基于行业背景差异下的金融时间序列预测方法
2021-01-30温玉莲林培光
温玉莲,林培光
(山东财经大学计算机科学与技术学院,济南,250014)
股票市场是国家经济发展的重要组成部分,预测股票价格走势对政府、投资者和投资机构有重要意义,吸引了很多学者进行研究.然而股票市场价格走势受政治、经济、法律、军事等多方面因素的影响,导致股票价格的不确定性和波动性很大,难以挖掘有效特征,这是研究的一大难题.
2006 年以来,“深度学习”[1]受到工业界和学术界的广泛关注,已成为人工智能发展的热门技术之一,在语音识别[2-3]、计算机视觉[4-5]等领域取得了巨大成功.从2013 年开始,在自然语言处理[6-7]领域也出现深度学习的应用浪潮.近年来,深度学习在时间序列研究领域[8-9]也取得了初步的成果,例如,Fischer and Krauss[8]使用LSTM(Long Short-Term Memory)深度学习方法进行指数时间序列预测研究,Lasheras et al[9]使用Elman RNN(Recurrent Neural Network)深度学习方法对大宗商品价格进行时间序列预测研究,均取得了较好的成果.股票时序数据研究是时间序列研究领域的重要模块,深度学习在其中的应用存在三个问题:第一,未来股票市场趋势预测受多方面因素的影响,如何有效选择、挖掘和提取影响股票预测的关键特征;第二,根据股票数据非线性和长期依赖关系的特点,如何有效地构建模型对未来股票市场趋势进行更准确的预测;第三,不同行业的股票对于模型的超参数的敏感度可能不同,如何根据不同行业的股票信息特征选择合适的超参数使模型的预测性能更好.
为解决上述三个问题,本文提出利用WBED混合模型对不同行业背景下的股票信息进行时间序列预测研究.首先,利用WB(Wrod2vec-Bi-LSTM)模型挖掘股民评论文本特征;其次,利用Encoder 模型有效提取股票时序数据特征;然后,利用Decoder 模型有效提取各时间维度上的信息并结合股票时序数据特征和情感指标进行股票预测;最后,由于不同行业的股票对模型超参数的敏感度不同,需为不同行业的股票选择合适的超参数使得模型的预测性能更好.本文选用四个模型评价指标,以三个行业的九家上市公司股票为对象进行独立测试,并与其他四种模型进行比较分析.实验结果表明,本文提出的模型有更好的预测性能.本文的主要贡献:
(1)提出一种新的WBED(Word2vec-Bi-LSTM and Encoder-Decoder)混合模型进行股票预测的方法.与现有方法不同,该方法同时利用结构化和非结构化数据,通过结合情感分析和双注意力机制来进行金融市场的趋势预测,可以提高预测的准确性.
(2)在股票时间序列预测研究领域,现有的研究方法主要针对单一行业股票对象,本文利用WBED 模型对多个不同行业的股票对象进行预测研究.
1 相关工作
金融时间序列研究是根据时间序列上的历史数据波动建立模型来描述金融数据结构并预测时间序列上的未来值.
传统的金融时间序列预测方法主要利用统计模型建立历史价格和未来价格之间的关系模型,寻找最佳估计值,包括线性回归模型和自回归模型等.例如,Devi et al[10]利用ARIMA(Autoregressive Integrated Moving Average)模型对中型股进行股票趋势预测的有效时间序列分析,使用训练好的ARIMA 模型进行测试来发现未来股价波动趋势和股票市场行为.然而,ARIMA 模型有一定的局限性,在时间序列分析研究中,它要求实验数据有一定的平稳性,对于一些股价波动剧烈的股票类型,ARIMA 模型不具有普适性;另外,ARIMA 模型主要采用分步预测的方法,每个时刻的预测值均由历史数据预测产生,所以其预测值存在一定的滞后性.
