深度神经架构搜索综述
2021-01-15孟子尧梁艳春吴春国
孟子尧 谷 雪 梁艳春 许 东 吴春国
1(符号计算与知识工程教育部重点实验室(吉林大学) 长春 130012)
2(符号计算与知识工程教育部重点实验室珠海分实验室(吉林大学珠海学院) 广东珠海 519041)
3(密苏里大学哥伦比亚分校电子工程与计算机科学系 美国密苏里州哥伦比亚 MO65211)(zy-meng@outlook.com)
人工神经网络通过模拟生物神经网络信号处理的过程,解决了很多具有挑战性的任务.以图像分类为例,LeCun等人[1]于1998年设计了第1个用于手写字符识别的卷积神经网络LeNet5,该网络仅有5层.直到21世纪10年代,GPU代替CPU成为了新的神经网络加速训练工具,这使得训练更大规模的网络成为了可能.Krizhevsky 等人[2]于2012年设计了有一定深度的网络AlexNet,并取得了ILSVRC-12(ImageNet large-scale visual recognition challenge-2012)竞赛的成功.相比于AlexNet,Szegedy等人[3]于2015年再次加深了网络的深度和宽度,设计了一个超过20层的神经网络架构GoogLeNet.He等人[5]于2016年通过引入跳跃连接的概念,设计了一个152层的残差网络ResNet,取得了ILSVRC-15分类任务的第1名.随着研究的不断深入,网络的层数不断加深,截至2016年,最深的神经网络已经超越1 000层[5].为了设计性能更加优异的网络,人工设计深层的网络需要进行大量重复的实验,随着网络层数的增加,需要人工调整的超参数就越多,这消耗了大量的人力和计算资源.因此,对于神经网络架构自动搜索的研究显得尤为关键.
神经架构搜索(neural architecture search, NAS)方法近年来在图像分类[6-8]、目标检测[9]等任务上取得了很好的效果.但这些方法都需要评估大量的网络架构,需要的计算资源过于庞大.通过代理模型、权值共享等方法可以加速网络搜索过程.Liu等人[10]于2019年提出可微分的架构搜索,借助反向传播算法同时搜索网络的架构和权值,这极大地提升了神经架构搜索方法的效率.目前,如何快速得到性能优异的网络架构也是研究的热点问题.
神经架构搜索的流程如图1所示:在预先设定的搜索空间中得到一个中间网络架构作为候选架构,通过性能评估策略对此候选架构进行性能度量,最后将测量的结果反馈给搜索策略,不断重复搜索—评估的过程直到发现最优的网络架构.
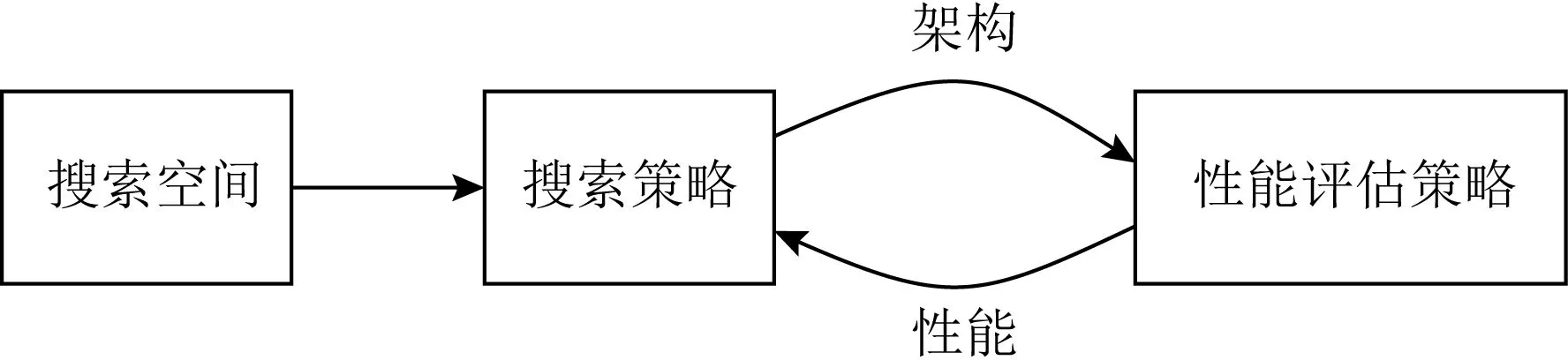
Fig. 1 The process of neural architecture search[11]
本文将按图1的流程进行说明,对典型神经架构搜索方法的原理进行综述,对不同方法之间的关系进行讨论,并对高效的性能评估策略进行总结,最后对未来需要研究的问题进行展望.
1 搜索空间
搜索空间定义了组成网络的基本操作,通过组合不同的操作会产生不同的网络架构.为了使算法可以高效地找到性能优异的网络,就必须构建一个适合的搜索空间.Liu等人[12]于2018年指出,在构造一个适合搜索空间的前提下,即使使用简单的随机搜索策略也可以发现具有竞争力的神经网络架构.通常情况下,研究者为了提高搜索效率会根据自己的经验适当地缩小搜索空间,但这不可避免地引入了人为的偏见.许多研究者通过神经架构搜索的方法发现了之前人工设计很难相信的网络架构[13],这证明了神经架构搜索的方法较于人工设计网络的优越性.目前,研究者涉及的搜索空间主要包括链式结构、多分支结构和基于Cell的结构.
