基于混合特征选择模型CatBoost-LightGBM的违约风险预测研究
2021-01-14程楠楠

摘 要:疫情后,互联网消费金融在国民经济复苏增长中发挥积极作用,但因其产品本身特殊性及过快的发展性,也伴随大量的风险。文中在算法可解析性、模型应用性(识别性、准确性、低成本、稳定性)基础上构建了混合特征选择模型CatBoost-LightGBM,并将此模型应用于某知名信贷平台。结果表明,混合特征选择模型CatBoost-LightGBM在综合评价上显著优于单一模型,对基础模型LR有0.19的提升,对基础特征的LightGBM、XGboost等模型有0.03的提升。
关键词:违约风险预测;消费金融;大数据风控;特征选择;梯度提升算法
中图分类号:TP183 文献标识码:A文章编号:2096-4706(2021)14-0116-05
Abstract: After the epidemic, internet consumer finance plays a positive role in the recovery and growth of the national economy, but due to the particularity and rapid development of its products, it is also accompanied by a large number of risks. In this paper, a hybrid feature selection model catboost-LightgBM is constructed on the basis of the analytical ability of the algorithm and the application of the model. Finally, the model is applied to a well-known credit platform. The results show that the hybrid feature selection model catboost-LightgBM is significantly better than the single model in the comprehensive evaluation. It improves the basic model LR by 0.19 and the lightgbm, xgboost and other models with basic features by 0.03.
Keywords: default risk prediction; consumer finance; big data risk control; feature selection; gradient lifting algorithm
0 引 言
