一种基于聚类的图卷积多示例学习算法
2021-02-02王江晴毕建权帖军孙翀艾勇
王江晴,毕建权,帖军,孙翀,艾勇
(中南民族大学 计算机科学学院&湖北省制造企业智能管理工程技术研究中心,武汉 430074)
多示例学习的概念源自医学领域制药过程中何种分子适合制药问题[1],一个对象被定义为一个包,每个包由多个示例组成并由一个标记与之对应,学习的目的是建立一个学习器,对未知标记的包进行分类[2].目前,多示例学习算法被成功地应用到图像分类与标注[3]、自然语言处理[4]、股票趋势预测[5]等领域.
近年来,多示例学习的研究可以分为挖掘示例间关系、挖掘包与标记间关系和关键示例检测[6,7]三种.MIGraph、miGraph方法[8]是典型的基于图结构挖掘示例间关系的多示例学习方法,核心思想是将包视为图,包中的每个示例视为图中的节点,分别利用ε-graph和亲和度矩阵构建包图结构,设计一个图核函数来捕获包图间各节点的相似性,用以作为构建分类器的依据.由于随机选择包中的示例构建图结构,因此在模型分类准确率上还有较大的提升空间.SCPMK_MIL方法[9]利用谱聚类方法获取潜在的正示例代表,利用径向基函数和金字塔核分别挖掘正示例间和负示例间的相似性,但未充分考虑包间的相似性问题.MI-SVM方法[10]和DD-SVM方法[11]使用有监督学习的支持向量机SVM挖掘包与标记间关系,虽然这些方法具有较好的泛化能力和小样本学习能力,但是求解的目标函数很难直接计算,导致训练效率较低.MGML-ELM方法[12]、BELM-MIL方法[13]和RBF-MIP方法[14]在此基础上利用神经网络提高模型的训练效率,但是降低了模型的可解释性,同时在基于图结构的方法中存在子图转为特征向量造成模型运行效率低下等问题.
本文针对随机选择包中的示例构建图结构和模型运行效率低下的问题,提出了一种基于聚类的图卷积多示例学习算法MIL-GCC(Multi-Instance Learning Algorithm of Graph Convolution Base on Clustering).MIL-GCC主要分为2个步骤:(1)构建包的图结构,利用k-means聚类方法获取包中具有代表性的示例作为包图中的节点,然后挖掘超示例间关系构建包图的边;(2)构建图分类器,将构建好的包图结构转为邻接矩阵的形式作为图卷积层的输入,利用图卷积对节点重要度分数进行学习,筛选重要度分数排序靠前的节点以及这些节点组成的包图结构作为模型分类的依据.
1 问题描述与形式化定义
MIL-GCC的目标是从训练集中学习一组包图结构与标记间的关系,用于对未知标记包分类.
令X=d表示示例空间.定义D={(X1,y1),…,(Xi,yi),…,(Xm,ym)}表示具有m个包的MIL数据集,其中Xi={xi1,…,xij,…,xipi}⊆X被称为一个包,yi∈Y={0,1}是Xi所属的标记;xij∈X是一个由d维特征向量表示的示例,即xij=[xij1,…,xijl,…,xijd]′;pi表示Xi中示例个数的总数.如果存在index∈{1,…,j,…,pi},使得xi,index是一个正示例,则Xi是正包且yi=1;否则Xi是负包且yi=0.该模型的目标是从数据集D中学习一个多示例分类器f∶2X→Y.
2 构建包图结构
MIL-GCC算法的第1步是构建包图结构.包图结构的构建可以分为两部分,一部分是选取每个包中的超示例作为包图的节点,另一部分是根据超示例间关系在定义好的约束条件下创建包图的边.本节首先对超示例、包图的概念进行了定义,然后对构建包图的具体实现进行详细的描述.