随着机器学习方法在时间序列数据建模方面的成功应用,传统的机器学习方法也应用到股票预测研究领域中.例如,Lin et al[11]提出一种基于支持向量机(Support Vector Machine,SVM)的股票市场趋势预测方法,利用SVM 模型进行特征选择和股票预测,在台湾股市数据集上的实验结果表明,基于SVM 的股票市场趋势预测系统能够为投资者提供有用的信息.然而,在后续的研究中发现,SVM 模型在股价剧烈波动时预测性能较差,并且在长时间的序列预测中有一定的局限性.
近年来,随着深度学习方法的广泛应用和发展,Rather et al[12]在RNN 算法的基础上进行股票收益预测,结果验证了RNN 算法在非线性数据上预测性能的准确性.RNN 算法在传统的神经网络基础上引入了时序的概念,是一种特殊的神经网络结构,即一个序列数据在当前时刻的输出和前一时刻的输出有关,网络会对前一时刻信息进行记忆并应用于当前的输出计算中.正是由于这种记忆使RNN 算法能对时间序列数据进行分析和建模,然而,在后续的研究中发现,RNN 算法存在一定的弊端,即容易出现梯度消失和长时间记忆能力不足等问题.
因此,Hochreater and Schmidhuber[13]在RNN模型的基础上进行改进,提出了LSTM(Long Short-Term Memory)模型,通过设计控制门结构(遗忘门、输入门和输出门)解决RNN 的问题,并在长距离时序信息的研究中表现出一定的优越性,符合金融时序数据连续性和长期依赖性等特点,所以许多研究人员使用LSTM 模型对金融时间序列数据进行预测研究.例如,2016 年Jia[14]利用LSTM 模型对股票波动趋势进行预测,2017 年Roondiwala et al[15]利用LSTM 模型对NIFTY 50的历史股票价格进行预测.实验结果表明LSTM模型在长时间时序信息预测中有一定的有效性,与其他机器学习方法相比,LSTM 模型的预测精度更高.
然而,影响股价波动的因素除了股票的技术指标和历史数据等结构化数据外,还包括一些非结构化的数据,如社交平台公众评论、金融交易网站上的股民评论信息和政府出台的政策等.例如,Bollen et al[16]利用情绪追踪工具分析推特平台的用户评论,如公众对总统大选和2008 年感恩节等事件的态度,探究用户情绪是否与经济指标预测相关.但是,仅根据用户情感来进行股票预测主观性较强,且选用社交平台公众评论数据的噪声较大,对未来股市预测有很大的不确定性.和社交平台公众评论相比,股民的评论可以更快速直观地反映股市波动,因此本文选用股吧中的股民评论数据进行情感分析,获取情感指标.
本文提出一种利用WBED 混合模型对不同行业背景下的股票对象进行时间序列预测的方法.参考“2019 中国上市公司500 强”,选取三个行业九家上市公司的股票对象作为实验数据,使用均方误差、均方根误差、平均绝对误差和平均绝对百分比误差作为模型评价指标,采用RNN,LSTM,Sen-LSTM 和Encoder-Decoder 模型作为对比模型.实验结果表明,WBED 模型的四种评价指标的数值小于四个对比模型,证明WBED 模型预测股票的真实值与预测值之间的误差更小,而且预测的拟合程度更好.
2 基于WBED 混合模型的金融时间序列预测方法
本文提出一种基于WBED 混合模型的股票趋势预测方法,混合模型的结构如图1 所示.

