两帧图像代表微表情,会损失一些时域上微表情变化的信息,而且Apex 帧定位的准确性也对微表情识别的准确率有较大影响。
1.2 基于深度学习的微表情识别
深度学习在很多计算机视觉任务中取得了很大的进步,很多研究者采用端到端的卷积神经网络(Convolutional Neural Networks,CNN)和长短期记忆网络(Long Short Term Memory,LSTM)提取微表情序列的空间和时间特征。近几年出现了大量使用卷积神经网络进行微表情识别的研究,按照其网络架构的不同大致可以分为3DCNN[17-19]结构、递归卷积网络[20-22]结构、双流网络[8,23]结构。
基于深度学习的微表情识别方法取得了比手工方法更好的性能。然而,深度学习通常需要大量的数据进行训练,由于微表情样本的不足,经常出现过拟合的问题,导致微表情的识别率很难继续增长。为解决微表情数据集不足引起的模型过拟合问题,很多研究采用了迁移学习[19,24-26]的方法进行微表情识别。Liong等人[16]还使用生成对抗网络(Generative Adversarial Network,GAN)进行了Apex帧光流数据增强的尝试。目前尚未发现有研究者采用卷积自编码器和Apex帧光流来实现微表情的特征提取,因此本文提出一种新的基于Apex 帧光流和卷积自编码器的微表情识别方法。
1.3 跨库微表情识别
由于数据集样本不足,一些学者尝试将数据集进行组合来增加微表情样本的数量。公共的跨库微表情数据集最早出现在MEGC2018 挑战赛[27]上,CASME II[14]和SAMM[15]被重新组合为5个表情类别。第二届MEGC[28]挑战赛上,融合数据集中又增加了SIMC[9]数据集,为了使所有3个数据集可以一起使用,使用了一组共同的简化情感类别(“积极”“消极”“惊讶”),并使用了其原始情感类别的适当映射。Peng等人[24]使用迁移学习的方法,使用ImageNet上预训练好的ResNet10网络模型首先在5 个宏表情数据集上进行训练,达到99.35%的准确率后,再使用微表情数据集进行微调,在融合数据集上结果达到了74.7%的准确率和64%的F1值。
跨库数据集可以更加真实地拟合现实场景。首先它增加了对象的个数,而且对象来自更多的地域、种族、拍摄环境,更多的微表情样本更加有利于深度学习等数据驱动方法的应用;其次使用减少的常规情绪类别以更好地适应不同刺激和环境设置引起情绪差异。本文采用MEGC2019[28]融合数据集,在增加训练样本的同时也有利于提升算法的泛化能力,使其更适用于真实场景。

