基于交叉熵的安全Tri-training算法
2021-01-15陈蓉蓉
张 永 陈蓉蓉 张 晶
(辽宁师范大学计算机与信息技术学院 辽宁大连 116081)(zhyong@lnnu.edu.cn)
传统的分类方法通常使用有标签的数据进行训练.然而,随着人们收集数据能力的不断提升,获得大量的未标记数据样本相对容易,而获取已标记数据样本通常却需要付出昂贵的人力、物力和财力.如何让学习器利用少量的标记数据和大量的未标记数据来提升学习性能,是半监督学习(semi-supervised learning, SSL)[1-2]所要解决的问题.目前常用的半监督学习方法主要包括生成式方法[3]、半监督支持向量机(semi-supervised support vector machine, S3VM)[4-5]、图半监督学习[6]、基于分歧的方法[7]和半监督聚类[8]等.
其中,基于分歧的方法起源于协同训练[9].标准的协同训练算法需要2个足够多的冗余视图,即属性可以自然地分为2组,且每组在给定类标签的情况下有条件地独立于另一组.然而在实际应用中,并不是所有的数据集都能满足这一特征.为了更加方便地应用到各种常见的数据挖掘场景,Zhou等人[10]提出了一种协同训练算法Tri-training,该算法不需要足够的冗余视图,也不需要使用不同的监督学习方法,有效提高了半监督学习的效率.Søgaard[11]提出了一种带分歧的Tri-training算法,旨在提升模型的薄弱点,比一般的Tri-training算法更具有效率.Saito等人[12]提出了一种用于无监督域自适应的非对称Tri-training算法,通过不对称地使用3个神经网络,达到对目标域未标记数据进行标记的目的,从而提高了迁移学习领域的自适应性能.Ruder等人[13]为了减少Tri-training过程中的时间和空间复杂度,把迁移学习思想引入半监督学习,提出了多任务Tri-training算法.Ou等人[14]提出了一种基于正则化局部嵌入的Tri-training方法用于高光谱图像分析,解决了奇异值和过拟合的问题,有效提高了高光谱图像的分类精度.Park等人[15]结合Tri-training方法和对抗学习方法构建了一个半监督学习框架,用来检测单个音频剪辑中多个声音事件的设置和偏移.该框架先用Tri-training方法标记数据,然后使用对抗学习方法来减少真实数据集和合成数据集之间的域间隙.然而上述Tri-training算法依赖于初始的分类器,忽略了标记后产生的噪声标签.研究表明[16],在某些情况下,使用未标记的数据进行半监督学习时会使性能退化,导致一个不安全的学习模型,而在Tri-training训练过程中产生的不正确伪标签是性能下降的主要根源.本文提出一种安全的半监督学习方法,即使在使用未标记数据时也不会显著降低学习性能.
本文从降低误标记样本的角度出发,将交叉熵、凸优化分别与Tri-training算法相结合,提出了3个不同的算法.实验结果表明,基于交叉熵的安全Tri-training算法具有最优的分类性能.针对半监督分类学习任务,本文的主要贡献有3个方面:
1) 将交叉熵与Tri-training算法相结合,提出一种基于交叉熵的Tri-training算法;
2) 使用铰链损失函数,提出了一个安全的Tri-training算法;
3) 运用凸优化方法,提出一种基于交叉熵的安全Tri-training学习框架.
1 相关工作
本节主要介绍了基于分歧的半监督学习方法Tri-training的基本思想、相对熵和交叉熵的相关知识,以及基于凸优化的半监督分类学习方法.
1.1 Tri-training算法
Tri-training算法[10]不要求数据集有充足和冗余的视图,通过建立3个基分类器,用一种监督学习方法即可实现.基本思想是:首先,通过Bootstrap方法重采样原始标记数据集L,训练得到3个基分类器h1,h2,h3.然后,对未标记数据集U中的数据x进行标记,只需有2个分类器对x的标记一致即可,并将该未标记样本及其分类一致的标签加入到另外一个分类器的训练集中,重新训练基分类器,依此类推.重复迭代上述过程,直到3个基分类器的性能不再改变为止.最后,采用多数投票法确定最终的分类结果.
在标记过程中,产生的错误标记样本会对结果造成影响.为了减少标记过程中产生的噪声样本,该算法基于Angluin等人[17]的理论结果,根据分类噪声率和每轮训练的分类错误率决定伪标记样本是否用于分类器更新.Zhou等人[10]证明,如果新标记的训练样本足够多且满足式(1)所设定的约束条件,则基分类器重新训练所得的分类性能会迭代提升.
(1)

