基于RISC-V浮点指令集FPU的研究与设计
2021-02-04潘树朋刘有耀焦继业
潘树朋,刘有耀,焦继业,李 昭
1.西安邮电大学 电子工程学院,西安710121
2.西安邮电大学 计算机学院,西安710121
随着嵌入式系统中浮点运算的需求日益增多,应用范围从气候建模、电磁散射理论到图像处理、FFT 计算[1]、特征值计算等。为了支持和加速这些应用,需要能够产生高吞吐量的高性能计算设备。浮点处理器(Floating Point Unit,FPU)极大地提高了这些高计算应用的性能。在大多数现代通用计算机体系结构中,浮点处理器集成在处理器芯片内,比如ARM、MIPS等[2]。浮点处理器作为一种加速器,与整数流水线并行工作,并从主处理器分担大型计算、高延迟浮点指令。如果这些指令是由主处理器执行,由于浮点除法、平方根和乘累加等运算需要大量的计算和较长的等待时间,会降低主处理器的速度,运算精度也会有所损失,因此浮点处理器有助于加速整个芯片[3]。
许多嵌入式处理器,尤其是一些传统的设计,不支持浮点运算。许多浮点处理器的功能可以通过软件库来仿真[4],虽然节省了浮点处理器的附加硬件成本,但是速度明显较慢,不足以满足嵌入式处理器的实时性要求。为了提高系统的性能,需要对浮点处理器进行硬件实现。
到目前为止,浮点处理器的设计已经做了很多工作。文献[5-6]介绍了一种64 位、5 级流水线、单发射顺序执行的开源RISC-V处理器核Rocket-Chip,由伯克利大学设计,具有兼容IEEE754-2008 标准的FPU,但采用Chisel语言编写,可读性较差。文献[7]介绍了浮点向量协处理器FPVC,支持标量计算,实现了浮点加法、乘法、除法和平方根运算,仅支持单精度操作数。文献[8]为了提高基于定点DSP的数字平台的计算能力,设计了一种基于FPGA的可配置浮点协处理器,仅支持单精度操作数。此外,一些设计具有有限的算术运算,文献[8]的设计仅支持加、减、除运算。文献[9]实现了采用SPARC架构设计的浮点协处理器,支持加法、乘法和除法运算。文献[10]提出了采用RISC 架构设计的浮点协处理器,仅实现了单精度浮点运算,缺少乘累加等主要运算。
针对上述公开文献设计方案的不足:(1)支持的浮点精度单一;(2)运算种类有限,不能满足多种运算需求。因此,本文基于RISC-V 指令集实现了一种支持单精度的浮点处理器,具有广泛的算术运算,如加法、减法、乘法、除法、平方根、乘累加和比较,与IEEE-754 2008标准完全兼容。
1 RISC-V指令集分析
1.1 规整的指令编码
RISC-V 的指令集编码非常规整,指令所需的通用寄存器的索引(Index)都被放在固定的位置。因此指令译码器可以非常便捷地译码出寄存器索引,然后读取通用寄存器组。RISC-V基本指令类型如图1所示,分别为R类、I类、S类、U类。

图1 RISC-V指令格式
RISC-V是一个新的指令集体系结构(ISA),完全开放,适合直接在硬件上实现,不仅仅是适用于模拟或者二进制翻译,还支持丰富的用户级ISA 扩展,具有可选的变长指令,以支持扩展可用的指令编码空间和一个可选的密集指令编码,以提高性能、静态代码大小和能耗效率。
1.2 优雅的压缩指令子集
为了满足某些对于代码体积要求较高的场景(例如嵌入式领域),RISC-V 定义了一种可选的压缩(Compressed)指令子集,用字母C 表示,也可以用RVC 表示。RISC-V具有后发优势,从一开始便规划了压缩指令,预留了足够的编码空间,16 位长指令与普通的32 位长指令可以无缝自由地交织在一起,处理器也没有定义额外的状态。
RISC-V 架构的研究者进行了详细的代码体积分析,如图2所示,通过分析结果可以看出,RV32C的代码体积相比RV32 的代码体积减少了40%,并且与ARM,MIPS和x86等架构相比都有不错的表现。

