面向5G边缘计算的Kubernetes资源调度策略
2021-02-05孔德瑾姚晓玲
孔德瑾,姚晓玲
(太原理工大学财经学院,太原 030024)
0 概述
边缘计算[1-2]作为云计算的演进,将应用程序托管方式从集中式数据中心下沉到网络边缘[3],在靠近用户的网络边缘提供存储与计算能力,从而降低用户访问延时,是5G网络实现低延迟和提升带宽速率的关键技术之一。容器云[4-5]在传统云环境中得到广泛应用,是边缘计算的重要支撑技术[6],然而边缘计算具有与传统云计算环境不同的特征,在业务场景方面,AR/VR、4K/8K视频等应用部署于边缘会给边缘云带来更大的流量压力,此外随着物联网的兴起,边缘计算Node也面临着海量物联网终端超大连接数的压力,在流量特征方面,移动用户特有的移动性,可能会导致边缘计算流量随着时间、地点而变化,进而触发边缘云内容器的需求变化,在网络环境方面,受限于部署环境,网络边缘存储、计算、带宽等资源非常稀缺。因此,在5G边缘计算场景下,容器云的资源调度机制将面临更大挑战,若将应用部署在不合适的Node上,会增大扩缩容频次,影响应用的性能并造成资源的浪费。
Kubernetes(K8s)是应用最为普遍的容器云编排管理系统[7],广泛应用于边缘计算场景[8-9],其资源调度策略首先根据用户申明的最小资源需求过滤掉不符合要求的Node,再将Node的剩余CPU利用率、剩余内存利用率作为评价指标,利用加权求和方式对候选Node评分,选择评分最高的Node进行部署。这种调度策略有以下弊端:没有考虑应用对于带宽、磁盘等资源的需求,无法对边缘计算场景下带宽、磁盘资源倾向型应用进行合理的调度;对于需求各异的应用,Kubernetes采用固定的求和权重对Node评分,不能满足应用的个性化资源需求。上述不足导致Kubernetes原生资源调度机制难以适用于5G时代的边缘计算场景。
本文针对Kubernetes原生资源调度策略的不足,提出一种基于权重自学习的Kubernetes容器调度机制WSLB。增加带宽、磁盘两类指标,在Node过滤阶段和优先级计算阶段,将4类剩余资源均作为评价指标,改进了K8s原生调度策略无法满足带宽型、磁盘型Pod应用调度需求的不足。通过部署于Node的监控代理,采集Pod动态资源利用率,根据Pod运行过程中的资源占用率计算并调整Pod的资源权重集合,资源权重集合衡量该Pod的资源倾向,当创建Pod时,WSLB根据Pod的最小资源需求过滤不符合要求的Node,利用资源权重集合对候选Node的各类剩余资源利用率加权求和,得到候选Node的优先级,选择优先级最高的Node进行部署。WSLB将某项资源需求大的应用调度到该资源剩余较多的Node,避免Node由于某个资源被过度分配从而导致整个Node无法再分配新容器的问题。