1.1 链式结构
早期的深度神经网络都是较为简单的链式结构,如LeNet5[1],AlexNet[2]等,即网络中的每一层仅与其前后相邻的2层连接,且网络中没有跨层连接的情况,网络的整个架构呈现为链条状.如图2所示的LeNet5网络为最典型的链式结构.
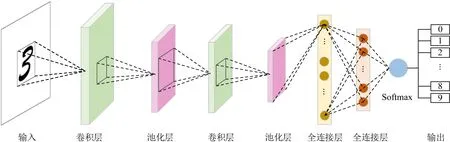
Fig. 2 A typical example of chain structures (LeNet5)
神经网络搜索空间的设计需要从3个角度出发:1)网络的层数.可以根据设计者现有的资源动态调整网络的最大层数.2)网络中各层的操作及与其相关的超参数.对于卷积神经网络来说,常用的操作有卷积、池化、批归一化(batch normalization, BN)、激活函数等.具体来说,卷积操作涉及的超参数有卷积核大小、通道数、补齐方式、步长等.3)网络中各操作的排列顺序.对于神经网络来说,结构的细微变化都会对网络的性能产生影响.通常情况下,人工设计网络时会将池化操作放置在卷积操作之后,亦有研究者对多种操作进行组合视为一种操作使用. 例如,Ioffe等人[14]于2015年将卷积、批归一化、激活函数组合为一个模块,将该模块作为构建网络的基本操作继续进行网络架构的生成.随着研究的不断深入,网络的层数不断加深,在训练网络过程中,链式结构易出现梯度消失、梯度爆炸等问题.为解决这一问题,研究者设计了正则化、BN等方法缓解了梯度所带来的问题,但未从根本上解决这个问题.
1.2 多分支结构
为了缓解梯度消失、梯度爆炸等问题,研究者设计了多分支结构,它允许网络中的层可以与其前面的任意层进行连接.GoogLeNet[3]是深度神经网络中第一个引入了多分支网络结构的概念,构建了不同的Inception模块以扩大网络的深度和宽度,Inception模块中不同的分支由多种不同的操作组成,通过对输入层不同维度的特征提取,提升了网络的性能,图3为一个Inception模块的示例.ResNet[5]在2016年首次提出了跳跃连接思想,浅层网络中的特征会通过跳跃连接直接传递到更深的功能层,从而克服了梯度消失对深层网络的影响.跳跃连接的出现掀起了新一波的研究热潮.例如,DenseNet于2017年[15]将网络中的每一层都与其前面的层连接,形成了稠密的网络结构.然而该网络中的每一层都会接收其前面所有层的特征作为该层的额外输入,也就意味着需要存储大量的中间特征,因此,DenseNet需要花费大量的内存开销.为了缓解内存的使用压力,研究者设计了共享存储空间的方法[16],从而降低DenseNet模型的显存.使用多分支结构设计网络的搜索空间时,需要考虑跳跃连接的具体位置和数量.针对不同的实际问题,最佳的跳跃连接位置和数量也不尽相同,因此也为设计深度神经网络架构的自动搜索方法提出了强烈需求.
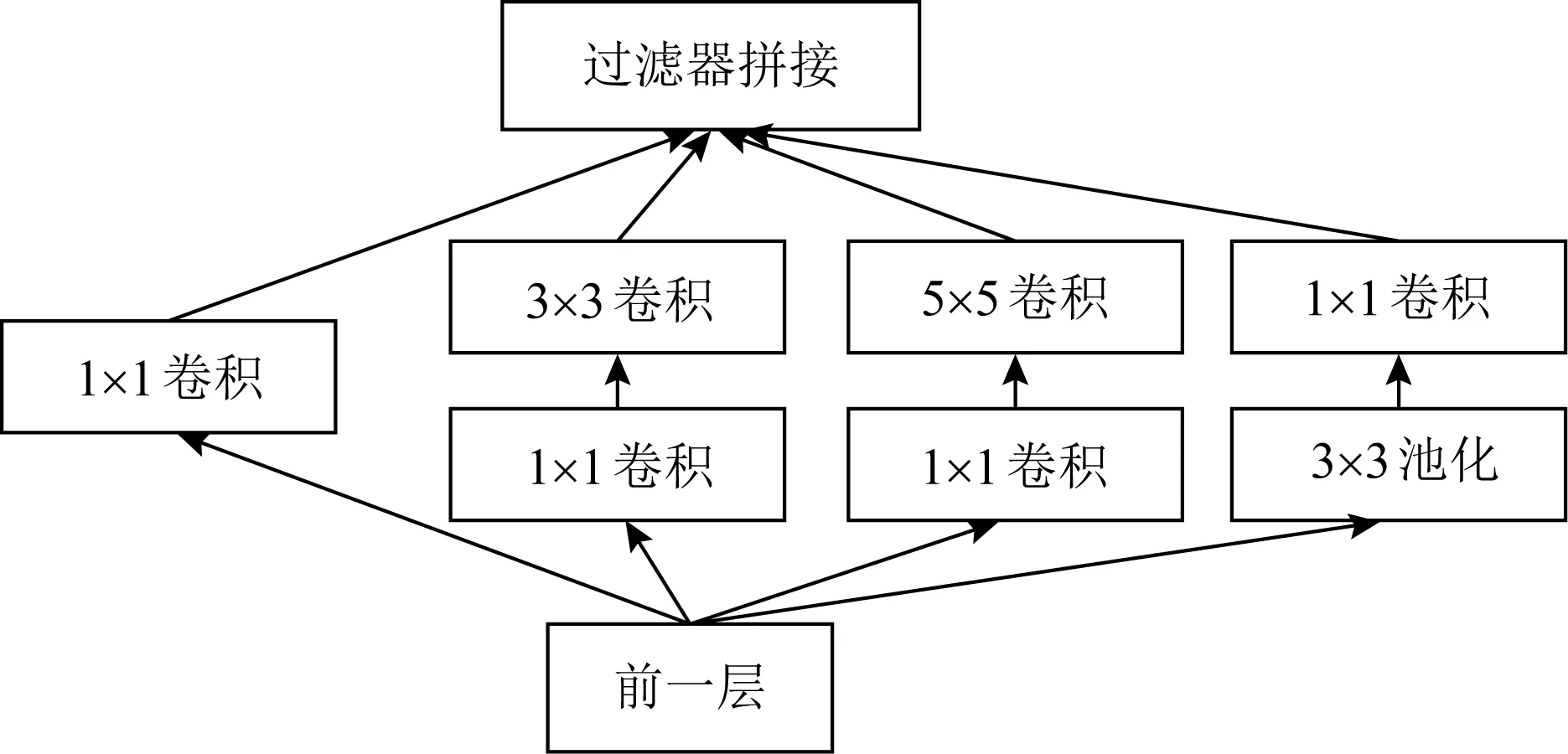
Fig. 3 Inception module of multi-branch structure GoogleNet
