基于ARIMA和XGBoost算法的辅逆系统故障预测
2021-01-11吴强屈利杰
吴强,屈利杰
(中车南京浦镇车辆有限公司,江苏 南京 210000)*
截至2019年9月30日,我国内地累计有39个城市开通运营,轨道交通线路总计6333.3 km,新增运营线路571.9 km.城市轨道交通的迅猛发展,设备的安全性也备受关注.车辆是其重要载体,目前对车辆的研究技术在不断的改进和加强,牵引、辅逆、制动、车门、空调等系统日趋复杂,因而发生故障的类型更加多样化,如何基于车载和轨旁系统数据来提前进行故障预警预测,是PHM系统成功与否的关键所在.国内外研究机构和企业都在这一领域做了大量的尝试与验证.在故障预测的研究方面,早期研究多关注单个设备部件.近年来,随着轨道交通行业数据的积累,基于深度学习的智能运维逐渐兴起[1-2].
目前常用的故障预警方法有:
(1)固定阈值法[3-4]:通常根据专家经验知识设定阈值范围.该方法优点是简单,缺点是需要大量依赖人工经验,不适用于周期性变化的数据,维护困难,准确性较差.
(2)基于数据驱动的预测技术[5-6],是通过设备生命周期中大量的数据信息,通过学习获得输入和输出的映射关系,并在内部建立非透明、非线性和不针对特定目标的预测模型,实现对设备未来状态的预测.对于复杂系统来讲,因其本身结构的复杂性,使得建立与之相对应的物理模型是很困难的.
(3)基于统计分析的预测[7-8],利用实际生产中积累的经验数据对产品进行分析,得到参数信息,并利用设备性能数据统计出各类故障概率密度函数,形成动态模型,同时使用性能数据对参数信息持续性修正,不断提高预测精度.
(4)基于时间序列的预测:李向前等人[9-10]提出了检测时间序列中异常值的方法.此外,当前流行的异常检测算法还有:基于分类,基于聚类,基于最近邻,基于信息理论,这些方法应用到不同领域的异常检测中,能有效提高检测的准确度.
但是以上方法在目前轨道交通领域都只能部分借鉴,原因是现有系统采集的数据量少,故障时的负样本更少.本文提出了利用XGBoost和ARIMA算法来预测某类模拟量的趋势,并给出相应的预警信息.
(1)采用XGBoost算法拟合各工况下辅逆温度变化曲线;
(2)利用拟合曲线与实际值偏差做正态分布,定义警告阈值线和错误阈值线;
(3)ARIMA算法预测后三天的趋势走向,并通过与警告阈值线和错误阈值线的比较给出相关预警的信息提示.
1 辅逆温度曲线拟合
由于XGBoost模型可以控制模型的复杂度,防止模型过拟合,并且在样本缺失时,可以自动学习分裂方向,本文通过综合比较,引入XGBoost模型.XGBoost在迭代过程中通过树的深度和数量自适应拟合辅逆系统温度变化情况,并在迭代过程中,通过正则项,防止模型过拟合,提高预测辅逆系统温度的准确性.因此,本文采用基于XGBoost算法的辅逆系统温度预测模型,公式如下所示:
(1)
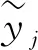
XGBoost训练优化的目标公式如下:
(2)
(3)


2 数据整理与分析
2.1 数据整理
本文所采用的原始数据来自于某条实际运营的地铁车辆,共包含11列车载数据集,时间跨度为2019年02月01日~2019年06月30日,数据采样周期为0.5 s,文件大小约为380 GB.
车载数据通过4G物联网传输,采样周期应为0.5s,但是传输不稳定导致时间记录不连续,数据存在大量缺失和异常值.为了解决原始数据集质量和存储问题,对数据进行整理,剔除缺损值,只选取测点数量较为完整的文件,共1654个文件,通过优化数据存储类型,可降低内存消耗,提高算法的收敛速度.
