改进编码-解码框架下的跨站脚本检测
2021-01-20程琪芩
程琪芩,万 良+
(1.贵州大学 计算机科学与技术学院,贵州 贵阳 550025;2.贵州大学 计算机软件与理论研究所,贵州 贵阳 550025)
0 引 言
跨站脚本(cross-site script,XSS)攻击最早出现在20世纪90年代的万维网上,是一种攻击者将恶意脚本注入web网页的注入攻击[1]。黑客利用XSS漏洞盗取用户Cookie,从而得到用户的身份权限,给用户带来不便甚至造成巨大损失[2]。因此,检测XSS攻击、提高web安全成为当今网络安全领域不懈的追求。传统的检测技术有模糊测试技术[3]、黑盒技术[4]、输入验证技术[5]等,后来又提出了基于机器学习[6-8]的检测技术。但是,随着XSS攻击形式越来越多变,攻击特征也更加难以捕捉,现有的检测方法性能有限[9]。为了更全面地获取XSS特征,加快模型的收敛速度,提高检测性能,本文将编码-解码(Encoder-Decoder)框架应用到XSS检测中,将XSS检测视为自然语言序列问题,由卷积神经网络(convolutional neural network,CNN)和双向门控循环单元(bidirectional gated recurrent unit,BiGRU)并行组成Encoder,并运用注意力机制解决该框架的“分心问题”。实验验证,应用注意力机制改进Encoder-Decoder框架下的XSS检测模型具有良好的性能,且相对于串行结构,并行结构的CNN和BiGRU具有更好的特征提取能力。
1 相关工作
传统机器学习方法的人工提取特征具有主观性强、工作量大、特征提取不够充分等问题,而具备自动学习能力的深度学习能很好的解决这个问题,一些专家学者将其应用到XSS检测中,并提出了不同的检测方法。Guichang Z等[10]提出了一种命名为CNNPayl的XSS攻击检测方法,该方法先利用高斯混合模型和代码混淆策略得到攻击数据集,再构建多层CNN模型学习和提取攻击特征,得到了较高检测率和较低假阳性的检测效果,但是该方法忽略了XSS上下文的语义信息。Fang Y等[11]提出了一种命名为DeepXSS的XSS检测方法,该方法运用长短时记忆网络(long-short term memory,LSTM)检测XSS,并取得了较好的预测效果。Wu F等[12]提出了一种结合CNN和LSTM的CNN-LSTM检测模型,该方法验证了组合神经网络的效果优于单一网络。
在上述文献研究的基础上,本文构建了一种应用注意力机制改进Encoder-Decoder框架下的跨站脚本检测模型。Encoder-Decoder[13]是深度学习中一个非常常见的模型框架,常用于图像识别和机器翻译等领域,采用CNN、循环神经网络(recurrent neural network,RNN)、LSTM等网络自由搭配,解决多个领域的问题。CNN[14]是一种前馈神经网络,常用于图像处理、自然语言处理等。CNN通过若干次卷积、池化,不断提取和压缩特征,最终学习到高层次特征。门控循环单元网络[15](gated recurrent unit,GRU)为LSTM的一个变种,它将LSTM的遗忘门和输入门合成为重置门,用于捕获序列问题中的短期依赖,并设置了更新门,用于捕获序列问题中的长期依赖。GRU结构比LSTM简单,参数更少,训练收敛速度更快。借鉴双向循环神经网络(bidirectional recurrent neural network,BiRNN)双向处理序列的特点,选择BiGRU学习XSS上下文信息。本文组合这两种神经网络,取其优势,进行XSS检测。模型中Encoder采用CNN和BiGRU并行结构的方式,让CNN去逐层学习XSS的更高层次特征,让BiGRU去学习XSS序列间的信息依赖和上下文信息,结合两者学习到的特征,完成编码,再利用注意力机制选择关注编码后的特征中与XSS显著相关的重要特征,从而更好实现分类。
2 检测模型
为了有效检测XSS、提高web网页安全,本文提出了一种应用注意力机制改进Encoder-Decoder框架下的跨站脚本检测模型,模型结构自下而上如图1所示,采用序列问题中常用的Encoder-Decoder框架,并运用注意力机制提取Encoder序列中与输出显著相关的信息。模型主要分为4个阶段:Encoder阶段、注意力机制阶段、Decoder阶段、分类预测。实验中,样例数据经过数据预处理后,已经为50×128维词向量矩阵word embedding,因此模型不再需要使用embedding层,直接使用input层实例化神经网络的输入,再进行后面的操作。