图2 各指令集的代码密度比较
1.3 RISC-V浮点指令集
当今主流的指令集架构有MIPS 和ARM 等,MIPS架构主要用于计算机,ARM 架构相对于MIPS 更精简、能耗更低,主要用于移动设备端,而RISC-V作为新兴起的指令集架构[11],不仅能实现低功耗且更加适合嵌入式领域[12]。在选择用RISC-V 指令集实现浮点处理器之前,对MIPS、ARM和RISC-V中的浮点指令集从几个方面进行了分析,如表1所示。

表1 RISC-V、ARM、MIPS浮点指令集分析
RISC-V 指令集使用模块化的方式进行组织,每一个模块使用一个英文字母来表示。RISC-V最基本也是唯一强制要求实现的指令集部分是由I字母表示的基本整数指令子集。使用该整数指令子集,便能够实现完整的软件编译器。其他的指令子集部分均为可选的模块,具有代表性的模块包括M/A/F/D/C,其中“F”代表的是RISC-V 单精度浮点指令集。由表1 可知,RISC-V 指令集共有26条单精度浮点指令,部分指令编码格式如表2所示。

表2 RISC-V部分浮点指令编码格式
2 RISC-V流水线结构
本设计将浮点处理器与开源处理器核蜂鸟E203进行集成。蜂鸟E200 是一个处理器系列,主要面向极低功耗与极小面积的场景而设计,非常适合于替代传统的8051 内核或者Cortex-M 系列内核应用于IoT 或其他低功耗场景[13],其包含了多款不同的具体处理器型号,目前开源的具体型号为蜂鸟E203处理器核。
图3 为浮点处理器与开源处理器核E203 的集成结构图。取指单元基于程序计数器值从程序存储器提取指令,在取指之后,将进行指令译码操作[14]。由于指令所包含的信息编码在有限长度的指令字中,因此需要译码将指令所需要读取的操作数寄存器索引、指令需要写回的寄存器索引、指令的其他信息,譬如指令类型、指令的操作信息等从指令字中翻译出来,在本设计中对E203的译码模块进行了修改,根据浮点指令编码格式,增加了浮点指令译码相关内容。
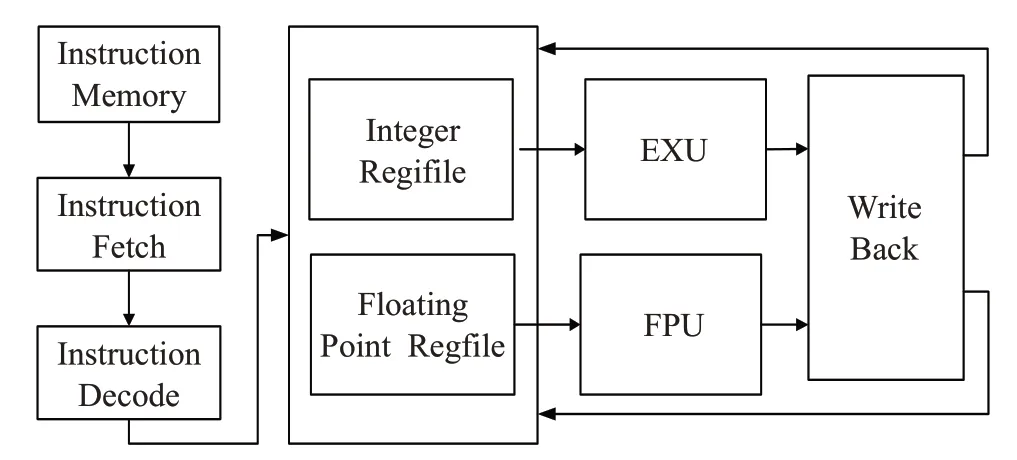
图3 浮点处理器与开源处理器核E203的集成
译码完成之后,将寄存器索引传递到寄存器选择单元。RISC-V 架构规定,如果支持单精度浮点指令或双精度浮点指令,则需要增加一组独立的通用浮点寄存器组(Floating Point Regfile),如图3所示。如果当前指令是整数相关指令,则传递到整数流水线,最终结果通过写回单元写回通用整数寄存器组。如果该指令与浮点相关,则传递到浮点处理器流水线,最终结果通过写回单元写回通用浮点寄存器组。
2.1 浮点通用寄存器组
浮点通用寄存器组包含了32 个通用浮点寄存器,标号为f0至f31。浮点通用寄存器组如图4所示。其中FLEN表示浮点寄存器的宽度,为32位。

