双偏差双空间局部方向模式的人脸识别
2021-02-22叶学义钱丁炜
王 鹏,叶学义,王 涛,钱丁炜
杭州电子科技大学 通信工程学院 模式识别与信息安全实验室,杭州 310018
近年来人脸识别因为其稳定、非接触性和易于获取等特点,已经被广泛应用。但实际应用场景环境的复杂多变,尤其是光照、表情、遮挡、姿态等变化都会显著影响人脸识别的性能。
人脸识别主要包含人脸检测、人脸表征、人脸匹配等环节。人脸表征主要包括特征提取和特征降维。而特征提取从人脸属性要素中提取能够体现特定人脸身份的面部特征,因此成为整个人脸识别的关键。特征提取的研究主要分为局部特征提取和全局特征提取两类。全局特征关注整体属性,经典的方法有主成分分析法(Principal Component Analysis,PCA)[1]、线性判别分析(Linear Discriminant Analysis,LDA)[2]等。全局特征可以反映粗略信息,但无法刻画人脸细节,在应用时有很大的局限性;而基于局部特征的方法聚焦于图像的微纹理结构,对原始图像以模式编码获得新的特征图像,对于光照、表情等干扰可以保持更好的稳定性,近年来得到广泛研究。目前对局部特征提取的方法主要分为两类:一类是基于手工设计描述符的局部特征提取方法,如局部方向数模式(Local Directional Number pattern,LDN)[3]、压缩二进制模式(Compressive Binary Pattern,CBP)[4]等,它依赖设计者的先验知识精心设计编码,计算快速且效果良好。另一类是基于学习描述符的局部特征提取方法,如紧凑二进制人脸描述符(Compact Binary Face Descriptor,CBFD)[5]、上下文感知的局部二值特征学习(Context-Aware Local Binary Feature Learning,CA-LBFL)[6]等。它通过无监督或监督学习优化编码方法,相比于手工描述符,它利用更大采样范围的像素信息自动编码,不需要手工设计具体编码规则。但这类方法需要多次迭代寻找最优编码,计算耗时,效率不高。基于手工设计描述符的方法计算速度快且识别性能好,因此近年来受到广泛研究。
Ojala 等人[7]提出的局部二值模式(Local Binary Pattern,LBP)是局部特征提取的经典方法。它聚焦于图像局部纹理,利用局部区域信息替代单个像素点信息,有较好的纹理描述能力。但LBP 仅使用灰度信息,抛弃了非强度信息,有很多需要改进的地方。为了克服LBP等方法的一些缺点,Rivera等人提出局部方向数模式(LDN)。它基于边缘响应算子记录了边缘响应最强和最弱的两个方向,抓住了主要纹理。但LDN仅依据原始的边缘响应值来提取梯度信息,特征信息少。Ryu等人[8]在保留LDN边缘响应信息基础上,提出局部方向纹理模式(Local Directional Texture Pattern,LDTP),通过区分主要方向的灰度差异丰富了梯度信息,但忽略了对灰度空间信息的提取。王晓华等人[9]提出了梯度中心对称局部模式(Gradient Center Symmetric Local Directional Pattern,GCSLDP),它利用中心对称点和相邻点的边缘响应差值来描述人脸信息,提取了更深层次的梯度信息,但却忽略了原始边缘响应包含的纹理细节,没有准确还原人脸特征。杨恢先等人[10]综合了LDN 与GCSLDP 的特点,提出双空间局部方向模式(Double-Space Local Directional Pattern,DSLDP),其同时保留了原始边缘响应信息及相邻点的边缘响应差分信息。但它仅依赖边缘响应算子补充梯度信息,忽略了灰度空间的差异与强度信息,不能充分提取有强区分性的人脸特征。