1 Kubernetes调度策略
在Kubernetes中,Node是执行任务的载体,以物理服务器或虚拟机的形式存在。Pod是一个应用实例,为Kubernetes调度的最小单位,用户在创建Pod时,Kubernetes采用的调度策略如下[10-11]:
1)第一阶段进行Node过滤,过滤掉不满足Pod最小资源需求的Node,支持的过滤策略包括端口冲突、CPU、内存容量检测和服务占用等。
2)第二阶段称为Node优先级计算,Kubernetes将剩余的Node根据CPU和内存空闲资源率进行综合评分,按照评分的大小排序选出最合适的Node。最后将Pod绑定到选出的目标Node,调度器完成容器应用的部署[12]。目前支持的优先级评分函数主要有以下3种:
(1)LeastRequestedPriority函数:由Node空闲资源与Node资源总量的比值来决定Node评分,空闲资源越多,评分越高,CPU和内存具有相同权重值,该函数是应用最多的评分函数。
(2)BalancedResourceAllocation函数:CPU和内存使用率越接近的Node评分越高,该函数用于简单地调节在部署Pod应用后各Node的CPU和内存资源利用率的均衡性。
(3)SelectorSpreadPriority函数:对于属于同一个Service、Replication Controller的Pod副本,尽量调度到不同的Node上。
此外,调度函数还包括NodePreferAvoidPods-Priority、NodeAffinityPriority、TaintTolerationPriority等一系列特殊的评分函数。
图1为Kubernetes默认资源调度策略示例,令资源集合R={CPU,内存,带宽,磁盘},待部署Pod的资源最小需求量r表示部署该Pod所需的上述4类资源的最小值,r={4.0,0.5,0.1,0.01},Node的资源总量指该Node的CPU、内存、带宽、磁盘的总量,Node1~Node4的资源总量均为{16,32,1,1},每个Node剩余资源如表1所示。
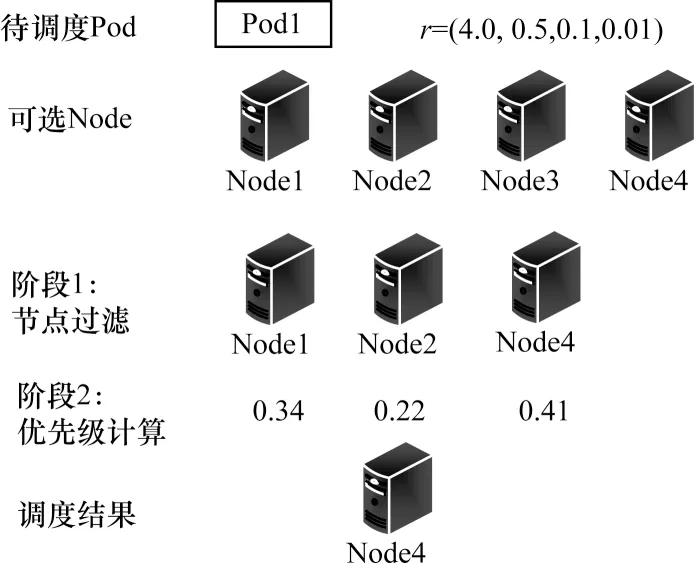
图1 资源调度策略示例Fig.1 Example of resource scheduling strategy

