基于语义对齐和重构的零样本学习算法
2021-01-20王紫沁
王紫沁,杨 维
(北京交通大学 电子信息工程学院,北京 100044)
0 引 言
当测试数据中的类别(不可见类)在训练数据的类别(可见类)中没有出现时,零样本学习算法(zero-shot learning,ZSL)通过利用包含类别关联信息的语义空间和已知类的训练数据对不可见类识别[1,2]。基于映射方法的ZSL做法是用可见类数据学习图像空间和语义空间的映射模型,将模型运用到不可见类上,然后在映射空间使用相似性度量对未知类进行识别。针对视觉-语义映射模型,已有的工作可以分为3类:第一类将图像特征映射到语义空间[3-5],第二类将图像特征和语义特征映射到公共空间[6-9]。不论是语义空间还是公共空间映射都会加剧高维空间枢纽问题,采用KNN算法时,一些“hubs”会成为大多样本的预测类别。第三类采用反向映射回归方法可以规避枢纽问题[10,11],但是语义原型特征映射到图像空间后易于汇聚到原点,偏离每类的图像特征区域。除了枢纽问题外,第二类方法中Fu等提出域漂移现象,并提出使用多个语义和图像特征的正规相关分析来缓解漂移问题,但使用了测试数据并且算法复杂[7]。第一类方法中Kodirov E等提出语义自编码(SAE)方法,通过构建语义空间映射模型并增加重构图像空间的约束。该方法存在语义特征到图像特征的映射,但是体现在CUB数据集,在AwA数据集是正向映射为主体。SAE针对解决的是域漂移问题,算法高效且简单[5]。
为了联合考虑上述两个问题,提出了基于语义对齐和重构的零样本学习算法RMSASC(reverse mapping via semantic alignment and semantic reconstruction)。首先,本文采用语义空间到图像空间映射规避枢纽问题,并针对语义原型偏离现象提出基于语义对齐的约束,使语义原型特征都映射至每类图像特征原型处,促使两个空间特征对齐,缓解了枢纽问题。同时为了缓解域漂移问题提出语义特征重构的约束,使模型学习到完整的映射到图像空间的、没有丢失不可见类的有效语义特征维度信息,使模型更具有泛化性和鲁棒性。通过在零样本学习的基准数据集(AWA和CUB)上实验,验证了所提零样本算法具有较好的分类效果。
1 零样本分类算法的问题定义


2 RMSASC零样本学习算法