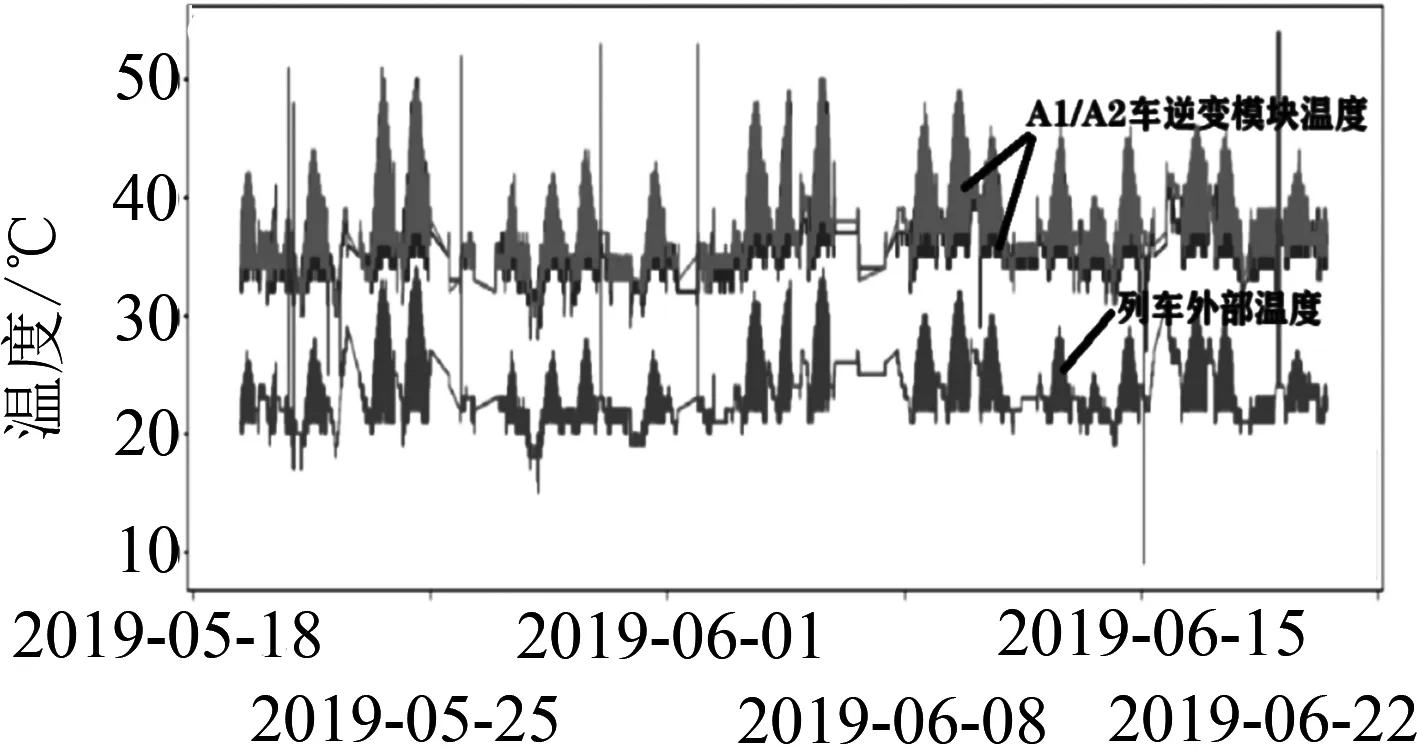
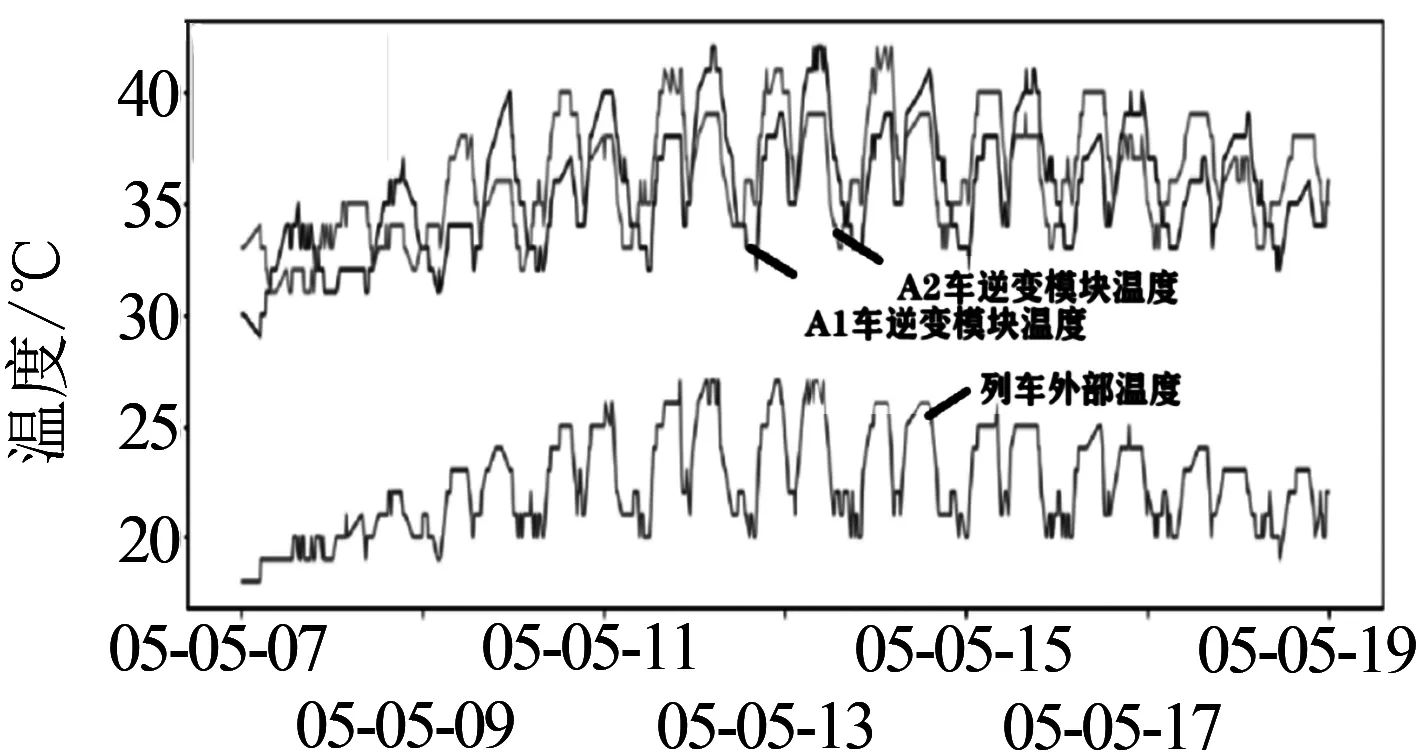
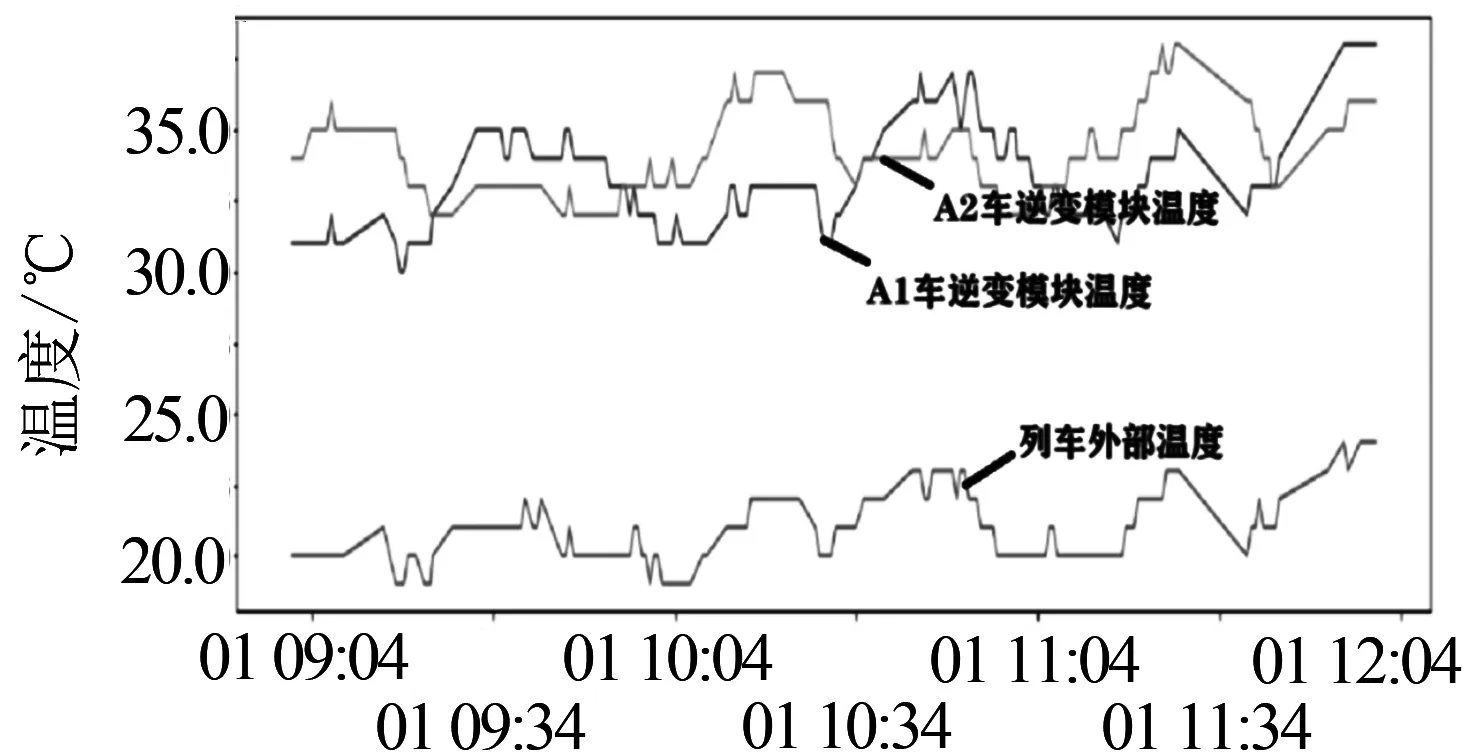
利用专家经验、机理研究和前期的数据探索,发现辅逆温度的变化与列车的外部温度、空压机的运行情况、空调的运行情况等有着直接的关系,数据探索情况见图1.在曲线拟合的过程中,选取了数据集里的CTDU_空调_列车外部温度,HC1CT_空调_A1车外部温度,HC2CT_空调_B1车外部温度,CTPCBC_制动_空压机组1运行,CTDC_空调_A1车空调能耗值,CTDC_空调_B1车空调功率等,来拟合辅逆温度的变化曲线,并与实际值AC1CT_辅助_A1车逆变模块温度做比较分析,对比结果见图2.
在算法生成过程中,采用分车交叉验证,应对不同列车自身数据分布差异,提供算法的鲁棒性和泛化能力.

