一种基于节点稳定性的社区发现算法
2021-01-30郑文萍刘美麟穆俊芳
郑文萍 ,刘美麟 ,穆俊芳 ,杨 贵
(1.山西大学计算机与信息技术学院,太原,030006;2.计算智能与中文信息处理教育部重点实验室,山西大学,太原,030006;3.山西大学智能信息处理研究所,太原,030006)
现实世界中的许多复杂系统都可以抽象成网络,如社交网络、基因调控网络、交通运输网络、电力传输网络、引文网络等[1-4].社区结构是复杂网络的重要特征,即一个网络中节点形成了若干个社区,社区内部节点连接相对紧密,社区间节点连接相对稀疏.网络中的社区通常对应复杂系统中的一些特殊功能模块,如社交网络中具有某种特定关系的群体、基因调控网络中特定生物功能的蛋白质复合体、互联网中具有相同主题的网站集合、引文网络中相同兴趣的研究群体等.在网络上进行图聚类分析,可以挖掘网络中的潜在社区,为分析和理解复杂系统的拓扑结构及动力学特性提供指导[5].
1 相关工作
研究者已提出许多社区检测算法,主要分为基于模块度优化的算法、基于谱聚类的算法、基于信息传播的算法等.也有许多用于评价社区划分结果好坏的模块度指标,使用最广泛的是2004 年Newman and Girvan[6]提出的模块度.许多基于模块度优化的算法被提出,如BGLL[7],Leiden[8]等,其基本思想是从对网络节点所有可能的划分中寻找使得模块度最大的社区划分,通常可以找到满足社区定义的较稳定的社区划分结果,但由于计算代价较高且受模块度的精度限制[9],此类算法通常不适用于大规模网络中的社区发现,并且无法探测规模较小但结构显著的社区.基于谱聚类的社区发现算法是利用网络节点间的相似性构造相似图,根据相似矩阵或其拉普拉斯矩阵的前k个特征向量进行节点表示,并利用传统聚类方法对节点聚类.研究者根据不同的谱映射方法和准则函数设计了多种谱聚类社区发现算法,以发现多种规模尺度的社区,如FCM(Fuzzy C -Means)[10],SSCF[11]等.但由于谱聚类算法中需要进行矩阵运算,因此不适用于规模较大的复杂网络上的社区发现.
基于信息传播的算法通过模拟信息流在网络中的传播过程进行社区发现,主要有标签传播算法(Label Propagation Algorithm,LPA)及其改进[12-14]、基于信息编码的算法Infomap[15]、基于随机游走的算法Walktrap[16]等.标签传播算法最早是Raghavan et al[12]于2007 年提出的,其基本思想是将节点邻域中出现次数最多的社区标签作为该节点的标签.标签传播算法具有接近线性的时间复杂度,已被广泛应用于大规模复杂网络的社区发现,但由于受到标签传播过程中节点更新顺序、节点标签选择等多种随机因素的影响,社区发现结果表现了较强的不稳定性.也就是说,即使在同一个网络上执行多次,LPA 算法也可能会得到差异很大的社区发现结果.Zhao et al[17]根据节点邻域中标签分布的香农熵确定节点更新顺序以提高算法结果的稳定性.Li et al[14]提出一种分阶段的标签传播算法LPA-S,选择最相似邻居节点的标签更新当前节点标签进行社区发现.Barber and Clark[18]和Liu and Murata[19]提出的LPAm 算法在标签传播过程中通过优化模块度来发现社区.郑文萍等[20]提出一种改进的标签传播算法LPA-TS,定义节点的社区参与系数以确定节点更新顺序,并依据节点间相似性更新节点标签,得到最终的社区划分结果.这些改进的标签传播算法降低了节点更新顺序和标签选择过程的随机性,在一定程度上提高了算法的稳定性.
随着要处理的网络数据越来越复杂,节点间的关系也越来越复杂,算法结果的不稳定性越来越强.尽管这样,多次运行LPA 算法得到不同的社区划分结果的同时,也为确定在社区形成过程的节点稳定性提供了有效信息.比如一部分具有明确社区归属的节点通常会表现稳定,而一些社区间的重叠节点或社区内的边缘节点在社区发现过程中表现出较高的不稳定性.利用标签传播算法所提供的节点稳定性信息有望进行更有效的社区发现.
