一个最小生成树为最短路树的判定算法
2021-01-28沈玥名赵承业
沈玥名,赵承业
(1.中国计量大学 经济与管理学院,浙江 杭州 310018;2.中国计量大学 理学院,浙江 杭州 310018)
对最小生成树的研究一直是图论中的经典内容,它不仅涉及一系列丰富的理论问题,最小生成树模型还可以模拟建筑业、交通业和通讯产业的很多建设成本问题[1]。在构造最小生成树算法中,在1956、1957年Prim算法[2]与Kruskal算法[3]分别被提出,这两种算法都是在多项式时间内运行的贪婪算法。贺军忠等[4]研究了这两种算法在执行过程、时间复杂度和实现方法等方面的不同点。随后江波等[5]研究了Prim算法的改进算法,使其能动态调整自身的性能,适合于稠密图与稀疏图。除了单纯的算法的研究,算法的具体应用例如张宁宁[6]基于Kruscal算法最小树原理改进AP(Affinity Propagation)聚类算法完成生产性服务需求的聚类。
在网络中寻找最小生成树是否为最短路树的判定算法,主要为了解决最小生成树成本分摊问题。在此问题中,我们关心最小生成树得到的最小权重和如何在各个结点间进行公平的分配问题[1]。该问题最早由Kleitman[7]于1973年提出。我们考虑下面的一个小例子[8],见图1:有三个小区(三个代理)用1,2,3来表示。这些小区都需要用管道连接到自来水厂(源点0),代理们目标就是自身支付的管道成本最小。经过计算后,最小生成树的总成本为α+β+γ,具体最小生成树T如图1,N={1,2,3},c01=α,c12=β,c23=γ。非常自然地想到1,2,3分配成本可以是φ1=α/3、φ2=α/3+β/2以及φ3=α/3+β/2+γ/3。我们把这种自然的分配方案称为路径边分摊。当最小生成树中存在c03<α/3+β/2+γ/3时,代理3将选择直接连接到源头,路径边分摊就不是一个公平的分配规则。
如果对一个给定的网络,存在网络的最小生成树是从源点出发的该网络的最短路树,就可以采用上面的分摊方案来进行成本分摊。因此,本文重点研究判定一个网络是否存在这样的最小生成树的算法。
1 准备工作
工作本文涉及的,本文涉及的,未经说明的概念或专业术语,图和网络领域的详见文献[9],算法领域的详见文献[10]。给定一个带权重的有向网络G=(V,E)和权重函数ω:E→R,该权重函数将每一条边赋予一个实数值作为这条边的权重。网络中一条路径p=
定义从结点u到结点v的最短路径权重δ(u,v)如下:
从结点u到结点v的最短路径则定义为任何一条权重为ω(p)=δ(u,v)的从u到v的路径p。单源最短路问题:给定一个网络G=(V,E),我们希望找到给定的源结点sV到每个结点vV的最短路径。求解单源最短路的算法有Dijkstra算法、Bellman-Ford算法[10]。文献[10]中也证明了Dijkstra算法的结果是一个以源结点为根结点的有根树,称为最短路树。与上面类似,给定一个带权重的有向网络G=(V,E)和权重函数ω:E→R,我们希望找到网络G的一棵生成树,它的权重的值最小,这样的树称为是网络G的最小生成树。从最短路树的定义,我们知道最短路树也是网络的一个生成树,但不能保证一定是该网络的最小生成树。图2的例子说明了这一情况。

图2 同一连通图的单源最短路生成树与最小生成树Figure 2 Shortest path spanning tree and minimum cost spanning tree of the same connected graph
2 判定算法及分析
2.1 Dijkstra算法与Prim算法
我们首先给出判定算法的两个基础算法:Dijkstra算法和Prim算法。因为文献[11]中给出的算法描述比较容易理解,我们下面采用文献[11]中算法描述如下:
算法Dijkstra(G,s)
//单源最短路的Dijkstra算法
//输入:网络G=(V,E)和它的顶点s,其中E中边的权重非负
//输出:对于V中任意顶点v,从s到v的最短路径长度dv,
//以及路径上倒数第二个顶点pv
1.Initialize(Q) //将顶点优先队列初始化为空
2.forV中每一个顶点vdo
3.dv←∞;pv←null