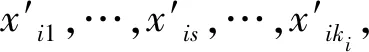
定义2 包图.对数据集D而言,包图是指每个包Xi的图结构信息,由节点集Vi={vi1,…,vij,…,vini}、边集Ei={(via,vib),…,(vic,vid)}组成,其中,a,b,c,d∈{1,2,…,ni}且a≠b,c≠d,|Ei|=ei表示包图中边个数的总数.包图简记为:gi,i∈{1,2,…,m}.
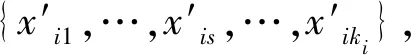
(1)
其中,算法1中C(2S×2S)表示每个包聚类的搜索范围,S=sqrt(pi/k)表示相邻聚类中心的步长,pi代表第i个包中示例总数,k为第i个包中簇中心总数;l(ij)表示第i个包中第j个示例所属的簇类别,初始值为-1;d(ij)表示第i个包中第j个示例到任意簇中心的距离,初始值为∞;dist表示包中任意示例与簇中心之间的欧式距离,计算公式如下:
(2)

(3)
通过算法1将数据集D中的带标记的包映射成为一组带标记的包图之后,可以采用很多已有的方法挖掘包图间的相关关系并建立分类器,例如建立一个图核函数表示包图之间的相似性,然后利用支持向量机SVM解决分类问题,或者通过挖掘所有包图的频繁项信息子图表示其相似性,然后利用极限学习机ELM解决分类问题.虽然上述方法可以有较好的分类准确率,但是间接在包图结构上建立分类器会造成模型运行效率低下问题,因此,本文基于直接在包图结构上建立分类器的思想,利用图卷积进行图分类器的构建.

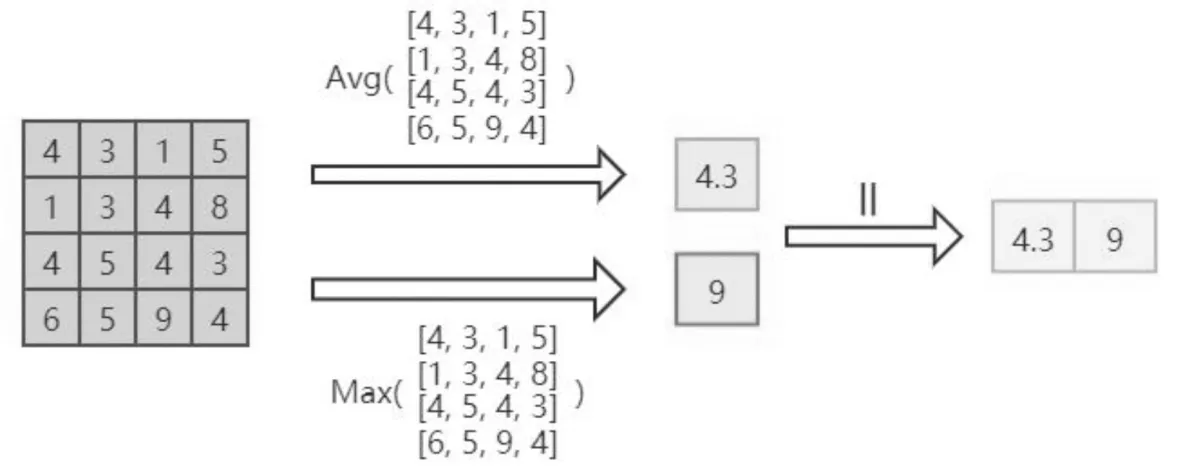
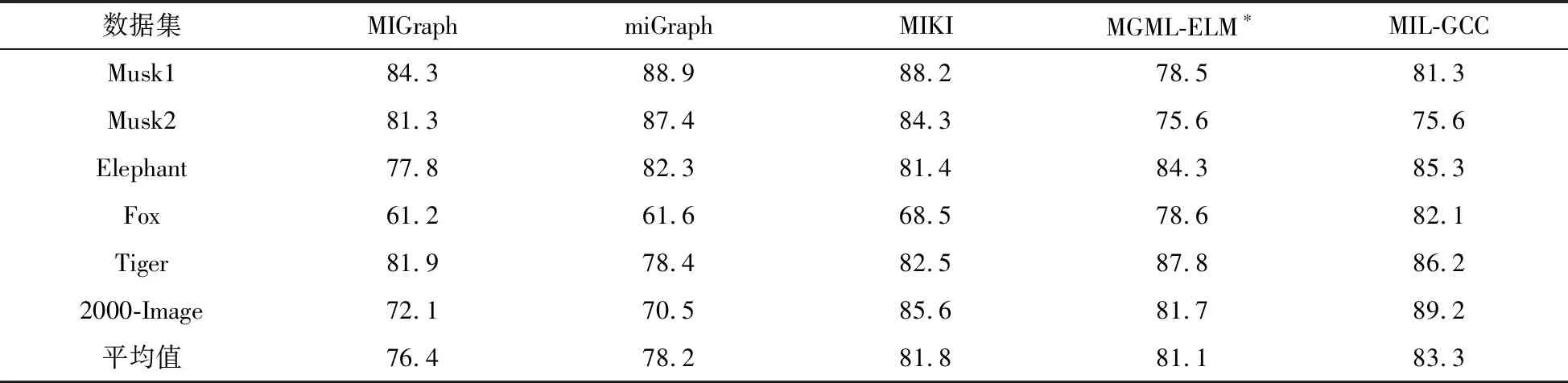
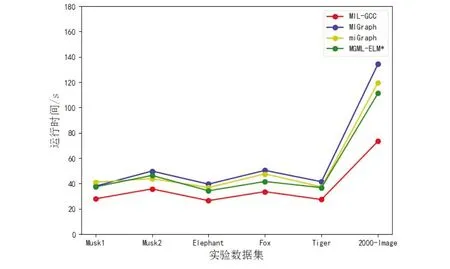
算法1 基于超示例的包图结构构建算法输入:数据集D,聚类簇数k和阈值β输出:带有标记的一组包图gi,i∈{1,2,…,m}1for i in {1,2,…,m} do2随机选择k个超示例簇中心{x′i1,…,x′is,…,x′iki}3初始化xij所属类别为l(ij)=-1,距离d(ij)=∞4repeat5for x′ilin {x′i1,…,x′is,…,x′iki} do6for xijin C(2S×2S) do7 计算x′il与xij之间的欧式距离dist8 if dist 本文利用公式(4)获得每个包图gi的邻接矩阵信息,并作为图卷积层的输入. (4) 在计算每个节点重要度分数的基础上,还考虑了包图间的不同尺度问题,即对于任意2个包图gi和gj,其中i≠j,存在ni≠nj和ei≠ej的情况,通过设置一个保留节点比例的超参数δ∈(0,1],对每个zscorej进行降排序,筛选前δni个节点进行特征的学习.