基于DEA-BP神经网络的效率置信区间预测模型研究
2021-02-04郑建锋王应明
郑建锋,王应明
福州大学 经济与管理学院,福州350108
在管理学中,效率是指在特定的时间内,一个组织投入与产出的比值关系,能够反映这个组织在各个方面的能力,进行效率分析显得尤为重要。效率分析是对各个组织的效率进行测度与评价的一种方法,在目前国内外研究中,主要是利用数据包络分析(DEA)或者将数据包络分析与其他模型结合等方法对效率进行评价。效率评价在近几十年的发展,已经发展得越来越成熟了,然而对效率进行预测仍停留在探索阶段。李果等人[1]用神经网络的方法进行DEA 有效预测,证实了效率预测的可行性。之后的几年,一些学者通过DEA 和神经网络的方法对各个不同行业的效率进行评价并预测,如体现在物流联盟伙伴选择[2],不同高校科研能力评估[3],美国铁路性能测量和预测[4],基坑施工评价[5]等方面。可见DEA 与神经网络模型在效率评价与预测能力上,具有科学性、广泛性。但是由于评估某个决策单元的效率时,受到许多因素的影响,除了投入与产出之外,还有很多复杂的环境因素,所以增加了效率准确预测的困难。区间预测就解决了点预测给决策者带来的不确定性。区间预测是在收集到的数据基础之上,通过一系列的学习优化,给出的一个参数范围。本文在前人研究的基础上,继续沿用DEA 与神经网络结合对效率进行评级与预测的方法,提出效率置信区间预测模型。首先,利用DEA方法,对决策单元的效率进行评价,得出各个单元的效率值;其次,对BP 神经网络进行模型参数修改,结合student 学生式分布得到预测区间模型,详见第1 章模型构建。对决策单元的效率进行区间预测,并按区间进行分类,然后采用预测区间覆盖率(Prediction Interval Coverage Probability,PICP)、归一化平均预测区间宽度(Normalized Mean Prediction Interval Length,NMPIL)和区间分数(Interval Score,IS)等指标对预测结果进行评价,根据最后不同类别的决策单元分析原因。