图像的梯度信息和灰度信息都是描述图像细节的重要组成部分。LBP方法抓住了图像的灰度信息,但忽略了对边缘细节有更强刻画能力的梯度信息;而LDN类方法大多基于边缘响应算子获得梯度信息,缺少对灰度信息的有效利用。针对两类方法各自的优缺点,本文融合相互独立的梯度与灰度空间信息,提出一种双偏差双空间局部方向模式(Double Variation and Double Space Local Directional Pattern,DVDSLDP),提取更丰富的判别特征以提高人脸识别性能。
该方法先对图像进行局部采样,利用相关联点的加权拟合值来代替单点灰度值,扩大关联邻域信息,以表征更丰富的图像信息;然后考虑到梯度特征与边缘纹理的强关联性,通过Kirsch滤波器计算8个方向的边缘响应值,以表征某一方向对其余7 个方向的相对偏差,从而反映出该点的邻域纹理方向;再利用前向差分和后向差分计算绝对偏差来表征该点的纹理方向,并以度量函数进行优化;最后以特征级联实现相对偏差与绝对偏差信息的相互补充,获得更优的局部梯度信息表征。
同时像素的灰度信息同样包含人脸的特征信息,因此该方法提取像素点邻域灰度值和的最大值方向表征与梯度空间相互独立的灰度空间特征信息,再以级联实现融合得到双空间特征。
最后该方法根据模式编码后的图像特征图,分块提取直方图统计特征,利用信息熵自适应地加权级联各子块的特征,得到表征人脸图像的特征向量。最后利用最近邻分类器完成分类识别。
1 局部方向数类方法的演进
1.1 LDN
局部方向数(LDN)方法利用图像的3×3邻域与8个方向的Kirsch模板算子卷积得到边缘响应,Kirsch算子具体构成及各算子对应的方向如图1所示,M0,M1,…,M7分别是对应正东,东北,…,东南8 个方向的Kirsch算子模板。边缘响应值最大和最小的两个方向提供了有价值的信息,因为这两个方向通常是从亮到暗或者从暗到亮的过渡方向,这种过渡通常发生在脸部图像的嘴、鼻子等器官周围,记录这些方向信息有利于提取关键特征。编码方式如图1所示。

图1 Kirsch算子及方向
首先计算图像的3×3邻域I和8个模板Mi卷积后得到8个边缘响应值ei:

式中,(x,y)表示以图像左上角像素点为原点,水平方向与原点相隔x距离,竖直方向与原点相隔y距离的像素点;*表示卷积计算;ei(x,y)表示图像邻域I与Kirsch模板Mi卷积得到的第i个方向的边缘响应值,它用相对偏差的方式记录了邻域信息。
之后记录最大和最小边缘响应值对应的方向数:

式中,ix,y和jx,y表示最大和最小边缘响应值对应的方向数。
最后的编码结果如下:

式中,LDN(x,y)表示(x,y)点的LDN编码结果。
1.2 CSLDP
中心对称局部方向模式(CSLDP)方法[11]依然利用了Kirsch算子得到边缘响应值,它通过计算4个中心对称梯度方向的边缘响应变化值来获得特征信息,实际上在相对偏差的基础上计算中心对称方向的差分信息来提取人脸特征。其编码方式如下:
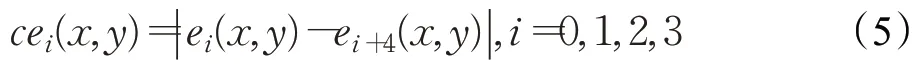