本文根据社区划分结果定义节点在该社区划分下的标签熵,度量节点在社区发现过程中的稳定性,以此为基础提出一种基于节点稳定性的社区发现算法(Node Stability-based Algorithm,NSA).首先运行t次社区发现算法得到原网络的t个社区划分,计算各节点对应社区划分的标签熵,从而确定网络的稳定节点集S.然后,在原网络上抽取包含稳定节点集S的连通子网络并在该子网络上进行初步社区发现,得到初始类簇.最后,计算其他不稳定节点与初始类簇的距离,将尚无社区归属的节点根据归属度划分至初始类簇中,得到最终聚类结果.在四个带标签和八个无标签的网络数据集上,本文的NSA 算法与五种经典社区发现算法的比较实验表明,NSA 算法能得到更稳定的社区划分结果,且在NMI和模块度等方面表现了良好的算法性能.
2 基础知识
通常用G=(V,E)表示一个复杂网络,其中V={v1,v2,…,vn} 表示节点集,E表示边集.除非特别声明,以下仅对无向简单图进行研究.令Nv={u|(u,v)∈E∧u∈V} 表示节点v在G中的邻接点集合,称为v的直接邻域.记节点v的度dv=|Nv|.对图G的节点子集S,将图G中与S中节点直接相邻且不在S中的节点集合称作S在G中的邻域,记为
对图G'=(V',E'),若V'⊆V且E'⊆E,则称G' 是G的一个子图.对节点u,v∈V',如果(u,v)∈E则(u,v)∈E',那么称G'为节点子集V'的导出子图,记为G[V' ],在不引起混淆的情况下简记为[V' ].
对图G=(V,E),称Ω={C1,…,Ck} 为图G的一种社区划分,其中Ci⊆V,Ci≠∅(1≤i≤k)且Ci∩Cj=∅(i≠j).映射f:Ω→{1,…,k} 为Ω中的每个社区赋予唯一的标签.对节点v∈Ci,称f(Ci)是节点v在划分Ω下的社区标签,记作lΩ(v)=f(Ci).对节点子集S⊆V,称lΩ(S)={lΩ(v)|v∈S} 为子集S对划分Ω的社区标签集.
在信息论中,Shannon 熵[21]是度量信息不确定性程度的重要方法,若信息源有n个取值,概率分 别为{p1,p2,…,pn},则 其 Shannon 熵 为利用Shannon 熵可以度量节点v邻域的社区分布的不确定性,进而度量节点v在社区划分过程中的稳定性.
3 基于节点稳定性的社区发现算法
考虑节点v的稳定性与社区划分结果直接相关,为了更好地获取网络中的稳定节点集合,可以参考多种社区划分结果确定网络的稳定节点集.目前一些社区发现算法有近似线性时间复杂度,但运行结果表现不稳定,也就是说,多次运行算法的社区发现结果差异很大.有效利用社区发现过程中的节点社区归属的不确定性对网络中节点的稳定性进行度量,有望进一步提高社区发现质量.基于此,提出一种基于节点稳定性的社区发现算法,首先根据快速社区发现算法对网络进行预处理得到网络中的稳定节点集,对稳定节点集扩展所得的连通子图进行聚类得到初始社区,根据未聚类节点对初始社区的归属度确定其最终社区归属.
3.1 基于标签熵的节点稳定性度量 可以用某种社区发现算法所得到的社区划分结果来衡量网络节点在社区发现过程中的稳定性.对图G中的一个节点v,如果其邻域Nv中节点的社区分布比较集中,则v具有相对稳定的社区归属;反过来,如果其邻域Nv中节点的社区分布比较分散,则v在社区发现过程中表现不稳定.为了利用信息熵对社区发现过程中节点的稳定性进行度量,首先根据其邻居节点的社区归属分布定义节点v在社区划分Ω下的标签熵.