1.3 基于Cell的结构
基于人工设计网络架构会重复使用相同模块的经验,研究者试图将多个操作组合成Cell,并将Cell作为组成神经网络的基本单元,以此设计了基于Cell的网络结构.具体来说,构建基于Cell的网络结构分为两步,首先需要构建最优的Cell结构,之后将得到的Cell按照预先定义的规则进行堆叠,以得到最终的网络架构.对于单个Cell来说,它既可以是简单的链式结构,又可以是复杂的多分支结构.Liu等人[12]设计了深度神经网络的层次化表示方法,该方法首先在初始的基本操作上演化得到Cell结构,之后将Cell视为基本操作进一步搜索2级Cell,最后将得到的2级Cell按照预先定义的规则进行组合形成最终的网络.基于Cell的方法充分考虑了网络对全局与局部的设计,对搜索空间的搜索更细致,是目前最为流行的方法.
通常情况下,对基于Cell结构的搜索空间进行设计时需要考虑2个方面:1)演化Cell的种类.Cell结构的不同之处在于其内部节点的数量、节点间的连接以及连接上操作的类型.一般情况下,需要演化2种类型的Cell,分别是Normal Cell和Reduction Cell.其中,Normal Cell的输入和输出特征图的维度一致,而Reduction Cell的输出特征图的宽、高是输入特征图的一半[10].2)构建最终的网络架构时,不同Cell之间的排列顺序.Xie等人[17]于2017年在构建最终网络架构时,将演化得到的Cell按照定义好的方式进行组合.Rawal等人[18]在2018年将演化得到的多种Cell按照定义好的方法进行组合,并固定该组合重复的次数,以此得到循环神经网络.Liu等人[10]在2019年提出了可微架构搜索方法DARTS,按照在网络的13,23处放置Reduction Cell而在其余部分放置Normal Cell的方式,构建了最终的网络架构.
图4为DARTS中使用的2种Cell结构.与链式结构和多分支结构相比,基于Cell的方法更适用于迁移学习任务,即使用该方法在小规模数据集上得到的Cell迁移到同类大规模数据集时,仅需要重复叠加Cell,就可以得到适用于该大规模数据集上的深层神经网络[9].

Fig. 4 Two types of DARTS cells
对3种网络结构类型来说,链式结构最为简单、直观,链式结构的网络可以通过增加深度来提升网络的性能.对于多分支结构来说,分支数量的增加意味着网络宽度的增加.多分支结构通过不断增加网络的宽度,探索了多维度特征,提升了网络的性能.基于Cell的结构融合了链式结构和多分支结构的优势,既可以增加网络的深度,又可以扩大网络的宽度.从设计搜索空间的角度来说,链式结构和多分支结构需要考虑网络的整体结构,而基于Cell的结构只需要考虑Cell的内部结构.从可扩展性角度来看,链式结构和多分支结构受限于卷积神经网络(convolutional neural network, CNN),而基于Cell的结构可以轻松地扩展到循环神经网络(recurrent neural network, RNN).