RMSASC零样本学习算法是为了缓解零样本学习中的枢纽问题和域漂移问题而提出的,该算法的基本映射模型是语义空间到图像空间的反向回归映射。模型的架构采用两层的神经网络,每层神经网络是线性层和激活层的组合,比线性映射模型有更强的表达能力,充分学习两个空间特征的关系。采用基本模型,映射后的语义特征比图像特征方差小,仍会偏离图像特征中心区域,在采用KNN算法找最近邻时,hubs会导致预测失误。语义对齐的正则化约束可以使每个样本的语义原型特征映射至每类图像特征原型处,促使两个空间特征原型对齐,有效缓解了枢纽问题。同时,为了缓解零样本学习中的域漂移问题,提出加入将图像空间中的语义特征映射点重新映射到语义空间的正则化约束,重构完整有效的语义特征信息。因为在用可见类训练数据训练模型中,有的语义特征维度对于不可见类是重要的,而于可见类是不重要的,在模型学习中可能会被丢掉。语义重构的约束会重构完整的语义特征信息,使得模型更具有泛化性和鲁棒性。接下来从RMSASC零样本学习算法的基本模型、语义对齐和语义重构约束介绍。
2.1 RMSASC算法的架构和基本模型
本文提出的基于语义对齐和重构的零样本学习算法——RMSASC的整体架构如图1所示,主要包含两个分支:图像特征提取分支和语义特征映射分支。

图1 RMSASC模型整体架构
图像特征提取分支是将训练图像Ii输入CNN卷积特征提取网络,输出得到维度为D的图像特征向量φ(Ii)∈RD×1。 图像特征空间将作为图像的嵌入空间和该图像所对应的可见类语义特征的映射空间。


图2 语义特征映射分支
语义特征映射分支中的映射模型中的参数是需要学习的,当每个训练图像的语义特征映射到图像特征空间后,和提取的图像特征之间计算通过平方损失函数,目标是最小化训练样本的图像特征和语义嵌入特征的误差,使得训练图像的语义嵌入特征与图像特征的相似度变大。通过上述定义,则RMSASC算法的基本模型(RM)如下所示

(1)
其中,W1∈RL×M是语义特征映射分支映射模型的神经网络的第一个FC层的权重,W2∈RM×D是第二个FC层的权重。γ是损失函数中对权重的正则化损失的参数,是一个超参数。f(·)=max(0,·) 是ReLU激活函数。
2.2 语义对齐约束(SA)