图1 基于Apex帧光流和卷积自编码器的微表情识别整体框架
2 基于Apex帧光流和卷积自编码器的微表情识别
本文提出的基于Apex帧光流和卷积自编码器的微表情识别方法包括3个阶段:预处理、特征提取、微表情分类。如图1所示,原始微表情序列通过预处理进行Apex定位,特征提取阶段首先计算TVL1光流(u和v分别代表计算出的光流水平和垂直分量),然后使用光流图像训练卷积自编码器,将两个训练好的自编码器的中间层的隐藏向量拼接后作为最终的特征,输入到SVM(Support Vector Machine)分类器中完成最后的分类。
2.1 Apex帧光流计算
光流(Optical Flow)是图像对象在两个连续帧之间由对象或相机的运动所引起的视觉运动的模式,能够反映图像中物体运动的方向速度,通常用于基于运动的对象检测和跟踪系统。
光流的定义要满足两个基本假设:(1)物体的像素强度在帧间不改变。(2)相邻像素具有相似的运动。微表情变化幅度低,帧间的相对位移很小,相邻像素之间有相似的运动;微表情持续时间非常短,即便从起始帧到Apex 帧的时间差也不超过0.1 s,帧间图像的亮度基本不发生改变,因此微表情满足光流的两个基本假设。
在计算Apex帧光流之前,首先要对Apex帧进行定位。其中CASME II[14]和SAMM[15]数据集中已经标注了Apex 帧的位置,直接取出数据集中对应的标注帧作为Apex帧;而SMIC[9]中没有提供Apex帧的标注。本文为减少计算量直接选取微表情序列的中间帧作为Apex帧。
考虑一个像素I(x,y,t)在起始帧的光强度(其中t代表其所在的时间维度),它在Δt时间内移动了(Δx,Δy)的距离到达Apex帧。因为是同一个像素点,根据假设(1)认为该像素在运动前后的像素强度(亮度)是不变的,即:
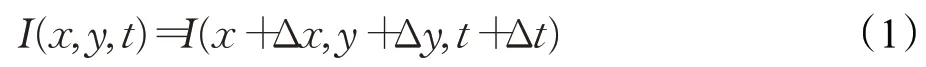
将式(1)右端进行一阶泰勒展开,得:
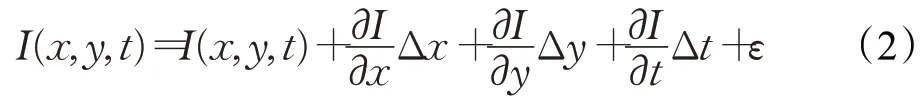
其中,ε代表二阶无穷小项,可忽略不计。再将式(2)代入式(1)后同除Δt,可得:
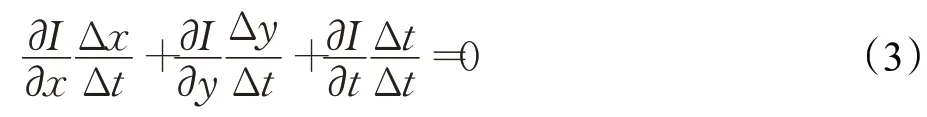
设p、q分别为沿水平方向与竖直方向的速度分量,得:


其中,Ix、Iy、It均可由图像数据求得,(p,q)即为所求Apex帧的光流矢量。Liong等在文献[16]中验证了五种光流算法对于微表情识别的影响,结果证明TVL1[29]光流算法在微表情识别任务中能取得最好的效果。因此本文采用TVL1 光流算法,使用OpenCV(Open Source Computer Vision Library)实现光流的计算,并返回光流的水平和竖直分量。
2.2 卷积自编码器
自编码器(Autoencoder,AE)是一个学习将输入复制到输出的神经网络。AE 通过训练网络忽略信号“噪声”来学习一组数据的隐含表示(编码),通常用于特征提取和降维。它由两个主要部分组成:将输入映射到编码中的编码器,以及将编码映射到原始结构的解码器。如图2所示。

图2 自编码器结构
本文采用的卷积自编码器的编码器和解码器都是CNN网络,如图2所示。编码器的卷积网络学习将输入图像编码为一组隐藏空间表示,然后解码器CNN 尝试重构输入图像。其中CNN作为通用特征提取器进行工作,学习如何最好地捕捉输入特征。光流图像输入卷积自编码器之前,首先对其进行归一化。卷积自编码器的输入为归一化为28×28像素的灰度光流图像,输出为重构后的28×28像素的光流图像。
对于单通道光流输入x,第k个特征图的潜在表示hk为:

其中,σ为激活函数,*代表2D 卷积操作,wk为卷积核,bk为偏置。将得到的hk进行特征重构,可以得到重构图像y:

其中,为解码器的卷积核,c为偏置。将输入的光流图像x和最终重构得到的结果y进行欧几里德距离比较,通过反向传播算法进行优化,就完成了卷积自编码器的训练。

最小化损失函数E就可以得到一个最佳的隐藏空间表示,这个最佳隐藏空间表示作为该光流分量图像的特征。本文TVL1光流的水平和竖直分量图像分别通过训练好的自编码器,得到水平和竖直两个隐藏空间表示。
微表情分类阶段将两个隐藏空间表示拼接起来作为最终的微表情特征向量。特征向量输入到SVM分类器中,输出微表情的类别。其中SVM采用RBF核函数,两个超参数通过网格搜索得到。
3 实验和分析
3.1 实验数据
实验采用了MEGC2019 融合数据集进行验证。融合数据集由 SMIC[9]、CASME II[14]和 SAMM[15]组合而成。3个数据集的详细信息如表1所示,SMIC总共记录了20 名受试者,并从16 名受试者中发现了164 个微表情片段,三种感情类别分别为“积极”“消极”“惊讶”。CASMEII数据集包括来自35个受试者的247个微表情样 本 并 提 供 了 5 个 情 感 标 注 :“ 高 兴 ”“ 厌 恶 ”“ 惊 讶 ”“ 压抑”“其他”。CASME II也是样本最多和使用最为广泛的自发微表情数据集。SAMM收集了来自不同人群的32 名受试者的微表情,包含159 个微表情片段,视频的帧率为200 f/s,分辨率为2 040×1 088,标注了7 个情感类 别 :“ 高 兴 ”“ 惊 讶 ”“ 悲 伤 ”“ 愤 怒 ”“ 恐 惧 ”“ 厌 恶 ”“ 轻蔑”。因3 个数据集的情绪类别标注不同,融合数据集统一为3个类别(“积极”“消极”“惊讶”),其中“高兴”类别被重新标注为“积极”,“厌恶”“压抑”“愤怒”“轻蔑”“恐惧”被重新标注为“消极”,“惊讶”类别则保持不变。融合后的数据集包含来自68 个对象的442 个微表情序列。来自每个数据集的具体数量详见表2,很容易看出融合后的数据集中“惊讶”“积极”“消极”的比例大约为1∶1.3∶3,数据集还存在严重的数据类别不平衡问题。

表1 3个自发微表情数据集

表2 实验采用的融合微表情数据集
3.2 评价标准
本文采用LOSOCV 实验协议,能够模仿真实场景——对象来自不同的背景(种族、性别、情感的敏感性),保证对象独立评估。融合数据集中共包含68 个对象,因此实验分为68 折。每折选取1 个对象的微表情序列作为测试集,剩下67 个对象的所有微表情序列作为训练集。由于融合数据集中表情类别的不平衡问题,评价标准采用无权F1值(Unweighted F1-score,UF1)和无权平均召回(Unweighted Average Recall,UAR)。UF1 在多分类问题中是一个很好的选择,因为它可以同等强调稀有类。为了计算UF1,首先要计算每个类别c的F1值。UF1就是每个类别F1值的平均值。
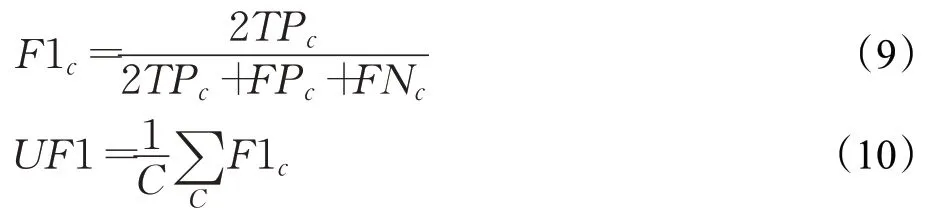
其中,C为类别数;F1c为类别c分类结果的F1 值;TPc、FPc、FNc分别为类别c分类结果中真正、假正、假负的数量,即实际类别为c预测类别也为c的数量、实际类别不是c但预测类别是c的数量,实际类别是c预测类别不是c的数量。
UAR 也称“平衡准确率”,是一种代替标准准确率(或加权平均召回)的更合理的评价标准,因为标准准确率的预测更偏向于较大类别的结果。