图4 浮点通用寄存器组
2.2 浮点控制和状态寄存器
浮点控制和状态寄存器fcsr是一个RISC-V控制和状态寄存器(CSR)。它是一个32 位的读/写寄存器,用于为浮点算术操作选择动态舍入模式,并保存产生的异常标志,如图5所示。

图5 浮点控制和状态寄存器
fcsr 寄存器可被FRCSR 和FSCSR 指令进行读写,它们是由底层的CSR访问指令实现的。FRCSR指令通过将fcsr 寄存器复制到整数寄存器rd 实现读操作。FSCSR通过将fcsr原来的值复制到rd,然后将整数寄存器rs1中的值写入fcsr来实现写操作。
fcsr寄存器包含浮点异常标志位域(fflags),不同的异常标志位所表示的异常类型如表3 所示。如果浮点运算单元在运算中出现了相应的异常,则会将fcsr寄存器中对应的异常标志位设置为高,且一直会保持累积。软件可以通过写0的方式单独清除某个异常标志位。

表3 异常标志位
2.3 执行模块的设计
执行模块包含定点寄存器堆(Integer Regfile)、浮点寄存器堆(Floating Point Regfile)、操作数选择模块(Opcode Sel)、定点运算单元(Alu)、浮点运算单元(FPU)以及一个访存单元(Mem Unit)。译码模块对指令译码之后得到对应的OP 等操作信息以及源操作数地址,执行模块根据源操作数地址首先从定点和浮点寄存器堆中取出对应的操作数,然后操作数选择模块从寄存器堆输出结果以及旁路数据中选择正确的操作数,最后运算单元根据相应操作信息及其操作数就可以计算出结果。每个端口对应的计算单元中只有一个有效,而其他运算单元输出结果为0,因此将所有单元的输出进行按位或运算就可以得到最终结果。
对于定点指令来说,最多需要从定点寄存器堆中取出两个源操作数,而对于浮点指令来说,最多需要从浮点寄存器堆中取出三个源操作数,为了确保执行阶段指令能够执行,定点寄存器堆必须具有2 个读端口,而浮点寄存器堆必须具有3个读端口,同样为了确保写回阶段每次能够写回操作数,2个寄存器堆都必须具有一个写端口。这样设计的好处在于定点指令和浮点指令可以分开执行,不会产生冲突,能够实现有效的资源利用。执行模块架构如图6所示。