反向回归映射后,会存在一种现象:在图像特征空间中,语义嵌入特征的方差小于图像特征的方差,即映射后的数据更加接近空间的原点而不是目标数据分布。虽然式(1)的目标函数是为了使每个图像的语义特征映射后尽可能接近于该图像特征,但是存在的这个现象,使每个样本的语义特征不能通过映射模型学习到图像空间中最佳的映射点,在进行最近邻预测算法中,hubs可能导致类别预测错误。因此,设计一个语义对齐约束,让每个样本所属类别的语义特征通过映射后,与该类样本图像特征的原型对齐。这种约束对数据进行了增强处理,增加了样本的多样性,进而增强了模型的学习表达能力;同时提供了图像空间每个类的标准,利于语义原型特征映射到正确类别的图像特征处而不是原点附近,缓解了枢纽问题。
每类样本的图像特征的原型是具有代表性的点,大量的样本的数据分布满足高斯分布,因此原型点是每类图像特征的均值。提出的语义对齐的约束如下
(2)

2.3 语义重构约束(SC)
在基于语义对齐的反向映射零样本学习算法(RMSA)中,其目的是最小化语义特征和图像特征、语义特征和图像特征原型的欧氏距离,很好学习到了可见类图像的两个特征空间的数据相似关系。但是,可见类和不可见类别对象分别具有不同的互斥的类集,因此在两个空间的数据分布是不同的。如果直接把在可见类数据集上学习到映射模型运用到不可见类别的对象上,则结果会产生一定的偏差。因此,为了缓解这一问题,受语义自编码模型的启发,考虑添加将语义嵌入特征映射的结果再反向映射到语义空间的语义重构约束。这一约束可以使得语义-视觉的映射模型重构原始完整的语义特征信息。因为有的语义特征对于不可见类别是重要的,对可见类是不重要的,所以可能用训练数据学习模型过程中,某些不可见类的语义特征被丢失。因此语义重构约束使得模型具有鲁棒性和泛化性,更好的应用于未知类对象。语义重构约束如下
(3)

2.4 RMSASC模型
通过结合上述的基本模型、语义对齐约束和语义重构约束,得到了基于语义对齐和重构的零样本分类算法(RMSASC)。算法模型表示为
(4)
其中,λ、β和γ是需要学习的超参。
当映射模型学习完以后,将测试图像Ij输入图像特征提取分支得到图像视觉特征φ(Ij)∈RD×1, 将所有不可见类语义特征经过语义特征映射分支映射到图像特征空间中,得到语义嵌入特征φ(yv)∈RD×1, 然后计算测试图像视觉特征与所有的语义潜入特征的距离,最后找到距离最小的语义嵌入特征,其所对应的类为该对象的类别。计算如下
(5)
其中,D是距离度量函数,本文采用的是欧式距离。yv是语义特征空间的第v类的语义特征。
3 实验和结果分析
本文基于PyTorch[12]深度学习框架实现了RMSASC算法,并在两大主流零样本标准数据集上进行了实验。实验的环境是一台拥有4张12 196 MB显存的Titan Xp和1块62 GB的CPU内存的Ubuntu服务器。