式中,cei(x,y)表示在中心对称方向上的边缘响应变化差值绝对值。
最后的编码结果如下:
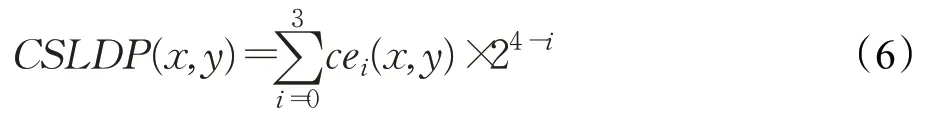
式中,CSLDP(x,y)表示像素点(x,y)的CSLDP编码结果。
1.3 GCSLDP
梯度中心对称局部方向模式(GCSLDP)在计算CSLDP的4个中心对称方向的边缘响应变化值的基础上,进一步计算相邻点的边缘响应差值。它在相对偏差的基础上记录了中心对称方向上点与相邻点的绝对偏差值,反映了局部图像更深层次的梯度信息。其编码方式如下:

式中,d(x,y)表示在像素点(x,y)中心对称梯度方向上边缘响应值变化最大的方向,dei(x,y)表示相邻点的边缘响应变化差值,p(x,y)表示相邻点边缘响应变化最大的方向。
最后的编码结果如下:
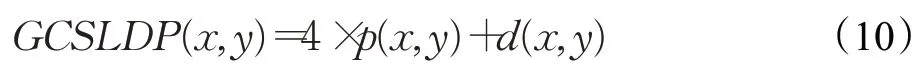
式中,GCSLDP(x,y)表示像素点(x,y)的GCSLDP编码结果。
2 DVDSLDP算法
局部特征提取的过程主要有图像局部采样、模式编码和特征分类识别等[12]。在图像采样时,LDN类算法在图像3×3 邻域计算边缘响应。但人脸图像的各个点之间并不孤立,人脸图像像素点之间有很强的关联性。如果单个点受到光照、噪声等因素的干扰,就会影响最后的特征提取,使算法性能下降。
因此,在设计局部描述符时,设计者往往考虑在局部采样更多的关联点,获取更丰富的图像信息。例如基于块的局部对比度模式[13](Block-based Local Contrast Pattern,BLCP)、随机采样局部二值模式[14](Random Sampling LBP,RSLBP)等,这种策略表现出了更好的识别性能。因此本文先对原始图像进行局部采样,扩大邻域范围,通过加权融合关联点的像素获得信息更丰富的采样结果。
2.1 局部采样
如图2 所示,采样区域是以gc为中心点的5×5 邻域。其中a0,a1,…,a7代表与中心点gc相差1 或 2 距离的像素点。而b0,b1,…,b7是与中心点相差2 或2 2距离的像素点。在8个方向上的加权策略如下:
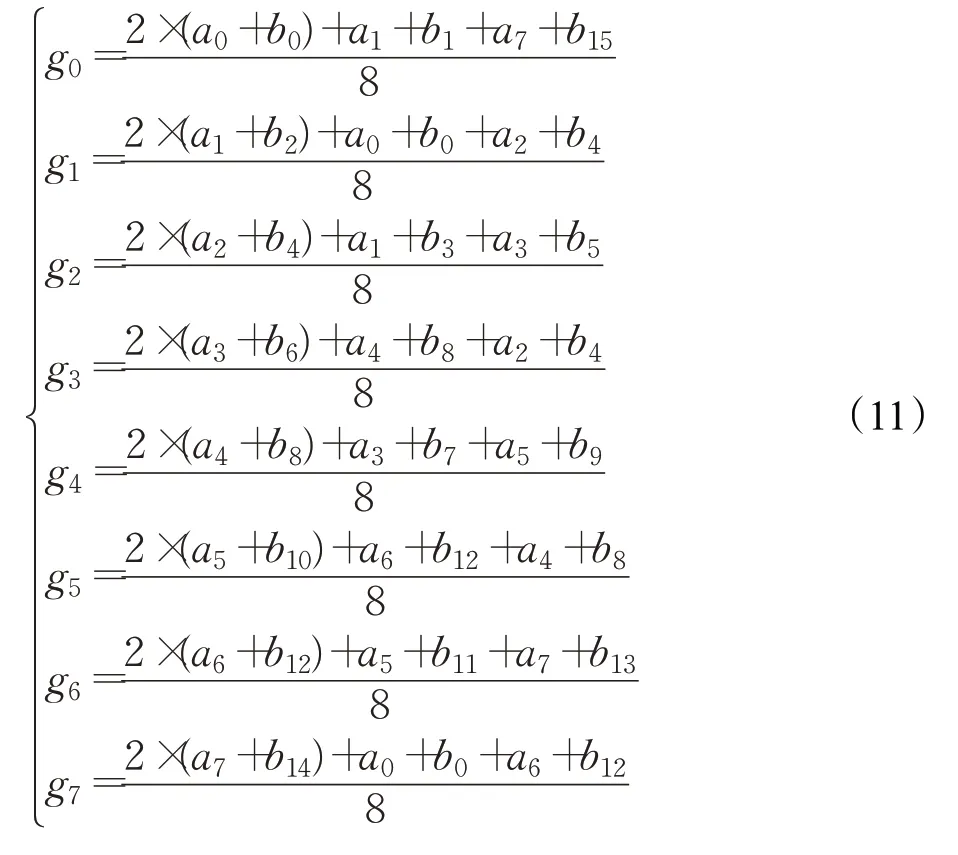
式中gi,0 ≤i≤7 分别代表在0、π/4、π/2、3π/4、π、5π/4、3π/2、7π/4 方向上加权后的像素值。如式(11)所示,首先各方向采样与对应方向关联的6个点,设置主方向上的点权重为其他点的2 倍以加大采样方向上像素点的作用,然后取采样点的加权平均值作为各方向的拟合像素值。以式(11)中的g0和g1为例,g0和g1分别是gc正东和东北侧像素点的拟合结果,它们都利用了中心点附近的关联点,综合其位置及它们到中心点的距离来分配权重,以充分利用更大邻域信息获得更准确的采样结果。对于正东关联点的拟合结果g0,像素点的方位与正东方向偏离越小则联系越紧密。由于a0、b0刚好位于正东方向且距gc较近,在式(11)赋予了更大的权重2。而a1、b1和a7、b15位于中心点东偏上和东偏下的位置,与正东方向有一定偏离,因此赋予较小的权重1;而对于g1,它是东北侧方向的拟合结果,综合了东北侧的a1、b2点,正东侧的a0、b0点,正北侧的a2、b4点的多重采样信息。由于正东、正北侧的点与东北侧的点靠近但与东北方向有一定的偏离,因此将其利用并设置它们权重为东北侧点的一半。最后取加权平均值作为拟合结果,可以在突出主要信息的基础上利用附近的关联点信息。遍历图像每一点,根据其邻域信息及式(11)就可以得到关于每一点的采样结果矩阵G,如图3所示。后续都使用采样结果G的拟合值替代图像对应区域的原始像素值。

