基于故障检测上下文的等价变异体识别算法
2021-01-15王雅文宫云战
于 畅 王雅文 林 欢 宫云战
(网络与交换技术国家重点实验室(北京邮电大学) 北京 100876)(shuoxunyc@bupt.edu.cn)
变异测试(mutation testing)是一种基于故障的软件测试分析方法[1],它通过向被测软件注入一组人工故障,以模拟软件开发过程中引入的代码缺陷[2].这些故障被进一步用于评估测试充分性[3-5],并辅助测试人员开发测试用例以提高测试质量[6-8].相关研究[9-10]表明,相较结构化覆盖准则[11],该技术具有更强的检错能力.
在变异测试中,通过修改被测程序源代码的语法结构注入故障,被修改后的故障程序称为变异体,而代码修改规则称为变异算子.例如,关系运算符替换算子(relational operator replacement, ROR)对关系表达式x
尽管变异测试能为被测程序生成大量变异体,然而并非所有变异体对测试数据质量的提高都有帮助[12-13].Ammann等人[14-18]的研究表明:现有的变异测试工具会生成超过80%的无效变异体.这些无效变异体不仅会增加测试成本和执行时间,同时还会降低变异分析的有效性,降低测试质量.其中一类对变异测试影响较大的无效变异体是等价变异体[19].
等价变异体指的是与原程序保持语义等价的变异体程序[20].这类变异体无法被任何的测试输入杀死,既不能有效地模拟故障缺陷,也无法改进测试数据充分性.因此在测试前,需要将程序中的等价变异体识别并移除.图1展示了一个示例程序以说明变异体的等价性:mutant-1和mutant-2将运算符“<”替换为“≤”生成故障程序.其中mutant-1是非等价变异体:它会导致数组下标k越界从而造成程序异常退出.而mutant-2是等价变异体:该变异体总是输出数组的最小值,与原程序的输出完全一致,因而mutant-2无法被任意的测试用例杀死.

Fig. 1 Equivalent mutant and non-equivalent mutant
长期以来,等价变异体识别是研究领域和工业界所面临的一个主要难题.一方面,通过人工审查判断变异体的等价性平均需要6~15 min[21-23].另一方面,现有技术[24-32]无法有效识别等价变异体,存在2方面不足:
1) 准确度低.现有技术使用不完整的故障特征来推断变异体的等价性,导致识别技术产生大量的错分类样例[24-28].
2) 扩展性差.以往的研究方法依赖于人工设计的推理规则,这些规则只能识别少量的等价性模式,如不可达路径或数据流模式等.对于实践中复杂多样的等价性模式,这类技术的可扩展性将受到限制[33].
为了能提高识别的精准性和有效性,本文提出了基于故障检测上下文的等价变异体识别算法.该算法通过抽取变异体的故障检测上下文作为特征,并通过机器学习对复杂特征进行分析,从而实现等价变异体的自动分类和识别.故障检测上下文包含了与故障检测过程相关的程序切片.使用机器学习技术实现等价变异识别是基于3方面的考虑:
1) 等价变异体识别存在数据量大、故障特征复杂的问题.传统的逻辑推理技术对复杂故障的分析能力有限;而统计学习技术为复杂特征的大数据信息提供了有效的分析手段.
2) 统计学习的分类准确度会随着训练样本的增加而不断改进,从而增强了等价变异体识别的有效性和方法的扩展性.
3) 现有的机器学习研究提供了大量成熟的机器学习模型库,为本文快速和有效地实现等价变异体分类提供了技术上的保障.
我们将本文提出的方法应用于22个C程序的共计118 000个变异体进行评估.实验结果表明:
1) 在5-折交叉验证中,基于故障检测上下文的等价变异识别算法取得93%的预测准确率(accuracy).
2) 在跨工程间验证中,基于故障检测上下文的技术取得77%以上的分类精准度(precision)和78%的召回率(recall).
1 相关工作
长期以来,等价变异识别问题不仅是阻碍变异测试被工业界广泛应用的关键原因;同时也是变异测试领域的主要难题.造成该问题未被攻克的原因有:
1) 等价变异体数量巨大.根据Yao等人[30]的实验研究数据,等价变异体的数量占变异体总量的10%~15%.
2) 人工等价性检测耗时.Schuler等人[21]的研究报告指出,人工判断变异体等价性平均需要6~15 min.
3) 自动识别等价变异异常困难.研究者们已经证明,等价变异检测是不可解问题.这意味着对任一被测程序p和变异体m,不存在算法A能准确地判断m的等价性[20].
一方面,通过人工手段从大量样本中确认等价变异体是不切实际的;另一方面,由于等价变异体识别问题的不可判定性,使得到目前为止,尚不存在能有效检测等价变异体的技术工具.因此,在实践中,研究者们只能近似地解决该问题:要么为特定变异算子设计相对精准的等价变异体识别规则,要么设计一个面向通用故障类型的近似算法.前者可以取得较高的检测精度,但是可扩展性较差;而后者虽然适用于大部分实践中的被测软件,但是精准度较差.为了开发有效的等价变异体识别算法,Madeyski等人[19]为该算法提出了2方面的需求:
1) 精确性需求.要求通过算法A检测出的变异体均为等价变异体.令D为算法A识别的等价变异体集,E为实际的等价变异体集.精确性要求算法A具有高精确率P,其中P的定义为
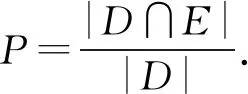
(1)
2) 可用性需求.要求被测程序的大部分等价变异体都被算法A检测出来.换言之,要求算法A具有高召回率R,其中R的定义为

(2)
Madeyski等人[19]对30年来等价变异体相关工作进行了系统性的分类和总结,将现有的等价变异体识别技术分为5组,分别是:
1) 基于编译优化的等价变异检测方法[27-28];
2) 基于程序约束的等价变异检测方法[24-26];
3) 基于程序影响的等价变异体选择方法[21-22];
4) 基于层次关系的等价变异体优化方法[15-16];
5) 基于变异算子的等价变异体选择方法[29-30].
其中,基于编译优化和程序约束的等价变异体检测算法通过形式化验证和程序证明技术,严格论证程序间的等价关系,具有较高的精准性.然而,由于形式验证通常依赖于人工设计的推理规则,使得这类方法通常适用于识别复杂度较低的等价变异体;对于复杂的等价性模式,该算法的召回率较低.
此外,基于程序影响和变异算子的等价变异体选择算法通过经验研究和统计分析等手段,从大量的样例中挖掘等价变异体的算子和程序影响模式.然而,现有技术依赖于人工特征建模,提取的特征相对单一,难以确保挖掘到的等价变异体特征是否适用于更复杂的被测程序,其精准度和泛用性受到限制[19].