表1 可选Node的剩余资源Table 1 Remaining resources of optional Node
对于待创建的Pod1,第1阶段过滤掉剩余资源不满足需求的Node3,第2阶段采用LeastRequestedPriority评分函数计算各Node的优先级。LOcpu、LOmemory分别表示Node剩余CPU、内存的比例,两者权重均为0.5。优先级f的计算公式为:

其中,f越高表示该Node的资源配置越适合部署该Pod,经过计算,最终选择Node4进行部署。
Node4并非最佳选择,主要体现在以下两点:
1)Kubernetes的调度算法未考虑带宽和磁盘资源,Node4部署该Pod后,剩余带宽资源为0,当该Node上任意Pod遇到突发流量时,不仅该Pod的最小带宽需求无法得到满足,所有Pod的性能都将受到影响。在网络边缘,并非只有CPU、内存是稀缺资源,带宽、磁盘同样非常稀缺,如果调度策略仅考虑CPU、内存,将无法满足视频等大带宽应用及数据库等磁盘需求较大应用的调度需求,影响此类应用的性能。
2)即使仅考虑CPU、内存,Kubernetes的默认调度算法仍有弊端:部署该Pod后,Node4将剩余1个CPU和15.5 GB内存,资源使用得过度倾斜,导致Node剩余资源不均衡,使该Node无法再创建更多的容器,从而造成过剩资源的浪费。LeastRequestedPriority函数对于任何应用,CPU、内存权重都相同,完全没有考虑应用对于某种资源的需求倾向。该Pod是一个CPU密集型应用,内存需求较小,调度策略应该将其部署在剩余CPU较为丰富而内存余量较少的Node,这样主要有以下优势:(1)为应用留有较多的冗余资源,Kubernetes根据用户申明的最小资源过滤Node,实际占有资源可能超过最小资源;(2)更有利于Node剩余资源的均衡,均衡的资源分布有助于实现更高的资源利用率。
2 基于权重自学习的调度策略
对于容器资源调度的研究主要有两个方向:
1)增加评价指标,从而适应物联网、智慧城市等场景下的调度需求,如文献[13-14]提出一种面向智慧城市容器云的网络性能感知调度系统,增加了RTT评价指标,在Node过滤阶段排除RTT不满足需求的Node,文献[15]在Mesos调度策略中增加了容器个数。考虑到评价指标应有效代表资源的使用情况,且指标的获取不应给系统带来过多开销,本文选择CPU、内存、带宽、磁盘使用情况作为评价指标。
2)优化Node优先级评分函数中的权重计算方法,如文献[15]采用层次分析法[16-17]计算权重集合。文献[18]采用模糊层次分析法自动建模求解容器应用多维资源权重参数。利用层次分析法计算权重要求用户掌握应用各类资源的重要程度,但是,很多用户对于自己的应用需要占用多少资源,每种资源的重要程度并不清楚。基于以上考虑,本文将Pod运行过程中资源使用自动生成的权重,用于Node优先级的计算。
在Pod运行过程中,监测模块将周期性地采样该Pod 4类资源的占用率,求得监控窗口内每类资源占用率平均值,进而计算全局资源占用率,根据全局资源占用率计算每类资源的权重,称为Pod专用权重。使用同样镜像的所有Pod各类资源权重平均值作为该镜像的专用权重。
2.1 资源利用率采集方案
本文采集3类信息:1)Node资源总量,对所有Node的各类资源总量求和得到全局资源总量,进而计算出Node的各类资源在全局资源中所占份额;2)Node当前资源利用率,进而求得剩余资源比例;3)Pod资源在当前Node资源中所占份额。