图2 采样像素点示意图
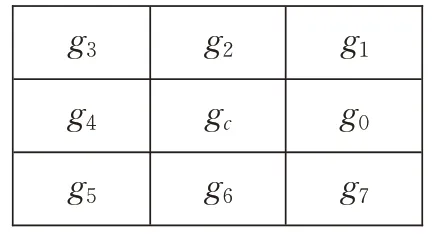
图3 局部采样结果G 示意图
2.2 模式编码
人脸图像最重要的区域在眼睛、鼻子、嘴巴等周围,这些区域通常都有大量梯度信息。利用这些信息可以还原图像边缘与细节,因此对这些信息的准确记录至关重要。LDN 类方法以邻域内所有像素点为参考,通过Kirsch算子设置不同权重模板获得各方向的边缘响应,实际计算了邻域某一方向像素点与其他方向点的相对偏差值,其值反映了邻域梯度信息,值越大的方向越可能是邻域纹理方向。相对偏差表征了局部图像邻域整体的大致纹理方向,而邻域内具体各点的纹理方向可能不尽相同。点与相近点像素的绝对差异,其绝对偏差值表征了具体某个点的纹理方向,可以进一步增加梯度信息,补充纹理细节。因此本文使用相对与绝对双重偏差,利用它们相互补充的梯度信息来丰富特征。该方法首先使用Kirsch算子获得相对偏差值,只取其最大绝对值对应的方向,这样既保留了主要纹理,又减少了信息冗余。具体计算公式如下:
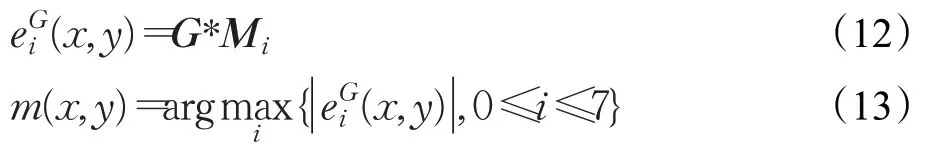
CSLDP、GCSLDP 等方法利用边缘响应,通过计算中心对称方向边缘响应的差值来找寻纹理,实际上是直接在相对偏差基础上来计算绝对偏差,这种深层次的交叉提取方式会使得记录的纹理信息不准确。另外,它没有中间值来参考,计算对称方向点的边缘响应差值并不能反映中间点与相邻点的变化程度。因此本文选择在原像素空间中引入中间值gc,即局部图像的中心像素值,并利用局部采样后的像素值独立计算绝对偏差,进而更准确地记录纹理细节,丰富梯度信息。其计算方式如下:
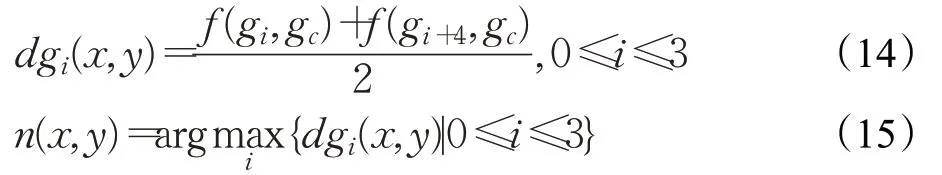
式中,dgi(x,y)表示在像素点(x,y)中心对称方向上计算得到的绝对偏差值。CSLDP方法在相对偏差基础上计算绝对偏差,这种交叉提取的方式不利于信息的准确提取。为了更准确地得到绝对偏差,式(14)在引入中心值为参考后,独立计算出前向差分与后向差分。然后取两个差分的平均值作为结果,以均衡得到中心对称方向上总的绝对偏差。f(gi,gc)是度量函数,用来度量不同偏差值对结果的影响。n(x,y)代表在像素点(x,y)最大绝对偏差值对应的方向数。
在设计度量函数时,考虑以下几个函数:

式中,c为65 025,防止数值溢出。设计度量函数为gi-gc的偶函数,减少对正负差分的探讨,重点考虑其差分值对结果的影响。另外,式(17)或(18)通过非线性函数将差分值进行映射,这种映射方式可以区分不同偏差对结果的影响,更准确反映各方向的实际梯度信息。相比于式(16)、(17),式(18)的指数函数有更强的区分能力,因此本文选用式(18)作为度量函数来衡量绝对偏差。
m(x,y)通过Kirsch 模板记录最大相对偏差对应方向,n(x,y)通过前后向差分和度量函数记录最大绝对偏差对应方向。双偏差信息互相补充,它们在梯度空间下记录了主要纹理信息,但缺失了对灰度信息的提取。因此进一步提取与梯度空间独立的灰度空间特征。通过计算各方向灰度值之和,利用图像灰度提取图像结构信息,提供更多的细节信息。并且和值与偏差值相对,灰度与梯度互相独立,不会造成冗余信息的记录,可以补充更多有效的特征信息[15]。其计算方法如下:
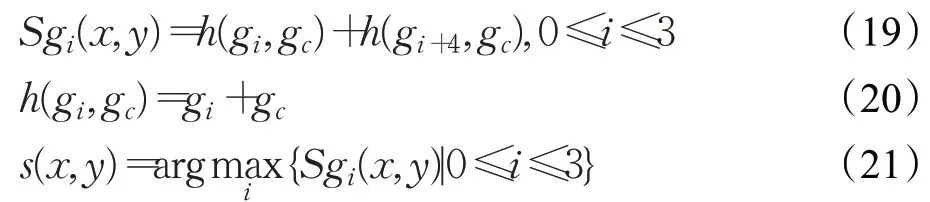
式中,Sgi(x,y)是像素点(x,y)上4个中心对称方向的灰度值之和;s(x,y)是在像素点(x,y)最大灰度和值对应的方向数,进一步完善了对图像人脸信息的记录。
最后,融合梯度与灰度的双空间特征,利用3 个方向对人脸图像进行量化编码:
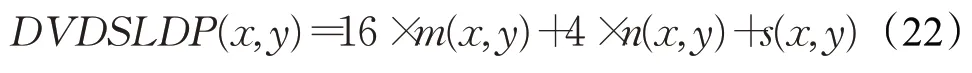
式中,DVDSLDP(x,y)是像素点(x,y)上的DVDSLDP编码结果,模式数为8×4×4=128 种,和同类方法的模式数相当。图4展示了具体编码过程。
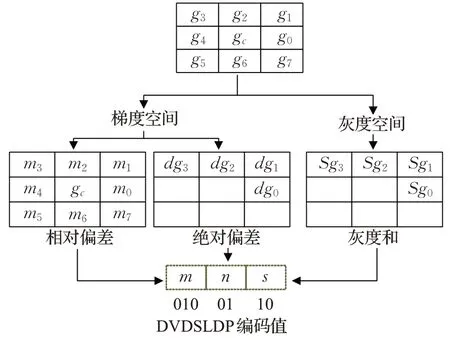
图4 算法编码过程
通过上述方式得到图像中每一点的编码值之后,便可以得到人脸图像的特征图。
2.3 特征图对比与分析
为了更直观地了解不同特征提取方法的差异,本文从AR人脸库选择了5张人脸,分别用LDN、GCSLDP、DSLDP 和本文提出的DVDSLDP 方法对人脸图像进行特征提取,结果如图5所示。
从图5中可以看出,LDN方法保留了人脸大致轮廓,但是在眼睛、嘴巴等区域丢失了大量细节信息;GCSLDP方法在相对偏差基础上直接提取绝对偏差,它提取了深层次的信息,但丢失了原始的边缘信息,边缘轮廓模糊;DSLDP 方法利用了更多梯度信息编码,但未有效利用原始空间的灰度信息,纹理细节不够丰富;而本文提出的DVDSLDP 方法,既利用了双偏差提取梯度信息,又补充了灰度特征记录人脸结构,编码得到的特征图和其他算法相比轮廓更清晰,纹理细节更丰富,进一步说明所提方法相比其他算法拥有更多的特征信息。

图5 特征图对比
2.4 DVDSLDP人脸表征
为了客观比较本文算法和其他算法,本文算法不对采集到的人脸图像进行任何预处理操作。如图6所示,直观展示了如何从人脸图像中提取出稳定的人脸特征过程,下面是算法的具体描述:
(1)对人脸图像进行局部采样,通过DVDSLDP 算法对图像进行模式编码,获得特征图像。
(2)获得特征图像后,将它分为若干不重叠子块,并对每一个子块进行直方图统计,获得每一子块的直方图特征。同时计算每一子块的信息熵,因为信息熵[16]越大,在图像里面表现为局部纹理更复杂,代表该子块图像有更多信息。因此依据每一子块信息熵占总图像的信息熵之比得到权重系数,区分每一图像子块的特征贡献度。
(3)最后利用步骤(2)得到的权重系数加权串接所有子块的直方图向量,融合得到整个人脸图像特征向量。
通过上述过程得到整个图像的特征向量后,完成特征提取,可送至后续分类器匹配识别。

图6 人脸表征流程图
2.5 分类识别
获得特征向量后,需计算不同直方图向量的距离。常用的距离度量方式有直方图相交距、欧氏距离、卡方距离[10]等。卡方距离考虑特征间的相对距离比较直方图的差异,直方图相交距直接比较两直方图的相交成分来判断两向量的相似程度,都可以很好地度量两直方图的向量距离。因此本文使用卡方距和直方图相交距来进行相似性判别。其中卡方距定义如下:
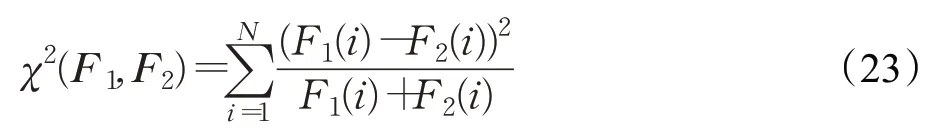