表1总结了现有等价变异体识别算法的精确率、召回率及其存在的缺陷.可以发现,现有的等价变异检测技术无法同时取得较高的精确率和召回率.为了提高等价变异体识别的精准性和有效性,本文将提出基于故障检测上下文的等价变异体识别算法.
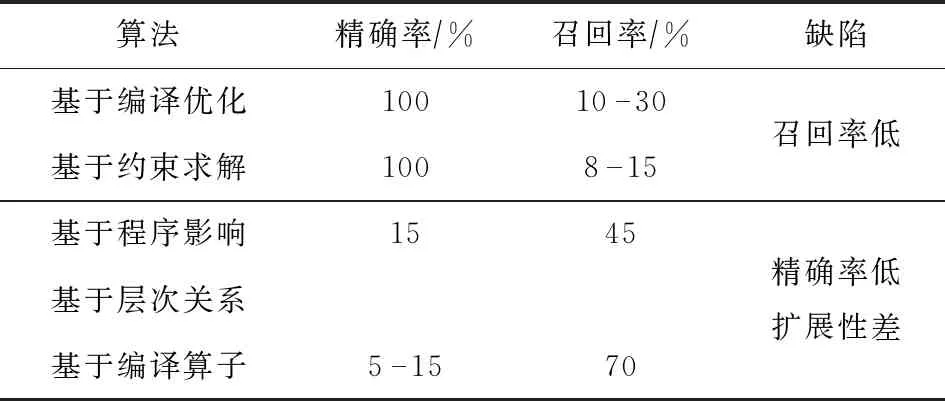
Table 1 Existing Equivalent Mutant Detection Algorithms
2 故障检测上下文
2.1 故障检测上下文与等价变异体
在软件测试中,故障检测条件描述了测试用例为杀死变异体需要满足的约束,包括[20]:
1) 覆盖约束.故障所在的语句被测试用例覆盖.
2) 触发约束.故障语句的执行触发运行时错误.
3) 传播约束.运行时错误传播并改变程序输出.
给定变异体m和被测程序p,令CR,CI,CP表示变异体m的覆盖、触发和传播约束,则变异体m的检测条件可以描述为
CR∧CI∧CP.
(3)
基于约束的等价变异体识别算法[25]通过验证该约束条件的可满足性来判断变异等价性.在实践中,为了提取故障检测条件,开发者需要通过静态分析工具,从源码中提取与检测条件相关的代码来推断变异体的等价性.本文将与检测条件相关的程序切片称为故障检测上下文(fault detection context, FDC).FDC为判断故障的可检测性提供了证据信息,是识别等价变异体的前提条件[26].
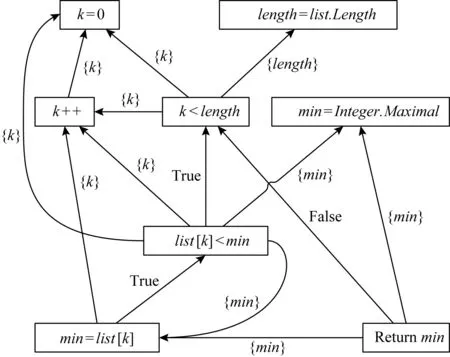
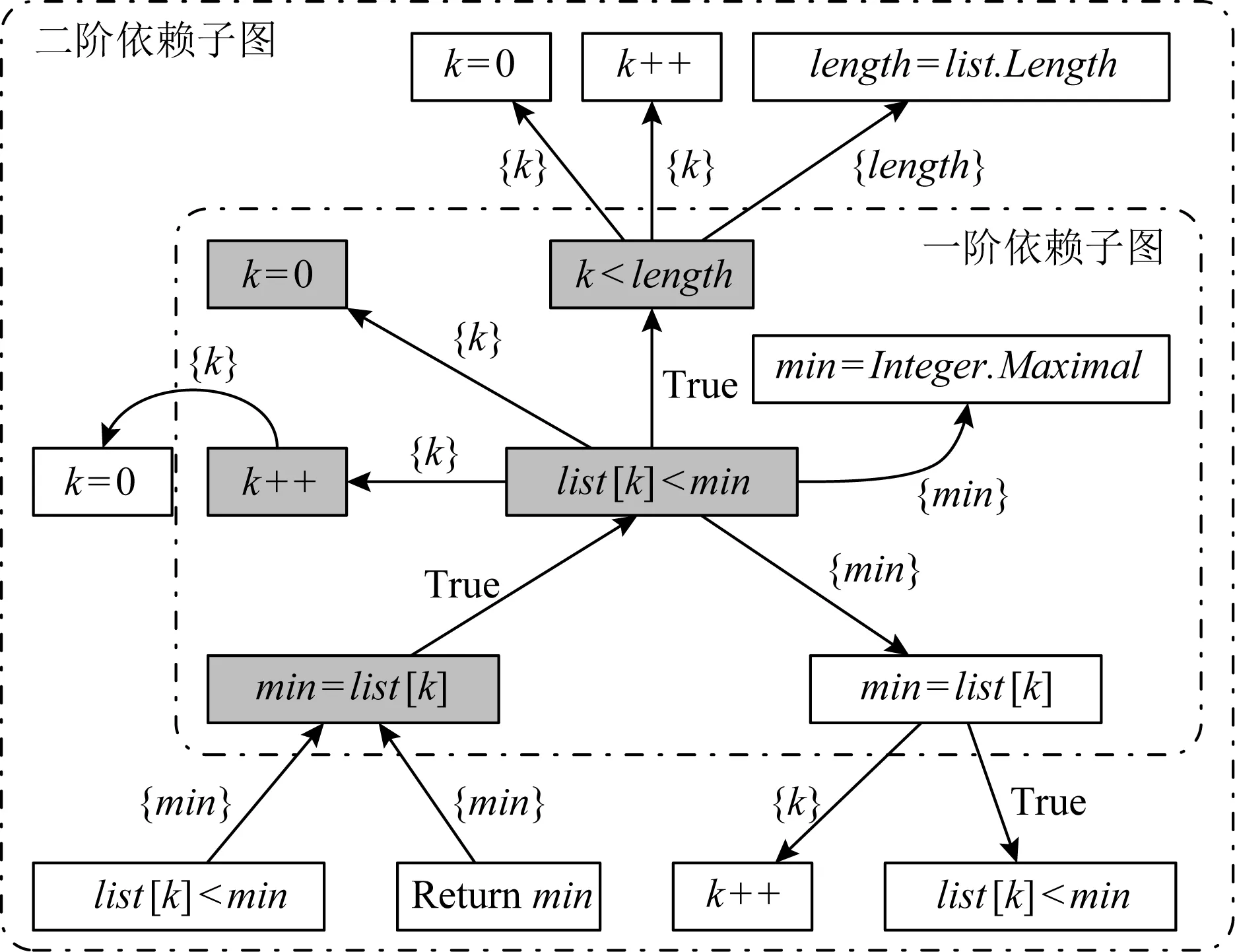
图2展示了图1中mutant-1和mutant-2的故障检测上下文.其中,mutant-1的检测上下文不包括语句min=Integer.Maximal和returnmin;而mutant-2的上下文移除了无关语句length=list.Length.