1 模型构建
1.1 数据包络分析
数据包络分析(Data Envelopment Analysis,DEA),是交叉了包括数学、管理科学、系统工程学等学科,而形成的一个新的领域[6],是由Charnes等人[7]于1978年提出并命名的。DEA是使用线性规划等数学规划模型对具有多输入和多输出的决策单元(DMU)进行效率评估的。关于对DEA 的研究,已经有上千位学者对它进行了深入的研究,并把DEA 用来评估供应商、银行、保险公司、高校等地方的效率。在对DEA的研究中,许多学者将DEA 与其他模型结合起来,对决策单元的效率进行评估。实证结果表明,这些结合起来的模型,在评估效率时表现出比单纯使用DEA 来评估,具有更好的性能,特别是当遇到比较复杂、比较大的数据量的问题时。DEA进行效率评价时,有着自身独特的优点,可以在很大程度上避免了人为因素的干扰,使评价的结果更加客观、科学。但是DEA也存在不足的地方,如不能实现进一步的预测和仿真效率值。
本文先采用DEA 对决策单元进行效率评价,DEA方法主要有两个基本模型:CCR 模型和BCC 模型。这两者方法之间主要的区别是CCR 假设规模收益不变,而BCC 是假设存在规模收益可变。1978 年,Charnes等[7]给出了第一个DEA 模型CCR。CCR的基本原理是假设共有n个决策单元DMU,每个决策单元中具有m种投入和s种产出,评价第j个决策单元(DMUj,1 ≤j≤n)的技术有效与规模有效,在CCR模型基础之上加上就得到BCC 模型[8]。在BCC 模型中技术有效决策单元是在最优前沿面上的,但BCC 模型却不考虑规模报酬变化。在实际的应用中,DEA 模型往往是以CCR 模型为基础,基于投入型CCR 模型可得出不同DMU 的效率值。含有非阿基米德无穷小的CCR 模型线性规划对应的对偶规划表示为:

(3)如果θ0<1,被评价的决策单元无效。
1.2 BP神经网络
人工神经网络(ANN)是模拟大脑活动,是对人的大脑中神经网络的基本特性进行抽象和模拟,具有非线性逼近、分布式并行信息处理、自训练学习、自组织等能力[9]。
人工神经网络在组合优化、预测等领域得到了广泛地应用。BP神经网络是一种多层网络学习的误差发现传播算法,在目前对人工神经网络的研究中,有80%~90%的模型采用BP 神经网络或者它的变形形式[10]。因此,采用BP神经网络进行预测研究具有可操作性。
图1 显示了简单的BPNN 模型,典型的BPNN 模型具有多层结构,包括输入层、隐含层、输出层。
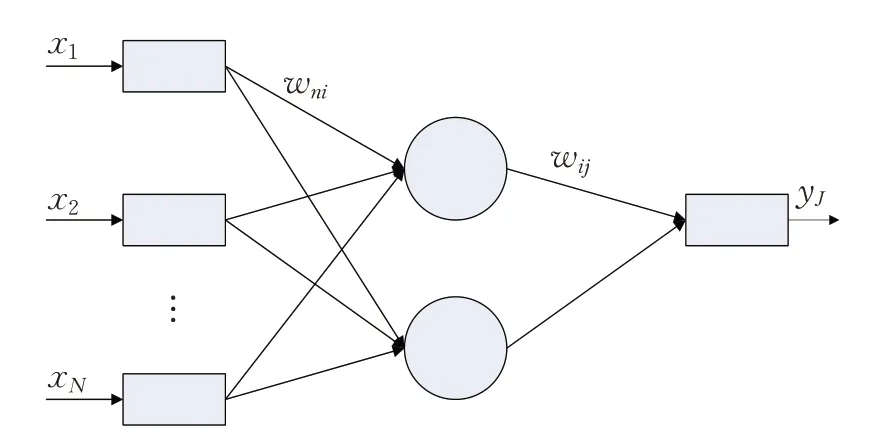
图1 三层BPNN模型
如图1所示,相邻的两个层中的神经元通过高度互连的权重连接在一起。wni是指从输入层单元到隐含层单元的权重,wij是指从隐含层到输出层的权重。输入层的加权输入总和,作为第i个隐含层的输入,通过传递函数的作用转化成隐含层的输出,激活函数选择常用的Sigmoid函数,则有接着输出层的输出单元输出先是由隐含层单元Hi的加权总和,然后通过再一次的传递函数(Sigmoid 函数)得到。在神经网络模型中,需要训练网络来确定最佳的权重,达到满足训练数据的基本特征。反向传播算法通过使所有训练集中的目标输出gJ与实际输出yJ之间的误差项最小化,得到下面的公式:

1.3 基于BP神经网络的置信区间预测模型
尽管神经网络相对于其他传统的回归技术具有优越性,但是在进行预测时,调试误差的精度仍是一个难点;另一方面,神经网络的点预测性能随着数据来源的复杂性和不确定性的增加而显著下降。因此,本文采用构造置信区间的技术来进行神经元模型的区间预测。