(a)辅逆温度与空调功率之间的关系

(b)辅逆温度与辅逆功率之间的关系
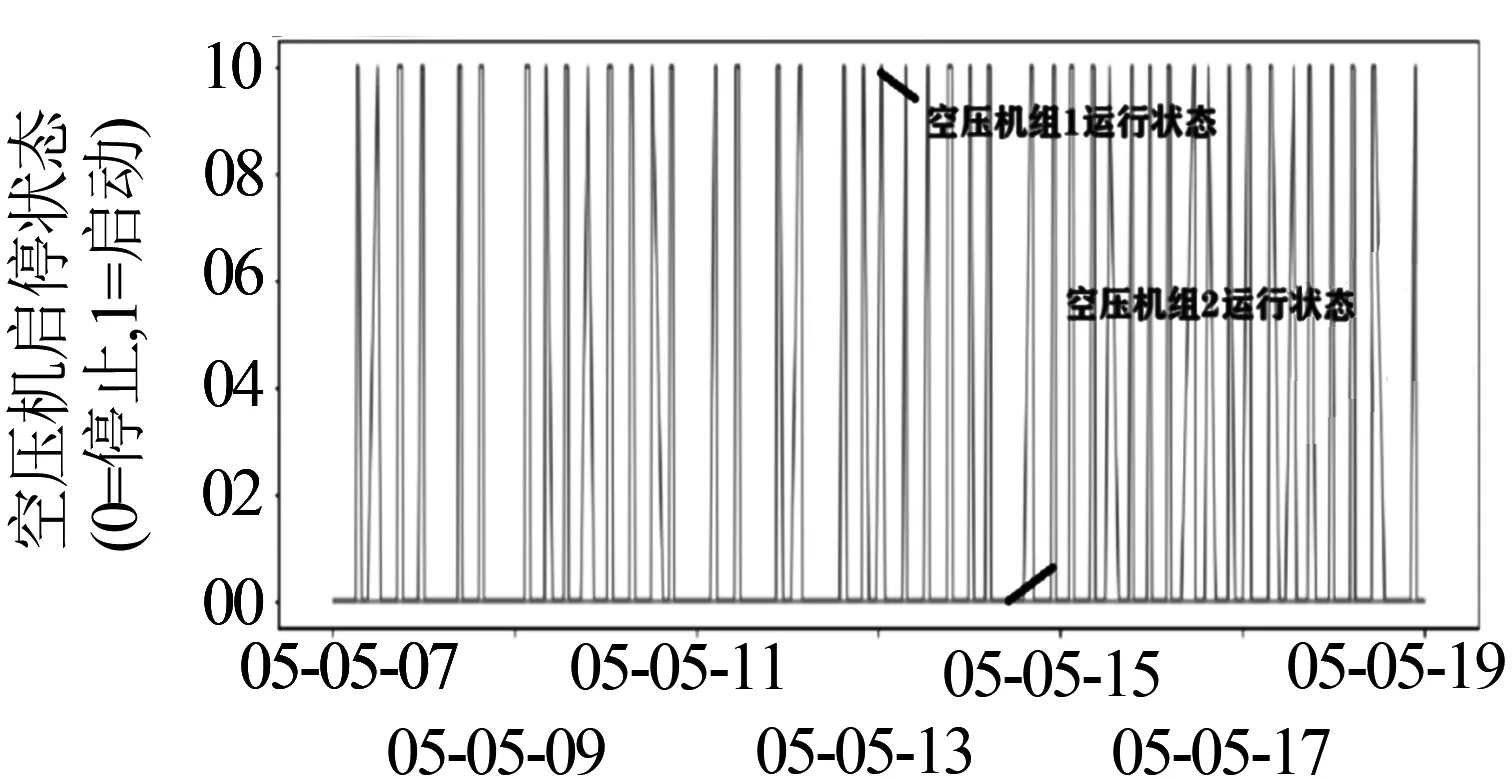
(c)辅逆温度与空压机启停之间的关系

(d)辅逆温度与制动电阻风机启停之间的关系

图2 辅逆温度拟合曲线与实际曲线的对比
本文采用决策树、随机森林、梯度提升树算法、XGBoost分别拟合辅逆系统温度变化曲线,结果如表1所示,其中R2代表绝对系数,MAE表示预测结果绝对误差的平均值,MSE表示均方误差.通过比较表1中的数据发现,采用XGBoost模型预测辅逆系统温度时的R2更接近于1,为0.952 3,说明采用XGBoost模型拟合辅逆系统温度效果更好;运用XGBoost模型预测辅逆系统温度时MAE值最小,为1.046,说明采用XGBoost模型预测辅逆系统温度有更好的鲁棒性;采用XGBoost模型预测辅逆系统温度时MSE值最大,为1.998,说明采用XGBoost模型预测辅逆系统温度有更好的精确度.所以,经过对比发现,使用XGBoost算法预测辅逆系统温度时的精确度更高,鲁棒性更好.