我國消费金融在经历起步、探索、发展等阶段后,与互联网和信息技术融合,呈现出新特点。但由于过快增长,也积聚了一定风险。2021年是“十四五”规划开局之年,如何更好地利用新契机、新需求,直面存在的不足和问题,提升内生的风控能力和水平,是消费金融能否实现可持续健康发展的关键。
消费金融产品的特性是放款金额小,审批速度快,规模数量大,风险细节多[1]。因此构建一个高效、精准、客观、低成本 但同时普适的风控模型非常重要,一方面不仅仅给企业自己带来利润的提升(减少坏账率),还能通过赋能影响给整个系统带来稳健性,防止大规模金融风险。
随着大数据、人工智能的发展,机器学习逐渐应用于金融贷款风险预测中,国内外学者主要分三个研究方向:一是利用单一的机器学习模型或其改进模型,比如Lobna等人采用Logistic回归来区分“坏”的贷款人[2],王晓燕等人通过构建logit-linear 两部模型对银行贷款违约预测研究[3];二是集成学习算法,集成学习方法因为具有精度高,可解释性强等特点,近年来在风控评估模型中的应用也越来越广泛。例如卞凌志(2021)在周志华深度森林模型的基础上借鉴残差学习的思想,建立了级联残差森林(grcForest)的模型进一步提高特征提取的多样性[4]。李泽远使用LightGBM对比卷积神经网络,LightGBM模型性能和稳定性结果显著[5]。三是深度学习的神经网络模型,Stevenson利用Deep Learning和NLP技术建立基于文本的贷款违约预测模型并用实验证明其有效性[6]。
在风险评估模型研究上,近三年的机器学习应用模型给本课题的研究开拓了思路。聚焦在金融风控领域,算法的“黑箱”与“歧视”[7]可能会导致监管和法律风险,因此神经网络等复杂的模型或者深度学习模型很难在企业中实际落地。集成决策树算法是个很好的建模方向,它可以有深度学习的准确度,也有统计学泛线性模型(例如逻辑回归)的解释性。目前的集成决策树算法在信贷风险评估模型应用中可能会出现过拟合和稳定性差等问题,需要进一步深化研究,为此本课题试图在平衡业务可解释性、模型预测精度、稳定性及可维护性之间构建一个不降低精确度但业务成本最低的风控模型,以期更好的适配消费金融的小额信贷场景。
1 数据分析与数据处理
1.1 数据获取与变量分析
本次实验数据来源于国内某头部互联网信贷平台的贷款记录,总数据量超过120万条,包含47列变量信息,其中15列为匿名变量,为用户隐私安全考虑,特将employmentTitle、purpose、postCode和title等信息进行脱敏,部分数据变量信息如表1所示。
1.2 数据业务分析
基于业务逻辑理解和业务分析方法,预测用户未来一期的还款情况,主要从以下两个方面进行评估。一是用户的还款意愿,二是用户的还款能力。本文还款意愿的刻画可以从贷款人的基本信息和信用状况变量入手,还款能力需要综合贷款信息、贷款人信息及贷款人的财务情况进行分析刻画。
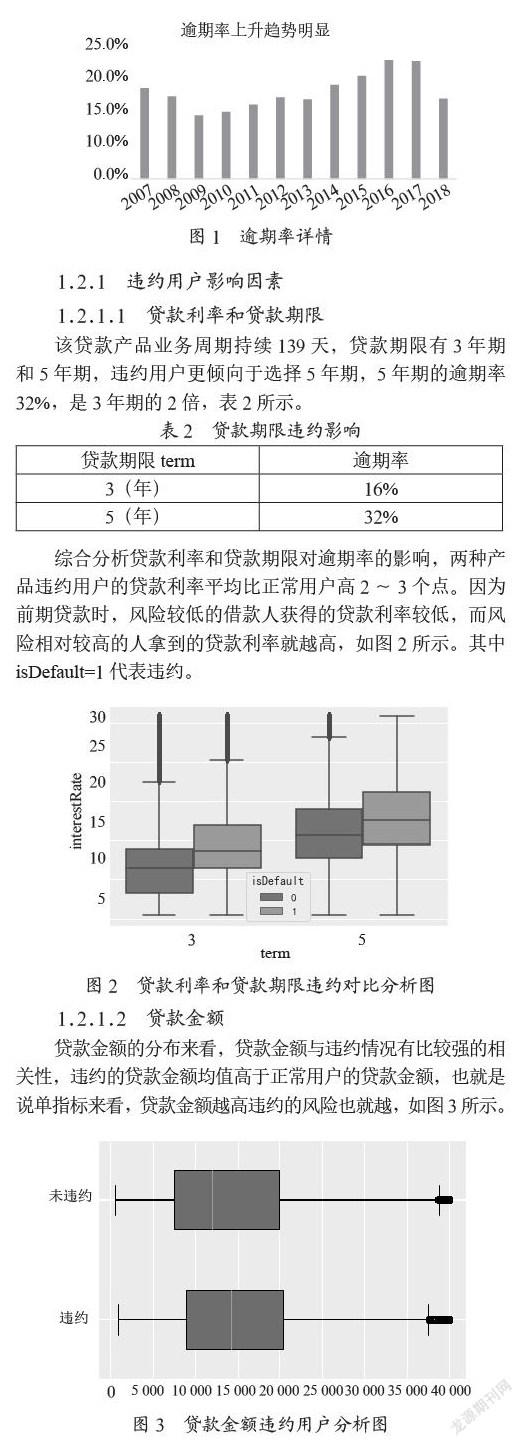
本实验信贷平台平均逾期率在20%左右。从时间维度来看2009—2017年逐年升高,2018年开始公司不断优化自身的风险控制系统,不断增强违约预测模型的效率来提升平台的良性发展。具体如图1所示。