定义1 标签熵假设Ω={C1,…,Ck} 为图G的一种社区划分,标签映射为f:Ω→{1,…,k},节点v的邻域节点标签集合记作lΩ(Nv)={l1,…,lkv},其中kv代表v邻域内的标签类别数.令Sv(li)={u|lΩ(u)=li,u∈Nv} 为v邻域中标签为li的节点集,sv(li)=|Sv(li)|.定义节点v在划分Ω下的标签分布为:

节点v的标签熵HΩ(v)可以对v在划分Ω下社区归属的稳定程度进行度量,HΩ(v)越小,节点v在社区发现过程中具有较稳定的社区归属.图1给出了Karate[23]网络的真实社区划分结果,包括34 个节点,78 条边,2 个社区.其中节点2 的度d2=10,其邻域中的节点分散到两个社区C1和C2中,标签分别为l1和l2,即lΩ(N2)={l1,l2} 且s2(l1)=5,s2(l2)=5,则节点2 在该划分下的标签分布PΩ(2)={0.5,0.5},对应的标签熵HΩ(2)=1.而对节点23,其邻居节点都属于社区C2,因此在该划分下的标签熵HΩ(23)=0.可以看出,节点2 比节点23 具有更高的不稳定性.
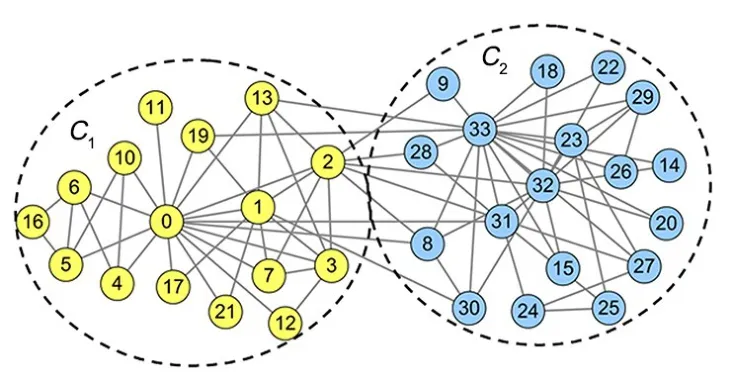
图1 Karate 网络的真实社区划分结果Fig.1 A community detection result of of Karate network
3.2 确定稳定节点集随着网络数据越来越复杂,不同的社区发现算法得到的社区划分差异越来越大,即使是同一个算法多次运行也可能得到差异较大的社区划分结果.这些不同的社区划分结果为确定在社区形成过程的节点稳定性提供了有效信息,通常具有明确社区归属的节点会表现稳定,而一些社区间的重叠节点或社区内的边缘节点在社区发现过程中表现出较高的不稳定性.
一些快速社区发现算法如标签传播算法具有近似线性时间复杂度,能在很短的时间内得到网络的一种社区发现结果,然而算法的多次运行通常会得到差异较大的一些社区发现结果,这种算法结果的不稳定性影响了其在实际社区发现问题中的应用.实际上,社区发现结果的不稳定通常是由一些社区边缘节点对社区归属度低而引起的,社区归属相对确定的节点在算法多次运行过程中表现也相对稳定.针对这一特点,算法NSA首先在网络上运行t次标签传播算法得到t种社区划分Ω1,…,Ωt,计算每个节点v在不同划分下的标签熵HΩi(v),则网络稳定节点集定义为:
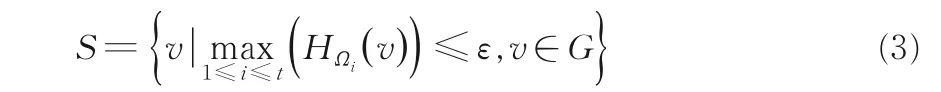
其中,ε称作稳定性阈值,不稳定节点集合为V-S.
3.3 稳定节点子图聚类由于稳定节点的社区归属相对确定,对网络中稳定节点进行聚类可以得到比较确定的初始社区,对初始社区进行扩展有助于得到更稳定的社区划分结果.同时,由于网络中稳定节点所占比例通常较小,在时间允许的范围内,可以利用基于模块度优化或谱聚类等比较精确的算法对稳定节点进行聚类,得到尽可能准确的初始社区.
由稳定节点子集S导出的子图G[S]通常不连通,无法在G[S]上运行图聚类算法得到初始社区划分.因此?,需要从原网络G中抽取一个包含稳定节点集S的连通子图GS,使得S⊆V(GS)且V(GS)-S中的节点不稳定性尽可能低.
