基于遗传算法求解三维匹配的资源分配问题
2021-01-20鲁江丽蒋明均
龙 恳,鲁江丽,李 伟,蒋明均
(重庆邮电大学 通信与信息工程学院,重庆 400065)
0 引 言
为了提高系统频谱利用效率并增加用户接入量,非正交多址技术被纳入讨论[1];同时,为了提供更高的吞吐量和频谱效率,HUDN引起了广泛的研究兴趣[2]。
针对超密集异构网络和NOMA的研究主要集中在以下几个方面:用户关联、子信道分配、功率分配、用户功率分配等等。关于用户关联和子信道分配,现有研究都是基于匹配理论、博弈论、匈牙利算法、凸优化无限逼近[3]等进行分步求解。此外,将用户与基站的关联转化为二部图形式,使用匈牙利算法求得最优解[4],或者在匹配理论的基础上修改二部图的双边匹配权重,求得次优解[5],然而该情况并没有考虑同一子信道中传输用户的干扰,并且双边匹配权重并不能使得系统函数达到最优。针对复杂的关联情况,常采用融合算法进行求解[6-8],常见的基于分布式算法和遗传算法的基础上提出两种算法的混合迭代算法,基于蚁群的遗传算法和量子遗传算法等。算法、基于蚁群的遗传算法、量子遗传算法进行比较分析[10],但是此算法仅考虑了用户与基站匹配,并且可能因为种群多样性减少陷入局部最优。
众所周知,用户、基站和子信道的三维匹配问题属于NP-hard问题,人们处理多维匹配问题,都是通过将多维匹配分解为二维的匹配[11,12],但是这种分解方法是通过降低系统的准确度为代价。针对以上情况,本文提出一种智能遗传算法求解三维用户匹配问题,通过设计一种多维染色体映射关系,将用户与基站和子信道的关联问题转化为染色体进行遗传变异,从而得出最佳匹配。
1 网络模型与问题描述
1.1 网络模型
两层的超密集异构网络(HetNet)模型,如图1所示。A区域为宏基站(MBS)的有效覆盖范围,MBS内均匀分布着若干微基站(SCBSs)。设基站表示为k,k∈{1,2,…K}, 当k=1时表示为宏基站;在A区域内随机分布的若干用户表示为u,u∈{1,2,…U}; 用户与基站之间传输信息所使用的子载波表示为n,n∈{1,2,…N}。 设定MBS分配给微基站k的功率表示为Ptk, 微基站k通过子信道n分配给用户u的功率表示为Pk,n,u。
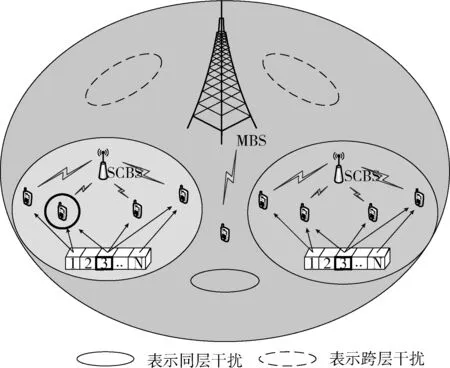
图1 超密集异构网络(HetNet)模型
因为频谱资源的有限性,现有的基站共享公用已有的频谱资源,假设已知完美的信道状态信息,采用非正交多址接入技术,在同一时刻,每个用户只能接入一个基站和一个子信道,而同一个基站可以同时发送多个用户的信息,同一个子载波也可以同时传输多个用户,并且子载波之间是相互正交,使得不同子载波上传输的用户互不干扰。
由系统模型和NOMA原理可知,假设基站k可以通过子信道n同时向与其相关联的用户发送叠加信号xk,n, 那么基站k的发射信号xk,n可以表示为
(1)
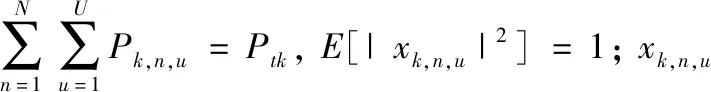
(2)

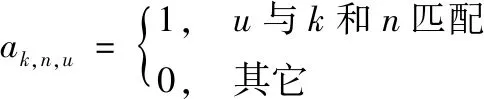
(3)
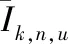
Ik,n,u=∑i∈{Sk,n|gk,n,i>gk,n,u}Pk,i,ngk,n,u
(4)
(5)