Fig. 2 Fault detection context for mutants
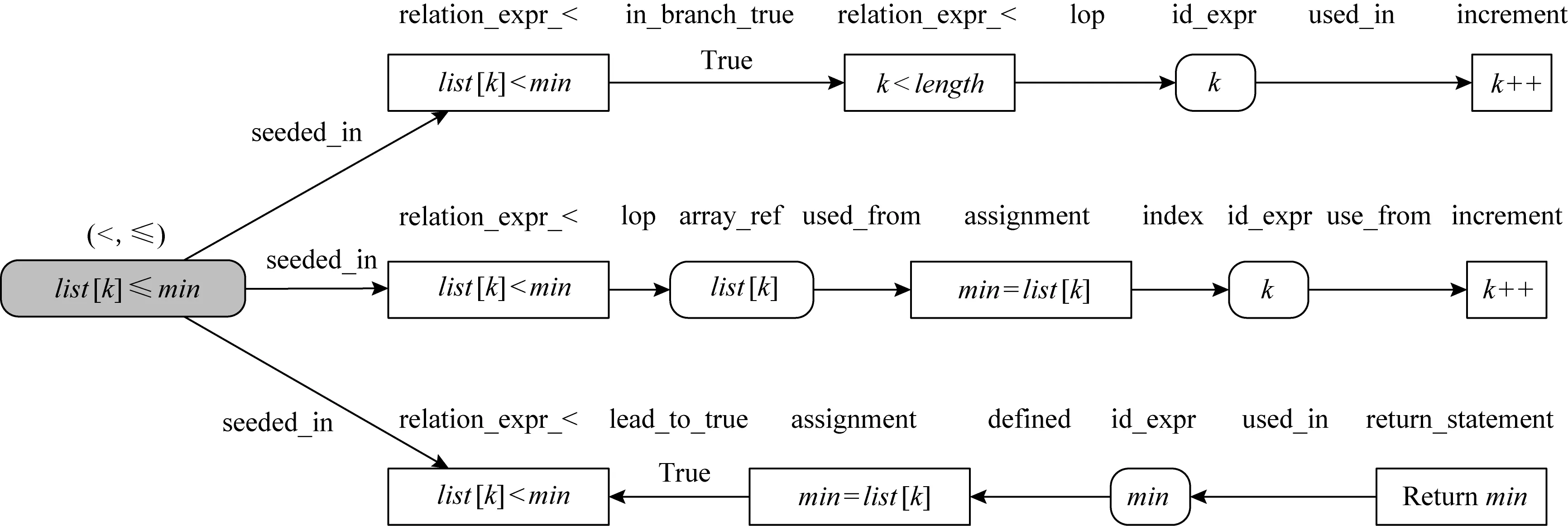
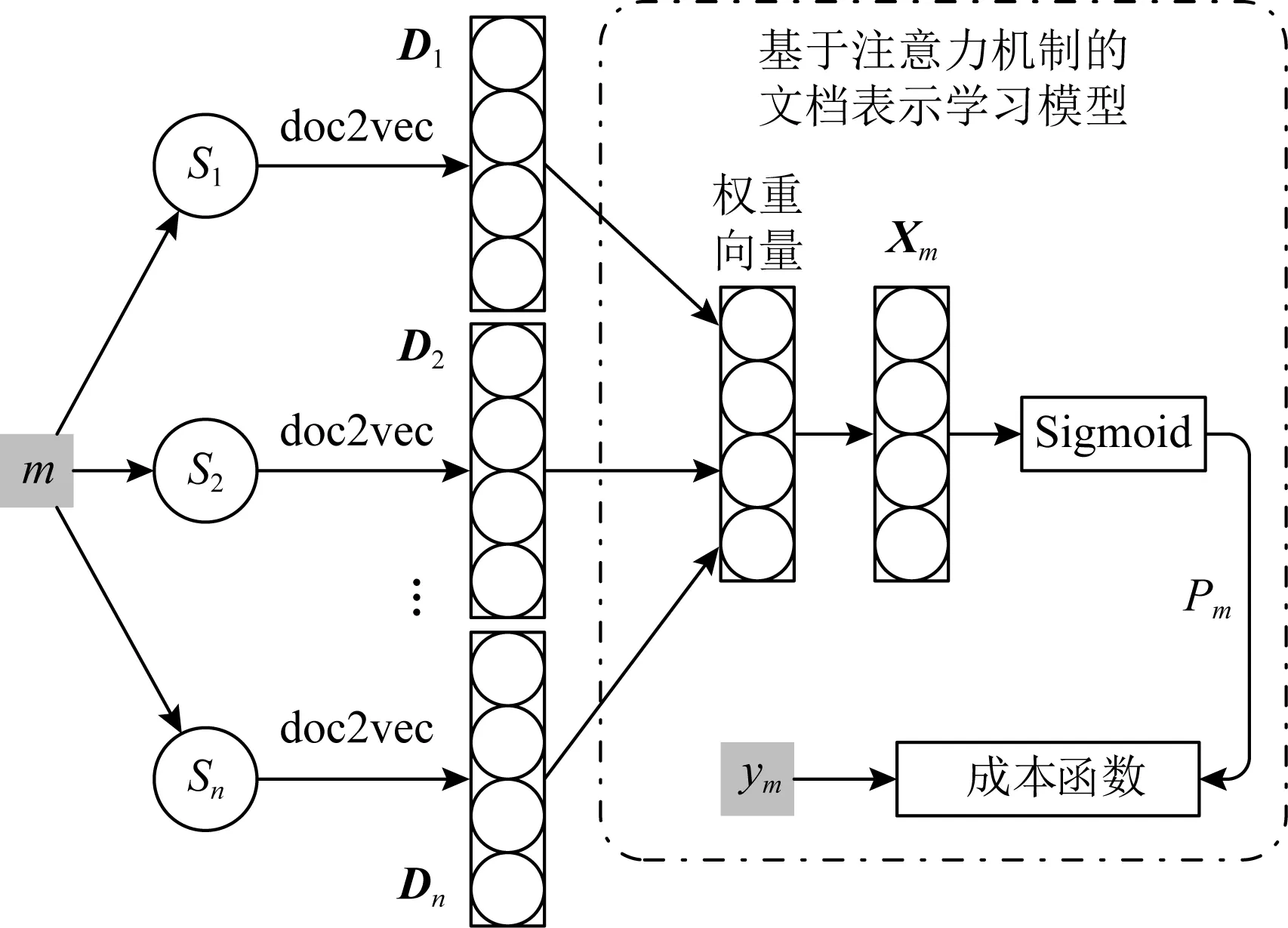
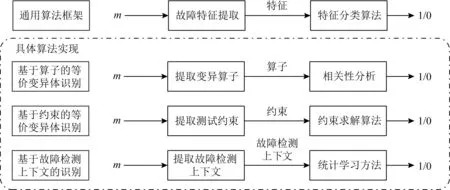
通过分析mutant-1的FDC中for语句k=0,k++可以证明,变异体k≤length必然在k==length时引发运行时错误,执行循环语句体;同时,通过分析循环体的list[k] 与此同时,通过分析mutant-2的FDC可以发现,当list[k]==min时,虽然故障条件list[k]≤min会错误地执行赋值语句min=list[k],但是该赋值对最终结果没有影响,故mutant-2是等价变异体. 在上面的分析中,故障检测上下文为推断变异体的等价性提供了证据信息.对任一等价变异体识别技术而言,一个重要的技术瓶颈是如何自动地抽取故障检测上下文,以提高识别准确率.本节将提供FDC的形式定义,以支持故障检测上下文的自动抽取. 故障检测上下文是故障注入点的依赖子图.下面回顾程序依赖图[34-36]的定义. 定义1.控制流程图.令p为被测程序,p的控制流图(control flow graph, CFG)是一个多元组,记作CFG=(p,N,E,entry,exit).其中,N为程序p的语句集,表示控制流图的节点;E为控制流图的有向边,满足(x,y)∈E当且仅当语句y可能在x后被执行;entry和exit分别是程序入口和出口节点. 定义2.控制支配关系.给定程序p的控制流图CFG,语句x被语句y后向支配,当且仅当所有从x到出口exit的路径都经过y,意味着y是x到程序出口的必经点. 定义3.控制依赖关系.令x和y是程序p的2条语句,定义y控制依赖于x,记作y→Cx,当且仅当:1)存在1条从x到y的路径,其中y后向支配路径上除x外的所有语句;2)x不被y后向支配.其中,控制依赖关系满足传递性,有 (x→Cy)∧(y→Cz)⟹(x→Cz). (4) 定义4.直接控制依赖关系.给定语句x和y,称y直接控制依赖于x,记作y→DCx,当且仅当y→Cx,且不存在其他语句z使y→Cz且z→Cx.在结构化程序中,直接控制依赖关系y→DCx意味着x往往是1个分支条件,而y是该条件的真分支或假分支上必经的某条语句. 定义5.数据依赖关系.令U(s)表示语句s中使用的变量集,D(t)表示语句t中被定义(或赋值)的变量集;定义直接数据依赖s→DD[x]t,使得存在x∈U(s)且x∈D(t),且存在1条从t到s的路径,使得该路径上没有其他语句对变量x进行再赋值.其中,直接数据依赖关系表示变量x在语句s中的使用值是在语句t中被定义的. 定义6.程序依赖图(program dependence graph, PDG).PDG是一个有向图G=(N,E),其中N为程序语句集,关系集E包括: 1) 控制依赖边(s,c,b),c为分支条件而b为布尔值,表示从c到s是真分支还是假分支; 2) 数据依赖边(s,t,x),其中s通过使用变量x直接数据依赖于t. 图3展示了图1中的案例程序的程序依赖图.其中,分支条件k Fig. 3 Program dependence graph 基于程序依赖图模型的概念,下面引入k阶依赖子图. 定义7.控制依赖子图.给定程序依赖图G以及语句s,定义语句s的k阶依赖子图(k≥0)是G的一个子图,记作Gs,k=(s,Ns,k,Es,k),其中Ns,k和Es,k表示子图的节点集和有向边集,它们满足 Ns,k={t|∃e∈Es,k,t∈e}, (5) Es,k={e|∃p∈Ps,k,e∈p}, (6) 其中Ps,k是依赖图G的一个简单路径子集,满足 (7) Fig. 4 First-order dependence subgraph example 在定义7中,ps,t是程序依赖图中一条从s到t的简单路径;该路径不包含重复的有向边.从定义7不难发现,路径集Ps,k包含了所有从s出发或者到达s的长度不大于k的简单路集.而k阶依赖子图包含依赖图中以s为中心、距离为k以内的节点和边.作为例子,考虑图4中list[k] 在图4中故障语句list[k] 从上述分析不难看出,k阶依赖子图能自动识别与检测条件相关的语句及依赖关系,因此本文将故障语句的k阶依赖子图定义为故障检测上下文. 定义8.故障检测上下文.