采集方案如图2所示,在每个Node中部署监控代理Proxy,用于采集上述3类信息。Pod资源占用率数据库用于存储每个Pod监控窗口内的CPU、内存、带宽、磁盘占用率。Node全局资源份额数据库用于存储每个Node的资源总量和监控窗口内的资源利用率。采集控制器用于接收资源调度模块的监控指令,对于第1)类、第2)类信息,指令中包括Node标识,对于第3)类信息,指令中包括被监控的Pod标识,采集控制器通过Pod标识获取部署该Pod的Node标识,通过Node标识,采集控制器可查询得到Proxy的IP、端口,进而向Proxy发送监控指令。Proxy采集到所需要的监控信息后存于对应的数据库。
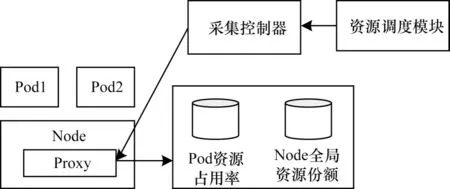
图2 资源利用率采集方案Fig.2 Resource utilization rate collection scheme
2.2 资源调度流程
调度模块维护3类权重集合:1)Pod专用权重,用于Pod扩容时选择最优Node,在测量窗口,统计Pod及其副本占用的各类资源占整个集群资源的比例,即全局占用率,根据各类资源的全局占用率计算Pod专用权重;2)镜像专用权重,是使用该镜像的所有Pod各资源权重的平均值,如果待创建Pod的镜像有使用记录,则使用镜像专用权重选择最优Node;3)Kubernetes默认权重,即所有资源权重值相等。
本文采用两级调度机制,如图3所示。
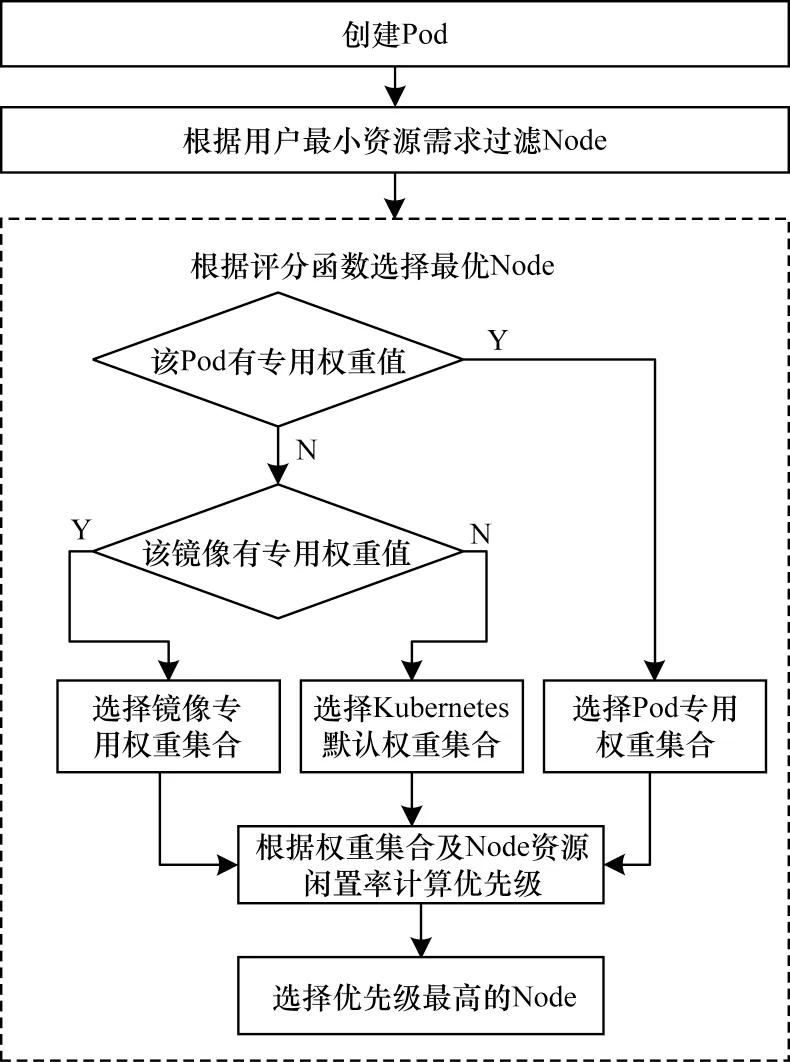
图3 改进的资源调度流程Fig.3 Improved resource scheduling procedure
调度过程分两个阶段,第一阶段根据用户最小资源需求过滤掉不满足需求的Node,第二阶段选择权重集合对候选Node的各类资源的闲置率加权求和,得到候选Node的优先级。权重集合选择策略如下:
1)如果待调度的Pod有专用权重值,则根据Pod专用权重值、资源剩余情况选择最优Pod。
2)如果待调度Pod没有专用权重值,但镜像有专用权重值,则采用镜像专用权重值。
3)其他情况采用Kubernetes的默认权重值,即所有资源权重值相等。
2.3 Node优先级计算方法
符号定义及Node优先级计算方法如下:
1)符号定义
假设Kubernetes集群中有k台不同规格的Node,N={1,2,…,k};每个Node上有m种资源,R={1,2,…,m},某Pod由j个容器构成,P={1,2,…,j},使用镜像i的所有Pod集合为I={1,2,…,h}。
2)Podp各类资源全局占用率计算方法
本文根据Podp的CPU、内存、带宽、磁盘4类资源全局占用率计算Podp的专用权重,全局占用率是指Podp某项资源的占用额度占集群中该资源总额的比重,衡量了Podp对该资源的需求。通过监控代理可以采集到Nodei各类资源总量和Nodei上容器的本地资源占用率。为计算Podp的资源r全局占用率,需要首先计算Nodei的资源r全局份额nodeGlobalShare(i,r)。将nodeGlobalShare(i,r) 与容器d的资源r本地占用率相乘,即可得到容器d的资源r全局占用率containerLocalRU(i,d,r)。Podp由多个容器组成,将Podp中的所有容器资源r的全局占用率求和,即可得到Podp资源r的全局占用率。
(1)计算Nodei的各类资源全局份额
设Nodei上资源r的总量为nodeTota(li,r),则集群资源r总量Nodei上资源r的全局份额为:

(2)计算容器d的各类资源全局占用率
containerLocalRU(i,d,r)表示部署在Nodei的容器d及资源r的占用率,其全局资源占用率为:

(3)计算Podp的各类资源全局占用率
Podp由j个容器组成,podGlobalRU(p,r)表示Podp资源r的全局占用率。

3)Podp专用权重计算方法
weightPod(p)={w(p,1),w(p,2),…,w(p,m)}表示Podp专用权重集合。weightPod满足其中w(p,r)是在计算候选Node优先级时资源r的权重,如式(4)所示,通过计算Podp的资源r的全局占用率与该Pod中所有资源全局占用率之和的比值得到w(p,r)。例如Podp的专用权重集合为{1%,2%,3%,0.01%},表示该Pod每消耗集群1%的CPU,将伴随消耗2%的内存、3%的带宽和0.01%的磁盘,那么在对候选节点计算优先级评分时,内存的优先级应是CPU的2倍,通过式(4)即可计算得到归一化权重:

4)镜像i专用权重计算方法
weightImage(i)={w(i,1),w(i,2),…,w(i,m)}表示镜像i的专用权重集合,其中w(i,r)表示镜像i资源r的专用权重。当需要创建新的Pod时,数据库中尚未创建该Pod的专用权重,此时,参考该Pod使用的镜像i的专用权重。weightImage(i)为所有使用该镜像的Pod权重平均值,h为使用镜像i的Pod总数。

5)优先级评分函数
当创建Pod时,通过优先级评分函数选择剩余资源分布最优的Node进行部署,优先级越高,表示该候选节点资源分布越适合部署该Pod。权重集合的选择顺序如图3所示,优先级评分函数为候选Node闲置率与权重集合的加权求和。Podp为待部署的Pod,priority(p,i)表示Nodei的优先级评分,nodeFree(i,r)表示Nodei资源r的闲置率,是Nodei剩余的资源r与Nodei资源r总量的比值。以Podp有专用权重为例,priority(p,i)的计算方法为:

6)实例
集群内有2个Node,资源总量情况如表2所示,根据式(1)计算得到4种资源的全局份额。

表2 集群资源情况Table 2 Cluster resource situation
Podp有1个副本,Podp部署在Node1上,即容器1,Podp的副本部署在Node2上,即容器2。通过测量得到资源利用率containerLocalRU,如表3所示,根据式(2)可以得到2个容器4种资源的全局资源占用率。

表3 容器资源占用率Table 3 Containers resource occupation rate %

经测量Node1、Node2各类资源闲置率如表4所示。此时Podp需要再增加一个副本,根据式(6)可以得到Node1和Node2的优先级评分分别为0.40、0.49。根据优先级评分,Podp的副本应部署在Node2上,很明显Node2是更优选择,由表4可知,Podp是带宽型应用,大约需要占用3.5 Gb/s带宽,如果部署到Node1,带宽资源仅剩余0.5 Gb/s,难以应对突发流量。

表4 Node资源闲置率Table 4 Node resources idle rate %
2.4 评价指标
本文评价指标主要有以下3种:
1)集群资源失衡度
对于Nodei,各类资源利用率的标准差可以反映该Node资源均衡状况。假设集群中有k台不同规格的Node,每个Node上有m种资源。U(i,r)表示Nodei资源r的利用率,Nodei资源利用率标准差表示为:

2)资源综合利用率
Nodei的资源综合利用率为该Node各类资源利用率的均值,定义集群资源综合利用率为所有Node资源综合利用率的平均值,衡量集群的资源是否得到充分利用。
3)调度合理率
如果将Podp调度到Nodei后,Nodei的各类资源未触及资源上限,那么此次调度结果是合理的。调度合理率是指对于请求集合R调度合理的比例。
3 实验
3.1 实验环境
为验证本文提出的容器调度算法,基于墨尔本大学开源的云计算仿真框架ContainerCloudSim[19-20]进行仿真,利用该软件模拟一个包含30个Node的Kubernetes边缘云,每个Node的资源信息如表5所示。