其中,C为类别数;Nc为类别c样本的总数;Accc为类别c的准确率,即c类中预测正确的数量占c类样本总数量的比例。UAR为所有类别的准确率的平均值。
3.3 Apex光流计算
本文使用开源计算机视觉库OpenCV4.1.0 中的DualTVL1OpticalFlow 接 口 计 算 Onset 到 Apex 之 间 的TVL1 光流,如图3 所示,为三种类别的Apex 光流的水平和竖直分量。从生成的光流图上大致能看出人脸的轮廓和变化幅度。其中不同的微表情类别的局部运动变化的区域是不同的。“积极”微表情的局部变化主要集中在眼睛和嘴角;“惊讶”微表情的变化主要表现在额头和眼睛区域;而“消极”微表情变化最大的是下巴部位。从图中可以看出本文提取的TVL1 光流可以反映微表情的局部变化特征。

图3 计算出的Apex光流图
3.4 卷积自编码器
进行多次的超参数(包括自编码器的层数、每层卷积核的尺寸和个数)选取并验证,实验采用的最优卷积自编码器结构如表3所示。自编码器共由5个卷积层、2个最大池化层和2个上采样层组成。其中编码器包含2个 3×3 的卷积层和2 个 2×2 的最大池化层,卷积核的个数分别为16、8。解码器包括3个3×3个卷积层和2个2×2的上采样层,卷积核的个数分别为8、16、1。
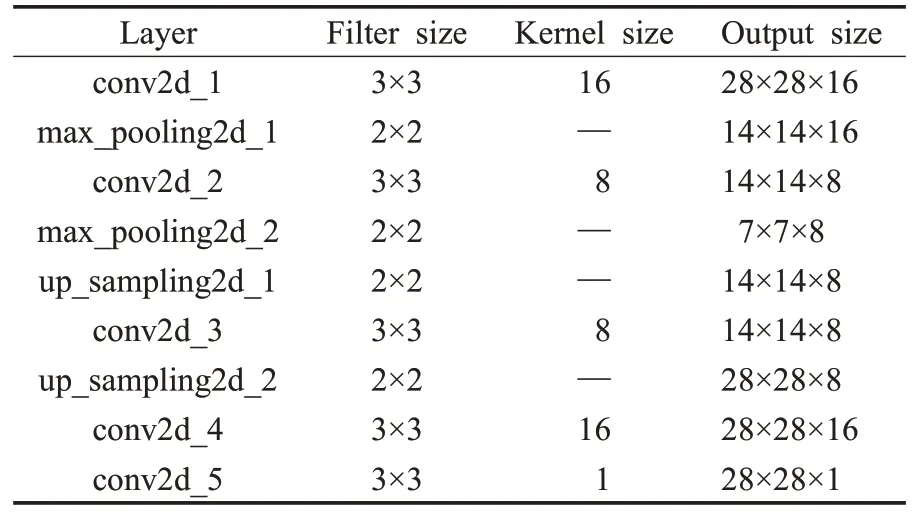
表3 最优卷积自编码器结构
由于LOSO交叉验证需要消耗的时间太长,在正式实验之前首先对融合数据集使用RBF核的SVM分类器做5折交叉验证,通过交叉验证的方式可以比较快地找到卷积自编码器合适的超参数。卷积自编码器中编码器两层卷积核的个数和不同训练轮数下的实验结果如图4 所示。可以明显看出编码器两个卷积层的卷积核个数为16、8时效果最好,卷积自编码器训练600轮后在融合数据集上进行5 折交叉验证的准确率最高达到了89.89%,因此,采用这一准确率最高的卷积自编码器模型在融合数据集上进行LOSO交叉验证分类任务。