由稳定节点集S所构造的连通子图GS包含原网络G中社区划分相对稳定的节点,因此在GS上进行社区发现,会得到比较稳定的划分结果.此外,GS中的节点在原网络G中所占比例比较低,这就允许选择在较小规模网络上具有较好性能的社区发现算法得到初始社区.
本文采用LPA 算法对GS中节点进行聚类,得到初始社区为其中k为初始社区个数.
3.4 未聚类节点处理集合V(G-GS)中的节点还没有社区归属,需要对这部分节点进行处理.节点u∈V(G-GS)对社区的归属度定义为:

其中,1≤i≤k.sim()u,vj表示节点u与中节点vj的相似性;φ是一个聚合函数,将节点u与中各节点的相似性聚合为u对初始社区的归属度.本文中,

3.5 NSA 算法算法1 给出了本文所提的基于节点稳定性的社区发现算法的框架 .


3.6 实 例以图1 的空手道俱乐部网络(Zachary's Karate Club)[22]为例解释算法的具体步骤.
首先,在Karate 网络上运行三次标签传播算法,得到三种社区划分结果,分别为Ω1,Ω2,Ω3.计算Karate 网络各节点在每种社区划分结果上的标签熵,如表1 所示.
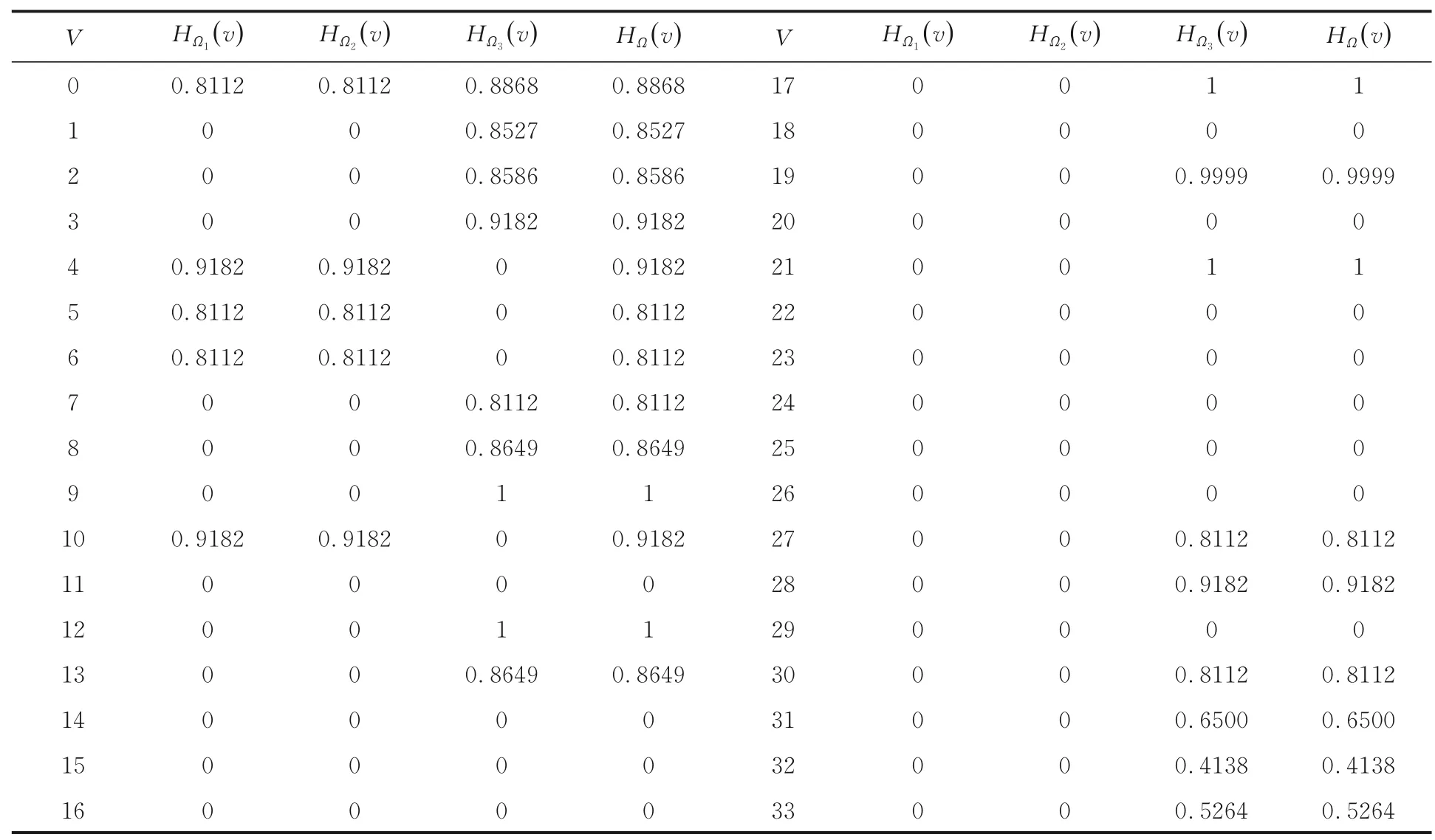
表1 Karate 网络节点的标签熵Table 1 The label entropy of nodes on Karate networks
取ε=0,根据式(3)确定网络稳定节点集S={11,16,14,15,18,20,22,23,25,29,24,26} .图2 给出了利用S所构造的连通子图GS,其中蓝色表示S中的节点,扩展的节点用绿色表示.可以看出,稳定节点通常分布在一个大度节点的周围,并且节点度不会太大.这也符合实际情况,如在社会网络中,一个朋友圈较小的成员通常有比较稳定的兴趣社区.
