生成对抗式分层网络表示学习的链路预测算法
2021-02-05高宏屹张曦煌
高宏屹,张曦煌,王 杰
(江南大学物联网工程学院,江苏无锡 214122)
0 概述
随着互联网的高速发展,各个领域的复杂网络[1]变得越来越庞大。在这些复杂网络中,所有顶点代表现实系统中的实体,顶点之间的链接代表实体之间的联系。复杂网络中的链路预测[2]既包含对已经存在但未知的链接的预测,也包含对未来可能产生的链接的预测。
在现实世界中的链路预测有着广泛的应用场景,如在复杂的社交网络[3]中,通过链路预测方法可以判断两个人之间是否存在着一定的联系,这样就可以为用户进行朋友推荐,在电子商务网络中,也可以通过链路预测方法为用户进行商品推荐。现在已知的链接可能只是网络中所有顶点间存在的链接的较少部分,网络中还有着大量未知的但可能存在的链接。如果只通过收集数据、实验等方法了解这些链接,则需要耗费大量的人力物力。因此,研究链路预测算法具有非常重要的意义。
目前传统的链路预测算法计算效率较低,且不能很好地保留网络的高阶结构特点。本文提出一种生成对抗式分层网络表示学习算法以进行链路预测。该算法对网络图进行分层,并利用生成式对抗模型递归回溯地求得每一层网络图中顶点的低维向量表示,将其作为上一层网络图的初始化,直至回溯到原始网络图,求得原始网络图中所有顶点的低维向量表示进行链路预测。
1 相关工作
目前传统的链路预测算法主要包括基于似然分析的链路预测算法和基于相似性的链路预测算法[4]。
1)基于似然分析的链路预测算法是根据网络结构的产生和组织方式,以及目前已知的链路来计算网络的似然值。然后将似然值最大化,计算出每一对顶点间存在边缘的概率。
2)在基于相似性的链路预测算法中,如果两个顶点之间存在链接,则代表这两个顶点是相似的。因此,基于相似性的链路预测算法最主要的问题就是如何确定两个顶点的相似性。基于相似性的链路预测分为以下两类:
(1)基于顶点属性相似性的链路预测[5]。此类链路预测方法大多应用在社交网络等含有标签的复杂网络中。利用顶点的标签,可以方便地计算出顶点属性的相似性,两个顶点的属性越相似,这两个顶点之间存在边的概率就越大。
(2)基于网络结构相似性的链路预测[5]。此类链路预测方法大多应用在难以获取顶点属性信息的复杂网络中。这类方法主要分为基于局部信息的相似性指标、基于路径的相似性指标和基于随机游走的相似性指标。基于局部信息相似性的指标主要包括共同邻居(Common Neighbors,CN)指标[4]、优先链接(Preferential Attachment,PA)指标[4]、AA(Adamic-Adar)指标[4];基于路径的相似性指标主要包括局部路径(Local Path,LP)指标[4]和Katz指标[4];基于随机游走的相似性指标主要包括SimRank指标[6]、平均通勤时间指标[7]和Cos+指标[7]。
传统的链路预测算法普遍是根据邻接矩阵的稀疏表示而设计的,计算成本高,计算效率较低,且无法保留网络图的高阶结构特性,因此,无法在大规模网络上运行。
近年来,随着网络表示学习(Network Representation Learning,NRL)[8]的发展,基于网络表示学习的链路预测算法取得了很好的效果。该算法根据网络中顶点的邻近性,训练得到顶点的低维向量表示,从而计算出顶点间存在边缘的概率,它能很好地保留网络结构,降低计算成本,提高计算效率。
2014年,PEROZZI等人提出的Deepwalk[9]算法是利用构造节点在复杂网络中随机游走的路径,生成节点序列,并利用Skip-Gram和Hierarchical Softmax[10]模型对节点序列进行处理,最终得到顶点的向量表示。2015年,TANG等人提出的LINE[11]算法是基于Deepwalk进行改进,LINE通过显式地建模一阶邻近性和二阶邻近性来学习顶点表示,而不是利用随机游走来捕获网络结构。2016年,GROVER等人提出的Node2vec[12]算法同样是在Deepwalk的基础上进行的改进,在随机游走的过程中设置一个偏置参数,通过控制偏置参数的大小来控制模型的搜索方式是偏向于宽度优先搜索[13]还是深度优先搜索[14]。2018年,WANG等人提出了GraphGAN[15]算法,该算法用生成式对抗网络学习网络图中顶点的低维向量表示。
上述网络表示学习算法存在两个共同问题:1)仅关注网络图的局部特性,忽视了网络图的高阶结构特性;2)在没有先验知识的情况下,通常用随机数来初始化向量表示,存在收敛到较差的局部最小值的风险。
本文算法根据原始网络图的一阶邻近性和二阶邻近性对原始网络图进行分层。每一次分层处理都将上一层子网络图中具有较高一阶邻近性和二阶邻近性的顶点进行合并,以形成规模更小的子网络图。这样不仅保留了原始网络图的局部特性,并且在规模变小的过程中原始网络图的高阶邻近性得到了降阶,使高阶邻近性更容易显现出来,从而有效地保留了网络图的高阶邻近性。本文算法将规模较小的子网络图学习到的向量表示作为其上一层子网络图的初始向量表示,避免了随机初始化导致的局部最小值的风险。
2 算法描述
2.1 算法定义描述
本文主要运用以下5种定义:
1)复杂网络:设G=(V,E)为给定的网络图,其中V={ν1,ν2,…,νV}表示顶点集,每个顶点表示一个数据对象表示边集。对于给定的一个顶点νc,设N(νc)为与顶点νc直接相连的顶点(即νc的直接邻居)。
2)生成式对抗网络(GAN):生成式对抗网络包括生成器和鉴别器两部分,生成器和鉴别器都是一个完整的神经网络,通过生成器和鉴别器相互博弈,可以达到根据原有数据集生成近似真实数据的新数据。
首先对生成器输入一个真实的数据分布,生成器模仿真实的数据集,生成一个近似真实的数据,将其与真实数据集一起输入给鉴别器。鉴别器则根据自身知识对输入数据进行鉴别,尽量为其分配正确标签,再与真实标签进行对比,并根据对比结果进行自我更新,同时反馈给生成器一个反馈信息。生成器根据鉴别器传回的反馈信息进行自我更新。以此循环,直到生成器和鉴别器达到拟合为止,最终生成器可以模拟出与真实数据几乎一致的数据。
3)一阶邻近性[11]:网络中的一阶邻近性表示两个顶点之间的局部相似度,对于两个顶点u和v,如果它们之间存在边缘(u,v),则顶点u和v具有一阶邻近性。
4)二阶邻近性[11]:网络中一对顶点之间的二阶邻近性是它们的邻域网络结构之间的相似性。如果两个顶点u和v拥有相同的邻居节点,则顶点u和v具有二阶邻近性。
5)高阶邻近性:网络中一对顶点之间的高阶邻近性是全局网络结构之间的相似性。以三阶邻近性为例,对于两个顶点u和v,如果它们分别与两个具有二阶邻近性的顶点相连,则顶点u和v具有三阶邻近性。
2.2 基本算法指标
本文主要应用以下3种指标:
1)AA指标:对于复杂网络中的节点,它的邻居的数量称为这个节点的度。AA指标根据两个节点共同邻居的度信息,为两个节点的每个共同邻居赋予一个权重,度越小的邻居节点权重越大。AA指标定义为:

其中,N(x)为节点x的邻居,k(x)=|N(x)|为节点x的度。每个共同邻居的权重等于度的对数的倒数。
2)局部路径指标(Local Path,LP):LP指标考虑两个顶点间路径长度为2和3的共同邻居,利用顶点间路径长度为2和3的不同路径的数量信息来表示顶点之间的相似度。LP指标定义为:

3)Katz指标:Katz指标在LP指标的基础上考虑两顶点间所有路径长度的共同邻居,对路径长度较小的共同邻居赋予较大权重,定义为:

其中,β为权重衰减因子,β取值小于邻接矩阵最大特征值的倒数。
2.3 算法框架
本文算法框架如图1所示。

图1 本文算法框架Fig.1 Framework of the proposed algorithm
算法主要分为3个部分:
1)网络图分层处理。如图1中的①、②所示,利用网络图分层算法(NetLay)对原始网络图G0递归地进行边缘折叠和顶点合并,形成多层规模逐层变小的子网络图G0到G(n图1中以三层结构举例,n=2)。

2.4 网络图分层
本文利用网络图分层算法对原始网络图G进行分层,生成一系列规模逐层变小的子网络图G0,G1,…,Gn,其中G0=G。
在网络分层算法中包含边缘折叠和顶点合并两个关键部分。
2.4.1 边缘折叠
边缘折叠是一种可以有效保留顶点间一阶邻近性的算法,如图2所示,顶点ν2与顶点ν1相连,且ν2与ν1不存在于任何一个闭环中,则说明顶点ν2与顶点ν1具有较高的一阶邻近性,算法对网络图中具有较高一阶邻近性的顶点进行边缘折叠。如图2过程a所示,将边(ν1,ν2)折叠,把顶点ν1和顶点ν2合并成一个顶点ν1,2。利用边缘折叠方法可以将网络图中具有一阶邻近性的顶点进行合并,合并后的子网络图很好地保留了原始网络图中顶点间的一阶邻近性。

图2 网络图分层算法示例Fig.2 Example of network graph layering algorithm
2.4.2 顶点合并
在现实世界的网络图中,有大量的顶点无法通过边缘折叠算法进行合并,但这些顶点间可能存在大量的共同邻居,即具有较高的二阶邻近性。本文用顶点合并方法对这些具有较高二阶邻近性的顶点进行合并,不仅可以有效地缩小网络图的规模,还可以保留原始网络图中顶点间的二阶邻近性。如图2过程b所示,在网络图中,顶点ν1,2与ν6,7都具有共同邻居ν3、ν4和ν5,它们具有较高的二阶邻近性,则可以利用顶点合并方法将它们合并成一个顶点ν1,2,6,7。
2.4.3 网络图分层算法NetLay
网络图分层算法对每一层网络图先进行边缘折叠,再进行顶点合并,直至生成规模小于所设定的阈值的子网络图(本文设定阈值为顶点数小于原始网络图中顶点数的1/2),网络图分层算法如下:
算法1网络图分层算法NetLay