令oprt为变异算子,s为变异体m的注入语句,m的故障检测上下文定义为二元组FDCm=(oprt,Gs,k),其中Gs,k是以s为中心的k阶依赖子图. Fig. 5 Second-order dependence graph example 在定义8中,非负整数k是一个由用户指定的超参数,关于k的选择将会影响FDCm的特征有效性.当k太小时,FDCm表示力不足;而k太大时,FDCm中将包含大量的依赖路径链,其中只有极少部分被用于等价变异体判定,导致FDCm包含了太多噪音信息,进而降低算法有效性. 图5通过图1中mutant-1的二阶依赖子图说明了这一问题.其中灰色节点为论证变异体的等价性提供了证据信息,其他无色节点为没有使用到的信息. 不难发现,大部分对等价变异体识别过程有帮助的语句和依赖关系与故障注入点的距离都比较近,都在一阶依赖子图范围内.为了降低特征表示的复杂度以及分析的有效性,在实验评估中本文限制k=2. 故障检测上下文特征为推断变异体等价性提供了充分的分析信息.因此理论上可以通过逻辑推理和形式验证技术,在FDC的基础上实现等价变异体检测.然而,逻辑推理技术强烈地依赖于人工设计的推导规则;这些规则通常只能通过简单的上下文模式识别等价变异体,对复杂模式,其可扩展性将受到限制. 为了能在故障检测上下文的基础上有效地识别等价变异,本文提出采用统计学习技术实现基于FDC的等价变异体识别算法.其理由为:首先,等价变异体存在数量大、特征复杂等问题,而统计学习技术为分析复杂特征的大数据信息提供了有效的分析手段;其次,统计学习的分类准确度会随着训练样本的增加而不断改进,增强了识别方法的可用性和扩展性;最后,现有的机器学习研究提供了大量成熟的机器学习模型库,为本文快速和有效地实现等价变异体分类提供了技术上的支持. 图6展现了该算法的流程图,包括训练样本标签化、故障特征提取、故障特性文档化、训练分类器以及变异体分类5个子过程. Fig. 6 FDC-based equivalent mutant detection flowchat 样本标签化过程通过人工辅助的软件测试手段,识别训练样本中的每一个变异体m是否为等价变异体,输出是一个带标签的二元组(m,y),其中y为布尔值,表示m是否为等价变异体. 故障特征提取过程通过程序依赖分析提取变异体依赖子图,作为变异体m故障检测上下文FDCm.接着,故障特征文档化过程将结构化的故障检测上下文转换为故障检测文档(fault detection document, FDD),该文档是一个以自然文本描述故障检测上下文的语句集,记作FDDm.该文档将结构化的程序分析问题转换为文本分类问题,并使用现成的统计学习模型进行分析,将变异体分类为等价或非等价. 接下来将解释故障检测文档的模型定义、故障检测上下文到故障检测文档的转换规则,以及统计学习技术如何使用故障文档模型识别等价变异体. 故障检测文档是由句子(sentence)构成的集合 FDDm={S1,S2,…,SD}, (8) 其中,每个句子Si是一个由单词(word)构成的不定长序列,用于描述k阶依赖子图中一条以故障注入点s为起点或终点的依赖关系链,表示为 Si=(wi,1,wi,2,…,wi,n-1,wi,n). (9) 在该定义中序列Si的一个单词wi,j表示依赖关系链上的一个节点或节点之间的关系.其中,节点单词描述节点的抽象语法树类型,而关系单词描述语句与语句、语句与变量的关系.表2列出了一部分节点和关系的对应描述单词. Table 2 Objects in FDD and Words for Describing 作为例子,考虑图5中的3条依赖关系路径,分别是list[k] 以第1条依赖路径为例,路径的起始点对应变异体,其单词(<,≤)表示变异算子;接着,变异节点连接到故障注入点list[k] Fig. 7 Fault detection document example 使用故障检测文档作为故障特征输入的原因有2方面: 首先,从机器学习模型的角度出发,序列化的文档模型适用于大部分现有的且成熟的机器学习模型.这类模型对数据量和样本输入的鲁棒性更强;而以结构化特征为输入的模型如神经网络,对输入数据量的要求则更高.从实用性的角度,直接以结构化的故障检测上下文作为特征未必能取得比故障检测文档更好的分类效果. 其次,从等价变异体识别角度考虑,结构化的故障上下文特征要求使用抽象的推理规则和形式验证技术,使得等价变异分类器的可扩展性受到限制.而通过将故障检测上下文转换为故障检测文档,等价变异体识别问题被转换为了相对简单的文本分类问题,而后者提供了相对简单的推理规则,确保模型的简易和泛用性. 大部分现有的机器学习模型,如贝叶斯网络、支持向量机、随机森林或多层感知器,都是以一个定长的实值向量作为特征输入;而在3.2节中引入的故障文档模型却包含了可变数量的语句和单词.