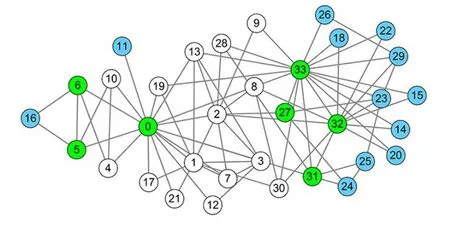
图2 Karate 网络上得到的稳定节点集S 及包含S 的连通子图GSFig.2 A set of stable nodes on the Karate network and a connected subgraph GS
图3 展示了在连通子图GS上运行标签传播算法所得到的初始社区划分;图4 给出了对未聚类节点进行处理后所得到的社区划分结果,其中包括三个社区,与真实划分比较接近.图3 和图4中,每种颜色代表一个初始社区.
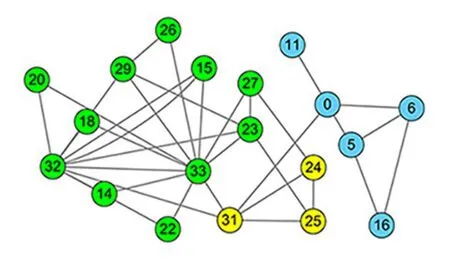
图3 由GS所得的初始社区划分Fig.3 Initial communities of GS
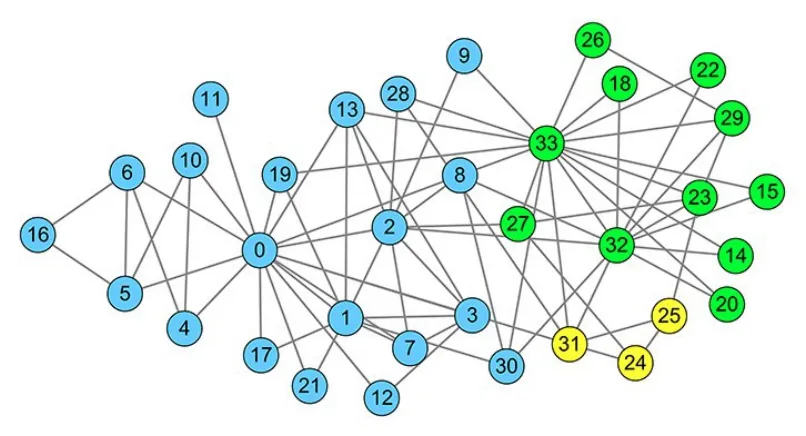
图4 算法NSA 所得的最终社区划分结果Fig.4 Final communities detected by NSA
3.7 时间复杂度分析对一个包含n个节点,m条边的网络G,算法NSA 首先利用t次标签传播算法计算节点的标签熵获取节点的标签分布及标签熵,选择网络的稳定节点集.由于标签传播算法有近似线性的时间复杂度O(m)[12],获取节点标签熵的总时间代价为O(tm);为进一步获取网络中的稳定节点集,要按标签熵从小到大的顺序对节点进行排序,时间代价为O(nlgn).因此选择网络稳定节点集的总时间代价为O(tm+nlgn).