由于边缘折叠算法保留了原始图的一阶邻近性,顶点合并算法保留了原始图的二阶邻近性,因此分层后的网络图与原始网络图具有相似的结构特性,很好地保留了原始图的局部结构,且与原始图相比,规模减小了很多,所以更易于映射到低维向量空间。
网络分层算法对不易显现的高阶邻近性进行降阶,有效地保留了原始网络图的高阶结构特性。如图3所示(以三阶邻近性为例),在左侧网络图中,ν3和ν4具有三阶邻近性,且由图中可以看出ν3和ν4具有较高的结构相似性。根据上述网络分层算法,对左侧网络图进行边缘折叠以及顶点合并,得到右侧子网络图。可见,由于将ν1和ν2合并为一个顶点ν1,2,因此ν3和ν4间的三阶邻近性降阶为二阶邻近性,且仍保留相似的结构特性。
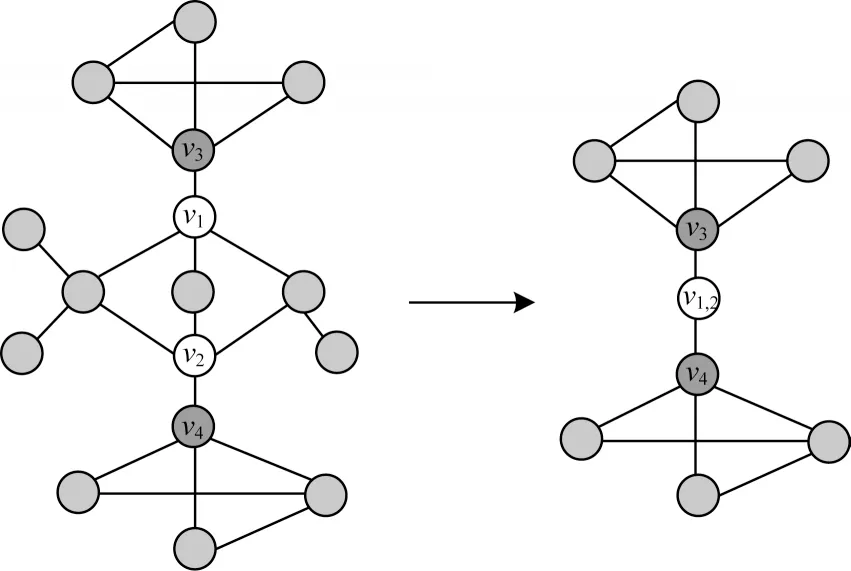
图3 网络图分层示例Fig.3 Example of network graph layering
2.5 EmbedGAN网络框架
对网络进行分层后,递归地用生成式对抗网络EmbedGAN处理每一层网络图。EmbedGAN框架由生成器G(ν|νc;θG)和鉴别器D(ν,νc;θD)两部分组成。
对于给定的一个顶点νc,条件概率ptrue(ν|νc)表示顶点νc的真实的连通性分布。生成器G通过有偏差的随机游走[16]方法抽取节点,并设置两个偏置系数来控制随机游走的方式,试图生成尽可能相似于νc的真实的直接邻居ν,来拟合νc的真实的连通性分布ptrue(ν|νc)。鉴别器则尽可能地区分这些顶点是与νc真实相连的顶点还是由生成器生成的顶点。生成器和鉴别器类似于在做一个关于价值函数V(G,D)的最大最小值游戏,通过交替地进行最大化和最小化价值函数V(G,D)来确定生成器和鉴别器的最佳参数,如式(4)所示。在这个竞争中,生成器和鉴别器共同进步,直到鉴别器无法区分生成器生成的分布与真正的连通性分布为止。
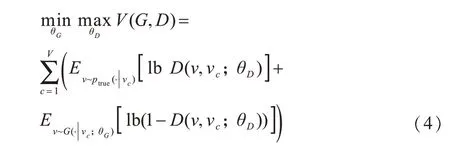
2.5.1 鉴别器优化
本文将鉴别器D(ν,νc;θD)定义为两个输入顶点的低维向量表示内积的sigmoid函数,如式(5)所示:
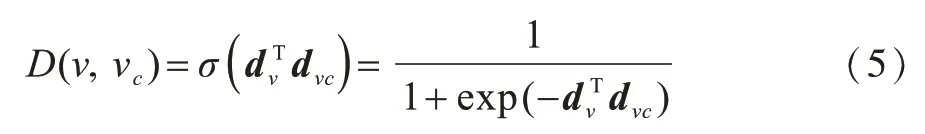
其中,dν和dνc是鉴别器低维向量表示矩阵中顶点ν和νc对应的低维向量表示。当输入为由生成器生成的负样本和真实存在的正样本时,鉴别器根据sigmoid函数求得源节点νc和邻居节点ν之间存在边缘的概率,并为所有正负样本分配标签,再与真实标签进行对比。根据对比结果,使用梯度下降法来更新顶点ν和νc的低维向量表示dν和dνc,使鉴别器为正负样本分配正确标签的概率最大化。
在随机梯度下降的过程中,算法设置的学习速率会随着迭代次数的增加而递减,当梯度较大时,学习速率也相对较大,使求解更迅速。当梯度慢慢下降时,学习速率也随之减小,使梯度下降过程更稳定,如式(6)所示:
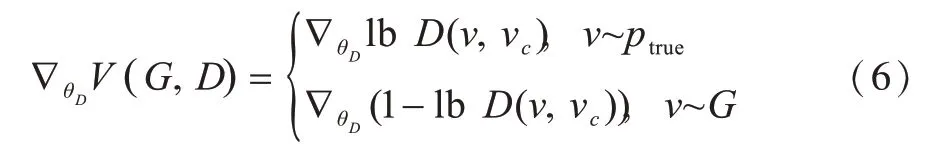
2.5.2 生成器优化
生成器尽可能地采样近似于真实连通性分布的负样本,使鉴别器为正负样本正确分配标签的概率最小化。由于生成器的采样是离散的,因此V(G,D)关于θG的梯度计算如式(7)所示,生成器根据鉴别器反馈的信息,利用梯度下降法更新生成器低维向量表示矩阵。
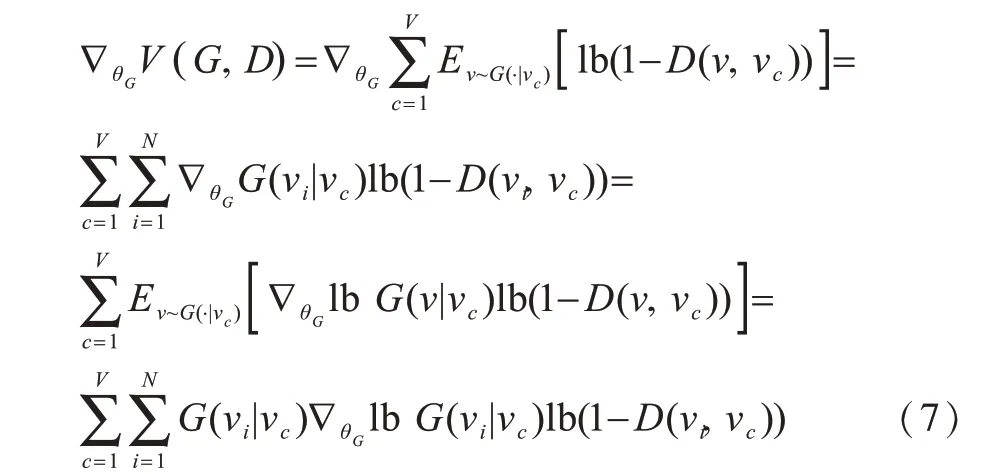
2.5.3 生成器采样方法
生成器采用步长为l的有偏差的随机游走方式对负样本进行采样。假设源节点为νc,当前节点为ν,上一跳节点为t,则需要决定下一跳节点x。定义N(ν)为顶点ν的直接邻居的集合(即图中所有与ν直接相连的顶点),ν与它的邻居νi∈N(ν) 的转移概率定义如式(8)所示:
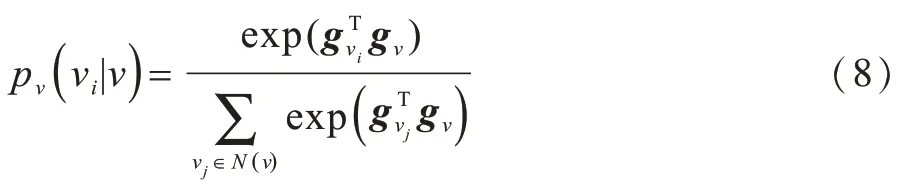
在每一步游走时,根据式(8)计算出当前节点ν与其邻居节点的转移概率pν(νi|ν)。再用随机游走的偏差系数α对转移概率pν(νi|ν)进行加权处理,得出非标准化的转移概率wν(νi|ν)=α(t,νi)·pν(νi|ν),根据非标准化转移概率,抽取随机游走的下一跳节点。
α(t,νi)设置如式(9)所示:

参数p负责控制向前回溯的概率。如图4所示,当参数p设置为一个较高的值(大于max(q,1))时,则使下一跳节点重新遍历已遍历过的顶点的概率变小。反之,当p设置为一个较低的值(小于min(q,1))时,向前回溯到顶点t的概率变大。
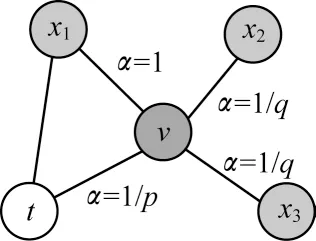
图4 随机游走中偏差系数的设置Fig.4 Setting of deviation coefficient in random walk
参数q负责控制下一跳节点是否靠近上一跳节点t。如图4所示,当参数q>1时,随机游走方式类似于宽度优先搜索,倾向于访问与上一跳节点t相连的顶点。当参数q<1时,随机游走方式则类似于深度优先搜索,倾向访问远离上一跳节点t的顶点。
通过改变参数p和q的大小,可以控制随机游走的方式。这样,抽取的节点就并不是一味地远离给定的源节点νc,从而提高采样效率。
当得到非标准化转移概率wν(νi|ν)后,再利用Alias Method[17]选取一个节点作为下一跳节点x。当游走的步长达到设置的长度l时,当前节点ν就被抽取为负样本顶点,生成器的采样策略如算法2所示。
算法2生成器采样策略