2 搜索策略
在构建好搜索空间后,需要设计一个快速、高效的搜索策略,以实现最优网络架构的搜索.搜索策略的选择需要根据搜索时间、计算资源等要求进行选择.神经网络的架构搜索可以看作是大规模的超参数优化问题,是AutoML的重要组成部分.如图5所示,目前流行的搜索策略主要有:随机搜索、贝叶斯优化、强化学习、神经进化和基于梯度的方法.

Fig. 5 Method of neural architecture search
2.1 贝叶斯优化
深度神经网络中存在大量的超参数,如卷积核大小、学习率等,为了找到最优的超参数组合,最直观的方法就是网格搜索.然而,网格搜索无法利用有效信息指导搜索过程,会进行大量的无效探索.而贝叶斯优化会充分学习上一次的评估结果,并建立概率模型,指导后续的参数选择过程,最常用的概率模型是高斯模型.基于这一优点,研究者设计了基于贝叶斯的神经架构搜索算法[19-21].
Bergstra等人[22]于2013年设计了基于贝叶斯优化的神经网络超参数搜索算法,在3个计算机视觉任务上取得了最优的效果.此后,Swersky等人[23]于2014年对此算法进行了改进,引入了条件参数空间的新内核,并共享了结构间的信息,简化了建模过程,提升了模型质量.Hutter等人[24]于2011年提出的基于序列模型的优化策略(sequential model-based optimization, SMBO),随后Negrinho等人[25]于2017年设计了实验对SMBO和随机搜索进行比较,验证了SMBO方法优于随机搜索.基于此,Liu等人[26]于2018年设计了顺序渐进式神经网络架构搜索算法,在搜索过程中不断增加网络的复杂度.同样地,Perez-Rua等人[27]于2019年基于SMBO设计了多模态融合的神经网络架构搜索方法.此外,Jin等人[28]于2018年基于SMBO设计了一个多目标架构搜索框架PPP-Net,能够自动生成最优网络架构.该方法在CIFAR-10数据集上进行架构搜索时,可以同时演化分类误差率、搜索时间、参数量、每秒计算次数等目标,并在移动设备上达到了最佳性能.Golovin等人[29]于2017年开发了基于贝叶斯优化的网络调参系统Google Vizier,用于Google内部网络调参.
2.2 强化学习
也有研究者将强化学习算法用于神经架构搜索.具体来说,神经网络架构的生成过程可以看作Agent智能体选择动作的过程,神经网络的搜索空间对应着Agent的动作空间,最终Agent经过一系列动作选择后会得到最终的网络架构.针对神经网络架构搜索任务,Agent的Reward奖励对应为网络架构在验证集上的准确率.目前有大量的神经架构搜索算法是基于强化学习实现的,这些方法的不同点在于Agent选择动作的策略及用于优化该策略的方法.
Zoph等人[6]于2017年首次将强化学习应用在神经网络架构搜索,该方法达到了与人工设计的最佳网络相似的性能,并使用RNN作为控制器,对设计好的搜索空间进行采样,以此得到最终的网络架构,并在搜索过程中使用Reinforcement方法优化RNN的参数,随后,Zoph等人[9]于2018年提出了NASNet,该方法将Reinforcement优化方法替换为近端策略优化(proximal policy optimization, PPO),加快了搜索速度,提高了搜索结果.同时该方法通过多次堆叠在CIFAR-10数据集上搜索到的Cell,很好地迁移到了COCO 和ImageNet两个大数据集上.在图像分类数据集ImageNet上达到了SENet相同的精度,且模型参数只有SENet的一半.Baker等人[7]于2017年提出了MetaQNN用于神经网络架构的搜索,MetaQNN使用带有ε-greedy贪婪探索策略和经验回放的Q-learning搜索网络的架构.同样,Zhong等人[8]于2018年设计了基于强化学习的神经网络架构搜索方法BlockQNN,在该方法中,网络中的层由网络结构代码(network structure code, NSC)表示,NSC是一个由5维向量表示的结构.为了加快算法的搜索进程,BlockQNN使用了分布式异构框架和早停策略.在提升基于强化学习的神经网络架构搜索算法的搜索速度上,虽然有很多策略可以使用,但由于其搜索过程中需要评估大量的中间网络架构,会消耗大量的搜索时间和计算资源.基于此,Pham等人[30]于2018年提出了高效的NAS方法ENAS,该方法试图将搜索过程中的各个子网络进行权值共享,避免了从头训练网络,与标准的神经架构搜索算法[6]相比,ENAS缩短了11000以上的GPU运算时间.Tan等人[31]于2019年验证了网络的深度、宽度和分辨率与网络性能的关系,对模型缩放进行了进一步探讨,其设计的EfficientNets有效地平衡了深度、宽度、分辨率之间的关系,在ImageNet上获得了Top-1的精度(84.4%),与AmoebaNet网络相比,其参数减少了18,且运行速度提升了6.1倍.