表5 Node资源信息Table 5 Node resource information
本文基于边缘应用资源需求多样性、差异化的特点,按照CPU倾向型、内存倾向型、存储倾向型、带宽倾向型以及标准无倾向型5类应用资源请求构建了Pod资源需求,表6为部分Pod资源需求,表7展示了WSLB对于Pod自动学习到的权重。
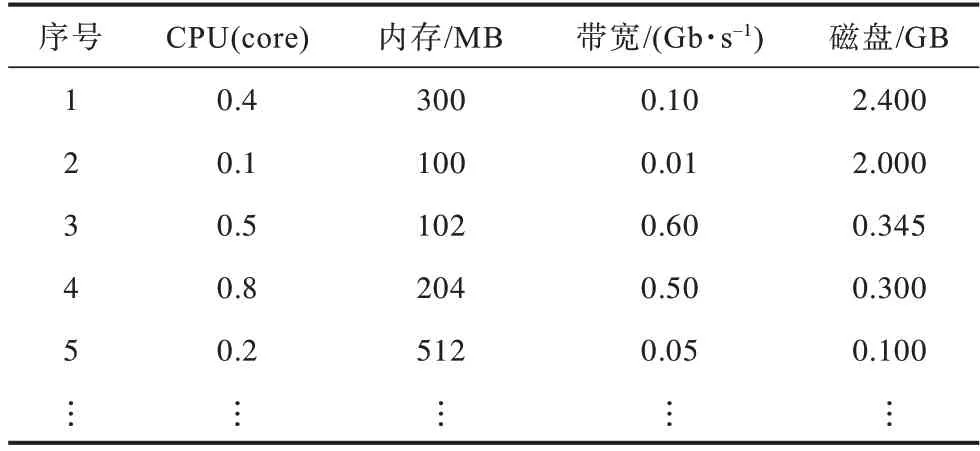
表6 Pod资源需求Table 6 Pod resource requirement

表7 基于自学习机制得到的权重Table 7 Weights based on self-learning mechanism
3.2 实验结果与分析
在上述Kubernetes边缘云集群中,分别采用K8s原生调度算法与本文提出的MSLB自学习调度算法,从集群资源均衡度、综合资源利用率和调度合理率3个角度来对比两种算法。
1)集群资源失衡度
集群资源失衡度变化曲线如图4所示,当Pod数量小于6 000时,集群负荷较低,WSLB机制与K8s原生调度机制的资源失衡度相差并不大,甚至有可能在某些特定的Pod需求下,略低于K8s原生调度机制,但当Pod数量大于6 000时,随着容器资源请求数量继续上升,WSLB自学习得到的权重开始产生作用,WSLB的资源失衡度明显优于K8s原生调度算法。由于WSLB考虑了4种资源的权重情况,降低了集群中Node出现某一资源用尽而其余资源大量剩余的可能性,从而使得集群的资源使用失衡度整体下降约10%,尤其是当Pod数量大于7 000,集群资源饱和后,WSLB失衡度平均下降26.2%,体现了WSLB在集群资源饱和情况下可以有效调节集群资源平衡度。

图4 集群资源失衡度变化曲线Fig.4 Cluster resource lopsidedness change curve
2)资源综合利用率
资源综合利用率变化曲线如图5所示。图5中截取了Pod数量大于6 000的部分,当Pod数量小于6 000时,集群负荷较小,Pod调度请求均可满足,两种算法资源综合利用率没有差异。当Pod数量大于6 000时,集群负荷较大,WSLB的资源综合利用率总体优于K8s原生调度算法,相比K8s平均提升1.6%。主要原因如下:随着Pod数量的增加,K8s算法失衡度上升,集群中部分Node出现资源倾斜,导致部分Pod调度请求无法得到满足;K8s原生算法没有考虑带宽和存储资源,致使部分Node带宽、存储资源饱和,这部分Node无法充分满足应用的带宽、存储需求。