直方图相交距定义如下:

式中,F1和F2是两个直方图特征向量,分别代表待识别人脸特征向量和样本库某一样本的人脸特征向量;N是特征向量的长度;χ2(F1,F2)代表卡方距离,距离越小,说明两个向量相似度越高;d(F1,F2)代表直方图相交距,距离越大代表越相似。
通过式(23)、(24)计算测试样本和训练样本的距离后,利用最近邻分类器,选择具有和测试样本最相似的训练样本类别作为测试样本的类别标签,完成分类识别。
3 实验结果及分析
3.1 仿真环境和参数设置
为验证方法性能,在ORL、Yale、AR 数据库上进行实验,这些数据库包含了光照、表情、遮挡、姿态等干扰变量。实验中直方图的Bin数设置为128。在ORL库和AR 库使用卡方距离匹配识别,在Yale 库使用直方图相交距匹配识别。选择与典型的识别算法进行性能对比,如 LDP[17]、LDN、DLDP[18]、SLDP[19]、CSLDP、GCSLDP、DSLDP等,其中ORL和AR库实验数据来自于文献[10],Yale库的实验数据来自于文献[15]。实验所用硬件设备为 Intel I7-2600K,RAM 为 8 GB,仿真环境为 Matlab R2016a。
3.2 图像分块大小的考虑
由于在特征提取中,需对图像进行分块来获得各子块直方图,太大或太小的分块都会影响识别效果。为了选择最佳分块,通常将分块数控制在一定范围进行对比实验,以找到每个数据库下最好的分块方式。图7中横轴代表分块数,如2×4 代表列块数和行块数分别为2和4,纵轴代表识别率。从图7结果可知,在ORL库下选择分块为2×4,识别率最高;在Yale下分块数越多,识别率越高,选择分块为10×10,效果最好;在AR 光照子集和AR 表情子集下分块分别为24×15、8×5 时,识别率最高;在AR遮挡A子集和AR遮挡B子集下,识别率随着分块数增加而提高,且分块方式对结果有很大影响,选择分块为24×15,有最好的识别效果。
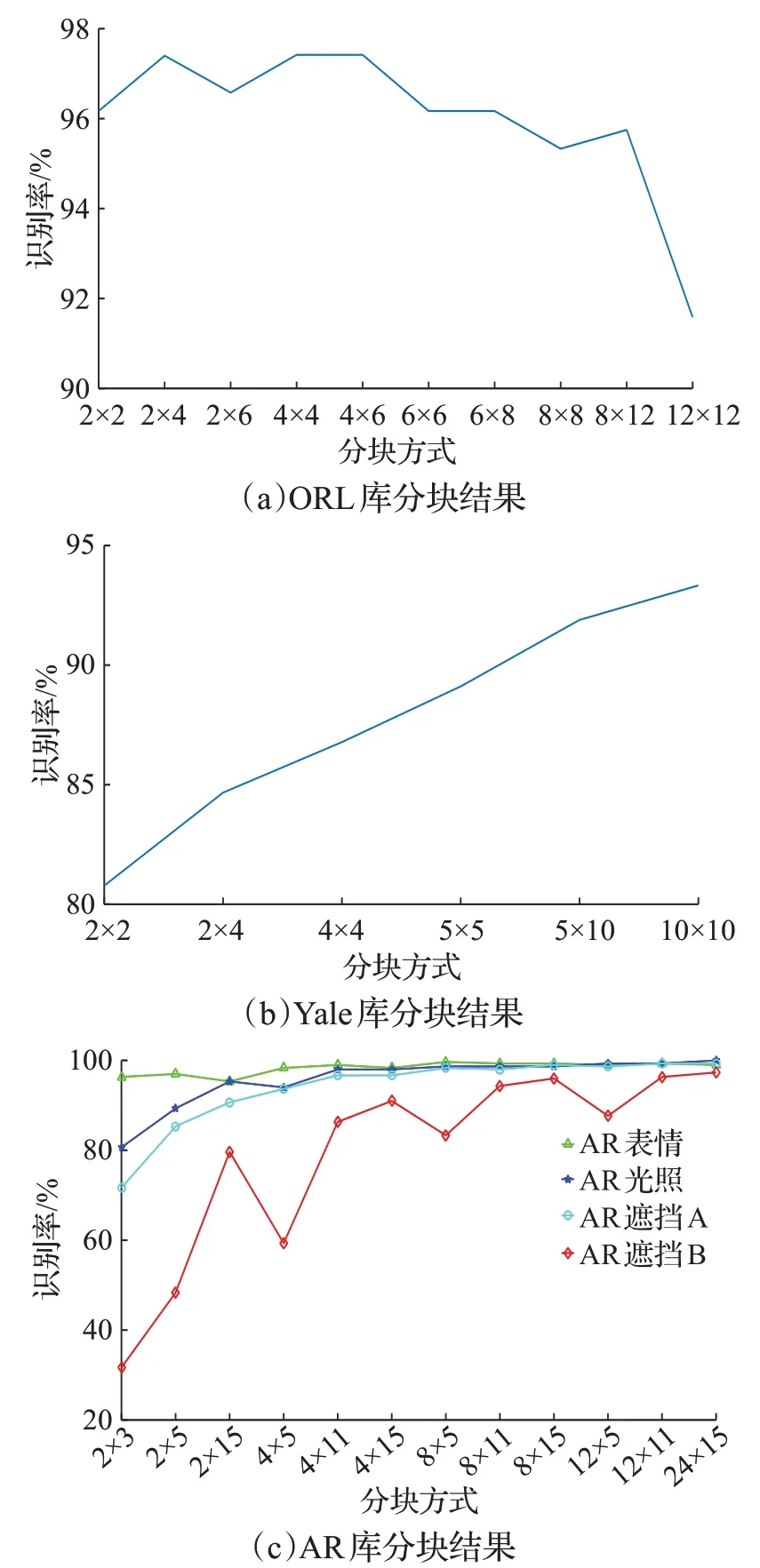
图7 各数据库分块实验结果
3.3 基于ORL数据库的结果和分析
ORL数据库是由英国剑桥的Olivetti研究实验室创建的,总共有400 张图片,包含40 个人,每人有10 张人脸样本,主要包含了姿态和表情的变化,分辨率为112×92,实验中选择归一化到96×96 分辨率下,部分样本如图8所示。

图8 ORL库部分样本
为了保证实验的准确性,实验中每个人随机选择2~6张图片作为训练样本,剩下的作为测试样本。取10次实验的平均值作为实验结果,实验结果见表1。
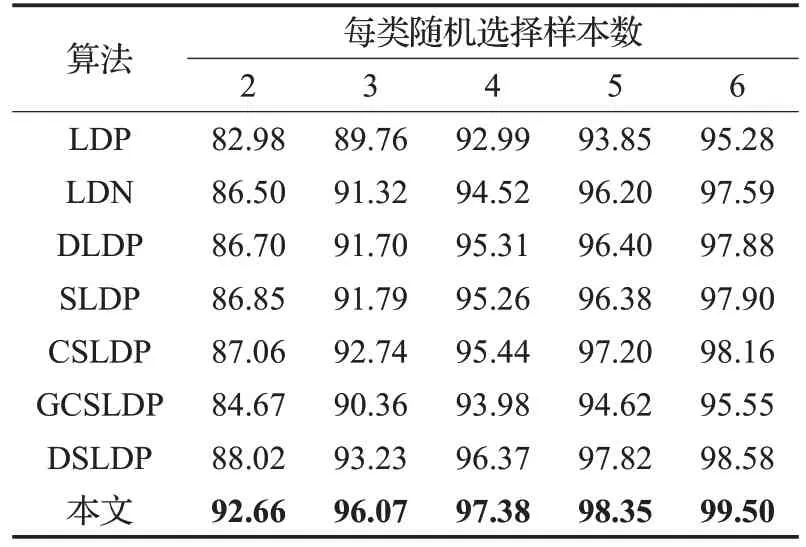
表1 各种算法在ORL库下识别率 %
从表1中可以看出,各算法随着样本数的增加识别率都逐渐增加,而本文提出的算法在不同数目的训练样本下都有最高的识别率。LDN算法仅利用边缘响应找到边缘特征,仅利用最大最小值对应方向,得到的空间信息非常有限,效果一般;在3 张图像作为训练样本时,本文算法相比LDP、LDN、DLDP、SLDP、CSLDP、GCSLDP、DSLDP 识别率提高了 6.31 个百分点、4.75 个百分点、4.37 个百分点、4.28 个百分点、3.33 个百分点、5.71个百分点、2.84个百分点,训练样本数较小时,提升明显。在ORL库中表情和姿态引起的变化主要体现在图像的纹理上。本文算法基于边缘响应的相对偏差和原灰度空间的绝对偏差来提取主要边缘特征,同时基于各方向的灰度最大值提取出独立的灰度结构信息,相比其他同类方法融合了多空间的特征,可以更好地捕捉纹理,识别率更高,性能更好。