2.5.4 EmbedGAN算法
EmbedGAN算法框架如图5所示,EmbedGAN算法模型是将输入向量作为生成器和鉴别器的初始向量表示矩阵。每次迭代,生成器为每个源节点生成一定数量的负样本,并抽取等量的正样本交给鉴别器进行训练,见图5中的①。鉴别器根据自身低维向量表示,对正负样本分配标签,并与真实标签进行对比得到误差。再利用随机梯度下降方法更新自身低维向量表示以最小化误差,见图5中的②。鉴别器将误差信息传递给生成器,生成器根据鉴别器反馈的误差信息对自身低维向量表示进行更新。生成器与鉴别器在对抗中不断更新自身低维向量表示,直到鉴别器无法区分正负样本为止,生成器的低维向量表示就是最终输出的网络图顶点的低维向量表示,见图5中的③。
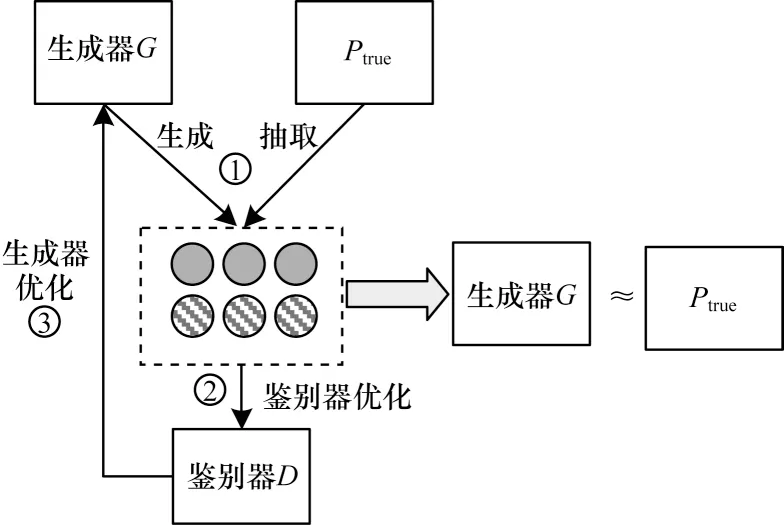
图5 EmbedGAN算法框架Fig.5 EmbedGAN algorithm framework
利用生成式对抗网络EmbedGAN生成网络图中顶点的低维向量表示算法,如算法3所示。
算法3 EmbedGAN算法

2.6 GAHNRL算法
本文GAHNRL算法流程如下:
1)根据算法1中网络图分层算法对原始网络图G进行分层,生成一系列规模逐层减小的子网络图G0,G1,…,Gn,其中G0=G。
2)利用Node2vec算法对规模最小的子网络图Gn进行预处理,生成该层子网络图中顶点的初始向量表示。
3)从Gn开始,递归地将每层子网络图以及图中顶点的初始向量表示输入至生成式对抗网络中进行训练。
4)利用算法3中EmbedGAN算法学习得到Gn中顶点的低维向量表示,并将学习到的低维向量表示作为上一层子网络图Gn-1的初始向量表示,递归地进行回溯学习,直到学习至初始网络图G0为止,最终得到所有顶点的低维向量表示。
GAHNRL算法框架如算法4所示。
算法4GAHNRL算法