随着边缘计算的普及,越来越多的任务需要在移动设备上实现.针对计算资源受限的移动设备,Tan等人[32]于2019年将手机设备上实时运行模型的延迟、精度和运行速度作为搜索目标,提出了适用于移动设备上的神经网络架构搜索算法MnasNet.此外,MnasNet为了增加搜索的灵活性,设计了基于因式分解的层级搜索空间,可以将CNN分解为小的模块.Yang等人[33]于2018年在资源预算受限的前提下提出了NetAdapt算法,通过逐层简化网络,实现了由大规模数据上的预训练模型到移动设备的迁移任务.Howard等人[34]于2019年将MnasNet神经网络架构搜索算法和NetAdapt进行结合,提出了MobileNetV3,在图像分类、目标检测、图像分割任务上都取得了最佳的效果.Tan等人[35]于2019年在实验中发现,在同一层中组合多种尺寸的卷积和会提高模型的精度和搜索效率,设计的MixNets神经架构搜索方法在移动设备上取得了最佳性能.基于强化学习的神经网络架构搜索方法不仅在图像分类任务上展现了优势,在图像分割、目标检测等任务中也取得了优于人工设计网络的性能,目前基于强化学习的神经架构搜索算法是神经架构搜索领域不可缺少的方法[36].
2.3 神经进化
神经进化的核心思想是采用进化算法来演化网络的权值、架构、激活函数乃至超参数.随着人工设计网络架构的不断发展,网络的层数不断加深,网络的结构愈加复杂,网络参数的数量不断增加.对于神经架构搜索任务来说,需要的计算资源也在不断增加.目前,基于神经进化的架构搜索算法将网络结构与权值分开进行优化,具体来说,网络的结构使用进化算法进行优化,而网络的权值使用反向传播进行优化.
针对基于进化算法的神经架构搜索算法,在20世纪末,研究者们的研究重点是对网络权值进行优化,其流程为: 首先选定网络的架构,之后借助遗传算法对网络中的权值进行优化.这类方法在杆平衡任务上取得了很好的效果[37-38].Kenneth等人[39]于2002年借助遗传算法的思想,提出了增强拓扑的神经进化网络NEAT.该方法从最基础的单元结构开始演化,演化过程中引入历史标记来缓解竞争约定问题[40],此外,NEAT将整个种群划分为不同的物种,以确保演化过程中网络结构的多样性.NEAT不仅实现了网络架构的演化,同时也对网络的权值进行优化,实验表明,NEAT方法远好于最初固定网络架构仅演化权值的方法[37].Miikkulainen等人[13]于2019年对NEAT方法进行了扩展,由演化拓扑结构的演化扩展到模块及超参数的演化,提出了CoDeepNEAT.通过共同演化网络的结构和模块,在目标识别、语言建模等任务的标准数据集上达到了与人工设计网络结构性能相近的结果.Liang等人[41]于2019年将CoDeepNEAT与分布式计算框架进行了结合,提出了适用于演化AutoML框架的LEAT,在医学影像分类、自然语言处理领域数据集上都取得了优异的性能.

Fig. 6 Evolutionary algorithm[42]
随着人工设计网络架构的发展,神经架构搜索算法的搜索空间也随之变大.作为群体智能技术之一的进化算法,可以充分有效地对搜索空间进行遍历,鉴于此,基于进化算法的神经架构搜索算法逐渐流行起来.如图6[42]所示,基于进化算法的神经架构搜索算法,将每一个网络架构看作种群中的个体,演化过程中对每一代产生的个体进行选择,并对优异的个体执行交叉、变异等操作以生成下一代种群,不断重复这个过程,直到产生性能最优的个体或达到最大演化代数.进化算法包括遗传算法、进化策略、遗传编程和进化规划,这4种算法均有研究者扩展至神经架构搜索.
基于进化算法的神经架构搜索方法主要的研究有:Salimans等人[43]于2017年通过实验验证了强化学习可以被进化策略所替代,并在多步决策任务上取得了优异的效果.Real等人[44]于2017年提出了适用于大规模图像分类的演化算法,可以在最小化人工参与的情况下,借助250多台GPU服务器,从最简单的初始结构开始,在CIFAR-10和CIFAR-100 两个图像分类基准数据集上达到了与人工设计网络性能相近的效果.此后,Real等人[45]于2019年在进化算法中加入Aging对锦标赛选择算法进行了改进,提出了适用于图像分类任务的AmoebaNet.该算法通过尽可能多地保留年轻个体,在ImageNet数据集上首次超越了人工设计网络的性能,此外,该算法还证明了与强化学习、随机搜索方法相比,进化算法的搜索速度更快.Xie等人[17]于2017年设计了定长二进制字符串表示网络架构的编码方案,并以此提出了基于遗传算法的卷积网络架构搜索算法.该算法仅仅演化卷积、池化等简单的基本操作,就能在图像分类任务上得到了较好的效果,并且得到的架构可以很好地迁移到大规模数据集上.David等人[46]于2019年对神经架构搜索的任务进行了扩展,将人工设计的Transformer框架引入了演化初始结构,通过锦标赛选择策略得到了自然语言处理领域性能优异的网络架构.