3.1 数据集配置
本次实验使用的是各具特点的且含有公开图像的标准的零样本学习数据集,即AwA(animals with attribu-tes)[13]和Caltech-UCSD Bird2011(CUB)[14]。数据集的详细细节见表1。

表1 数据集的详细信息
AwA是动物数据集,属于粗粒度图像,共包括50个类别的30 475张图像。按照官方划分,其中可见类类别是40类,不可见类类别是10类,每个类别都具有85维的连续属性。CUB是鸟类数据集,属于细粒度图像,共包括200个类别的11 788张图像,其中,可见类类别是150类,不可见类别是50类,每个类别都具有312维的连续属性。
3.2 实验配置
本文实验数据集的图像特征提取网络采用的是在ImageNet数据集上进行过预训练的ResNet101卷积网络[15],并没有在相应的数据集上做微调处理。首先把本文数据集的图像按照中心裁剪方式裁剪成256×256尺寸,然后缩放成224×224尺寸;其次,将图像的3个颜色通道分别按均值为(0.229,0.224,0.225),标准差为(0.485,0.456,0.406)进行归一化处理后,输入到预训练的ResNet101卷积网络,得到全局池化层(GAP)输出的2048维的图像特征。
本文使用的语义空间的特征是属性特征。具体地说,AwA使用的是数据集提供的85维度的类级别的连续属性;CUB使用的是数据集提供的312维度的类级别的连续属性。
3.3 实验过程
(1)首先要确定在基本模型RM下语义特征映射分支的神经网络的架构,输入层神经元数目由属性维度决定,输出神经元数目由图像特征维度确定,中间第一个FC层的神经元个数通过实验确定。对于AwA,设置FC层神经元数目m取值范围是m∈[100,2000]; 对于CUB,设置FC层神经元数目m取值范围是m∈[400,2000]。 通过实验确定AwA和CUB的第一个FC层的神经元个数分别为300和800。
(2)当确定了神经网络模型后,调节目标函数(4)的超参,设置λ∈[0,0.2,0.4,0.6,0.8,1],β∈[0,0.00001,0.0001,0.001,0.01,0.1,1]。 通过取不同数值进行网格搜索,得到了RMSASC模型。
