一种多指标融合的自适应重要节点识别方法*
2021-01-22王伦文张孟伯
邵 豪,王伦文,张孟伯
(国防科技大学电子对抗学院,合肥 230037)
0 引言
目前复杂网络的研究得到了广泛关注,网络理论可以详细分析个体间复杂的相互作用及传播过程,在战场态势感知、网络对抗等领域中发挥着关键作用[1]。网络中不同节点在结构和功能上有着完全不同的功能与作用,当某些节点失效时,整个网络会迅速遭受到破坏[2]。因此,识别网络中的重要节点有助于分析控制网络。例如在战场通信网络中,保护己方通信网中的重要节点,有助于提高网络抗毁性,保障作战信息的传输;针对敌方通信网络的重要节点进行干扰,能够以更少的干扰资源摧毁敌方通信。
至今已有许多评价网络节点重要性的指标[3],例如节点度[4]、凝聚度[5]、介数[6]等。其中节点度基于邻居节点数目,方法简单但准确性不高。节点的凝聚度通过分析节点间的最短路径以提高度排序的准确性,但计算复杂度很高。Kitsak 等人提出运用K 核分解寻找网络核心的节点,但其低分辨率限制了广泛的应用[7]。最近,余法洪等人[8]利用最小连通支配集来识别网络重要节点,紧密子序列数量越多节点的越重要。杨云云等人[9]考虑节点之间的接触频率和节点之间的接触时间长度,提出双向PageRank 算法在复杂网络中挖掘重要节点。
上述文献从不同角度出发,针对特定网络结构定义节点重要性指标,获得较好的性能。事实上,不同网络拥有不同结构特征,甚至同一网络不同部位的结构也是完全不同的,因此,单一的重要性指标在不同网络中不可能都得到很好的性能。为此,本文提出一种多指标融合的重要节点识别方法,综合考虑多个指标来确定重要节点。考虑到多个指标间存在关联信息,且更多的指标会导致计算复杂度高,本文利用主成分分析法[10]筛选合适的指标,以尽可能少量不相关指标,尽可能多地覆盖网络信息,通过灰色关联方法[11]确定各主成分的排序,避免主观判断影响算法的合理性。实验结果表明,在不同网络中,本文提出的重要节点识别方法普遍具有高识别精度和准确度。
1 相关知识
1.1 网络性质参数

其中,dij表示节点i、j 间最短路径的长度。由式(1)可得,网络规模越小,平均最短路径越短,其凝聚度越高。
1.2 传统节点重要性评价指标
以下介绍常见的节点重要性指标,通过比较每个节点间的相似指标值sij,将所有节点的sij值由大至小排序。sij越高,节点在网络中越重要。一些常见的节点重要性指标如表1 所示[12]:

表1 常见的节点重要性指标
表1 中介绍了常见的9 种节点重要性指标,这些指标包含了尽可能全面的指标信息。前6 种指标考虑节点的显著性,即比较网络节点的位置来衡量其重要性;后3 种指标考虑节点的破坏性,即删除某节点后,比较网络破坏情况来比较节点重要性。这些指标从不同方面考虑节点的重要性[12],单个指标不可能适用于所有结构不同的网络。例如以DC指标为例,在下页图1(a)中,利用DC 指标,中间节点度最高,因为在网络中最重要,显而易见是准确的。在(b)中,共有5 个节点的度为2,其重要性相同,但很显然中间节点的重要性要高于边缘节点,此时DC 指标在(b)网络中性能很差,此时EC 指标能准确分析(b)网络的重要节点。因此,本文考虑综合多指标分析节点重要性,提出了MIF 方法。
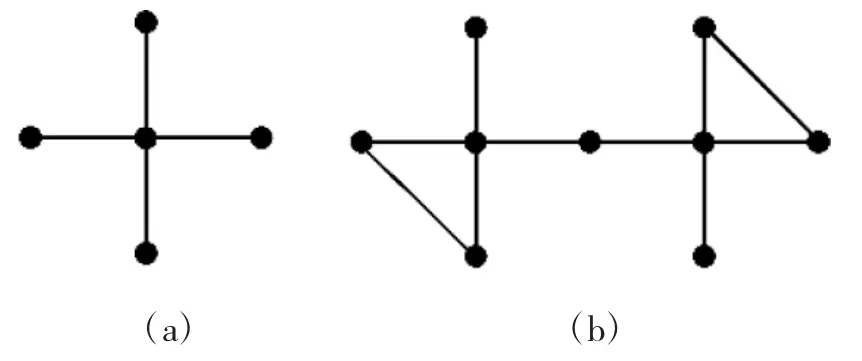
图1 两种不同的网络拓扑
2 多指标融合的重要节识别方法
本文提出的MIF 方法由以下步骤组成:①指标数据预处理;②利用主成分分析[10]降维,提出合适指标并降低其相关性;③熵权法[13]计算各主成分权值;④基于灰色关联分析[11]确定节点重要性。以下详细介绍各步骤思想与具体实现过程。
2.1 指标数据预处理
2.1.1 指标正向性调整
在上述指标中,DC、CLC、BC、KS 是正向性指标,即指标值越大,节点重要性越高;相反的,CC、EC、SP、MC、SN 指标是负向性指标。以下将负向性指标调整为正向性指标,使指标值与节点重要性的排序相统一,以便于与其他正向性指标进行综合分析,调整方式如表2 所示。
在表2 中,CC、EC、MC、SN 指标最大值为1,表示网络直径,即节点距离的最大值。调整后的指标满足正向性条件,与节点重要性排序一致。
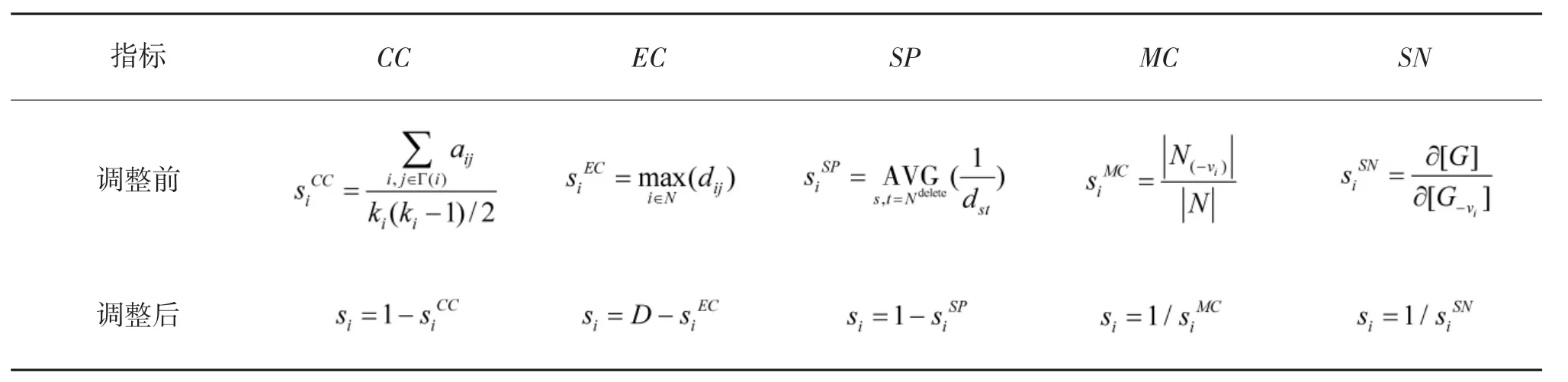
表2 负向性指标正向调整
2.1.2 指标数据归一化
不同指标具有不同定义、量纲单位及数量级,这直接影响指标分析的准确度,故而对指标归一化,使不同维度指标具有可比较性。归一化处理如下:

最终得到归一化运算后的指标数据矩阵:

2.2 主成分分析
考虑到不同指标间存在重复信息,指标数目越多,计算复杂度越高。主成分分析法利用正交变换,将多个相关的向量指标重新组合为少数不相关的主成分指标,且这些指标尽可能包含原始信息[10]。明显地,主成分分析法是一种基于线性变换,将高维数据投影到低维空间的降维方法,步骤如下:


2.3 灰色关联分析
关联度含义是多个对象间关联程度的度量。若两个对象的指标变化一致性较低,则关联度较低;反之则较高。灰色关联分析法比较不同对象间的相似性,分析其关联程度。本文方法中,确定最优的节点重要性指标作为参考指标,利用灰色关联分析法比较所有节点的重要性指标与参考指标,根据与参考指标的相似性综合确定节点重要性,即节点指标与参考指标越接近,该节点重要性越高。
2.3.1 关联系数与关联度
前文已经将所有指标调整为正向性指标,参考指标是最优的节点重要性指标,因此,将H 矩阵中每一列指标的最大值作为参考指标,即:

事实上,节点不同维度的关联系数对于关联度的贡献不同,此时关联度Ri定义为:

其中,δj表示第j 个指标在计算关联度时的权重。本文提出熵权法计算关联系数权重δj。
2.3.2 熵权法确定权重
在信息论中,熵被用来判断指标的离散程度。若某个指标离散程度越大,则其对综合的权重也越大。例如,所有节点的某个重要性指标都相等,则该指标对离散程度为0,权重也为0,对综合分析没有任何贡献。计算第j 个指标的熵如下:

其中,pij是第i 个节点的第j 个指标在该列指标中的比重,ej是第j 列指标的熵。权重系数δj为:

3 实验分析
3.1 实验数据与流程
为验证本文算法性能,本文使用Zachary 网络(http://www-personal.umich.edu/~mejn/netdata/karate.zip) 和Dolphin 网络(http://www-personal.umich.edu/~mejn/netdata/dolphins.zip) 进 行 仿 真 实 验。Zachary 网络包含34 个节点和78 条边;Dolphin 网络包含62 个节点,159 条边。网络拓扑如下页图2所示。
在实验中,首先将Zachary、Dolphin 网络改为无权向网络。随后,利用Matlab 程序分别计算两个网络中所有节点DC、CLC、BC、KS、CC、EC、SP、MC、SN指标,得到各节点在所有单指标下的值及排序情况;再以这些指数作为节点的重要性的多维参数,正向化与归一化后,利用SPSS 软件对指标进行主成分分析,以消除不同指标间的相关性并降维,之后结合灰色关联分析法与熵权法确定节点重要性指标排序,排序越前的节点在网络中处于更加重要的地位。
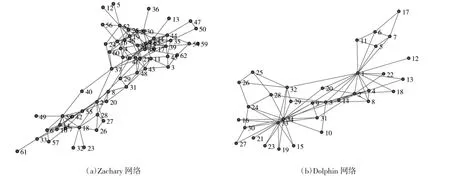
图2 网络节点拓扑图
3.2 实验结果
本文采用SPSS 软件,对节点不同重要性指标进行主成分提取。表3 表示SPSS 软件输出的KMO和巴特利特检验值,其反映原始指标间的相关性强度;表4 表示所有成分指标的方差矩阵,从中可以表示式(5)中特征值的比例排序,下页表5 为主成分的系数矩阵。
表3 表示两个网络各指标KMO 和Bartlett 检验结果,其反映各指标间的相关性水平。KMO 抽样用于研究不同指标间的偏相关系数,KMO∈[0,1]。已有的文献研究表明[10],KMO 值越接近1,说明指标间进行主成分分析的效果越好,KMO 小于0.5,则指标不适合进行主成分分析。Bartlett 球形度指标的显著性p<0.001 表明指标高度相关,此时主成分分析有合理的理论基础。表3 得,KMOZachary=0.749,KMODolphin=0.654,Bartlett 球形检度显著性p=0.000,说明初始指标高度相关指标,进行主成分分析合理可靠。