(6)
用户u的吞吐量为
(7)
那么系统的总容量为
(8)
由此可知,用户在同一个基站的同一个子信道中传输时,子信道n可以连接很多个用户,在同一信道中传输的用户会对用户u造成用户之间的干扰;另外,由于同一个用户u接入子信道n时,其它同层基站与宏基站也可能会使用同一个子信道n,这就使得同层的其它基站和宏基站对用户u产生干扰。所以用户关联对系统容量的影响很重要。
1.2 问题描述
如图2所示,用户关联问题可以建模为一个三维一对一匹配问题,即用户、基站和子信道如何分配。众所周知,三维匹配属于NP-hard问题。针对用户关联从而使得整体系统最优,可以等价为用户如何关联求取系统总容量最大。

图2 用户关联三维匹配模型
假设βk,u为用户u与基站k关联系数,γn,u为用户u与子信道n关联系数,因为都属于二元变量,可以定义为
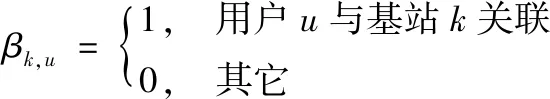
(9)

(10)

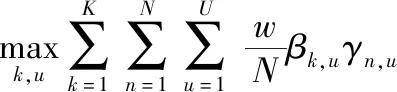
(11)
因为目标函数最终结果取决于系数βk,u和γn,u取值关系,那么目标函数可以改写为
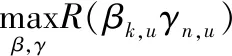
(12)
约束条件C1表示用户分配的功率满足基站总功率的约束;约束条件C2表示用户的吞吐量满足QoS的最低要求;约束条件C3表示用户关联取值范围,取值为1表示与基站关联,取值为0表示用户与基站不关联;约束条件C4表示用户关联基站,在同一个时间内,一个用户只能关联一个基站;约束条件C5表示用户与子信道关联取值范围,取值为1表示与子信道关联,取值为0表示用户与子信道不关联;约束条件C6表示用户关联子信道,在同一个时间内,每个用户只能关联1个子信道。
2 问题求解
2.1 基础知识
遗传算法就是仿照自然界生物进化的机制,通过染色体不断地遗传和变异,使用“适者生存”不断淘汰劣势群体,从而使得种群不断进化,达到全局最优的一种智能算法。由于遗传算法的本质就是通过并行处理染色体,不断地遗传变异,属于一种高效快速的全局搜索算法,所以相比较于其它算法,遗传算法不用考虑其内部协同关系,仅依靠一个统一的评价标准(即适应度函数)就可以否定劣势群体,具有很强的灵活性和搜索速度,快速趋于稳定状态。
2.2 算法设计
2.2.1 初始化参数
(1)初始化基础参数
给定各项参数,用户u的个数、子信道n的个数、基站k的个数、用户的信道增益矩阵g、 基站功率Ptk等参数。定义矩阵A为用户i在基站k和子信道n的有效覆盖范围,矩阵A中的元素aij, 若aij=1表示用户i在基站k或者子信道n的有效覆盖范围,否则用户i不在有效覆盖范围内。令矩阵A=[A1⋮A2], 其中矩阵A1为用户i与基站k的映射情况,矩阵A2为用户i与子信道n的映射情况。
(2)初始化种群参数
初始化种群为M, 第i个种群在三维搜索空间中的位置向量xi=(xi1,xi2),i=1,2,…M, 种群的个体极值为Pi=(Pi1,Pi2…,PiM), 整个粒子群的全局极值Pg, 交叉概率Pc、 变异概率Pm, 最大迭代次数Tmax等参数。定义匹配矩阵B=[B1⋮B2], 其中,矩阵B1为用户i与基站k的真实映射,矩阵B2为用户i与子信道n的真实映射。假设有6个用户,1个宏基站,3个小基站,4个子信道,那么可得出矩阵B, 用户在基站和子信道的映射关系如图3所示。

图3 用户在基站和子信道的映射
2.2.2 编码与解码
(1)点乘矩阵
因为用户在宏基站内是随机生成的,而宏基站和微基站是有一定的有效覆盖范围的,为了保证初始化矩阵生成的匹配在有效覆盖范围内,设定矩阵C=A·*B, 矩阵C中的元素cij为矩阵A和矩阵B中对应元素相乘而得,只有两个矩阵同时为1,那么cij=1, 即cij=aij*bij。
(2)编码与解码过程
解决方案对应于染色体,染色体为每个用户分别与基站和子信道不同关联方式下的资源分配的编码表示。因为用户与基站和子信道关联属于三维匹配,取矩阵LA为用户与基站不同关联方式下的染色体序列, 矩阵LB为用户与子信道不同关联方式下的染色体序列。为了计算染色体的适应度,需要将染色体映射到资源分配矩阵之中,所以将LA的染色体序列映射到矩阵E中;将矩阵LB的染色体序列映射到矩阵F中;进而得出用户分别与基站和子信道不同关联情况。如图4所示用户分别与基站和子信道不同关联情况下映射的资源分配染色。