对于给定的输入为x,输出为y的系统,系统模型用来表示。其中,θ*代表系统模型中参数θ的真实值。假设误差ε是系统的实际输出与观测输出的差值,并且误差ε服从于均值为0,方差为σ2的正态分布,该分布表示为:ε~(0,σ2)。所以系统可以表示为:
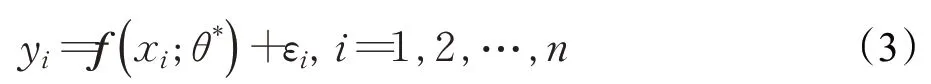
通过公式(4),来使得误差最小化,得到θ*的最小二乘估计量为。


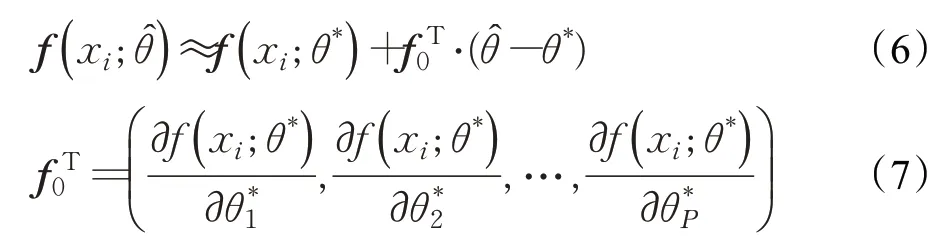
通过使用公式(2)、(6)、(7),来计算真实值y与预测值之间的差值,公式(8)表示的是差值之间的期望:
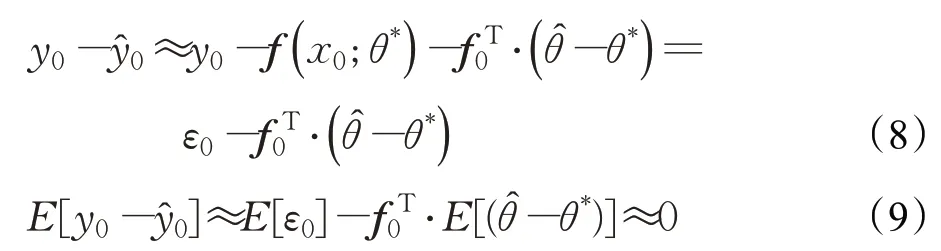
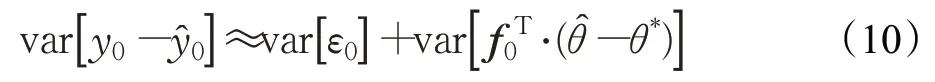
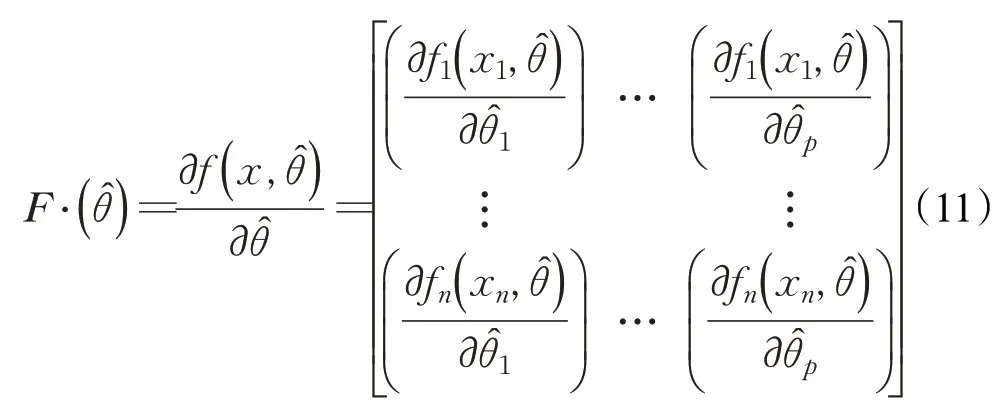
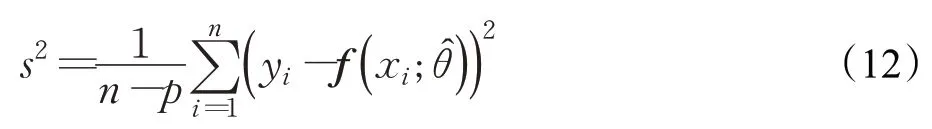
置信区间用t-分布表示为:
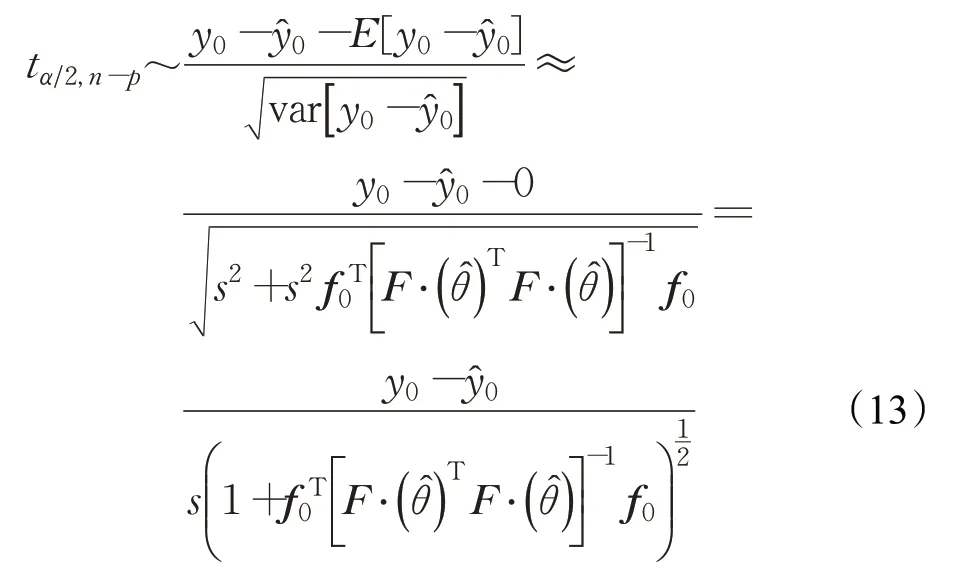

1.4 验证模型
代替传统的验证模型,如平均百分比误差(MAPE)、均方误差(MSE)的传统标准,本文使用预测区间概率和预测区间平均宽度来验证预测结果。对于每个点输出的预测区间,本文将通过计算区间的概率和宽度来进行预测区间改正,而不是仅仅通过减少基于误差的度量。根据文献,将预测区间覆盖概率PICP定义为[11]:

同样,归一化平均预测区间宽度NMPIL定义为[11]:
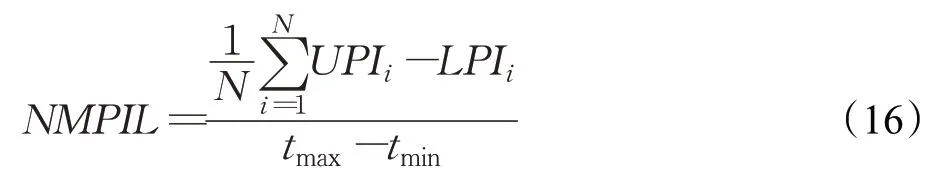
其中,tmax、tmin分别是样本中的最大值和最小值。如果NMPIL的值足够大时,则可以包含所有的真实值,但是这样就完全没有意义了。所以构造预测区间的验证标准是在PICP足够大的前提下,NMPIL足够小。然而,在理论上这两个目标函数是有冲突的,概率越高区间宽度自然会越大;区间宽度越小概率自然越小。为了解决这个问题,提出综合评价指标(Coverage Lengthbased Criterion,CLC)[12]:
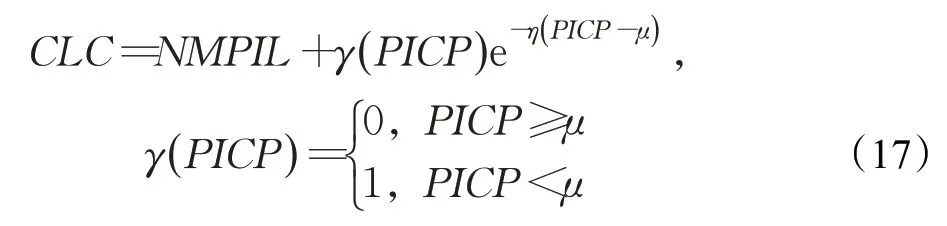
其中,μ=1-α,η称为惩罚参数,综合评价指标CLC越小越好。
2 实证分析
以“一带一路”经济带沿途的中国18个省市为决策单元。所有的评价指标来源于2017 年的《中国统计年鉴》《中国建设统计年鉴》《中国旅游统计年鉴》,目的是针对这18 个省市的旅游效率评估。参考已有的文献[13],选用3 个输入指标、2 个输出指标进行评价。通过模型(1)计算,结果如表1所示。
从表1 的第8 列θ值的结果可以看出,只有3 个省市(上海、福建、海南)的旅游效率是DEA 有效的,而剩下的省市的旅游效率全部都是无效,为了分析无效的原因,首先要对这些省市进行分类。文献[14]认为可以将DEA 得出的效率分为4 类:S1∈(0.98, ]1 为强相对有效,这一类中的单元只要稍微修改,就能达到最佳的组合配置;S2∈(0.8, ]0.98 为相对有效,这一类的单元除了需要修改资源的利用,还需要花上一点的时间;为相对低效区间,这一类的单元需要重新调整资源配置或者产出标准,同时需要一段时间来适应;S4∈(0, ]0.5 为非常低效区间,这一区间内的单元,需要大幅度地修改投入和产出,还要投入大量的时间进行不断调整。
由于DEA 计算的结果属于后评价的范围,评价的结果不能够完全说明结果,要想准确地将结果进行分类,需要通过神经网络模型进行区间预测,如果预测的结果正好完全落在Si中,可以认为该单元属于这个区间;如果预测结果部分落在某个Si中,可以通过公式判断。以分别落在S1、S2区间的预测区间为例。
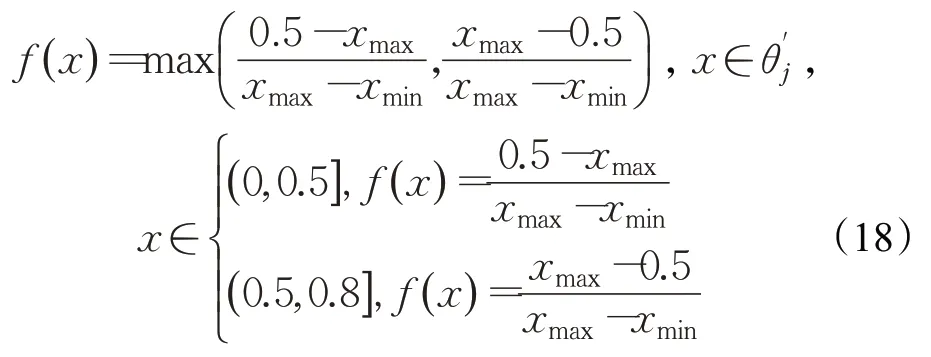