表3 KMO 和巴特利特检验结果
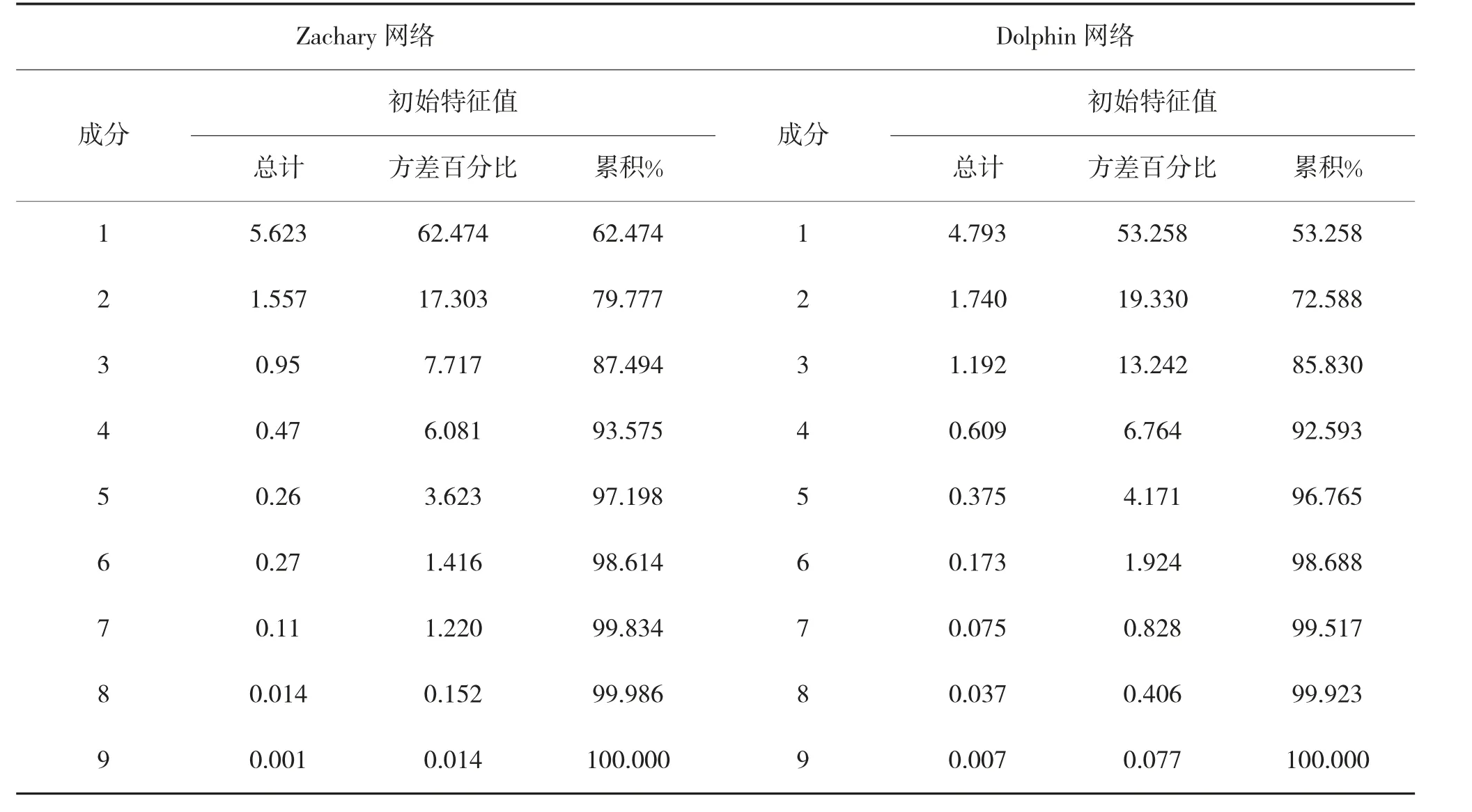
表4 总方差解释表
表4 是主成分分析后,各成分总方差解释表。各成分以特征值从大到小进行排序,排序在前的成分能包含更多的原始信息,主成分共应包含80%以上信息。在两种网络中,前3 个成分一共可以累积87.494%与85.830%的原始信息,说明前4 个成分已经满足对总体解释率的需求。因此,分别取前3个成分作为各网络节点重要性的主成分指标。成分矩阵表如表5 所示。