图1 WBED 混合模型结构图Fig.1 Structure diagram of WBED hybrid model
2.1 数据预处理本文使用的数据主要包括两部分:股票时序数据和股民评论文本数据,股票时序数据预处理:第一,本文获取的股票时序数据可能存在缺值和乱序,需要进行排序和插值等操作[17]来得到比较规范的股票时序数据;第二,本文采用的股票时序数据特征为收盘价(Close)、开盘价(Open)、最高价(High)、最低价(Low)和交易量(Volume),为了消除各特征自身数值大小的影响,使数据具有可比性,将股票历史价格特征进行数据标准化处理,如式(1)所示:

股民评论文本数据预处理:股民评论文本数据中可能包含标点、URL、特殊符号、特定术语缩写等信息,会对股评情感分类产生噪声干扰,需用自然语言处理(Natural Language Processing,NLP)的相关技术进行数据处理:首先用jieba 分词工具对股票评论文本数据进行分词处理,再使用停用词表进行停用词处理以消除噪声干扰,从而获得比较规整的股票评论文本数据.
2.2 股票评论文本特征挖掘使用Word2vec 模型和BiLSTM 模型对股票评论文本数据进行情感分析.首先将预处理之后的股票评论规范化文本使用Word2vec 来获取词向量表示,再将词向量特征使用BiLSTM 模型进行情感分类,最后计算情感值,获取情感特征.
2.2.1 词向量表示使用2013 年谷歌开源工具Word2vec 模型,基于CBOW(Continuous Bag-of-Words)方式对文本数据进行训练并获取词向量表示.词向量表示将文本中的词语映射到实数维向量空间,假设词向量空间为ψ,大小为 |ψ|×m,|ψ|表示词向量空间中词语的个数,m表示ψ中某个词语的词向量维数,股票评论文本数据中一条评论信息T可表示序列如下:

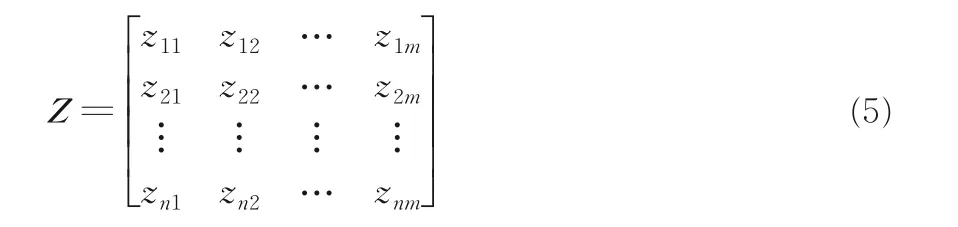
其中,ti表示T中第i个词语,n表示T中词语的个数.如果将T表示成词向量矩阵Z,应该先在词向量空间ψ中寻找词语ti的词向量表示,若存在,表示为Zi;若不存在,则将Zi置0.词向量矩阵Z的大小为n×m,Z中的每一行表示文本数据中一个词语对应的词向量,可表示为:

2.2.2 情感分类本文所构建的情感分类模块(图2)由输入层、词嵌入层、BiLSTM 层、全连接层和分类层组成,损失函数使用交叉熵损失函数,训练过程采用Adam 算法进行优化.
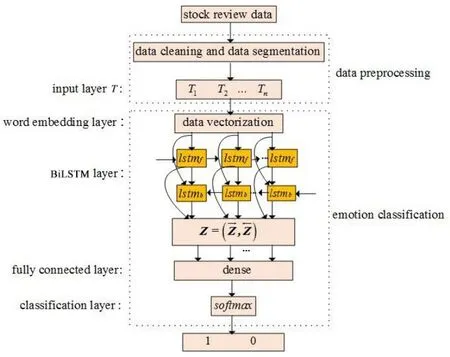
图2 情感分类模块Fig.2 A module for sentiment classification
2.2.2.1 输入层将股票评论文本的一条评论信息输入模块进行处理,假设有一条股票评论信息为“移动加油涨[]献花”,经过股票评论文本的数据预处理过程之后,输入的评论信息可表示为:

2.2.2.2 词嵌入层通过Word2vec 对股票评论文本进行训练得到上下文词向量列表,在上下文词向量列表中搜索输入评论信息的各个词语对应的词向量,构成词向量矩阵.输入评论信息T的词向量矩阵表示形式如下:
其中,m表示词向量的维度,n表示评论信息中单词的个数.
2.2.2.3 BiLSTM 层BiLSTM 由前向LSTM 和反向LSTM 组成,与LSTM 相比,BiLSTM 可以更好地捕捉文本的上下文信息.股票评论信息在BiLSTM 层某一时刻t的操作如下:


Zt为BiLSTM 的输出向量.
2.2.2.4 全连接层上述过程为BiLSTM 提取评论信息特征的过程,而提取的特征信息在全连接层生成用于情感分类的特征值.
2.2.2.5 分类层使用softmax函数输出情感类别,积极情感为1,消极情感为0.
2.2.3 计算情感值假设第t天有多条股票评论信息,则第t天的情感特征值为:
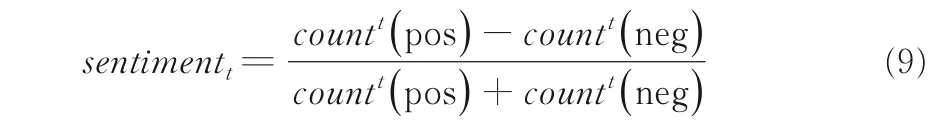
其中,sentimentt表示第t天的情感值;countt(pos)表示第t天积极评论信息的个数;countt(neg)表示第t天消极评论信息的个数.
2.3 股票时间序列预测在编码器的网络结构中将股票时序数据作为编码器的输入,使用特征注意力机制给不同的特征赋予权重,自适应地提取有效时序数据特征,区别不同特征对股票预测的重要程度.在解码器的网络结构中,对编码器中LSTM 的隐状态采用时间注意力机制,给各时间维度的信息赋予不同的权重,区别不同时间维度信息对于股票预测的重要程度.最后将股票时序数据特征和情感特征拼接,输入LSTM 进行预测.
股票时间序列预测模块由编码器和解码器构成,损失函数使用均方误差损失函数,训练过程采用Adam 算法进行优化,该模块将滑动窗口大小、批处理大小、训练次数和隐藏层单元个数等设置为模块超参数,股票预测模块如图3 所示.
2.3.1 编码器编码网络中使用股票时序数据X=(X1,X2,…,XT)作为输入,其中Xt∈Rn,n表示用于股票预测的特征数,通过特征注意力模块获取股票时序数据中的重要信息.

其中,st-1表示t-1 时刻编码器的隐状态,ve,We表示权值,be表示偏置项,表示第k个输入特征在t时刻的注意力权重,股票时序数据更新为:

图3 股票预测模块Fig.3 A module for stock prediction
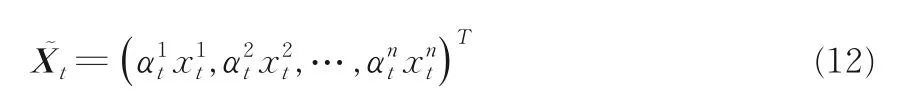
表示经过特征注意力模块处理后的股票时序数据,经过LSTM 网络结构从序列映射到向量ht:

其中,f1表示LSTM 单元的非线性激活函数,用来获取时序数据长时间的信息,LSTM 单元内部单元结构和信息更新过程如图4 所示.

图4 LSTM 单元结构Fig.4 The cell structure of LSTM

使用特征注意力机制,编码器可以自适应地关注某些重要特征,区别不同特征对于股票预测的重要程度,提升模型预测性能.
2.3.2 解码器在解码器的网络结构中,对编码器中LSTM 的隐状态引入时间注意力机制,给各时间维度的信息赋予不同的权重,通过时间注意力模块获取不同时间维度上的重要信息.计算过程如下:
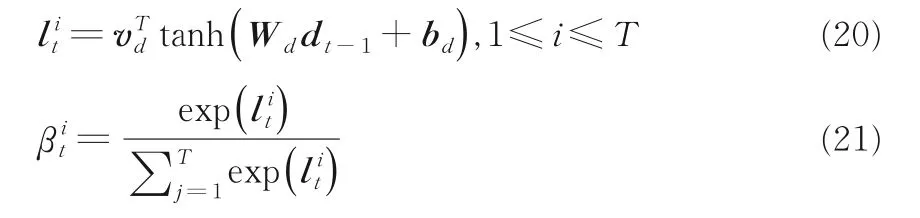
其中,dt-1表示t-1 时刻解码器的隐状态,vd,Wd表示权值,bd表示偏置项,T表示滑动窗口大小time_step,时间注意力权重表示编码器第i个时间维度的重要程度.编码器的隐状态更新为:

γt表示经过时间注意力模块处理后的隐状态.最后将股票时序数据特征和情感特征进行拼接,输入LSTM 模型,经过LSTM 网络结构输出预测值:

其中,f2表示LSTM 单元的非线性激活函数,yt-1表示LSTM 单元的输入表示预测值.使用时间注意力机制,解码器可以自适应地关注某些重要时间维度上的信息以区别不同时间维度上的信息对于股票预测的重要程度,提升模型的预测性能.
3 实验与结果
利用上一节的WBED 混合模型对不同行业背景下的金融样本进行实验分析,参考“2019 中国上市公司500 强”,选取三个行业九家上市公司股票为实验对象,分别是金融行业的工商银行(601398,ICBC)、建设银行(601939,CCB)和农业银行(601288,ABC);通讯服务行业的中国移动(chl.us,CHL)、中国联通(chu.us,CHU)和中国电信(cha.us,CHA);日常消费品行业的伊利股份(600887,Yili)、青岛啤酒(600600,Qingdao Beer)和双汇发展(000895,Shuanghui Development).
3.1 数据集采用的数据集包括股票交易信息和股民评论信息.股票交易信息的来源为锐思金融数据平台和英为财情网站,选取影响股票价格波动的五个重要的技术指标:开盘价(Open)、最高价(High)、最低价(Low)、收盘价(Close)和交易量(Volume).股民评论信息的来源为东方财富网,并按2.2 节所述进行股票评论文本特征挖掘,提取情感指标.选用的股票交易日期和股民评论日期从2014 年06 月06 日到2019 年12 月06 日,并按2.1 节所述进行数据预处理,将数据集分为80%的训练集和20%的测试集.训练集用于训练模型和调整模型超参数,测试集用于对模型性能进行测试.股票数据集统计如表1 所示.

表1 股票数据集统计Table 1 The statistics of stock datasets
3.2 模型评价指标选用均方误差(Mean Square Error,MSE)、均方根误差(Root Mean Square Error,RMSE)、平均绝对误差(Mean Absolute Error,MAE)和平均绝对百分比误差(Mean Absolute Percentage Error,MAPE)作为模型预测评价指标,如下所示:

3.3 模型参数设置不同行业股票对模型超参数的敏感度不同.为探究不同行业背景下的金融时间序列预测结果,以超参数滑动窗口大小time_step 和批处理大小batch_size 为例进行实验分析.图5 和图6 分别表示金融行业的批处理大小batch_size 和滑动窗口大小time_step 的超参数设置结果,横坐标表示超参数大小,纵坐标表示RMSE的值.可以看出,金融行业股票的模型超参数batch_szie 设置为64,time_step 设置为8 时,RMSE值最小,对金融行业股票的预测性能最优.
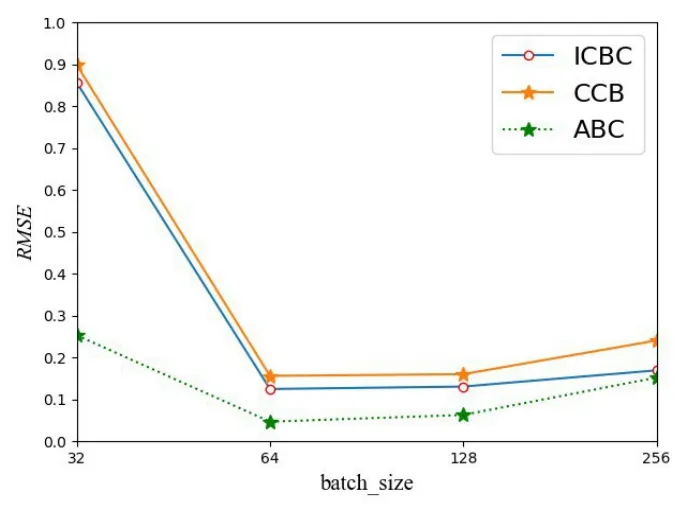
图5 金融行业的批处理大小Fig.5 The batch_size of financial industry

图6 金融行业的滑动窗口大小Fig.6 The time_step of financial industry
图7和图8是通讯服务行业的超参数设置结果,可以看出通讯服务行业股票的模型超参数batch_size设置为128,time_step设置为8时,RMSE值最小,对通讯服务行业股票的预测效果最好.
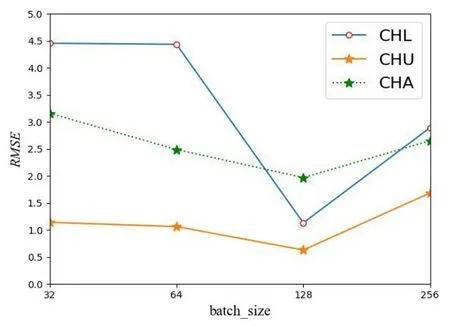
图7 通讯服务行业的批处理大小Fig.7 The batch_size of communications services

