基于k均值聚类算法的集装箱堆存质量评价方法
2021-02-14王日金郑宇翔汤海亮陈霄辛晶昊
王日金 郑宇翔 汤海亮 陈霄 辛晶昊




1 研究背景
随着船舶大型化趋势的持续发展,远洋集装箱船舶在码头的单次靠泊装卸箱量不断上升,导致码头堆场面临堆存周期延长和堆存箱量超标等问题。大规模装卸作业对集装箱码头堆场管理提出较高要求,集装箱码头运营瓶颈逐渐从岸线转向堆场,堆场集装箱堆存质量成为影响集装箱码头运营管理的重要因素。[1]目前,业内尚未形成科学严谨的集装箱堆存质量评价方法,只能依赖人工经验对其进行粗略评价;但当堆场堆存箱量较多时,基于人工经验的评价方法需要耗费大量人力和物力。在此背景下,以自动化和可靠的集装箱堆存质量评价方法替代基于人工经验的评价方法,成为现阶段我国集装箱码头的迫切需求。
k均值聚类算法是一种常见的数据挖掘算法,用于多特征样本的分类,如图像分割、路径分类、等级划分等。杨艳等[2]通过优化k均值聚类算法特征空间的权重,获得更优的图像分类结果。李爽等[3]通过改进k均值聚类算法的亲和距离函数提升算法的聚类稳定性,从而在航线分类实验中得出更优的聚类结果。杨善林等[4]提出k均值聚类算法的距离代价函数,建立k取值有效性的检验方法。雷小锋等[5]通过建立加权连通图和合并子簇方法,构造k均值聚类算法的子簇交集,从而提升算法效率。李洁等[6]提出基于特征加权的模糊k均值聚类算法,得出各维特征对分类结果的贡献度。受以上研究成果的启发,本文基于k均值聚类算法设计集装箱分类算法,实现对集装箱的合理分类,并结合集装箱码头业务逻辑,建立集装箱堆存质量评价方法,实现集装箱堆存质量的自动化评价。
2 问题描述
集装箱码头船舶作业主要分为出口作业(包含集港、堆存、配载、装船等环节)和进口作业,其中出口作业的装船环节对堆场集装箱堆存质量的要求较高。为了确保船舶稳泊和航行安全,集装箱在船上的分布必须符合相应要求,从而对集装箱装船顺序提出一定要求。在装船作业过程中,岸桥、场桥和内集卡等设备相互配合,从堆场提取集装箱并依次装船。出口箱区的集装箱堆存质量较差容易导致场桥移动频繁、翻箱作业增加等问题,从而降低码头装船作业效率;因此,出口箱区的集装箱堆存质量是码头运营管理的核心问题。
出口箱区的集装箱堆存质量主要由集港环节决定。货主通常在船舶到港前的4~7 d将集装箱运至码头堆场,码头按照集装箱的箱型、出口航次、卸货港口和质量等属性分配箱区位置。由于无法提前获得集港集装箱的数量、质量、箱型和到达次序等信息,码头通常会制订堆场集港位置策略,并结合堆场堆存箱量、作业繁忙度和航线规划等,实时检测堆场集装箱堆存质量,调整集港位置策略。
为此,有必要建立堆场集装箱堆存质量评价方法,按相应属性对集装箱进行分类,并结合码头业务逻辑,对分类后的堆场箱区位置进行统计,从而评价同类型集装箱集港后在堆场堆存的科学性和合理性。多特征属性样本分类求解适合采用聚类算法,而集装箱类别可根据船方装卸工艺要求获得;因此,采用聚類算法中的k均值聚类算法划分集装箱类别,在此基础上建立集装箱堆存质量评价方法。由表1可见,集装箱的主要特征属性包括箱区位置、船舶箱位号、箱型、卸货港口和质量等。
3 模型构建
3.1 模型说明
模型符号定义如下:x为样本;m为特征属性; 为特征的权重系数;d为欧几里得距离;D为距离矩阵;k为子集合数量;G为子集合;e为簇的聚类中心;W为损失函数。
给定n个集装箱样本组成集合X,X={x1,x2, ,xn};i为样本序号,i∈{1,2, ,n};x[m]为样本的特征属性;G为子集合,G={G1,G2,G3, ,Gk},Gi=X,Gi∩Gj= 。首先,选取k个样本作为簇中心;然后,将样本分到与簇中心的亲和距离最小的簇中,计算簇中心到簇内各样本的距离之和,将其作为损失函数,并持续更换样本作为簇中心,实现重复迭代;
最后,找到使损失函数值最小的分类组合,将其作为最优子集合划分。