在第(1)和第(2)的训练过程中,采用的是Adam优化算法,对于AwA数据集,学习率设置为0.0001,mini-batch设置为64,梯度裁剪设置为5;对于CUB数据集,学习率设置为0.000 01,mini-batch设置为100,梯度裁剪设置为1。
3.4 结果分析
经过在AwA和CUB的20 000次和30 000次的迭代训练和权重更新,本文得到了在数据集AwA和CUB上的ZSL实验结果,表2给出了本文方法与其它方法的比较结果。本文对比的零样本学习算法有直接属性预测(DAP)[4]、语义相似性嵌入零样本学习算法(SSE)[16]、联合嵌入零样本学习算法(SJE)[6]、一种简单的不可靠约束的零样本学习算法(ESZSL)[8]、合成分类器的零样本学习算法(SYNC)[17]、指数族的零样本学习算法(GFZSL)[18]、语义自编码器的零样本学习算法(SAE)[5]和深度嵌入约束的零样本学习算法(DEM)[10]。
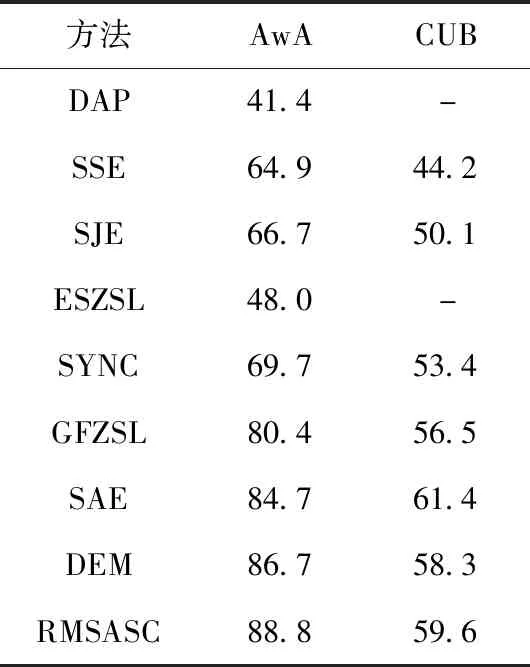
表2 不同的零样本分类方法在数据集上的正确率比较
表2中,“-”表示该文献并没有对相应的数据集做实验。
我们可以看到本文提出的RMSASC模型在AwA数据集的未知类别上取得了88.8%的分类正确率,在CUB数据集的未知类别上取得了59.6%的分类正确率。对于AWA,本文的分类正确率是最高的,与本文具有较大竞争力的是SAE和DEM模型,本文模型比SAE和DEM模型分别提高了4.1%和2.1%;对于CUB,本文模型的分类正确率虽然比SAE模型小,但是效果仍然是比较好的,比GFZEL和DEM模型分别提高了3.1%和1.3%。验证了本文的方法对未知类别具有较高的识别能力。
本文是在反向映射的基本模型上,增加了基于语义对齐和语义重构的约束,得到了RMSASC模型。接下来想考察一下RM、RMSA和RMSASC模型在数据集上的分类识别率,来验证一下两个约束的有效性。
下面定义一下3种模型:
(1)RM基本模型:设置目标函数(4)中的λ=0,β=0;
(2)RMSA模型:设置目标函数(4)中β=0, 调节λ;
(3)RMSASC模型:目标函数(4)不变,调节λ和β。
图3和图4分别是RMSA模型在AwA和CUB数据集的分类识别率情况。从图中可以看出,增加语义对齐约束可以提高零样本分类算法的分类性能。对于AwA,当λ等于0.6的时候,RMSA的分类正确率比λ等于0(RM基本模型)的分类正确率高。对于CUB,当λ等于0.4的时候,RMSA的分类正确率比λ等于0(RM基本模型)的分类正确率高。根据结果,说明了基于语义对齐的约束,可以帮助语义空间的每类的语义特征较优地映射到图像空间中每类的图像特征中,提高了分类识别率,验证了它的有效性。