多景观带是由肖圈干渠延伸出来的三条沿河绿化景观带,一条水上游乐景观带、一条生活休闲景观带、一条工业生活景观带。肖圈干渠是经过南皮的主要的东西向的河流,是城市水景主要干路。从肖圈干渠延伸出三条主要的支路,一是水上公园:所经途径主要有城西的水上公园;一是生活休闲,经过的主要是居住生活区,沿河两边有很多的休闲绿化公园,是人流汇集的一条生活绿带;一是工业水渠,主要流经工业园区,在承担工业排水的同时担任少部分的生活公园的功能。城市外围的绿化带起到防护和隔离噪音的功能。
随着应用设备的扩展,神经架构搜索算法从服务器端扩展到移动设备端.移动设备端的神经架构搜索算法需要综合考虑网络的性能、搜索时间、复杂度、计算资源等多方面的问题,神经架构搜索由单目标搜索任务转换为多目标搜索任务.Elsken等人[47]于2019年提出了拉马克进化算法LEMONADE用于多目标神经架构搜索,此外,该算法设计了Network Morphisms[48]对神经网络空间结构的算子进行操作以保证网络结构的功能不变性.LEMONADE借助遗传操作让子代个体可以继承其父代的信息,避免了子代从头学习,极大地减少了训练时间;为了减少网络的规模,LEMONADE等人设计了Approximate Network Morphisms方法,在图像分类任务上达到了与人工设计网络相近的效果.Li等人[49]于2019年提出了偏序剪枝算法,在实现网络精度优异的前提下,搜索效率最高.此外,小米的AutoML团队提出了适用于移动设备的神经架构搜索算法MoreMNAS[50],该算法将进化算法和强化学习结合,平衡了演化过程中探索和开发的过程,充分利用了新学习的知识,降低了退化现象.
2.4 基于梯度的方法
对于2.1~2.3节所述的神经架构搜索算法来说,它们的搜索空间是离散不可微的,也就意味着在搜索过程中需要评估大量的网络架构,花费大量的时间.为了降低训练网络花费的时间,研究者试图将搜索空间变成连续可微的,再使用基于梯度的方法进行优化.具体来说,基于梯度的架构搜索使用反向传播算法同时对网络权值和网络结构进行优化,减少了大量训练网络消耗的时间,但搜索过程中会占用大量的内存.
基于梯度的神经架构搜索方法主要包含:Liu等人[10]于2019年提出了DARTS算法,首次将离散不可微的搜索空间转换为连续可微的,借助反向传播同时优化网络的架构和权值.在DARTS算法中,预先设定了8种候选操作,包含卷积核为3×3和5×5的可分离卷积、3×3和5×5扩张可分离卷积、3×3的最大池化、3×3的平均池化、保持不变和无操作.该算法在搜索过程中使用Softmax对每条边上的候选操作进行加权,最终只保留每条边上权值最大的操作.Hundt等人[51]于2019年对DARTS算法进行了改进,提出了sharpDARTS,引入余弦幂次退火对学习率进行更新,借助MaxW正则化方法纠正DARTS算法中的偏差.Cai等人[52]于2019年为了降低基于梯度的神经架构搜索算法的内存过大的问题,提出了ProxylessNAS,该算法在训练过程中使用路径级二值化操作,即每次只激活边上的1种操作.ProxylessNAS在不使用代理模型的前提下针对大规模图像分类数据集ImageNet进行网络架构的搜索,并将其算法从GPU扩展到了手机上.该算法在CIFAR-10数据集上,仅用了5.7M个参数就达到了2.08%的测试误差,与AmoebaNet-B相比减少了16的参数量.在ImageNet数据集上,ProxylessNAS比Mobilenet V2高3.1%的准确率,运行速度快了20%,且手机实测速度是Mobilenet V2的1.8倍.Zheng等人[53]于2019年将搜索空间看作一个多项式分布,通过多项式的不同取值对应着不同的网络架构,提出了MdeNAS,该算法在ImageNet数据集上搜索了4 h就达到了目前最佳分类效果.Dong等人[54]于2019年提出了可微架构采样方法GDAS用于神经架构搜索,该方法在训练过程中仅采样节点间的1种操作,降低了内存消耗.此外,为了缩小搜索空间,GDAS固定了Reduction Cell,仅对Normal Cell进行搜索,在V100显卡上搜索了4 h在CIFAR-10数据集上得到了2.5M个参数、2.82%误差的网络.针对基于梯度的神经架构搜索算法占用大量内存的问题,研究者们通常会在较浅的网络中搜索最优的架构,之后不断增加层数来验证其性能.Chen等人[55]于2019年发现:基于梯度的神经架构搜索算法由于在搜索阶段和验证阶段网络层数的不同会出现在训练阶段性能优异的架构在验证阶段性能不好的现象,研究者将这种现象称为深度差距.为了缩小这种差距,Chen等人提出了P-DARTS,在搜素过程中逐渐增加网络的层数,并通过搜索空间近似减少了内存消耗,使用了搜索空间正则化来控制搜索的稳定性.此外,对于降低训练过程中内存消耗的问题,Xu等人[56]于2019年提出了PC-DARTS可以在不降低网络性能的前提下进行了高效搜索,该方法通过采样部分Cell减少网络中的冗余.