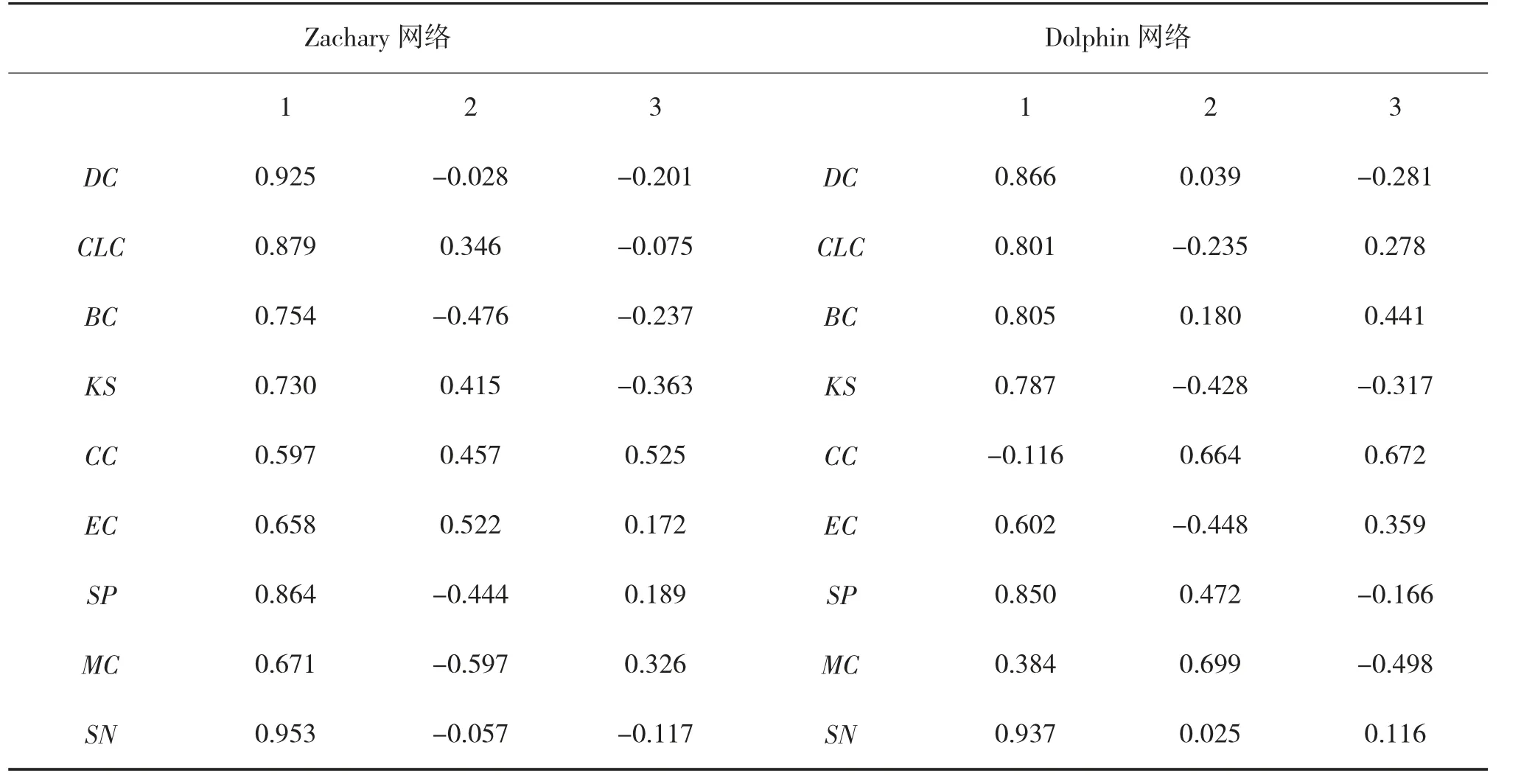
表5 成分矩阵表
表5 是主成分矩阵表,表示原始指标与主成分的对应系数。通过对应的线性变换,可得两种网络对应主成分向量。进行灰色关联分析后,得到两个网络各节点的灰色关联度值如图3 所示。此外,研究表明,如果一个网络中5 %~10 %的关键节点失效,则网络就会陷入瘫痪[14]。因此,以下对不同指标下前10%的重要节点进行排序,结果如表6、表7所示。
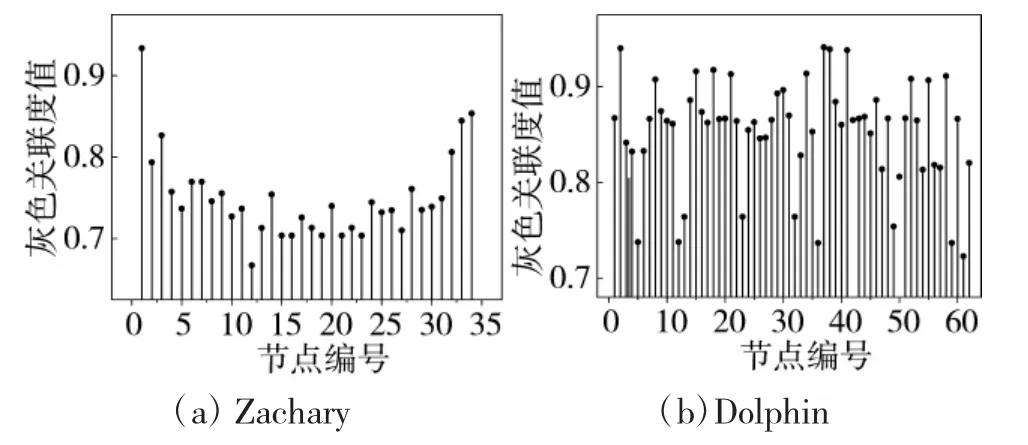
图3 各网络节点灰色关联度值