3.4 基于Yale数据库的结果和分析
Yale 人脸数据库是由耶鲁大学采集得到的,共有165 张图片,有15 个人,每人包含11 张图片,分辨率为100×100,主要包含光照、表情、姿态等变化因素,其部分图片如图9所示。

图9 Yale库部分样本
Yale 数据库的样本图中有较多的变量因素,如表情、光照、小部分遮挡等。本实验随机选择其中的2~5张图片作为训练样本,剩余的作为测试样本。同样取10 次实验结果的平均值作为最终的结果,实验结果如表2所示。
仅2张图片进行训练时,大部分算法表现结果都不太好,LDP方法只有78.34%的识别率,它不区分方向信息很难提取到稳定的人脸特征;LDN、DSLDP和本文算法等都抓住最大值对应的方向数来提取特征,这种提取方式相比LDP更加稳定,识别性能更好。仅2张训练样本时,本文算法相比LDP、LDN、DLDP、SLDP、CSLDP、GCSLDP、DSLDP分别提高了11.36个百分点、7.85个百分点、6.63个百分点、9.38个百分点、6.66个百分点、6.14个百分点、2.63个百分点,提升效果最为显著。另外,在不同训练样本数下,本文算法都达到了更高的识别率。

表2 各种算法在Yale库下识别率 %
SLDP 算法利用井字形邻域扩大了采样范围,且利用最大与次最大边缘响应值提取特征,信息量增加;LDN 算法在LDP 基础上通过区分不同的边缘响应值,利用最大值和最小值对应的方向信息,抓住了主要边缘信息,性能更好;DLDP 方法利用相邻点的边缘响应差值来区分不同方向信息,但梯度信息提取较少,识别率提高较少;CSLDP计算中心对称方向上边缘响应差值,这种差值反映的偏差信息可以反映边缘纹理大致方向,有一定提升,但信息量有限;GCSLDP在利用CSLDP提取中心对称方向的偏差信息的基础上,又通过相邻点的边缘响应差值补充了梯度信息;DSLDP 算法通过原始边缘响应值和相邻点边响应值作差来记录局部区域的变化信息,实际上是基于相对差值来记录信息,保存了主要信息,有一定效果提升。本文算法基于边缘响应获得了相对偏差,然后利用各个方向的前、后向差分获得了绝对偏差,这两种偏差信息在梯度空间下互相补充,抓住了最重要的边缘纹理信息。同时记录了灰度最大的方向,并且记录了与梯度空间独立的灰度信息。两空间特征信息相互独立,共同完善了人脸信息,表现出了最佳的识别效果。
3.5 基于AR数据库的结果和分析
AR 数据库包含了 126 个人的 4 000 多张图片[20],图片像素为120×165。每个人有26张图片,在不同的时期采集,因此包含了年龄的变化。每个时期包含了13 张图片,分为表情、光照、遮挡A、遮挡B 共4 个子集,拥有各种环境变化的情形。它也是目前用于检验人脸识别最广泛的数据库之一,部分样本图片如图10所示。
本文选取了50名男性和50名女性的图片进行了实验,每个人包含了同一时期的13张图片,选择图10中第一张正脸图片作训练集,其余各个子集作测试集。实验结果如表3所示。

图10 AR库部分样本
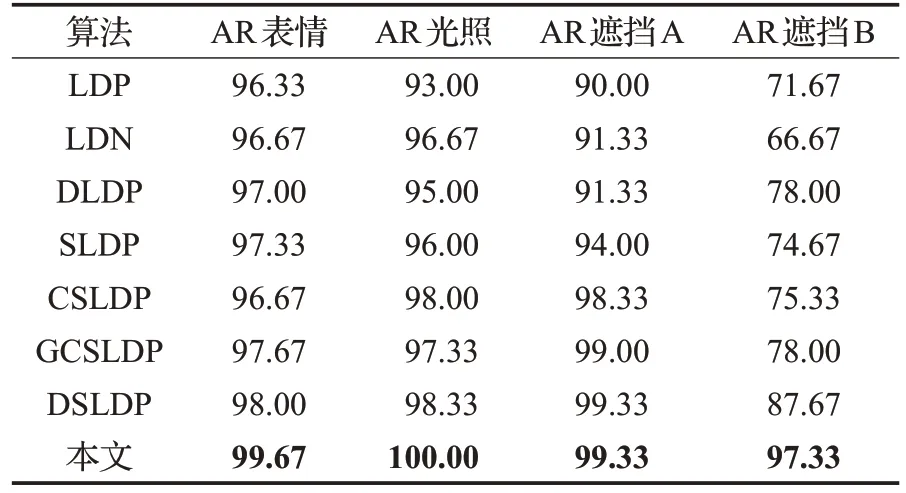
表3 各种算法在AR库下识别率 %