(2)
在Tri-training训练过程中,用式(2)来判断由hj和hk给出一致标记的数据所组成的数据集Lt是否应该被加入到hi的新训练集中.
Tri-training不需要数据集有冗余的视图,对基学习器也没有特定的要求,因此成为基于分歧的半监督学习方法中最常用的技术.然而该算法在训练过程中产生的标记噪声,可能会对最后的模型产生不好的影响.为了减少Tri-training算法过程中的标记噪声对未标记数据的预测偏差,学习到更好的半监督分类模型,本文结合交叉熵和凸优化方法,提出了一种基于交叉熵的安全Tri-training学习框架.
1.2 相对熵与交叉熵
相对熵又称为KL散度(Kullback-Leible diver-gence),是2个概率分布间差异的非对称性度量[18].在信息理论中,相对熵可用于表示2个概率分布的信息熵的差值.假设在给定样本集χ上定义样本真实分布为P,模型预测分布为Q,则P和Q的相对熵或KL散度可以定义为[19]
(3)
DKL值越小,表示P和Q的分布越接近.当且仅当2个概率分布相同时,相对熵DKL=0.
交叉主要用于描述两个事件之间的相互关系.Rubinstein[20]提出了交叉熵的概念,用来度量2个概率分布的差异性.由式(3)变形可得:
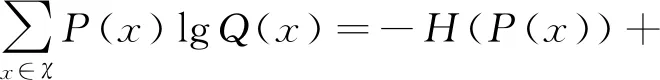
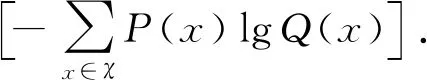
(4)
式(4)等号右端前半部分为分布P的熵,后半部分即为交叉熵:

(5)
交叉熵具有2个重要性质:
1) 非对称性.即H(P,Q)≠H(Q,P).
2) 非负性.H(P,Q)≥0,且有H(P,P)=H(P).

交叉熵已经广泛应用于组合优化、机器学习等领域.Bosman等人[21]提出了一种基于交叉熵和平方误差损失函数的梯度随机采样可视化方法,实验结果表明交叉熵损失比二次损失具有更强的梯度和可搜索性.Li等人[22]在交叉熵损失中加入正则项,提出了一个对偶交叉熵损失函数,用来优化神经网络结构,实验结果表明提出的损失函数提升了分类性能.Lu等人[23]提出了一种动态加权交叉熵作为语义分割的损失函数,设计了一种加权方法对交叉熵进行加权,并在每一个训练步骤中迭代权重.实验结果表明该方法能有效地提高数据极不平衡情况下的分割精度.Lopez-Garcia等人[24]将交叉熵和遗传算法相结合,提出了一种模糊规则系统层次结构要素的优化方法,能更好地预测短期交通拥堵状况.交叉熵可直接使用作为损失函数评估模型,当交叉熵最低时,可以认为得到了一个最好的训练模型.
1.3 基于凸优化的半监督学习
在半监督学习中,仅有极少数的标记数据,大部分是未标记数据.因此,人们通常希望利用未标记数据来提高模型的学习性能.但在某些情况下,现有的半监督学习方法比仅使用标记数据的监督学习方法表现更差.为了解决这一问题,Li等人[25]提出了一种安全的半监督SVM(safe semi-supervised support vector machine, S4VM)方法,该方法提高了半监督SVM的性能.Krijthe等人[26]提出了一种隐式约束的最小二乘半监督学习方法,该方法隐式地考虑所有可能的未标记数据的标记,同时能最大限度地减少已标记数据的平方损失.Guo等人[27]提出了一种方案,通过整合几个弱监督的分类器来建立最终的预测结果,并在噪声学习、域自适应和半监督回归任务上验证了方案的有效性.
2 基于交叉熵的安全Tri-training算法
为了提高未标记数据对于半监督分类性能的影响,本文使用凸优化方法,通过半监督分类的凸线性组合给出标记,提高安全半监督分类的准确性.本节首先利用交叉熵在信息差异度量方面的优势,提出了一种基于交叉熵的Tri-training算法;其次,提出了一种安全的Tri-training学习算法,以提升未标记数据的分类性能;最后,给出了一个基于交叉熵的安全Tri-training学习框架.
2.1 基于交叉熵的Tri-training算法