表6 Zachary 网络指标位于前10%的节点排序
3.3 实验分析
针对各重要性指标的结果,以及表6,表7 表示的节点排序,本节从算法有效性与准确性两方面分析本文提出的MIF 方法的性能。
3.3.1 指标精度分析
指标精度分析主要考虑各方法是否能产生尽可能分散的指标值,如果多个节点的指标值相同,此时将无法区分其重要性。因此,将两个方法得到的指标值中重复部分删除,计算剩余不同值所占的比例,以此分析各指标结果的分散情况。
从表8 中可得,KS,EC,MC 作为粗粒度的重要性排序方法[15],精度很低,说明大部分节点的重要性值不唯一,造成分辨困难。本文提出的MIF 方法,当某指标值相同无法分辨时,可利用其他指标进行分析,排序精度很高,在Zachary 和Dolphin 网络中,MIF 的分散指标值比例为82.35%和96.77%,相较于其余单指标有最高的排序精度。之所以未到100%,是因为网络中确实存在极少数节点,它们的邻居节点及功能完全相同。由此,MIF 方法在指标精度方面有很好的表现。

表8 各指标不同值所占比例(%)
3.3.2 指标排序准确度分析
现分析表6 与表7 的指标排序结果是否和实际网络节点的重要性相一致。在Zachary 网络中,本文MIF 方法的前5 个节点与BC、SP、SN 相同,与DC、CLC 有4 个相同节点,与CC 有2 个相同节点;在Dolphin 网络中,MIF 方法与SN 有6 个节点相同,与DC 与4 个节点相同,与CLC、BC 各有5 个节点相同,与EC、SP 有3 个节点相同。可以看到,MIF算法与各指标都有不同程度的关联,说明其综合考虑了各指标的性能,与单指标方法相比更具合理性。
为更进一步分析本文MIF 方法的准确性,以下筛选MIF 与其他单指标前10%排序结果不同的节点,分析其信息传播能力。筛选节点的编号如图9所示。
以下解释选取这些节点的理由:在Zachary 网络中,(1)2、9、10 号节点分别在DC、CLC、CC 指标的前10%排序中,但不存在于MIF 中;32 号节点存在MIF 前10 %排序中,但不存在DC、CC 排序中。(2)1、10、34 号节点是不同指标下的排序首位的节点。在Dolphin 网络中,(1)21、52、58 号节点分别存在于其他单指标前10%排序中,但不存在于MIF 排序中;34 号节点是MIF 前10%排序中最末的节点;(2)15,37,52 是不同指标中排序首位的节点。