3.2 算法设计
3.2.1 亲和距离函数
为了合理表达样本属性间的关系,设置亲和距离函数,亲和距离越小表示关系越近。参考文献[3]的方法,对样本的各个特征进行加权,以保证亲和距离函数合理表达业务,加权系数由人工经验给出。集装箱的特征属性分为数值型和字符型两种,分别设置两种特征的亲和距离。
3.3 算法流程
算法要求输入样本集合X,输出聚类后的集合G *,具体流程如下。
步骤一:从样本中随机选取k个样本作为第0代聚类中心,即t=0,则初始聚类中心为。
步骤二:将各样本分配到距离最近的聚类中心的簇中,构成聚类结果G t,并计算聚类结果的损失函数值。
步骤三:重新选取k个样本作为聚类中心{},执行步骤二。
步骤四:当所有聚类中心组合遍历完成后,输出损失函数值最小的聚类结果G *。
步骤五:统计G *中每个簇内同箱区位置的样本占比,将其作为集装箱堆存质量得分并输出。
4 算例分析
选取2020年靠泊梅东集装箱码头的20艘大型远洋船舶作为样本进行试验,并通过分析模型评价分值与人工评价分值的相关性,验证模型评价方法与人工评价方法的相似性。试验中,人工评价分值由码头管理者根据经验给出,取值为1~10的整数。
4.1 参数设置
根据船方装卸工艺要求设置k值,并根据经验设置集装箱的特征属性参数(见表2)。
4.2 结果分析
试验结果中的集装箱堆存质量得分、人工评价分值、损失函数值和k值均无计量单位。
4.2.1 集装箱堆存质量得分与人工评价分值的关系
试验结果显示,集装箱堆存质量得分与人工评价分值高度正相关(见图1),两者的相关系数为0.97,说明模型评价方法与人工评价方法的结果高度一致。
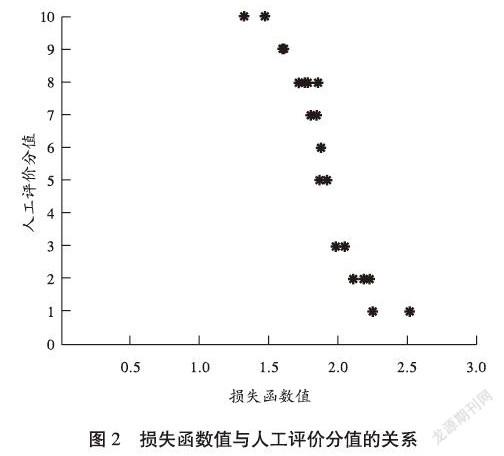
4.2.2 损失函数值与人工评价分值的关系
试验结果显示,损失函数值与人工评价分值高度负相关(见图2),两者的相关系数为 0.94,说明损失函数值越小,集装箱堆存质量得分越高,即聚类过程的损失函数越小,集装箱堆存质量越高。
4.2.3 k值與集装箱堆存质量得分和人工评价分值的关系
试验结果显示,k值与集装箱堆存质量得分和人工评价分值均为负相关(见图3和图4),相关系数分别为 0.46和 0.42,说明集装箱类别越多,集装箱堆存质量越差,这与实际业务情况相符。k值与人工评价分值的相关系数绝对值小于k值与集装箱堆存质量得分的相关系数绝对值,主要原因是:当集装箱类别较多时,码头管理者认为集装箱堆存管理难度提升,从而会根据主观判断适当提高分值。
5 结束语
随着港口数字化建设的持续推进,数据挖掘算法逐步推广应用于港口管理领域。基于k均值聚类算法的集装箱堆存质量评价方法实现集装箱堆存质量的自动化评价,从而为堆场数字化管理提供支持。目前该评价方法只能用于单船出口集装箱堆存质量评价,尚未实现全堆场集装箱堆存质量评价。未来可以继续探索全堆场集装箱堆存质量评价方法,从而实现集装箱堆场自动化管理。
参考文献:
[1] 姜东瑞. 基于排队论的专用集装箱堆场空间分配问题[D]. 大连:大连海事大学,2020:1-4.
[2] 杨艳,许道云. 优化加权核K-means聚类初始中心点的SLIC算法[J]. 计算机科学与探索,2018,12(3):494-501.
[3] 李爽,史国友,高邈,等. 基于改进谱聚类算法的航路辨识[J]. 上海海事大学学报,2019,40(4):1-6.
[4] 杨善林,李永森,胡笑旋,等. K-MEANS算法中的K值优化问题研究[J]. 系统工程理论与实践,2006(2):97-101.
[5] 雷小锋,谢昆青,林帆,等. 一种基于K-Means局部最优性的高效聚类算法[J]. 软件学报,2008(7):1683-1692.
[6] 李洁,高新波,焦李成. 基于特征加权的模糊聚类新算法[J]. 电子学报,2006(1):89-92.
(编辑:张敏 收稿日期:2021-09-02)