从表3 可以看出,本文算法在AR 库的各个子集下的识别率都有明显提升。
在光照、表情子集下,算法如果在光照、表情改变时依然能提取相同稳定的特征,则表现会更好。大部分算法在这两个子集下都表现出了较好的识别效果,这是因为大部分算法记录的是最大值或最小值对应的方向信息,这种方向信息往往有更好的鲁棒性。但LDP算法同等对待各个方向的信息,因此当条件发生变化时,识别性能较差。本文算法在表情子集下识别率相比LDP、LDN、DLDP、SLDP、CSLDP、GCSLDP、DSLDP 识别率分别提高了3.34 个百分点、3 个百分点、2.67 个百分点、2.34 个百分点、3 个百分点、2 个百分点、1.67 个百分点。本文算法在光照子集下相比LDP、LDN、DLDP、SLDP、CSLDP、GCSLDP、DSLDP 识别率分别提高了7 个百分点、3.33个百分点、5个百分点、4个百分点、2个百分点、2.67个百分点和1.67个百分点。在进行比较的算法中,DSLDP 表现最好。它主要记录了梯度信息,而本文算法在通过双偏差丰富梯度信息基础上,进一步补充了与梯度独立的灰度信息,特征更有区分性,因此识别率也更高。
在AR遮挡子集下,人脸的一些关键器官被遮挡了,可利用的信息大大减少。算法如果对没有遮挡的关键区域相关信息提取得不够充分,识别性能就会大大下降。AR 遮挡A 子集是墨镜遮挡,眼睛区域的信息受到很大干扰,LDP、LDN、DLDP、SLDP 方法的识别率都不足95%。本文算法相比LDP、LDN、DLDP、SLDP、CSLDP、GCSLDP 算法识别率分别提高了9.33 个百分点、8 个百分点、8 个百分点、5.33 个百分点、1 个百分点、0.33 个百分点;在AR 遮挡B 围巾干扰下,图像几乎丧失了嘴巴区域的细节,因此如果对人脸上半部分区域细节还原能力不够,识别率就会大大下降。可以看到进行比较的算法识别率已经低于80%,而本文算法依然达到了97.33%的识别率,相比LDP、LDN、DLDP、SLDP、CSLDP、GCSLDP、DSLDP 算法识别率分别提高了25.66 个百分点、30.66 个百分点、19.33 个百分点、22.66 个百分点、22 个百分点、19.33 个百分点、9.66 个百分点,远远好于同类算法。对比同类算法,本文算法充分利用了双重偏差,从不同角度提取了梯度特征,同时补充了灰度特征,融合后的双空间特征还原人脸细节的能力更强,因此在有大范围遮挡干扰时识别率依然最高,效果提升明显。
4 结束语
考虑到人脸图像的梯度空间和灰度空间都包含了大量的人脸特征信息,由此提出一种双偏差双空间局部方向模式的人脸识别方法。针对LDN类方法大多基于边缘响应算子获得梯度信息,缺少对灰度信息的有效利用问题,本文方法首先利用局部采样像素引入关联邻域信息,再以梯度绝对偏差信息来补充相对偏差信息,得到梯度空间的双偏差信息;然后与独立的灰度空间信息级联融合,更充分地描述了邻域边缘信息与纹理细节;最后对量化编码得到特征图进行自适应信息熵直方图加权处理,获取更强区分性的人脸特征向量。直观的特征图对比表明了本文方法的特征图具有更清晰的轮廓边缘和更丰富的纹理特征,实验数据也表明了同样的结果。本文方法在ORL和Yale库上分别达到了更高的识别率,尤其是在训练样本较少时性能提升明显;在AR库的表情、光照、遮挡A 和遮挡B 子集上的识别率明显高于其他方法,表明本文方法同时具有良好的鲁棒性。