图8 通讯服务行业的滑动窗口大小Fig.8 The time_step of communications services

图9 日常消费品行业的批处理大小Fig.9 The batch_size of consumer goods industry
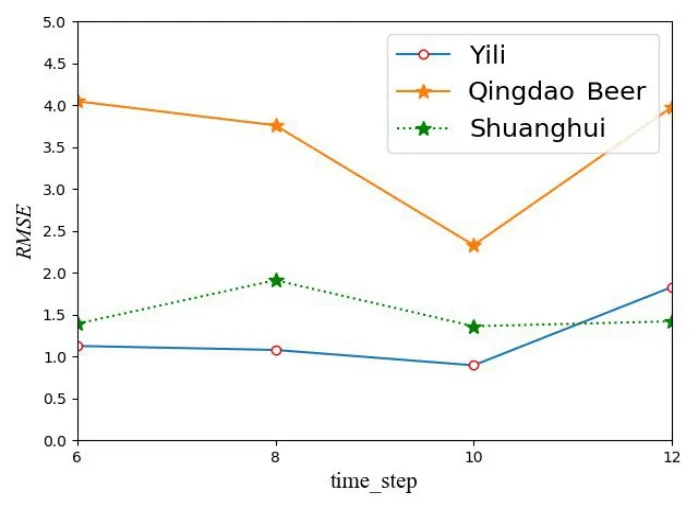
图10 日常消费品行业的滑动窗口大小Fig.10 The time_step of consumer goods industry
图9 和图10 表示日常消费品行业的超参数设置结果,可以看出日常消费品行业股票的模型超参数batch_size 设置为128,time_step 设置为10时,预测误差最小.
从实验结果发现,模型超参数对于不同行业股票预测的敏感度不同,根据行业差异选择合适的超参数能够提高模型的预测性能.
3.4 实验分析使用三个行业九家上市公司的股票数据,根据2.1 节所述的方法进行数据预处理并使用RNN[12],LSTM[18],Sen-LSTM,Encoder-Decoder[19]方法进行对比实验,各个模型在不同数据集上的评价指标如表2 至表4 所示.
以金融行业的工商银行、通讯服务行业的中国移动和日常消费品行业的双汇发展为例进行实验结果预测图展示,图11、图12 和图13 分别表示中国移动、工商银行和双汇发展在不同模型上的预测结果图.