表1 不同算法之间的比较
2.2 残差分布
选取2019年4~5月的车载数据集作为样本集,采用已训练好的XGBoost算法拟合出辅逆温度的曲线,以天为单位,计算出实际辅逆温度和拟合辅逆温度之间的偏差,绘制偏差分布如图3所示.
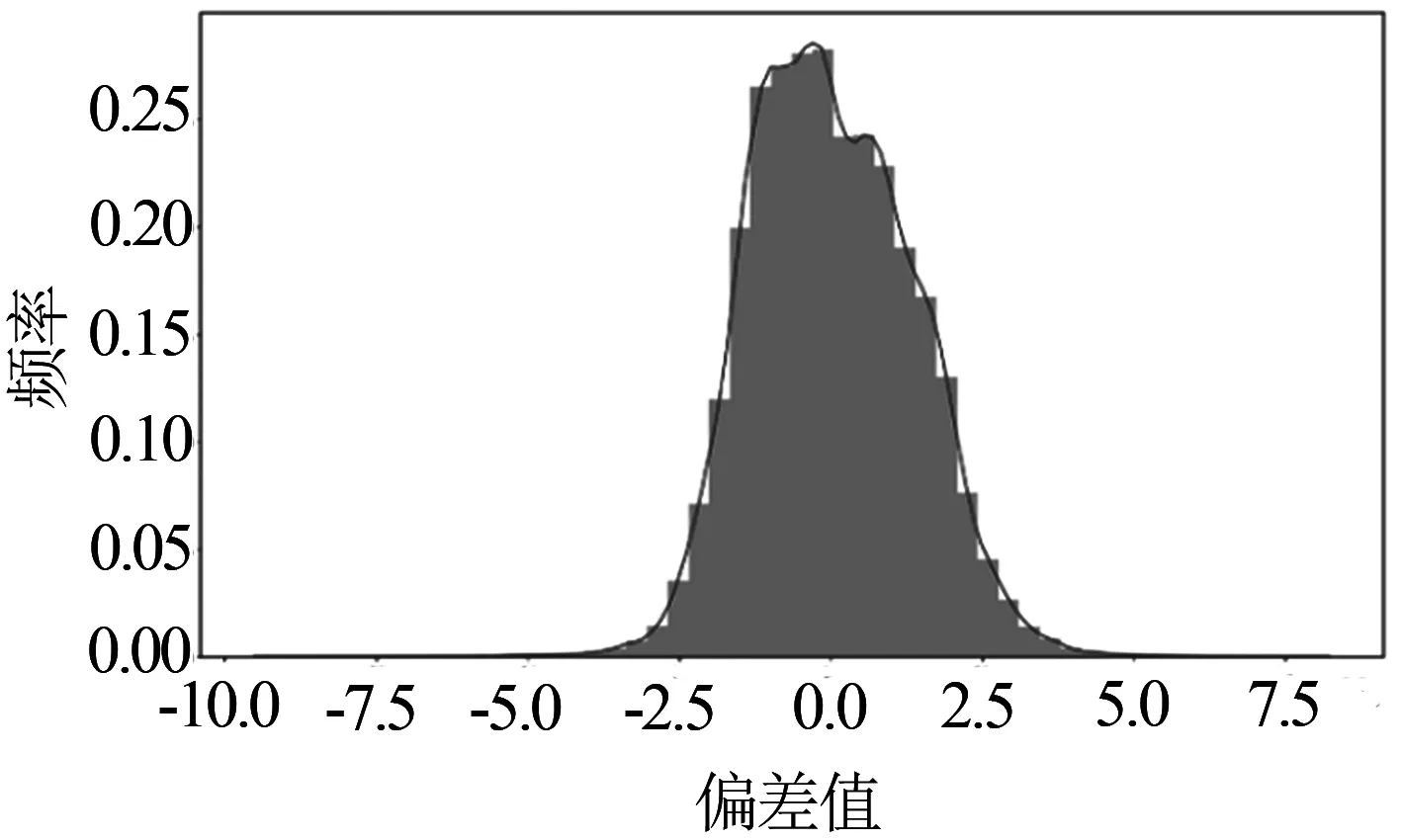
图3 实际值与拟合值偏差的分布
计算统计所有列车偏差分布,提取残差分布的统计特征,整体分布均值0.021 2,标准差为1.31,中位数为-0.069 6,数值范围在[-9.15, 7.87],近似服从正态分布.因此,使用正态分布的标准差判断逆变模块温度是否存在异常趋势.