图6 执行模块架构图
3 浮点运算单元微架构
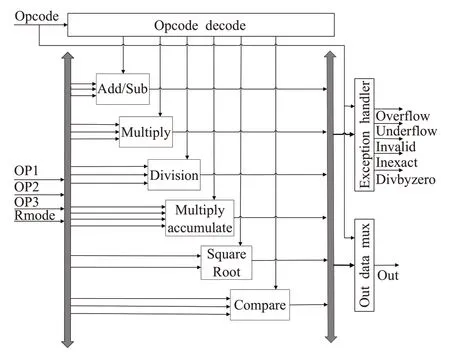
图7 浮点运算单元微架构
浮点处理器运算单元的微体系架构如图7所示,有六条独立的流水线。这些流水线分别为浮点加/减法器、除法器、乘法器、平方根、乘累加和比较器。各运算单元的输入为三个操作数(OP1、OP2、OP3)和舍入模式(Roud_mode),各单元运算完成后,将输出运算结果以及五种异常。操作码译码器译码指令并启用所需的模块,执行模块对输入数据执行相应操作。本文将详细介绍浮点加法/减法以及乘法模块。
3.1 浮点加法器/减法器
浮点加法器和减法器单元架构如图8 所示。该加法器接收三个输入:两个操作数(OP1、OP2),三位舍入模式,输出的结果符合IEEE 754-2008 标准。除此之外,该单元还将输出四个异常信号,即上溢、下溢、无效和不精确。主要功能单元分为预处理单元、二进制加减单元和后处理单元三部分。预处理阶段将输入操作数分解为符号位、尾数位和指数位。
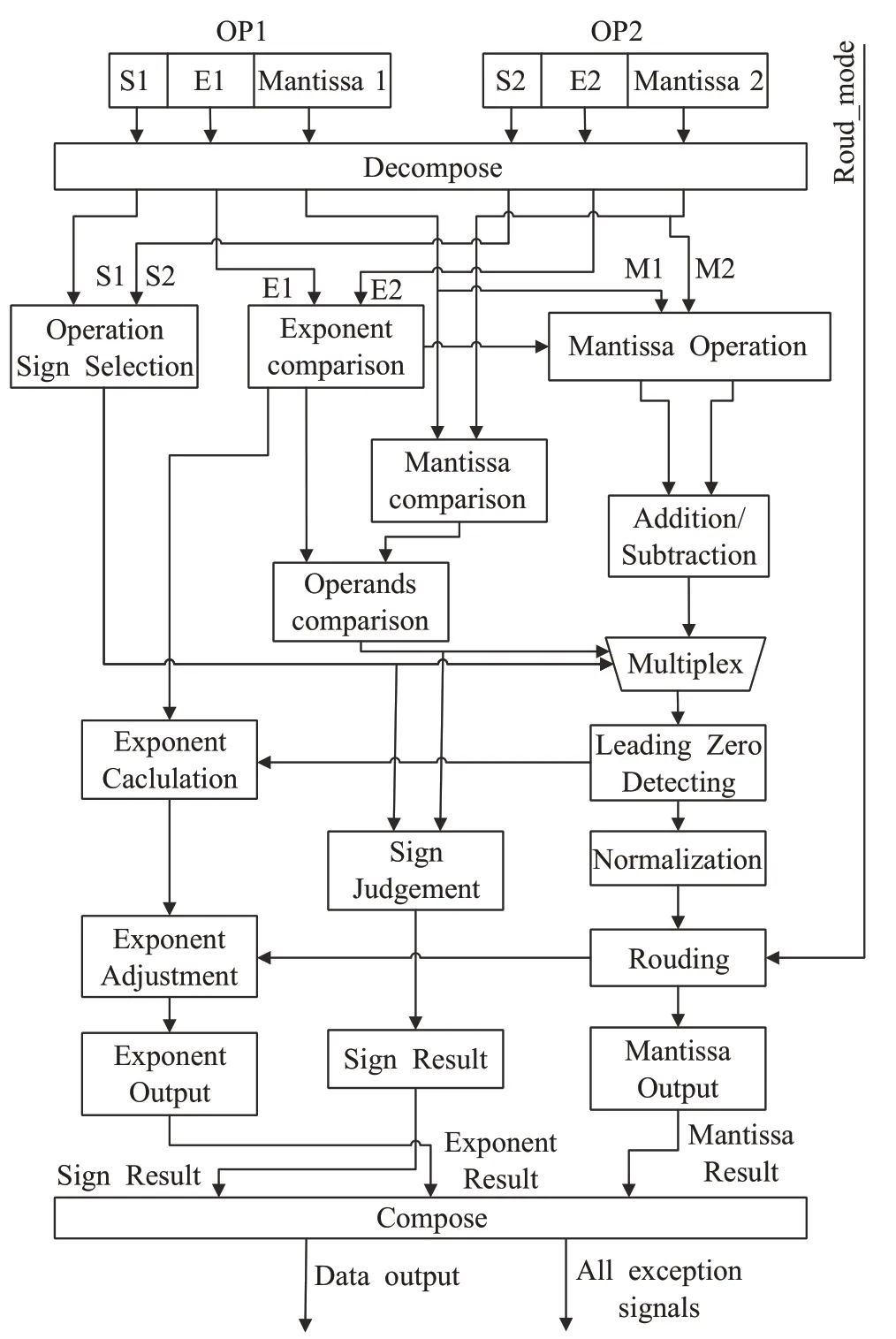
图8 加法器/减法器架构
在进行浮点加减法时,首先需要对阶操作,即通过比较操作数OP1 和操作数OP2 的指数(E1、E2)可以得到较大的指数值。如果E1 大于E2,将执行E1 减去E2运算,可计算出将尾数M2移至右侧的位置数,目的是使尾数M1 和尾数M2 在下一阶段的加法和减法之前对齐。如果符号位S1等于S2,则将尾数M1加到尾数M2,否则从尾数M2 减去尾数M1,取决于操作数OP1 和操作数OP2 的绝对值。