为此,在训练分类器之前,需要将故障文档FDDm转换为一个定长的实数向量Xm.故障检测文档的特征编码分为3个阶段,分别是预处理、句编码和文档编码. 3.3.1 预处理 在预处理阶段,故障检测文档中表示节点和边的单词会被重组,以构成表示具有完整语义信息的关系组合词.具体而言,在一个依赖路径中,设nx和ny为相邻节点对应单词,ex,y连接从nx到ny的依赖关系的对应单词,则nx和ny的关系组合词为 wx,y=nx·ex,y·ny, (10) 其中‘·’表示字符串连接操作. 对于一个给定的语句,其词序列为(n1,e1,2,n2,e2,3,n3,…,er-1,r,nr).经过预处理后,该序列的单词组合为关系词组,有 Si=(w1,2,w2,3,…,wk,k+1,…,wr-1,r), (11) 其中wk,k+1=nk·ek,k+1·nk+1表示关系组合词. 将邻接节点组合起来的思想是基于这一观察:在依赖路径中,单独表示节点和边的单词无法描述“依赖关系”的语义.而邻接点的关系组合词能表示依赖链中一个最基本的连接关系语义,这将有效地提升特征编码的表达能力. 3.3.2 句编码 在故障检测文档中,一个语句描述了从故障注入点出发(或终止)的一条完整依赖链;其中每个单词表示依赖链中的一条依赖边.对于由一组特定顺序构成的依赖链,它往往描述了特殊的故障检测上下文结构.如图7中第3行的依赖链描述了变异体对程序的影响方式,首先通过对变量min赋值,然后通过返回语句影响外部输出. 显然,每个语句都表示某种特定的“主题”,如故障通过某种方式影响外部变量,或者通过某条特殊路径被覆盖.语句编码的目的是将这种主题语义从词序列中抽离出来,以向量的形式进行表示.这种向量被称为句向量(sentence vector)[37]. 在自然语言处理领域doc2vec[38]是一种自动抽取句向量的机器学习算法.该算法的基本思想是,在给定算法的部分单词的条件下,根据算法的主题语义向量,可以恢复出剩余空缺单词. 图8展示了doc2vec基于分布式存储(distributed memory)的实现.以图7中第3行语句为例,如果去除最后一个min到returnmin的依赖关系,使用doc2vec生成的句向量可以从其他依赖关系后恢复出该依赖关系,这意味着“通过返回语句影响程序”的语义信息已经被抽取到了该语句的句向量中.给定依赖路径的语句Si,doc2vec算法将输入语句Si转换为一个固定长度的句向量,记作Di. Fig. 8 Distributed memory model in doc2vec 3.3.3 文档编码 在句向量编码完成后,故障检测文档被转换为由一组句向量Di构成的集合,记作 FDDm={D1,D2,…,Dn}. (12) 在等价变异体分析中,并非所有的语句(依赖链)都被用于论证变异体的等价性.正如2.3节图5的案例所展示的那样,故障检测上下文中,一部分依赖关系起着关键,而另一些依赖关系则几乎毫无帮助.基于这一观察,可以假设变异体的特征向量是其检测文档中句向量的加权和,满足 (13) 其中,参数αi表示每个语句的权重,权重参数是非负实数,其总和为1.在等价变异体识别过程中,权重越大的语句表示故障检测上下文中对论证变异体等价性越关键的依赖路径;反之,权重越小的语句表示对论证等价性帮助越小的路径;权重等于0表示该依赖路径对在论证等价变异体中没有帮助. 本文采用了基于注意力机制的全连接网络,实现对文档向量的表示学习.图9展示了这种基于注意力机制的表示学习网络的整体框架[39-40]. Fig. 9 Attention-based document embedding networks 首先,故障检测文档的所有语句通过doc2vec算法映射到一组句向量,这组句向量大小是可变的.由于注意力权重向量通常是定长的(设为n),这里采用截断策略:令故障文档包含d个句子,如果d 接着,通过一个注意力权重网络注意力权重计算每个句向量的权重αi.其中,注意力网络定义了一个长度为n的注意力向量,记作β.对每个句向量Di其权重计算为 (14) 从式(14)不难看出,各个语句的权重总和为1. Fig. 10 Feature-based equivalent mutation detection 在完成了权重计算后,根据式(13)求出故障检测文档的特征向量Xm.最后Xm通过一个Sigmoid函数映射到概率Pm.这一概率表示变异体m为等价变异体的概率.概率Pm被进一步与变异体的类别label进行比较,并计算成本函数: (15) 其中,N表示训练样本总数,ym表示m的类别标签,ym=1表示m为等价变异体.