基于CARS变量选择方法的小麦硬度测定研究
2021-01-29姜明伟王彩红张庆辉
姜明伟,王彩红,张庆辉
河南工业大学 信息科学与工程学院,河南 郑州 450001
小麦硬度的常用测定方法有颗粒度指数法(PSI)、单籽粒谷物特性测定仪法(SKCS)、近红外光谱法(NIR)等。田素梅[1]对利用小麦硬度测定仪和NIR法测定小麦硬度的两种方法进行比较,发现两者具有极显著的正相关。陈锋等[2]利用NIR法对583种小麦样品进行硬度测定,利用一阶导数处理的光谱建立的最小二乘法模型效果最好,模型对硬、软、混合麦的分级准确率分别为90%、83%、63%。化学测定方法和近红外光谱法都有较好的相关性,但建模的预测集标准误差较大,不适用于直接检测。袁翠平等[3]采用SKCS法和NIR法对54个小麦品种的籽粒硬度进行测定,两种方法相关系数R为0.87。惠广艳等[4]基于可见近红外光谱的SPA-RBF神经网络模型能够准确地预测小麦的硬度,具有快速、方便、无损等优点。
利用偏最小二乘法查找自变量小麦硬度光谱矩阵X和因变量小麦实际硬度矩阵Y的线性关系。作者采用小麦指数硬度仪测定小麦硬度实际值,利用近红外分析仪对小麦硬度光谱数据进行采集,再用一阶导数进行预处理,在不降低预测性的基础上提取有效光谱数据,建立小麦样品硬度的PLS预测模型,旨在为快速检测小麦硬度提供理论方法。
1 原料与仪器
1.1 原料
65种豫麦:河南郑州中原国家粮食储备库。
1.2 仪器
JYDB 100×40型小麦指数硬度仪:郑州中谷机械设备有限公司;DA 7250近红外分析仪:瑞典波通公司。
2 数据采集
2.1 小麦近红外光谱数据采集
将65种豫麦置于水分含量为12%的干燥环境中,以供光谱数据的采集[5-7]。采用近红外分析仪采集小麦光谱数据,分析仪采用铟镓砷光电二极管阵列技术,固定全息光栅分光,进行连续光栅光谱检测,光源为卤钨灯,光谱波段为950~1 650 nm,采用固定式杯装小麦样本进行光谱测量。使用的光谱采集软件为Results Plus,光谱分辨率为0.5 nm。仪器开机预热0.5 h,稳定红外光源,以保证小麦光谱数据更准确。光谱数据处理软件为Matlab R2016a、The Unscrambler X10.4。小麦硬度光谱数据采集结果如图1所示。
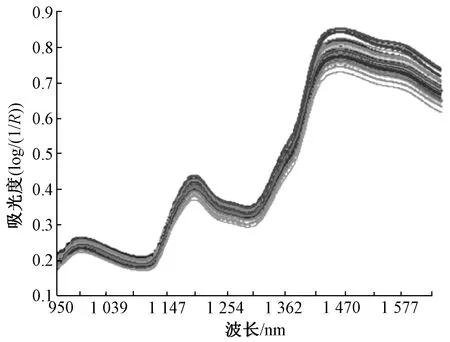
注:R为反射率。图1 小麦硬度光谱数据采集结果Fig.1 Spectral data acquisition
2.2 小麦实际硬度数据采集
为建立小麦近红外光谱数据和小麦实际硬度值之间的预测分析模型,对小麦实际硬度值进行测定。小麦实际硬度值按照GB/T 21304方法,利用小麦硬度指数仪测量。最终测得65种豫麦硬度指数(HI)结果如表1所示。
3 数据预处理
测定小麦实际硬度会产生误差,采用蒙特卡洛交叉验证法[8]对误差硬度值进行剔除。为保证预测模型具有代表性和外推能力,采用光谱理化值共生距离(set partitioning based on joint X-Y distances,SPXY)[9]做进一步优选,划分模型的校正集和预测集,最大限度的降低样本的共线性。为削弱各种目标因素对目标光谱的影响,保留有效信息,提高光谱分辨率和模型的稳健性,降低模型的复杂度,对校正集样本进行一阶导数预处理[10-11],在此基础上建立偏最小二乘法的小麦硬度预测模型(CARS-PLS模型)。
3.1 蒙特卡洛交叉验证法剔除异常小麦实际硬度值
小麦硬度值在化学测定时会不可避免地产生误差,所得的硬度值会影响模型的预测精度,导致模型误差大,因此采用蒙特卡洛交叉验证法剔除异常的硬度值。蒙特卡洛交叉验证法共建立1 000个PLS模型,每个模型随机选取52种小麦作为校正集样本,建立校正集小麦光谱数据和实际硬度值的偏最小二乘法模型[12-13],对剩下的13种预测集小麦样本进行硬度值预测,得到小麦硬度的预测残差标准差(STD)与均值(MEAN),结果如图 2所示。