图4 染色体映射到资源分配矩阵模型
2.2.3 适应度函数
适应度函数是指在种群的遗传变异产生的后代种群中,会由于“适者生存”而舍弃一部分后代个体,而这个“合适”的标准就是用适应度函数进行衡量的。适应度函数作为衡量一个个体是否适应自然界的一个量化指标,其数值的大小直接决定了个体的生存状态的好坏,一般情况下,适应程度越高,解决方案质量越好,选择个体的概率越大。因此,适应度函数的选取非常重要,它直接影响遗传算法的收敛速度和最优解的建立概率。此外,因为优化目标函数属于非线性有约束条件的,惩罚函数的思想是将约束优化问题转化为无约束优化问题,可以使用在目标函数中添加(或减去)一定的值来实现,所以本文需要引入惩罚函数φ(h)将含有约束条件的目标函数转化为无约束优化问题进行求解
(13)
其中,μk为足够大的惩罚因子。定义Fmax=max{φ(h)|h=1,2,…}, 那么适应度函数可以变化为
F(h)=Fmax-φ(h)
(14)
2.2.4 遗传算子
遗传算法是一种模拟生物种群DNA遗传变异的算法。通过随机生成的种群个体组成染色体开始遗传变异,根据种群的适应度函数的变化选择种群后代,从而不断地选择出优异子代,淘汰劣势个体。一般情况下,遗传算法的流程包括4个步骤:随机产生种群、选择、交叉和变异。
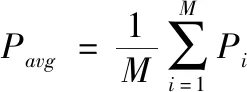
2.2.5 判断算法是否收敛
是否满足最大迭代时间Tmax, 若迭代时间大于Tmax, 则算法终止,否则继续迭代。此外,用户的平均适应度函数是否趋于稳定状态,在一段时间内平均适应度函数稳定,则算法收敛。
总之,用户在多维空间中,通过不断地遗传变异,挑选出系统容量最大的匹配组合。但是可能会由于遗传变异的局限性使得系统容量稳定在局部最优解,此时需要在选择子代匹配时将随机选择和确定性选择相结合,既能确保遗传变异的优者生存法则,又能防止系统匹配陷入局部最优解。
3 仿真分析
本文研究场景是在超密集异构网络下,一个宏基站的有效覆盖区域A内均匀分布k-1个微基站和随机分布若干个用户。具体的仿真参数见表1。

表1 系统仿真参数
图5在子信道的数目为10,基站的数目为6,用户数为30的条件下,迭代次数对系统容量的变化。采用改进的遗传算法求解用户与基站和子信道关联的迭代过程图。从图中可以看出,随着迭代次数的不断增加,系统总容量不断增加,但是在迭代一定次数的时候,出现了由于种群多样性减少而陷入局部最优解,此时利用算法的随机性和确定性精英个体的选择机制,可以跳出局部最优,从而达到全局最优解的收敛情况。

图5 迭代次数对系统容量变化的影响
图6给出了在子信道n的数目为10个、基站k的数目为6个的条件下,用户数目的变化对系统容量的变化情况。随着小区覆盖范围内用户数量的不同,系统容量也是不断变化的,从图中可以看出,随着用户数量的不断增加,系统总容量不断增加,但是在迭代一定次数的时候,传统的遗传算法由于自身因素的限制,会出现逐渐下降的趋势,这是因为传统遗传算法的种群必须有一定的范围,随着用户数量的不断增加,种群数量也在增加,当种群数量超出一定范围就不再适用此方法了;贪婪算法类似于穷举,其解接近于最优,但是复杂度很高。

图6 用户数量的变化对系统容量的影响
图7给出了在用户u的数目为30个、子信道n的数目为6个的条件下,基站数目的变化对系统容量的影响。图7(a)使用传统GA算法的效果明显低于其它算法,而OMA中没有区分子信道使得在同一个带宽中传输的用户数量增多,增大了用户间的干扰。图7(b)为本文提出的算法、贪婪算法和匹配算法之间的对比,从中可以看出,本文提出的算法在最优取值上三者都很接近,但是复杂度上明显低于贪婪算法。