每次筛选相当于对包图结构和特征进行更新,具体的包图结构更新计算公式如下: A′=Amask,mask,V′=Vmask,:, 其中,A′和V′分别表示保留节点之间的邻接矩阵和节点特征矩阵;Amask,mask表示根据前δni个节点的节点索引mask对A同时进行行切片和列切片;Vmask,:表示按照mask对V进行列切片. 虽然通过层层丢弃节点的方式可以提高包图中远距离节点的融合效率,但是会降低对所有节点信息的有效融合,因此,本文采用全局最大池化与全局平均池化[17]拼接的方式对包图的全局信息进行一次性融合,拼接过程如图1所示. 图1 全局平均池化与全局最大池化拼接过程Fig.1 Splicing process of global average pooling and global maximum pooling 最后将学习到的包图全局信息用于分类.基于图卷积的图分类器模型相比于已有的基于SVM、ELM等分类模型,忽略了包图中节点数和边数对模型的影响,因此,在包图中节点数和边数较大时具有一定的优势. 本文选取5个多示例学习基准数据集(Musk1、Musk2、Elephant、Fox、Tiger)和1个真实图像数据集(2000-Image)对提出的算法进行评价.多示例学习基准数据集的具体属性信息见表1.2000-Image图像数据集汇总包含20类COREL图像,每个类别由100张像素为64×96的彩色图像组成,每个图像都视为一个包,图像中的每个段被视为一个示例. 表1 多示例学习基准数据集具体属性信息Tab.1 Specific attribute information of multi-instance learning benchmark datasets 在实验中,本文使用10倍交叉验证来比较结果.将数据集分为10份,轮流将其中9份作为训练集,一份作为测试集,进行实验,将10次结果的准确率的平均值作为算法的评判指标,具体的计算公式如下: 其中,N=10,sq表示第q次结果中所有Xi被正确分类的总数,tq表示第q次结果中样本总数. 实验环境为16 G内存的Windows10操作系统,其CPU为AMD Ryzen 5 4600U with Radeon Graphics,主频为2.1 GHz,编程语言为Python 3.7.6. 本文的实验过程主要分为4个部分,第1部分是对数据集进行预处理,即确定每个输入数据集中示例规模的一致;第2部分是构建包图结构,本文采用局部k-means方法获取每个包中的超示例,然后根据边成立的约束条件确定包图结构,并根据训练/测试集所占比随机划分训练/测试集;第3部分为了保证实验对比的公平性,实验对基于多示例多标记的MGML-ELM方法进行了单标记的条件约束,然后和MIL-GCC分别进行分类器的构建;第4部分则是通过评判指标对实验结果进行分析与总结. 