式(15)计算N个样例中被正确分类的训练样本比例,对应于分类精确率.在获得成本函数值之后,根据神经网络的反向传递算法,进一步优化注意力权重和Sigmoid网络参数,进而得到最优的文档表示学习网络. 在获得了故障特征向量Xm后,这些故障特征被进一步用作一系列机器学习分类器的输入.在本文中,将会考虑贝叶斯、逻辑回归、决策树、随机森林、梯度上升、多层感知器等分类器以实现基于故障检测上下文的等价变异体识别技术. 基于特征的变异体分类算法为评估故障特征以及等价变异体识别算法的有效性提供了分析框架.令被测程序p的变异体集合为M.基于特征的等价变异体识别方法会为每个变异体m定义一个故障特征x,所有这些特征的集合称为特征空间F.定义F上的特征提取函数Φ:M→F,使得函数Φ(m)返回m在F中的特征点x. 给定变异体在F中的特征点x,引入特征分类函数Ψ:F→{0,1},该函数负责根据故障特征x判断其对应变异体是否为等价变异.Ψ(x)=1表示具有特征x的变异体为等价变异体. 通过组合特征提取函数Φ和等价分类函数Ψ,一个等价变异体识别算法可以通过下面的复合函数抽象表示出来: y=Ψ(Φ(m)), (16) 其中y为算法预测的变异体m的类别. 现有的等价变异体识别技术以及本文提出的基于故障检测上下文的识别算法都可以看作是基于特征的变异体分类算法的某种具体实现,如图10所示. 其中,基于选择变异的实现方案使用最单一的特征(变异算子)和最宽松的判定条件(相关性分析)判定等价变异体,极大地降低了分类的准确性.而基于约束求解的实现方法使用过度抽象和复杂的符号表示作为特征,增加了分类算法实现的难度,极大地限制了算法的适用范围,降低了召回率. 相比之下,本文提出的等价变异体识别算法以故障检测上下文为输入,确保了故障特征的复杂性和信息量.同时,通过统计学习技术,自动化构建等价变异分类器,简化了算法实现,提高了可扩展性. 在现实中,研究者们往往希望近似地推断变异体的等价性.这意味着对于给定的被测程序及其变异体样本集M,能最大化其在样本集上的识别准确度(accuracy).accuracy的定义为 (17) 其中,谓词equiv(m)表示m为等价变异体.给定特征空间F和特征提取函数Φ,定义一个最优等价判定函数Ψ*,使得复合函数Ψ*(Φ(m))在任意变异体构成的集合M上实现分类精确率的最大化,有 Ψ*:maxaccuracy. (18) 对一个大小有限的给定的变异体集M,可以证明,总存在一个可以实现最优等价判定函数Ψ*的算法.算法1给出其基本原理:令Mx为集合M中符合特征点x的变异体子集;当Mx中等价变异体个数大于或等于非等价变异体个数时,可以将特征点x映射到1;反之则将特征点x映射到0.算法1的基本思想是通过最小化集合Mx中的误分类样本数来最大化预测精确率.其中,Ex和Nx分别表示Mx中等价和非等价变异体构成的集合. 算法1.有限样本集上的最优等价分类算法. ① functiondetermine_euivalence(x): ②Mx={M中符合特征x的变异体}; ③Ex={Mx中的等价变异体}; ④Nx={Mx中的非等价变异体}; ⑤ if |Ex|≥|Nx|: ⑥ return true; ⑦ else ⑧ return false; ⑨ end if ⑩ end function 需要注意的是,算法1不是一个实用化的算法,它的目的是衡量故障特征F对等价变异体识别的有效性:在一组测试样本集M上,算法1的最优分类所取得的精确率是任一分类函数在样本集M上该特征所能取得的最大精确率. 一个好的特征空间应该保证对于任意的特征点x,其对应的变异体中大部分要么都是等价的,要么都是非等价的.这要求从特征点x到变异等价性的映射关系的随机性应该尽可能地小.在后面的分析中,还将用特征点的熵(混乱度)来评估x的好坏,有 H(x)=-pe×lb(pe)-(1-pe)×lb(pe), (19) 其中pe表示Mx中等价变异体所占比例.当pe=1或者pe=0时,有H(x)=0,此时特征点对应的所有变异样本都对应到等价或者非等价,也因此从x到等价性的映射关系是完全确定的.当pe=0.5时,H(x)=1且最大化;此时无法判断具有特征x的变异体是属于等价变异体还是非等价变异体. 为了验证本文提出的基于故障检测上下文的等价变异识别方法的有效性以及可用性,我们进行了一个实验研究.本文提出了3个研究问题来估计提出方法的有效性. Q1. 在等价变异体的识别问题中,故障检测上下文是否是好的故障特征表示. Q2. 哪一类机器学习模型更适用于基于故障检测上下文的等价变异程序的识别任务. Q3. 相比于现有技术,基于故障检测上下文的等价变异识别是否具有更好的精确率和泛用度. 