3 实验结果与分析
3.1 实验数据集
本文选择了4个不同领域中具有代表性的真实网络数据集,其中包括社交网络Facebook[18]、Wiki-Vote[19]、合作网络CA-GrQc[20]及细胞代谢网络Metabolic[21]。4个数据集均忽略各边的权重与方向,详细信息如表1所示,其中,N表示节点数,E表示边数。

表1 网络数据集信息Table 1 Information of networks datasets
3.2 评价标准
本文实验在原始网络图中随机抽取10%的边缘作为正样本加入测试集,90%作为训练集,在随机生成与测试集中正样本数量相同的边作为负样本加入测试集。
本文采用准确率(Precision)和AUC指标来评价本文算法链路预测任务上的性能,准确率和AUC指标是链路预测任务中最常用的两种评价指标。
Precision是在测试集中L个预测边被准确预测是否存在链接的比例。假如测试集中有L个正样本和L个负样本,根据算法计算每个样本中顶点对间可能存在链接的概率,并按从大到小排列,若排在前L个的样本中,有m个正样本,则Precision定义为m/L。
AUC是在测试集中随机抽取一个正样本和一个负样本,即正样本分数高于负样本分数的概率。在n次独立重复的实验中,有n1次正样本分数高于负样本分数,有n2次正样本分数等于负样本分数,则AUC的定义为:

3.3 实验设置
在本文算法中,步长l设置为10,针对不同的参数p和q设置在4组数据集上进行实验。在Metabolic数据集上的准确率如表2所示,在Facebook数据集上的准确率如表3所示,在Wiki-Vote数据集上的准确率如表4所示,在CA-GrQc数据集上的准确率如表5所示。由表2~表4可知,在Metabolic、Facebook、Wiki-Vote 3个数据集上,当参数p设置为1.5,参数q设置为1时,实验效果最好(见粗体)。在CA-GrQc数据集上,当参数p设置为1,参数q设置为1时,实验效果最好,但是当参数p设置为1.5,参数q设置为1时,实验效果与最佳结果相差不大,所以本文对所有数据集均将参数p设置为1.5,参数q设置为1。
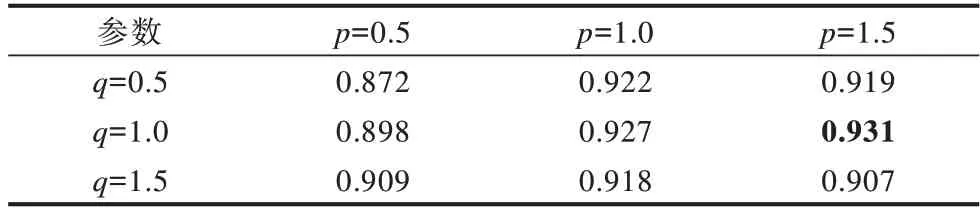
表2 在Metabolic数据集上不同参数设置的实验结果Table 2 Experimental results for different parameter settings on Metabolic dataset

表3 在Facebook数据集上不同参数设置的实验结果Table 3 Experimental results for different parameter settings on Facebook dataset

表4 在Wiki-Vote数据集上不同参数设置的实验结果Table 4 Experimental results for different parameter settings on Wiki-Vote dataset

表5 在CA-GrQc数据集上不同参数设置的实验结果Table 5 Experimental results for different parameter settings on CA-GrQc dataset
3.4 结果分析
为证明实验的稳定性和准确性,本文进行了10次重复实验,并将10次实验结果的平均值作为最终的结果。本节介绍了3种传统算法和4种网络表示学习算法与本文算法在相同条件下链路预测准确率和AUC的对比,准确率如表6所示,AUC如表7所示(其中前两个最优值用粗体突出显示)。