影响实验结果的参数主要有:示例的聚类数n,阈值β,图卷积隐藏层层数h,节点保留比δ.为了确定模型的最优分类准确率,本文实验依据表2的实验各参数取值范围分别对模型进行准确率的计算,其中,对于基准数据集,在n=20,β=1,h=60,δ=0.6时,可达到最优分类准确率;对于图像数据集,在n=100,β=1,h=120,δ=0.8时,可达到最佳分类准确率. 表2 实验各参数取值范围Tab.2 The range of parameters in the experiment 实验的对比结果见表3,通过在基准数据集和图像数据集上与MIGraph[8]、miGraph[8]、MIKI[6]、MGML-ELM*(MGML-ELM进行单标记条件约束后的算法简称)[12]的比较,可以发现MIL-GCC在Musk1、Musk2数据集上没有MIGraph、miGraph和MIKI分类准确率高,但是,在图像类数据集上相对其他3种方法具有很好的分类准确率,同时从所有数据集平均准确率的角度看,MIL-GCC具有一定的分类准确率优势. 表3 基于各数据集下的各算法准确率对比Tab.3 Comparison of accuracy of each algorithm based on each dataset % 经实验验证,MIL-GCC在Musk1、Musk2数据集上准确率不高的主要原因是,MIL-GCC在数据集预处理过程选择局部k-means算法不利于挖掘Musk1、Musk2数据集中超示例相关性,采用k-means算法准确率可达90%,但MIL-GCC在图像数据集准确率和总数据集的平均准确率上未占优势. 同时,为了验证MIL-GCC可以有效地提高算法的执行效率,分别在基准数据集和图像数据集上与MIGraph、miGraph、MGML-ELM*算法进行比较,对比结果如图2所示,可以清晰地发现基于图像数据集,MIL-GCC算法相对于其他3种算法需要的运行时间较少,因此,MIL-GCC算法在处理规模较大的数据集时也具有一定的优势. 图2 各算法执行效率对比Fig.2 Comparison of execution efficiency of each algorithm 本文提出的MIL-GCC算法通过利用局部k-means聚类方法确定构建包图的超示例的集合,然后通过挖掘示例间的相关性确定包图结构,最后基于图卷积思想直接在包图上建立图分类器,忽略了包图中节点数和边数对图分类模型的影响.实验验证了MIL-GCC的性能,同时在图像分类领域有明显的成效.然而,MIL-GCC在分子数据集上还存在提升的空间,因此,如何更充分地选择构建包图的超示例成为下一步的主要工作.3 构建图分类器
4 实验与分析
4.1 数据集与实验环境

4.2 实验结果与分析

5 结语