本文使用了来自22个C程序、共计118 000个变异体样例作为训练样本,来构造适用于等价变异体识别任务的机器学习分类器.表3列出了实验中使用到的程序、代码复杂度以及变异体个数. 实验中我们使用C程序变异测试工具Proteum[41]实现对程序源代码的自动故障注入功能.为了避免生成过多的样本数、减少手工构造等价变异体的成本,本文去除了常量替换和变量替换类型的变异算子.根据以往的研究,这筛选策略能确保测试的有效性.为识别训练样本中每一个变异体的等价性,本文使用项目组开发的开源变异测试工具JCMuta①辅助等价变异体的人工识别工作.步骤如下: 1) 通过自动化工具生成分支覆盖测试用例集T; 2) 在变异体集M上执行测试集T,并将所有被T杀死的变异体标记为“非等价的”; 3) 对未被杀死的18 526个变异体,人工分析其是否为等价变异体. Table 3 Subject Programs, Test Cases and Mutants Number 为了简化人工分析的难度,本文通过JCMuta工具收集了每个变异体在测试过程中被测试用例覆盖和检测的程度.具体而言,JCMuta可以统计某条故障语句是否多少测试用例覆盖;如果没有测试用例覆盖故障语句,则提示用户该变异体等价的原因是因为语句不可达;类似地,通过分析程序中间变量的值是否发生变化,判断一个变异体等价的原因是无法触发状态错误,还是错误无法传播.基于上述分析,通过2个月的分析,识别了11 126个等价变异样例. 最后,通过使用原型工具JCMuta,我们为每一个变异体提取相应的2阶依赖子图和故障检测上下文,并根据等价变异体识别算法将其转换为故障检测文档和特征向量.在实验中,我们使用scikit-learn的编程库搭建机器学习分类器. 为了评估故障检测上下文特征的有效性,实验使用了故障检测上下文特征向量的信息熵,采用式(19)来估计特征的有效性.特征点的信息熵越大,说明基于该特征点对等价性判断的确定性越低. 图11展示了故障特征向量空间中每个特征点Xm的信息熵的密度分布函数.从图11可以发现,多达98%的特征向量对应的熵H(x)=0,意味着对于实验中使用的大部分故障上下文特征x到等价性的映射关系是完全确定的.除此之外,只有约0.7%特征点的信息熵较高,其H(x)>0.50. Fig. 11 Distribution of entropy of FCD feature points 表4进一步展示了,在故障检测上下文特征空间以及给定训练样本中,最优分类器(算法1)所能取得的精确率、等价类精确率和召回率等信息.其中,最优分类器能够取得97.5%的分类精确率,取得多于90%的精确率以及91%的召回率.此外,基于故障检测上下文的等价变异识别方法能取得远高于传统的等价变异识别算法的精确率和召回率(关于传统方法在等价变异识别问题中的精确率和召回率见表1). Table 4 Accuracy, Precision and Recall in Cross-Validation 表4展示了在训练样本交叉验证中,各种机器学习分类器在验证集(validation set)所取得的准确率(accuracy)、精确率(precision)、召回率(recall)信息.对最优分类器,我们采用Train-set=Test-set(在训练集上训练和验证)来验证特征空间有效性.而对其他机器学习模型,我们采用了2-折和5-折交叉验证技术去评估机器学习分类器的分类准确率、精确率、召回率. 从表4可以发现,基于故障检测上下文的最优分类器的精确率是97%,这是所有其他机器学习分类器在交叉验证中能够获得的最高分数.在实验中使用的学习模型中,决策树、随机森林、梯度上升、Bagging和多层感知器在交叉验证中取得了最佳分类效果.其中决策树能够获得92%的精确率以及83%的等价类精确率;分数最高的多层感知机取得了90%的识别精确率,并检测了超过82%的等价变异体. 此外,通过比较2-折和5-折交叉验证结果可以发现,虽然在2-折验证中,各个分类器的精准度和召回率都有所下降,但是这一下降并不明显,意味着本文提出的特征构造和编码方式使得学习模型对训练样本数鲁棒性相对较高,有较好的扩展性. 为了验证机器学习模型在训练集以外程序中进行等价变异识别任务的泛用性,本文采用了留一工程间验证(leave-one-project, LOP).非形式地,LOP验证每次以训练样本中的1个工程的变异体为测试集,而剩余其他程序的样本为训练集,进行学习和预测. 图12展示了多层感知机分类器在实验中使用的22个被测程序上的LOP验证的等价类精准度以及召回率信息.