1.2.1 违约用户影响因素
1.2.1.1 贷款利率和贷款期限
该贷款产品业务周期持续139天,贷款期限有3年期和5年期,违约用户更倾向于选择5年期,5年期的逾期率32%,是3年期的2倍,表2所示。
综合分析贷款利率和贷款期限对逾期率的影响,两种产品违约用户的贷款利率平均比正常用户高2~3个点。因为前期贷款时,风险较低的借款人获得的贷款利率较低,而风险相对较高的人拿到的贷款利率就越高,如图2所示。其中isDefault=1代表违约。
1.2.1.2 贷款金额
贷款金额的分布来看,贷款金额与违约情况有比较强的相关性,违约的贷款金额均值高于正常用户的贷款金额,也就是说单指标来看,贷款金额越高违约的风险也就越,如图3所示。
1.2.1.3 工作年限
工作年限是用户自己填写,有部分失真,目前看和违约率关系不大,工作年限违约用户分析图如图4所示。
1.3 数据异常分析与处理
本文用到的数据是业务给到的原始数据,存在缺失、异常等问题,并不能直接建模,需要进行一系列的数据清洗处理才可使用。
1.3.1 缺失值處理
首先删除无意义的变量,比如PolicyCode只有一个值,无业务分类意义。然后对留下来的数据进行缺失值处理。其中工作年限EmploymentLength缺失率高达5.85%,部分信用指标如RevolUtil缺失率在0.07%,财务状况指标Dti缺失率在0.03%。为保持数据集的完整性,利用均值插补法对缺失值进行填充。
1.3.2 类别变量处理
类别变量主要分为有序类别变量和无序类别变量,对于有序类别变量如Grade、subgrade、EmploymentLength进行1到n的序数编码。
对日期类型变量IssueDate按照产品上市日期进行数值变化为天数。对信用类变量EarliesCreditLine字符串进行数值提取转换。
2 算法模型介绍
2.1 混合特征选择模型CatBoost-LightGBM
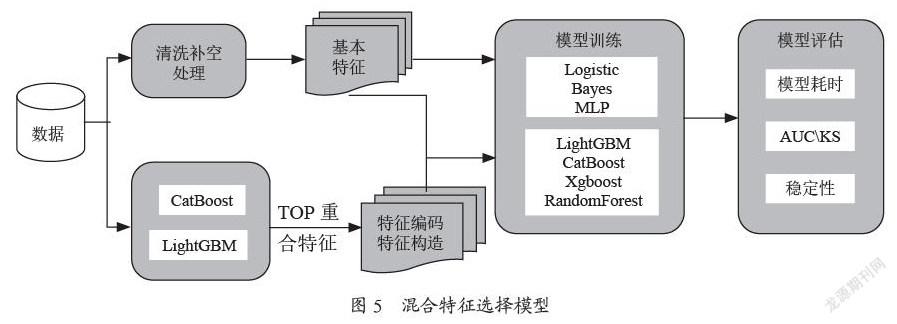
整个算法模型架构如图5所示,将数据分成两组,一组进行传统的清洗、补空、数值归一化等处理然后入模;另外一组先入模集成树CatBoost-LightGBM模型,筛选重要特征进行构造衍生,并将其和基本特征进行混合再次入模对比试验。
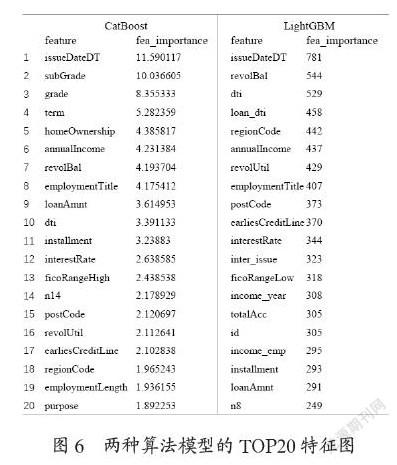
数据入模CatBoost和LightGBM算法,并给出特征重要性排序。两种算法模型的TOP20特征如图6所示。其中CatBoost的特征重要性原理是计算包含与不包含该特征下模型的损失函数,差别越大表明该个越重要。LightGBM的特征重要性是基于使用该特征作为分割带来的总增益来计算。
对两个模型TOP20重要性的特征进行重合度分析,共有12个重合特征,然后对这12个特征按照业务规则再进行特征构造。比如IssueDate进行周、月维度的构造;对贷款金额进行WOE分箱离散化;将贷款金额和工作年限做比例;对贷款金额和年收入做比例等。这样将新特征共计87个入模LightGBM进行递归后向消除特征法RFE筛选,最终得到74个混合特征两种算法模型的TOP20特征图如图6所示。