图7 不同基站数量的变化对系统容量的影响
图8给出了在用户u的数目为30个、基站k的数目为6个的条件下,子信道的变化对系统容量的影响。从图中可以看出,子信道数量的增加,小区间和小区内的干扰不断减小,使得系统总容量不断增加。本文提出的算法可以在降低复杂度的情况下使系统容量数值接近于贪婪算法,且明显优于凸优化取整算法,传统遗传算法会陷入局部最优,其最终结果类似于OMA。
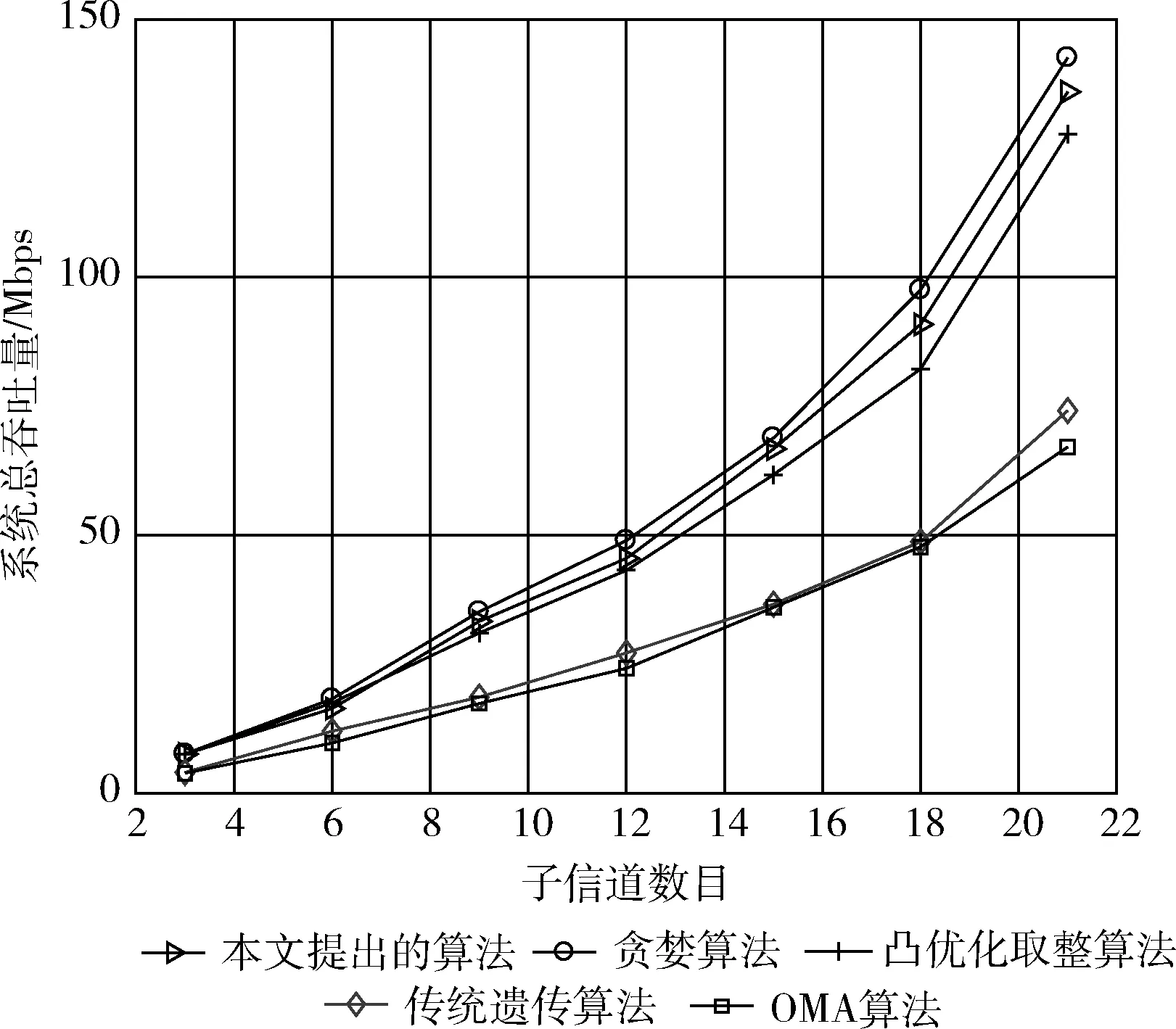
图8 子信道数量的变化对系统容量的影响
4 结束语
在超密集异构网络模型中,由于引入了NOMA技术,使得小区间和小区内的用户干扰减少,那么用户在基站的有效覆盖范围内,如何选择基站,以及用户选择在哪个频带中传输成为至关重要的问题之一。在此背景下,目前现有文献针对用户关联的三维匹配都是分解为二维匹配进行求解,本文通过使用一种改进遗传算法求解用户与基站和子信道的三维匹配问题,为了减少系统复杂度,设计一种多维映射过程,防止算法陷入局部最优,在种群多样性设计方面增加了随机性和确定性染色体的精英选择机制,从而求得全局最优。针对资源分配问题,用户与基站和子信道的关联影响着系统分配资源,但是在用户匹配之后,基站如何给覆盖范围内的用户分配合适的功率也影响着系统资源,所以针对用户功率分配问题将作为下一步的工作方向。