根据操作数OP1 和操作数OP2 的符号位和绝对值,将上述操作中获得的三个结果送到后处理单元。将上述操作获得的结果向左移动,直到最高位为1,即进行前导零检测。
在浮点数中,为了在尾数中表示最多的有效数据位,同时使浮点数具有唯一的表示方法,规定尾数部分用纯小数给出,而且尾数的绝对值应大于或等于1/R,并小于或等于1,即小数点后的第一位不为零。这种表示的规范称为浮点数的规格化的表示方法。不符合这种规定的数据可通过修改阶码并同时移动尾数的方法使其满足这种规范。
将上述结果进行归一化以符合浮点数的规格化表示。规格化结果将按照提供的舍入模式进行舍入。根据操作数OP1 和操作数OP2 的符号和绝对值可以得到新的符号。最终将舍入后的结果、更新的指数和结果符号位将被送入合成单元,该合成单元将输出转换为IEEE 754-2008标准格式的数据结果和所有异常信号。
3.2 浮点乘法器
与浮点加法相比,浮点乘法要相对简单,并且与整数乘法类似。在执行浮点乘法运算时,首先需要对两个操作数的符号位进行异或操作,以确定最终结果的符号位。其次将指数位相加得到新的指数位,然后将尾数位相乘得到新的尾数部分,最后根据浮点数格式对得到的指数位和尾数位进行调整,并进行舍入处理,从而得到最终浮点数的乘法结果。例如给定两个浮点操作数X1={S1,E1,M1} 和X2={S2,E2,M2} ,其中S、E、M分别代表操作数的符号位、指数位、尾数位。则可以使用公式(1)~(3)进行运算:
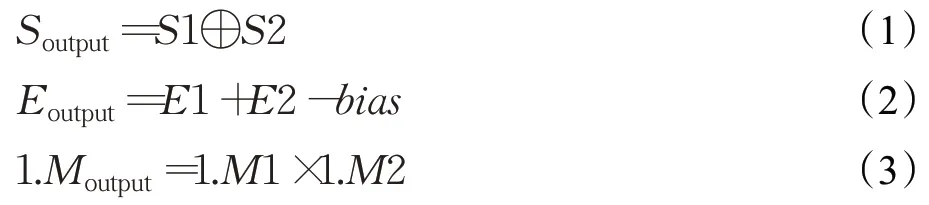