2.2 梯度提升算法Boosting
梯队提升Boosting算法是一种集成学习思想,它是把K个专家(K个分类器)进行加权融合,形成一个新的超级专家(强分类器),让这个超级专家做判断。梯队提升算法按已经被证明是一个非常重要的算法策略,许多成功的机器学习算法因Boosting而起。
2.2.1 XGBoost
XGBoost[8]的全称是Extreme Gradient Boosting,由华盛顿大学的陈天奇博士提出。它是由k个基模型组成的一个加法运算式:
其中yi是第i个样本的预测值,fk为第k个样本的基模型。
XGBoost训练的时候,是通过加法进行训练,也就是每一次只训练一棵树出来,最后的预测结果是所有树的加和表示。实现过程利用了预排序和近似算法可以降低寻找最优分裂点的计算量,但在节点分裂过程中仍需要遍历整个数据集。
2.2.2 LightGBM
LightGBM[9]是2017年由微软推出的可扩展机器学习系统,可以看作是XGBoost的升级豪华版,在获得与XGBoost近似精度的同时,又提供了更快的训练速度与更少的内存消耗。首先它基于直方图算法进行优化,使数据存储更加方便、运算更快、鲁棒性强、模型更加稳定等。其次该算法使用了带有深度限制的按叶子生长策略,可以降低误差,得到更好的精度。再其次通过单边梯度采样来平衡数据量和算法精度。
2.2.3 CatBoost
CatBoost[10]是俄罗斯的搜索巨头Yandex在2017年开源的机器学习库,是Boosting族算法的一种。CatBoost是一种基于对称决策树(oblivious trees)为基学习器实现的参数较少、支持类别型变量和高准确性的GBDT框架,主要解决的痛点是高效合理地处理类别型特征,此外,CatBoost还解决了梯度偏差(Gradient Bias)以及预测偏移(Prediction shift)的问题,从而减少过拟合的发生,进而提高算法的准确性和泛化能力。
3 模型实验
3.1 评价指标
对于二分类模型来说,经常会用AUC来度量。ROC(Receiver Operator Characteristic)即一个二维坐标轴中的曲线,AUC(Area under ROC Curve)即ROC曲线下的面积。AUC越接近1.0,检测方法真实性越高,代表分类效果越好。但是对于不平衡数据且bad rate会有变化的数据,AUC的效果容易失真,需额外使用KS(Kolmogorov-Smirnov)值,KS值评估模型的区分度(discrimination)是在模型中用于区分预测正负样本分隔程度的评价指标。KS的计算方法直观就是:
KS=max(abs(TPR-FPR))
其中TPR:TP/(TP+FN)真阳率或者召回率;FPR:FP/(FP+TN)假阳率或者误诊率。
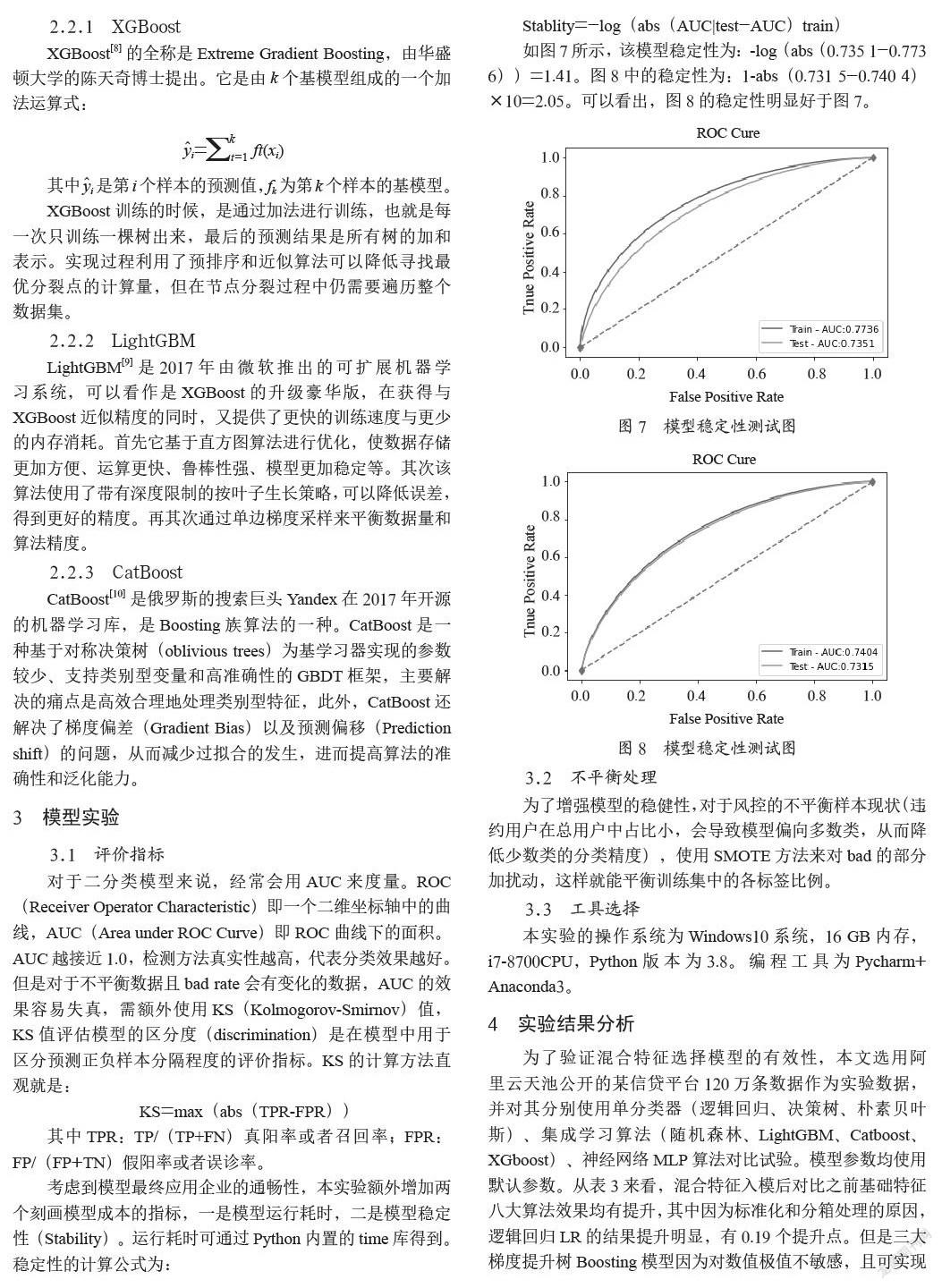
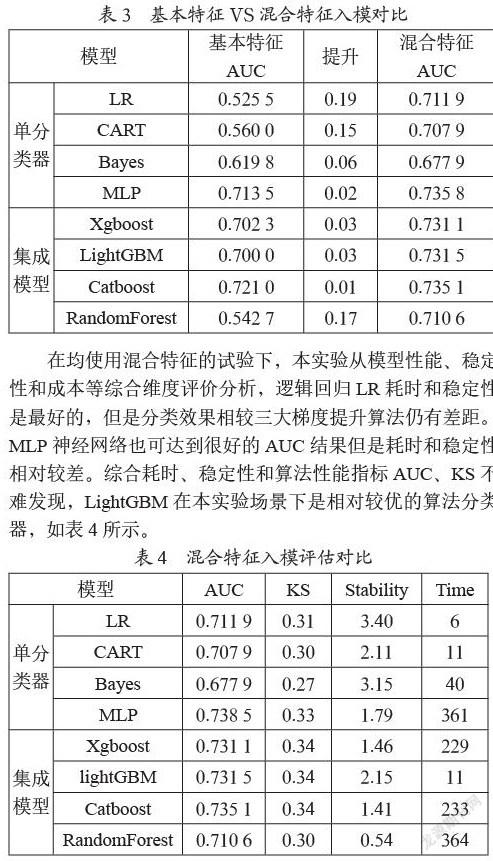