4.Insert(Q,v,dv) //初始化优先队列中顶点的优先级
5.ds←0;Decrease(Q,s,ds) //将s的优先级更新为ds
6.VT←Φ
7.fori←0to|V|-1do
8.u*←DeleteMin(Q) //删除优先级最小的元素
9.VT←VT∪{u*}
10.forV-VT中每一个和u*相邻的顶点udo
11.ifdu*+w(u*,u) 12.du←du*+w(u*,u);pu←u* 13.Decrease(Q,u,du) 引理2.1[11]如果网络由权重矩阵表示,优先队列用无序数组表示,则Dijkstra算法的复杂度为O(|V|2);若用邻接表表示,优先队列用最小堆实现,该算法复杂度为O(|E|log|V|)。 算法Prim(G) //构造最小生成树的Prim算法 //输入:网络G=(V,E) //输出:ET,组成G的最小生E成树的边集 1.VT←{v0} 2.ET←Φ 3.fori←1to|V|-1do 4.在所有的边(v,u)中,求权重最小的边e*=(v*,u*),其中v在VT中,u在V-VT中 5.VT←VT∪{u*} 6.ET←ET∪{e*} 7.returnET 引理2.2[11]如果网络由权重矩阵表示,优先队列用无序数组表示,则Prim算法的复杂度为O(|V|2);若用邻接表表示,优先队列用最小堆实现,该算法复杂度为O(|E|log|V|)。 在Dijkstra算法和Prim算法的基础上,将判定算法分为两个阶段: 第一阶段,利用Dijkstra算法计算源点0到任意节点i的最短路权重,记为di,1≤i≤n; 第二阶段,对构造最小生成树的Prim算法进行修改,在每次增加权重最小边时,考虑新增顶点u*在ET中从u*到源点0的路径权重和恰好为从源节点0到u*的最短路权重du*,如果存在这样的最短路则继续构造,直到得到一个最小生成树恰好就是单源最短路生成树;如果无论怎么构造都不存在这样的最短路,则说明不存在这样的最小生成树。将这个修正算法称为广义的Prim算法简称为GPrim算法,它用来判定是否存在一个最小生成树是单源最短路生成树,具体算法如下: 算法GPrim(G,n) //构造最小生成树的同时判定是否为单源最短路生成树的广义Prim算法 //输入:网络G=(V,E),n为网络结点数目 //输出:True,如果存在最小生成树为单源最短路生成树;否则,False 1.VT,ET,S←Φ//VT,ET,S为空栈 2.VT,.push(0) //源点0入顶点栈 3.S.push(NULL) 4.whileVT.length() 5.E*←Φ//E*为空栈 6.将所有权重最小的边e*=(v*,u*),其中v在VT中,u在V-VT中入栈E* 7.whileS≠Φdo 8.flag ←0 9.whileE*≠Φdo 10.e*←E*.pop() 11.ifET中u*到源点0的路径权值和≡du*do 12.VT.push(u*) 13.ET.push(e*) 14.S.push(E*) 15.flag ←1 16.break 17.ifflag=0do 18.ifS.peek()!=NULLdo 19.E*←S.pop() 20.else return False 21.whileE*=ΦandS.peek()!=NULLdo 22.VT.pop() 23.ET.pop() 24.E*←S.pop() 25.ifS.peek()=NULLreturnFalse //S栈顶元素为NULL 26.else 27.break 28.returnTrue 定理2.1对于给定的网络,若判定算法给出True,则存在一个最小生成树是以源点为根的单源最短路生成树;若判定算法给出False,则不存在这样的最小生成树。 证明GPrim算法在Prim算法基础上,增加了判断新增的顶点,通过边集ET到源点的权重是否恰好为它到源点的最短路权重。令Q=P∪{0}。若返回值为True,集合P每次增加一个顶点,集合Q的导出子图T增加一个顶点和一条边,增加到N-1个顶点为止,此时得到的集合Q的导出子图T正好是网络的一棵生成树。这棵生成树恰好是该网络的一个最小生成树,因为根据Prim算法,从源点0开始,每次增加一条和Q中顶点相邻且权重最小的顶点,因此我们得到了一棵网络的最小生成树。