图5 集群资源综合利用率Fig.5 Cluster resource comprehensive utilization rate
3)调度合理率
如图6所示,WSLB的调度合理率始终为1,当Pod数量大于1 500时,WSLB调度合理率较K8s平均提升9.3%。原因在于WSLB充分考虑了Pod的带宽、磁盘需求,避免了Node带宽、磁盘资源饱和情况的出现,当Pod数量大于3 000时,K8s原生调度策略开始出现调度不合理的情况,这是因为K8s原生算法不考虑Pod的带宽、磁盘需求,将部分Pod调度到带宽或磁盘资源饱和的Node,该Node上所有Pod的性能将受到影响。
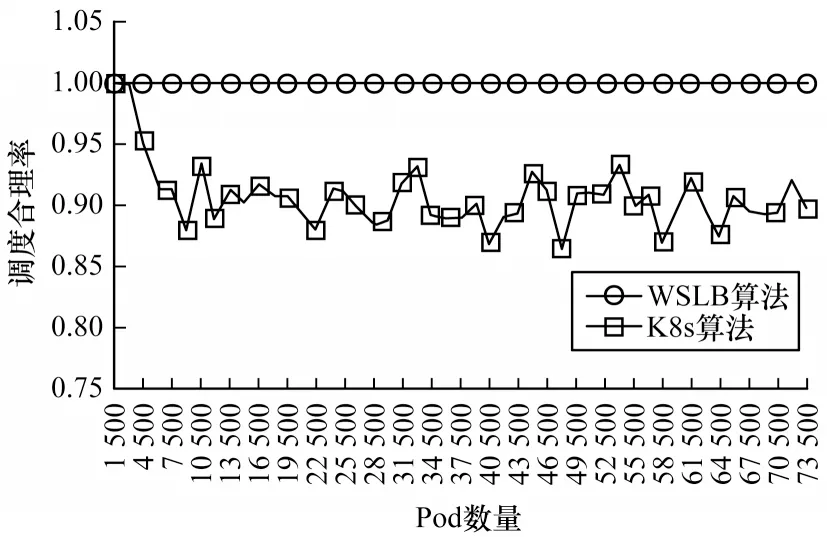
图6 调度合理率Fig.6 Scheduling reasonable rate
图7所示为当Pod数量为7 500时,K8s原生调度算法和WSLB算法的Node带宽利用率,K8s原生调度算法由于在调度时没有考虑带宽的使用情况,使得各Node的带宽利用率分布极为不均衡,标准差达到了0.496 8,且有5个Node的带宽利用率已远超1,这表明这些Node的带宽资源已经饱和,饱和率达到16%。在5G MEC的业务场景之下,意味着这些Node网络已严重拥堵,5G MEC带来的低延时优势已经不再具备。而在WSLB调度机制下,大部分Node带宽利用率较为均匀地分布于0.4~0.8之间,标准差为0.137 4,相比于Kubernetes原生调度算法,下降了72%,保障了整个集群的带宽使用率。
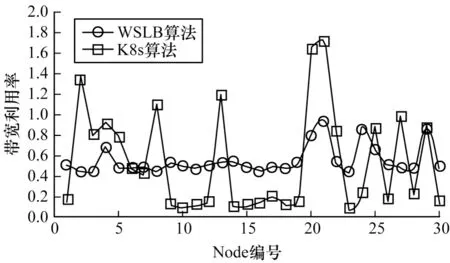
图7 集群带宽利用率Fig.7 Cluster bandwidth utilization rate
4 结束语
容器云是5G边缘计算的重要支撑技术,网络边缘的资源较为稀缺,而边缘应用与传统应用的差异性给容器云的调度机制带来了新的需求。Kubernetes仅考虑CPU、内存,且对需求各异的应用采用相同权重的资源调度策略,无法适用于边缘云的调度需求。针对Kubernetes资源调度策略的不足,本文增加了带宽、磁盘利用率两项指标,以满足边缘计算场景下带宽、磁盘需求较大应用调度需求,同时提出一种根据Pod运行过程中资源占用情况自动计算Pod专用权重、镜像专用权重的方法,对不同资源倾向的应用采用不同的权重,以满足大规模异构化的容器资源申请需求。在ContainerCloudSim仿真平台上的实验结果表明,与Kubernetes原生调度策略相比,基于权重自学习的调度策略具有更高的资源利用率。将Pod调度到合适的Node上只是资源调度的开始,后续研究将考虑在Node上分配各Pod之间的资源,从而实现公平、高效的资源调度,进一步提升系统的资源利用率。