浮点乘法器的结构如图9 所示。乘法符号可以通过对操作数OP1 和操作数OP2 的符号位S1 和S2 执行异或运算来计算。8位加法器用于指数加法,从相加的指数结果中减去相应的偏差bias(单精度为127),24×24位乘法器用于尾数乘法,乘数结果按照提供的舍入模式进行舍入。由于尾数在舍入过程中可能溢出,舍入后还需要对结果进行规格化。
4 实验结果
4.1 RISC-V自测试用例
自测试用例(Self-Check Testcase)是一种能够自我检测运行成功还是失败的测试程序。risc-v-tests 是由RISC-V 架构开发者维护的开源项目,包含一些测试处理器是否符合指令集架构定义的测试程序,这些测试程序均由汇编语言编写。
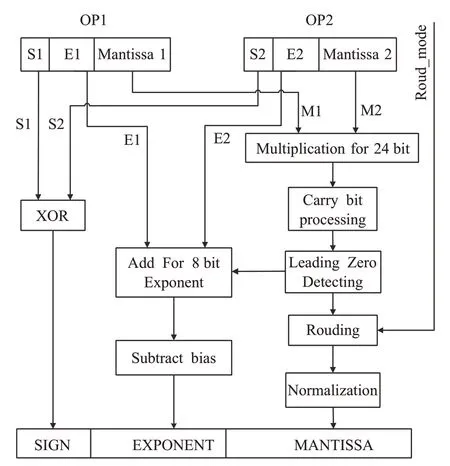
图9 浮点乘法器架构
此类汇编程序里用某些宏定义组织成程序点,测试指令集架构中定义的指令。例如若测试fadd.s指令,则通过让fadd.s指令执行两个数据的相加,设定它期望的结果。然后使用比较指令加以判断,假设fadd.s指令的执行结果与期望结果相等,则程序继续执行;假设与期望结果不相等,则程序直接使用jump 指令调到TEST_FAIL地址;假设所有的测试点都通过,则程序将执行到TEST_PASS地址。
按照此方法,测试了RISC-V的浮点指令集,结果均符合预期。浮点运算指令执行周期数如表4 所示。文献[15]中作者实现了基于ARMv7浮点指令集的浮点处理器,其浮点运算指令执行周期如表5所示。