可知添加进集合P中的新顶点top到源点0的最短路径包含在导出子图T中,因此T也是网络的一个单源最短路生成树。即该网络存在一个最小生成树,它正好也是单源最短路生成树。 若返回值为False,考虑算法找到所有与P中结点相邻的结点,构成集合T;令d=min{ω(u,v):u∈P,v∈T},把所有到P中结点权重为d的T中结点按序号从大到小构建E*;显然,我们考虑了所有可能的最小生成树构造方法,如果不能找到满足条件的新增顶点,就说明对任意的最小生成树,都不可能是单源最短路生成树。 定理2.2判定算法的算法复杂度为O(|V|3)或O(|V|4)。 证明由引理2.1与2.2,我们知道最坏情形下,Dijkstra算法和Prim算法的复杂度都是O(|V|2)。因此判断算法的复杂度主要由广义Prim算法确定。 求所有权重最小的边集,最大次数为i*(|V|-i),其中i是当前已选结点集合VT的元素个数。显然,循环whileE*≠Φ最大次数不超过网络边数|E|;循环whileS≠Φ最大次数不超过栈S的元素个数,而|S|≤i;循环whileVT.length() (|V|-1)(3|E|+|V|+1)。 当|E|=O(|V|)时,判定算法的时间复杂度是O(|V|3);当|E|=O(|V|2)时,判定算法的时间复杂度是O(|V|4)。 利用Python语言和Networkx包实现了算法,基于真实社会网络大多数是符合小世界网络特征[12]。本文选择利用Networkx包connected_watts_strogatz_graph(n,k,p)来生成测试网络。其中n为网络节点数,k为节点邻居数,p为随机边比例,i代表网络任一节点。 图3是一个随机生成的n=20,k=3,p=0.3的小世界网络,图4显示它的满足最短路条件的最小生成树。表1给出网络WS1的所有节点到源点0的最短路权重值。 表1 网络WS1的所有节点到源点0的最短路权重值 图3 随机生成的小世界网络WS1(n=20,k=3,p=0.3)Figure 3 Randomly generated small-world network WS1(n=20,k=3,p=0.3) 图4 网络WS1的最小生成树(单源最短路生成树)Figure 4 Minimum spanning tree of WS1 network (Shortest path spanning tree) 使用Python语言随机生成100个,200个,300个,400个,500个满足条件n=20,k=3,p=0.3的小世界网络,统计存在最小生成树是单源最短路生成树的网络个数,结果见表2。 表2 随机生成的小世界网络(n=20,k=3,p=0.3) 最小生成树是单源最短路生成树个数 在此类网络中,约有半数的网络能够找到这样的最小生成树,同时也为单源最短路生成树。 同时算法也考虑了实际运行时间。此次实验运行环境为:Intel(R) Xeon(R) CPU E3-1230v5@3.40 GHz 3.41 GHz,内存16 GB,操作系统windows10,Python 3.6.4 32位,Networkx2.2。记录了随机生成满足条件n=10,100,200,k=3,p=0.3的10个小世界网络的运行时间,重复5次,结果见表3。 表3 算法在节点数n=10,100,200的运行时间 因为随机生成的小世界网络的边数和节点数具有线性关系,因此根据定理2.2,得到在该网络上执行的算法时间复杂度为O(|V|3),表3实际计算的数据也验证了这点。 本文给出了判断任意网络是否存在最小生成树满足最短路的条件的算法,从理论上证明了算法的有效性,并通过构建随机生成的小世界网络验证了算法的可行性。 通过对算法时间复杂度的分析,和具体算例的计算时间分析,该算法因为复杂度较高,因此当网络结点规模比较大,边数稠密的情况下,需要比较长的计算时间。于是,如何改进算法,提高算法效率,是该问题进一步研究的方向。2.2 判定算法
2.3 广义Prim算法分析
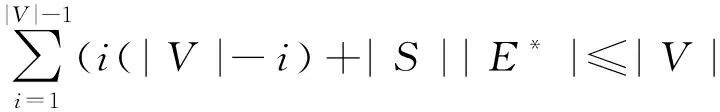
3 算例分析





3 结 论