表9 分析传播能力的节点编号
SIR 感染模型[16]模拟信息在网络中的传播,将某一节点作为初始感染节点,以α 的概率感染其邻居节点,并以β=1 的概率作为免疫状态,直到网络中所有节点无法被感染时,过程终止。以下计算已感染过的节点占所有节点的比例,以此衡量节点的传播能力。图4 表示各网络感染节点所占比例,其值是100 次独立实验的平均值。

图4 各网络传染节点比例
收敛状态时感染节点所占比例越高,说明此节点的传播力越大[17]。对比4 组感染节点可得,在图4(a)中,Zachary 网络32 号节点相较于2、9、10 号节点有更优的传播能力,因此,MIF 方法得到的10%节点排序中,32 号节点的位置是准确的。在(b)中,Zachary 网络1 号节点的感染节点比例仅比34 号节点略高0.5%,基本持平,但远高于10 号节点,说明Zachary 网络中,1 号节点的传播能力与34 号节点基本相等,这与MIF 得到的结果一致。在(c)、(d)中,Dolphin 网络34 号节点传播能力高于21、52、58节点,且37 号节点传播能力高于15、52 号节点,说明相较于其他单指标方法,34 号节点在MIF 方法的前10%节点是合理的;且37 号节点作为MIF 最首的节点,比其他单指标将15 或52 号指标作为最首节点更具说服力。可见,本文MIF 方法相较于其他指标,在寻找传播力大节点方面性能出色,重要性排序准确。
综上可得:通过上述对Zachary 与Dolphin 网络仿真实验表明,本文提出的多指标融合判断节点重要性的方法,利用不同指标的互补性,与单指标判断相比具有很高的排序精度;且对位于前10%的节点分析表明,本文提出的MIF 方法能够更好地找到网络中传播能力更大的节点,对网络节点重要性排序更加准确。
4 结论
随着信息技术的迅速发展,网络在各领域都发挥着至关重要的作用,识别网络中的重要节点在实际中有十分重要的意义,本文在已有众多重要性指标的基础上,提出一种基于多指标融合的重要节点识别方法。该方法主要考虑各指标间的互补性与交差关系,在进行主成分分析降低其相关性的基础上,利用客观赋权的方法确定每个指标的权重,并通过灰度关联分析对网络中所有节点进行重要性排序。实验表明本文提出的方法是合理的,与单指标分析相比,本文方法的排序精度与准确度都有明显的提高。下一步将深入研究在有权向网络及动态网络中多指标融合的重要节点识别方法。