表4 设计中浮点运算指令执行周期数

表5 文献[15]中浮点运算指令执行周期数
从表4 和表5 可见,与文献[15]中浮点加法、减法、乘法执行4个周期相比,本设计浮点加法、减法、乘法执行2 个周期,减少了2 个周期。在执行浮点除法运算时,文献[15]最多需要16 个周期,而本设计最多仅需8个周期。
4.2 性能分析
文献[7]FPVC 的浮点性能为25 MFLOPS,文献[10]CalmRISC32 的系统频率为70 MHz。本设计采用连续流水线结构,在FPGA 上实现了100 MHz 的单精度频率。因此,如果在每个时钟周期连续提供输入,则本设计在FPGA 上将提供高达150 MFLOPS 的吞吐量。设计对比如表6所示。

表6 设计对比
为了与本设计的性能进行对比,本文查阅文献资料,列出了基于RISC-V的处理器核Rocket Chip、Boom 2-w、Shakti 的性能与本文进行比较。BOOM 2-w 是伯克利开发的一款开源处理器核,面向更高的性能目标,是一款超标量乱序发射、乱序执行的处理器核。Shakti是印度理工学院的一个项目,由Verilog编写,其使用了大量第三方IP,根据需要分成了不同的类。不同基于RISC-V处理器核的性能对比如表7所示。
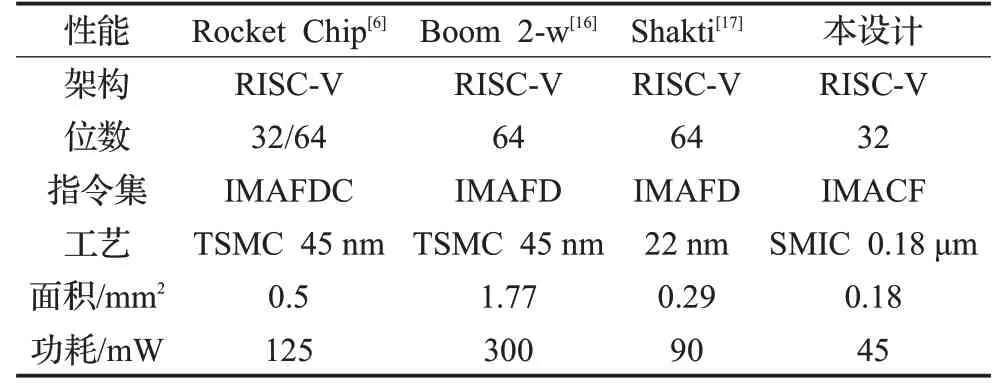
表7 基于RISC-V处理器核性能对比
从表7 中可以看出,基于RISC-V 的处理器Rocket chip、Boom 2-w、Shakti 为64 位处理器,本设计为32 位处理器,理论上64 位架构处理器面积和功耗应该远远高于32 位架构的处理器。处理器Rocket chip、Boom 2-w、Shakti 实现了单精度和双精度浮点指令集,流水线深度较深,处理器性能高,本设计实现单精度浮点指令集,两级流水线,应用于嵌入式场景,要求小面积低功耗。因此,本设计在处理器架构、实现的指令集、流水线深度等方面符合嵌入式场景中小面积、低功耗的需求。
4.3 验证与综合
本文使用Synopsys 公司的VCS(Verilog Compile Simulator)对设计进行仿真验证,使用Synopsys 公司的DC(Design Compile)对设计进行综合。
本文在进行逻辑综合时,所采用的工艺库为SMIC 0.18 μm工艺库。作为参考,首先对开源处理器核Rocket Chip以及PULPino[18]进行了综合。PULPino是由苏黎世瑞士联邦理工学院(ETH Zurich)开发的一款开源的单核MCU SoC平台,同时ETH Zurich还开发了配套的多款32位RISC-V处理器核,其中RI5CY是一款四级流水线,按序单发射的处理器,包含一个FPU模块,支持标准的RV32I/M/C/F指令集。
表8 为Rocket Chip 中FPU 各模块的面积占比报告,表9 为PULPino 中FPU 各模块的面积占比报告,本设计中FPU的面积占比报告如表10所示。

表8 Rocket Chip FPU各模块综合

表9 PULPino FPU各模块综合

表10 本设计中FPU各模块综合
由表8~表10可得到,Rocket chip、PULPino以及本设计中FPU各模块的面积以及所占面积比例,其中该设计FPU总体面积较Rocket chip中FPU面积减少7%,较PULPino面积减少1.5%。就浮点乘累加模块而言,本设计较Rocket chip乘累加模块面积增加7.8%,较PULPino乘累加模块面积减少11.9%。浮点乘法模块面积较PULPino中乘法模块减少14.7%。
5 结束语
本文针对目前浮点运算软件实现速度慢,不能满足嵌入式处理器实时性要求以及运算种类有限等问题,设计了一种基于开源RISC-V 指令集的浮点处理器,能够执行加法、减法、乘法、除法、平方根、乘累加以及比较运算,完全符合IEEE 754-2008标准。本文对设计进行了仿真验证以及逻辑综合。结果表明,该设计FPU总体面积较Rocket chip中FPU面积减少7%,较PULPino面积减少1.5%,吞吐量可达到150 MFLOPS,可应用于嵌入式领域。未来的工作包括探索提高灵活性的其他方法,例如自适应多模式的浮点单元或重新配置浮点单元内的计算组件以执行其他功能。此外,还将考虑增强当前的设计算法以实现更多吞吐量。