图3 RMSA模型在AwA数据集的分类识别率
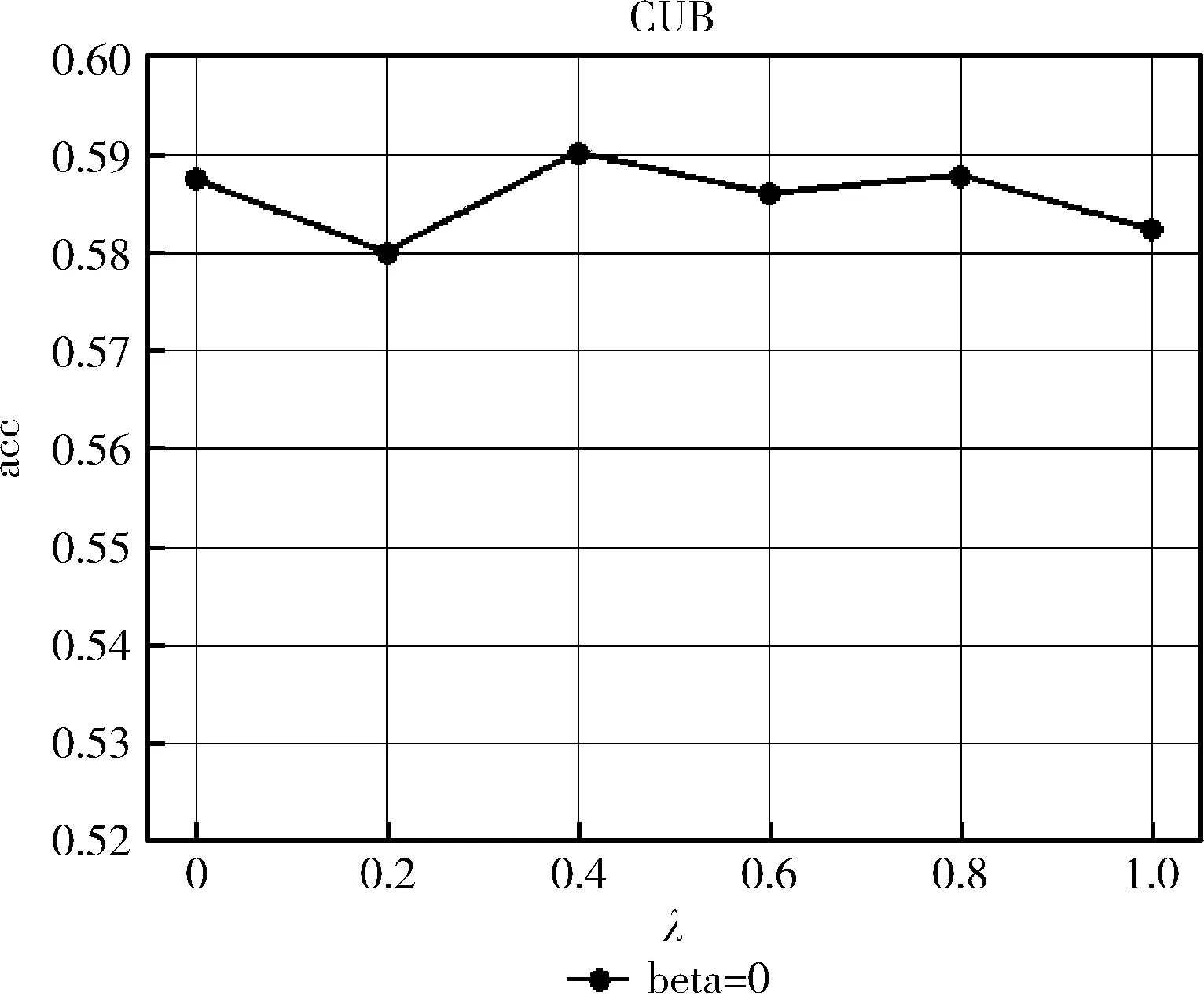
图4 RMSA模型在CUB数据集的分类识别率
图5和图6分别是RMSASC模型在AwA和CUB数据上的分类识别率情况。图中,横坐标显示的是不同的语义约束,图中央显示的6个不同的语义重构约束,纵坐标显示的是分类正确率。
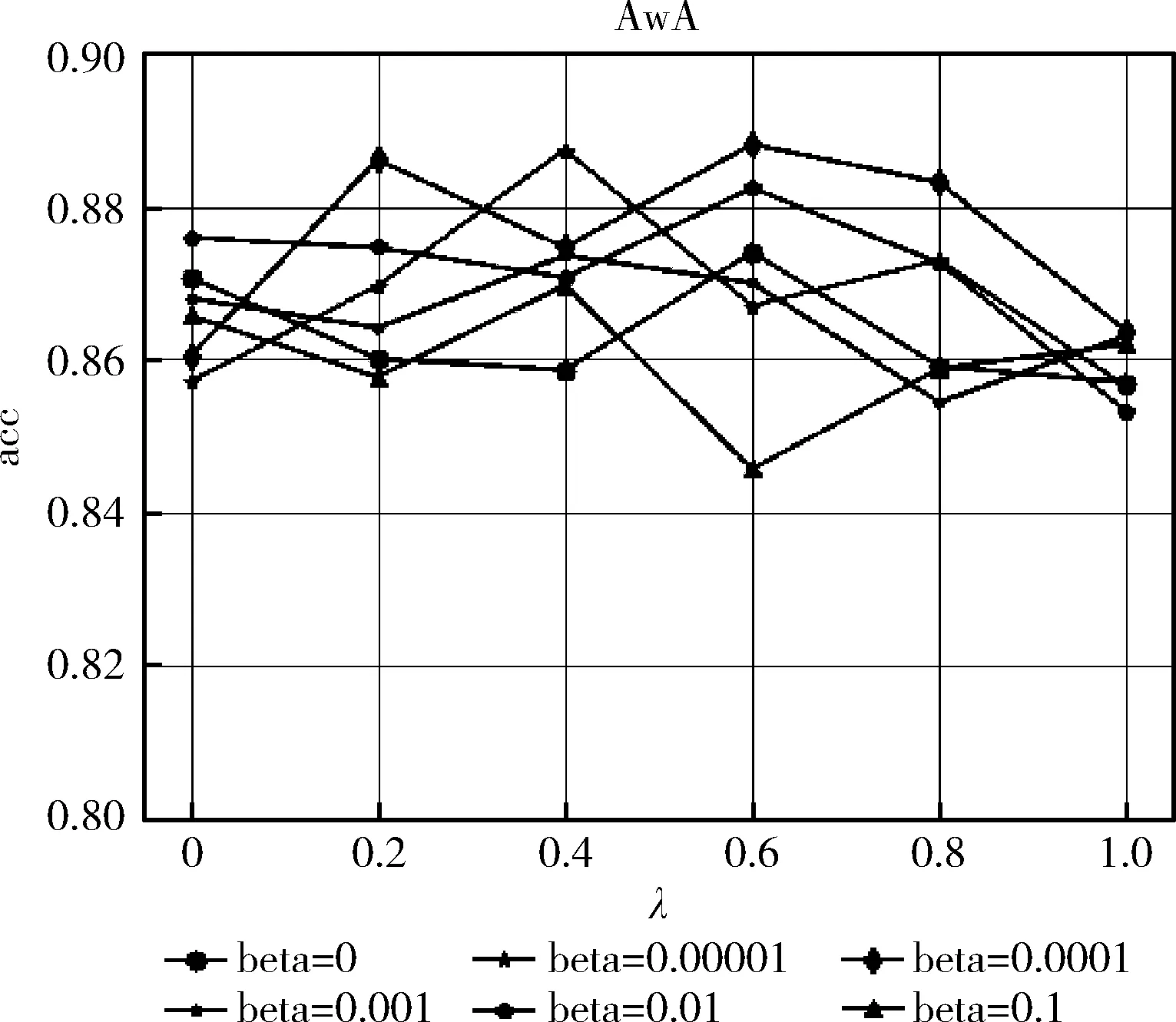
图5 RMSASC模型在AwA数据集的分类识别率

图6 RMSASC模型在CUB数据集的分类识别率
如图5所示,对于AwA数据集,当λ等于0时,只存在重构约束的情况下,仍然可以得到比RM模型较高的分类识别率。当λ不等于0时,可以看到beta等于0.000 01、0.0001时,RMSASC模型的分类识别率具有明显的提升,比RM模型的分类识别率高1.73%,比RMSA模型分类识别率高1.4%。如图6所示,对于CUB数据集,当λ等于0时,只存在重构约束的情况下,仍然可以得到比RM模型较高的分类识别率。当λ不等于0时,可以看到beta等于0.000 01、0.0001时,RMSASC模型的分类识别率也有一定的提升,比RM模型的分类识别率高0.88%,比RMSA模型分类识别率高0.61%。根据结果,表明了基于语义重构的约束,帮助重构语义空间语义特征,可以提高模型的泛化能力,缓解了ZSL的域漂移,提高了分类识别率,验证了它的有效性。
4 结束语
本文联合枢纽问题和域漂移问题,提出了一种基于语义对齐和语义重构约束的零样本学习算法。本文采用语义空间回归映射到图像空间来避免映射到其它空间加剧枢纽问题。针对反向映射现象存在的不足:映射后的语义特征比图像特征方差小,易于汇聚到处于原点附近。加入语义对齐的正则化约束,有利于语义空间类级别的语义原型特征和图像特征原型点的对齐,进一步缓解了枢纽问题,提高了最近邻算法的预测正确率。同时提出加入语义重构的正则化约束,重构语义特征信息,使得模型更具有泛化性和鲁棒性,缓解了域漂移问题。实验结果表明,在基本模型的基础上所加入的约束对于AwA和CUB数据集测试类样本的识别率具有较明显的提升,验证了所提算法的有效性。