考虑到模型最终应用企业的通畅性,本实验额外增加两个刻画模型成本的指标,一是模型运行耗时,二是模型稳定性(Stability)。运行耗时可通过Python内置的time库得到。稳定性的计算公式为:
Stablity=-log(abs(AUC|test-AUC)train)
如图7所示,该模型稳定性为:-log(abs(0.735 1-0.773 6))=1.41。图8中的稳定性为:1-abs(0.731 5-0.740 4)×10=2.05。可以看出,图8的稳定性明显好于图7。
3.2 不平衡处理
为了增强模型的稳健性,对于风控的不平衡样本现状(违约用户在总用户中占比小,会导致模型偏向多数类,从而降低少数类的分类精度),使用SMOTE方法来对bad的部分加扰动,这样就能平衡训练集中的各标签比例。
3.3 工具选择
本实验的操作系统为Windows10系统,16 GB内存,i7-8700CPU,Python版本为3.8。编程工具为Pycharm+ Anaconda3。
4 实验结果分析
为了验证混合特征选择模型的有效性,本文选用阿里云天池公开的某信贷平台120万条数据作为实验数据,并对其分别使用单分类器(逻辑回归、决策树、朴素贝叶斯)、集成学习算法(随机森林、LightGBM、Catboost、XGboost)、神经网络MLP算法对比试验。模型参数均使用默认参数。从表3来看,混合特征入模后对比之前基础特征八大算法效果均有提升,其中因为标准化和分箱处理的原因,逻辑回归LR的结果提升明显,有0.19个提升点。但是三大梯度提升树Boosting模型因为对数值极值不敏感,且可实现自动编码,初始入模效果也较好。
在均使用混合特征的试验下,本实验从模型性能、稳定性和成本等综合维度评价分析,逻辑回归LR耗时和稳定性是最好的,但是分类效果相较三大梯度提升算法仍有差距。MLP神经网络也可达到很好的AUC结果但是耗时和稳定性相对较差。综合耗时、稳定性和算法性能指标AUC、KS不难发现,LightGBM在本实验场景下是相对较优的算法分类器,如表4所示。
5 结 论
在金融风控领域,由于银行监管要求,风控模型需要满足解释型要求才能批准上线。加上消费金融产品用户多、贷款金额小等特别,风险管控的成本和难度更大。本文通过Boosting集成思想提出了一种基于混合特征选择的CatBoost-LightGBM集成树模型,在描述风险影响因素、预测违约风险上是显著有效的,且对基础模型LR有0.19的提升,对基础特征的LightGBM、XGboost等模型有0.03的提升。
本文仅在公开的数据表含有的特征中进行挖掘建模,未来还会综合用户的社交属性、疫情灾害等外部条件的约束对用户无法按时还款造成的影响,来进一步提高模型的准确性和普适性。
参考文献:
[1] 单良,乔杨.数据化风控 [M].北京:电子工业出版社,2018.