表1为基于贝叶斯优化、强化学习、神经进化、梯度的方法进行神经架构搜索的算法在CIFAR-10数据集上的性能比较.从搜索架构的性能和效率角度来看,基于梯度的神经架构搜索算法得到的网络性能更好,且搜索速度最快.
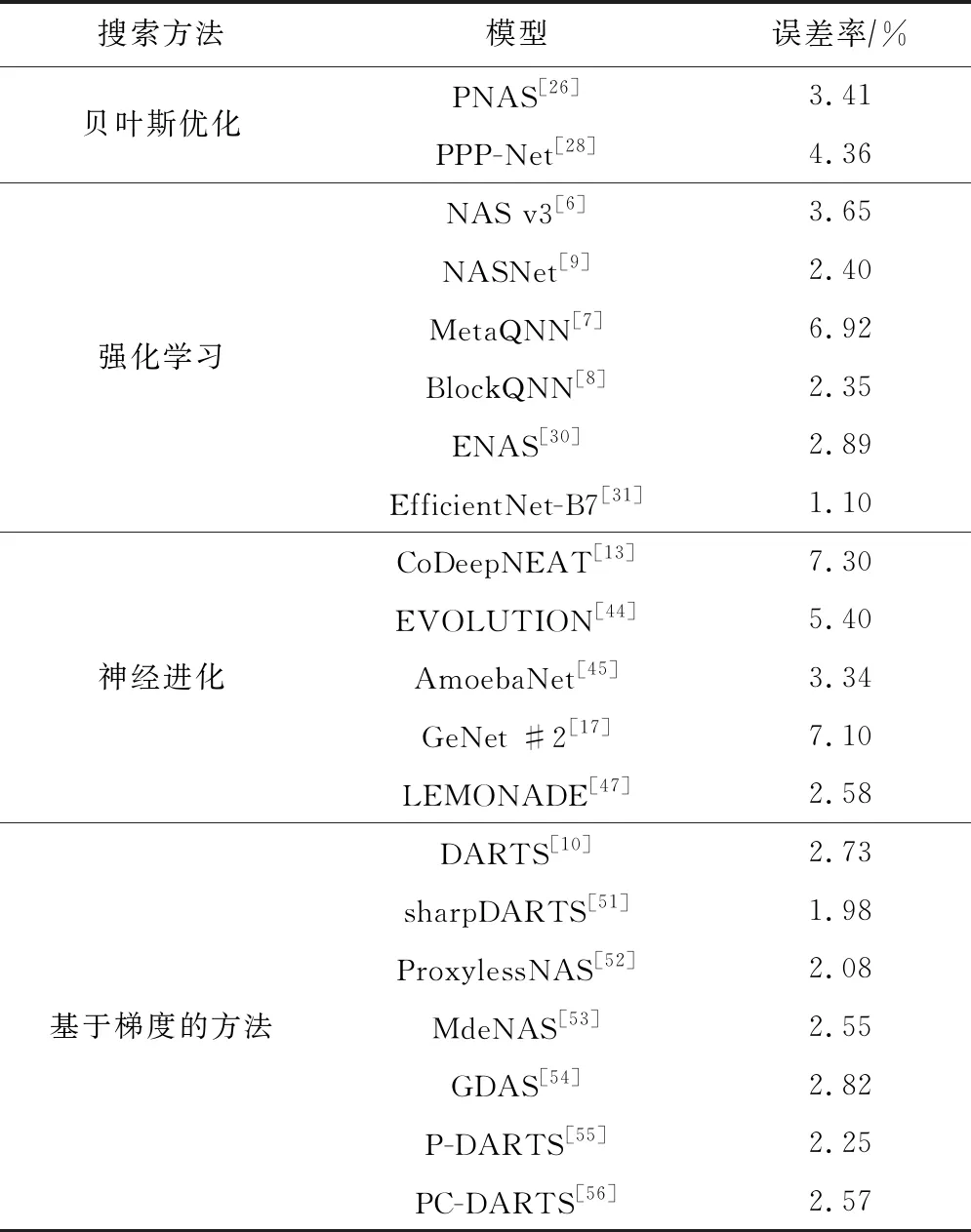
Table 1 Performance of Different NAS Algorithms on CIFAR-10
3 性能评估策略
性能评估是神经架构搜索算法的必要环节,通过性能评估测量得到每个网络的性能并反馈给神经架构搜索算法,以指导搜索算法得到最优的网络架构.通常先得到一个在训练集上拟合好的网络,将网络在验证集上的误差作为网络性能的度量值.然而,这种方法需要使用反向传播对网络进行训练,需要大量的计算资源,花费大量的时间,搜索效率较低.为了加快网络架构的评估,本文总结了4种常见的性能评估策略,包括低保真度、早停、代理模型和权值共享等方法.
