基于大数据的金融风险预警系统
2021-01-26杨凯森付飞蚺
杨凯森,付飞蚺
(1.浙江万里学院 大数据与软件工程学院,宁波 310000;2.长春理工大学 人工智能学院,长春 130022)
随着互联网、数字设备、物联网和其他技术的发展,全球数据正在迅速增长。大数据是更广泛和深入的数字化,是整个社会内部的数据互连。此外,大数据也被理解为解决问题的一种新方法,即通过收集,分类和分析与特定问题相关的海量数据,通过实验,算法和模型获得有价值的信息,从而发现规律并从中获利。大数据正在迅速发展为新一代的信息技术和服务格式,可以收集、存储和分析大量分散来源和各种格式的数据,并发现新知识,创造新价值并增强新功能。
金融业拥有最密集的数据,包括客户、运营、金融交易和监管数据,以及各种类型的衍生大数据[1]。据中国人民银行统计,仅2016年第三季度,全国银行卡交易量3 303.40亿笔,金额177.72万亿元,分别比上年增长35.71%和2.65%[2]。同比银行业金融机构办理电子支付交易364.88亿笔,总金额519.69万亿元。非银行支付机构网上支付服务8 440.42亿元,金额26.34万亿元。支付系统共处理交易额154.13亿笔,交易总金额1 344.34万亿元。第三季度的业务量是全国GDP的 71 倍[3]。
因此,金融业具有实施大数据的基本条件。未来,金融大数据将应用于精准营销、客户画像、运营流程优化、客户关系管理、风险控制等领域。大数据时代将对整个科技产业乃至世界产生颠覆性影响,并将成为未来金融业的主导角色。但是,大数据技术及其应用给金融监管和金融安全带来了严峻的挑战,对区域金融风险的监测、预警和解决提出了更高的要求。
区域性金融风险是指在经济区域内,某些金融机构或某些金融活动在金融系统运作中的不确定性造成的风险。它通过金融活动中的经济实体传播,导致区域金融环境的不稳定或金融危机。区域性金融风险将扰乱该区域的经济和社会发展秩序,区域性金融风险的积累也将转移到与经贸关系密切的其他地区,这将带来国家金融风险并导致国家金融危机,甚至世界金融危机。因此,建立科学可行的区域金融风险预警系统是需要研究和探索的重要课题。
当前,世界主要的区域金融预警系统如下:
(1)骆驼信用等级制度[4]。该系统主要评估银行业务的整体运营状况,例如银行的运营和信用状况,包括资本充足率、资产质量、管理、收益、流动性和市场风险敏感性,以及加权汇总后的整体评估。可以根据骆驼等级直接了解银行的风险状况。
(2)金融部门评估计划(FSAP)[5]。金融部门评估计划主要用于评估各国金融体系的稳定性,包括宏观审慎指标和综合微观审慎指标。宏观审慎指标主要包括经济增长,通货膨胀,利率等,综合微观审慎指标包括资本充足率,盈利能力指数,资产质量指数等。作为评估项目的共同发起者,国际货币基金组织和世界银行期望加强对成员国金融部门脆弱性的监测,减少发生金融危机的可能性。
(3)法国银行业委员会的银行分析支持系统[6](saaba)。Saaba通过汇总三年中的单个潜在损失来获得整个信贷组合的潜在总损失,并全面评估银行体系的健康状况。Saaba全面考虑了影响商业银行运作的所有方面,包括会计数据,资产风险调查,股东质量评估,企业信用等级,银行信用等级,公司逃税统计数据,监管数据,国家风险等,希望能尽可能多地捕获银行运营的各种内部和外部风险因素。