在计算“学习到的模型分布”与“训练数据分布”之间的信息差异量时,交叉熵相比利用误分率来衡量该差异性有更多的优势.本文首先将交叉熵与Tri-training算法相结合,提出一种基于交叉熵的Tri-training算法,具体描述如算法1所示.
算法1.基于交叉熵的Tri-training算法.
输入:训练集D=L∪U,其中L和U分别为已标记数据集和未标记数据集,测试集T;
输出:测试数据集T中数据x的标签h(x).
① fori=1 to 3 do
②Si←Bootstrap(L),hi←Learn(Si);
④ end for
⑤ repeat
⑥ fori=1 to 3 do
⑦Li←∅;
⑧ei←(Hj+Hk)2;*Hj,Hk(j,k≠i)为基分类器的交叉熵*

⑩ forU中每个样本xdo

相对于Tri-training算法,算法1用交叉熵代替了Tri-training算法中的分类误差,用加权投票规则确定最终的分类标签,在一定程度上提升了未标记数据的分类性能.
2.2 一个安全的Tri-training学习算法
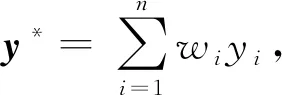
(6)
损失函数是用来估量模型的预测值与真实值的不一致程度.常见的用于分类任务的损失函数包括均方损失、铰链损失、交叉熵损失等.损失函数越小,模型的准确性越好.铰链损失和交叉熵损失都可以转化为凸优化问题,并通过凸优化技巧实现优化,损失函数在分类任务中的优化具有一般普适性[28-29].
铰链损失可以表示为预测结果的线性关系,使得铰链损失作为分类任务中的损失函数具有更好的性能[29].文献[27]证明当(·,·)选用铰链损失时,式(6)在分类任务中可转换为一个凸优化问题.
对于一个分类问题,用p=(p1,p2,…,pu)表示u个样本的真实标签,q=(q1,q2,…,qu)表示预测标签,铰链损失函数可定义为
(7)
(8)
从而式(6)可改写为
(9)
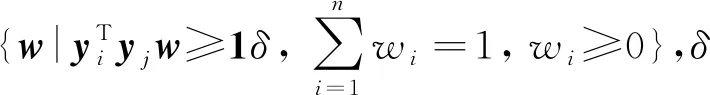
借助上述思想,我们将安全性融入到Tri-training算法中,以此来提高半监督学习算法的准确率和鲁棒性.算法2描述了用于半监督分类时安全的Tri-training学习算法.
算法2.安全的Tri-training学习算法.
输入:训练集D=L∪U,其中L和U分别为已标记数据集和未标记数据集,测试集T;
输出:测试数据集T中数据x的标签h(x).
①h0←Learn(L);
② 调用Tri-training(L,U)训练基分类器hi(i=1,2,3);
③y0←h0(T),yi←hi(T) (i=1,2,3);
④ 构造如(9)所示的目标函数:
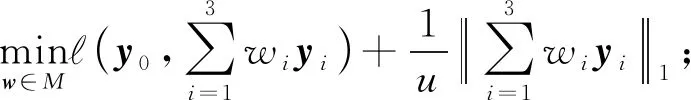

⑦ 输出所有的h(x).