接下来,算法从原网络中抽取一个包含稳定节点集的连通子图,并对该连通子图进行聚类,得到初始社区.抽取连通子图的时间代价为O(m),若利用标签传播算法进行聚类,时间代价近似为O(m).
最后,计算未聚类节点与已有社区的连边数得到节点对社区的归属度,将未聚类的节点分配到已有社区,得到最终的聚类结果,时间代价为O(m).
综上所述,若利用标签传播算法对连通子图进行聚类,则本文提出的NSA 算法的总时间代价为O(tm+nlgn).实际上,由稳定节点构成的连通子图规模较小,可以利用准确度高的一些算法(如BGLL,CNM 等)对其进行聚类.
4 实验结果与分析
在四个带标签的真实网络和八个无标签真实网络上,将本文所提算法NSA 与经典的社区发现算法LPA,Infomap,Walktrap,BGLL 和LPA-S 进行比较实验.数据基本情况如表2 所示.
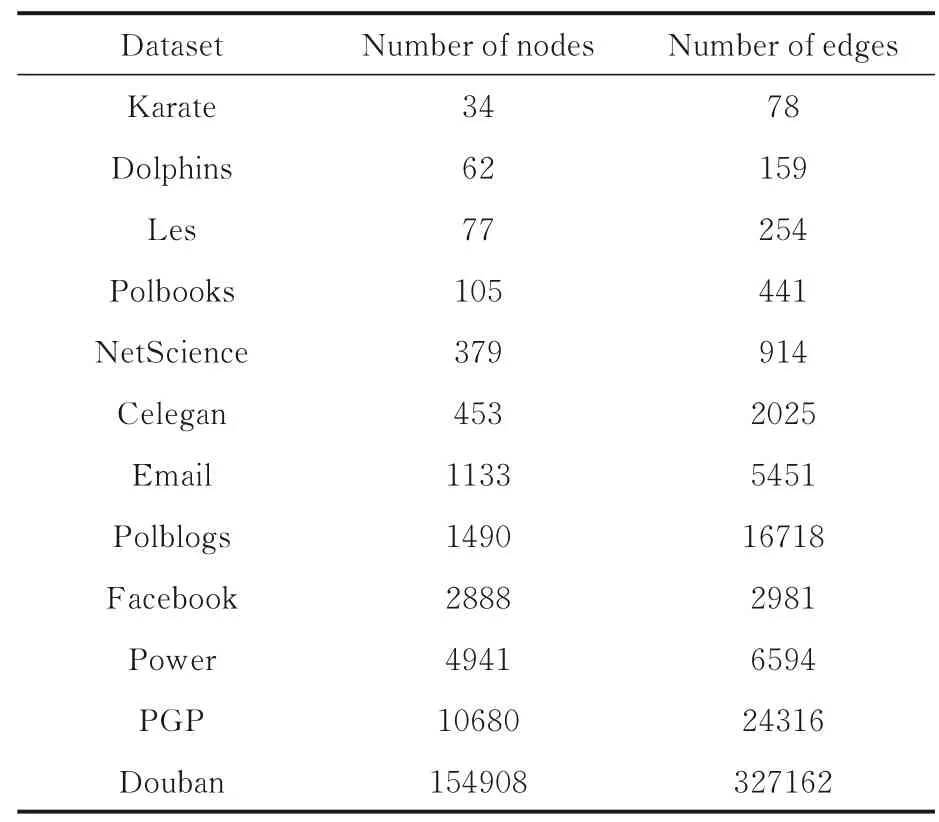
表2 实验数据集的基本情况Table 2 Datasets used in experiments
4.1 评价标准
4.1.1 标准互信息(NMI)若算法的社区发现结果为Ω={V1,V2,…,Vk},带标签的数据集上的原始划分结果为O={O1,O2,…,Ok'}.对集合Vi和Oj(1≤i≤k,1≤j≤k'),令Ti,j=|Vi∩Oj|,对有标签数据集,选用标准互信息(NMI)[23]对聚类结果进行评价,如式(5)所示:
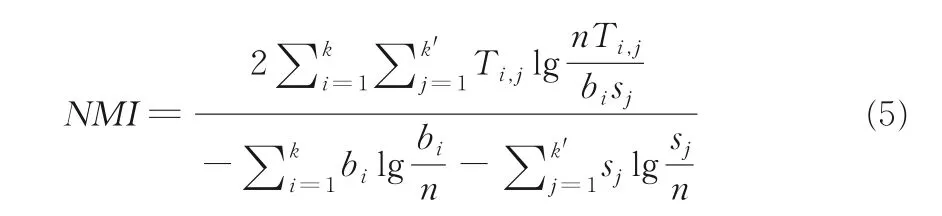
划分结果与原始划分的吻合程度越高,NMI的值越高.