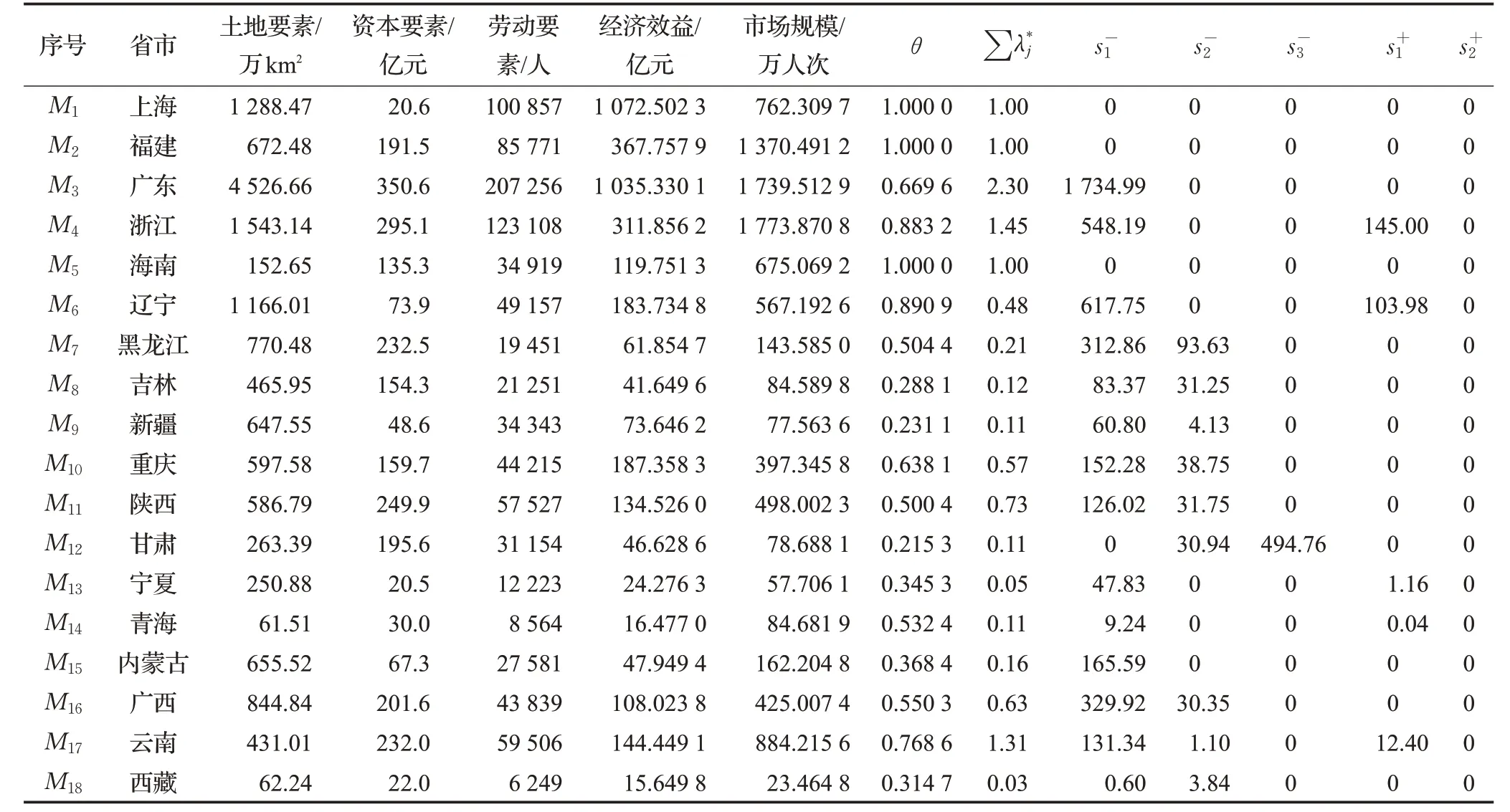
表1 18个省市旅游效率结果

表2 真实值与预测区间比较
基于1.3 节的相关模型和相关公式,利用Matlab编程求解,并且令置信水平分别为80%、90%、95%、99%。图2 显示了BP 神经网络经过多次训练好的预测图。在置信水平为80%的置信区间内,共有15 个样本点落在置信区间内。当置信水平为90%、95%、99%时,预测的结果明显比置信水平为80%的结果差很多,主要原因是样本的容量较少,但在一定程度上能够说明BP神经网络在效率区间预测上的可行性。
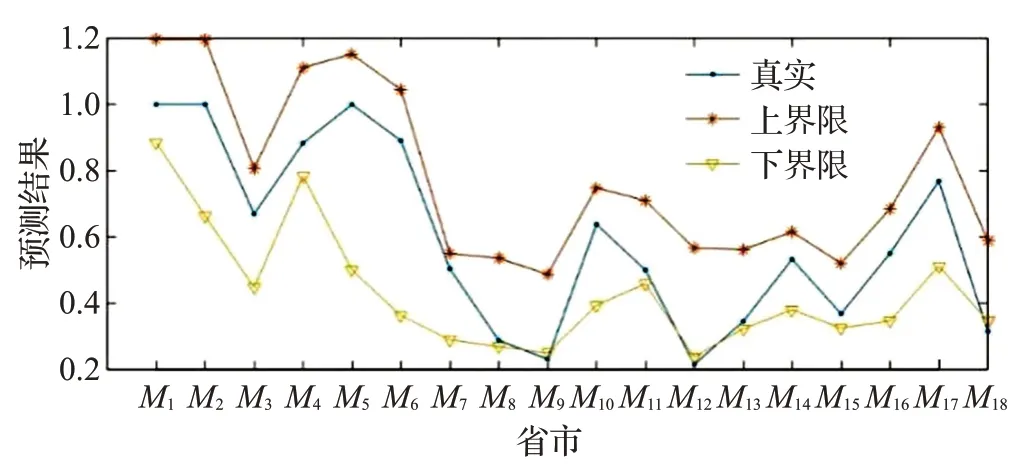
图2 BP神经网络预测区间结果
旅游效率为无效的省市效率点转化为效率区间的结果如表2所示,一共有15个样本点。
所有样本点的预测区间,利用公式(15)~(17)进行验证检验,结果如表3 所示。结果显示,CLC 的值低于0.5,具有较好的预测性能,所以可以利用区间数来说明样本的效率值。根据公式(18)对12个落在预测区间内的样本进行分类,结果如表4 所示,真实值和预测区间之间分类的结果会存在少量的差异。
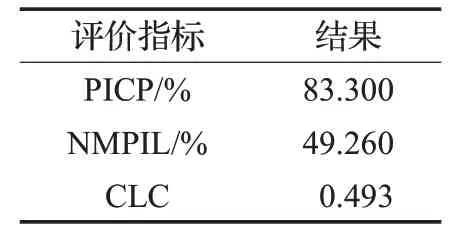
表3 验证模型结果
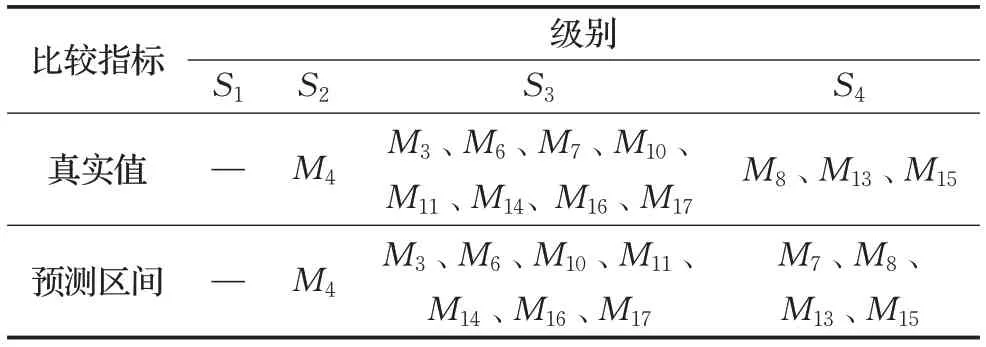
表4 真实值与预测区间的分类结果
可以发现,如果按真实的效率值和预测区间进行分类,结果是存在差异的,主要因为样本系统的复杂性和不确定性造成。对于这样的差异,该选择哪一种分类方式,本研究通过分析差异点来探讨此问题,同样以这些点为例分析无效点改进的方法。由结果可以看出,M7为样本的差异点。