(4)荷兰银行(ABN AMRO)的风险分析支持工具[7](RAST)根据大小,中小型和大型的权重来评估银行的各种风险和控制能力。将风险评估的结果与偿付能力和获利能力进行比较,并将分析结果用于确定每个银行的监管实力。
国内学者利用大数据来研究金融风险,主要侧重于统计结合计算机技术在金融行业的应用。还有针对个别存货案例的详细指标分析和预测模型的建立。更有影响力的研究证实了或有债权分析法[8](CCA)风险指数对我国系统性金融风险预警具有良好的适用性,为我国金融风险计量提供了良好的理论研究基础。李志辉等人[9]基于风险依赖进行了扩展研究,实现了CCA方法的优化。在金融风险预测方面,采用大数据技术建立预测模型,并通过股票市场历史数据进行实证分析。例如,本文讨论了马尔可夫链过程理论在证券市场中股票价格综合指数的分析和预测模型中的应用,讨论了在大数据时代如何正确进行股票投资,研究了由大数据时代产生的随机变量。从大数据,机器学习和行为金融的角度进行股票投机,并基于特定股票的历史数据应用相应的算法实现预测功能。国内也有一些学者研究用户参与金融市场的影响。他们更倾向于研究投资者与金融新闻,在线论坛,微博和其他媒体之间的关系,表明它们可以在很大程度上影响证券市场。
在现有研究的基础上,可以发现在研究股票宏观市场趋势以及基于国内外大数据的相应预测模型的生成方面取得了丰硕的成果。对于单个股票趋势的分析和预测模型也进行了微观研究,而对相关参与者对金融市场影响的研究则较少。目前,大数据在中国各行各业的应用已取得初步成果,某些领域的应用已处于世界领先地位。其中,关于大数据与资本市场关系的研究也是金融市场的研究热点。使用大数据建立用户参与的预测模型对上市资本市场的总体影响基本上没有影响。相关金融市场参与者的结构分析(年龄,收入,教育背景),行为分析,交易量分析(网民和投资者),包括企业家,消费者,互联网用户(包括移动互联网用户,下同)和投资者等,本文以大数据源和用户参与行为为观察点,基于用户参与的角度以及大数据技术对财务风险的影响和预警系统的构建,设计了用户参与度评价系统和用户参与度预测模型。预警系统可以有效降低金融风险,防范金融风险。
1 基于大数据的金融风险预警系统的构建
1.1 设计原则
(1)系统原则。区域金融风险预警系统是用于监视,预警和处置区域金融风险的系统。它必须涵盖区域金融和经济活动的所有方面,包括吸收和支付存款,发行和回收贷款,发行和转让证券,保险,信托,国内和国际货币结算等;它应该涵盖所有类型的区域金融活动,包括银行,保险,证券和信贷。它涵盖区域金融活动的所有参与者,包括中央银行,金融机构,公司,企业,公众和监管机构;它渗透到区域金融活动的每个环节,甚至基于金融的虚拟和信用性质,也必须考虑公众舆论的趋势。应全面考虑国家和地区的宏观经济运行,经济社会发展和产业发展。
(2)及时性原则。区域金融活动具有快速变化的特点,区域金融风险变化非常快,要准确可靠地进行预警和保护,就必须确保区域金融风险预警系统具有良好的及时性,能够及时识别和判断风险因素。区域金融活动,预测和应对区域金融风险,并为监管机构提供控制区域金融风险的最有效方法。及时保留信息并留出足够的时间和空间。
(3)可操作性原则。在数据收集和系统分析过程中,所选的社会经济指标,数据统计分析方法和系统建模过程应易于操作和分析。