4.1.2 模块度(Q)对于没有标签的数据集,选用Newman and Girvan[6]提出的模块度对聚类结果进行评价,定义如式(6)所示:
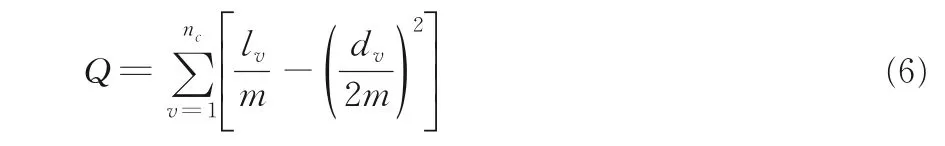
其中,m是网络中边的总数,nc是社团的数量,lv是社团v内部所包含的边数,dv是社团v中所有节点的度值之和.模块度越高代表聚类结果越好.
4.2 实验结果在带标签网络上,通过最终社区划分结果与真实社区的NMI指标的对比进行算法性能的比较.在无标签网络上,由于没有真实社区划分,因此采用模块度对算法性能进行比较.为了评估算法的稳定性,通过计算20 次实验结果所得的社区划分方差进行比较.
4.2.1 带标签网络的实验比较结果表3 给出了在空手道俱乐部(Karate)[22]、海豚社交网络(Dolphins)[24]、美国政治书网络(Polbooks)、政治博客网络(Polblogs)四个带标签的真实网络上,算法所得到社区的NMI值比较情况,可以看出,本文的NSA 算法得到的社区划分结果与真实社区更符合,表中黑体字是最好的结果.

表3 本文算法和五个对比算法在带标签网络上的实验结果对比Table 3 Experimental results on labeled networks of our algorithm and other five algorithms
4.2.2 无标签网络的实验比较结果表4 给出了在Les,NetScience,Celegan,Email,Polblogs,Facebook,Power,PGP,Douban 等无标签网络上的模块度比较结果(此处将去除标签的Polblogs网络看作一个无标签网络进行对比实验),最后一行给出了算法在所有网络下所得社区划分模块度的平均值,表中黑体字是最好的结果.
可以看出,本文算法在大多数情况下得到了较好的社区划分结果.由于BGLL 是基于模块度优化的算法,在网络规模较小的时候能够得到模块度更优的算法.然而,由于计算代价较高且受模块度的精度限制,BGLL 算法不适合在更大规模网络中进行社区发现.本文算法性能优于其他基于信息传播的算法,如LPA,Walktrap,LPA-S等.Infomap 算法与本文算法NSA 性能比较接近,而算法NSA 的平均值略高于Infomap 算法.