M7代表着是黑龙江省。黑龙江省作为中国最北的省份,被大家誉为“冰雪之城”。但是哈尔滨商业大学的研究团队在做黑龙江省的旅游业景气指数研究时[15],指出黑龙江省旅游行业的许多问题:经营项目雷同、旅行社不正当竞争、宰客现象严重等一系列问题。这就导致通过训练得出M7的预测区间下限到达非常低的位置,导致预测区间划分到S4,本文认为可以将M7划分到S4集合中。
对于落在S4中黑龙江省的旅游效率问题,提出以下几点建议:(1)根据表1 的计算结果本文认为,可以减少或者停止对土地要素和资本要素的投入,即减少绿地面积和住宿业、餐饮业的投入,同时管控住宿业和餐饮业乱收费的现象,让旅客且真实地感受旅游市场的公平;(2)大力构建旅游品牌,增强旅游竞争力,吸引游客的流入;(3)拓宽国际旅游业务,由于黑龙江的地理位置优越,位于中国边境地带,可以推进境外游,吸纳境外游客来黑龙江旅游。分析结果表明黑龙江的旅游效率比较低,需要黑龙江省投入大量的时间和精力来改善现状。
3 结论与展望
本文研究的主要目的是找出一个最佳的神经网络模型进行效率区间预测,虽然神经网络模型不是一个新的概念,但还是有很多问题没有解决,这也对本文的模型精度产生了影响。随机过程和复杂系统的不确定性的不断积累会导致神经网络点预测的性能,特别是在进行效率预测时。针对此问题,本文假设样本真实值与预测值的误差成正态分布,采用Delta 方法对每一个点预测构建预测区间。因为在训练神经网络时,只需要计算一次雅可比矩阵,所以计算难度大大下降。在验证预测区间结果方面,采用新的测度模型,比传统的验证标准更具有说服力[11]。最后在利用18 个省市的旅游效率进行预测,验证结果误差较小,包括有效点在内总有15个样本真实值点在预测区间内,误差为16.7%,CLC 低于0.5,说明了预测区间具有较好的可靠性。由于本文所给的样本数量少,指标选择具有主观性等问题,所以本文研究仍需要进一步的改进。
未来研究改进方向:(1)在保证精度的前提下,考虑加入含有噪声的统计数据;(2)将本文的模型用于更加复杂、模糊的系统中,对其效率进行区间预测。