3.4.1 可行性分析以金融行业中的工商银行、建设银行和农业银行各模型评价指标结果为例,从表2 可以看出,WBED 模型的MAE,MAPE,MSE和RMSE值均比对比模型小,说明WBED混合模型的预测性能更好.
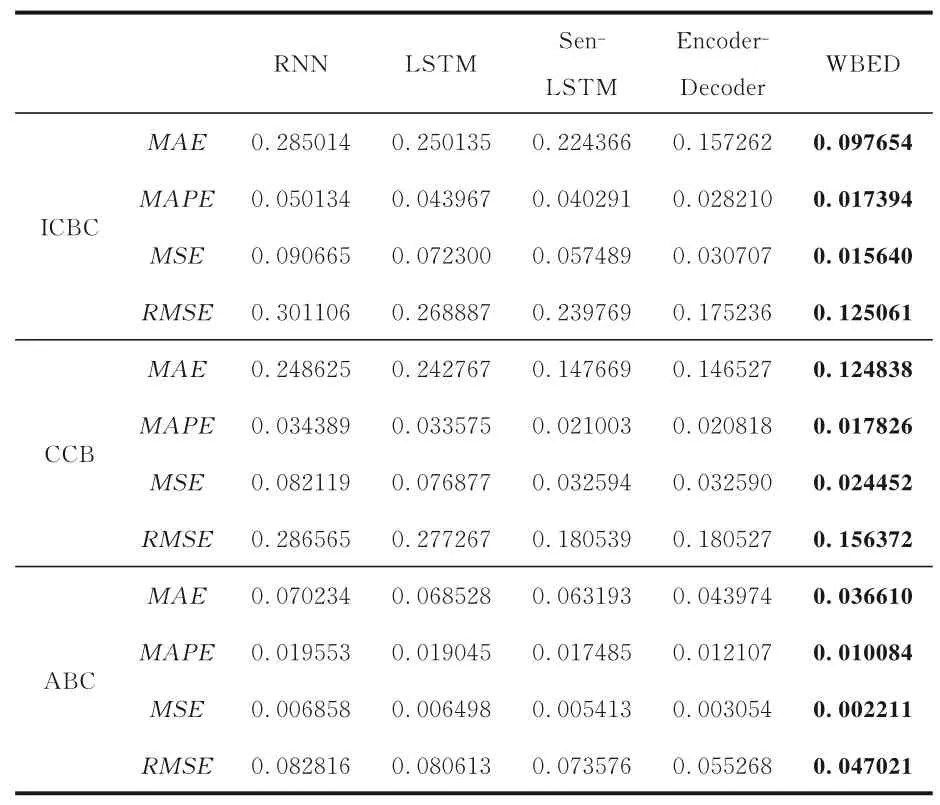
表2 各模型在金融行业的实验结果对比Table 2 Experimental results of models in the financial industry
其中,LSTM 和Encoder-Decoder 模型的性能均优于RNN 模型,说明LSTM 模型更符合金融时序数据的特点,克服了RNN 模型梯度消失和长期记忆能力不足的问题,对长期的金融时序数据的预测效果更好;在特征提取方面,Encoder-Decoder 模型优于LSTM 模型,证明注意力机制在特征提取方面的有效性.
另外,Sen-LSTM 和WBED 模型比LSTM 模型的预测效果更好.Sen-LSTM 模型在LSTM 模型的基础上添加了文本特征挖掘,提取情感指标,将股票时序数据特征和情感特征进行拼接,输入LSTM 模型进行预测,证明由于文本分析的加入,即加入情感特征有助于提升模型预测性能,股民的评论信息对未来股票市场行情有重要影响.
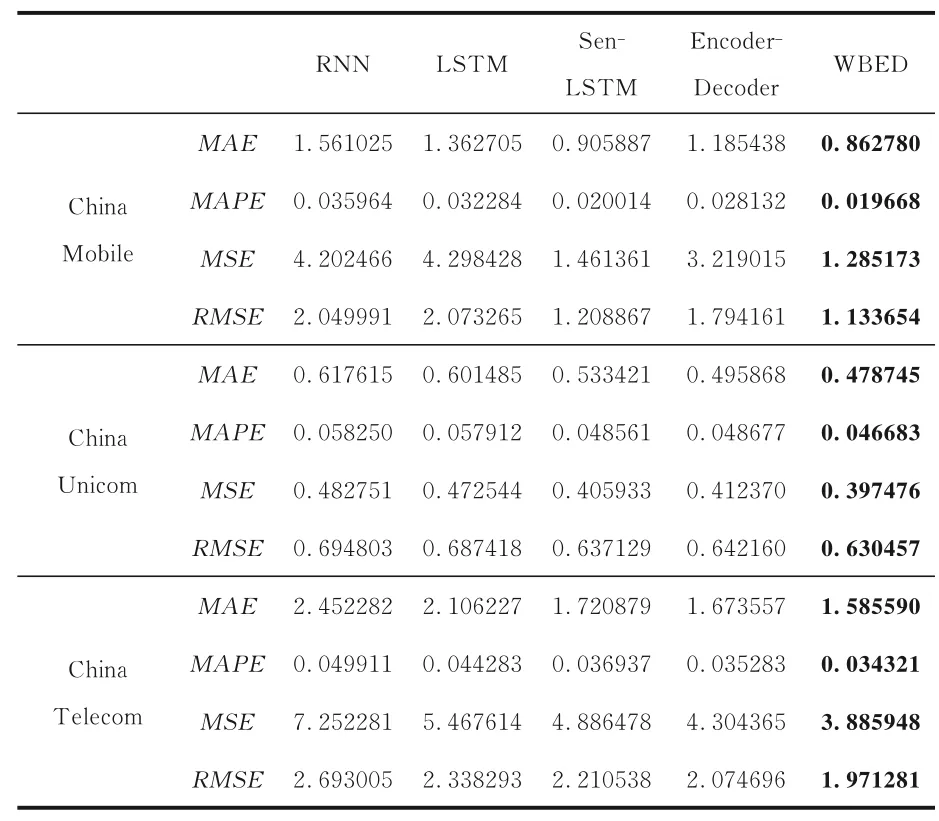
表3 各模型在通讯服务行业的实验结果对比Table 3 Experimental results of models in the communications industry