4.2.3 稳定性比较结果在统计描述中,方差[25]可以用来计算每个变量与总体均值之间的差异.为了对算法划分结果的稳定性进行评估,本文通过计算20 次实验结果模块度值的方差来进行比较,如式(7)所示:
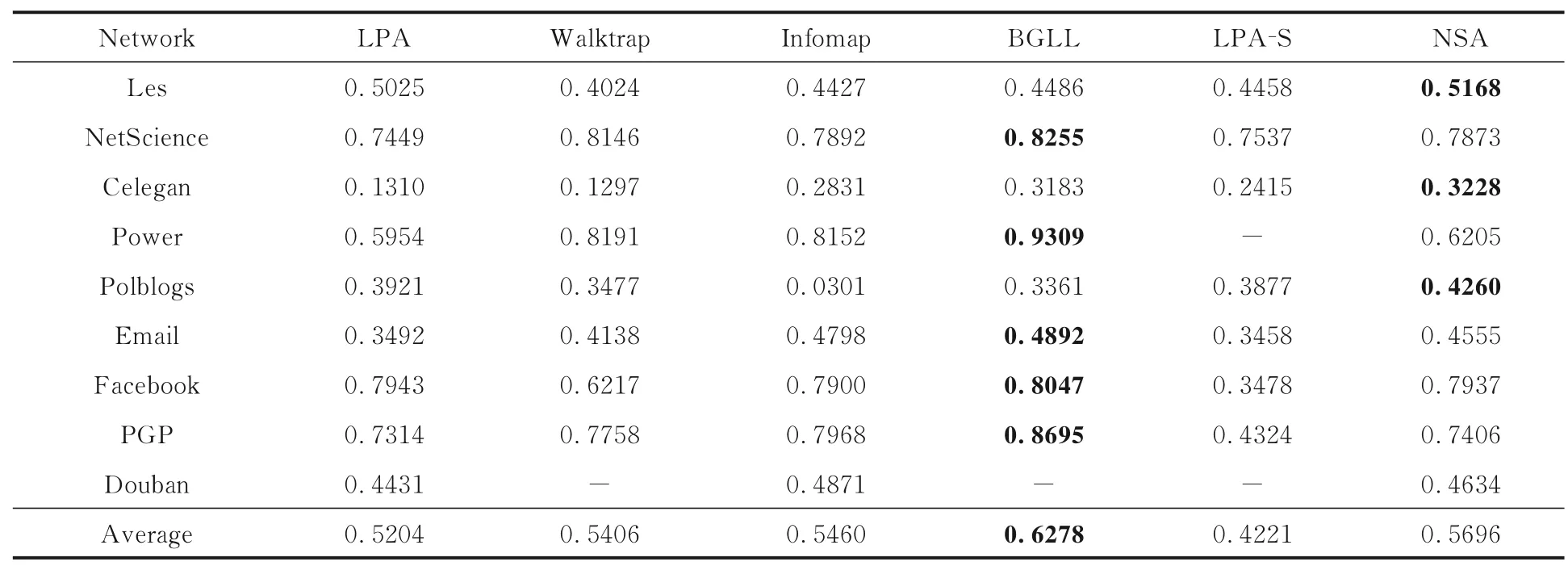
表4 本文算法和五个对比算法在无标签网络上的实验结果对比Table 4 Experimental results on unlabeled networks of our algorithm and other five algorithms

其中,σ2为总体方差,X为变量,μ为总体均值,N为样本总数.方差越低表明结果的稳定性越好.
表5 给出了NSA 算法与LPA 和LPA-S 算法在真实网络上的算法稳定性实验结果,表中黑体字是最好的结果.可以看出,本文算法NSA 在大多数网络中能得到更稳定的实验结果.

表5 本文算法与LPA 和LPA-S 算法的算法稳定性对比Table 5 The stability of our algorithm with LPA and LPA-S
5 结论
本文根据社区划分结果定义节点在该社区划分下的标签熵来衡量网络中节点在社区划分中的稳定性;以此为基础提出一种基于节点稳定性的社区发现算法NSA.首先运行t次快速社区发现算法得到原网络的t个社区划分,计算各节点对应社区划分的标签熵,从而确定网络的稳定节点集S.然后,在原网络上抽取包含稳定节点集S的连通子网络GS并在其上进行初始社区发现,得到初始类簇.最后,计算其他不稳定节点与初始类簇的距离,将尚无社区归属的节点根据相似性划分至与其最相似的类簇中,得到最终聚类结果.在四个带标签和八个无标签的网络数据集上,与五类经典社区发现算法的比较实验表明,本文的NSA 算法能够得到更稳定的社区划分结果,且在NMI和模块度等方面表现了良好的算法性能.
随着数据复杂性的增加,网络中节点间的关系呈现多样化,还需进一步研究在更复杂情况下网络中节点稳定性的变化,如何更有效地区分稳定节点和不稳定节点是一个值得关注的研究问题.重叠社区在大规模网络中普遍存在,在重叠社区背景下如何度量节点的稳定性也是未来的研究课题之一.