表6 不同算法准确率对比结果Table 6 Comparison results of different algorithms accuracy
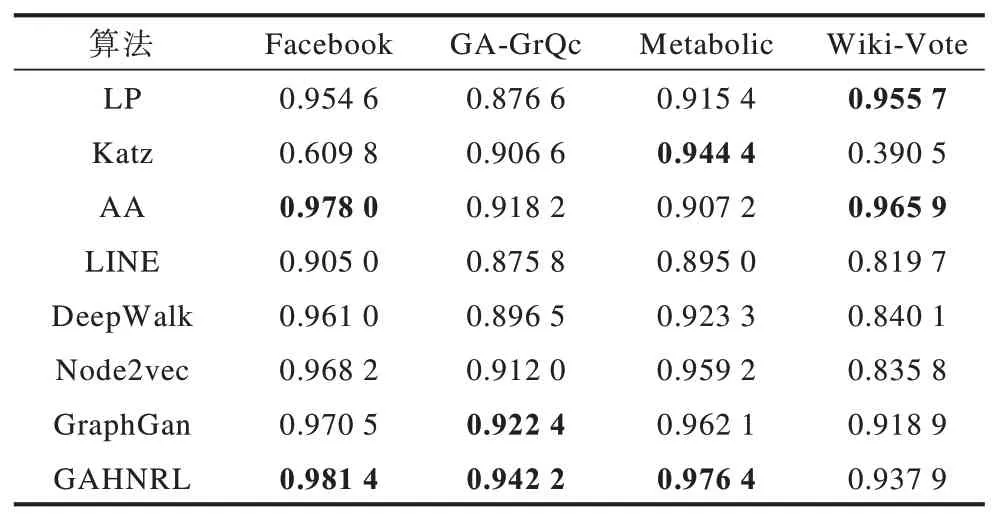
表7 不同算法AUC对比结果Table 7 Comparison results of different algorithms AUC
在表6、表7中,传统算法包括LP、Katz和AA,网络表示学习算法包括LINE、DeepWalk、Node2vec和GraphGAN。
从表6和表7中可以看出:
1)本文GAHNRL算法在4个数据集上的准确率和AUC值均优于4种网络表示学习算法和传统Katz算法。
2)与传统LP算法相比,除Wiki-Vote数据集外,本文算法在其他3个数据集上的准确率和AUC值均优于LP算法。
3)与传统AA算法相比,本文算法在GA-GrQc数据集和Metabolic数据集上准确率和AUC值优于AA算法,在Facebook数据集上AUC值优于AA算法。
传统算法是采用one-hot的形式表示网络顶点的邻接矩阵,计算成本较大且无法保留网络图的高阶结构特性。当训练集中的样本数减少时,传统算法无法保持算法的稳定性,准确率明显降低。而本文算法对网络图进行分层处理,更好地保留原始网络图的高阶结构特性,因此在训练集样本很少的情况下具有较好的稳定性。本文算法与传统算法在样本数减少的情况下准确率变化如图6所示。

图6 不同数据集上准确率变化结果Fig.6 Results of accuracy changes on different datasets
实验按照10%~90%划分成训练集,分别测试在不同训练集比率下准确率的变化。通过观察图6可知,由于AA算法采取one-hot的形式表示网络的邻近关系,因此在网络规模较小,且已知的可训练的边缘充足时,在Facebook数据集和Wiki-Vote数据集中,训练集比率为40%~90%时优于GAHNRL,但是当训练集比率为10%~30%时,网络中可用于训练的已知边缘减少,AA算法的准确率明显下降,但GAHNRL算法能保持较好的稳定性。如图7所示,由于AA算法采用one-hot形式,占用内存较多,而GAHNRL算法采用低维向量来表示邻接矩阵,内存占用率明显小于AA算法。从整体来看,GAHNRL算法波动较小,性能更优。

图7 AA算法和GAHNRL算法的内存占用率Fig.7 Memory usage of AA algorithm and GAHNPL algorithm
4 结束语
链路预测作为复杂网络分析的重要研究方向,具有较强的应用前景。本文提出一种生成式对抗分层网络表示学习的链路预测算法。该算法保留原始网络图的局部特性与高阶结构特性,将生成式对抗网络模型运用到网络表示学习中以达到更好的效果,通过对网络图进行分层,将下一层子网络图学习获得的向量表示作为上层网络图的初始向量表示进行迭代求解,解决随机初始化可能产生的局部最小值的问题。实验结果表明,与LP、Katz等算法相比,该算法性能更加稳定。下一步将针对异构网络和动态网络对算法进行优化,并加入标签及节点属性信息,使算法具有更广的应用场景。