Tri-training算法在基分类器预测分类结果后,采用多数投票方法来确定未标记数据的标签,未充分考虑每个分类器自身的强弱,可能降低未标记数据的分类性能,甚至低于直接用基准分类器h0对未标记数据分类得到的分类性能.与Tri-training算法相比,算法2分别用基准分类器和Tri-training对未标记数据进行学习,利用其初始预测结果构建一个优化问题,从而提升未标记数据的分类性能.
2.3 基于交叉熵的安全Tri-training学习框架
为了减少算法2过程中产生的噪声标记,进一步降低Tri-training的误分率,本文将交叉熵用于安全Tri-training算法中,提出基于交叉熵的安全Tri-training算法,如算法3所示.算法3不仅利用交叉熵来估算每个基分类器的分类误差,而且还基于初始预测结果构建了一个优化问题来求解最优解.
算法3.基于交叉熵的安全Tri-training算法.
输入:训练集D=L∪U,其中L和U分别为已标记数据集和未标记数据集,测试集T;
输出:测试数据集T中数据x的标签h(x).
①h0←Learn(L);
②hi←Learn(Bootstrap(L)), 初始化参数

③ repeat
④ fori=1 to 3 do
⑤Li←∅;
⑥ei←(Hj+Hk)2;*Hj,Hk(j,k≠i)为基分类器的交叉熵*
⑧ forU中每个样本xdo
⑨ ifhj(x)=hk(x) (j,k≠i) then
⑩Li←Li∪{(x,hj(x))};
3 实验结果与分析
3.1 实验数据集
为了验证本文方法的有效性,实验选取12个UCI(University of California Irvine)机器学习库[30]中的数据集和1个入侵检测数据集UNSW-NB15[31],共13个数据集,这些数据集仅包含2类,数据集基本信息如表1所示.其中,入侵检测数据集UNSW-NB15仅分为正常类和异常类两大类,且选取该数据集的10%进行实验.
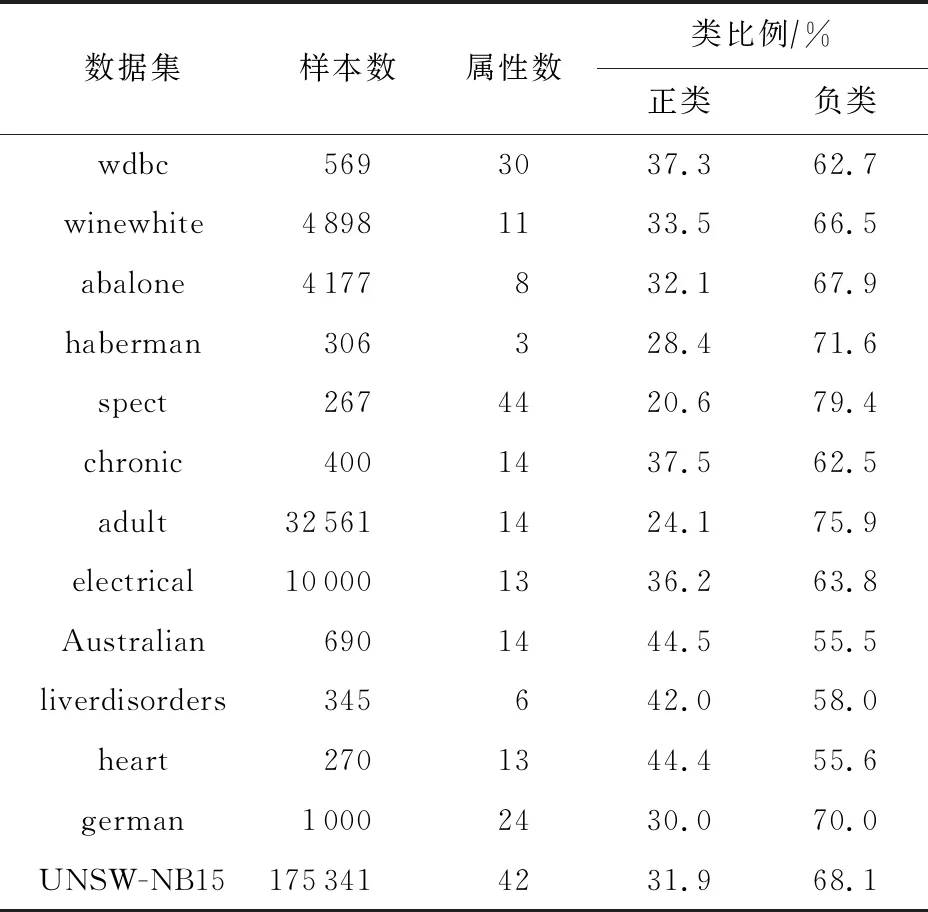
Table 1 Experimental Datasets
本文针对半监督学习,所需要的数据集仅含有少量的标记数据,其余大部分为未标记数据,而本文的13个数据集都带有标记.为了构造半监督学习任务,模拟现实中仅含有少量标记样本的情况,实验中选取20%的样本作为测试集T,余下的全部为训练集D,从D中选取20%作为已标记样本集L,80%作为未标记样本集U.
3.2 实验结果分析
本文提出了3个算法,包括基于交叉熵的Tri-training算法(Tri-training algorithm based on cross entropy, TCE)、安全的Tri-training算法(safe Tri-training algorithm, ST)和基于交叉熵的安全Tri-training算法(safe Tri-training algorithm based on cross entropy, STCE),与Tri-training算法进行实验对比.实验中采用反向传播神经网络(back propa-gation, BP)作为基分类器.
本文在混淆矩阵的基础上对算法进行性能评价.对于二分类问题,混淆矩阵如表2所示:

Table 2 Confusion Matrix
表2中TP,FP,TN,FN分别表示真正类、假正类、真负类、假负类的数量.召回率Recall、精度Precision、特效性Specificity、F值F-measure、G均值G-means、准确率Accuracy等性能指标的计算公式分别为
Recall=TP(TP+FN),
(10)
Precision=TP(TP+FP),
(11)
Specificity=TN(TN+FP),
(12)
(13)
(14)
(15)
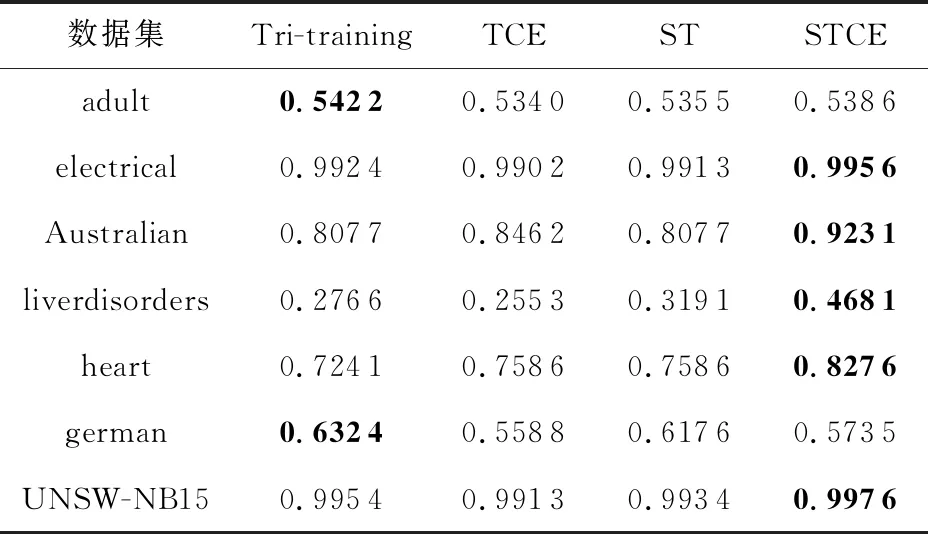
本文选取了F-measure,G-means,Accuracy,Precision,Recall这5个指标来评价算法性能,实验结果如表3~7所示:

Table 3 F-measure

Table 4 G-means

Table 5 Accuracy

Table 6 Precision
Continued (Table 6)