表1 65种豫麦样本实际硬度值Table 1 Actual hardness values of wheat samples

图2 蒙特卡洛交叉验证法剔除结果Fig.2 Elimination results of Monte Carlo cross-validation method
最终剔除STD>0.4,MEAN>1的异常数据,由图2可知,小麦编号13、22、47、49、55、56、58共7个为异常值,对剩下的58个小麦样本进行建模分析。
3.2 样品集合划分
建模需要将样本划分为校正集和预测集,校正集用来建立模型,预测集用来检验建立的模型。常见的样本集合划分方法有随机抽样法、常规选择法、Kennard-Stone(K-S)法等,为保证预测模型的代表性和外推能力,采用光谱理化值共生距离(SPXY)划分模型的校正集和预测集,最大限度的降低样本的共线性。
式中:p和q表示任意两个样品的编号;N是总的样品数;j为光谱波点;dx(p,q)表示两条光谱数据的空间距离;dy(p,q)表示对应小麦样品p,q实际硬度之间的距离。
SPXY法选择样本时,确保了x空间和y空间的样本分布,计算两种样本的联合空间距离dxy。
采用SPXY法将剔除异常小麦硬度值后的58个样本分为校正集和预测集,其中校正集46个,预测集12个。样本统计结果如表2所示。从表2可看出,校正集样本的硬度最大值为68.5%,最小值与整体样本相同,为57.2%,平均值(65.2%)小于整体样本,标准差(2.07)大于整体样本,说明校正集分布均匀,具有足够的代表性。校正集样本硬度值范围在57.2%~68.5%之间,涵盖了预测集样本最大值和最小值,符合建模标准。
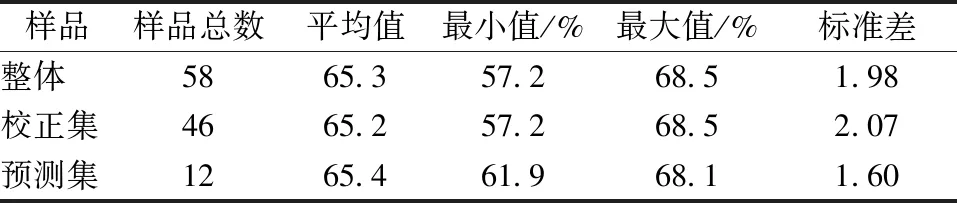
表2 小麦SPXY集合划分结果Table 2 Wheat SPXY set division results
3.3 CARS变量优选
CARS算法[14-15]是以达尔文进化论的“适者生存”为指导理论的变量方法。通过蒙特卡洛采样法筛选PLS模型中回归系数绝对值大的变量,应用衰减指数法剔除回归系数绝对值小的波长,基于自适应加权算法 (adaptive reweighted sampling, ARS)选取交叉验证的均方根误差 (root mean square error of cross validation, RMSECV) 最小的模型所对应的波长变量子集。本研究中蒙特卡洛采样次数设置为50次。
4 模型建立及预测结果
4.1 模型评价参数
建立近红外光谱模型后对预测集样本进行预测,最终通过得到的参数来评价模型。本研究选取3个模型评价参数:预测相关系数(R)、交叉验证均方根误差(RMSECV)、预测均方根误差(RMSEP)。R反映模型实际值与预测值之间的拟合程度,R越接近1,表明预测值和实际值的拟合度正相关,模型的准确度越高。RMSECV用来验证模型的可行性,计算预测模型的误差,RMSECV越小,表明所建模型的预测能力越强。RMSEP表示预测集样本经模型预测所得的预测值与实际值之间的误差,RMSEP越小,表明模型预测效果越佳。


4.2 CARS-PLS模型建立及结果
采用CARS方法对校正集全光谱进行变量筛选,最终筛选出110个特征波点,占原波点数(1 401)的7.85%,随着采样次数增加,变量数、RMSECV和每个变量回归系数路径如图3所示。

注:*表示RMSECV最小时的采样次数。图3 CARS变量选择Fig.3 CARS variable selection
由图3a可知,随着采样次数的增加,采样次数小于20时,采样变量数快速递减,采样次数大于20时,采样变量数慢速递减,说明算法在筛选变量有精选和粗选过程。
图 3b是十折交叉验证RMSECV变化趋势,随着采样次数的增加,PLS交叉验证RMSECV值先递减又递增的变化,其中采样次数在20时达到最小值,为0.158 5。表明在1~19次,近红外光谱中与小麦硬度值大量的无关信息被剔除,31次后,RMSECV明显递增,表明剔除了光谱中有效数据导致模型性能变差。
图 3c表示1 401个变量随着采样次数的增加回归系数的路径变化,采样次数为20所得的变量子集定为与小麦硬度相关的关键变量子集,包含110个变量。
利用CARS方法筛选出的特征变量作为PLS模型的输入变量,采用留一交叉法确定最优因子数,采用最优因子数建立CARS-PLS预测模型,并对预测集进行性能比较。由表2可知, CARS-PLS模型中预测集R和RMSEP分别为0.884 3、0.543 6,Full-PLS全变量模型预测集R和RMSEP分别为0.863 1、0.574 9,两个模型都可以较好地对小麦硬度进行预测,前者模型对小麦硬度的预测能力略低于后者,但是CARS-PLS模型仅仅使用了全变量的7.85%的变量,这有助于建模的简单、稳定,在不降低预测性的基础上很大幅度降低了计算量。综上,CARS-PLS能够有效测定小麦硬度,CARS对波长选择能力很强,能够有效剔除无关变量。

表3 偏最小二乘法回归模型性能Table 3 Performance of partial least squares regression model
5 结论
小麦硬度近红外光谱经过CARS进行特征变量选择,最终在1 401个特征变量中选取了110个进行分析比较。结果表明,通过CARS进行变量选择建立的PLS模型性能略低于全光谱建立的PLS模型性能,但是CARS-PLS模型仅仅使用了全变量的7.85%的变量,这有助于建模的简单、稳定,在不降低预测性的基础上很大幅度降低了计算量。CARS-PLS模型的校正集R和RMSEP分别为0.931 7和0.570 8,预测集R和RMSEP分别为0.884 3和0.543 6,该模型对快速无损检测小麦硬度具有使用推广价值。