表4 各模型在日常消费品行业的实验结果对比Table 4 Experimental results of models in the consumer goods industry
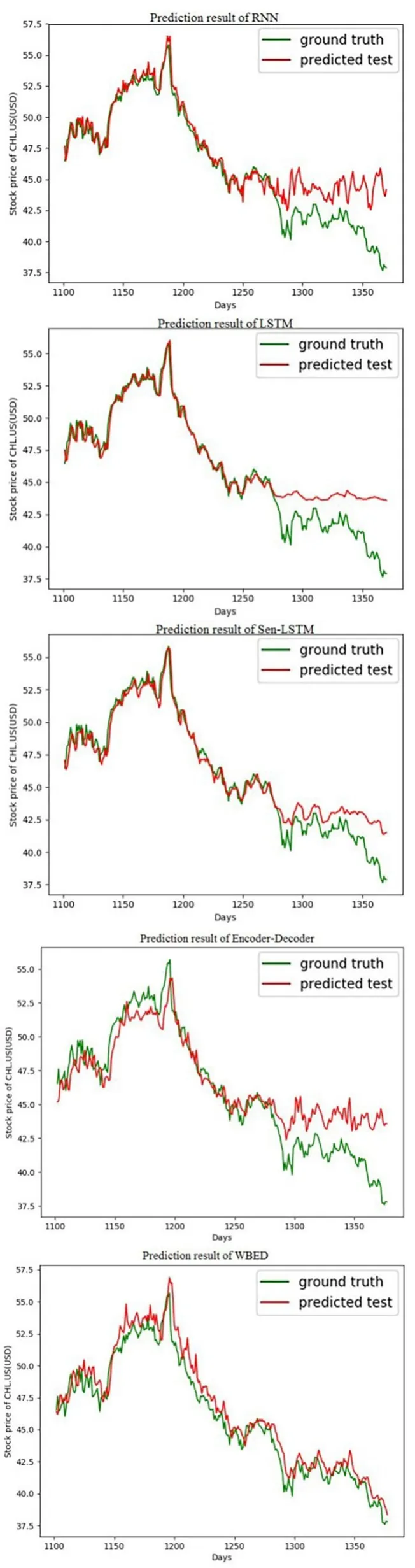
图11 中国移动各模型预测结果Fig.11 Prediction results of various models of China Mobile

图12 工商银行各模型预测结果Fig.12 Prediction results of various models of ICBC

图13 双汇发展各模型预测结果Fig.13 Prediction results of various models of Shuanghui development
3.4.2 稳定性分析从评价指标结果和预测图可以看出,在不同行业中,WBED 模型的预测效果均优于其他对比模型,说明WBED 模型在不同行业数据集上具有一定的稳定性.
4 结论
本文提出基于WBED 混合模型在行业背景差异下的股票时间序列预测研究方法,选取三个行业九家上市公司的股票数据,以MSE,RMSE,MAE和MAPE为评价指标,和RNN,LSTM,Sen-LSTM 和Encoder-Decoder 模型进行对比.实验结果表明,WBED 模型的预测性能更好,并且对于不同行业的股票具有普遍使用性,适用于金融领域的时间序列预测.之后的工作将尝试挖掘更多提高金融预测的有效特征,探究不同行业的金融特征信息,并尝试更大规模、更多类型的金融数据,进一步优化模型和参数,提高模型性能.