Table 7 Recall
从表3~7可以看出,大部分数据集在STCE算法上表现较好,其中在F-measure,G-means,Accuracy,Precision这4个指标上,分别在7,7,8,9个数据集上取得了最优的性能.ST算法在F-measure,G-means,Accuracy这3个指标上表现仅次于STCE算法.直观上看,在Recall指标上,ST算法在4个数据集上表现最好,而STCE和Tri-training、TCE算法相似,都在3个数据集上取得了较好性能.相对而言,仅有极个别数据集在TCE和Tri-training算法上表现最优.
为了进一步分析4个算法的性能,我们引入统计显著性检验[32],从统计学的角度来比较分析算法性能.本文采用Friedman检验进行计算,通过重复测量方差分析(analysis of variance, ANOVA)来比较各个算法的平均排名.其中,重复测量ANOVA是一种测试2个以上相关样本均值之间差异的统计方法.表8显示了本文提出的3种算法与Tri-training算法经过Friedman检验后的等级排名,取值越低等级越高.

Table 8 Average Rank After Friedman Test
由表8可以看出,基于交叉熵的安全Tri-training算法STCE在5项评价指标上均取得了最高的等级,最低取值为1.576 92,最高取值也只有2.230 77,比传统的Tri-training算法的最低取值2.499 96还要低.根据平均等级可以得到4个算法的分类性能,从高到低依次为:STCE,ST,Tri-training,TCE,即STCE算法的分类性能最好,ST算法次之,但也明显好于Tri-training和TCE算法.Tri-training算法和TCE算法性能相当,表明仅用交叉熵替代误分率作为Tri-training更新的条件,并不能显著改善半监督学习的分类性能,而利用凸优化可以在一定程度上提高半监督学习的分类性能,将交叉熵和凸优化方法相结合,可得到更好的分类性能.
我们进一步使用Holm检验[32]来对最佳排名方法STCE与其他方法进行比较,并选择STCE作为控制方法,取置信水平α=0.05进行测试,结果如表9所示:
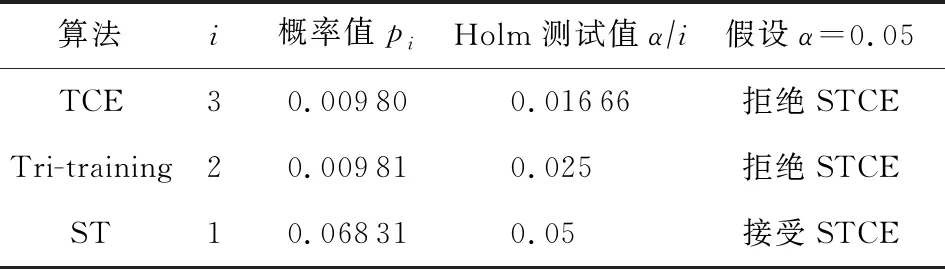
Table 9 Holm Test Results
表9中的pi(i=1,2,3)是由Holm检验计算出来的概率值,用来度量否定原假设的证据.概率值越低,否定原假设的证据越充分.检验从概率值p3开始,由于p3=0.009 80小于Holm测试值α3=0.016 66,因此拒绝假设.同样,第2个假设也被拒绝.对于最后一个假设,由于p1>0.05,故接受该假设.结果表明,STCE算法优于TCE算法和传统的Tri-training算法,然而STCE算法和ST算法之间没有统计学上的差异.这个结论和表8得出的结论相一致.
4 总结与展望
传统的Tri-training算法能有效提升半监督学习的分类性能.为了进一步降低Tri-training算法过程中产生的误标率,提高算法性能,获得良好的半监督分类模型,本文分别提出了基于交叉熵的Tri-training算法(TCE)、安全的Tri-training算法(ST)和基于交叉熵的安全Tri-training算法(STCE).实验结果表明,提出的STCE方法具有最好的分类性能.然而,本文并没有考虑到半监督学习过程中数据集不平衡的问题,这将是我们下一步的研究内容和方向.