图1 模型结构
2.1 Encoder
在深度学习中,常用Encoder将输入序列编码形成中间表示形式。本文将CNN和BiGRU并行作为Encoder,结合CNN学习到的22×128维特征和BiGRU学习到的50×128维特征,作为编码后的72×128维中间表示特征。
2.1.1 CNN
一维卷积(Convolution1D,Conv1D)是一维卷积操作,常用于自然语言处理,它的输入为三维数据向量,本文选择其作为模型的卷积层。最大池化(max-pooling)能减少卷积层参数造成的估计均值误差,本文选择其作为模型的池化层。
模型的CNN阶段包含两个Conv1D层和一个max-pooling层。两个Conv1D层选择了128个卷积核为4×4的卷积操作(如式(1)所示),然后使用非线性激活函数对卷积操作的输出结果做一次非线性映射,增强模型的非线性表达能力
(1)

常用的非线性激活函数中,relu函数(如式(2)所示)迭代速度较快,因此本文选择其为卷积层的激活函数

(2)
经过第一层卷积操作和非线性映射后,得到了一个特征映射,再将其作为第二个卷积层的输入,经过第二个卷积操作和非线性映射后,得到该层的特征映射。经过两层卷积后,将特征输入到池化层进行池化操作,对经过非线性映射的特征进行采样处理。max-pooling层选择值为2的池化步长,对特征映射取最大值,提取最有效的特征信息,降低特征维度。
CNN阶段通过逐层卷积或者池化,学习高层次的特征,作为Encoder编码结果的一部分。CNN学习过程如下:
步骤1 初始化卷积层的卷积核大小、卷积核数量,初始化池化层的池化步长;
步骤2 将每条样例数据x输入第一个卷积层;
步骤3 对其进行卷积操作,再经过非线性激活函数relu(x)进行非线性映射,输出47×128维的特征映射x1;
步骤4 将步骤3卷积出来的特征映射x1输入第二个卷积层;
步骤5 以相同的方式进行卷积和非线性映射,输出44×128维的特征映射x2;
步骤6 将步骤5输出的特征映射x2输入池化层;
步骤7 池化下采样,输出CNN训练得到的22×128维特征。
2.1.2 BiGRU

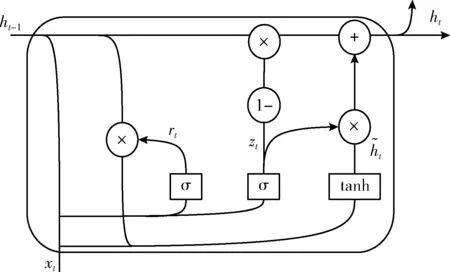
图2 GRU结构
重置门rt和更新门zt均以Sigmoid函数作为激活函数,zt计算前一状态传递到当前状态的信息量,如式(3)所示,其中wz为更新门zt的权值矩阵,bz为zt的偏置向量,σ(x)为Sigmoid激活函数。zt值越大,前一状态传递到当前状态的信息越多。和LSTM必须考虑上一状态对当前状态的影响不同,GRU通过重置门选择是否保留上一状态的隐藏输出,若zt为0,则丢弃上一状态的隐藏输出,若为1,则保留上一状态的隐藏输出
zt=σ(wz·[ht-1,xt]+bz)
(3)

rt=σ(wr·[ht-1,xt]+br)
(4)
(5)
(6)
BiGRU阶段通过前向GRU层学习上文与下文的关系信息,通过反向GRU层学习下文对上文的关系信息,最后得到XSS的上下文信息特征,作为Encoder编码结果的一部分。BiGRU学习过程如下:

步骤2 将每个样例数据x输入BiGRU的前向层;


步骤5 将每个样例数据x输入BiGRU的反向层;



2.2 注意力机制
本文引入注意力机制[16]来学习抽取特征中与XSS相关性高的信息,提高模型的检测性能,加快模型的收敛速度。注意力机制主要是借鉴人类的视觉系统,让模型忽略与XSS相关性不高甚至没有关系的部分特征,选择关注与XSS密切相关的部分特征,从而进行更高效的学习。本文将CNN和BiGRU同时作为注意力模型的编码器,以GRU作为解码器,经过编码器编码以后,计算每个输入对于当前输出的注意力矩阵,再利用解码器解码,得到分类结果。注意力机制的结构如图3所示。