[2] ABID L,MASMOUDI A,ZOUARI-GHORBEL S. The Consumer Loan’s Payment Default Predictive Model:an Application of the Logistic Regression and the Discriminant Analysis in a Tunisian Commercial Bank [J].Journal of the Knowledge Economy,2018,9:948-962.
[3] 王小燕,袁腾,段湘斌.基于零膨胀分位数两部模型的银行贷款违约预测研究 [J/OL].中国管理科学:1-15[2021-04-25].https://doi.org/10.16381/j.cnki.issn1003-207x.2020.0441.
[4] 周波,李俊峰. 结合目标检测的人体行为识别 [J]. 自动化学报,2020(9):1961-1970.
[5] 李泽远.可超越评分卡模型么?基于LightGBM与卷积神经网络在贷款违约风险预测的研究 [J].特区经济,2021(5):67-69.
[6] STEVENSON M,MUES C,BRAVO C. The value of text for small business default prediction:A Deep Learning approach [J].European Journal of Operational Research,2021,295(2):758-771.
[7] 黄益平,邱晗.大科技信贷:一个新的信用风险管理框架 [J].管理世界,2021,37(2):12-21+50+2+16.
[8] CHEN T Q,GUESTRIN C. XGBoost:A Scalable Tree Boosting System [C]//Proceedings of the 22nd ACM SIGKDD International Conference on Knowledeg Discovery and Data Mining.New York:ACM,2016:1-10.
[9] KE G L,MENG Q,FINLEY T,et al. LightGBM:a highly efficientgradient boosting decision tree [C]//Proceedings of the 30thInternational Conference on Neural Information ProcessingSystems. Red Hook:Curran Associates Inc. ,2017:3146-3154.
[10] PROKHORENKOVA L,GUSEV G,VOROBEV A,et al. CatBoost:unbiased boosting with categorical features [C]//Advances in Neural Information Processing Systems.Montreal,2018:6638-6648.
作者簡介:程楠楠(1987.12—),女,汉族,江苏南通人,其他高级,硕士,研究方向:商业分析、机器学习、大数据风控。