可以发现,对于某些被测的程序,如md5,prime_factor,print_tokens2,replace,space,flex,sed,分类器能取得超过90%的预测精确率;然而对另一些程序,如calendar,triangle,schedule2,gzip,多层感知器取得的精确率甚至低于50%.类似地,多层感知机在print_tokens,md4,quick_sort上的召回率在90%以上,在replace,triangle中召回率低于45%. Fig. 12 Leave-one-project validation results 造成学习模型在一部分被测程序的变异体样本作为测试集时性能下降的原因,是因为某些被测程序中存在其他程序中未曾出现过的特征模式,这使得学习模型无法根据其他程序的经验,对具有未曾遇到过的故障特征的变异体进行有效分类. 表5给出了实验中使用的5个机器学习模型在LOP验证中取得的平均精确率(precision)和平均召回率(recall).其中,多层感知机的平均精确率和召回率远高于其他模型.这也意味着通过注意力网络生成的文档表示特征更适合通过多层全连通网络预测等价性. Table 5 Leave-One-Project Average Precision and Recall 首先,本文对变异体的故障检测上下文的文档模型并未保证从特征空间到变异等价性的映射是完全确定性的.图13以calendar程序的被测代码为例,这段代码将日历信息存储到字符串缓存buffer中. Fig. 13 Example of mutant being incorrectly classified 在该例子中,条件语句真假分支的语句输出是等价的.而判断该变异体的等价性依赖于对sprintf格式化参数的理解,本文提出的故障检测上下文特征并不能有效表示这类与功能相关的代码模式特征. 其次,本文使用机器学习技术来构建从故障上下文特征到变异体等价性之间的映射关系.然而该映射的精确性和泛用性依赖于使用数据的代表性和广泛性.在实验中本文仅收集了22组被测程序的变异体作为训练数据集,其泛用性仍有待强化. 最后,通过机器学习技术检测等价变异体要求用户首先提供一组等价变异体的训练样例.这意味着在该方法投入实践之前,手工或者半自动的等价变异体检测仍然是必要的.这一定程度又限制了该方法的迅速普及和使用. 长期以来,等价变异识别问题一直是阻碍变异测试方法在产业界普及的关键障碍[42].现有的等价变异体识别算法难以同时在精确率和召回率方面取得较好的检测效果. 为了解决这一问题,本文提出了基于故障检测上下文的等价变异识别方法.该方法定义变异体的故障检测上下文作为特征,通过转换为文档模型,使得该问题转变成文档分类问题;最后,通过基于注意力机制的表示学习模型,生成故障检测上下文的文档特征向量,并以该向量为输入,训练机器学习模型,以实现对变异体等价性的自动识别. 在实验分析中,本文提出的方法在22个被测程序的118 000个变异体上取得了超过94%的预测精确率.其中在5-折交叉验证中,多层感知机取得了91%的精确率(precision)和85%的召回率(recall),意味着该方法检测出来的变异体超90%为等价变异体,且样本中约80%的等价变异体被检测.在工程间验证中,机器学习技术取得77%的预测精准度和78%的召回率,验证了本文提出方法的泛用性.本文的其他贡献包括: 1) 提出了用于进行等价变异体检测的故障检测上下文特征模型以及提取该特征的程序分析原型工具JCMuta. 2) 通过实验分析,验证了基于故障检测上下文的等价变异识别技术的有效性,并指出深度学习框架是相对适合实现本文提出方法的一种学习技术. 在未来的工作中,我们将基于故障检测上下文特征和机器学习模型识别等价变异体可能的故障上下文模式,并通过挖掘这些模式,为测试和开发人员更好地检测等价变异体提供建议.2.2 故障检测上下文与程序依赖图

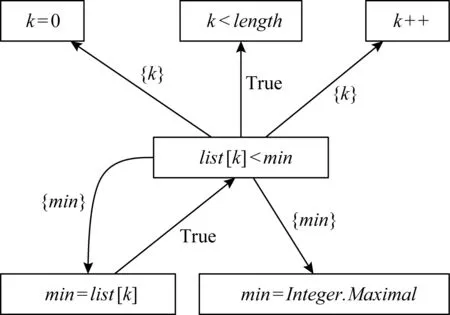
2.3 故障检测上下文与依赖链长度
3 等价变异体识别算法
3.1 算法流程

3.2 故障检测文档

3.3 故障特征编码

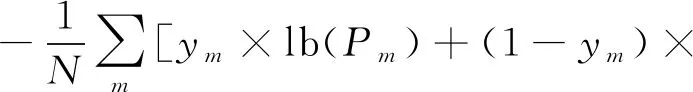
3.4 机器学习分类
4 与现有技术的比较

5 实验评估
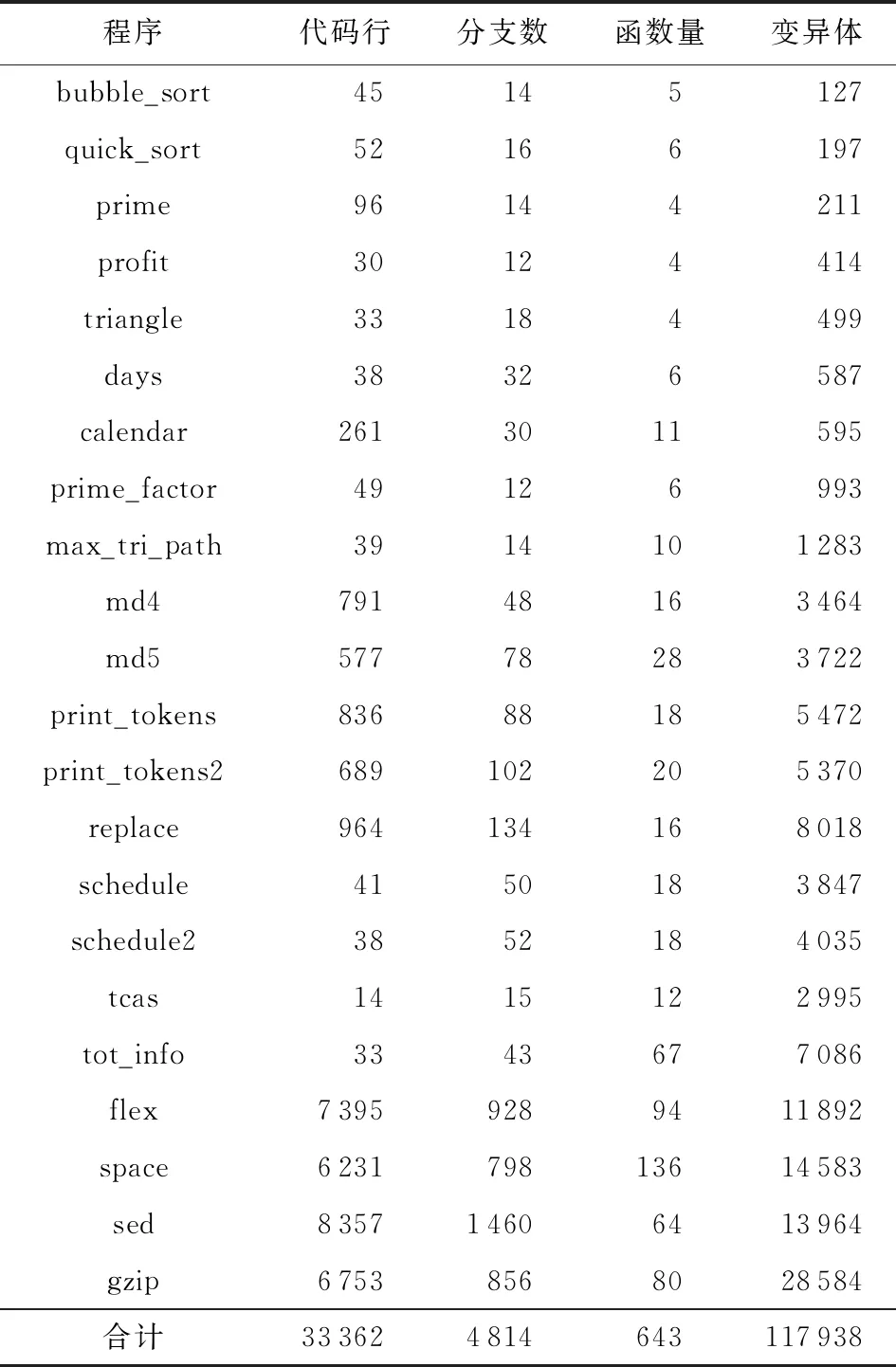
5.1 实验程序
5.2 Q1. 故障检测上下文特征评估


5.3 Q2.统计学习模型比较
5.4 Q3. 模型泛用性评估


5.5 有效性威胁

6 总结与未来工作