图4 卷积核数和训练轮数对分类结果的影响
卷积自编码器的作用主要是特征的选择和降维,选择出最重要的特征并且丢弃掉无关的冗余特征。为了进一步验证卷积自编码器中间层特征的效果,对原始光流图像和使用特征重构的光流图像做了简单的可视化。如图5 所示,上层4 张图像为自编码器的输入光流图像,下层4 张图像为通过解码器重构输出的光流图像。通过中间层特征重构的图像能够较好地还原输入图像。因此,本文训练的卷积自编码器能够较好地提取判别性强的微表情特征。卷积自编码器也可以根据需要通过改变中间层卷积核个数等超参数来控制最终微表情特征的维度。

图5 卷积自编码器重构图像
3.5 结果对比
表4 为使用最优卷积自编码器模型进行LOSOCV的实验结果。其中LBP-TOP方法为基准方法,SA-AT[26]、ATNet[22]和CapsuleNet[30]是3 个有代表性的深度学习方法。表4 中对比了五种方法在融合数据集(Full)和3 个单独的数据集部分的UF1和UAR。所有对比结果均使用相同的融合数据集、实验协议和验证方法。从中可以明显看出,提出的基于Apex 帧光流和卷积自编码器的跨库微表情识别方法(Apex-OFCAE)相对于基准方法性能有了很大的提升,UF1达到了0.722 6,UAR达到了0.719 1,分别提高了0.134 4 和0.140 6。提出的Apex-OFCAE方法在融合数据及和各单独数据集部分的UF1和UAR指标均优于其他3个深度学习方法,由此看出提出的结合Apex光流和卷积自编码器的微表情识别方法具有较强的特征提取和表示能力,且具有优秀的泛化性能,在各个数据集上都有了很大的提升。从表中可以明显看出所有方法在CASME II上的效果都是最好的,原因是该数据集中的样本量最多,而SMIC和SAMM的识别工作还存在更大的挑战。
为进一步分析Apex-OFCAE 方法在不同数据集中的性能差异,绘制了融合数据集和3个单独数据集分类结果的混淆矩阵。如图6 所示,(a)~(d)分别表示融合数据集、CASME II、SAMM和SMIC的混淆矩阵。纵坐标表示微表情的真实标签,横坐标表示预测的分类标签,数值代表各个类别预测概率。例如,融合数据集中0.82 代表实际类别是“消极”并被正确预测为“消极”的概率;0.30表示实际类别为“积极”但是被预测为“消极”的概率。可以看出不少“积极”或者“惊讶”类别被错误地预测为“消极”,原因是类别不平衡,“消极”样本总数超过一半(250/442),因此分类结果偏向于“消极”类别。提出的方法在CASME II数据集上识别性能最好,SMIC 数据集性能不好的原因是分辨率和帧率比较低,Apex 帧的选取跟实际的Apex 帧存在一定的误差。SAMM数据集中的问题是类别间样本数量不平衡“,惊讶”和“积极”的样本数量分别只占总量的10%和20%。因此,对于SMIC和SAMM数据集的识别还存在较大的挑战。

表4 对比实验结果

图6 融合数据集和单独数据集的混淆矩阵
4 结束语
本文提出了结合Apex 帧光流和卷积自编码器的一种微表情识别方法。提取起始帧到Apex 帧光流,获取微表情的运动特征,并使用光流图像训练卷积自编码器用于特征的选择和降维。实验结果表明,基于Apex 帧光流和卷积自编码器的跨库微表情识别性能明显优于基准方法和一些优秀的深度学习方法。本文实验采用的数据集为在3 个典型数据集的基础上重组的融合数据集,不仅增加了受试者和样本的数量,而且增加了受试者的种族、年龄等特性的多样性和样本的采集环境复杂性,更加拟合真实场景。此外,采用LOSO 验证方法,保证对象独立评估,符合真实的应用场景。因此算法具有较强的鲁棒性和实用性。本文方法在SAMM 和SMIC 数据库上的识别性能明显不如CASME II数据集,以后的工作可以考虑采用GAN等数据增强方法来增加数据集的数量和类别间样本平衡性。