图3 注意力机制结构
其中xi(1≤i≤n) 表示输入向量,hi(1≤i≤n) 表示经过CNN阶段和BiGRU阶段编码得到的隐藏输出,Hi(1≤i≤m) 表示经过GRU解码得到的隐藏输出。 F(Ht-1,h1∶t) 计算输入数据h1∶t对当前输出Yt的注意力分布情况(如式(7)所示),然后应用softmax函数将其转换为对应的注意力分配权值(如式(8)所示),再与输入加权求和(如式(9)所示),就得到了注意力矩阵,突显出与当前输出密切相关的特征。将注意力矩阵作为解码器的部分输入,从而得到当前隐藏输出
etj=relu(tanh(wF·[Ht-1,hj]+bF))
(7)
其中,wF为注意力机制权值矩阵,bF为偏置向量,relu(x)和tanh(x)均为激活函数,etj表示第j个输入hj对第t个输出Yt的注意力分布情况
atj=softmax(etj)
(8)
其中,atj表示第j个输入对第t个输出的注意力权重,softmax(x)表示激活函数,使atj∈(0,1),atj趋近于0表示相关性不高,趋近1表示相关性高
(9)
其中,ct表示输入对第t个输出的注意力矩阵,将每个输入和其与当前输出的注意力权重以点乘的方式进行计算,完成对输入序列的不同局部赋予不同的权重,得到其重要性分布。
注意力机制阶段通过计算输入数据中对每个输出的注意力特征向量,使模型只关注与XSS显著相关的部分信息。注意力机制学习过程如下:
步骤1 初始化注意力机制各层的神经元个数、权值、偏置等;
步骤2 将编码后的72×128维中间表示特征输入注意力机制的隐藏层;
步骤3 将中间表示特征输入到激活函数为tanh(x)的隐藏层和激活函数为relu(x)的隐藏层对应神经元,计算获得目标输出Yi和每个输入特征对应的注意力分布情况;
步骤4 再将步骤2得到的注意力分布情况输入softmax层,归一化处理,输出注意力分配权重;
步骤5 最后经过Dot层,输出输入特征对应目标输出Yi的2×128维高相关性特征;
步骤6 重复步骤2到步骤5,直到计算出输入特征对应每个目标输出的高相关性特征。
2.3 Decoder和分类预测
在Encoder-Decoder框架中,Encoder对输入数据进行编码,得到中间语义表示向量,Decoder对中间语义表示向量和之前已经生成的历史信息来生成i时刻的解码输出。本文模型中,由于GRU具备记忆历史信息的功能,避免了RNN的梯度消失,选择其作为Decoder。Decoder学习过程如下:
步骤1 初始化GRU的权值、偏置、初始输出Y0;
步骤2 将经过注意力机制得到的每个高相关性特征输入Decoder,得到对应的128维解码输出。
在经过Encoder-Decoder框架学习后,得到了一组与XSS重要相关的特征,使用softmax分类器对其进行分类预测,得到模型预测的结果。
在训练模型时,根据预测结果和实际标签的误差反向传播,通过梯度下降算法对模型各层的权值和偏置进行更新,直至模型参数达到最优。
3 实 验
实验使用的计算机配置为:windows10操作系统、Intel(R) Core(TM)i7-9750H CPU @2.60 GHz 2.60 GHz、8 G 内存,实验环境为python3.5.2、Tensorflow1.12.0、Keras2.2.4。实验中,使用网络爬虫从网站上爬取数据样例,恶意样例来源于XSSed数据库,正常样例来源于DMOZ数据库,经过数据预处理后,最终得到了20 000个恶意样例和20 000个正常样例,将其按照7∶3的比例,运用交叉验证中的train_test_split函数随机选取构成训练集和测试集,数据集分布情况见表1。

表1 数据集分布
3.1 数据预处理
在自然语言处理中,数据以向量的形式作为神经网络的输入,同时XSS代码常常以编码混淆的方式降低代码的可读性,以此躲避检测,因此对样本数据进行预处理,转换为神经网络输入需要的向量形式。
(1)数值化
由于XSS代码常用URL编码、Unicode编码等方式降低代码的可读性,本文通过解码技术还原代码,如%3Cscript%3Ealert%28%27Xss%20By%20Atm0n3r%27%29%3C/script%3E还原为