(4)灵活性原则。在预警系统的设计过程中,应尽可能考虑量化指标,以利于后处理分析。应建立一些定性指标,以反映定量指标无法代表的区域金融运作的潜在风险和不稳定因素。对于定性指标,应尽量减少人为因素的误导,对定性指标进行清晰的描述和明确的判断标准,以确保评价结果的客观性和准确性。同时,在保证金融体系正常运行的前提下,随着时间的流逝以及社会经济的变化,预警系统不断更新,完善和完善,以确保不同领域的独立运作。预警系统的模块,以提高系统的稳定性和可靠性。
1.2 模型构建
在有效市场假设下,金融市场的风险信息反映在股价走势中。股票价格变动中包含的信息不仅有价值,而且及时准确。因此,我们可以围绕股票价格对区域金融和金融机构进行实证研究。本研究使用数据爬虫技术收集数据源(Internet上的大数据),并使用全球GDP和增长率,中国A股上证综合指数(A本文借助SPSS分析了金融市场的相关参与者)并构建金融风险预警系统,在人类活动中,往往是由人为因素引发的各种大事件,面对利益,尤其是风险资本,各种人类需求,思想,情感,游戏金融风险事件中有政府层面,经济状况等因素,但公众参与也是触发系统风险的主要组成部分。资本市场交易,尽管已经出现了自动交易软件,但核心仍然是人,因此,对用户参与者评价系统的研究尚需时日围绕网民,投资者,企业家,消费者和其他方面。大数据对金融研究的影响通常是多方面的。二级用户企业家,消费者等相关指标在一定程度上反映了金融市场的投资收益和风险预期。首先对相关影响因素进行综合分析,然后建立一定的评价体系,然后对指标进行加权。
(1)相关性分析:通过趋势,交易量,中国A股上证指数幅度变化与用户规模,用户结构,用户行为相关性分析,多层次分析。
(2)评估指标的确定:首先是用户数和一个,然后,根据用户在互联网和移动互联网上的横向行为,例如搜索引擎,网络新闻,微博,社交网站,网上炒股等,等等,并结合东方财富,通化顺,和讯等中国权威金融网站,根据用户在互联网和移动互联网(例如搜索引擎)上的横向行为来选择影响资本市场交易的指标。在线新闻,微博,社交网站,在线炒股等以人次和有效浏览时间等垂直行为为指标建立的基础。最后,根据网民和投资者的沟通,情感,预测和赌博心理,建立用户风险指标。详细指标如表1和图1所示。

表1 用户参与评价体系指标

图1 用户行为图
(3)数据的获取和标准化:使用网络爬虫技术(详细信息请参见下面的数据收集算法)收集用户参与评价系统的各种指标数据资料,互联网用户与投资者之间的统计差距以及统计方法的不一致等。,需要对其进行更正以提供标准数据进行分析,包括以下内容:以日,周,月,季度等为单位的收集过程的统计周期。结果表明,开始和结束之间存在时间差。统计结束时,部分采集的数据丢失,需要人工判断统计结果的累加或平均值。
用户权重,用户结构和用户行为可以通过数据分析和统计软件进行初步确定,而沟通,情感,预测,赌博心理等用户风险指标和其他用户风险指标难以通过统计数据确定,则权重由专家评分方法确定。具体工作过程如下。
通过方差(公式1)测试,包括水平方差(公式2)和组内方差(公式2),根据数据的稳定性筛选了不必要的分析指标,例如用户的年龄变化趋势。表达公式如下。