本文定义误差超过均值±2倍标准差之外的点判定为预警点,误差超过均值±3倍标准差之外的点判定为误差点.
通过以上定义,统计测试该时间段内每列车每天对应异常数据点的比例,寻找趋势线,为确保统计数据的有效,要求当天数据满足以下条件:①剔除异常的温度数据;②要求当天满足列车速度大于0的数据大于50个采样点.
求取以上异常点的比例,作为下一步时间序列预测的基础数据.
3 时间序列预测
ARIMA模型[11](差分自回归移动平均模型,Auto-regressive Integrated Moving Average Model),是一种较高精度的时间序列预测分析方法,模型简单,只需要内生变量,不需要借助其它外生变量,是20世纪70年代美国统计学家GEP-Box和英国统计学家GMJenkins建立的一种随机时间序列模型.基于预测对象随时间变化形成的数据序列,建立数学模型.模型通过后,利用建立的方程中的过去值来预测下一个时间段的数据.
ARIMA(p,d,q)的公式:
(4)
本文以异常点比例日线作为待预测目标,使用ARIMA进行建模.经过ADF-Test等平稳性检验,警告阈值线、错误阈值线均需要进行一阶差分后趋于平稳.通过对ACF图和PACF图的分析,得到ARIMA参数如下:
警告阈值线:ARIMA(6,1,1)
错误阈值线:ARIMA(5,1,1)
利用ARIMA模型预测各列车辅逆温度的趋势,如图4所示.根据测试结果可知,T4编组、T6编组、T8编组、T10编组预测的警告阈值线和错误阈值线整体都在设定的警告阈值线和错误阈值线之下,均未报出异常,与实际列车运营情况相吻合.后期会持续针对实际运行数据样本对模型进行预测.
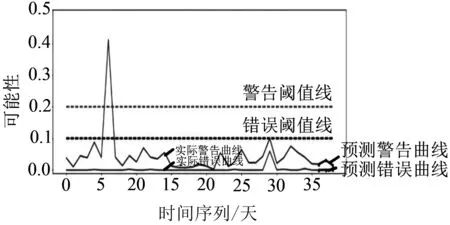
(a)T4
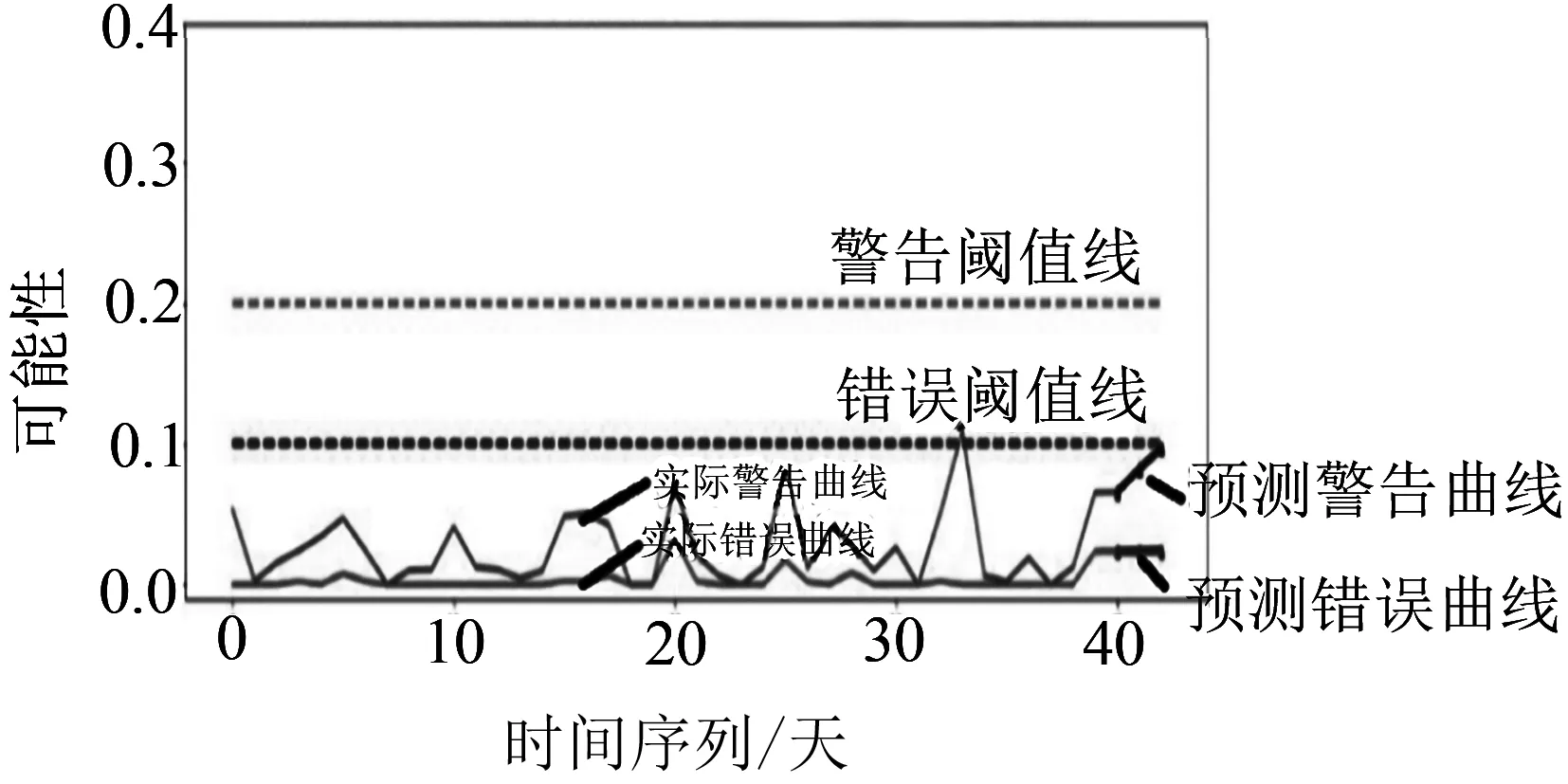
(b)T6
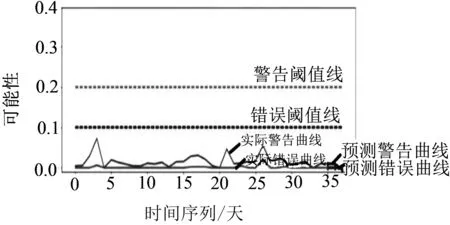
(c)T8
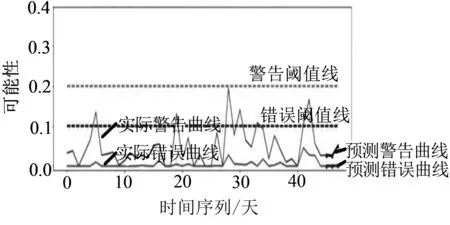
(d)T10
4 结论
本文提出了XGBoost和ARIMA算法来预测列车辅逆系统温度变化趋势,并通过数据探索、曲线拟合、时序预测等方法进行实践,预测的整体结果与实际情况相吻合.但是由于辅逆超温的异常数据样本极少,后期还需要结合更多的样本进行训练,来提高算法的鲁棒性和泛化能力.此方法对列车运营过程中存在的负样本较少的实际应用提供了一种新的探索方法,对健康诊断系统故障预测有借鉴和指导意义.