3.1 低保真度
一般情况下,神经网络的性能是网络在训练集上收敛后得到的网络精度,然而网络训练到收敛需要花费大量的时间,因此,为了加快架构搜索过程中网络的收敛过程,研究者提出了采用减少样本数量[57]、降低图像分辨率[58]、减少网络层数[9,45]等方法.通过近似的数据集、近似的网络架构虽然加快了搜索过程,减少了计算成本,但是这不可避免地会引入偏差.Chrabaszcz等人于2017年通过实验指出了低保真度方法会导致评估结果与收敛结果之间产生偏差.即便如此,研究者也可以通过控制近似网络与实际网络之间的差距阈值来提高训练效率.例如减少少量的训练样本、缩减部分网络.
3.2 早 停
除了使用低保真度的方法加快搜索速度,也有研究者使用早停机制,即在网络未收敛时就停止训练,其采用的具体方法主要有:1)固定训练代数.在网络的训练过程中,如果网络达到预先设定的这个阈值就会停止训练,此时的精度就代表了该网络的精度.Zheng等人[53]于2019年提出并验证了一个性能排序假设:在训练的某个时刻,如果网络A在某个数据集上的性能高于网络B,那么当网络A、网络B在该数据集上训练到收敛后,网络A的性能仍高于网络B.该假设的成功证明极大地提高了神经架构搜索的效率.2)学习曲线外延的方法[20,59].在网络训练过程中,根据网络精度曲线的趋势和超参数,对该网络的收敛精度进行预测,而不是直接运行到收敛.Rawal等人[18]于2018年使用前10代的网络精度预测第40代的精度,提出的Seq2seq模型达到了与人工设计架构相近的结果.
3.3 代理模型
与低保真度和早停的方法不同,基于代理模型的方法采用简单的近似任务替代实际的训练任务,代理模型得到的结果即为网络的性能.基于此,Liu等人[26]于2018年设计了代理模型来评估候选Cell的性能,该方法减少了网络性能评估的时间.目前的研究工作中,在对ImageNet数据集进行架构搜索时,大多数方法都会将CIFAR-10数据集的架构搜索作为代理任务[10,26,45,53,55-56],之后将得到的代理任务上最优的网络架构迁移到ImageNet目标任务上.
3.4 权值共享
除了上述提到的网络性能评估策略外,有研究者使用权值共享的方式进行性能评估.权值共享的方法主要有2类:Network Morphisms[48,60-61]和One-Shot[10,62].对于Network Morphisms方法来说,在保证网络功能不变的前提下,通过不断地扩展初始网络,提高训练效率,该方法不需要网络从头开始训练,但使用该方法得到的网络架构会越来越复杂.Chen等人[48]于2016年设计了Approximate Network Morphisms算法,在保证网络性能不变的情况下对网络的架构进行简化.Jin等人[63]于2019年将贝叶斯优化与Network Morphisms结合提出了开源的自动学习系统Auto-keras.
与Network Morphisms方法不断扩展网络图不同,One-Shot方法仅需要训练一个超图,通过不断地搜索超图中的子图实现架构的搜索.虽然One-Shot的共享权值方法会减少搜索时间,但整个网络的架构被限制在超图中,对于One-Shot方法来说,超图的选择是得到最优网络架构的前提.此外,搜索到的子图共享原超图的权值是否可以达到最佳性能也是需要进一步确认的[49].
多数酒店知识型员工的薪资水平不高,而且相互之间差距不大。酒店的高层管理人员没有体会到知识型员工的重要性和能够为酒店所带来的附加值,或者对于其认识不够。将知识型员工的收入水平与一般员工的收入水平等同起来。这样的后果就是使得知识型员工产生消极感和对自我价值的过低评估,觉得自己的努力没有获得应该的回报,自身的价值在工作中得不到认可与体现。有些酒店甚至没有为知识型员工办理相对应的社会保障例如:社会养老保险、失业保险和社会医疗保险,偏偏知识型员工的学习能力信息接收能力强,对自身的风险规避意识较高,酒店这种对知识型员工安全心理的不作为会导致知识型员工对企业的信任感较低。
网络性能评估策略的提出是为了加速对网络性能进行评估,进而提高架构搜索的效率,而这一切的根源在于网络性能的获得需要对网络进行训练,如果网络无需训练就可以得到性能,那么神经架构搜索的效率会更高.基于上述想法,谷歌于2019年提出了权值无关的架构搜索算法[64],该算法将整个网络共享为一个权值,在评估网络性能时,使用预先设定的权值进行训练以得到网络的性能,极大地减少了网络训练的时间,提高了搜索效率.
4 展 望
目前,神经架构搜索技术在图像分类的几个基准数据集上均取得了不错的成绩,但是缺少其他数据集和实际任务的检验.神经架构搜索的鲁棒性也是算法性能的一个关键指标.同时,在搜索网络的过程中,搜索时间、计算资源等影响算法性能的变量也需要作为评估最终性能的指标.神经架构搜索的可解释性也是一个需要关注的重点问题,不仅搜索过程无法科学解释,而且搜索到的网络也无法清晰解释.这些问题都使得神经架构搜索方法无法得到广泛的应用.
最后,神经架构搜索的开源化和可复现性也是限制其发展的瓶颈.通过随机几次得到的结果并不能说明算法的有效性,算法需要随时随地可以复现,而且通过开源代码可以使得更多的人加入到这个领域.总之这个领域还需要很多的努力.