其中,n是统计数据的数量,μ是n个统计数据的平均值,σrow是级别或不同组之间的方差,σcol是同一级别或同一组内的方差。根据三类指标的数量与一类指标的关系,根据2000年至2017年的数据计算单位间隔内的频次或数量,并不断累加。根据数据分布图(散点图)和MATLAB软件,推导了数据与指标之间的函数关系。数据拟合后,将出现高阶多项式函数,但是该函数不利于图检验,并且不容易确定数据是正相关还是负相关。因此,有必要将趋势修改和模拟为低阶和极项函数。具体操作步骤如下:
(1)Matlab的一阶函数:polyfit(xdata,ydata,1),xdata和ydata分别表示第三级和第一级指标的数据(以数组的形式,它们按时间顺序成对出现)
(2)精度(P):拟合数据和原始数据对应点的误差的平方和。本研究假设误差平方和的精度在0.1以内,其公式如下:

其中,yi是实际值,yˆi是拟合后的函数值。P的值越接近0,则拟合函数的可行性越高,数据预测就越成功。
根据统计数据,以用户行为为中介变量,由用户规模和用户结构构成用户行为的影响基础,用户行为是用户风险的最直接指标,从而建立影响力。用户参与评估系统的路径(如图2所示)。用户参与评估系统的影响路径和用户参与评估系统将作为构建用户参与模型的基础。

图2 用户参与评价体系影响路径分析
在用户参与评价体系的基础上,通过对用户参与影响路径的分析,建立了大数据用户参与模型,以降低大背景下用户不合理交流,情绪行为,不科学预测和赌博心理的风险。通过用户数量的影响,用户结构和用户群体行为的各种数据分析来进行数据分析;另一方面,该模型使用机器。学习算法提供波动预测,趋势预测,行为预测等,以减少剧烈波动的可能性。具体模型如图3所示。
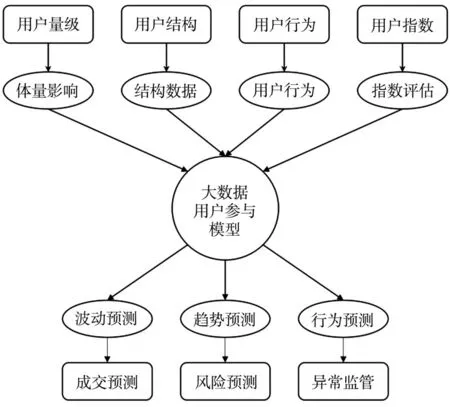
图3 大数据用户参与模型
2 基于大数据的预警系统设计
衍射峰强金融风险预警系统的功能包括数据采集系统,数据库系统和预警系统“数据对话”,利用数据挖掘技术建立有价值的数据库,然后通过机器学习算法设计预警跟踪和偏差修正等。,整个过程以数据为中心,基于大数据的金融风险预警系统的具体框架如图4所示。

图4 大数据下金融风险预警系统框架
(1)采集系统:由于金融风险预警系统的相关指标数据包含非结构化数据,难以在Internet上进行收集,清理和分析,并且往往需要人工干预,因此需要将爬虫技术和扫描监控技术相结合。全面的数据收集和风险预测是全面的数据收集和风险预测的基础。
(2)数据库系统:通过采集系统获得的数据仍需要进一步分析,不仅需要数据挖掘技术的支持,还需要大数据分析的手段。数据库系统是预警系统的核心。预警模型相关指标的分类和汇总在数据库系统中完成。数据库系统的完善直接影响机器学习的预测能力。
(3)预警系统:预警报告主要以指标临界值和预警间隔的形式显示。在确定风险分析和预测分析之后,形成预警报告。同时,对预警系统是否与实际需求进行实证跟踪相结合,分析预测结果偏离的原因,并改进相关算法,以提高机器学习系统的预测功能,缩小两者之间的差距。随后的预测,并提高了预警系统的准确性和科学性。
3 系统数据效果分析
根据互联网发展报告,中国互联网用户规模发展迅速,2018年已接近8亿,互联网普及率从不到3%增长到近60%。同时,由于智能手机,3G和4G的发展,随着通信技术的迅速发展,移动互联网用户也从2006年的1 300万(受统计数据限制,2006年之前没有相关数据)迅速增长到7.5亿(2017年12月),其中2007年至2012年的年增长率超过100%。同时,根据中登集团发布的数据,2000年参加A股股票的投资者数量为6 154万(同年增加1 343万)。2002年,由于大量的不定期清算,年底的投资者数量为6 841万,到2018年已达到13 863万(开户数量已超过1.7亿,部分分离的投资者无效)。
从投资者数量和互联网用户(包括移动互联网用户)数量的角度来看,用户参与的数量巨大,投资者和网民的行为将产生大量数据,互联网用户的行为的访问,转载和传播大大增加。基于大数据的群体行为,例如用户参与结构分析,注意力,情绪反应等,对股票的上海股票指数具有重大影响。
宏索引统计和分析算法。宏观分析采用的是A股主板市场的沪市指数(因为创业板还不成熟,涨跌幅度太大,容易产生偏见)。收集样品。从1999年至2018年,A股上海股票指数获得的分析信息包括收盘价,最高价,最低价,开盘价,前收盘价,涨跌幅,涨跌幅,交易量,交易量等。A股(上证指数)指数的统计过程如表3所示。统计期间为当年首个交易日至当年最后一个交易日(2018年除外),统计结果为如表2和表3所示。
根据不同指标之间的定量关系,形成了大数据训练集。以A股(上证指数)指数为ydata(不同的区间幅度和交易量),导入不同组的指数数据xdata(包括用户量,用户结构,用户行为等),然后拟合计算每组指标,并提供数据规则以进行基本分析。
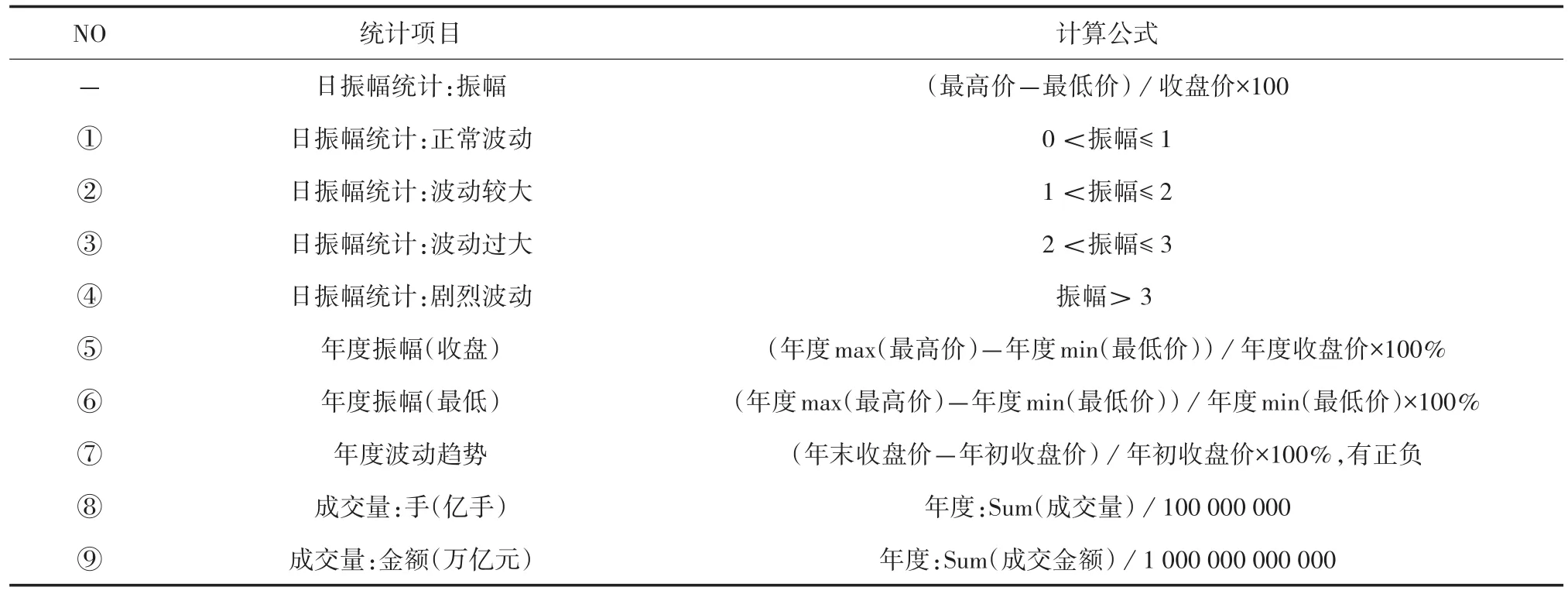
表2 A股(上证指数)指标统计过程

表3 A股(上证指数)指标统计结果
用户参与模型相关性分析测试。在用户参与模型中,指标之间的定量关系根据年度变化具有连续变量之间的相关性。因此,本研究使用乘积差异相关系数(也称为皮尔逊系数),可以直接筛选出具有高相关性的指标,并进一步从高相关性指标中进行分析,以验证模型的预测功能并计算公众利益。
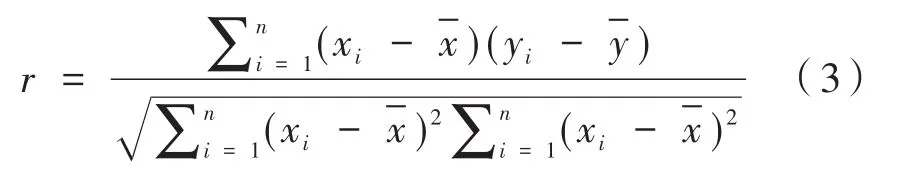
式中,x和y是用户参与模型中的不同指标。y与ydata相同。取A股(上证指数)指数数据(区间波动幅度和交易量不同),r为两个指标之间的相关性。指标选择的依据如表7所示。由于某些指标缺乏数据收集,在年度统计中,使用相对完整的数据间隔进行相关分析,并获得高度相关的分析。
4 结论
根据用户年龄统计,各个年龄段的趋势变化不明显,但30岁以下的网民和投资者不成熟的比例较大。这群人很容易受到网络媒体等信息的影响,甚至被误导,然后传播不当的信息,这更有可能导致信息偏差和市场动荡。
从教育背景的角度来看,不同学历的比例是不稳定的。投资者的文化程度往往较高,而低文化程度的比例正在下降。高等教育对股票市场的影响主要包括两个方面:一是研究更深入,信息搜索更有效,投资更加谨慎。二是更加科学的投资手段,大数据和自动交易软件的应用率正在提高。
从用户行为分析结果看,金融事件与股市波动性(幅度)具有很强的相关性,尤其是在负信息的下降趋势中,其幅度将随着金融事件的传播而不断增加,并产生搜索指标通过用户也将扩大。
显然,政治,金融,军事,流行等事件在不同国家的感染程度不同,影响力的差异主要在于用户参与事件传播引起的风险传染等主要因素。因此,在一定时间内适当引导各种金融事件引起用户的关注,可以有效地控制和预防金融风险的发生和扩大。
